







 本文介绍如何使用Python的pandas库创建和操作CSV文件,包括数据的生成、写入及可视化展示,并展示了如何创建和写入TXT文件。
本文介绍如何使用Python的pandas库创建和操作CSV文件,包括数据的生成、写入及可视化展示,并展示了如何创建和写入TXT文件。
1.csv文件
1.1 创建csv文件
这里用的是pandas库,以创建train_acc.csv为例,var_acc.csv类似
- 代码
import random
import pandas as pd
from datetime import datetime
#创建train_acc.csv和var_acc.csv文件,记录loss和accuracy
df = pd.DataFrame(columns=['time','step','train Loss','training accuracy'])#列名
df.to_csv("F:\\Documents\\train_acc.csv",index=False) #路径可以根据需要更改
- 生成train_acc.csv文件

1.2 将数据写入csv文件
说明:这里用的loss和accuracy数据是随机生成的,仅用作test
#初始化train数据
t_loss = 0.4
t_acc = 0.3
for i in range(20):#假设迭代20次
time = "%s"%datetime.now()#获取当前时间
step = "Step[%d]"%i
t_loss = t_loss - random.uniform(0.01,0.017)
train_loss = "%f"%t_loss
t_acc = t_acc + random.uniform(0.025,0.035)
train_acc = "%g"%t_acc
#将数据保存在一维列表
list = [time,step,train_loss,train_acc]
#由于DataFrame是Pandas库中的一种数据结构,它类似excel,是一种二维表,所以需要将list以二维列表的形式转化为DataFrame
data = pd.DataFrame([list])
data.to_csv('F:\\Documents\\train_acc.csv',mode='a',header=False,index=False)#mode设为a,就可以向csv文件追加数据了
- 写入数据后
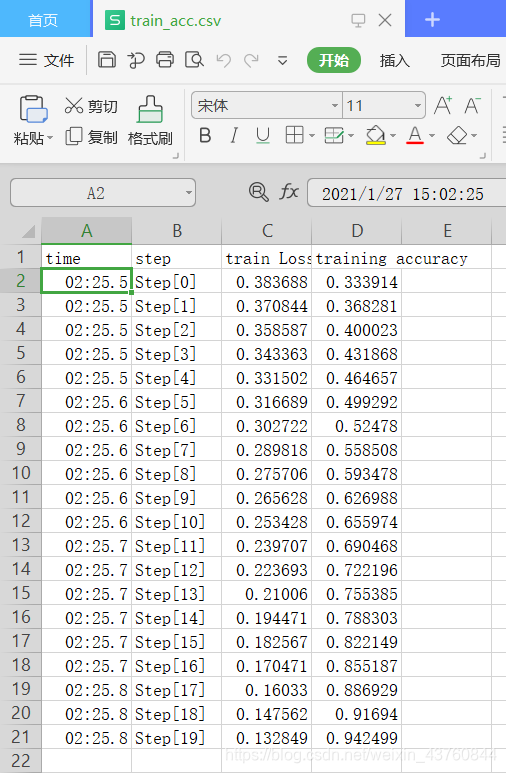
1.3 可视化
- 代码
#可视化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#读取csv中指定列的数据
data = pd.read_csv('F:\\Documents\\train_acc.csv')
data_loss = data[['train Loss']] #class 'pandas.core.frame.DataFrame'
data_acc = data[['training accuracy']]
x = np.arange(0,20,1)
y1 =np.array(data_loss)#将DataFrame类型转化为numpy数组
y2 = np.array(data_acc)
#绘图
plt.plot(x,y1,label="loss")
plt.plot(x,y2,label="accuracy")
plt.title("loss & accuracy")
plt.xlabel('step')
plt.ylabel('probability')
plt.legend() #显示标签
plt.show()
- 折线图
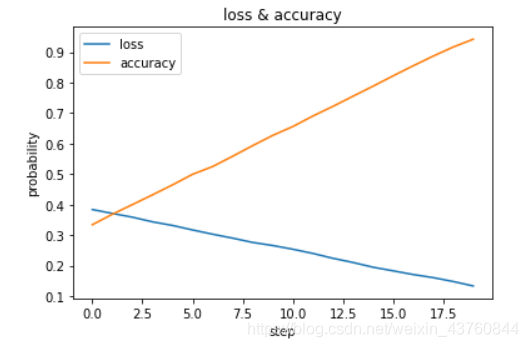
2.txt文件
2.1 创建txt文件并写入数据
这里重新生成一组数据写入txt文件,这个较简单,直接上代码
- 代码
from datetime import datetime
import random
train_loss = 0.4
train_acc = 0.3
trainAcc_txt = "F:\\Documents\\train_acc.txt"
for i in range(20):
train_loss = train_loss - random.uniform(0.01,0.017)
train_acc = train_acc + random.uniform(0.025,0.035)
output = "%s:Step [%d] train Loss : %f, training accuracy : %g" % (datetime.now(),i, train_loss, train_acc)
with open(trainAcc_txt,"a+") as f:
f.write(output+'\n')
f.close
- 效果


















 3045
3045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









