







 一、概述:
一、概述:
本文通过回顾最新的方法,特别关注基于深度学习模型的通用领域事件抽取,填补了研究空白。
1、根据任务定义对当前通用领域事件抽取研究进行了新的文献分类。
2、总结了事件抽取方法的范例和模型,并详细讨论了每种方法。
3、总结了支持预测和评估指标测试的基准。
4、提供了不同方法之间的综合比较。
5、最后,作者通过总结未来研究方向来结束。
二、一些预备知识:
1、什么是事件:事件指的是动作或状态变化的发生,通常由动词或动名词驱动。事件包含涉及动作的主要组成部分,例如时间、地点和角色。
2、什么是事件抽取(EE):事件抽取技术从非结构化文本中提取用户感兴趣的事件并以结构化形式呈现给用户。
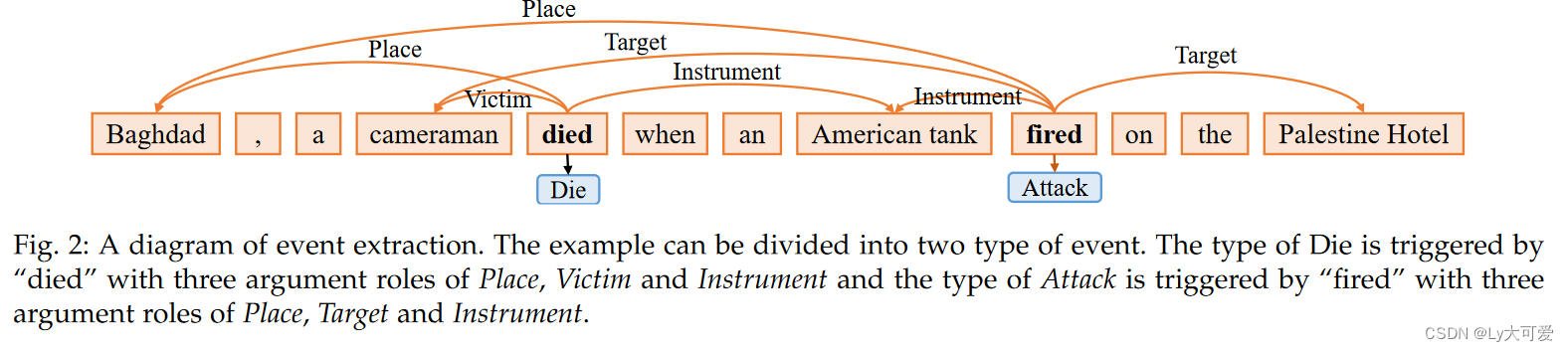
3、实体:实体是语义类别中的对象或对象组。实体主要包括人物、组织、地点、时间、物品等。在图2中,“Baghdad”、“cameraman”、“American tank”和“Palestine Hotel”是实体。
4、事件提及(论元):描述事件的短语或句子,包含触发器和相应的论点。
5、事件类型:事件类型描述事件的性质,并指事件对应的类别,通常由事件触发器的类型表示。图2中的句子包含“Die”和“Attack”事件类型。
6、事件触发器:事件触发器是事件抽取中的核心单元,可以是动词或名词。触发器识别是基于流水线的事件抽取中的关键步骤。图2中,“Die”事件的事件触发器是“died”。
