







文章目录
第一讲 推荐系统
一、推荐系统简介
1.1 搜索与推荐
搜索:用户主动提供意图明确的query·
推荐:系统主动提供给用户一种选择
推荐的优势:·用户大多数情况下并没有明确的意图·推荐可以给帮助用户发现,带给用户惊喜
1.2 推荐系统的任务
–联系用户和物品,解决信息过载的问题
•帮助用户发现对自己有价值的信息
•让信息能够展现在对它感兴趣的用户面前
二、推荐系统模型
三个重要模块及使用
•推荐系统有3个重要的模块:
-
–用户建模模块、
-
–推荐对象建模模块、
-
–推荐算法模块
•推荐系统
- –把用户模型中兴趣需求信息
- –和推荐对象模型中的特征信息匹配,
- –同时使用相应的推荐算法进行计算筛选,
- –找到用户可能感兴趣的推荐对象,
- –然后推荐给用户。
2.1用户建模
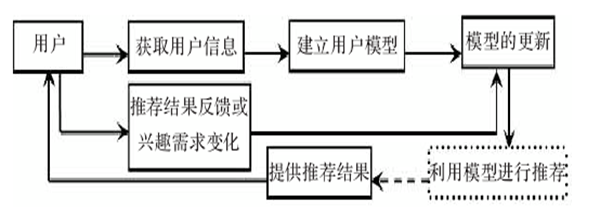
2.2. 推荐对象item的建模
推荐对象的建模方法(文档类对象)
•基于内容的方法
-
–是从对象本身抽取信息来表示对象,
-
–使用最广泛的方法是用加权关键词矢量
•目前使用最广泛的是TF—IDF方法。
•基于分类的方法
-
–把同类文档推荐给对该类文档感兴趣的用户
-
–文本分类的方法有多种,
•比如朴素贝叶斯(Naive-Bayes),k最近邻方法(KNN)和支持向量机(SVM)等。
-
–对象的类别可以预先定义,也可以利用聚类技术自动产生
2.3 推荐算法
–是根据用户的兴趣特点或行为–向用户推荐用户感兴趣的信息或商品
•推荐系统的输入
–项目item :各种属性描述
–用户User:用户信息和行为日志
评价 review(评分矩阵
三、推荐系统评测
3.1 推荐系统实验方法
-
–离线实验(offline experiment)
机器学习思想,收集用户历史数据生成数据集,分为训练集测试集,训练预测,评估
优点:不需要真实用户参与,快速计算,测试大量不同算法
缺点:无法获得商业指标(点击率之类的)
-
–用户调查(user study)
–向用户推荐用户感兴趣的信息或商品-相对在线实验风险很低,出现错误后很容易弥补
-
–在线实验(online experiment)
AB测试:
–通过一定的规则将用户随机分成几组,
–并对不同组的用户采用不同的算法,
-然后通过统计不同组用户的各种不同的评测指标比较不同算法
AB测试的优点:
可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标
AB测试的缺点:
主要是周期比较长,必须进行长期的实验才能得到可靠的结果。
工程问题:进行一个后台推荐算法的AB测试,同时网页团队在做推荐页面的界面AB测试,最终的结果就是你不知道测试结果是自己算法的改变,还是推荐界面的改变造成的。
3.2评测指标
•1. 用户满意度
•2. 预测准确度
评分预测
分类准确度
排序准确度
•3. 覆盖率
•4. 多样性
•5. 新颖性
•6. 惊喜度
•7. 信任度
•8. 实时性
•9. 健壮性
•10. 商业目标
3.2.1 满意度
3.2.2 预测准确度(三个角度)
-
评分预测
•平均绝对误差(MAE)
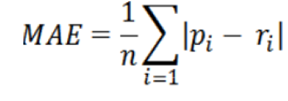
•平均平方误差MSE
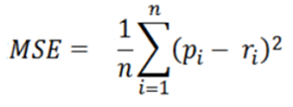
•均方根误差(RMSE)
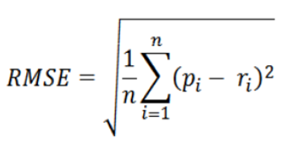
Normalized
•避免个别点值比较小,预测不准引起的误差非常大
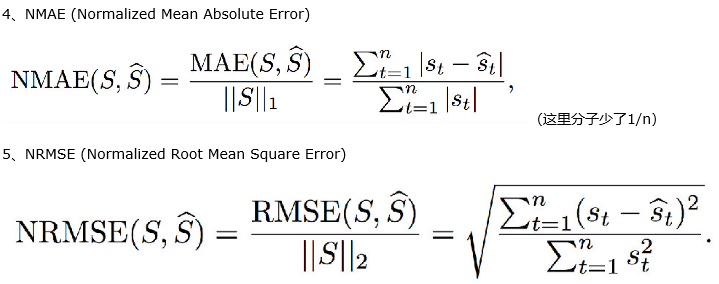
-
分类准确率
分类准确度定义为推荐算法对一个产品用户是否喜欢判定正确的比例
-
排序准确度
排序准确度用于度量推荐算法产生的列表符合用户对产品排序的程度
3.2.3 覆盖率
覆盖率(coverage)描述一个推荐系统对物品长尾的发掘能力。
长尾(The Long Tail)是统计学中幂律(Power Laws)和帕累托分布(Pareto distributions)特征的一个口语化表达,推荐系统中有长尾效应(马太效应)。
主流商品往往代表了绝大多数用户的需求,而长尾商品往往代表了一小部分用户的个性化需求。

3.2. 7. 信任度
推荐可解释
3.2.8 实时性
–推荐系统需要实时地更新推荐列表来满足用户新的行为变化。
–实时性的第二个方面是推荐系统需要能够将新加入系统的物品推荐给用户。
3.2.9. 健壮性
•推荐系统抗击作弊的能力
综合考虑各种指标
• 在给定覆盖率、多样性、新颖性等限制条件下,尽量优化预测准确度。
• 用一个数学公式表达,离线实验的优化目标是:
– 最大化预测准确度
• 使得 覆盖率 > A
• 多样性 > B
• 新颖性 > C
• 其中,A、B、C的取值应该视不同的应用而定。
3.3评测维度
•一个推荐算法,虽然整体性能不好,但可能在某种情况下性能比较好,而增加评测维度的目的就是知道一个算法在什么情况下性能最好。
•一般来说,评测维度分为如下3种。
- –用户维度: 主要包括用户的人口统计学信息、活跃度以及是不是新用户等。
- –**物品维度 :**包括物品的属性信息、流行度、平均分以及是不是新加入的物品等。
- –时间维度 :包括季节,是工作日还是周末,是白天还是晚上等。
四、推荐系统的挑战

第二讲 推荐算法
一、推荐系统(算法)的本质
- 通过一定的方式将用户和物品联系起来,而不同的推荐系统利用了不同的方式。
- 联系用户和物品的常用方式,比如利用好友、用户的历史兴趣记录以及用户的注册信息等。
•推荐系统核心问题
-
–预测
•预测喜好 rating
-
–推荐
•对预测结果排序 topN
-
–解释
•对推荐列表进行解释
**二、**推荐算法的输入数据
•推荐系统的输入
- –项目item :各种属性描述
- –用户User:用户信息和行为日志
- –评价 review(评分矩阵)
- –附加信息
2.1推荐系统附加信息

2.2用户行为数据----用户反馈行为
•按照反馈的明确性分
-
–显性反馈行为(explicit feedback)
•用户明确表示对物品喜好的行为
-
–隐性反馈行为(implicit feedback)
•用户发出这些行为时并不是为了表达兴趣/态度,只是在正常使用产品而已

比较:

优缺点
显式反馈
– 优点:简单而直接的做法,能相对准确地反映用户的需求,同时所得的信息比较具体、全面、客观,结果往往比较可靠
– 缺点:很难收到实效,主要原因就是很少用户愿意花时间或不愿向系统表达自己的喜好
隐式反馈
– 优点:减少用户很多不必要的负担,不会打扰用户的正常生活
– 缺点:跟踪的结果未必能正确反映用户的兴趣偏好
•按照反馈的方向分,
- –正反馈
- –负反馈。
2.3 用户行为分析
•用户行为数据中蕴含着各种信息
三、推荐算法分类
3.1 依据推荐结果分类
•大众化推荐
- –查询推荐,和具体用户关联不大
- –搜索词联想 推荐
- –Popular 算法
•个性化推荐
- –需要了解用户喜好
- –个性化推荐算法都是基于用户行为数据分析设计的
3.2 依据推荐模型构建方式分类
•基于物品和用户本身的启发式推荐
•基于关联规则的推荐
•基于模型的推荐
3.3依据输入数据分类
•基于规则的推荐:
–这类算法常见的比如基于最多用户点击,最多用户浏览等,
–属于大众型的推荐方法,
–在目前的大数据时代并不主流。
•基于人口统计学的推荐
–根据系统用户的基本信息发现用户的相关程度
•基于内容的推荐
–根据推荐物品或内容的元数据,发现用户偏好与物品(或者内容)的相关性
•基于协同过滤的推荐
–根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性
•混合型推荐 hybrid Recommendation
•基于社交网络关系的推荐
四、 基于人口统计的推荐
•根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户
五、 基于内容的推荐

六、基于协同过滤的推荐
包括在线的协同和离线的过滤两部分。
- –所谓在线协同,就是通过在线数据找到用户可能喜欢的物品,
- –而离线过滤,则是过滤掉一些不值得推荐的数据,
•协同过滤的模型一般为m个物品,n个用户的评分矩阵
算法输入
•基于人口统计学的推荐
–算法输入:用户信息
•基于内容的推荐
–算法输入:物品信息,用户行为日志
•基于协同过滤的推荐
–算法输入:评分矩阵
推荐系统老司机的十条经验
•1、隐式反馈比显式反馈要爽
•2、深刻理解数据——–深入业务理解,到底什么样的数据才是我们要找的
从豆瓣评分的形状一辨别电影质量
3、为模型定义好学习任务
4、推荐可解释比精准更有意义
5、矩阵分解大法好
6、万能的集成方法
7、推荐系统也不能免俗之特征工程
8、对你的推荐系统要了如指掌
9、数据和模型是重要,但正确的演进路径更不容忽视
10、别一言不合就要上分布式
三讲 基于邻域的协同推荐
一、协同推荐
1、协同推荐的优点
①不需要太多特定领域的知识
②可以通过基于统计的机器学习算法来得到比较好的效果
③最大的优点是工程上容易实现,可以方便的应用到商品中
2、协同过滤
(1)定义
①作为推荐算法中最经典的类型
②过滤掉一些不值得推荐的数据
(2)思想:
①收集用户的历史行为和偏好信息,利用群体智慧给出推荐。
②朋友之间互相推荐。
(3)协同过滤最大优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。
(4)协同过滤存在的问题
①冷启动问题
②兴趣漂移
3、协同过滤推荐的三种类型
①基于用户(user-based)的协同过滤:主要考虑的是用户和用户之间的相似度。
②基于**项目(item-based)**的协同过滤:物品和物品之间的相似度。
③基于**模型(model based)**的协同过滤:主流的方法可以分为:用关联算法,聚类算法,分类算法,回归算法,矩阵分解,神经网络,图模型以及隐语义模型来解决。
4、基于邻域的方法
(1)user-based CF
①通过不同用户对item的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐;
(2)item-based CF
通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐;
二、基于用户的协同推荐
1、基本思想:
用户的选择是基于朋友的推荐
2、算法步骤
(1)找到和目标用户兴趣相似的用户集合。
关键就是计算两个用户的兴趣相似度
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
3、不同的相似度度量方式
(1)欧式距离:欧氏度量在处理一些受主观影响很大的评分数据时,效果则不太明显。
(2)jaccard距离
(3)余弦相似度
(4)2.1.4Pearson correlation
4、Jaccard相似度
(1)公式

(2)问题:忽略了评价的分值
5、余弦相似度
(1)公式:

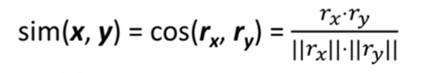
(2)存在问题:时间复杂度是O(U*U)
解决方法:
①先计算出分子不为0的情况,再计算分母
②快速计算
(3)余弦相似度变种:没有分值,只有0和1

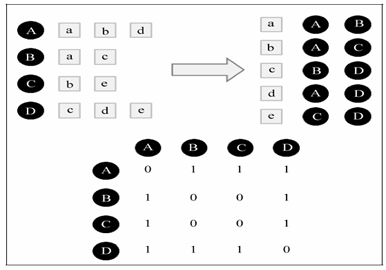
(4)快速计算
①建立物品到用户的倒排表,a是item
②建立一个4*4的用户相似度矩阵W,W是余弦相似度中的分子部分,是共现次数。
(5)改进:惩罚热门item
如果两个用户都曾经买过《新华字典》,这丝毫不能说明他们兴趣相似
新的度量函数为:
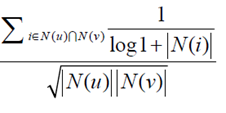 N是物品的热门程度
N是物品的热门程度
6、皮尔逊相关系数
皮尔逊相关系数就是把两组数据标准化处理之后的向量夹角的余弦
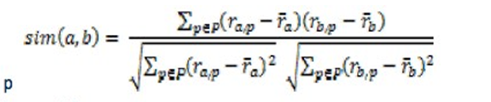
就是减掉个人的平均得分
7、分数预测
(1)方法一:简单的将所有相似用户的得分加起来平均
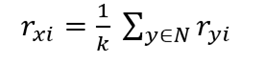
(2)方法二:基于相似度加权平均
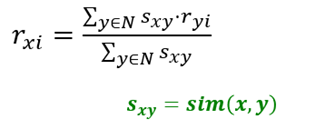
(3)方法三:从活动用户的平均值中添加/减去邻居的偏差,并将其用作预测
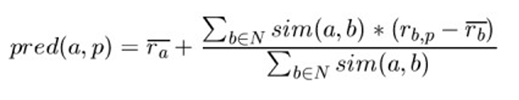
(4)提升预测方程
Item之间需要横向比价预测值
给每个items加权重

8、应用场景
用户数远远小于物品数的场景
9、存在的问题
(1)如果U2U的用户比项目多,则会出现可量测性问题。
(2)高稀疏性导致两个用户之间很少有共同的评分。
三、基于物品的协同推荐
1、思路:
基于用户对推荐对象品牌的信任而进行的推荐。
2、假设:
如果大部分用户对一些推荐对象的评分比较相似,则当前用户对这些项的评分也比较相似。
3、基本观点:
利用物品之间的相似度去做预测。
4、item相似度的计算
这里N就是向量,上面的基于用户的相似度N(u)是用户为主体,用户喜欢的item的向量
N(i)指的是一个item的喜欢他的用户的向量
(1)方法一:分值是0和1
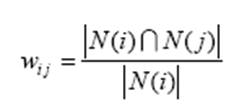
问题:如果物品j很热门,很多人都喜欢,那么Wij就会很大,接近1。
(2)方法二:余弦相似度
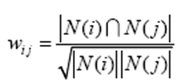
(3)方法三:在相似度公式中增加惩罚因子
用户活跃度
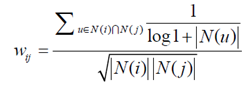
(4)增加item流行度

