





事件抽取综述
- 摘要
- 简介 INTRODUCTION
- 本文贡献 Contributions
- 本文的组织结构 cOrganization of the Survey
- PRELIMINARY
- 事件抽取的例子 EVENT EXTRACTION PARADIGM
- 深度学习时间抽取模型 DEEP LEARNING EVENT EXTRACTION MODELS
- 事件抽取的场景 EVENT EXTRACTION SCENARIOS
- 事件抽取语料库 EVENT EXTRACTION CORPUS
- 评价指标 METRICS
- 定量结果 QUANTITATIVE RESULTS
- 事件抽取的应用 EVENT EXTRACTION APPLICATIONS
- 未来研究趋势 FUTURE RESEARCH TRENDS
- 结论 CONCLUSION
A Survey on Deep Learning Event Extraction:Approaches and Applications:
深度学习事件抽取的调查:方法和应用
摘要
事件抽取是从海量文本数据中快速获取事件信息的一项重要研究任务。 随着深度学习的快速发展,基于深度学习技术的事件抽取成为研究热点。 文献中提出了许多方法、数据集和评估指标,提出了对全面和更新调查的需求。 本文通过回顾最先进的方法,尤其关注基于深度学习模型的一般领域事件提取。 我们根据任务定义介绍了当前通用领域事件提取研究的新文献分类。 之后,我们总结了事件提取方法的范例和模型,然后详细讨论了它们中的每一个。 最重要的是我们总结了支持预测和评估指标测试的基准。 本次调查还提供了不同方法之间的综合比较。 最后,我们总结了该研究领域未来的研究方向。
简介 INTRODUCTION