7、事件论点:事件的主要属性,包括实体、非实体参与者、时间等。图2中,“Die”事件的事件论点是“Baghdad”、“cameraman”和“American tank”。
8、论点角色:论点角色是事件中由论点扮演的角色,即事件论点与事件触发器之间的关系表示。,“Die”事件的论点“Baghdad”的角色是“Place”。
9、事件抽取子任务:事件抽取包括四个子任务:触发器分类、触发器识别、论点识别和论点角色分类。
10、事件抽取任务可以被视为分类任务、机器阅读理解任务、序列标注任务和序列到结构的任务,如下图所示:

三、事件抽取范式:
事件抽取包括四个子任务:触发器识别、事件类型分类、论点识别和论点角色分类。根据解决这四个子任务的程序,事件抽取任务被分为基于流水线的事件抽取和基于联合的事件抽取。
1、基于流水线的范式:
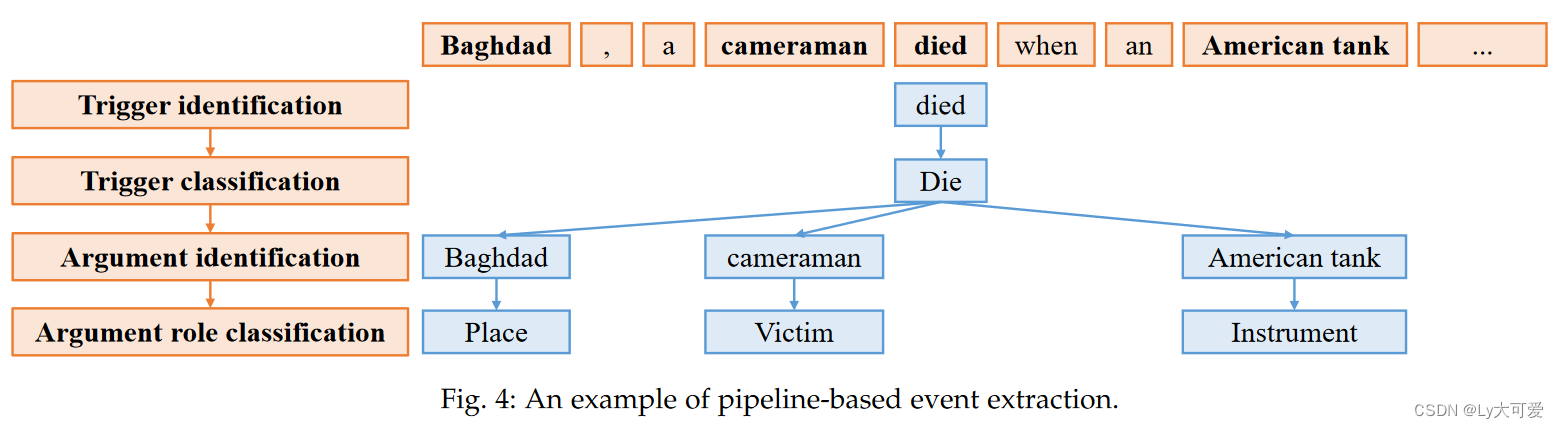
基于流水线的范式,如上图所示将事件抽取任务转化为多阶段分类问题。所需的分类器包括:触发器分类器用于确定术语是否为事件触发器以及事件类型;论点分类器用于确定单词是否为事件的论点;论点角色分类器用于确定论点的类别。
水线事件抽取方法认为触发器是事件的核心。基于流水线的方法将事件抽取任务转化为多阶段分类问题。基于流水线的事件抽取方法首先识别触发器,论点识别是基于触发器识别结果的。它将触发器视为事件的核心。然而,这种分阶段的策略会导致错误传播。触发器的识别错误将传递到论点分类阶段,导致整体性能的降级。