如果α=0.5就是标准的ItemCF算法。
(5)存在的问题:
两个不同领域的最热门物品之间往往具有比较高的相似度。
5、预测
(1)公式:
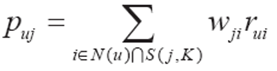
N(u)是用户喜欢的的物品的集合
S是和物品j最相似的k个物品的集合
W是物品之间的相似度
R是用户对物品的兴趣
算法通过item-j的相似物中u喜欢的物品预测,所有满足要求的item相似度乘以喜欢程度
ppt有实例,去看看
6、基于item过滤的预处理
①构建item-item矩阵
②在运行时使用的邻域通常比较小,因为只考虑用户已评分的项目
③项目相似性应该比用户相似性更稳定
7、基于item和基于内容的特点
(1)基于item:
①需要某种形式的评级反馈。
②新用户和新项目的冷启动。
(2)基于内容的:
①无需社区,项目之间可进行比较。
②必要的内容描述,
③新用户冷启动,没有惊喜。
四、基于item和基于用户的比较
(1)user-based: User-user 比较,适用于用户较少的场合
(2)item-based:Item-item 比较,适用于物品数明显小于用户数的场合。
(3)领域:
①user-based: 时效性较强,用户个性化兴趣不太明显的领域.
②Item-based:长尾物品丰富,用户个性化需求强烈的领域。
userCF新用户冷启动问题
ItmeCF新物品冷启动问题
(4)应用:



五、基于邻域的协同过滤存在的问题
(1)冷启动问题
(2)数据稀疏问题
(3)
第四讲
1、协同过滤推荐的分类
(1)基于邻域的CF
①基于用户的协同过滤
②基于项目的协同过滤
(2)基于模型的协同过滤
一、基于模型的协同过滤
是目前最主流的协同过滤类型。用机器学习的思想来建模模块,训练集、模型、测试集。
1、主流的方法
用关联算法,聚类算法,分类算法,回归算法,矩阵分解,神经网络,图模型以及隐语义模型来解决。
2、基于memory的推荐算法
①将所有用户的数据读入内存,进行运算。
②当数据量特别大时,显然这种方法是不靠谱的。
二、基于关联规则的推荐
(1)基本思想
基于物品之间的共线性挖掘频繁项。基于关联规则的推荐不是一个个性化的推荐**,是一个整体的推荐,因为和个人偏好无关**
(2)算法:A-priori,FP-Growth
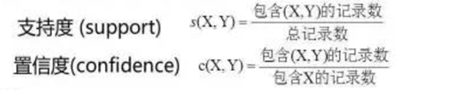
(3)评价:
①实现简单,实用性较强。
②相似商品的推荐效果往往不如协同过滤好。
③解释变量之间的关联时要特别小心,很可能受一些隐含因素的影响。
(4)步骤:
①找出用户u喜好过的item x。
②与所有其他items(y)计算支持度和置信度。
③推荐数值最高的给用户。
(5)关联规则的问题
①关联规则直接从数据中挖掘潜在的关联,与个人的偏好无关,忽略了个性化的场景。
②关联规则的发现最为关键且最耗时,是算法的瓶颈,但可以离线进行。
③没有体现出用户对物品的喜好程度。
三、用矩阵分解做协同过滤
老司机的十条建议
1、隐语义模型LFM
(1)核心思想
①通过隐含特征联系用户兴趣和物品。
②对于某个用户,首先找到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
(2)目标:
挖掘用户潜在因子和项目的潜在因子。
(3)隐语义模型所解决的问题
对物品进行分类,判定用户对哪些物品类别有兴趣,兴趣程度如何,物品在类别中权重如何。
(4)隐语义模型:基于用户的行为统计进行自动聚类
①能反应用户对物品的分类意见;
②可以指定将物品聚类的类别数k,k越大,则粒度越细;
③隐语义模型能计算出物品在各个类别中的权重。
(5)隐语义模型LFM也就是矩阵分解模型MF
2、SVD奇异值分解
(1)SVD用于推荐
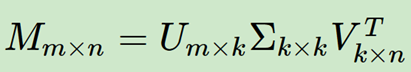
①用SVD将原始数据映射到低维空间中,找出和用户距离近,同时没有评价过的物品。
②在已经降维的数据中,基于SVD对用户未打分的物品进行评分预测,返回未打分物品的评分预测值。
(2)传统SVD存在的问题
①SVD分解要求矩阵是稠密的,也就是说矩阵的所有位置不能有空白。
采用的方法是对评分矩阵中的缺失值进行简单的补全。
比如用全局平均值或者用用户物品平均值补全
②较难使用
用户数和物品一般都是超级大,随便就成千上万了。这么大一个矩阵做SVD分解是非常耗时的。
3、LFM算法
常见的矩阵分解推荐方法有
①基本矩阵分解(basic MF)
② 正则化矩阵分解(Regularized MF)
③基于概率的矩阵分解(PMF)
3.1FunkSVD算法
(1)矩阵M 分解为P 和Q
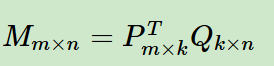
P表示用户对于某个隐因子的喜好度
Q表示物品对于某个隐因子的包含度
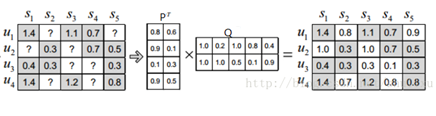
先分解成近似的P和Q矩阵,然后再补全。
(2)构造优化函数
①直接通过训练集中的观察值,利用最小化RMSE学习P和Q的矩阵。
②采用了机器学习的思想。
(3)均方根误差(标准误差)RMSE
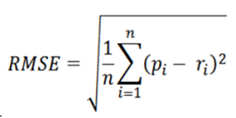
P是预测值,r是用户评分。
(4)损失函数
后面这个 ∑ f = 1 F \sum_{f=1}^{F} ∑f=1F代表用户矩阵和物品矩阵对应的行列相乘
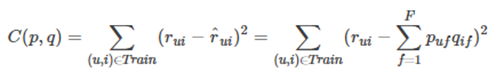
(5)学习方法有两种
①梯度下降迭代法
对损失函数里有两组参数( puf 和qif )分别求偏导数
参数沿着速下降方向向前推进
α 是学习速率,它的取值需要通过反复实验获得
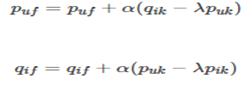
②交替最小二乘
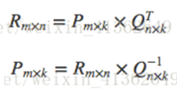
好处:
1)在交替的其中一步,也就是假设已知其中一个矩阵求解另一个时,要优化的参数是很容易并行的。
2)在不是很稀疏的数据集合上,交替最小二乘通常比随机梯度下降要更快的得到结果
3.2正则化矩阵分解
①是Basic MF的优化
②解决MF造成的过拟合问题。
③在优化目标上加入正则项,也就是惩罚项
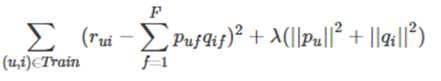
Lamda为正则化参数
(1)在隐语义模型中,一共有四个参数
①隐分类的个数f
②梯度下降过程中的步长
③损失函数中的惩罚因子λ;
④正反馈样本数和负反馈样本数的比例ratio。
3.3BasicSVD算法
(1)BasicSVD假设评分系统包括三部分的偏置因素
①一些和用户物品无关的评分因素
②用户偏置项:用户有一些和物品无关的评分因素
③物品偏置项:物品有一些和用户无关的评分因素。
(2)评分预测为:

系统平均分为*μ,*第i个用户的用户偏置项为 bi ,用户打分习惯,第j个物品的物品偏置项为bj物品整体评价水平。
(3)损失函数

(4)时间因素
①用户的兴趣包括长期和短期,动态地考虑一段时间内用户的兴趣是很有必要的。
②上面的几个因素中随着时间变化
3.4 LFM和基于邻域的方法的比较
(1)理论基础
①LFM具有比较好的理论基础,它是一种学习方法,通过优化一个设定的指标建立最优的模型。
②基于邻域的方法更多的是一种基于统计的方法,并没有学习过程。
(2)推荐解释
①基于邻域的算法支持很好的推荐解释,它可以利用用户的历史行为解释推荐结果。
②LFM无法提供这样的解释,它计算出的隐类虽然在语义上确实代表了一类兴趣和物品。
(3)离线计算的空间复杂度
①基于邻域的方法需要维护一张离线的相关表
假设有N个用户和M个物品
用户相关表,则需要O(N*N)的空间,
物品相关表,则需要O(M*M)的空间。
②LFM在建模过程中,如果是F个隐类,那么它需要的存储空间是O(F*(M+N))。
(4)离线计算的时间复杂度
① 在一般情况下,LFM的时间复杂度要稍微高于UserCF和ItemCF,这主要是因为该算法需要多次迭代。
②但总体上,这两种算法在时间复杂度上没有质的差别。
(5)在线实时推荐
①UserCF和ItemCF在线服务算法需要将相关表缓存在内存中,然后可以在线进行实时的预测。
②LFM不能进行在线实时推荐。
3.5 SVD++算法
(1)思想
①在basicSVD上做了进一步的加强,考虑增加用户的隐式反馈。
(2)考虑邻域影响的LFM
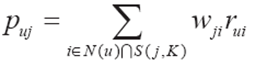
N(u)是用户喜欢的物品的集合,
S(j,K)是和物品j最相似的K个物品的集合,
wji是物品j和i的相似度,
rui是用户u对物品i的兴趣
W是一个需要学习的参数,通过如下损失函数进行优化:
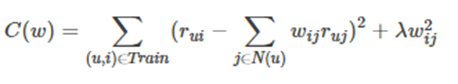
(3)问题:
①w将是一个比较稠密的矩阵,存储他需要比较大的空间。
(4)对W进行分解,将参数降低到2nF个,
xi 、 yi 是两个F 维的向量。
由此可见,该模型用 x i T x^{T}_i xiT y j y_j yj代替了 w i j w_{ij} wij
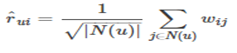
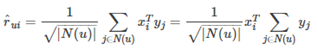
(5)最终的SVD++模型

–用户兴趣=显式兴趣+偏见+ 隐式反馈
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vydn2KX2-1624585530151)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20210613115331098.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eBMUKhWI-1624585530151)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20210613115337694.png)]
(6)SVD++算法在BiasSVD上的改进
①隐式反馈
②邻域行为
③增加历史行为
④要学习的参数多了两个向量x和y
3.6 SVD算法的实际应用
用户数量和物品数量都巨大的应用,提出两个办法得到真正的推荐结果
①第一种,利用一些专门设计的数据结构存储所有物品的隐因子向量,从而实现通过一个用户向量可以返回最相似的K个物品。
②第二种,拿着物品的隐因子向量先做聚类,给用户推荐物品就变成了给用户推荐物品聚类,得到给用户推荐的聚类后,再从每个聚类中挑选几个物品作为推荐结果。
(1)雅虎新闻推荐
利用新闻链接的内容属性(关键词、类别等)

四、协同过滤总结
(1)优点
1)邻域
2)模型:模型通用性强,不需要太多对应数据领域的专业知识,工程实现简单,效果也不错。
在工业界广泛应用。
(2)协同过滤问题
冷启动,考虑上下文,发掘用户个性化需求
五、冷启动问题
1、基于矩阵分解和基于协同过滤方法的比较

一、冷启动问题
(1)、定义:
如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动问题。
(2)、冷启动问题的分类:
①用户冷启动
②物品冷启动
③系统冷启动
(3)、冷启动问题的解决方案
①提供非个性化的推荐
②利用用户注册信息
③对于新加入的物品,可以利用人口统计学信息,将它们推荐给喜欢过和它们相似的物品的用户。
④在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
背下面三个
1、利用用户注册信息
(1)用户的注册信息的分类
①人口统计学信息
②用户兴趣描述
③从其他网站导入的用户站外行为数据
(2)基于人口统计的推荐的3种算法
①基于人口统计的推荐

②Lifestyle Finder:将用户分成不同的族群
1)将美国人群按照人口统计学分成62类
2)对于每个新用户根据其填写的个人资料判断他属于什么分类。
3)最后给他推荐这类用户最喜欢的15个链接。
③考虑用户的个性:
计算某种特征f的用户喜欢的物品i:
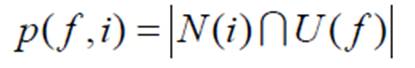
N是喜欢物品i的用户的集合
U是具有特征f的用户集合
然后给每一类用户推荐p最高的10个物品,并通过准确率和召回率计算预测准确度。
1)归一化:

