









- ZIP压缩的历史
1977年,两位以色列人Jacob Ziv和Abraham Lempel,发表了一篇论文《A Universal Algorithm forSequential Data Compression》,一种通用的数据压缩算法,所谓通用压缩算法指的是这种压缩算法没有对数据的类型有什么限定,该算法奠基了今天大多数无损数据压缩的核心,为了纪念两位科学家,该算法被称为LZ77,过了一年他们又提了一个类似的算法,称为LZ78。ZIP这个算法就是基于LZ77的思想演变过来的,但ZIP对LZ77编码之后的结果又继续进行压缩,直到难以压缩为止。在LZ77、LZ78基础上变种的算法很多,基本都以LZ开头,如LZW、LZO、LZMA、LZSS、LZR、LZB、LZH、LZC、LZT、LZMW、LZJ、LZFG等等。
2.GZIP压缩算法的原理
GZIP压缩算法经历了两个阶段,第一个阶段使用改进的LZ77压缩算法对上下文中的重复语句进行压缩,第二阶段,采用huffman编码思想对第一阶段压缩完成的数据进行字节上的压缩,从而实现对数据的高效压缩存储。
3.LZ77压缩算法:LZ77是一种基于字典的算法,它将长字符串(也称为短语)编码成短小的标记,用小标记代替字典中的短语,从而达到压缩的的。
通俗来讲就是将文件中重复的字符串换成<距离,长度>对,从而达到压缩的目的。距离2个字节,长度1个字节,但所能表示的最大匹配为255 + 3 = 258.
因为我们是从最小3个字节开始匹配的。
例:aaaaabbbbfgnkmpbfgno
压缩后:aaaaabbbbfgnkmp74o。 4,7表示在距离当前位置7个字符前存在4个重复字符。
①1或2个字符重复,不用替换。
②当重复长度大于等于3时,替换。
3.1如此一来就引入几个问题?匹配字符串时采用暴力破解还是其他方法。不用想就知道暴力破解不可取,于是我们采用了hash表,将匹配的最小条件(3个字符算出的hash值和3个字符的首字符的下标)插入到hash表,此时又引入一个问题?三个字符总共可以组成种取值(即16M = 256 * 256 * 256),桶的个数需要个,而索引大小占2个字节,总共桶占32M字节,是一个非常大的开销。随着窗口的移动,表中的数据会不断过时,维护这么大的表,会降低程序运行的效率。
3.2 于是我们取hash桶的个数wsize = 2^15个,此时又引入查找缓冲区和先行缓冲区的概念。哈希表由一整块连续的内存构成,分为两个部分。

hash表
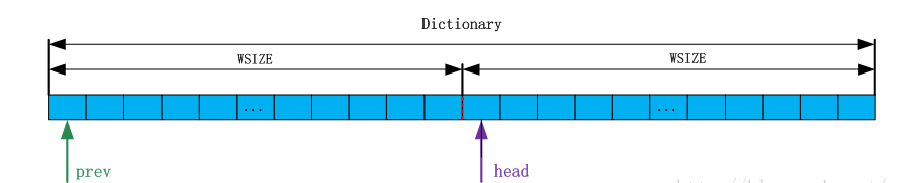
prev指向该字典整个内存的起始位置,head = prev + WSIZE,内存是连续的,所以prev和head可以看作两个数组,即prev[]和head[]。
head数组用来保存三个字符串首字符的索引位置,head的索引为三个字符通过哈希函数计算的哈希值。而prev就是来解决冲突的。