事件提取(EE)是信息提取研究中一项重要但具有挑战性的任务。 作为一种特定形式的信息,事件是指在特定时间和特定地点发生的涉及一个或多个参与者的事情的特定事件, 这通常可以描述为状态的变化[1]。 事件提取任务旨在将此类事件信息从非结构化纯文本中提取为结构化形式, 它主要描述“谁,何时,何地,什么,为什么”和“如何”发生的现实世界事件。在应用方面,该任务便于人们检索事件信息并分析人们的行为,引起信息检索,推荐,智能问答,知识图谱构建,以及其他与事件相关应用的广泛关注。
事件提取可分为两组:特定领域事件提取和开放领域事件提取 。事件通常在预定义的事件模式中考虑,其中一些特定的 人和物在特定的时间和地点相互作用。 特定领域事件抽取任务旨在寻找属于一个特定的事件模式的词语,它指的是一个 发生的动作或状态变化,及其抽取目标 包括时间、地点、人物、动作等。在开放域事件抽取任务中,事件被认为是一个集合 一个主题的相关描述,可以制定 进入分类或聚类任务。开放领域事件 提取是指获取一系列相关的事件 一个特定的主题,通常由多个事件组成。 特定领域事件提取还是开放域事件提取 任务,事件抽取的目的是捕获事件 我们从众多文本中抽取感兴趣的类型和并且以结构化的形式展示事件的基本论点。
一般领域的深度学习事件抽取有大量的工作,已经是一个比较成熟的研究分类法。
它从文本中发现事件提及(event mentions)并提取包含事件触发器和事件参数的事件(event triggers and event arguments),其中事件提及被称为包含一个或多个触发器和参数的句子。
事件抽取需要对事件进行识别,对事件类型进行分类,识别论元,判断论元的作用。 具体来说,触发识别和触发分类通常形成为事件检测任务、 而参数识别和参数角色分类通常被定义为参数提取任务。 触发分类是一个多分类任务,对每个事件的类型进行分类。 角色分类任务是基于词对的多类分类任务,确定句子中任意一对触发器和实体之间的角色关系。 从技术角度来看,事件提取可以依赖于其他一些基础自然语言处理 (NLP) 任务,例如命名实体识别、语义解析和关系抽取。