**2)数据稀疏问题:**如果一个物品只被一个用户喜欢,而这个用户刚好就有特征f,那么p为1,没有统计意义,解决方法:在分母中加入参数a
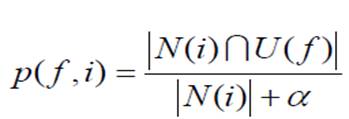
2、选择合适的物品启动用户的兴趣
应对冷启动:让用户对物品进行评分来收集用户兴趣,系统的首要问题:如何选择物品让用户进行反馈
(1)选择启动用户兴趣的物品需要具有以下特征
①比较热门
②启动物品需要有多样性
③具有代表性和区分性。
(2)物品选择一种解决方法-决策树
①从根节点开始询问用户对该节点物品的看法
②根据用户的选择将用户放到不同的分支
③直到进入最后的叶子节点(某个用户族群,很难解释)
④此时我们就已经对用户的兴趣有了比较清楚的了解,从而可以开始对用户进行比较准确地个性化推荐。
(3)如何判断物品是否具有较高的区分度?
①将用户分成3类:喜欢物品i、不喜欢、不知道物品i的用户。
②如果这三类用户集合内的用户对其他的物品兴趣很不一致,说明物品i具有较高的区分度:
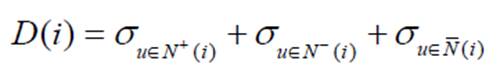
1)Nadav Golbandi的算法
①首先会从所有用户中找到具有最高区分度的物品i,
②然后将用户分成3类。
③然后在每类用户中再找到最具区分度的物品
④然后将每一类用户又各自分为3类
⑤继续下去,最终可以通过对一系列物品的看法将用户进行分类
3、利用物品的内容信息
基于内容的推荐
二、基于内容的推荐CB
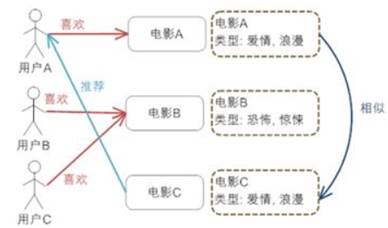
1、CB算法的主要步骤
①Item Representation:
为每一个item抽取一些特征属性出来,也就是结构化物品的描述操作,
对应的处理过程叫做: Content Analyzer(内容分析);
②Profile Learning:
利用一个用户过去喜欢(不喜欢)的item特征数据,来学习该用户的喜好特征(profile);
对应的处理过程叫做:Profile Learning(特征学习);
③. Recommendation Generation:
通过比较上一步得到的用户profile于特征item的特征,为此用户推荐一组相关性最大的item即可;
对应的处理过程叫做:Filtering Component(过滤组件)。
2、Content Analyzer(内容分析)
Item的属性
1)结构化属性:属性的意义比较明确,其取值限定在某个范围
2)非结构化的属性:文本、图片
3)混合型:朋友推荐
3、Profile Learning(特征学习)
①该过程就是通过用户u过去的这些喜好喜好判断,构建一个判别模型
②最后可以根据这个模型判断用户u对于一个新的item是否会更好。
③是一个比较典型的有监督学习问题。
④理论上可以使用机器学习的分类算法求解所需要的判别模型。
⑤常用的算法:
1)最近邻
2)决策树
3)线性分类
4)朴素贝叶斯
2、CB-Item Representation
(1)物品特征属性
①非结构化属性:图片、文本
②结构化属性:数值型、布尔型、文本型
(1)物品的文本属性
1)大段自然文本
①自然语言处理:
词袋模型:词条化,分词
词袋法转化为特征向量:计算词频TF/IDF,计算文本之间的相似度。
2)短文本:关键词很少
解决方案:
①合并为长文本
②合并近义词,降低数据维集度
③关键词内容扩展
④采用主题模型:PLSA,LDA
(2)主题模型PLSA
①利用文档-词项信息p(w|d) ,文档-主题p(z|d)
训练主题-词项p(w|z),话题z固定
②计算出物品(文档)在话题上的分布
跑一次只包含一个文章的pLSA
算出p( z k z_k zk |d)
③然后利用两个物品的话题分布计算物品的相似度。
p(z k |d) 作为权重,文档可以表示成 k维向量
(3)计算分布的相似度-KL散度
①相对熵
②是两个概率分布(probability distribution)间差异的非对称性度量,不是距离
③度量使用一个分布来近似另一个分布时所损失的信息。
④KL散度越大说明分布的相似度越低

(4)物品的结构化属性
可分为:1、连续。2、离散:二值、非二值。

(1)集中计算相似度的距离

(2)非二值属性的编码方式
连续属性-离散化
离散属性-编码
①Onehot独热编码
1)主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
2)将离散特征的取值扩展到了欧式空间。
3、CB特点:
(1)优点:
①. 用户之间的独立性(User Independence):
既然每个用户的profile都是依据他本身对item的喜好获得的,自然就与他人的行为无关。
②好的可解释性(Transparency)
如果需要向用户解释为什么推荐了这些产品给他,你只要告诉他这些产品有某某属性,这些属性跟你的品味很匹配等等。
③新的item可以立刻得到推荐(New Item Problem)
只要一个新item加进item库,它就马上可以被推荐,被推荐的机会和老的item是一致的。
(2)缺点:
①item的特征抽取一般很难(Limited Content Analysis)
②无法挖掘出用户的潜在兴趣(Over-specialization):
缺乏惊喜
③无法为新用户产生推荐(New User Problem):
用户冷启动
三、基于特征的推荐
(一)特征工程
(1)特征:在观测现象中的一种独立、可测量的属性。
(2)特征工程就是一个把原始数据转变成特征的过程。
(3)特征工程:利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
(4)获得更好的训练数据。
(5)特征工程的子问题:
①特征选择:1)选择: 信息量大的、有差别性的、独立的特征。2)目的: 从特征集合中挑选一组最具统计意义的特征子集,从而达到降维的效果。3)利用领域知识生成和提取特征。
②特征提取:指利用已有的特征计算出一个抽象程度更高的特征集,也指计算得到某个特征的算法。如SVD, PCA。
③特征构造:从原始数据中人工的构建新的特征。
(二)现代推荐系统框架

1、CTR任务
(1)什么是CTR任务
①ClickThroughRate
②CTR是计算广告中最核心的算法之一。
③CTR预估是指对每次广告的点击情况做出预测,预测用户是点击还是不点击。
④CTR预估和很多因素相关,比如历史点击率、广告位置、时间、用户等。
⑤现在常用的推荐系统完全可以转为为CTR任务来实现。
(2)CTR预估与推荐系统的目标存在gap
1)CTR预估必须“绝对准确”
①LearningToRank(L2R中采用pointwise loss
每个样本由<user, item, label(0或1)>组成,
loss采用binary cross entropy loss
②由于实际系统中,正样本太稀疏
算法将所有<user, item>都预测成0,binary cross entropy loss同样能够最小化。
③现实的CTR算法,往往伴随着在训练时对正样本加权,而在预测时还需要对预估出来的ctr进行校正。
④CTR预估是非常讲究“真实负样本”的,
一定是给用户真实曝光过而被用户忽略的item,才能作为负样本
2)推荐系统只要求“相对准确”
①采用Pairwise LearningToRank(LTR)
每个样本由<user, item+, item->三元组组成
预测的目标是<user, item+>的匹配得分要高于<user, item->的匹配得分
采用margin-based hinge loss或BPR loss,贝叶斯个性化排序 BPR
②通过随机采样来获得负样本
随机采样毕竟引入了噪声, 对于“相对准确”可以接受。
(3)CTR任务的关键特征
1)大量离散特征
2)大量高纬度稀疏特征:Onehot表示。
2、CTR预估模型
(1)Logistic回归
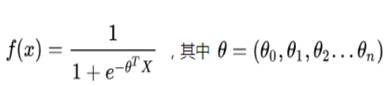
Ctr预估模型的最基本模型。
也是工业界最喜爱的方案,简单。
1)优势:
①处理离散化特征,海量高纬离散特征
②模型十分简单,很容易实现分布式计算。
③LR的变种也有许多,比如Google的FTRL,其实这些变种都可以看成:LR+正则化+特定优化方法。
2)缺点:
①特征与特征之间在模型中是独立的,实际上存在特征交叉可能性。
②需要将特征进行离散化,归一化,在离散化过程中也可能出现边界问题。
(2)GBDT梯度提升决策树
1)什么是GBDT
①是一种表达能力较强的非线性模型
2)优点:
①优势在于处理连续值特征
②由于树的分裂算法,它具有一定的组合特征的能力,模型的表达能力要比LR强。
③使用GBDT减少人工特征工程的工作量和进行特征筛选。
3)缺点:
①对大规模离散化特征,则需要将更多特征统计成连续值特征,或者embedding,可能需要耗费比较多的时间。
②GBDT模型具有很强的记忆能力,不利于挖掘长尾特征。
(3)GBDT+LR
1)先使用GBDT对一些稠密的特征进行特征选择,得到叶子节点
①利用GBDT替代人工实现连续值特征的离散化,改善了人工离散化中可能出现的边界问题
②也减少了人工的工作量。
2)再拼接离散化特征放进去LR进行训练。
(4)因子分解机
1)对于特征组合,业界通常的做法
①Tree系列:1、RF(Random Forests)。2、GBDT(Gradient Boost Decision Tree)
②FM系列:FM,FFM,DeepFM。
2)什么是特征组合?
①通过将单独的特征进行组合(相乘或求笛卡尔积)而形成的合成特征。
②特征组合有助于表示非线性关系。
3)Poly2模型:degree-2 poly-nomial mappings
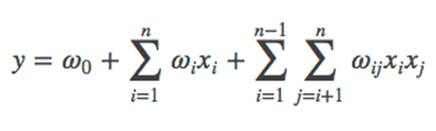
3、贝叶斯个性化排序
Bayesian Personalized Ranking,
简称BPR
(1)排序算法大体上可以分为3类:
①点对方法(Pointwise Approach)
将排序问题被转化为分类、回归之类的问题,并使用现有分类、回归等方法进行实现。
CTR
②成对算法(Pairwise Approach)
排序被转化为对序列分类或对序列回归。
所谓的pair就是成对的排序,比如(a,b)一组表明a比b排的靠前。
BPR
③列表方法(Listwise Approach)
学习和预测过程中都将排序列表作为一个样本。排序的组结构被保持。
3.3.1 非负矩阵分解 Non-negative Matrix Factorization(NMF)
(1)基本思想
①对于任意给定的一个非负矩阵V。
②NMF算法能够寻找到一个非负矩阵W和一个非负矩阵H,,使得满足:
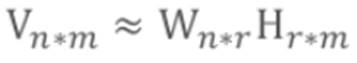
③从而将一个非负的矩阵分解为左右两个非负矩阵的乘积 ,r远远小于m和n。
④约束:所有矩阵非负。
(2)应用:
①应用的领域很广,源于其对事物的局部特性有很好的解释。
②最有效的就是图像处理领域,是图像处理的数据降维和特征提取的一种有效方法。
(3)物理意义:
NMF也是将矩阵分解成两个矩阵。
①基矩阵W:每一列包含一个基向量,这组基向量构成一个r维的空间。
②投影矩阵H:每一列则近似为原始数据对应的列向量在该r维空间的投影。
(4)NMF和SVD的区别:
①物理意义不同
②SVD : A=UΣV T 正交 . NMF: 分解为两个矩阵 W 和 H ,只要 W 和 H 的entries都是non-negative的就好,不需要是orthogonal的。
③NMF的 W H 只是approximate,而SVD是分解后的矩阵相乘可以reconstruct原矩阵。
④SVD的singular vector即对角矩阵是unique的,而NMF分解的矩阵不是unique的。
⑤svd或者latent factor model会得到负的值。
(5)方法:
NMF 方法也是构造一个目标函数和一些约束条件,然后用梯度下降的算法来计算得到一个局部最优解。

(6)利用nmf进行推荐的思路:
①将评分矩阵转置然后分解成两个矩阵W和H。
②根据基矩阵W,可以计算得到目标用户评分向量a对基矩阵W的投影向量h。
③计算投影向量h与投影矩阵H各行之间的欧式距离,将其中距离最小的前k个用户组成目标用户a的最近邻集合。
④然后用皮尔逊相关法将最近邻集合中的数据进行加权计算,然后排序进行推荐。
主要思想还是knn(基于邻域),只是在中间用了矩阵分解的方法降维降低了计算的时间复杂度。
3.3.2 BPR算法
(1)基本思想:
①三元组<u,i,j>:用>u符号表示用户u的偏好。<u,i,j>可以表示为:i >u j。表示对用户u来说,i的排序要比j靠前。
②在BPR中也用到了类似矩阵分解的思想:
NMF 非负矩阵分解,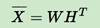
预测得出的用户对该物品的偏好计算
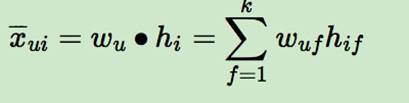
用户u对物品i的偏好。
(2)BPR参数求解过程:
BPR 基于最大后验估计P(W,H|>u)来求解模型参数W,H。
①用θ来表示参数W和H
②>u代表用户u对应的所有商品的全序关系,则优化目标是P(θ|>u)
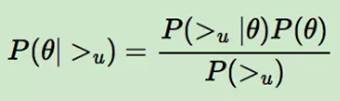
③假设了用户的排序和其他用户无关,那么对于任意一个用户u来说,P(>u)对所有的物品一样
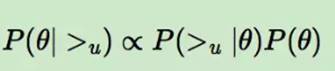
④优化目标转化为两部分。第一部分和样本数据集D有关,第二部分和样本数据集D无关。

σ(x)是sigmoid函数,σ里面的项我们可以理解为用户u对i和j偏好程度的差异
优化目标的第一项可以写作
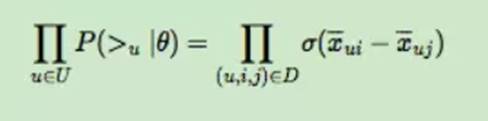
• 思想:
– 对于训练数据中的<u,i,j>,用户更偏好于i,
– 那么我们当然希望在X–矩阵中ui对应的值比uj对应的值大
– 而且差距越大越好!
(3)总结:
①BPR是基于矩阵分解的一种排序算法,它不是做全局的评分优化,而是针对每一个用户自己的商品喜好分别做排序优化。
②它是一种pairwise的排序算法,对于每一个三元组<u,i,j>,模型希望能够使用户u对物品i和j的差异更明显。
③同时,引入了贝叶斯先验,假设参数服从正态分布,在转换后变为了L2正则,减小了模型的过拟合。
第七讲 基于标签的推荐
1、推荐算法的分类
(1)基于人口统计学的推荐
根据系统用户的基本信息发现用户的相关程度
(2)基于内容的推荐
根据推荐物品或内容的元数据,发现用户偏好与物品(或者内容)的相关性
(3)基于协同过滤的推荐
根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性
①基于邻域的CF
1)基于用户(user-based)的协同过滤
2)基于项目(item-based)的协同过滤
②基于模型的协同过滤
隐语义模型LFM:FunkSVD算法、Regularized MF、BiasSVD算法、SVD++算法 (包含邻域思想)
(4)混合型推荐 hybrid Recommendation
一、基于图模型的协同过滤
graph-based model CF
**(1)输入:**用户行为
①用户行为用二分图G(V,E)表示
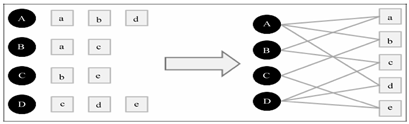
V为用户user和物品item组成的顶点集。
E则代表每一个二元组(u,i)之间对应的边e(u,i)。(不考虑权重;考虑权重)
**(2)**用图模型做协同过滤,则将用户之间的相似度放到了一个图模型里面去考虑
**(3)目标:**度量用户顶点vu和与vu没有边直接相连的物品节点在图上的相关性
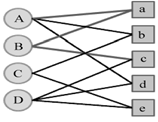
**(4)**相关性高的一对顶点一般具有以下特证
①两个顶点之间有路径相连。
②连接两个顶点之间的路径长度都比较短。
③连接两个顶点之间的路径不会经过出度比较大的顶点。
(5)相似度度量的方法:
①基于内容(content-based):匹配文本相似度、计算项集合的重叠区域等。
②基于链接(对象间的关系)的方法:基于结构的相似度度量方法、最近的研究表明,更加符合人的直觉判断。
(6)常用的算法:
1**)simrank算法**
①基本思想:被相似对象引用的两个对象也具有相似性
2**)PersonalRank算法**
基于随机游走的PersonalRank算法
和PangRank算法相似
1.1 simrank算法
(1)定义:
SimRank 是一种基于图的拓扑结构信息来衡量任意两个对象间相似程度的模型。
(2)特点:
①完全基于结构信息
②且可以计算图中任意两个节点间的相似度
③评分
(3)SimRank相似度的核心思想:
①如果两个对象被其相似的对象所引用(即它们有相似的入邻边结构),那么这两个对象也相似。
②换句话说,如果两个用户相似,则与这两个用户相关联的物品也类似;如果两个物品类似,则与这两个物品相关联的用户也类似。
(4)如何计算集合内两个点的相似度
某一个子集内两个点的相似度s(a,b) 可以用和相关联的另一个子集节点之间相似度表示。
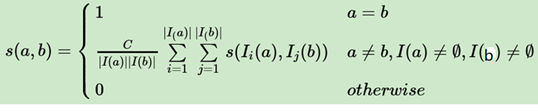
①C是一个常数,衰减因子,经验取值为0.8
②I(a)分别代表和a相连的二部图另一个子集的节点集合。
③I(b) 分别代表和b相连的二部图另一个子集的节点集合。
④s(I i (a),I i (b)) 即为相连的二部图另一个子集节点之间的相似度。
一般通过迭代算法计算:
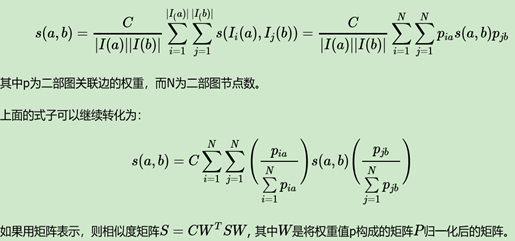

