






Dplyr_info
1.Dplyr包的介绍
Dplyr是一个强大的R数据处理基础软件包,用于处理,清理和汇总非结构化数据。Dplyr函数处理速度比基本R函数快。 这是因为Dplyr函数是以计算有效的方式编写的。它们在语法上也更稳定,并且比向量更好地支持数据帧。简言之,它使得R中的数据探索和数据操作变得简单快捷。
Dplyr包中预设的数据集:
| Data | Description |
|---|---|
| band_instruments | Band membership |
| band_instruments2 | Band membership |
| band_members | Band membership |
| nasa | Starwars characters |
| storms | Storm tracks data |
2. Dplyr函数
介绍Dplyr包一些主要的函数:
select()函数filter()函数mutate()函数join函数summarise()函数group_by()函数bind、add函数distinct函数arrange函数
3.select函数
select函数,根据名称来筛选变量,使用如select(df,var1,var2)的命令可选择指定名称的变量。

可搭配的主要函数数如下:
| 搭配函数 | 功能 |
|---|---|
| starts_with() | 以某字符串开头的变量 |
| ends_with() | 以某字符串结尾的变量 |
| contains() | 包含某字符串的变量 |
| matchs() | 正则表达式匹配变量名 |
| num_range() | 有数字规律的变量名,从哪里到哪里 |
| one_of() | 变量名属于某字符串向量 |
| everything() | 返回所有变量名 |
| last_col() | 最后一个变量 |
下面给出一些示例:
-
select(df,starts_with('A')):筛选df中以"A"开头的变量

-
select(df,one_of(c('Alpha','Delta','Gamma'))):筛选Alpha、Delta和Gamma变量(若存在)

-
select(df,Alpha:Delta):选择了从Alpha到Delta列

-
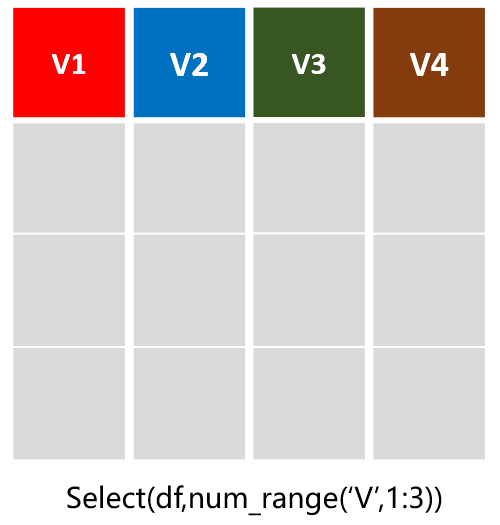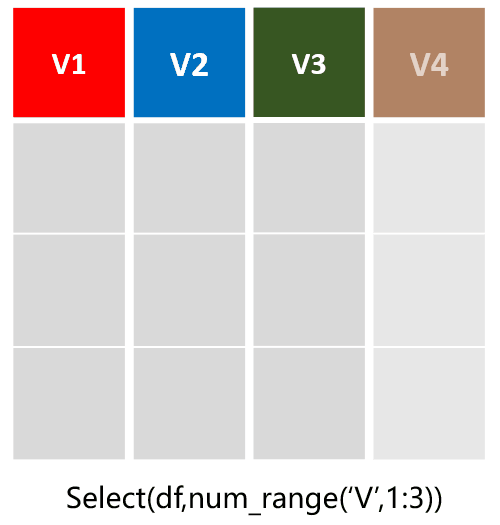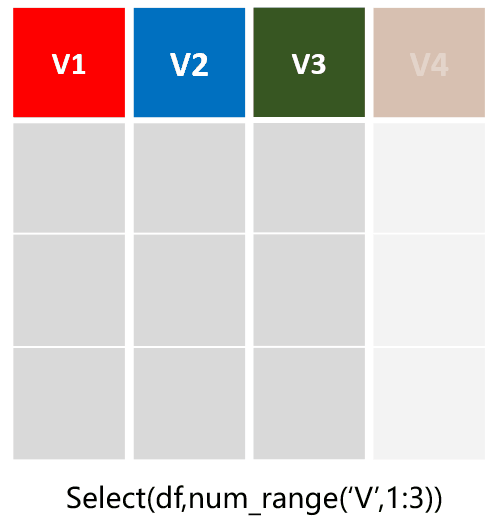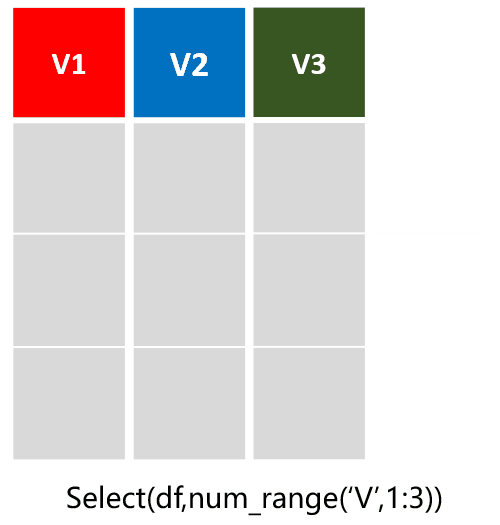
select(df,num_range('V',1:3)):选择从V1到V3列
-
select(df,last_col()):选择最后一列
此外,使用select函数还能实现对列的一些其他操作:
-
删除列:
select(df,-Alpha)删除了Alpha列

