







前言
很高兴遇见你~
HashMap是一个非常重要的集合,日常使用也非常的频繁,同时也是面试重点。本文并不打算讲解基础的使用api,而是深入HashMap的底层,讲解关于HashMap的重点知识。需要读者对散列表和HashMap有一定的认识。
HashMap本质上是一个散列表,那么就离不开散列表的三大问题:散列函数、哈希冲突、扩容方案;同时作为一个数据结构,必须考虑多线程并发访问的问题,也就是线程安全。这四大重点则为学习HashMap的重点,也是HashMap设计的重点。
HashMap属于Map集合体系的一部分,同时继承了Serializable接口可以被序列化,继承了Cloneable接口可以被复制。他的的继承结构如下:
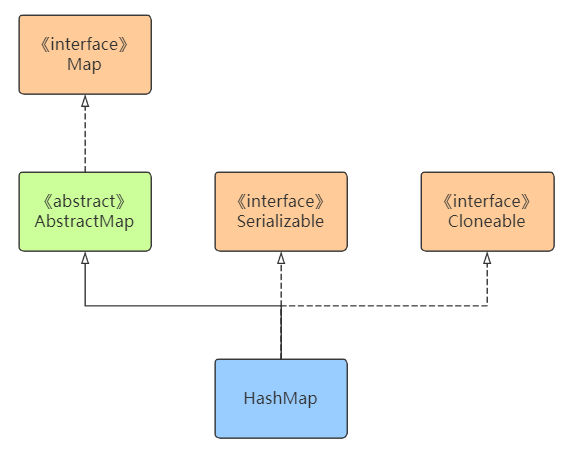
HashMap并不是全能的,对于一些特殊的情景下的需求官方拓展了一些其他的类来满足,如线程安全的ConcurrentHashMap、记录插入顺序的LinkHashMap、给key排序的TreeMap等。
文章内容主要讲解四大重点:散列函数、哈希冲突、扩容方案、线程安全,再补充关键的源码分析和相关的问题。
本文所有内容如若未特殊说明,均为JDK1.8版本。
哈希函数
哈希函数的目标是计算key在数组中的下标。判断一个哈希函数的标准是:散列是否均匀、计算是否简单。
HashMap哈希函数的步骤:
- 对key对象的hashcode进行扰动
- 通过取模求得数组下标
扰动是为了让hashcode的随机性更高,第二步取模就不会让所以的key都聚集在一起,提高散列均匀度。扰动可以看到hash()方法:
static final int hash(Object key) {
int h;
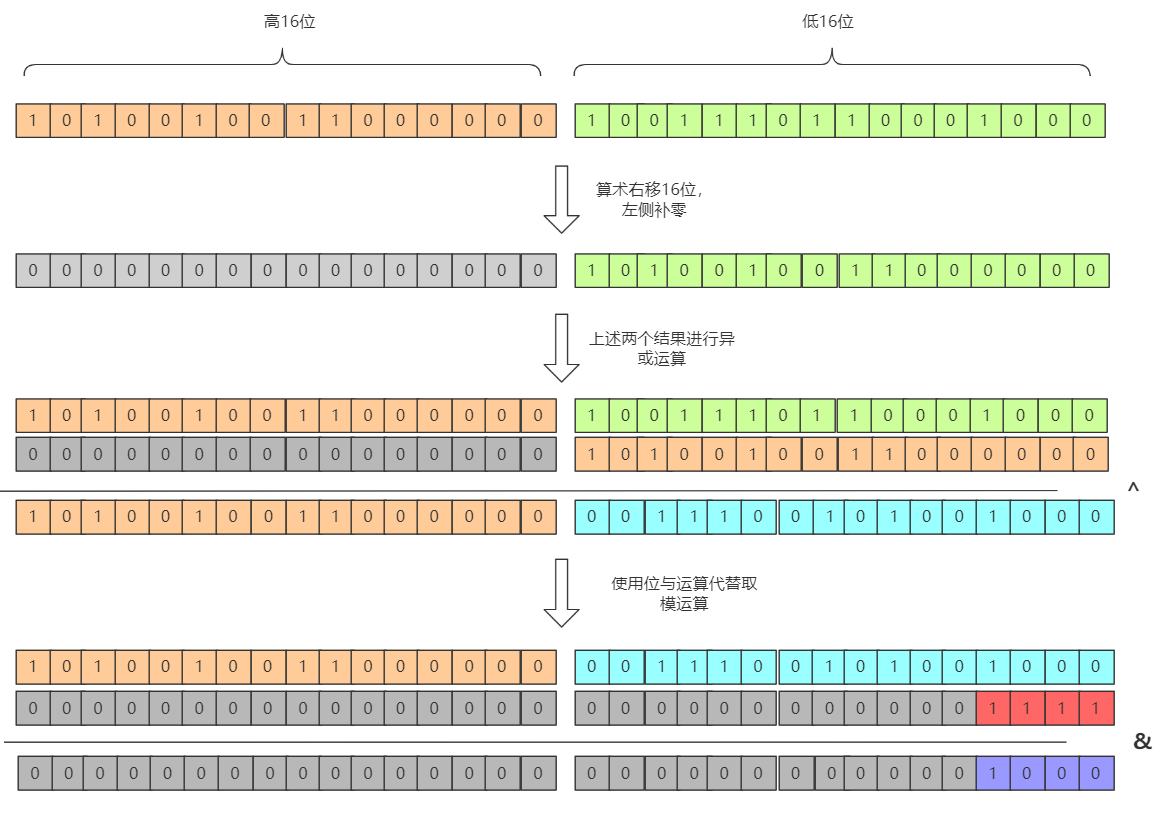
// 获取到key的hashcode,在高低位异或运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