我们给出了通用领域的深度学习事件提取的流程图,如图1所示。事件提取是查找焦点事件类型,并提取其参数及其角色。 对于管道范式事件提取,有必要区分给定文本的文本中的事件类型,称为触发器分类。 针对不同的事件类型,设计了不同的事件架构。 然后,根据架构提取事件参数,其中包括参数标识和参数角色分类子任务。 在最早阶段,论证角色分类被视为一个单词分类任务,文本中的每个单词都被分类。 此外,还有序列标记、机器阅读理解(MRC)和序列到结构的生成方法。 对于联合范式事件提取,模型同时对事件类型和参数角色进行分类,以避免触发器分类子任务出现错误。

本文贡献 Contributions
对于传统的事件提取方法,特征设计是必要的,而对于一般域上的深度学习事件提取方法,特征可以是 由深度学习模型进行端到端提取。 现有综述主要介绍了主题事件的提取,其中基于深度学习模型的事件提取方法较少。 近年来,提出了大量的事件提取方法, 基于Transformer的事件提取方法取得了显著的改进。 此外,事件提取不再局限于分类和序列注释方式, 但也可以以机器阅读理解和生成的方式制定。 因此,本文对现有的基于深度学习的事件提取方法进行了综合分析,并对未来的研究工作进行了展望。 本文的主要贡献如下:
-
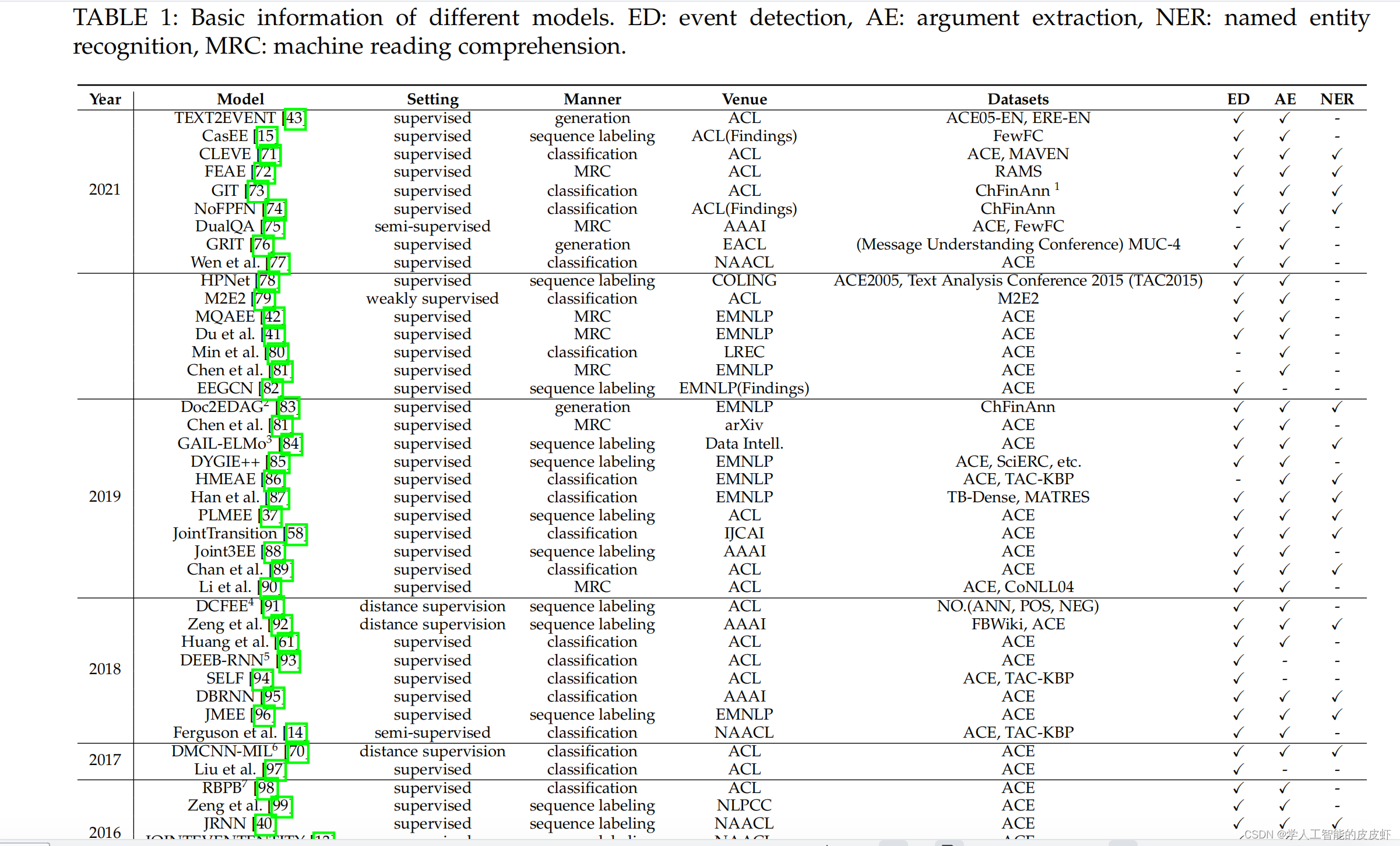
我们介绍了通用领域事件提取技术,回顾了事件提取方法的发展历程, 并指出具有深度学习的事件提取方法已成为主流。 我们根据表1中的出版年份总结了深度学习模型的必要信息。
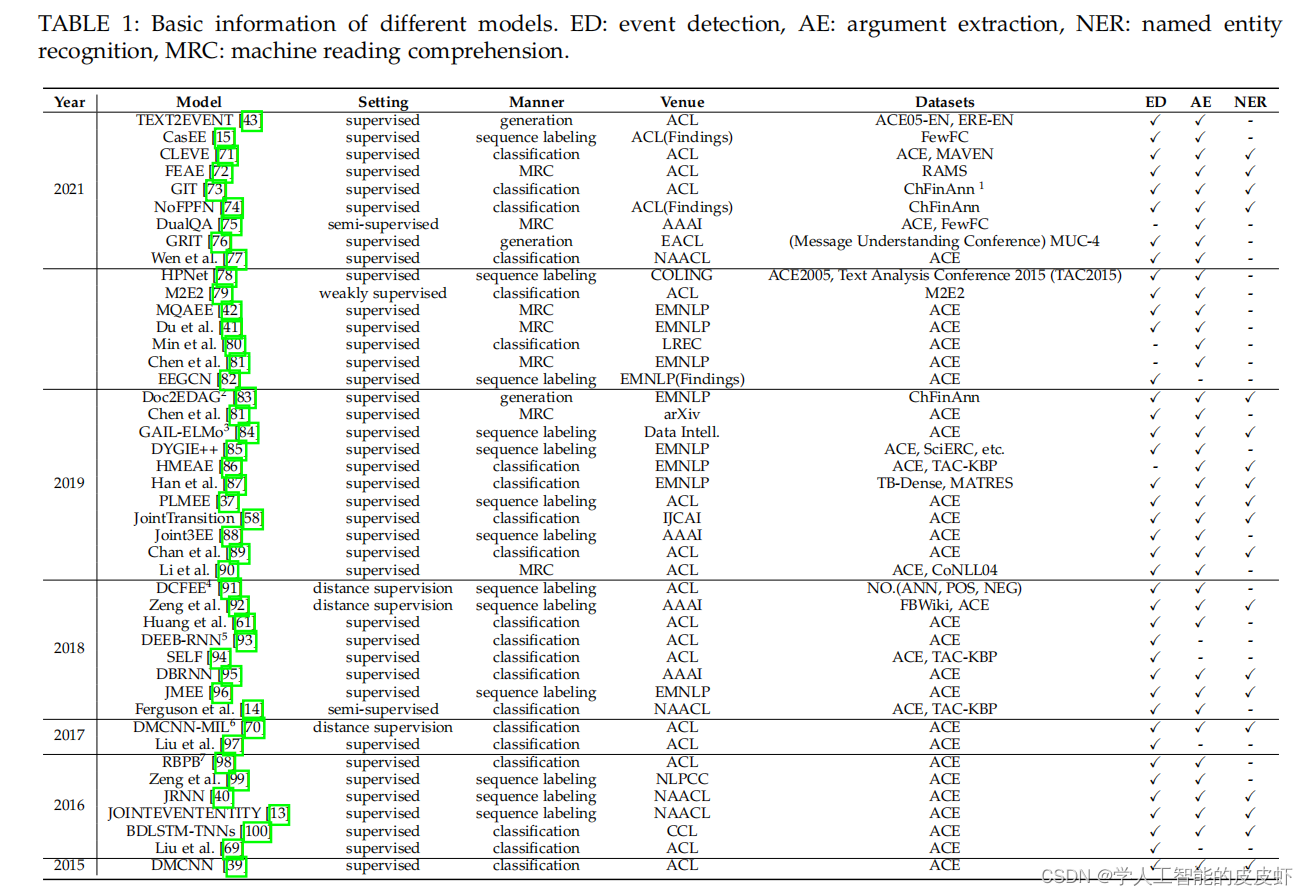
-