(5)simRank迭代算法
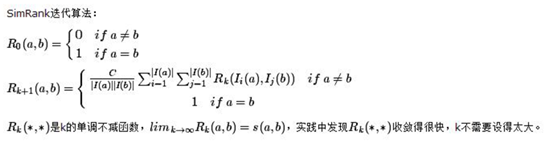
(6)simRank算法流程
1)输入:
①二部图对应的转移矩阵W,w是按列归一化的图邻接,每一列之和为1.
②阻尼常数c
③最大迭代次数k
2)输出:子集相似度矩阵S
①将相似度矩阵设置为单位阵I
②对于i=1,2…k:
a) temp=CW T SW
b) S=temp+I−Diag(diag(temp))
(7)simRank++算法
1)simRank++算法对simRank算法做了两点改进:
①考虑了边的权值。
②考虑了子集节点相似度。
2)simRank算法和simRank++算法的区别:
simRank算法:
①只要认为有边相连,则为相似。
②却没有考虑到如果共同相连的边越多,则意味着两个节点的相似度会越高。
simRank++算法:利用共同相连的边数作为证据,
①在每一轮迭代过程中,对SimRank算法计算出来的节点相似度进行修正。
②即乘以对应的证据值得到当前轮迭代的的最终相似度值。
(8)simRank算法的问题
由于SimRank算法涉及矩阵运算,如果用户和物品量非常大,则对应的计算量是非常大的。
常用的有两种方法来加快求解速度
①第一种是利用大数据平台并行化,即利用Hadoop的MapReduce或者Spark来将矩阵运算并行化,加速算法的求解。
②第二种是利用蒙特卡罗法(Monte Carlo, MC)模拟,
将两结点间 SimRank 的相似度表示为两个随机游走者分别从结点 a和 b出发到最后相遇的总时间的期望函数。
用这种方法时间复杂度会大大降低,
但是由于MC带有一定的随机性,因此求解得到的结果的精度可能不高。
1.2 PersonalRank算法
(1)随机游走random walk
l指基于过去的表现,无法预测将来的发展步骤和方向。
l核心概念是指任何无规则行走者所带的守恒量都各自对应着一个扩散运输定律 ,接近于布朗运动,是布朗运动理想的数学状态,
l现阶段主要应用于互联网链接分析及金融股票市场中。
pageRank算法
(2)pagerank公式
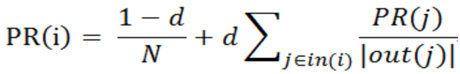
(3)personalRank算法目标
所有顶点相对于目标用户结点的相关性:

(4)用该算法进行推荐的步骤
①从用户u对应的节点vu开始在用户物品二分图上进行随机游走。
②游走到任何一个节点时,
l首先按照概率α决定是继续游走
l还是停止这次游走并从vu节点开始重新游走。
l如果决定继续游走,
那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。
③这样,经过很多次随机游走后,每个物品节点被访问到的概率会收敛到一个数。
④最终的推荐列表中物品的权重就是物品节点的访问概率。
有实例
(5)为了解决PersonalRank每次都需要在全图迭代并因此造成时间复杂度很高的问题,
两种解决方案
①减少迭代次数,在收敛之前就停止。这样会影响最终的精度,但一般来说影响不会特别大。
②从矩阵论出发,重新设计算法。
l令M为用户物品二分图的转移概率矩阵
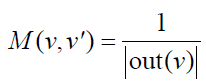
l迭代公式可以转化为
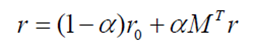
l解出上面的方程,得到

l只需要计算一次
二、标签信息
2.1UGC标签系统
(1)标签
①是一种无层次化结构的、用来描述信息的关键词。
②它可以用来描述物品的语义。
(2)根据给物品打标签的人的不同,标签应用一般分为两种:
①专家给物品打标签
②普通用户给物品打标签, UGC标签
2.2 标签数据预处理
(1)数据集
一个用户标签行为的数据集
①一般由一个三元组的集合表示
其中记录(u, i, b) 表示用户u给物品i打上了标签b。
②真实标签行为数据远远比三元组表示的要复杂
比如用户打标签的时间、
用户的属性数据、
物品的属性数据等。
(2)标签清理
1)意义:
①提高推荐性能
②将标签作为推荐解释
2)标签清理的方法
①清理不能反应用户的兴趣的tag
②清理包含没有意义的停止词的tag
词频很高
TF/IDF思想
③清理表示情绪的词
④合并词形不同、词义相同的标签
⑤标签扩展
(3)标签扩展
1)
①本质对每个标签找到和它相似的标签
②也就是计算标签之间的相似度
l同义词词典
l主题模型
l共现 统计学方法
同一个物品上的不同标签具有某种相似度
当两个标签同时出现在很多物品的标签集合中时,我们就可以认为这两个标签具有较大的相似度
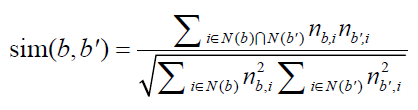
B为标签,i是item
(4)标签系统中的推荐问题
①基于标签的推荐
如何利用用户打标签的行为为其推荐物品
②标签推荐
如何在用户给物品打标签时为其推荐适合该物品的标签
三、基于标签的推荐
如何利用用户打标签的行为为其推荐物品
1、目标
用户u对物品i的兴趣程度p(u,i)
2、算法1:

nu,b是用户u打过标签b的次数
nb,i是物品i被打过标签b的次数。
该算法存在的问题:
①给热门标签对应的热门物品很大的权重
因此会造成推荐热门的物品给用户,
不能反应用户个性化的兴趣
从而降低推荐结果的新颖性。
3、算法2:借鉴TF-IDF的思想,区分度
(1)对热门标签惩罚
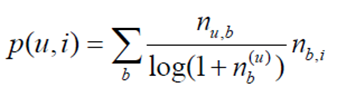
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qFLnIdkg-1624585530173)(file:///C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image026.jpg)]
(2)对热门物品惩罚
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xDE9u3My-1624585530174)(file:///C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image027.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mz7aIl1r-1624585530174)(file:///C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image029.jpg)]
4、算法3:利用标签来设计基于图的推荐算法
①将用户打标签的行为表示到一张图上
②三分图:
用户u,物品i,标签b
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J2NyWjxr-1624585530175)(file:///C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image031.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e62lWWRm-1624585530175)(file:///C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image032.png)]
③构建了SimpleTagGraph
l用户节点指向标签节点
l由标签节点指向物品节点
四、标签推荐
如何在用户给物品打标签时为其推荐适合该物品的标签
(1)UGC标签问题
①标签不专业,不准确
②缺乏标签
(2)标签推荐方法
①PopularTags 用户手工选择
②从物品的内容数据中抽取关键词作为标签
③机器学习方法自动添加
第八讲 上下文感知推荐
一、时间上下文感知推荐
•在给定时间信息后
–推荐系统从一个静态系统变成了一个时变的系统
–用户行为数据也变成了时间序列
1、时间特性的分析(三种角度)
(1)系统的时间特性分析
①数据集每天独立用户数的增长情况。
②系统的物品变化情况
③用户访问情况
(2)时间信息对用户兴趣的影响表现:
①用户兴趣随时间迁移
②物品有生命周期
③季节效应
(3)物品生存周期度量指标
1)物品平均在线天数
2)相隔T天系统物品流行度向量的平均相似度
①计算方法:
取系统中相邻T天的两天,分别计算这两天的物品流行度,从而得到两个流行度向量。
然后,计算这两个向量的余弦相似度。
②如果相似度大,说明系统的物品在相隔T天的时间内没有发生大的变化,从而说明系统的时效性不强,物品的平均在线时间较长。
③如果相似度很小,说明系统中的物品在相隔T天的时间内发生了很大变化,从而说明系统的时效性很强,物品的平均在线时间很短。
2、时间上下文推荐算法
(1)Pop 给用户推荐最近最热门的物品。
1)流行度计算公式

(2)时间上下文相关的ItemCF算法
相似度计算公式和最后的加权求和,都用了时间衰减公式
2)TitemCF
①考虑时间信息
②引入了和时间有关的衰减项
α是时间衰减参数,相似度改变
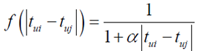
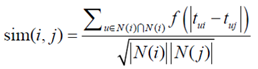
③用户对物品i的兴趣
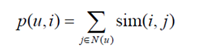
变为:
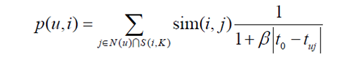

(3)时间上下文相关的UserCF算法
同上:相似度计算公式和最后的加权求和,都用了时间衰减公式
1)核心:
计算用户u和用户v的兴趣相似度
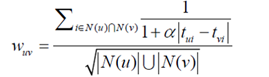
2)推荐
①S(u,K)包含了和用户u兴趣最接近的K个用户。
②如果用户v对物品i产生过行为,那么rvi=1,否则rvi=0

(4)时间段图模型
1)时间段图:是一个二分图
除了有用户和物品节点,每个用户和物品都有对应的时间段,边链接用户和物品时也要链接对应的时间段。
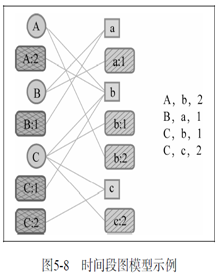
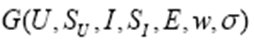
U:用户
S U S_U SU :用户时间段节点集合
I:物品
S I S_I SI:物品时间段节点集合

2)参数设定
①所有边的权重都定义为1
②而顶点的权重定义如下
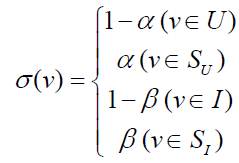
③USGM 物品时间节点权重为0的时间段图模型。
④ISGM 用户时间节点权重为0的时间段图模型。
3)算法目标:
度量图上两个顶点的相关性
4)图上两个相关性比较高的顶点一般具有如下特征
①两个顶点之间有很多路径相连;
②两个顶点之间的路径比较短;
③两个顶点之间的路径不经过出度比较大的顶点
下面的这个算法把上面那三个全考虑到了
5)路径融合算法
权重是路径而言的
①思路:首先提取出两个顶点之间长度小于一个阈值的所有路径。
然后根据每条路径P经过的顶点给每条路径赋予一定的权重
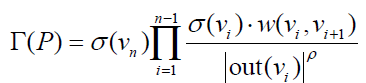
路径越长,越小
路径经过了出度大的顶点,越小
最后将两个顶点之间所有路径的权重之和作为两个顶点的相关度:
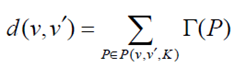
(5)时间变化的隐因子模型time-SVD++
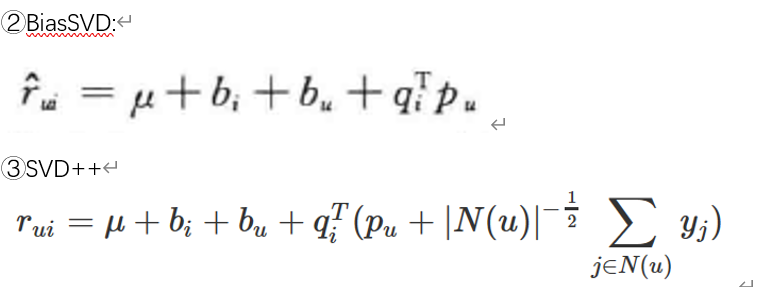
2)SVD 用户兴趣可能随时间变化,改进思路:
评分时间、评分时间区间、特殊期间
①对评分按照时间加权,让久远的评分更趋近平均值。
②对评分时间划分区间,不同的时间区间内分别学习出隐因子向量,使用时按照区间使用对应的隐因子向量来计算。
③对特殊的期间,如节日、周末等训练对应的隐因子向量。
3**)time-SVD++
①分别对待不同的时间视角
l用户的评分偏差bu(评分尺度)随时间变化。
l产品的评分偏差bi(产品流行度)随时间变化。
l用户偏好pu随时间变化。
l产品特征qi与人不同不会随时间变化。
4**)时间变化的基准预测方法*
①基准预测的时序性变化主要体现在两个时间效应上面:
l物品的流行度或许随时间变化
l随着时间变化,用户或许会改变他们的基准评分。
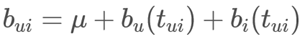
②对物品相关偏置的建模:选择一个相对较粗的时间粒度
l参数分时间段取值
l天数t关联着一个整数Bin(t)
l于是电影偏置就被分为一个固定部分和一个随时间变化的部分
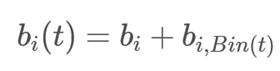
③对用户偏置的建模:需要一个较细的时间粒度,用以发现非常短时间的时间效应
l
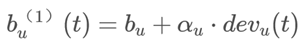
l一个简单的建模选择是使用一个线性函数来模拟用户偏置可能的渐变过程。
需要为每一个用户u学习两个参数:
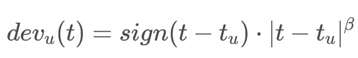
U:用户
Tu:该用户评分的日期

