









数据集
https://download.csdn.net/download/weixin_43755104/39603621
如果下载不了请私信,看到会发给你,数据集最好与你建的脚本在一个目录下,在读取路径时好写。
pd.read_csv要改成自己的路径
第一步:数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
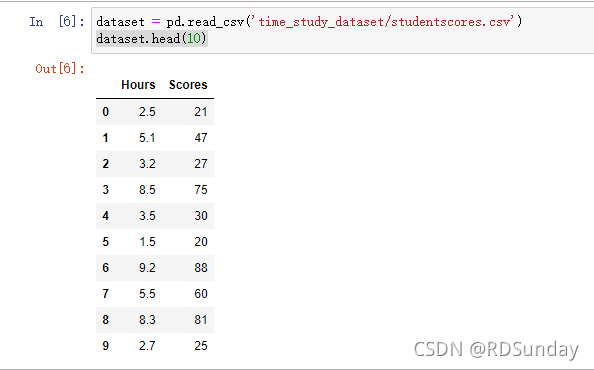
dataset = pd.read_csv('studentscores.csv')
dataset.head(10)
第二步:通过训练集来训练简单线性回归模型
feature_culumns = ['Hours']
laber_column = ['Scores']
features = dataset[feature_culumns]
laber = dataset[laber_column]
# 它的一个features也就是hours那一列数据的值赋给x,引文features是二维的表格,带有索引的值,要把值提取出来不要索引
x=features.values
y=laber.values
from sklearn.model_selection import train_test_split
#对训练数据集合测试数据集进行负值,测试数据集为1/4,训练数据集为3/4
X_train,X_test,Y_train,Y_test = train_test_split(x,y,test_size=1/4,random_state=0)
#通过训练集来训练简单线性回归模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
#导入回归模型之后,对训练数据进行拟合
regressor = regressor.fit(X_train,Y_train)
#对测试集进行预测
Y_pred = regressor.predict(X_test)
第三步:训练结果可视化
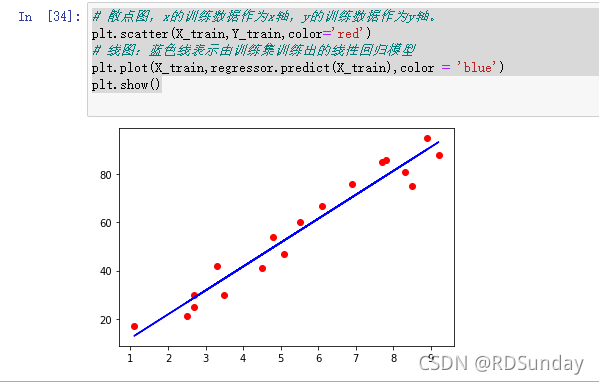
训练结果可视化:
# 散点图,x的训练数据作为x轴,y的训练数据作为y轴。
plt.scatter(X_train,Y_train,color='red')
# 线图:蓝色线表示由训练集训练出的线性回归模型
plt.plot(X_train,regressor.predict(X_train),color = 'blue')
plt.show()
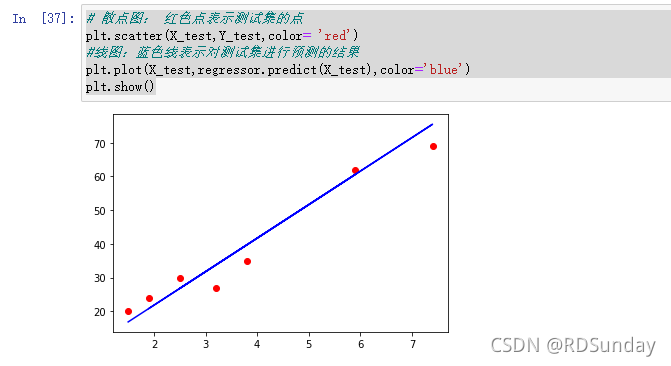
测试结果可视化:
# 散点图: 红色点表示测试集的点
plt.scatter(X_test,Y_test,color= 'red')
#线图:蓝色线表示对测试集进行预测的结果
plt.plot(X_test,regressor.predict(X_test),color='blue')
plt.show()
报错
如果报错可能你没有安装scikit-learn,请安装。
conda install scikit-learn
写在最后不知道为啥我的导不出md文件,导出之后是个压缩包,损坏打开不了,我还得一块块复制到CSDN















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