也就是低16位是和高16位进行异或,高16位保持不变。一般的数组长度都会比较短,取模运算中只有低位参与散列;高位与地位进行异或,让高位也得以参与散列运算,使得散列更加均匀。具体运算如下图(图中为了方便采用8位进行演示,32位同理):
[站外图片上传中…(image-402a88-1607182394423)]
对hashcode扰动之后需要对结果进行取模。HashMap在jdk1.8并不是简单使用%进行取模,而是采用了另外一种更加高性能的方法。HashMap控制数组长度为2的整数次幂,好处是对hashcode进行求余运算和让hashcode与数组长度-1进行位与运算是相同的效果。如下图:
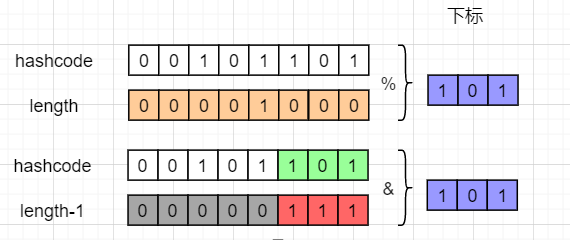
但位与运算的效率却比求余高得多,从而提升了性能。在扩容运算中也利用到了此特性,后面会讲。取模运算的源码看到putVal()方法,该方法在put()方法中被调用:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
// 与数组长度-1进行位与运算,得到下标
if ((p = tab[i = (n - 1) & hash]) == null)
...
}
完整的hash计算过程可以参考下图:
上面我们提到HashMap的数组长度为2的整数次幂,那么HashMap是如何控制数组的长度为2的整数次幂的?修改数组长度有两种情况:
- 初始化时指定的长度
- 扩容时的长度增量
先看第一种情况。默认情况下,如未在HashMap构造器中指定长度,则初始长度为16。16是一个较为合适的经验值,他是2的整数次幂,同时太小会频繁触发扩容、太大会浪费空间。如果指定一个非2的整数次幂,会自动转化成大于该指定数的最小2的整数次幂。如指定6则转化为8,指定11则转化为16。结合源码来分析,当我们初始化指定一个非2的整数次幂长度时,HashMap会调用tableSizeFor()方法:
public HashMap(int initialCapacity, float loadFactor) {
...