2、基于联合的范式:
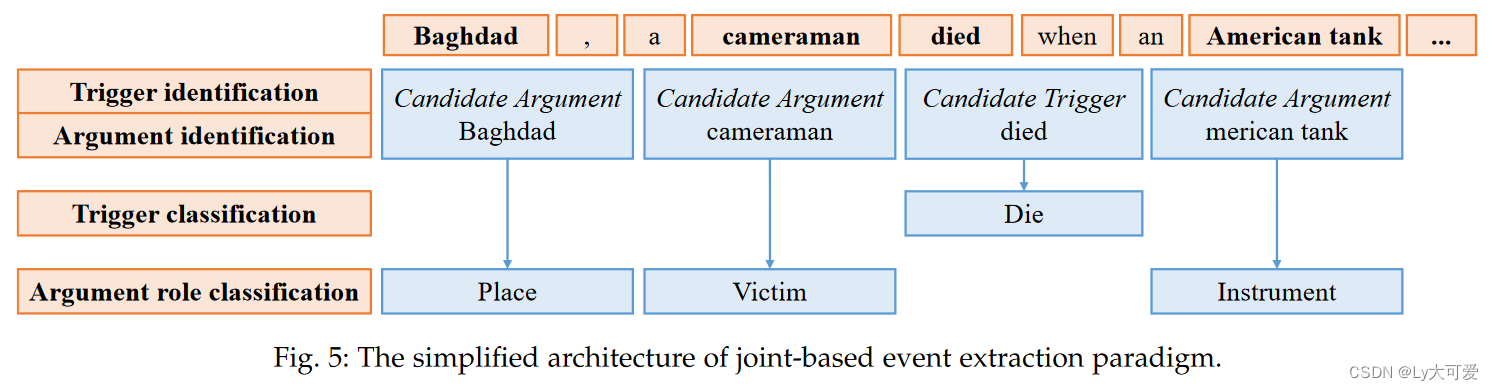
如上图所示:该方法根据第一阶段的候选触发器和实体来识别触发器和论点。在第二阶段,为了避免来自事件类型的错误信息传播,同时实现触发器分类和论点角色分类。
总之,为了克服流水线方法的缺点,研究人员提出了一种联合方法。联合方法构建了一个联合学习模型来识别触发器和论点,其中触发器和论点可以相互促进彼此的提取效果。实验证明,联合学习方法的效果优于流水线学习方法。联合事件提取方法避免了对事件论点提取的触发器识别错误的影响,认为事件中的触发器和论点同等重要。
3、总结:无论是基于流水线的事件抽取还是基于联合的事件抽取,都无法避免事件类型预测错误对论点提取性能的影响。此外,这些方法不能在不同事件类型之间共享信息并独立学习每种类型,这对于仅有少量标记数据的事件抽取是不利的。
四、基于深度学习的事件抽取模型汇总(2022之前)
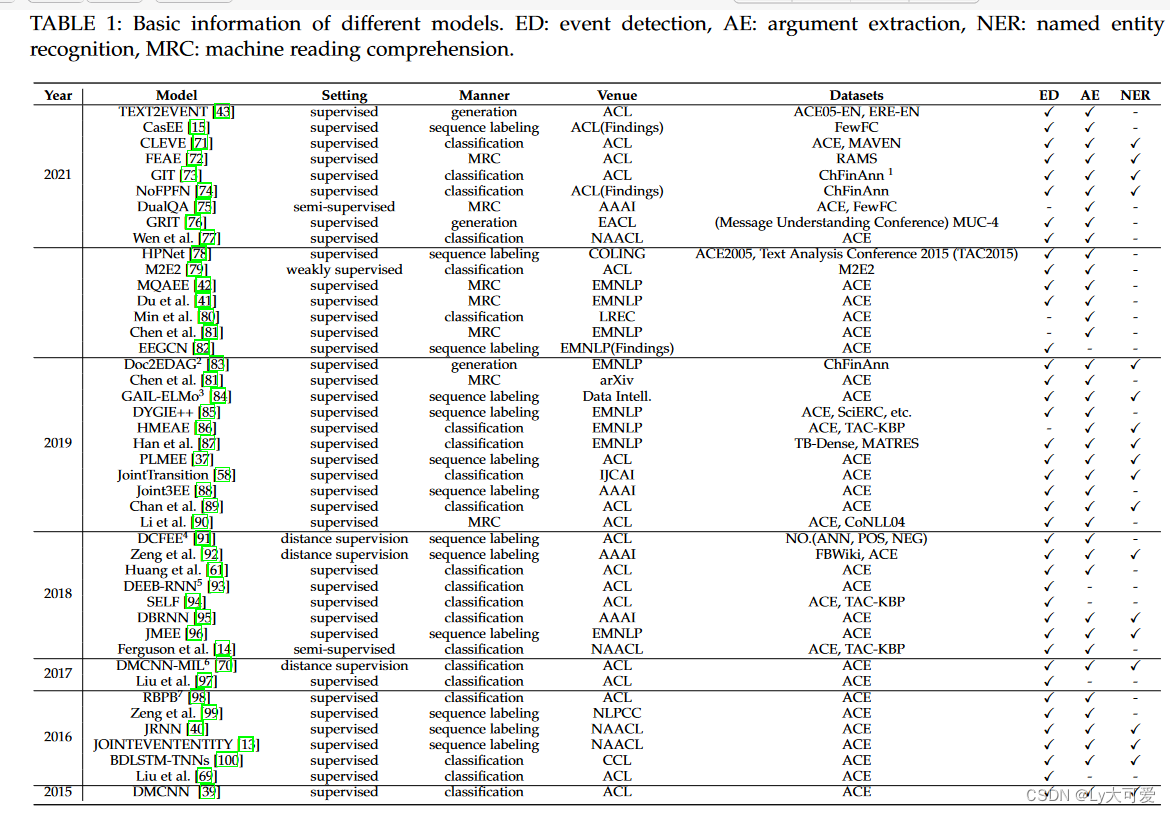
1、基于CNN的经典模型:
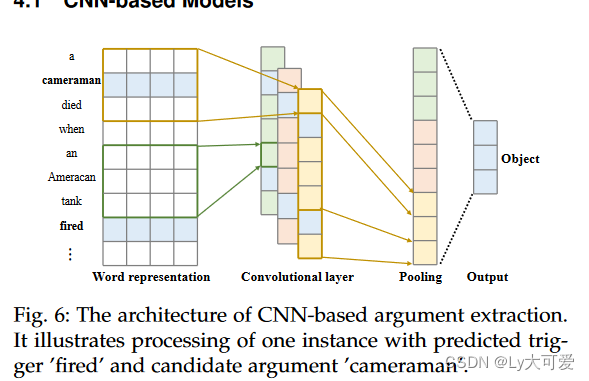
DMCNN:DMCNN对句子中的每个单词进行分类以识别触发器。对于具有触发器的句子,该阶段使用类似的DMCNN为触发器分配论点并对论点的角色进行对齐。图6描绘了论点分类的架构。
2、基于RNN的事件抽取模型:
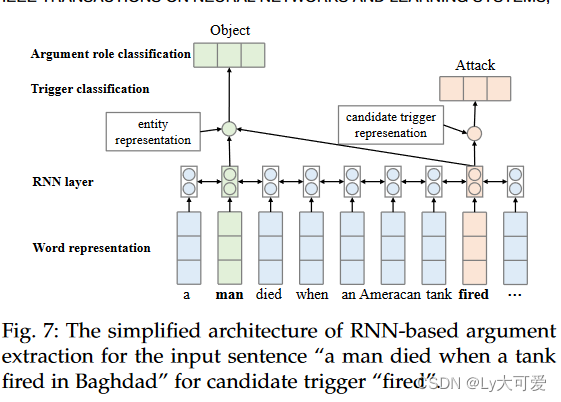