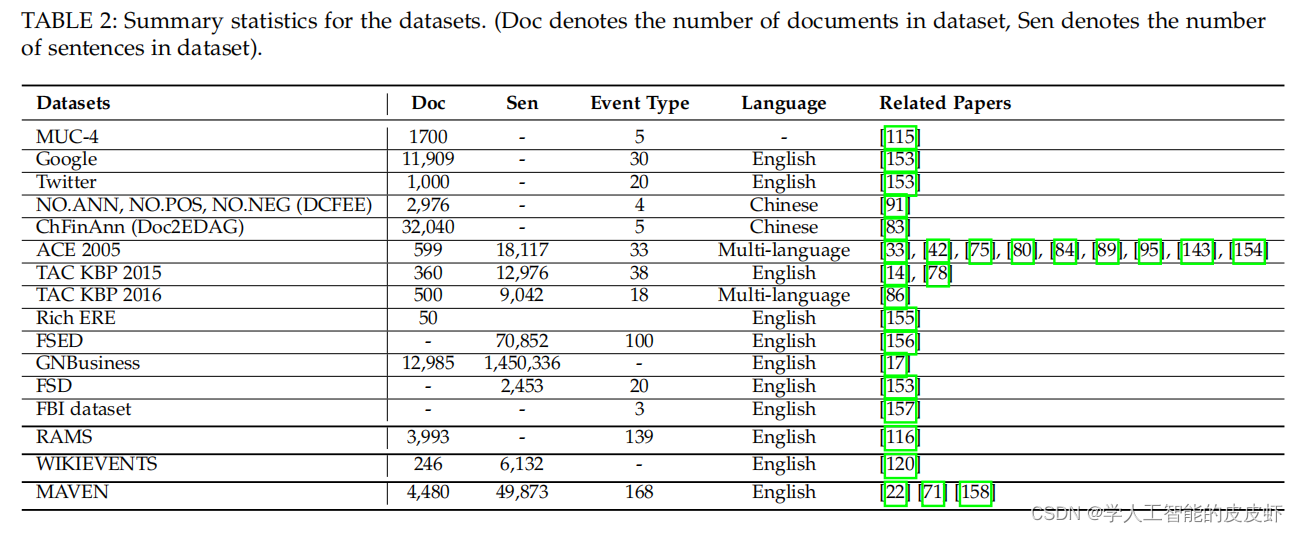
我们详细分析了各种基于深度学习的提取范式和模型,包括它们的优缺点。我们介绍了目前可用的数据集,并给出了主要评估指标的制定。我们在表2中总结了主要数据集的必要信息。
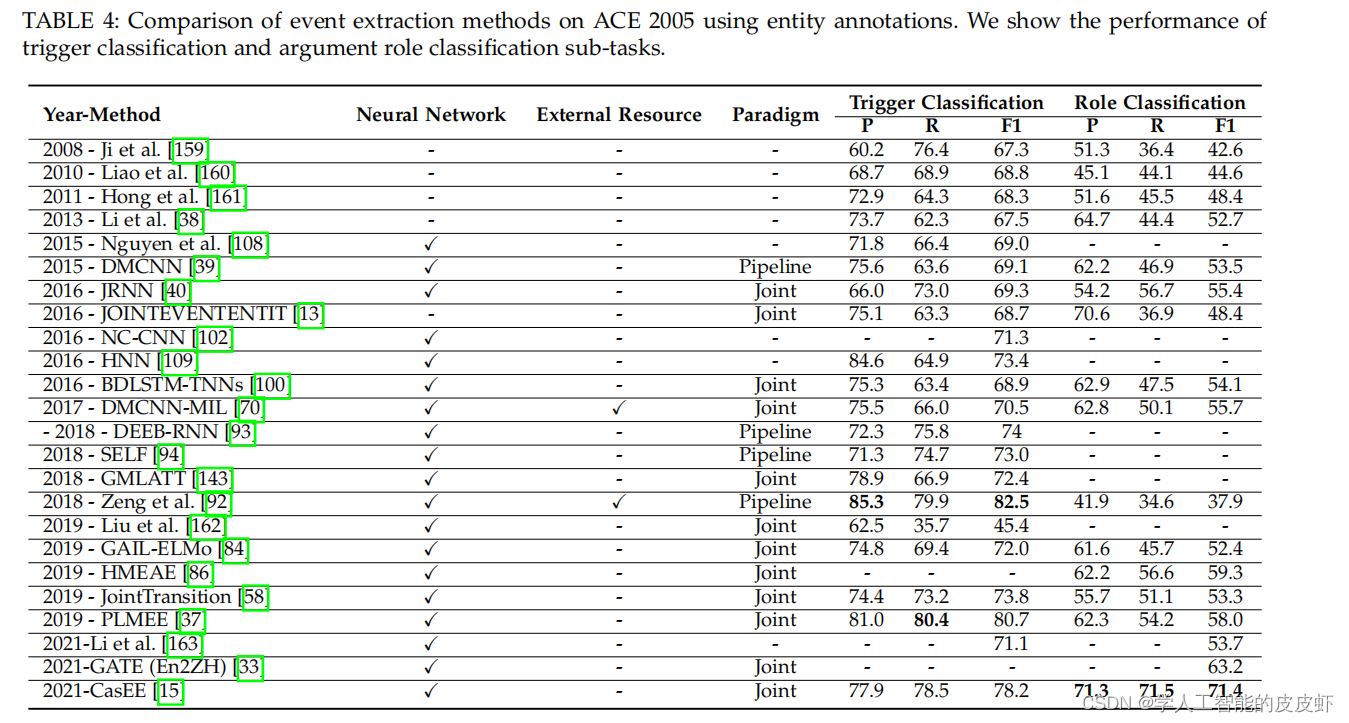
- 我们在表 4 中总结了 ACE 2005 数据集的事件提取准确性分数和事件提取应用程序。我们通过讨论未来来结束审查 事件提取面临的研究趋势。
本文的组织结构 cOrganization of the Survey
接下来本文综述的组织架构如下:
- 第2节介绍了事件抽取的概念和任务定义。
- 第3节分总结了与事件提取相关的现有范例,包括基于管道的方法 和基于联合的方法,并汇总成表。
- 第4节介绍传统事件提取与深度事件提取 基于学习的事件提取与比较。
- 第5节介绍了不同场景下的事件提取。
- 第 6 节和第 7 节主要介绍了事件提取的语料库和评价指标。然后我们给出领先的定量结果
- 第 8 节中介绍经典事件提取数据集中的模型。
- 最后,我们总结了事件提取应用和主要 第 9 节和第 10 节中事件提取的挑战
- 在第 11 节对本文进行总结。
PRELIMINARY
本节介绍目前事件抽取的概念(Concepts)、子任务(Sub-tasks)和事件抽取的模型方式( Event Extraction Manner)。
Concepts
一个事件(event)表示动作(action)或状态变化(state change)的发生,通常由动词或动名词驱动。它包含了动作所涉及的主要成分,如时间、地点和人物。事件提取技术从非结构化文本中提取用户感兴趣的事件,并以结构化形式呈现给用户。 简而言之,事件提取检测事件及其类型,并从文本中提取核心参数,如图所示2.
