







Iris Species
KMeans核心算法
import numpy as np
import pandas as pd
import sklearn as sl
class Kmeans:
def __init__(self,data,k):
self.data = data
self.k = k
#开始训练,核心是指定迭代次数
def train(self,max_iterations):
#随机选k个质心
centroids = Kmeans.centroids_init(self.data,self.k)
#开始训练
num_examples = self.data.shape[0]
closest_centorids_ids = np.empty((num_examples,1))
#算距离
for _ in range(max_iterations):
# 算每个点到质心的最近距离
closest_centorids_ids = Kmeans.centroids_find_closest(self.data,centroids)
# 更新中心点位置
centroids = Kmeans.centroids_compute(self.data,closest_centorids_ids,self.k)
return centroids,closest_centorids_ids
@staticmethod
def centroids_init(data,k):
#指定数据源
num_examples = data.shape[0]
#permutation不会洗牌,不改变原始数据.shuffle会改变
# random_ids = np.random.shuffle(num_examples)
random_ids = np.random.permutation(num_examples)
#定义中心点
centroids = data[random_ids[:k],:]
return centroids
@staticmethod
def centroids_find_closest(data,centroids):
#导入数据
num_examples = data.shape[0]
num_centroids = centroids.shape[0]
#初始化
closest_centroids_ids = np.zeros((num_examples,1))
for example_index in range(num_examples):
#定义多少个distance,和类别个数一样多
distance = np.zeros((num_centroids, 1))
#每一个k的位置
for centroid_index in range(num_centroids):
distance_diff = data[example_index,:] - centroids[centroid_index,:]
distance[centroid_index] = np.sum(distance_diff ** 2)
closest_centroids_ids[example_index] = np.argmin(distance)
return closest_centroids_ids
#计算质心
@staticmethod
def centroids_compute(data,closest_centroids_ids,k):
num_features = data.shape[1]
centroids = np.zeros((k,num_features))
for centroid_id in range (k):
closest_ids = closest_centroids_ids == centroid_id
# 返回每一个簇的质心
centroids[centroid_id] = np.mean(data[closest_ids.flatten(),:],axis=0)
return centroids
花卉识别
原始数据
数据下载地址:
https://www.kaggle.com/uciml/iris
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from KMeans import KMeans
data = pd.read_csv('./archive/Iris.csv')
