







第八章 检索
书面作业:
一、判断题
1、在散列表中,所谓同义词就是具有相同散列地址的两个元素。 (T)
解析:
具有相同函数值的关键字对该散列函数来说称作同义词。
2、在散列中,函数“插入”和“查找”具有同样的时间复杂度。 (T)
解析:
插入和查找具有同样的时间复杂度O(1)。
3、即使把 2 个元素散列到有 100 个单元的表中,仍然有可能发生冲突。 (T)
解析:
若2个元素的相同散列函数值,则发生冲突;
4、在散列表中,所谓同义词就是被不同散列函数映射到同一地址的两个元素。 (F)
解析:
具有相同函数值的关键字对该散列函数来说称作同义词。
5、在一棵二叉搜索树上查找 63,序列 39、101、25、80、70、59、63 是一种可能的查找时的结点值比较序列。 (F)
解析:
不是二叉搜索树;
6、二叉搜索树的查找和折半查找的时间复杂度相同。 (F)
解析:
不一定相同。
- 二叉排序树不一定是平衡树,它是只要求了左右子树与根结点存在大小关系,但是对左右子树之间没有层次差异的约束,因此通过二叉排序树进行查找不一定能够满足logn的,例如一棵只有多层左子树的二叉排序树。
- 只有是一棵平衡的二叉排序树时,其查找时间性能才和折半查找类似。
7、任何二叉搜索树中同一层的结点从左到右是有序的(从小到大)。 (T)
解析:
证明
第二层:b<c,显然;
第三层:d<e,e<a,f<g,a<f;推出:d<e<f<g;
第四层:同理;
…
8、在一棵由包含 4、5、6 等等一系列整数结点构成的二叉搜索树中,如果结点 4 和 6 在树的同一层,那么可以断定结点 5 一定是结点 4 和 6 的父亲结点。 (F)
解析:
反例
5不是4和6的父节点;
9、把数组中元素按某种顺序排列的过程叫做查找 。 (F)
解析:
把数组中元素按某种顺序排列的过程叫做排序;
10、将 N 个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是 O(logN)。 (F)
解析:
数组二分查找的平均复杂度是O(logN)没有错,但是二分查找是不可以用链表存储的。因为数据在链表中的位置只能通过从头到尾的顺序检索得到,即使是有序的,要操作其中的某个数据也必须从头开始。这和数组有本质的不同。数组中的元素是通过下标来确定的,只要你知道了下标,就可以直接存储整个元素,比如a[5],是直接的。链表没有这个,所以,折半查找只能在数组上进行。
11、由顺序表和单链表表示的有序表均可使用二分查找法来提高查找速度。 (F)
解析:
分查找是不可以用链表存储;
二、单选题
1、在散列表中,所谓同义词就是: (B)
A. 两个意义相近的单词
B. 具有相同散列地址的两个元素
C. 被映射到不同散列地址的一个元素
D. 被不同散列函数映射到同一地址的两个元素
2、在下列查找的方法中,平均查找长度与结点个数无关的查找方法是: ©
A. 顺序查找
B. 二分法
C. 利用哈希(散列)表
D. 利用二叉搜索树
解析:
顺序查找方法和折半查找方法的平均查找长度都与元素的个数有关,由于散列结构是由事先准备好的散列函数关系与处理冲突的方法来确定数据元素在散列表中的存储位置的,因此散列表查找方法的平均查找长度与元素的个数无关。故选C。
3、设散列表的地址区间为[0,16],散列函数为 H(Key)=Key%17。采用线性探测法处理冲突,并将关键字序列{ 26,25,72,38,8,18,59 }依次存储到散列中。元素 59 存放在散列中的地址是: (D)
A. 8
B. 9
C. 10
D. 11
解析:
26%17=9
25%17=8
72%17=4
38%17=4+1=5
8%17=8+1+1=10
18%17=1
