




 该博客介绍了如何构建科研文献的知识图谱,利用Neo4j数据库存储文章、作者、来源单位和关键词等实体及其关系。首先,通过DataToNeo4jClass.py模块创建节点,包括文章节点(含作者、来源、关键词信息)、作者节点、来源单位节点和关键词节点。然后,通过read_excel提取节点数据和关系数据,构建实体间的关系。在relation_extraction()函数中,提取了文章与关键词、作者、来源单位的关系,并存储到DataFrame中。最终,知识图谱以文章为中心,连接相同关键词的文章,形成一个相互连接的网络结构。
该博客介绍了如何构建科研文献的知识图谱,利用Neo4j数据库存储文章、作者、来源单位和关键词等实体及其关系。首先,通过DataToNeo4jClass.py模块创建节点,包括文章节点(含作者、来源、关键词信息)、作者节点、来源单位节点和关键词节点。然后,通过read_excel提取节点数据和关系数据,构建实体间的关系。在relation_extraction()函数中,提取了文章与关键词、作者、来源单位的关系,并存储到DataFrame中。最终,知识图谱以文章为中心,连接相同关键词的文章,形成一个相互连接的网络结构。
大体思路
对科研文献进行知识存储。数据结构如图

实体节点分为四类:
self.Paper = '文章'
self.Author = '作者'
self.Organ = '来源单位'
self.Keyword = '关键词'
关系分为三类:
self.lists={'Author':'作者','Organ':'来源单位','Keyword':'关键词'}
知识存储需要对数据进行处理,读取数据之间的关系并存入neo4j数据库
分为两个功能模块:
第一个模块创建实体节点和实体间的关系
第二个模块读取excel并提取节点数据和关系数据
具体实现
DataToNeo4jClass.py
创建节点:
def create_node(self, node_list_paper, node_list_author,node_list_organ,node_list_keyword):
"""建立节点"""
#对文章,属性包括名字,作者,来源,关键词
for line in node_list_paper:
paper = Node(self.Paper, title=line[0],author=line[1],organ=line[2],keyword=line[3])
self.graph.create(paper)
#对作者
for name in node_list_author:
value_node = Node(self.Author, name=name)
self.graph.create(value_node)
#对机构
for name2 in node_list_organ:
value2_node = Node(self.Organ, name=name2)
self.graph.create(value2_node)
#对关键词
for name3 in node_list_keyword:
value3_node = Node(self.Keyword, name=name3)
self.graph.create(value3_node)
对导入的节点列表获取列表数据,利用py2neo语句创建节点
创建关系
def create_relation(self, df_data):
"""建立联系"""
#matcher = NodeMatcher(self.graph)
m = 0
# try:
# index=df_data['relation'][m]
# rel = Relationship(matcher.match(self.Paper, title=df_data['name'][m]),#起始node
# index, #关系
# matcher.match(self.lists[index],name=df_data['name2'][m]))
# self.graph.create(rel)
# except AttributeError as e:
# print(e, m)
for m in range(0, len(df_data)):
index = df_data['relation'][m]
query = "match(p:%s),(q:%s) where p.title='%s'and q.name='%s' create (p)-[rel:%s]->(q)" % (
self.Paper, self.lists[index], df_data['name'][m], df_data['name2'][m], index)
try:
self.graph.run(query)
except Exception as e:
print(e)
df_data为字典结构,有三个键值,
links_dict['name'] = name_list
links_dict['relation'] = relation_list
links_dict['name2'] = name2_list
# 将数据转成DataFrame
df_data = pd.DataFrame(links_dict)
build_graph.py
data_extraction():
"""节点数据抽取"""
# 取出excel各个数据取值到list
node_list_paper = []
node_list_author = []
node_list_organ = []
node_list_keyword = []
for i in range(0, len(invoice_data)):
node_list_paper.append(invoice_data.iloc[i].tolist())
#
node_list_author1=[i for i in str(invoice_data['Author'][i]).split(';') if i !='']
node_list_author.extend(node_list_author1)
#x
node_list_organ1=[i for i in str(invoice_data['Organ'][i]).split(';') if i !='']
node_list_organ.extend(node_list_organ1)
#
node_list_keyword1 =[i for i in str(invoice_data['Keyword'][i]).split(';;') if i !='']
node_list_keyword.extend(node_list_keyword1)
node_list_author= list(set(node_list_author))
node_list_organ= list(set(node_list_organ))
node_list_keyword= list(set(node_list_keyword))
return node_list_paper ,node_list_author, node_list_organ ,node_list_keyword
所有数据进行抽离,建立节点
relation_extraction():
"""联系数据抽取"""
links_dict = {}
name_list = []
relation_list = []
name2_list = []
for i in range(0, len(invoice_data)):
m = 0
#获取每一行的文章名
name_node = invoice_data[invoice_data.columns[m]][i]
while m < len(invoice_data.columns)-2:
m += 1 ##最后namelist一直是首个列,name2list是剩下的列数据,relation保存列首元素和其他列数据的关
# 获取当前节点所在列的下一列列名下的数据,作为指向节点
list1= [i for i in str(invoice_data[invoice_data.columns[m]][i]).split(';') if i != '']
for j in list1:
# 获取当前节点所在列的下一列列名作为关系
relation_list.append(invoice_data.columns[m])
name2_list.append(j)
name_list.append(name_node)
# 对关键词单独分析
m += 1
list2 = [i for i in str(invoice_data[invoice_data.columns[m]][i]).split(';;') if i != '']
for k in list2:
# 获取当前节点所在列的下一列列名作为关系
relation_list.append(invoice_data.columns[m])
name2_list.append(k)
name_list.append(name_node)
# 整合数据,将三个list整合成一个dict
links_dict['name'] = name_list
links_dict['relation'] = relation_list
links_dict['name2'] = name2_list
# 将数据转成DataFrame
df_data = pd.DataFrame(links_dict)
print(df_data['relation'])
return df_data
dfdata中 name通过relation关联到name2
实现效果
以关键词关系作为实例
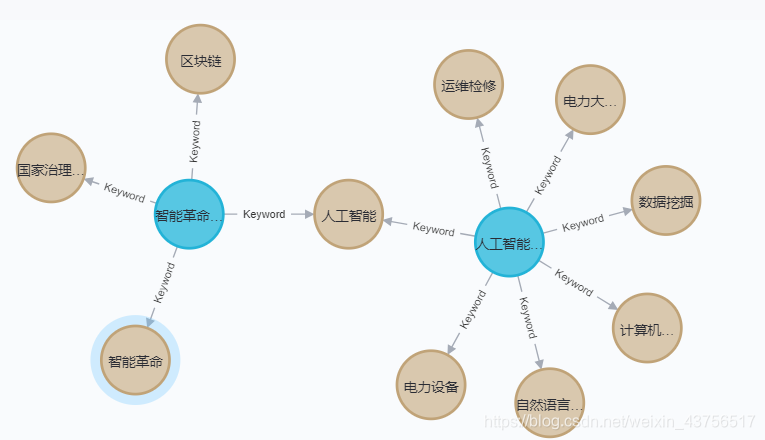
中间蓝色节点为论文文献,四周灰色节点为关键词。拥有相同关键词论文会被关键词链接,每个论文通过自身关键词互连。

















 7993
7993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