-
移动列:
-
select(df,Alpha,Delta,everything())将Alpha,Delta列移至最前

-
select(df,-Alpha,Alpha)将Alpha列移至最后

-
4.filter函数
filter()也是Dplyr中的筛选函数,不同于select()作用于列(变量),filter()的筛选对象是满足条件的行(case)

filter()函数除了能针对特定列筛选case外,还可以使用filter_all()对所有列筛选,filter_at()对vars()中给定的变量进行筛选、filter_if()对满足特定条件的列进行筛选。filter()系列函数通常搭配一些逻辑符进行操作。
| 搭配符号/函数 | 功能 |
|---|---|
| <、==、> | 筛选满足对应数量关系的case |
| &、|、!、xor | 筛选布尔值为真的case |
| is.na() | 根据是否为缺失值筛选case |
| all_vars() | 筛选所有变量都满足某一条件的case |
| any_vars() | 筛选存在变量满足某一条件的case |
下面给出示例:
-
filter(df,Alpah >1 & Beta =='b')筛选Alpha值大于1,且Beta为b的行
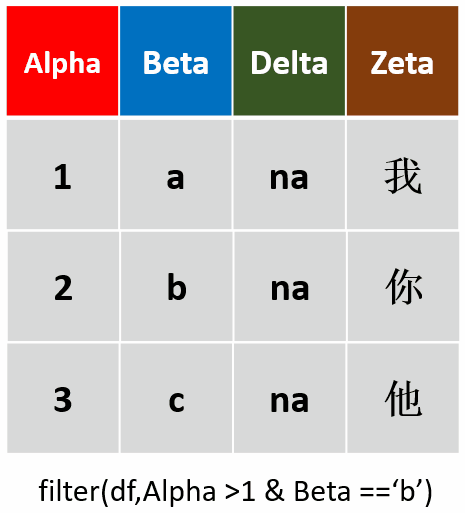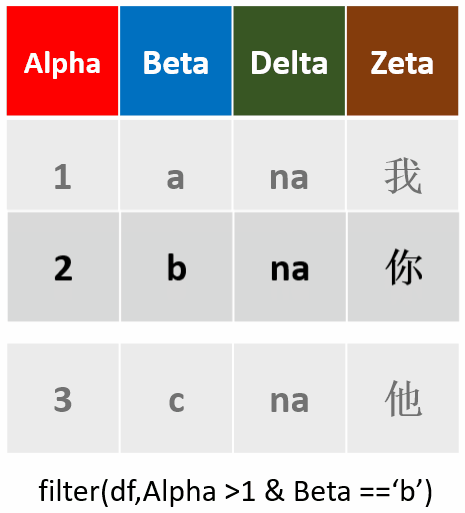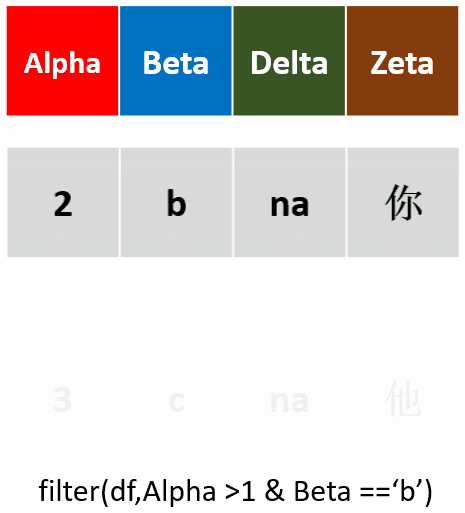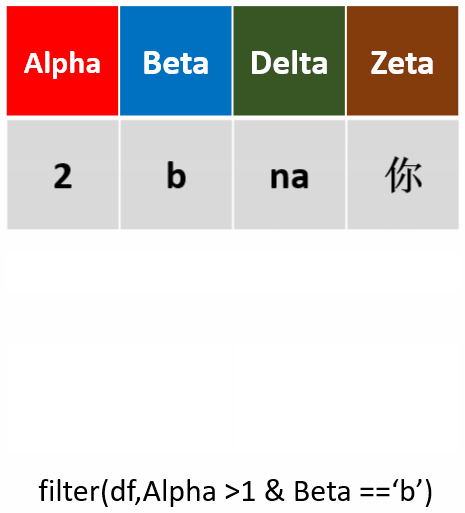
-
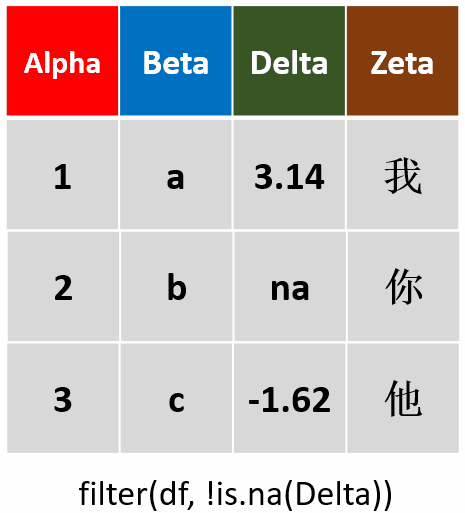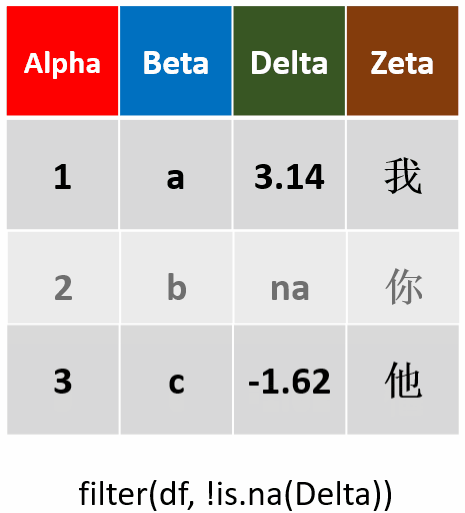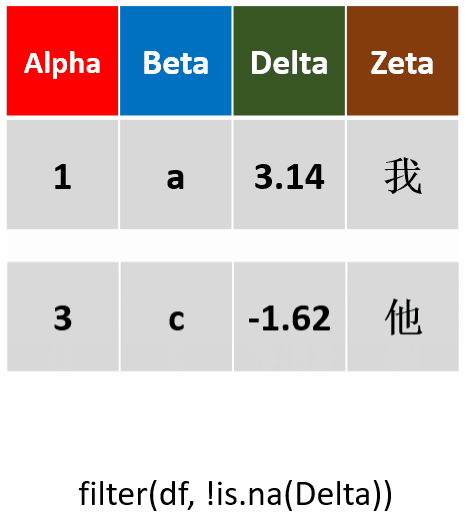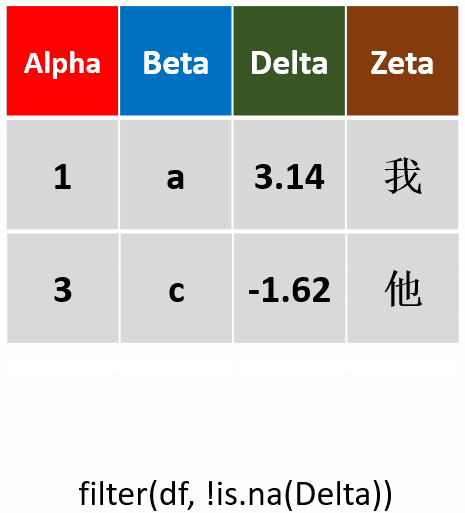