59%17=8+1+1+1=11
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 18 | 72 | 38 | 25 | 26 | 8 | 59 |
4、将元素序列{18,23,11,20,2,7,27,33,42,15}按顺序插入一个初始为空的、大小为11的散列表中。散列函数为:H(Key)=Key%11,采用线性探测法处理冲突。问:当第一次发现有冲突时,散列表的装填因子大约是多少? (B)
A. 0.27
B. 0.45
C. 0.64
D. 0.73
解析:
18%11=7
23%11=1
11%11=0
20%11=9
2%11=2
7%11=7+1=8(第一次冲突)
装填因子=5/11=0.45
5、给定散列表大小为 11,散列函数为 H(Key)=Key%11。采用平方探测法处理冲突:
h
i
(
k
)
=
(
H
(
k
)
±
i
2
)
h_i(k)=(H(k)±i^2)%11
hi(k)=(H(k)±i2) 将关键字序列{ 6,25,39,61 }依次插入到散列表中。那么元素 61 存放在散列表中的位置是: (A)
A. 5
B. 6
C. 7
D. 8
解析:
6%11=6
25%11=3
39%11=6+1=7
61%11=6-1=5
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 25 | 61 | 6 | 39 |
6、给定散列表大小为 11,散列函数为 H(Key)=Key%11。按照线性探测冲突解决策略连续插入散列值相同的 4 个元素。问:此时该散列表的平均不成功查找次数是多少? ©
A. 1
B. 4/11
C. 21/11
D. 不确定
解析:
(7+5+4+3+2)/11=21/11;
7、给定散列表大小为 11,散列函数为 H(Key)=Key%11。按照线性探测冲突解决策略连续插入散列值相同的 5 个元素。问:此时该散列表的平均不成功查找次数是多少?(A)
A. 26/11
B. 5/11
C. 1
D. 不确定
解析:
(6+6+5+4+3+2)/11=26/11
8、现有长度为 7、初始为空的散列表 HT,散列函数 H(k)=k%7,用线性探测再散列法解决冲突。将关键字 22, 43, 15 依次插入到 HT 后,查找成功的平均查找长度是:(C )
A. 1.5
B. 1.6
C. 2
D. 3
解析:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 22 | 43 | 15 |
查找22,长度为1;
查找43,长度为2;
查找15,长度为3;
总长度为3;
平均查找长度=(3+2+1)/3=2;
9、将 10 个元素散列到 100000 个单元的哈希表中,是否一定产生冲突? (B)
A. 一定会
B. 可能会
C. 一定不会
D. 有万分之一的可能会
解析:
由于散列函数的选取,仍然有可能产生地址冲突,冲突不能绝对地避免;
10、采用线性探测法解决冲突时所产生的一系列后继散列地址: (C )
A. 必须大于等于原散列地址
B. 必须小于等于原散列地址
C. 可以大于或小于但不等于原散列地址
D. 对地址在何处没有限制
解析:
循环后会在原散列地址前。
11、已知一个长度为 16 的顺序表 L,其元素按关键字有序排列。若采用二分查找法查找一个 L中不存在的元素,则关键字的比较次数最多是: (B)
A. 4
B. 5
C. 6
D. 7
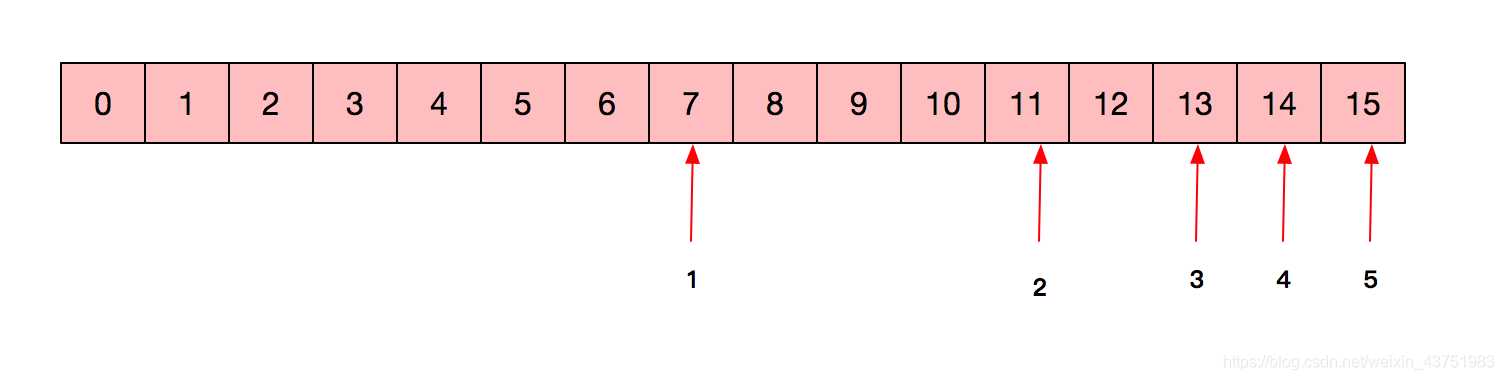
假设查找的数据为20,那么就是按图中箭头挨个查找,查到15还没有查到,但此时已经查了5次。