④用户偏好随着时间变化
这种演进通过把用户因子(向量)p(u) 作为时间的函数来建模。
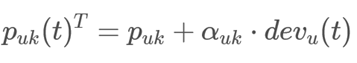
3、推荐算法的时间多样性
(1)定义:
推荐系统每天推荐结果的变化程度被定义为推荐系统的时间多样性。
(2)解决步骤:
①首先,需要保证推荐系统能够在用户有了新的行为后及时调整推荐结果,使推荐结果满足用户最近的兴趣;
②其次,需要保证推荐系统在用户没有新的行为时也能够经常变化一下结果,具有一定的时间多样性。
(3)如何做?
①在生成推荐结果时加入一定的随机性。
②记录用户每天看到的推荐结果,然后在每天给用户进行推荐时,对他前几天看到过很多次的推荐结果进行适当地降权。
③每天给用户使用不同的推荐算法。
随机挑选一种算法给他进行推荐。
二、地理位置感知推荐
1、用户兴趣和地点相关的两种特征
①兴趣本地化
不同地方的用户兴趣存在着很大的差别
②活动本地化
一个用户往往在附近的地区活动。
2.1 地理位置GPS
评分公式引入了一个位置代价
(1)距离度量
①欧式距离
②利用交通网络数据,将人们实际需要走的最短距离作为距离度
(2)推荐公式
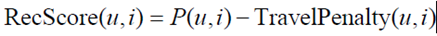
①TravelPenalty(u,i)表示了物品i的位置对用户u的代价。
②为了避免计算用户对所有物品的TravelPenalty
聚类思想:
首先对用户每一个曾经评过分的物品(一般是餐馆、商店、景点),找到和他距离小于一个阈值d的所有其他物品,
然后将这些物品的集合作为候选集,然后再利用上面公式计算最终的RecScore。
2.2 地理位置 --地点名称
位置信息是一个树状结构
给定每一个用户的位置,我们可以将他分配到某一个叶子节点中,
而该叶子节点包含了所有和他同一个位置的用户的行为数据集。
第九讲 Bandit算法与推荐系统
一、强化学习
1、机器学习的分类
有监督学习、无监督学习、半监督学习、增强学习。
2、强化学习的几个概念
(1)Agent:我们的搜索目标,我们需要优化的目标。
(2)Environment:同Agent交互的个体。
几个行为方式:
(1)state:智能体检测到的环境的状况。
(2)reward: 智能体做出一定动作后,环境给它的反馈。即时奖赏和累积奖赏。
(3)Action:智能体根据接收到的奖赏和环境状态做出的行动。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-msSeLhAS-1624585530188)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image002.jpg)]
3、强化学习的定义
①机器学习的范式和方法论之一。
②用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
4、将强化学习纳入到马尔科夫决策过程
①马尔科夫决策过程可以用4元组来描述,根据这些因素是否已知,可以分为基于模型的动态规划方法和基于无模型的强化学习方法如图所示。
②基于模型的强化学习可以利用动态规划的思想来解决。
③在现实的强化学习任务中,环境的这样概率、奖赏函数往往很难得知,甚至很难知道环境中一共有多少的状态。若学习算法不依赖于环境建模,则称为“免模型学习”。比如下棋。
5、强化学习最明显的特征
①强化学习最明显的特征是,使用训练信息来评估采取的行动,而非给出正确行动的指导,这就使得积极的探索十分必要。
②对于一个使用试错行为的搜索:
1)纯粹的评估回馈可以表示行动好的程度,但不能确定是最好还是最坏。
2)纯粹的指导回馈指示要采取的正确行动,却可能与实际采取行动的无关。
这两种回馈截然不同:
1)评估回馈完全依赖于采取的行动,
2)而指导回馈与采取的行动无关,
将两者结合的中间例子:
多臂Bandit问题。
二、bandit算法
1、推荐系统里有两个经典问题
①Exploit( 开拓):对用户比较确定的兴趣,已知金矿当然要开采。
②Explore(探索):不断探索用户新的兴趣。
Bandit算法是一种简单的在线学习算法,常常用于尝试解决这两个问题。
2.1 多臂赌博机问题
①bandit问题就是研究如何使这些奖励最大化。
②bandit问题是一个online问题,我们只能对比算法与最优arm之间的差别,称之为regret。
2.2 bandit算法与推荐系统
推荐系统经典问题本质上都是如何选择用户感兴趣的主题进行推荐。比较符合Bandit算法背后的MAB问题。
1、用bandit算法解决冷启动问题的大致思路
①用分类或者Topic来表示每个用户兴趣,也就是MAB问题中的臂(Arm)。
②可以通过几次试验,来刻画出新用户心目中对每个Topic的感兴趣概率。
-如果用户对某个Topic感兴趣(提供了显式反馈或隐式反馈),就表示我们得到了收益。
-如果推给了它不感兴趣的Topic,推荐系统就表示很遗憾(regret)了。
③如此经历“选择-观察-更新-选择”的循环,理论上是越来越逼近用户真正感兴趣的Topic。
2、E&E算法框架
(1)EE问题,是为了平衡推荐系统的准确性和多样性。
①Exploitation 开发:
l基于已知最好策略,开发利用已知具有较高回报的item(贪婪、短期回报)
l优点:充分利用已知高回报item。
l缺点:陷于局部最优,错过潜在更高回报item的机会。
②Exploration 探索:
l不考虑曾经的经验,勘探潜在可能高回报的item(非贪婪、长期回报)
l优点:发现更好回报的item
l缺点:充分利用已有高回报item机会减少(如已经找到最好item)。
(2)目标:要找到Exploitation & Exploration的trade-off,以达到累计回报最大化。
(3)confidence 置信度
①极端情况下,Exploitation每次选择最高mean回报的item(太“confident”)。
②Exploration每次随机选择一个item(太不“confident”)
两个极端都不能达到最终目标
因此,在选择item时,我们不仅要考虑item的mean回报,同时也要兼顾confidence。
(4)评估指标Regret(遗憾)
①Bandit算法需要量化一个核心问题:错误的选择到底有多大的遗憾?能不能遗憾少一些?
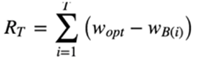
wB(i)是第i次试验时被选中臂的期望收益。
w*是所有臂中的最佳那个
regret公式可以用来对比不同Bandit算法的效果:
对同样的多臂问题,用不同的Bandit算法试验相同次数,看看谁的regret增长得慢。
2.3 常用Bandit算法
2.3.1朴素Bandit算法
(1)算法:
①先对每个item进行一定次数(如100次)选择尝试,计算item的回报率。
②接下来选择回报率高的item。
简单直接
(2)问题:
①item很多导致获取item回报率的成本太大。(计算量大)
②尝试一定次数(如100次)得到的“高回报”item未必靠谱。
item的回报率有可能会随时间发生变化。
2.3.2 ε-Greedy/Epsilon-Greedy算法
(1)算法
①选一个(0,1)之间较小的数ε
②每次决策以概率ε去勘探Exploration,
1-ε的概率来开发Exploitation。
③不断循环下去。
(2)好处
①能够应对变化:如果item的回报发生变化,能及时改变策略,避免卡在次优状态。
②可以控制对Exploration和Exploitation的偏好程度
lε大,模型具有更大的灵活性
能更快的探索潜在可能高回报item,
适应变化,收敛速度更快
lε小,模型具有更好的稳定性
更多的机会用来开发利用当前最好回报的item
收敛速度变慢
(3)问题:
①设置最好的ε比较困难
②策略运行一段时间后,我们对item的好坏了解的确定性增强
l但没用利用这些信息
l仍然花费固定的精力去exploration,会选择到明显较差的item。
l浪费本应该更多进行exploitation机会。
(4)算法的变体
①ε-first strategy:
l首先进行小部分次数进行随机尝试来确定那些item能获得较高回报。
l然后接下来大部分次数选择前面确定较高回报的item。
②ε-decreasing strategy:
lepsilon随着时间的次数逐步降低
l开始的时候exploration更多次数,然后逐步降低ε_t=1/log(itemSelectCnt+0.00001 ))
l增加exploitation比重,Annealing退火-Epsilon-Greedy。
2.3.3 Softmax选择策略
ε-Greedy在探索时采用完全随机的策略,经常会选择一个看起来很差的item
(1)解决方法
①基于我们目前已经知道部分item回报信息,不进行随机决策。
②而是使用softmax决策找出回报最大的item。
(2)softmax策略
①利用softmax函数来确定各item的回报的期望概率排序
②在选择item时考虑该信息,减少exploration过程中低回报率item的选择机会
③同时收敛速度也会较ε-Greedy更快。
2.3.4 Thompson sampling算法
(1)基于贝叶斯思想,全部用概率分布来表达不确定性。
(2)Thompson sampling算法用到了Beta分布
(3)为什么使用beta分布
①使用Beta分布是因为Beta分布是二项分布的共轭先验分布。
②关于Beta-Binomial共轭,意思就是,数据符合二项分布的时候,参数的先验分布和后验分布都能保持Beta分布的形式。
③Beta分布是表示概率的概率分布的最佳方式:我们可能无法提前知道一件事的概率,
但是我们可以做一些合理的猜测。
(4)原理:
①假设每个老虎机都有一个吐钱(收益)的概率p
②同时该概率p的概率分布符合beta(wins, lose)分布
③每个臂都维护一个beta分布的参数,即wins, lose
④每次试验后,选中一个臂,摇一下,有收益则该臂的wins增加1,否则该臂的lose增加1。
⑤不断地试验,去估计出一个置信度较高的“概率p的概率分布”。
(5)Thompson sampling算法选择臂的方式
①用每个臂现有的beta分布产生一个随机数b
②选择所有臂产生的随机数中最大的那个臂去摇。
2.3.5 UCB算法
(1)Upper Confidence Bound(置信区间上界)
①完全不使用随机性的
②除了要考虑收益回报外,还要考虑一点,这个收益回报的置信度有多高。

参数释义:
①第一项是开发,第二项是探索
②第一项,表示期望回报,那就是一个纯利用,也就是贪婪策略,它很容易陷入局部极值。
③第二项可以当做一个测量对臂了解多少的指标。本质上是均值的标准差,了解越少,第二项越大。
④当对于一个臂的了解不够时,它会被选中,即使这个臂的平均回报很低。
(2)UCB公式反映了一个特点
①均值越大,标准差越小,被选中的概率会越来越大,
②同时哪些被选次数较少的臂也会得到试验机会。
(3)算法步骤:
①初始化:先对每一个臂都试一遍;
②计算每个臂的分数,然后选择分数最大的臂作为选择。
③观察选择结果,更新n和nj。
(4)UCB解决Multi-armed bandit问题的思路是
①用置信区间
②置信区间可以简单地理解为不确定性的程度
③区间越宽,越不确定
(5)每个item的回报均值都有个置信区间,随着试验次数增加,置信区间会变窄(逐渐确定了到底回报丰厚还是可怜)。
(6)每次选择前,都根据已经试验的结果重新估计每个Item的均值及置信区间。
(7)选择UCB最大的那个Item
①如果Item置信区间很宽(被选次数很少,还不确定),
那么它会倾向于被多次选择,这个是算法冒风险的部分
②如果Item置信区间很窄(备选次数很多,比较确定其好坏了),那么均值大的倾向于被多次选择,这个是算法保守稳妥的部分;
(8)UCB是一种乐观的算法,选择置信区间上界排序,
如果是悲观保守的做法,是选择置信区间下界排序。
三、Bandit算法与线性回归
3.1 LinUCB 算法
(1)linUCB算法做了一个假设
①一个Item被选择后推送给一个User
②其回报和相关Feature成线性关系,“相关feature”就是context,也是实际项目中发挥空间最大的部分。
(2)试验过程
①用User和Item的特征预估回报及其置信区间
用线性回归
②选择置信区间上界最大的item推荐。
③观察回报后更新线性关系的参数。
④以此达到试验学习的目的。
(8)LinUCB算法
①在每次选择Item之前,通过Feature预估每一个arm(item)的期望回报及置信区间。
②选择的收益就可以通过Feature泛化到不同的Item上
(9)优点:
①解决了UCB等MAB算法context-free的问题,
考虑到用户的特征和物品的特征
②计算复杂度同arm的数量成线性关系
③支持动态变化的候选arm集合,
有新的arm出来时,实时支持对新的arm进行初始化,并添加到分数选取中。
④在线学习
l在计算arm的参数和recommend的时候,用到了上下文的特征+用户反馈。
l每次信息都进行了保存更新到A和b中。
lA和b可以异步增量更新。
3.2 Linucb算法的特征构建
(1)LinUCB算法的重要的步骤:
l就是给User和Item构建特征
l也就是刻画context。
(2)目标
l对原始特征降维,
l模型要能刻画一些非线性的关系
四、Bandit结合协同过滤
(1)基本思想:
①每一个推荐候选Item,都可以根据用户对其偏好不同(payoff不同)将用户聚类成不同的群体,一个群体来集体预测这个Item的可能的收益,这就有了协同的效果。
②然后再实时观察真实反馈回来更新用户的个人参数,这就有了Bandit的思想在里面。
(3)COFIBA算法
①与LinUCB不同,COFIBA算法的不同有两个
l基于用户聚类挑选最佳的Item(相似用户集体决策的Bandit)。