iris_types = ['Iris-setosa','Iris-versicolor','Iris-virginica']
x_axis = 'PetalLengthCm'
y_axis = 'PetalWidthCm'
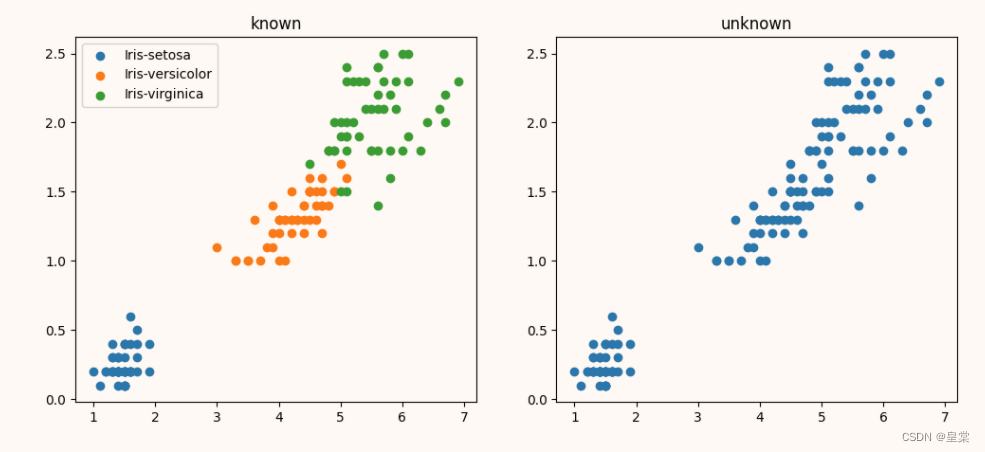
plt.figure(figsize=(12,5))
#生成一个一行两列的图,激活第一个
plt.subplot(1,2,1)
# 根据已经存在的数据类别,画散点图
for iris_type in iris_types:
plt.scatter(data[x_axis][data['Species']==iris_type],
data[y_axis][data['Species']==iris_type],
label=iris_type)
plt.title('known')
plt.legend()
#生成一个一行两列的图,激活第二个
plt.subplot(1,2,2)
# 画一个没有分类的图
plt.scatter(data[x_axis][:],data[y_axis][:])
plt.title('unknown')
plt.show()
KMeans 算法的应用
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from KMeans import Kmeans
data = pd.read_csv('./archive/Iris.csv')
iris_types = ['Iris-setosa','Iris-versicolor','Iris-virginica']
x_axis = 'PetalLengthCm'
y_axis = 'PetalWidthCm'
num_examples = data.shape[0]
x_train = data[[x_axis,y_axis]].values.reshape(num_examples,2)
#指定好训练所需要的参数
k = 3
max_itritions = 1000
k_means = Kmeans(x_train,k)
centroids,closest_centroids_ids = k_means.train(max_itritions)
print('centroids,closest_centroids_ids',centroids,closest_centroids_ids)
#对比结果
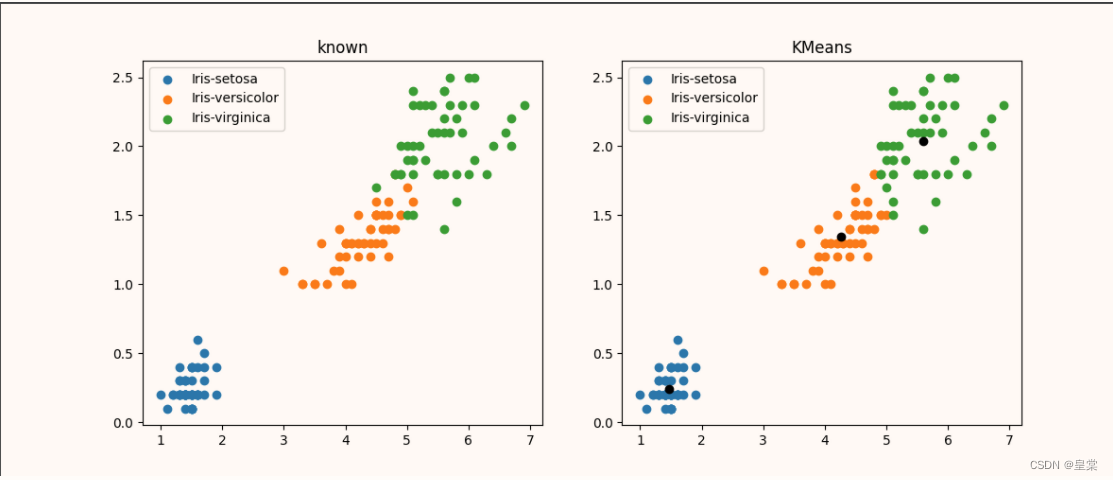
plt.figure(figsize=(12,5))
#生成一个一行两列的图,激活第一个
plt.subplot(1,2,1)
# 根据已经存在的数据类别,画散点图
for iris_type in iris_types:
plt.scatter(data[x_axis][data['Species']==iris_type],
data[y_axis][data['Species']==iris_type],
label=iris_type)
plt.title('known')
plt.legend()
# 画kmeans分类后的
plt.subplot(1,2,2)
for centroid_id ,centroid in enumerate(centroids):
# 分类别
current_examples_index = (closest_centroids_ids == centroid_id).flatten()
plt.scatter(data[x_axis][current_examples_index],
data[y_axis][current_examples_index],
label=iris_types[centroid_id])
for centroid_id,centroid in enumerate(centroids):
plt.scatter(centroid[0],centroid[1],color='black',marker='o')
plt.legend()
plt.title('KMeans')
plt.show()
















 1553
1553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