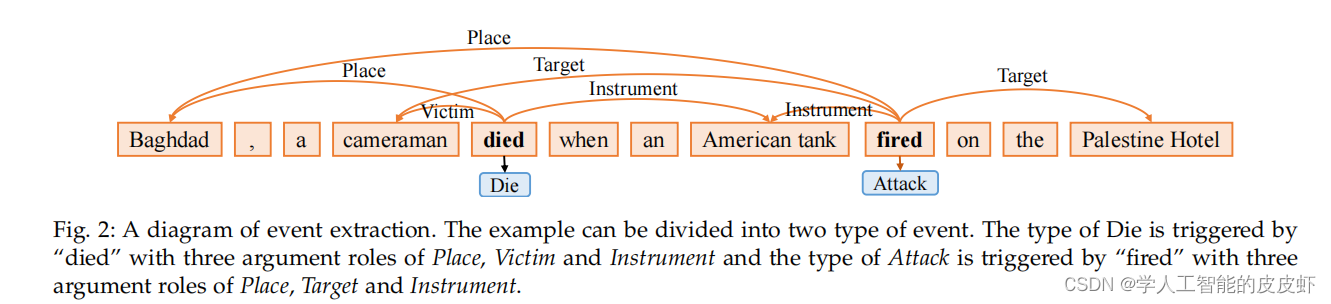
给定文本,事件提取技术可以预测文本中提到的事件,每个事件对应的触发器和参数,并对每个参数的作用进行分类。 事件提取需要识别两个事件(死亡和攻击),分别由单词“死亡”和“触发”触发,如图所示。2. 对于 Die 事件类型,我们认识到“巴格达”、“摄影师”和“美国坦克”分别承担事件参数角色“地点”、“受害者”和“手段”。 对于攻击,“巴格达”和“美国坦克”分别承担事件参数角色“地点”和“手段”。 而“摄影师”和“巴勒斯坦酒店”承担了事件论证角色目标。
事件抽取涉及机器学习、模式匹配、自然语言处理等诸多前沿学科。 同时,各个领域的事件抽取可以帮助相关人员从海量信息中快速抽取相关内容, 提高工作时效性,为定量分析提供技术支持。 因此,事件抽取在各个领域都具有广阔的应用前景。 通常,自动内容提取 (ACE,Automatic Content Extraction) 描述了一个包含以下术语的事件提取任务:
- Entity:实体是语义类别中的一个对象或对象组。实体主要包括人, 组织、地点、时间、事物等。在图表2、“巴格达”、“摄影师”、“美国坦克”、“巴勒斯坦饭店”等字样为实体。
- Event mentions:描述事件的短语或句子包含触发器和相应的参数。
- Event type:事件类型描述事件的性质,并引用事件对应的类别,通常由事件触发器的类型表示。 对于图2中的句子,它包含死亡和攻击事件类型。
- Event trigger:事件触发器是指事件提取中的核心单元,动词或名词。 触发器识别是基于管道的事件提取中的关键步骤。 对于图2中的事件Die,事件触发器为“died”。
- Event argument:事件参数是事件的主要属性。它包括实体、非实体参与者和时间等。 对于图2中的事件 Die,事件参数为“巴格达Baghdad”、“摄像师cameraman”和“美国坦克American tank”。
- Argument role:参数角色是参数在事件中扮演的角色,即事件参数Event argument与事件触发器Event trigger之间的关系表示形式。 对于图2中Die事件的参数“巴格达Baghdad”,参数角色为Place。
Sub-tasks
事件提取包括四个子任务:触发器分类、触发器识别、参数识别和参数角色分类。
(Event extraction includes four sub-tasks: trigger classifi-cation, trigger identification, argument identification and argument role classification.)
- Trigger identification:一般认为,触发器是事件提取中的核心单元,可以清楚地表达事件的发生。 触发器识别子任务是从文本中查找触发器。在图2中,触发识别是识别触发“died”和“fired”。
- Trigger classification:触发分类是根据现有的触发因素判断每个句子是否是一个事件。 此外,如果句子是一个事件,我们需要确定句子所属的一个或多个事件类型。 例如图2,子任务旨在对触发的事件类型进行分类 “died”和“fired”, 分别对应于Die和Attack。因此,触发器分类子任务可以看作是多标签文本分类任务。
- Argument identification:参数标识是从文本中标识事件类型中包含的所有参数。 参数识别通常取决于触发器分类和触发器识别的结果。 例如图2中的Die事件。参数识别是提取“Baghdad”、“cameraman和“American tank””等字眼。
- Argument role classification:参数角色分类基于事件提取架构(event extraction schema)中包含的参数, 并且每个参数的类别根据确定的参数进行分类。 对于图2的提取单词,如“cameraman”,这个子任务是将单词分类到Object这一类别。 因此,它也可以看作是一个多标签文本分类任务。
Event Extraction Manner
事件抽取是信息抽取中非常有代表性的热点话题, 它研究如何从包含事件信息的非结构化文本(新闻、博客等)中提取特定类型的事件信息。 它可以简化为多个分类任务,它确定事件的类型和每个实体所属的参数角色。 例如,图2中的“cameraman”这个词,基于分类的方法是在给定的角色集中分类它属于哪个参数角色。 分类方法依赖于命名实体识别(NER),导致错误信息的传播。 在此基础上,提出了一种基于序列标注的事件抽取方法, 它标记了每个参数的开始和结束位置。基于序列标记的方法在 BIO 中给出“摄影师”一词的标签,其中 B 代表“开始”, I代表“内部”,O代表“外部”。 事件提取的任务很复杂,参数彼此密切相关。事件提取的任务很复杂,参数彼此密切相关。 采用机器阅读理解(MRC)来学习联想, 每个参数都是通过问答对找到的。 基于 MRC 的方法生成参数角色的问题,比如Object,模型就是找出句子中具有Object角色的词语。 因此,可以考虑事件提取任务 作为分类任务、序列标记任务和机器 阅读理解任务。近期,一些作品聚焦于以下 使用生成方式。关于这些任务( classification task, sequence labeling task and machine reading comprehension task.更)详细的定义如下:
Classification-based Task
对于分类任务,作者通常会预先细化n个事件类型及其对应的参数角色,
例如对于给定的包含了一系列参数角色argument roles [ri,1, ri,2…, ri,l]的事件ei (i ∈ [1, n])。
输入为:事件提及m(一条句子?),模型需要输出一个矩阵T,其中第i个输出Ti表示事件提及m属于事件ei(例如:Die)的概率。在基于分类的事件抽取中,触发器分类判断一个词是否属于触发器(例如:die)。
在获得了一个关于输入为提及m的矩阵R(矩阵R由一系列 事件ek组成)之后,其中,Ri,j表示抽取出的参数ai(摄影师、巴格达、美国坦克)属于角色rk,j(地点Place、时间Time、职业)的概率。也就是将每个实体分类为预先定义的参数角色。
it classifies each entity to a predefined argument role.