JRNN:如图7所示。JRNN 提出了一种基于RNN的双向RNN用于联合范式中的事件抽取。它具有编码阶段和预测阶段。在编码阶段,它使用RNN总结上下文信息。此外,在预测阶段同时预测触发器和论点角色。
3、基于注意力机制的事件抽取模型:
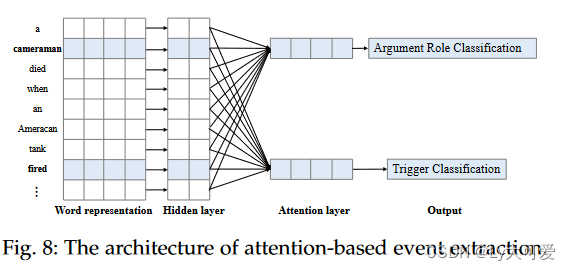
图8所示。注意机制的特性决定了它可以利用全局信息来模拟局部上下文,而不考虑位置信息。在更新单词的语义表示时,它具有很好的应用效果。通过控制句子各部分的不同权重信息,注意机制使模型关注句子的重要特征信息,同时忽略其他不重要的特征信息,并合理分配资源以提取更准确的结果。同时,注意机制本身可以作为一种对齐方式,解释端到端模型中输入和输出之间的对齐,使模型更具可解释性。
4、基于图卷积网络的事件抽取模型:暂不举例
5、基于Transformer的事件抽取模型:
PLMEE、GAIL、DYGIE++等。
BERT模型出现之前,主流方法是从文本中找到触发器,并根据触发器判断文本的事件类型。近年来,随着BERT引入的事件提取模型的出现,基于全文识别事件类型的方法成为主流。这是因为BERT具有出色的上下文表示能力,在文本分类任务中表现良好,尤其是在数据量较小的情况下。
五、事件提取场景:
文档级事件提取场景、开放领域事件提取场景、低资源事件提取场景、多语言事件提取场景、中文事件提取场景
六、事件提取语料库:
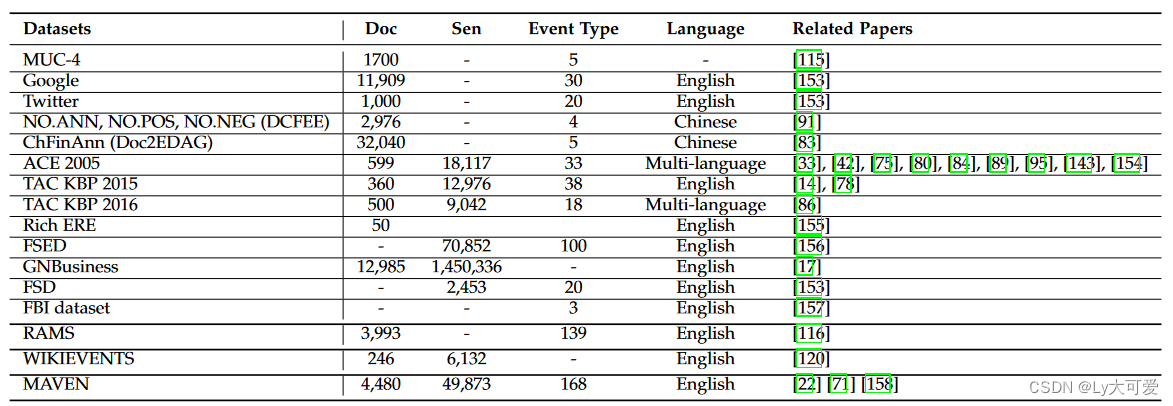