12、用二分查找从 100 个有序整数中查找某数,最坏情况下需要比较的次数是:(A)
A. 7
B. 10
C. 50
D. 99
解析:
2
7
=
128
>
100
2^7=128>100
27=128>100
13、下列二叉树中,可能成为折半查找判定树(不含外部结点)的是: (A)
A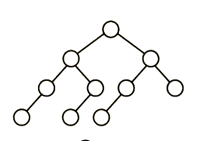
B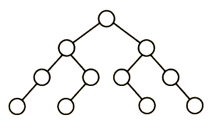
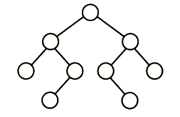
C
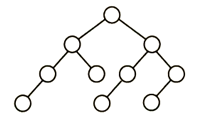
D
解析:
折半查找树的特点就在于其中序遍历是一个升序序列,因此相比于在以往的序列中进行二分查找,折半查找二叉树的优点在于不用自己去找中点,而是直接将要查找的关键字与根节点相比,小的话再和根节点的左子节点比较,大的话则是和根节点的右子节点比较。
而对于这道题的解题思路就在于向上或向下取整的问题,也就是说如果升序序列是偶数个,那么中点应该偏左多右少还是左少右多。但是很显然应该进行一个统一,像B和C选项中间的对称部分明显就是选择了不同的策略。D则由根节点左子树4个节点而点右子树5个节点可以确定用的是向下取整策略,但是我们再看它的左子节点在左子树中对应的中点左边2个数,右边一个数,明显是向上取整策略,策略没有统一,所以是错的。
14、若在线性表中采用二分查找法查找元素,该线性表应该(C)
A. 元素按值有序
B. 采用顺序存储结构
C. 元素按值有序,且采用顺序存储结构
D. 元素按值有序,且采用链式存储结构
15、设有一个已排序的线性表(长度>=2),分别用顺序查找法和二分查找法找一个与 K 相等的元素,比较的次数分别是 S 和 B,在查找不成功的情况下,S 和 B 的关系是(D )。
A. S = B
B. S < B
C. S > B
D. S >= B
解析:
设线性表长度为N
S=N;
B=
l
o
g
2
N
log_2N
log2N+1
当N=2时,S=B;
当N>2时,S>B;
16、在有 n(n>1000)个元素的升序数组 A 中查找关键字 x。查找算法的伪代码如下所示:
k = 0;
while ( k<n 且 A[k]<x ) k = k+3;
if ( k<n 且 A[k]==x ) 查找成功;
else if ( k-1<n 且 A[k-1]==x ) 查找成功;
else if ( k-2<n 且 A[k-2]==x ) 查找成功;
else 查找失败;
本算法与二分查找(折半查找)算法相比,有可能具有更少比较次数的情形是(B)
A. 当 x 不在数组中
B. 当 x 接近数组开头处
C. 当 x 接近数组结尾处
D. 当 x 位于数组中间位置
17、用线性时间复杂度的算法将给定序列{ 28, 12, 7, 8, 19, 20, 15, 22 }调整为最大堆(大根堆),然后插入 29。则结果序列为:(B)
A. { 29, 28, 20, 22, 12, 7, 15, 8, 19 }
B. { 29, 28, 20, 22, 19, 7, 15, 8, 12 }
C. { 29, 28, 22, 20, 19, 15, 12, 8, 7 }
D. { 7, 8, 28, 12, 19, 20, 15, 22, 29 }
解析:
- 构建大根堆
- 调整堆
- 插入29
- 再次调整堆
- 层次输出:29,28,20,22,19,7,15,8,12;














 1731
1731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