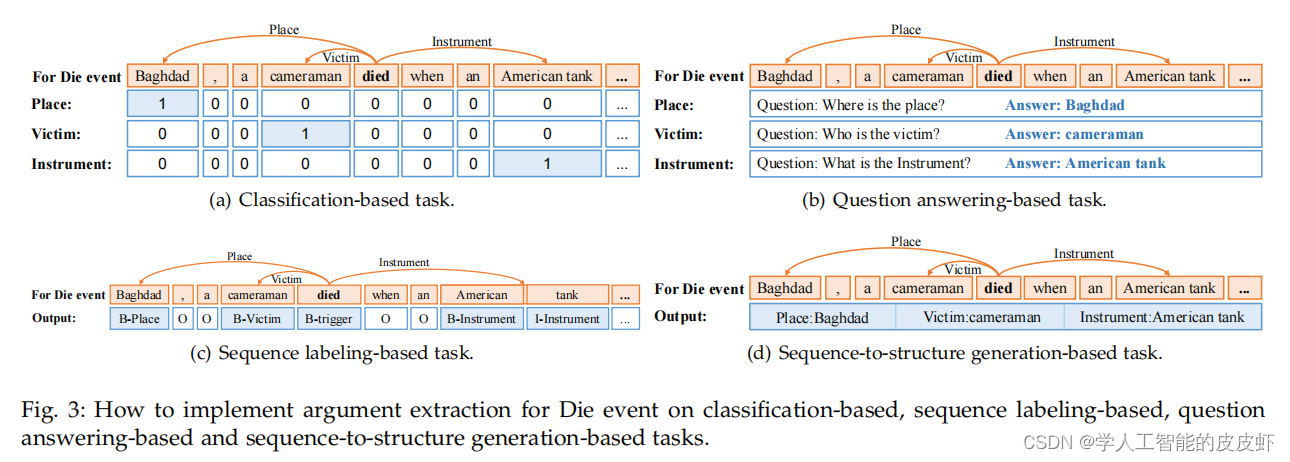
基于机器阅读理解的任务 Machine Reading Comprehension-based Task
机器阅读理解模型可以理解一段自然语言的文本并回答有关它的问题。 在基于机器阅读理解的任务中,触发器识别也是对一个单词是否是触发器进行分类。 首先,为每个参数角色 r 设计一个问题模式,称为 Qr。由于不同的事件类型具有不同的参数,因此模型需要首先标识文本所属的事件类型。 然后,根据事件类型确定要提取的参数角色。 最后,基于机器阅读理解的事件提取方法的输入为一段文本T, 并将设计的问题Qr逐一应用到提取模型中,如图所示。第3(b)段。 模型提取答案 Ar,即为每个参数角色 r 对应的参数。
基于序列标注的任务 Sequence labeling-based Task
序列标注任务是基于词级的多分类任务,可以直接匹配基于词级事件类型提取的事件参数。 事件提取主要包括两个核心任务:识别和分类事件的类别(Die)并提取出事件的参数(Victim、Place、Instrument)。 基于序列标注的事件提取可以简单快速地实现事件类型和事件参数的匹配,无需附加功能。 在基于序列标注的任务中,标识的触发器是将一个单词标注为触发器。序列标注方法从文本中标记出目标,适用于事件提取任务。例如对于图3中的c;给定文本 T = x1, x2, . . . , xN 和事件模式(event schema),参数对应的参数角色 r 被序列标注模型标注。 输出为, y = y1, y2, . . . , yN ,因此序列标注模型的主要任务是标注文本中的所有单词。
基于生成式序列-to-结构化的任务 Sequence-to-structure Generation-based Task
基于序列到结构生成的事件提取以端到端的方式从文本中提取事件。 在sequence-to-structure generation-based任务中,trigger的识别就是生成一个trigger。 它在单个模型中统一建模所有任务,并普遍预测不同的标签。 如图 3(d) 所示,基于序列到结构生成的方法直接生成所有参数及其角色。 它通常采用编码器-解码器模型,这是一种将文本转换为结构化形式的简便方法。
事件抽取的例子 EVENT EXTRACTION PARADIGM
事件提取包括四个子任务:触发器识别、事件类型分类、参数标识和参数角色分类(trigger identification, event type classification, argument identification, and argument role classification.)。 根据解决这四个子任务的程序,事件提取任务分为基于管道的事件提取和基于联合抽取的事件提取。 首先,采用基于管道的方法首先会去检测触发器,并根据触发器判断事件类型。 然后,参数提取模型提取参数并根据事件类型和触发器的预测结果对参数角色进行分类。 为了克服事件检测引起的错误信息传播,研究人员提出了一种基于联合抽取的事件提取范式。 它通过组合事件检测和参数提取任务来减少错误信息的传播。
基于管道的事件抽取方法 Pipeline-based Paradigm