l基于用户的反馈情况调整User和Item的聚类(协同过滤部分)。
第十讲 因子分解机
一、召回
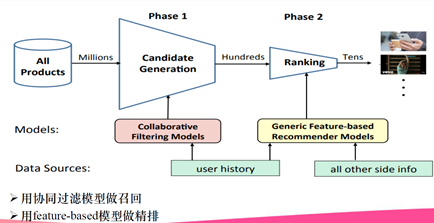
1、什么是召回
(1)召回是推荐系统的第一阶段
①主要根据用户和商品部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节。
(2)这部分需要处理的数据量非常大,速度要求快
(3)所有使用的策略、模型和特征都不能太复杂。
2、现代推荐系统框架
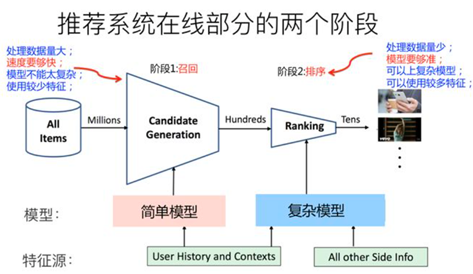
3、推荐系统在线部分的两个阶段
4、推荐系统的四个环节
(1)召回
①主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节。
②排序环节可以融入较多特征,使用复杂模型,来精准地做个性化推荐。
③召回强调快,排序强调准。
(2)粗排
①有时候因为每个用户召回环节返回的物品数量还是太多,怕排序环节速度跟不上,所以可以在召回和精排之间加入一个粗排环节。
②通过少量用户和物品特征,简单模型,来对召回的结果进行个粗略的排序。
③在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的,可用可不同,跟场景有关。
(3)精排
①使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽量精准地对物品进行个性化排序。
(4)重排
①往往会上各种技术及业务策略,
②比如去已读、去重、打散、多样性保证、固定类型物品插入等等,
③主要是技术产品策略主导或者为了改进用户体验的。
5、多路召回
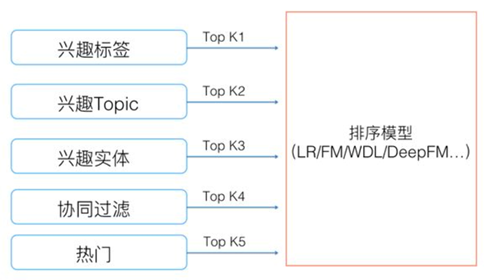
5、四种常见的召回方法
①基于内容的召回
②协同过滤
③基于FM模型召回
④基于深度神经网络的方法
二、基于内容的的召回
1、基于内容的推荐CB
算法的三个步骤
①Item Representation
为每一个item抽取一些特征属性出来,也就是结构化物品的描述操作。
②Profile Learning
③Recommendation Generation
2、基于内容的召回
(1)核心思想:
基于item自身的属性,这些属性可以表达tag,cate,用户id,用户类型等,更可以通过⼀些交叉验证的⽅式,针对内容提取向量,将内容表达为连续向量的方式进行召回。
(2)优点
①不需要其他用户的任何数据,因为推荐是针对该用户的。 这使得更容易扩展到大量用户。
②可以捕获用户的特定兴趣。
(3)缺点:
①模型很依赖手工设计特征的好坏
需要大量领域知识。
②扩展用户现有兴趣的能力有限。
③如果item属性很多,还会需要利用检索的方式,去提升CB的效果。
倒排表结构。
(4)多维度内容属性,多term的问题
解决方案:
①通过设置每个term的权重,可以在返回结果⾥去得到包含多term的结果。
②直接使用word2vec。用户身上有多个标签,内容上面也有多个标签
把用户标签和内容标签作为⼀个sentence训练,
离线把内容的标签加和表征为内容的属性向量,在线做召回即可。
三、基于协同过滤的召回
(1)优点:
①无需领域知识
②发掘用户兴趣:
相似的用户有着相同的兴趣点。
③很好的初始模型:
在某种程度上,该方法仅需要反馈矩阵即可训练矩阵分解模型。
而且该方法不需要上下文特征。
实际上,该方法可以用作多个召回队列中的一个。
(2)缺点:
①冷启动问题
②难以融入query/item的附加特征
(3)冷启动问题
①利用WALS进行预测。
l加权交替最小二乘(WALS)
随机初始化Embedding,然后在以下条件之间交替进行:
固定U 求解V 。
固定V 求解U 。
l给定一个在训练集中未出现的item,如果系统与用户有一些交互,则系统可以很容易计算出该item的Embedding。
用户Embedding保持固定,系统求解item的Embedding。
②启发式生成新item的Embedding
如果系统没有相应的交互信息,则系统可以通过对来自同一类别,来自同一上传者(在视频推荐中)的item的Embedding进行平均来近似其Embedding。
四、因子分解机
基于内容的推荐/基于特征的推荐
1、推荐系统中的特征工程
(1)最简单的线性拟合
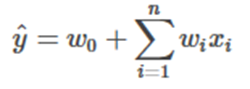
(2)特征组合
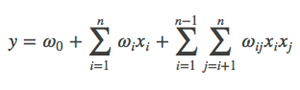