this.loadFactor = loadFactor;
// 这里调用了tableSizeFor方法
this.threshold = tableSizeFor(initialCapacity);
}
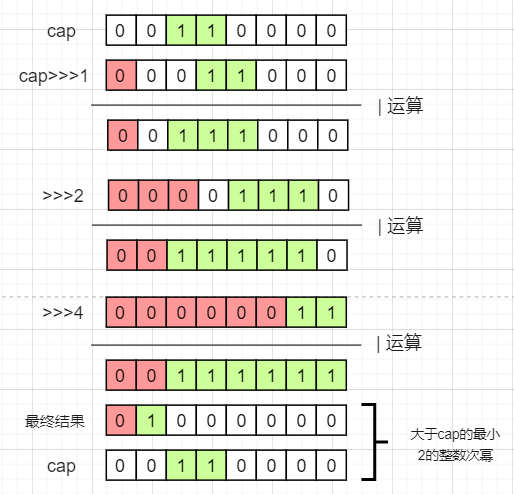
static final int tableSizeFor(int cap) {
// 注意这里必须减一
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
tableSizeFor()方法的看起来很复杂,作用是使得最高位1后续的所有位都变为1,最后再+1则得到刚好大于initialCapacity的最小2的整数次幂数。如下图(这里使用了8位进行模拟,32位也是同理):
那为什么必须要对cap进行-1之后再进行运算呢?如果指定的数刚好是2的整数次幂,如果没有-1结果会变成比他大两倍的数,如下:
00100 --高位1之后全变1--> 00111 --加1---> 01000
第二种改变数组长度的情况是扩容。HashMap每次扩容的大小都是原来的两倍,控制了数组大小一定是2的整数次幂,相关源码如下:
final Node<K,V>[] resize() {
...
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 设置为原来的两倍
newThr = oldThr << 1;
...
}
小结:
- HashMap通过高16位与低16位进行异或运算来让高位参与散列,提高散列效果;
- HashMap控制数组的长度为2的整数次幂来简化取模运算,提高性能;
- HashMap通过控制初始化的数组长度为2的整数次幂、扩容为原来的2倍来控制数组长度一定为2的整数次幂。
哈希冲突解决方案
再优秀的hash算法永远无法避免出现hash冲突。hash冲突指的是两个不同的key经过hash计算之后得到的数组下标是相同的。解决hash冲突的方式很多,如开放定址法、再哈希法、公共溢出表法、链地址法。HashMap采用的是链地址法,jdk1.8之后还增加了红黑树的优化,如下图:
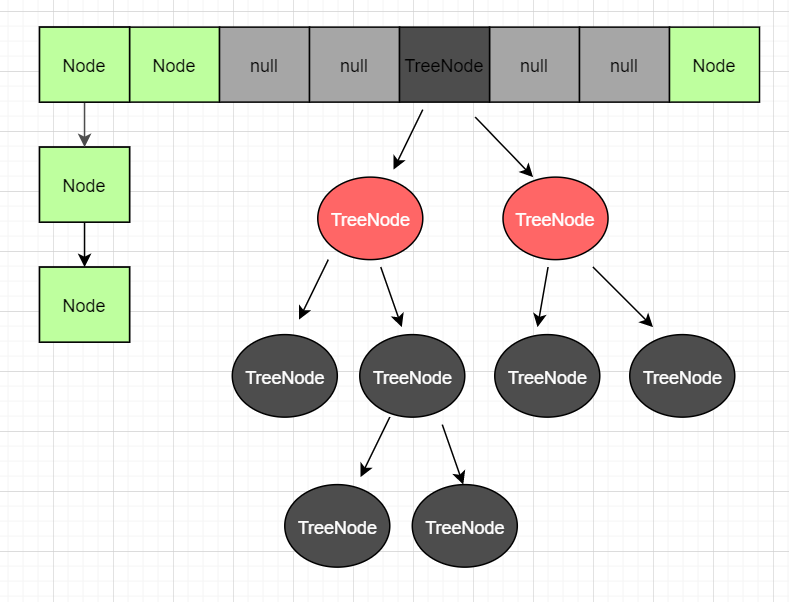
出现冲突后会在当前节点形成链表,而当链表过长之后,会自动转化成红黑树提高查找效率。红黑树是一个查找效率很高的数据结构,时间复杂度为O(logN),但红黑树只有在数据量较大时才能发挥它的优势。关于红黑树的转化,HashMap做了以下限制
- 当链表的长度>=8且数组长度>=64时,会把链表转化成红黑树。
- 当链表长度>=8,但数组长度<64时,会优先进行扩容,而不是转化成红黑树。
- 当红黑树节点数<=6,自动转化成链表。
那就有了以下问题:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