基于管道的方法将所有子任务视为独立的分类问题。管道方法被广泛使用,因为它简化了整个事件提取任务。基于管道的事件提取方法,如图所示。4、将事件提取任务转化为多阶段分类问题。所需的分类器包括:1) 触发器分类器用于确定术语是否为事件触发器和事件类型。2) 参数分类器用于确定单词是否是事件的参数。3) 参数角色分类器用于确定参数的类别。 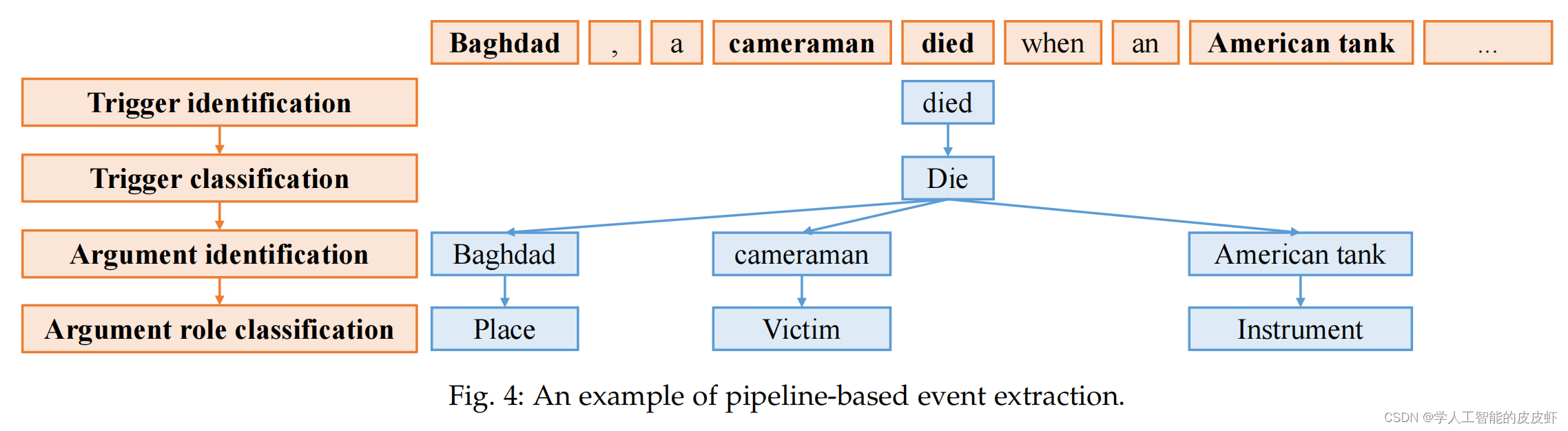
基于深度学习的经典事件提取模型动态多池卷积神经网络(DMCNN)使用两个动态多池卷积神经网络进行触发器分类和参数分类。 触发器分类模型标识触发器。 如果存在触发器,则使用参数分类模型来标识参数及其角色。 PLMEE 还使用两种模型,分别采用触发器提取和参数提取。 参数提取器使用触发器提取的结果进行推理。 它通过引入变压器的双向编码器表示(BERT)表现良好。
基于管道的事件提取方法通过以前的子任务为后续子任务提供附加信息,并利用子任务之间的依赖关系。 Du et al. [41] 采用问答方法来实现事件提取。 首先,模型通过设计的触发器问题模板识别输入句子中的触发因素; 模型的输入包括输入句子和问题。 然后,它根据标识的触发器对事件类型进行分类。 触发器可以为触发器分类提供其他信息, 但错误的触发识别结果也会影响触发器分类。 最后,模型识别事件参数,并根据事件类型对应的架构对参数角色进行分类。在参数提取中,该模型利用上一轮历史内容的答案。
这种方法最大的缺陷是误差传播。直观地说,如果在第一步中触发器识别存在错误,那么参数识别的准确性就会降低。 因此,在使用管道提取事件时,会出现错误级联和任务拆分问题。 管道事件提取方法可以使用触发器的信息提取事件参数。 然而,这需要高精度的触发器识别。 错误的触发器会严重影响参数提取的准确率。 因此,管道事件提取方法将触发器视为事件的核心。
Summary:
基于管道的事件提取方法将事件提取任务转换为多阶段分类问题。 该方法首先识别触发器,然后再基于识别的触发器识别参数。 它将触发器视为事件的核心。 然而,这种分阶段的策略将导致错误传播。 触发器的识别误差将传递到参数分类阶段,这将导致整体性能下降。 此外,由于触发器检测始终在参数检测之前,因此在检测触发器时不会考虑参数。 因此,每个环节都是独立的,缺乏互动,忽略了它们之间的影响。 因此,无法处理整体依赖关系。典型案例是DMCNN 。
联合抽取的方法 Joint-based Paradigm
事件抽取在自然语言处理中具有很大的实用价值。 在使用深度学习对事件抽取任务进行建模之前,联合学习方法已经在事件抽取方面进行了研究。 如图5所示,该方法在第一阶段根据候选触发器和实体识别触发器和参数。 第二阶段,为了避免错误信息从事件类型传播,触发分类 和参数角色分类是同时实现的。 它将触发器“die”分类为 Die 事件类型和参数 “Baghdad” 识别为参数角色Place。
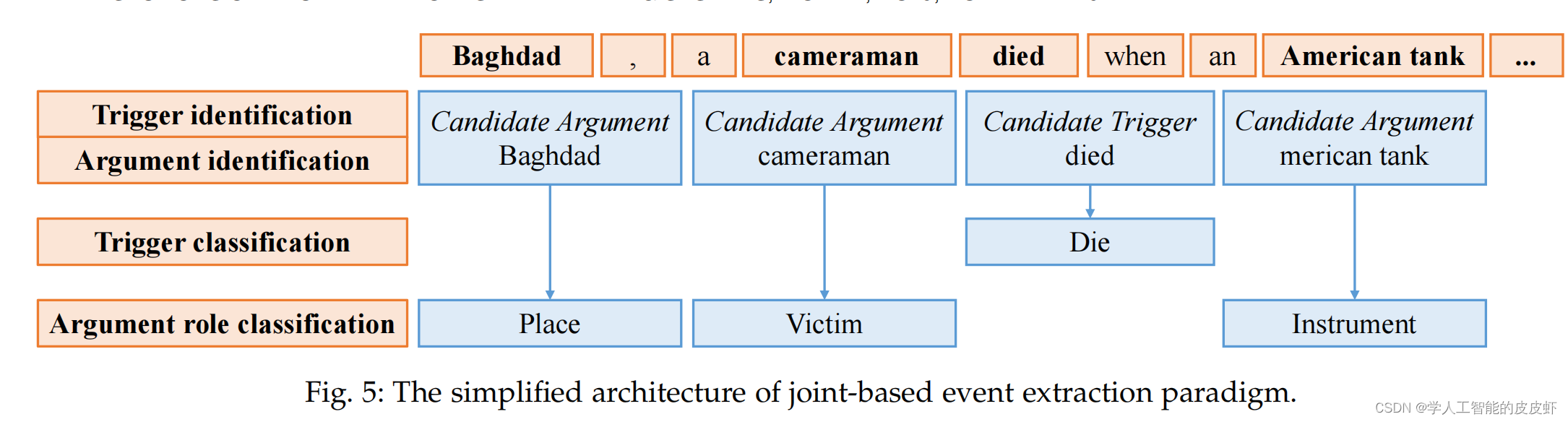
基于联合模型的深度学习事件抽取方法主要是利用深度学习和联合学习与特征学习交互, 这样可以长时间训练和复杂的特征工程。 xxx研究了基于传统特征提取方法的触发提取和参数提取任务的联合学习,并通过结构化感知器模型获得最优结果。xxx 设计高效的离散特征,包括特征词中包含的所有信息的局部特征和可以将触发器与参数信息联系起来的全局特征。 xxx 通过深度学习和联合学习成功构建了局部特征和全局特征。 它使用递归神经网络将事件识别和参数角色分类结合起来。 构建的局部特征是文本序列特征和局部窗口特征。输入文本由词向量、实体向量和事件参数组成。 然后将文本转入递归神经网络模型得到 深度学习的序列特征。