(3)one-Hot编码带来的问题
①样本的数据变得很稀疏
②样本空间变大
(4)特征组合带来的问题
①特征之间两两组合容易导致维度灾难;
②组合后的特征未必有效,可能存在特征冗余现象
③在稀疏场景下,二次项的训练是很困难的。
l因为要训练wij ,需要有大量的xi和xj都非零的样本(只有非零组合才有意义)。
l而样本本身是稀疏的,满足xi和xj都非零的样本会非常少,样本少则难以估计参数wij ,训练出来容易导致模型的过拟合。
2、FM模型
五、矩阵分解和FM
六、基于FM模型的召回
七、FM的特点
1、特点
(1)功能齐全
①FM这样实现三个领域全覆盖:召回、粗排、精排
②FM对新用户、新物料也非常友好
③是主力召回模型
④可解释性强
lFM将模型的最终打分拆解到每个特征和特征组合上,
l能够分析出到底是哪些因素提高或拉低了模型的打分
l区别于GBDT那种只能提供特征的全局重要性,FM提供的重要性是针对某一个、某一群样本的,使我们能够做更加精细化的特征分析。
(2)性能优异
①FM存在一阶项,实际就是LR,能够记忆高频、常见模式
②FM通过feature embedding,能够自动挖掘低频、长尾模式。
在这一点上,基于embedding的二阶交叉,并不比DNN的高阶交叉,逊色多少。
(3)便于上线
①模型越复杂,离线和线上指标未必就更好,但是线上的时间开销肯定会增加。
②超时严重的时候,你那离线指标完美的模型压根没有上线的机会。
③FM模型,时间复杂: O(kn)
八、FM实战技巧
1、FM精排
2、FM召回
3、FM可解释性
(1)模型解释性
①GBDT那种只能提供特征的全局重要性
②FM能够提供针对一个或一群样本上的“局部特征重要性”
l分析出该样本的每个特征对该样本预测得分的贡献
l可以按性别、年龄筛选出不同用户的消费样本,“局部特征重要性”能够告诉我们,影响某一类用户消费的正负向因素
l我们专门筛选出那些false positive/false negative的bad case,看看哪些特征的表现不如预期,导致预测失败
③FM将最终预测得分,拆解到各feature和feature组合上。
l针对每一个样本,
feature embedding按所属field分组,
同一field下所有feature embedding相加得到field embedding,
两两field embedding做点积。
将样本得分拆解到了field和field pair的维度上。
l选取一组样本进行得分拆解,然后将这组样本在各个field pair上的得分进行统计,比如绘制热力图,就能看出哪些field pair对这组样本至关重要。
第11讲 FM家族
一、FFM模型
1、什么是FFM模型
(1)场感知分解机
(2)FM的升级版模型。通过引入field的概念
(3)场感知
①隐向量不仅与特征相关,也与field相关
②FFM把相同性质的特征归于同一个field
③在FFM中,每一维特征 xi ,针对每一种field fj ,都会学习一个隐向量Vi,fj 。
④因此,隐向量不仅与特征相关,也与field相关。这也是FFM中“Field-aware”的由来。
2、FM模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Bnk5kkFm-1624585530194)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image002.jpg)]
①是根据对应两个特征的Embedding向量(隐向量)内积,来作为这个组合特征重要性的指示。
②当训练好FM模型后,每个特征都可以学会一个特征embedding向量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tomsXqLS-1624585530195)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image004.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I6bIIQuw-1624585530195)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image006.jpg)]
③和不同特征/字段 组合ESPN都用同一个隐向量
ESPN+Nike
ESPN+Male
3、FFM
(1)Vespn这个特征
①和属于Advertiser这个域的特征进行组合的时候,用一个特征embedding。
②和属于Gendor这个特征域的特征进行组合的时候,用另外一个特征embedding。
(2)这意味着,如果有F个特征域,那么每个特征由FM模型的一个k维特征embedding,拓展成了(F-1)个k维特征embedding。
之所以是F-1,而不是F,是因为特征不和自己组合,所以不用考虑自己。
(3)例子
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aFkTQIlt-1624585530196)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image008.jpg)]
4、FM和FFM模型的区别
(1)FFM模型比FM模型笨重
(2)假设模型具有n个特征,
①FM模型的参数量是n*k(暂时忽略掉一阶特征的参数),其中k是特征向量大小。
②FFM模型的参数量是(F-1)nk,每个特征具有(F-1)个k维特征向量。
③参数量比FM模型扩充了(F-1)倍。
④现实任务中,特征数量n是个很大的数值,特征域几十上百也很常见。
(3)FM模型可以通过公式改写,把复杂度从O(n2) ,降低到 O(kn)。
FFM无法做类似的改写,所以它的计算复杂度是O(kn2)。
(4)FFM模型参数量太大,所以在训练FFM模型的时候,很容易过拟合,
需要采取早停等防止过拟合的手段。
(5)根据经验,FFM模型的k值可以取得小一些
①一般在几千万训练数据规模下,取8到10能取得较好的效果,
②当然,k具体取哪个数值,这其实跟具体训练数据规模大小有关系,
③理论上,训练数据集合越大,越不容易过拟合,这个k值可以设置得越大些。
二、FFM做召回模型
1、简单版FFM召回模型
(1)构建用户Embedding以及物品Embedding
(2)希望通过FFM模型来做用户任意特征和物品任意特征的组合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1v0X7hyy-1624585530196)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image010.jpg)]
规律就是<Uij,Iji>
lItem特征重排序,然后flattern成一维向量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K7x5mUTP-1624585530197)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image012.jpg)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bwsnlEMk-1624585530198)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image014.jpg)]
l两个拉长版本的User Embeding和Item Embedding,通过Faiss内积计算,最后的得到匹配分数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sxaCyv44-1624585530199)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image016.jpg)]
embedding向量的长度 size=MNK
M:用户侧特征域个数
N:物品侧特征域个数
K:特征长度
2、加入用户侧及物品侧内部特征组合
①用户侧或者物品侧内部的两两特征组合
Score(User_i*User_j)
Score(Item_i*Item_j)
②embedding后添加两位
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l55js5Ba-1624585530199)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image018.jpg)]
理论上来说:
①如果是只用FM/FFM模型做召回,用户侧内部的特征组合对于返回结果排序没有影响,所以可以不用加入。
②物品侧内部特征之间的特征组合可能会对返回的物品排序结果有影响,可以考虑引入这种做法,把它统一加进去。
③如果是希望用FM/FFM模型一阶段地替代掉“多路召回+Ranking”的两阶段模式,则可以考虑完全复现FM/FFM模型,如此,应将两侧的内部特征组合都考虑进去。
3、加入一阶项
(1)方法一
在用户侧的embedding中增加两位,第一位是属于用户特征域的特征对应的一阶项累加和。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nEuaWgSn-1624585530200)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image020.jpg)]
-
(2)方法二
- 直接将用户侧及物品侧对应特征的一阶权重拼接到二阶项的embedding后。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jotPtGKN-1624585530200)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image022.jpg)]
4、加入场景上下文特征
(1)上下文特征动态性强
①用户在每一次刷新可能都需要重新捕获当前的特征值。
②不太可能像用户特征离线算好存起来直接使用的。
(2)场景特征——根据用户和物品分拆特征
①假设只有一个Context特征
②对应了(6-1)=5个embedding向量
③其中2个是用于和用户侧特征进行组合的,3个是用于和物品侧特征进行组合的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oOH7ZyIs-1624585530200)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image024.jpg)]
(3)场景特征→用户特征组合
内积数值代表用户特征和上下文特征的二阶特征组合得分
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NHdJ2x6S-1624585530201)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image026.jpg)]
(4)场景特征→物品特征组合
①通过内积方式取出Top K物品。
②同时考虑到了用户和物品的特征组合<U,I>,以及上下文和物品的特征组合<C,I>。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zmuyWcQa-1624585530201)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image028.jpg)]
5、并行拉取提速策略
(1)为什么要提速
①embedding向量的长度 size=MNK
②embedding长度太长,这会导致Faiss提取速度变慢
③减小embedding长度的方法
把k值往小放,比如k=2或者4
如果只是使用FFM模型做召回,这个策略是可行的,反正召回阶段不用特别准
把特征域数量降下来。
(2)优化想法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HcvEjR3t-1624585530202)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image030.jpg)]
①把太长的用户embedding打断成连续片段,
②物品embedding也相应地打断,同一个物品的embedding片段分别存在不同的Faiss数据库中,这样由于减少了embedding的长度,所以会极大加快Faiss的提取速度。
③在结果返回时,对每个User Embedding片段拉回的Item子集合进行合并。
④同一个物品,把各自的片段内积得分累加,就得到了这个物品相对用户的FFM最终得分。
⑤这是一种典型的并行策略
⑥理论上,这个方案能够处理相当长的embedding匹配问题。
(3)上述方法存在的问题
①并不能保证返回结果的最终排序和真实排序是一致的。
因为有可能某个综合总得分较高的物品没有被从任何一个Faiss子数据库拉回来,
比如这个物品每个片段的得分都不太高也不太低的情况,
是可能发生这种漏召回的情况的。
三、FM模型的神经网络表示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A4KoVMy9-1624585530202)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image032.jpg)]
(1)模型输入
x=[x field 1 ,x field 2 ,⋯,x field m ]
①d维向量
②其中x field i 即为第i个field的特征表示,
③如果是类别,则为one-hot编码后的向量,
④连续值则为它本身
(2)然后对每个field分别进行embedding
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-91hDchdi-1624585530203)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image034.jpg)]
①即使各个field的维度是不一样的,但是它们embedding后长度均为k。
②embedding层表示和fm模型等价
(3)接着FM层即为embedding后结果的内积和一次项的和,
(4)最后一层sigmoid后再输出结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XobjwIv3-1624585530203)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image036.jpg)]
四、深度FM模型
(1)推演的核心思路
通过设计网络结构进行组合特征的挖掘。
①从FM开始推演其在深度学习上的各种推广(对应下图的红线)
②从embedding+MLP自身的演进特点结合CTR预估本身的业务场景进行推演
神经网络:多层感知器-MLP
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aj3jVB3V-1624585530204)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image038.jpg)]
(2)背景
①由于计算复杂度等原因,FM通常只对特征进行二阶交叉。
当面对海量高度稀疏的用户行为反馈数据时,二阶交叉往往是不够的,
三阶、四阶甚至更高阶的组合交叉能够进一步提升模型学习能力。
②如何能在引入更高阶的特征组合的同时,将计算复杂度控制在一个可接受的范围内?
1、FNN
(1)什么是FNN
①FNN(Factorization Machine supported Neural Network)模型
参考图像领域CNN通过相邻层连接扩大感受野的做法。
②使用DNN来对FM显式表达的二阶交叉特征进行再交叉,从而产生更高阶的特征组合,加强模型对数据模式的学习能力 。
③Embeding+MLP:神经网络:多层感知器-MLP。
(2)思想:
①FNN的思想比较简单,直接在FM上接入若干全连接层。
②利用DNN对特征进行隐式交叉,可以减轻特征工程的工作,同时也能够将计算时间复杂度控制在一个合理的范围内。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zGo7iyZS-1624585530204)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image039.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gClItUMa-1624585530205)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image041.png)]
(3)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q2KK99mS-1624585530205)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image043.jpg)]
为了加速模型的收敛,充分利用FM的特征表达能力,FNN采用了两阶段训练方式:
①首先,针对任务构建FM模型,完成模型参数的学习。
②然后,将FM的参数作为FNN底层参数的初始值。
③这种两阶段方式的应用,是为了将FM作为先验知识加入到模型中,防止因为数据稀疏带来的歧义造成模型参数偏差。
(4)FNN特点
l优点:
①引入DNN对特征进行更高阶组合,减少特征工程,
②能在一定程度上增强FM的学习能力。
l缺点:
①两阶段训练模式,在应用过程中不方便,且模型能力受限于FM表征能力的上限。
②FNN专注于高阶组合特征,但是却没有将低阶特征纳入模型。
(5)这种两阶段训练的方式,存在几个问题:
①FM中进行特征组合,使用的是隐向量点积。将FM得到的隐向量移植到DNN中接入全连接层,全连接本质是将输入向量的所有元素进行加权求和,且不会对特征Field进行区分,
l也就是说FNN中高阶特征组合使用的是全部隐向量元素相加的方式。
l说到底,在理解特征组合的层面上FNN与FM是存在Gap的,而这一点也正是PNN对其进行改进的动力。
②在神经网络的调参过程中,参数学习率是很重要的。况且FNN中底层参数是通过FM预训练而来,如果在进行反向传播更新参数的时候学习率过大,很容易将FM得到的信息抹去。
l个人理解,FNN至少应该采用Layer-wise learning rate,底层的学习率小一点,上层可以稍微大一点,在保留FM的二阶交叉信息的同时,在DNN上层进行更高阶的组合。
2、DeepFM
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-atL91Lq7-1624585530206)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image044.jpg)]
(1)模型结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XBvvpkGC-1624585530206)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image046.jpg)]
①左边:FM模型的神经网络表示
②右边: 为deep部分,为全连接的网络,用于挖掘高阶的交叉特征。
③整个模型共享embedding层,
④最后的结果就是把FM部分和DNN的部分做sigmoid
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j351rGHc-1624585530207)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image048.jpg)]
(2)DeepFM目的是同时学习低阶和高阶的特征交叉,主要由FM和DNN两部分组成,底部共享同样的输入。
(3)并行结构
①FM部分和DNN部分分开计算,只在输出层进行一次融合得到结果
②DeepFM
3、FM和深度网络DNN的结合
(1)并行结构
①FM部分和DNN部分分开计算,只在输出层进行一次融合得到结果。
②DeepFM
③
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qVHbvLbB-1624585530207)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image050.jpg)]
④它在特征预处理或者构造方面不需要人为的做更多操作。
直接将类别型特征进行one-hot处理,
对于数值型特征直接保留原始数值。
⑤然后直接将类别型特征的embedding和数值型特征concat在一起,作为Cross Net和Deep Net的输入。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6HKKRelQ-1624585530208)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image052.jpg)]
(2)串行结构
①将FM的一次项和二次项结果(或其中之一)作为DNN部分的输入,经DNN得到最终结果。
②[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N1q534uG-1624585530208)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image054.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KmFzmZHS-1624585530209)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image056.jpg)]
第十二讲 社交网络分析
1、什么是社交网络
①由许多节点构成的一种社会结构。
②节点通常是指个人或组织
③社交网络代表着各种社会关系。
2、社交网络特点:
迅捷性、蔓延性、平等性与自组织性
3、社交网络分析 SNS的目的
利用好社交网络的特性,产生价值,消除危害。
4、SNS是一种基于信息学、数学、社会学、管理学和心理学等科学的交叉科学。
5、其主要研究的三大内容
①社交网络的结构特性与演化机理
②社交网络群体行为形成与互动规律
③社交网络信息传播与演化机理
一、社交网络的特性和演化机理
1、社交网络结构分析与建模
1、1 统计特性
(1)度:
①与该节点相连的边的数目。
②有向图中入度,出度,代表关注和粉丝
③而通过度分布则可以刻画不同节点的重要性。
④网络平均度反应了网络的疏密程度。
(2)网络密度
①网络中实际存在边数与可容纳边数上限的比值(编者:完全图吗)
②用于刻画节点间相互连边的密集程度,
③常用来测量社交网络中社交关系的密集程度及演化趋势。
(3)聚类系数**(Clustering Coefficient)**
①用于描述网络中与同一节点相连的节点间也互为相邻节点的程度。
②其用于刻画社交网络中一个人朋友们之间也互相是朋友的概率,
③反应了社交网络中的聚集性。
(4)介数
①为图中某节点承载整个图所有最短路径的数量。
②通常用来评价节点的重要程度,
连接不同社群之间的中介节点的介数相对于其他节点来说会非常大
③也体现了其在社交网络信息传递中的重要程度。
1.2 网络特性
(1)小世界现象
①指地理位置相距遥远的人可能具有较短的社会关系间隔。
②六度分割理论
(2)无标度特性
①节点度分布不存在有限衡量分布范围的性质。
②度分布特征为幂律分布
大多数节点有少量边,少数节点有大量边。
2、虚拟社区(社团)及发现技术
(1)虚拟社区基于子图局部性的定义
①社区结构是复杂网络节点集合的若干子集
②每个子集内部的节点之间的连接相对非常紧密。
③而不同子集节点之间的连边相对稀疏。
(2)在社交网络中发现虚拟社区有助于
①理解网络拓扑结构特点
②揭示复杂系统内在功能特性
③理解社区内个体关系。
④为信息检索、信息推荐、信息传播控制和公共事件管控提供有力支撑。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vMJ7VIpc-1624585530209)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image002.jpg)]
(3)社区发现算法
①用来发现网络中的社区结构
②也可以视为一种广义的聚类算法。
③许多经典的算法。
(4)社区发现算法有哪些
①GN算法
②Louvain 算法
③Label Propagation 标签传播算法
④随机游走算法
2.1 GN算法
(1)什么是GN算法
①GN算法相当于是一棵自顶向下的层次树,划分社区就是层次分裂的过程。
②计算网络中所有边的介数(Betweeness)
介数为图中某节点承载整个图所有最短路径的数量
③找到介数最高的边,并将它从网络中移除
④重复以上步骤,直到每个节点就是一个社区为止。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DEiLWbbQ-1624585530210)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image004.jpg)]
2.2 Louvain 算法
基于模块度的算法,其优化目标就是最大化整个社区网络结构的模块度
(1)什么是模块度
①社区内节点的连边数与随机情况下节点的连边数之差,
②它可以衡量一个社区紧密程度的度量。
(2)算法思想
①不断遍历网络中的节点,尝试把单个节点加入能使模块度提升最大的社区,直到所有节点不再改变。
②将第一阶段形成的一个个小的社区并为一个节点,重新构造网络。
这时边的权重为两个节点内所有原始节点的边权重之和。
③重复以上两步
2.3 Label Propagation 标签传播算法
一种基于图的半监督学习方法
(1)基本思路:
①用已标记节点的标签信息去预测未标记节点的标签信息。
②利用样本间的关系建立关系完全图模型
(2)算法基本理论
①每个节点的标签按相似度传播给相邻节点。
②在节点传播的每一步
l每个节点根据相邻节点的标签来更新自己的标签。
l与该节点相似度越大,其相邻节点对其标注的影响权值越大,相似节点的标签越趋于一致,其标签就越容易传播。
l在标签传播过程中,保持已标注数据的标签不变,使其像一个源头把标签传向未标注数据。
③最终,当迭代过程结束时
l相似节点的概率分布也趋于相似,可以划分到同一个类别中。
l从而完成标签传播过程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pOloxeHJ-1624585530210)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image006.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CBMCOJrM-1624585530211)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image008.jpg)]和上面不太一样
(3)SLPA:LPA的扩展
1)重叠式社区检测
2)算法基本思想
①给每个节点设置一个list存储历史标签。
②每个speaker节点带概率选择自己标签列表中标签传播给listener节点。(两个节点互为邻居节点)。
③节点将最热门的标签更新到标签列表中
④使用阀值去除低频标签,产出标签一致的节点为社区。
2.4 随机游走算法
(1)什么是随机游走
从一个顶点向下一个顶点移动时,以相等的概率来选择当前顶点的一个邻居作为下一个顶点。
(2)随机游走算法的基本思想
①社团是相对比较稠密的子图,
②因此在图中进行随机游走时很容易“陷入”一个社团中。
(3)WalkTrap算法:随机游走中的一个经典算法
(4)随机游走的过程构成了一个Markov链
①图中每一个顶点对应一种状态
②不同状态之间的转移概率 :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vlJbuwj6-1624585530211)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image009.png)]
矩阵形式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ievg6IkA-1624585530212)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image010.png)]
A是邻接/相似度矩阵、
D是度矩阵,dj是j的度
t 步随机游走从 i 到 j 的概率是 Pij 的t次幂,表示为Ptij。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OaY08KXf-1624585530212)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image012.jpg)]
(5)随机游走中的一个经典算法,叫做WalkTrap算法。
1)定义一些距离
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2QxH0s79-1624585530212)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image014.jpg)]
2)算法步骤:
①每一个点当做一个社区,计算相邻的点(社团)之间的距离。
②选取使得下式最小的两个社团C1和C2 合并为一个社团
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-33go4j8c-1624585530213)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image016.jpg)]
③重复Step2直到所有点合并为一个社团。
3、虚拟社区演化分析
(1)虚拟社区的涌现
①虚拟社区涌现即在社交网络中虚拟社区从无到有的过程
②其最重要的特征是网络聚集现象。
③周期闭包
④偏好连接
(2)什么是周期闭包
①所谓周期闭包,是指网络节点倾向于和自己在网络中邻居的邻居建立连接关系而形成的结构。
②该机制是导致虚拟社区形成的主要因素。
③实验表明三元闭包的出现概率随着两个节点之间测地距离的增减呈指数递减。
④相反地,焦点闭包和测地距离无关,其生成原因是两个节点之间有共同的兴趣或参与共同的活动。
(3)什么是偏好连接
真实网络中,新增加的边并不是随机连接的,而是倾向于和具有较大度数的连接。
(4)虚拟社区演化的影响因素
①用户个体的累积效应
②结构多样性
③结构平衡性
二、社交网络群体行为形成与互动规律
1、用户行为分析
(1)什么是用户采纳和忠诚
①采纳某种社交网络服务(SNS)的意愿和行动
②使用SNS之后,能够继续保持使用的习惯
(2)用户个体使用行为有哪些?
①使用SNS之后,能够继续保持使用的习惯。
②内容创建行为:
③内容消费行为:
(3)内容创建行为
①用户在社交网络通过写博客微博,发帖评论等行为产生内容。
②主要研究
创建内容的动机、
创建内容时的主题选择偏好以及内容创建时的语言表述等。
关于主题,可通过搜索引擎搜索 LDA 模型。
(4)内容消费行为
①被动消费即“浏览”,社交网络中高达92%的行为都是浏览行为。
②主动消费即社交搜索,例如搜索朋友的信息以及向社交圈内好友提问等等。
(5)用户群体互动行为
①群体互动关系选择:
l识别用户之间的关系
l通过制定不同的衡量指标,研究用户之间的关系强弱。
②群体互动的内容选择
l社交网络中用户对内容选择与其社交关系密不可分。
l例如,两位维基百科编辑在互动前后产生的编辑内容的相似性有所不同。
③群体互动的时间规律
l分析行为发生的时间间隔分布
l在线社交网络中用户行为时间间隔分布不同于传统的负指数分布,而是呈现幂律分布,即具有“长尾效应”。
l应用:地点性质确定
2、社交网络情感分析
(1)情感分析,在此等同于意见挖掘,是针对主观性信息进行分析、处理和归纳过程。
(2)并在产品评论、舆情监控、信息预测等多个领域发挥着重要的作用。
2.1 文本情感分析技术
(1)词语级情感分析
①基于语义规则的情感分析技术:
l带有感情的形容词和副词提取出来构成一个情感词典
正向 中性 负向
l计算评价词和情感词典中已经标注倾向性词语的距离
—利用词典中的近义、反义关系以及词典的结构层次,
—利用统计信息,计算词语与正、负极性种子词汇之间的语义关联度
②基于机器学习的分析方法
l让分类模型学习训练数据中的规律,然后用训练好的模型对测试数据进行预测。
(2)基于语义规则的情感分析技术
①最经典的算法是是 SO-PMI 算法
②点互信息算法(PMI)
l统计两个词语在文本中同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9uaRh8r8-1624585530213)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image018.jpg)]
③情感倾向点互信息算法(SO-PMI)
l选用一组褒义词(Pwords)跟一组贬义词(Nwords)作为基准词。
l一个词语word1跟Pwords的点间互信息减去word1跟Nwords的点间互信息会得到一个差值。
l根据该差值判断词语word1的情感倾向。
(3)文档级情感分析
计算文档中词语情感分数
1)基于监督学习的情感分析方法:
l人工标注文本的情感极性,作为训练集
l通过机器学习的方法对目标文本进行情感分类
l常用方法:朴素贝叶斯,支持向量机。
2)基于话题模型的情感分析技术:
lPLSA (Probabilistic Latent Semantic Analysis)
lLDA (Latent Dirichlet Allocation) 模型
2.2 社交网络情感分析技术
(1)社交网络情感分析技术有哪些?
①面向短文本的情感分析技术:
②基于群体智能的情感分析技术:
l用户在社交网络中表达意见会受到其社交关系的影响
l情感会沿着社交关系进行传播
l因此可以通过研究社交用户之间的关系来提高情感分析的准确度。
③社交网络的垃圾意见挖掘技术:
包括水军与广告等信息
3、个体影响力分析
(1)影响力计算的方式
①基于网络结构计算节点的影响力
②基于行为的个体影响力计算
③基于话题的个体影响力计算
(2)基于网络结构计算节点的影响力
1)
l中心度:表示一个节点在网络中处于核心地位的程度
l四种中心性的分析方法:
①度中心度:
与该节点直接相连的节点的数量
在有向图中,既可以利用入度(声望)或出度(合群性),也可以将两者之和作为度中心值
②介数:间接中心性
衡量某节点在社交网络中中介作用大小。
网络中某两个节点所有最短路径的数量除以这些路径中经过 A 节点路径的数量便是 A 节点的介数,也叫中间中心度。、
间接中心性高,节点对于其他节点信息传播的控制能力
③接近中心度 (Closeness Centrality):
节点与网络中所有其他节点的最短距离之和
节点离其他节点越近,那么他传播信息的时候也就越不需要依赖他人
④特征向量中心性(eigenvector centrality)
—节点的重要性也取决于其邻居节点的重要性
—与重要的节点连接的节点更重要,有少量有影响的联系人的节点其中心性可能超过拥有大量平庸的联系人的节点。
—计算:
1、计算图的成对临近矩阵的特征分解
2、选择有最大特征值的特征向量
3、第i个节点的中心性等于特征向量中的第i元素
PageRank算法是特征向量中心性的一个变种。
(3)基于行为的个体影响力计算
①社交网络中用户的行为决定用户的影响力
②基于这些行为特征构建多种网络关系图,可通过随机游走等方法发现网络中的影响力个体。
(4)基于话题的个体影响力计算
①在社交网络中用户在不同话题下的影响力不同
②可以根据用户的关注网络和用户兴趣相似性来计算用户在每个话题上的影响力。
4、群体聚集及影响机制分析
(1)群体极化
在群体决策的情境中,个体意见或决定往往会受到群体间的彼此讨论的影响,而产生一个群体性的结果。
(2)群体极化的条件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pqkUFmeG-1624585530214)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image020.jpg)]
(3)研究群体极化主要的分析模型
①基于博弈论和委托—代理理论的从众行为模型
②基于信息瀑的群体一致性模型
③基于元胞自动机群决策和行为仿真。
三、社交网络信息传播与演 化机理
1、在线社交网络信息检索
1.1 社交网络内容搜索
内容检索建模,两种主要的方法:
(1)时间先验方法
①语料库中的文档具有不同的重要性,考虑语料库背景定义不同的计算公式,再将计算结果用于检索模型以期得到更好的检索效果的一种检索方法。
②目前考虑时间信息计算文档先验的研究工作可分为两种:
定义文档的时间变化关系;
修改 PageRank 的方法,在其中加入时间关系。
(2)多特征组合方法
①组合多个微博特性来检索微博内容。
②微博个数,关注数,粉丝数,微博长度,微博是否含有外链。
1.2 社交网络推荐
2、社交网络信息传播规律
(1)什么是社交网络信息传播模型
①描述信息传递过程
②多数模型认为信息由源(或种子)节点集开始传播,其他节点只能通过源(或种子)节点集的邻近节点获得信息。
③进行预测
l通过评估用户带来的影响,可以识别出有影响力的传播者(influential spreaders)、找到专家。
l影响力最大化 营销
l根据已经观察到的受影响的节点,推测出源节点,即进行信息源检测(information source detection)。
2.1 基于网络结构的传播模型
(1)线性阈值模型( Linear Threshold)
lLT模型
l如果一个结点 v 要被激活的话,必须当结点v 的入度权重之和达到阈值。
(2)独立级联模型( Independent Cascade)
lIC模型
l在时间 t−1 激活的结点在时间 t 试图去激活未被激活的邻居结点,成功感染的概率是P(u,v)
(2)基于群体状态的传播模型
①传染病模型(SI, SIS, SIR),传染病模型是经典的信息传播模型,描述传播过程,分析感染人群变化规律,预测传染病高潮。
②SI 模型( 模型2)
l疾病传播期内所考察地区的总人数N不变,即不考虑生死,也不考虑迁移。
l人群分为易感染者(Susceptible)和已感染者(Infective)两类(取两个词的第一个字母,称之为SI模型)
l每个病人每天有效接触的平均人数是常数,称为日接触率 λ
l当病人与健康者接触时,使健康者受感染变为病人。
③SIS模型
治愈后变健康者,可能继续 被传染
④SIR模型
人群分为健康者、病人和病愈免疫的移出者(Removed)三类
⑤SEIR模型
E 潜伏者
(3)基于信息特性的传播模型
①在线社交网络中的信息承载着用户网上活动的所有记录,在信息传播分析时起着不可或缺的重要作用。
②信息本身也具有一些特性,
时效性,
主体多样性,
多源触发,
信息合作与竞争等。
③依据这些特征,可建立不同的模型
3、话题发现与演化
(1)什么是话题
话题是指一个引起关注的事件或活动,及其所有相关事件和活动。
其中,事件或者活动是指在一个特定的时间和地点,发生的一些事情。
(2)TDT跟踪任务
①报道切分(Story Segmentation)
找出所有的报道边界,把输入的源数据流分割成各个独立的报道。
②话题跟踪(Story Tracking)
给出某话题的一则或多则报道,训练得到话题模型
然后在后续报道中找出所有讨论目标话题的报道。
③话题检测(Story Detection)
发现以前未知的新话题。
④关联检测(Link Detection)
判断两则报道是否讨论的是同一个话题。
(3)需要解决以下问题
①话题/报道的模型化
②话题-报道相似度的计算
③聚类策略
④分类策略(阈值选择策略)
(4)话题发现核心:实质上是文本聚类
①基于主题模型的话题发现 LDA
②基于向量空间模型的话题发现
③基于词项关系图的话题发现
词项之间的共现频率在某种程度上反映了词项的语义关联。
(5)社交网络语料库中的数据和传统话题发现语料库的数据区别
一般社交网络例如 Twitter 的数据,数据规模大,内容简短,噪声多,数据特征丰富等。
4、影响力最大化
(1)什么是影响力最大化
①影响力最大化是在社交网络中选定信息初始传播用户,使得信息的传播范围能达到最大,即影响力最大。
②影响力最大化算法的目的就是找出一定数量的用户作为影响力传播的初始节点。
③对影响力最大化的问题的建模是基于社交网络信息传播模型的,线性阈值和独立级联模型。
④影响力最大化算法被证明为 NP-hard问题。
(2)两种典型的影响力最大化算法
①贪心算法
l从单个节点开始,计算每选一个新节点作为初始节点对每个节点带来的边际收益
l取能造成边际收益最大的点加入初始节点集合。
l贪心算法的缺点是计算时间成本较大,但是计算精度较高。
②启发式算法
l先通过一定策略选取一定数量的初始节点,然后计算其影响力传播。
l其优点是速度快,缺点是精度低。
第十三讲 基于社交网络的推荐
基于社交网络的推荐
一、社交网络数据
1、三种不同的社交网络数据
①双向确认的社交网络数据
②单向关注的社交网络数据
③基于社区的社交网络数据
2、用图*G(V,E,w)*定义社交网络
①V是顶点集合,每个顶点代表一个用户
②E是边集合,如果用户va和vb有社交网络关系,那么就有一条边e(va, vb) 连接这两个用户
③w (va, vb)定义了边的权重。
④用户的入度(indegree)和出度(out degree),分布也是满足长尾分布的。
二、链接推荐
1、又称好友推荐/朋友推荐,社交网络分析中的链接预测。
2、目的:
①根据用户现有的好友、用户的行为记录给用户推荐新的好友。
②从而增加整个社交网络的稠密程度和社交网站用户的活跃度。
3、有哪些链接预测算法?
①基于用户属性的链接预测
②基于共同兴趣的链接预测
③基于社会关系的链接预测
④基于社交网络图的好友推荐
2.1 基于用户属性的链接预测
什么是基于用户属性的链接预测?
①给用户推荐和他们有相似属性的用户作为好友。
②内容属性
l用户人口统计学属性,
l用户的位置信息。
2.2 基于共同兴趣的链接预测
根据用户在社交网络中的发言提取用户的兴趣标签,来计算用户的兴趣相似度。
步骤:
①分析用户发言的内容
②提取文本的关键词
③计算文本的相似度
2.3 基于社会关系的链接预测
①基于用户的协同过滤算法(UserCF)
主要思想就是如果用户喜欢相同的物品,则说明他们具有相似的兴趣
②评分矩阵—社会关系
Item—people
2.4 基于社交网络图的好友推荐
1、算法一:用共同好友比例计算他们的相似度
(1)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vyZc5hrm-1624585530215)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image002.jpg)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YIphQ6op-1624585530215)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image004.jpg)]
①out(u)是在社交网络图中用户u指向的其他好友的集合。
兴趣重合度
②in(u)是在社交网络图中指向用户u的用户的集合
粉丝重合度
③在无向社交网络图中,out(u)和in(u)是相同的集合。
共同好友。
2、算法二:三元闭包
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yBylliDr-1624585530215)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image006.jpg)]
①朋友A的朋友C是B的朋友, 共同好友。
②用户u关注的用户中,有多大比例也关注了用户v:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YntMAJ4p-1624585530216)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image008.jpg)]
优点:
用户v是顶流,所有中间人都关注名人。
缺点:
在分母的部分没有考虑|in(v)|的大小。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hAIbCAhV-1624585530217)(C:/Users/yandalao/AppData/Local/Temp/msohtmlclip1/01/clip_image010.jpg)]
三、组推荐
3.1组关系
1、社交网络的两种关系
①社交网络关系为friendship
有向图、无向图
②社交网络关系称为membership
基于社区的社交网络数据
2、根据研究组的类型将群组分为4类:
①固定群,有共同的长期兴趣;
②偶然群,成员在特定时刻有共同目标
③随机群,特定时刻共处相同环境,成员之间没有明确的共同兴趣;
④自动识别群,根据用户的偏好或者可用资源自动检测组。
3、从群组特征而言,群组分为
①拥有共同兴趣的既定群体
②特定场合有共同目标的偶然异质群体
③共享环境中无共同点的随机群体
3.2 组推荐算法