说明:当pos超过WSIZE时,在插入函数中如果直接使用pos肯定会越界,因此需要与上WMASK,即_prev[pos & WMASK] = _head[hashAddr],但是该语句可能会破坏匹配链,让匹配链构成环而造成死循环,该情况如何处理?
设置一个最长匹配次数,比如:255,匹配了255次也没有匹配到,放弃本次匹配。
3.3 滑动窗口
MIN_LOOKAHEAD = 258为最小先行匹配单元,如果小于它,那么可能出现匹配不到258个字符的情况。
随着滑动窗口的不断移动,右侧窗口中的数据不足MIN_LOOKAHEAD时怎么办?在压缩时,如果文件没有读到结尾,为了保证最大匹配,必须保持look_ahead中至少有MIN_LOOKAHEAD的源数据。那么此时就会搬移数据,将右窗的数据搬移到左窗,然后更新hash表,hash的值小于wsize则置为0,大于wsize则减去wsize。
3.4 解压缩
我们是如何将<距离,长度>对和原字符解析出来,最简单的方法是再创建一个标记文件,0表示原字符,1表示遇到<长度,距离>对。
注意:在解压缩时,每更新一个字符都需要手动更新缓冲区,不然会出错。
例:a b c d a b c d a e f 压缩后–> a b c d 4 5 e f
如果不及时更新缓冲区,解压到abcd后, 第二个abcd在缓冲区而不在文件,那么第五个字符a解码不出来。
4.huffman压缩
通过前面LZ77变形思想对源数据进行语句的重复压缩之后,语句层面的重复性已经解决,但并不代表压缩效果已经达到最佳,字节层面可能也有大量重复的。
如:"BCDCDDBDDCA"一个字节占8个比特位,那如果能对所有字节找到小于8个比特位的编码,然后用找到的编码对源文件中对应字节重新进行改写,也可以让源文件更小。
若此时我们找到的编码 A:111 B:110 C:10 D:0
此时编码 110 10 0 10 0 0 110 0 0 10 111,很显然文件变小了。
4.1 如何构建huffman树
从二叉树的根结点到二叉树中所有叶结点的路径长度与相应权值的乘积之和为该二叉树的带权路径长度WPL。

上述四棵树的带权路径长度分别为:
WPLa = 1 * 2 + 3 * 2 + 5 * 2 + 7 * 2 = 32
WPLb = 1 * 2 + 3 * 3 + 5 * 3 + 7 * 1 = 33
WPLc = 7 * 3 + 5 * 3 + 3 * 2 + 1 * 1 = 43
WPLd = 1 * 3 + 3 * 3 + 5 * 2 + 7 * 1 = 29
把带权路径最小的二叉树称为Huffman树
构造huffman树及获取编码的详细步骤请参考链接:构造huffman树
4.2 利用huffman编码对源文件进行压缩
- 统计源文件中每个字符出现的次数
- 以字符出现的次数为权值创建huffman树
- 通过huffman树获取每个字符对应的huffman编码
- 读取源文件,对源文件中的每个字符使用获取的huffman编码进行改写,将改写结果写到压缩文件中,直到文件结束。
4.3 压缩文件格式
压缩文件中只保存压缩之后的数据可以吗?
答案是不行的,因为在解压缩时,没有办法进行解压缩。比如:10111011 00101001 11000111 01011,只有压缩数据是没办法进行解压缩的,因此压缩文件中除了要保存压缩数据,还必须保存解压缩需要用到的信息:
1.源文件的后缀
2.字符次数对的总行数
5. 字符以及字符出现次数(为简单期间,每个字符放置一行)
6. 压缩数据
4.4 解压缩
1.从压缩文件中获取源文件的后缀
2. 从压缩文件中获取字符次数的总行数
3. 获取每个字符出现的次数
4. 重建huffman树
5. 解压缩
4.5 实现过程中遇到的问题
①需要用unsigned char,表示0–255
②解压缩时遇到换行符时需要多读取一行。
③打开文件方式需使用二进制,注意windows下换行是/r/n,以及获取文本文件和二进制文件的结尾都是不一样的。
最后,压缩比率分析。
笔者初学,又没有接触过测试,所以也是采用了笨办法,一个文件一个文件测试。测试用例和样本复杂度都不高,仅供参考。
①对于一般的文本文件(txt),LZ77压缩比率大概为60%–80%,而再次huffman压缩后,源文件较小(2-3k以下),会大于源文件,源文件(5k以上),huffman压缩后略小于源文件。而官方GZIP压缩率大在60%以下。
②对于图片文件(png,jpg),在文件小于200k时,压缩效果大概在80%–100%,当大于500k时,压缩后的文件比源文件大
③对于MP3文件10M以下时,大概在85%–100%,大于10M压缩会变大,官方GZIP压缩率小于75%。
笔者在测试的时候发现一个现象,那就是我们自己实现的压缩算法有以下特点:
①LZ77对小文件压缩率更佳。原因:我们在压缩时采用了标记位来区分原字符和压缩字符。若一个文件8M,最坏情况下,压缩后9M = 8M + 1M(标记位)。
②huffman对大文件压缩率更佳。原因:我们在压缩文件中写入了字符及其出现次数(比如 B:200代表B出现了200次),显然,字符越多越划算。
存在一个bug:源文件字符种类只有一种的时候压缩失败。原因:huffman树只有根节点的情况获取不到编码。
当然,GZIP不是这样的,基本思想一致,但在其做了许多优化。参考博客















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