上述联合学习方法可以实现触发器和参数的联合建模事件提取。 但是,在实际工作过程中,触发器和参数的提取是连续进行的,而不是同时进行的, 这是一个亟待讨论的问题,有待稍后讨论。 此外,如果在深度学习中加入端到端模式,特征选择工作量将显着减少, 这也将在后面讨论。联合事件提取方法避免了触发器识别误差对事件参数提取的影响,同时考虑到触发器和参数。
Summary:
为了克服流水线法的不足,研究人员提出了联合法。 联合方法构建联合学习模型触发识别和论证识别, 其中触发器和参数可以相互促进彼此的提取效果。 实验证明联合学习方法的效果优于流水线学习方法。 经典案例是通过递归神经网络 (JRNN) [40] 联合事件提取。 联合事件抽取方法避免了对事件参数抽取的触发器识别,但不能利用触发器的信息。 联合事件抽取方法认为事件中的触发器和参数同等重要。 然而,无论是基于流水线的事件抽取还是基于联合的事件抽取都无法避免事件类型预测错误对参数抽取性能的影响。此外,这些方法不能在不同事件类型之间共享信息,不能独立学习每种类型,不利于仅使用少量标注数据进行事件提取。
深度学习时间抽取模型 DEEP LEARNING EVENT EXTRACTION MODELS
传统的事件抽取方法难以学习深度特征,难以改进依赖复杂语义关系的事件抽取任务。 最近的事件提取工作基于深度学习架构,如卷积神经网络 (CNN), 递归神经网络 (RNN) 图神经网络 (GNN) Transformer 或其他网络。 如表 1 所示,我们按照发布年份展示了现有模型的基本信息。 它包括作为模型探索的领域、模型发布的地点以及模型使用的数据集。 此外,我们得出结论,每个模型是否包含事件检测、参数提取和命名实体识别。 深度学习方法可以捕获复杂的语义关系并显着改善多事件提取数据集。 我们介绍几种典型的事件抽取模型
事件抽取的场景 EVENT EXTRACTION SCENARIOS
事件抽取语料库 EVENT EXTRACTION CORPUS
用于事件提取的标记数据集的可用性已成为快速发展背后的主要驱动力。在本节中,我们将总结这些数据集。
文档级语料库:
金融数据集:中文:H. Yang, Y. Chen, K. Liu, Y. Xiao, and J. Zhao, “DCFEE: A
document-level chinese financial event extraction system based
on automatically labeled training data,” in ACL, 2018.
中文:新的中文事件数据集包括32,040份文件和5种事件类型:股权冻结、股权回购、股权减持、股权增持和股权质押。http://www.cninfo.com.cn/new/index
评价指标 METRICS
P
R
F1














 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