第14 讲 深度推荐中的表示学习
•**一、**深度学习推荐
•**二、**AutoREC 模型

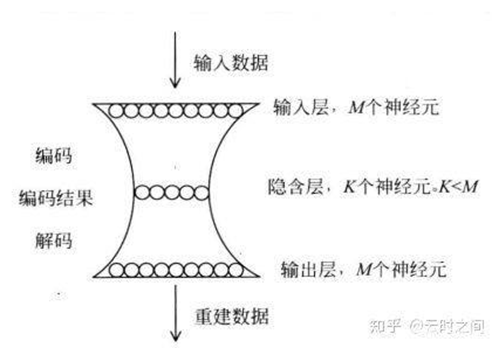
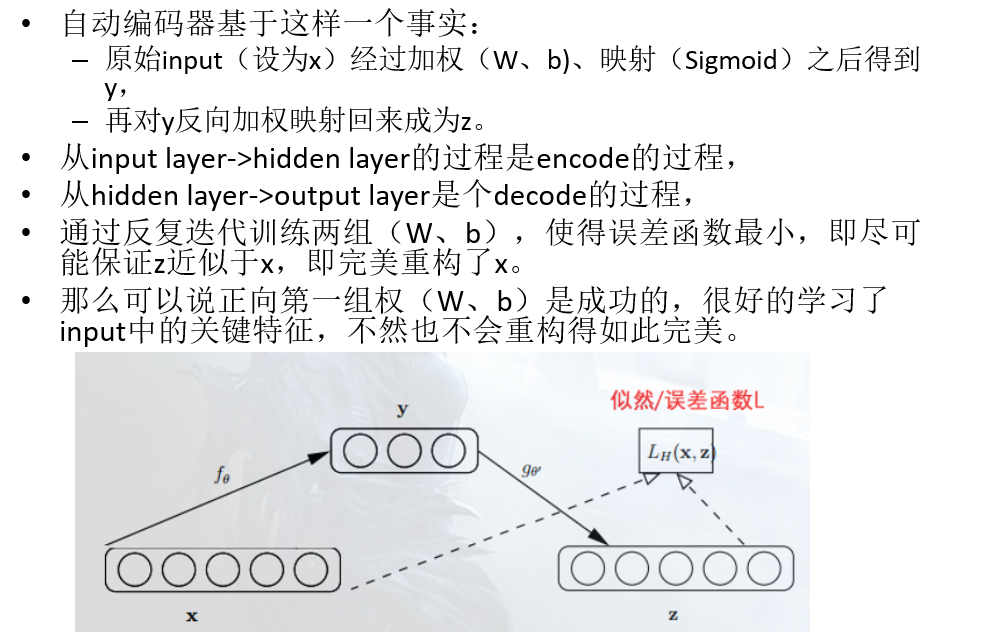


•在数据很稀疏的情况下用AE去学习的效果会不理想
•**三、**CDAE 模型
DAE
autoenocder引入了噪音:–以一定概率把输入层节点的值置为0,从而得到含有噪音的模型输入xˆ。
CDAE

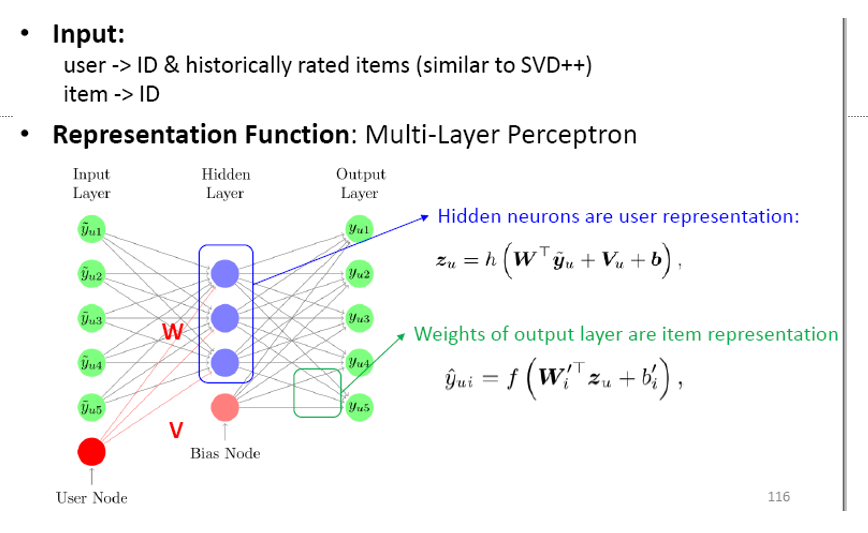
•**四、**MLP表示学习
Youtube-DNN

MV-DNN


DMF

•五、用Attention方法表示学习
Attention机制
NAIS 模型
FISM
•user 作用过的 item 的 embedding 的和来表示 user
•最后两者的内积表示 user 对该 item 的偏好
•NAIS模型
•历史交互物品对用户表示贡献的权重并不全是相同的
–利用一个attention网络学习每个物品的权重。
–与FISM同样,每个物品关联两个Embedding和分别表示物品作为目标物品和历史交互物品时的向量。
ACF模型
•在协同过滤中引入了注意力机制
–根据 SVD++ 进行改进


DIN
•体现用户兴趣的多样性
–对用户行为历史做sum-pooling
–或average-pooling
–引入local-activation,
–以待预测物品与用户历史行为的相关性做权重来动态生成用户表示
第十五讲 深度推荐中的匹配学习
•一、 CF+side information 表示学习
1.1、 DCF
•Deep Collaborative Filtering via Marginalized DAE
–DCF: 评分矩阵+ 特征信息
通过边缘化降噪自编码器对用户和物品的附加信息编码得到隐藏因子(U,V矩阵),用U,V矩阵预测评分
1.2、 DUIF
用CNN对物品(图片)进行特征提取,用线性投影将用户特征和图片特征映射到同一个维度空间,再用内积来表示他们的匹配程度
•二、matching function learning 方法
用内积来表明相似度有局限性,不够深度,可以用用深度学习给 user 和 item 进行交互建模
•三、基于NCF框架的纯CF模型
3.1 NCF 框架
•Neural Collaborative Filtering
•将 user 的 embedding 和 item 的 embedding concat 合并到一起,然后用几层 FC 来学习他们的匹配程度
3.2 NeuMF****模型
基于NCF,运用GMF和MLP,两种结构使用的输入向量不同。

3.3 NNCF: Neighbor-based NCF
•四、基于 Translation 的纯CF模型
translation-based 的模型是,让用户的向量加上一个 relation vector 尽量接近 item 的向量















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