七、评价指标:
精确度(P)、召回率(R)和F1。
八、定量结果:
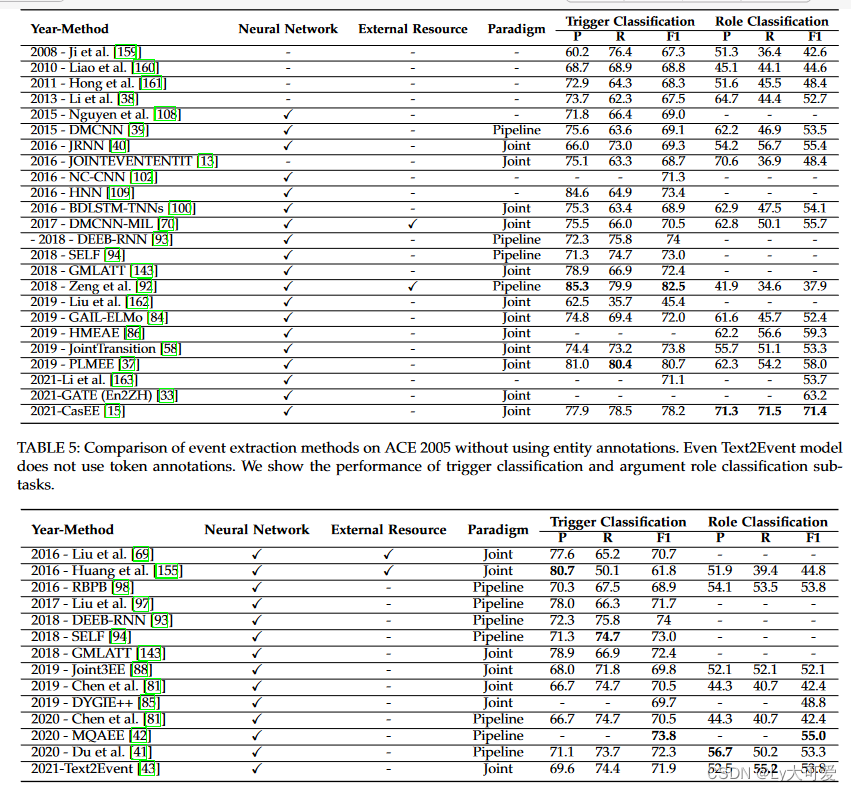
在F1值方面,深度学习方法在事件检测和参数抽取方面均优于基于机器学习和模式匹配的方法。
在基于深度学习的模型中,基于BERT的方法在表4和表5中表现最佳。这表明BERT可以更好地学习句子的上下文信息,并根据当前文本学习单词表示。
联合模型的事件提取方法优于流水线模型,特别是在参数角色分类任务中。
当在基于深度学习的方法中使用外部资源时,效果显著提高,略高于联合模型。
九、事件提取的直接下游任务:
1、事件事实性识别旨在确定关于事件在现实世界中是否发生的确定程度,可以看作是事件知识图构建中的下游任务。
2、抽取事件关系是构建事件知识图的一项重要而具有挑战性的任务,旨在检测已识别事件之间的关系,因此也可以看作是事件提取的下游任务。现有的事件关系抽取研究(ERE)主要关注三种事件关系类型,包括共指关系、因果关系和时间关系。
3、脚本事件预测,脚本是描述主人公活动的一系列有序事件,而脚本事件预测(SEP)旨在从候选事件列表中预测给定链的后续事件。
十、挑战:
事件提取数据集构建、外部资源、事件提取架构、依赖关系学习、端到端学习模型、多事件提取、领域事件提取、事件提取的可解释性。

















 5805
5805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