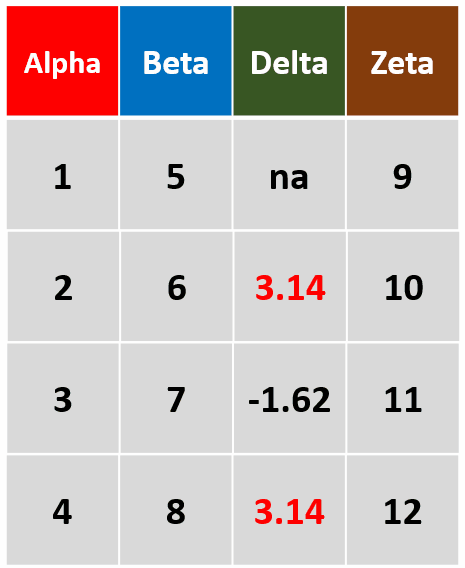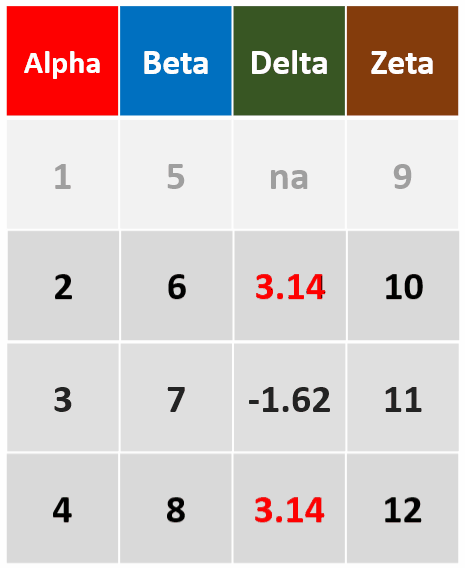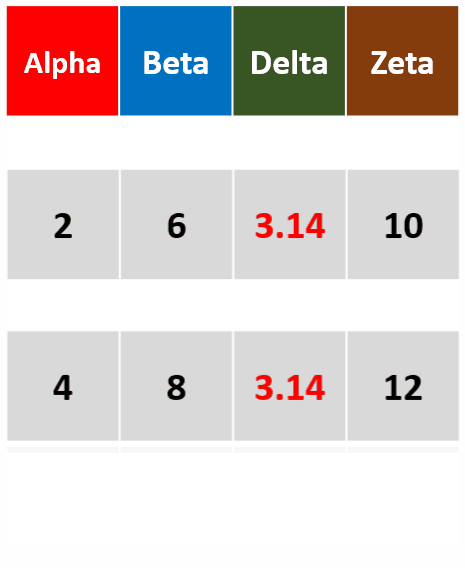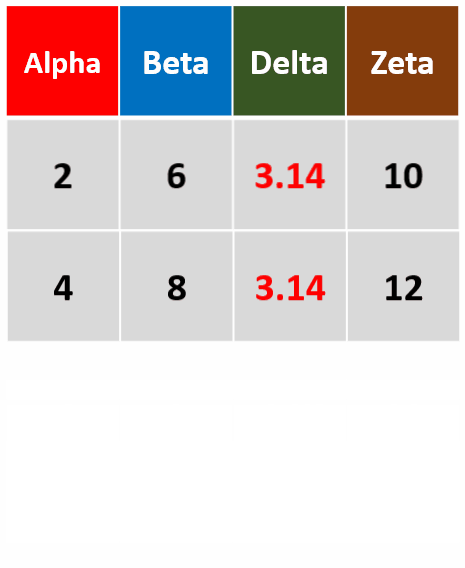
filter(df,!is.na(Delta))筛选Delta未缺失的行
-
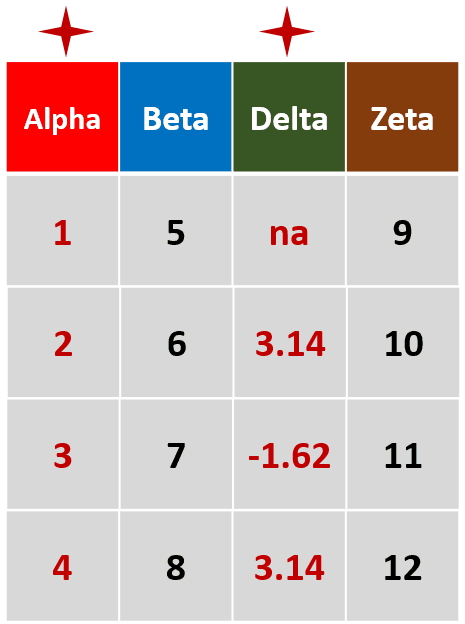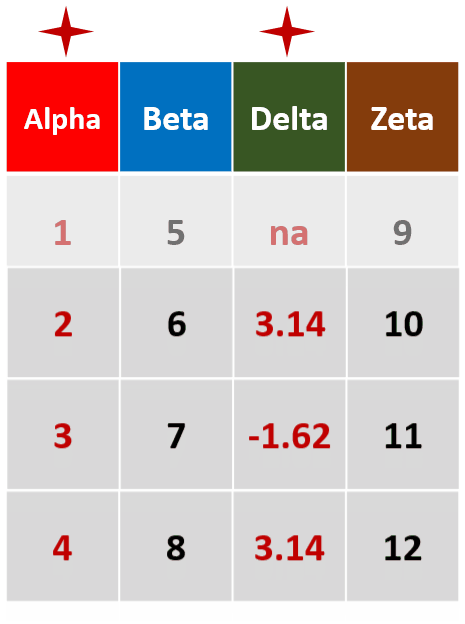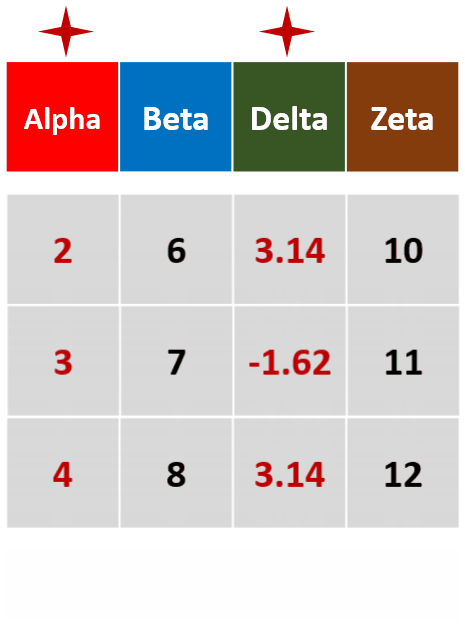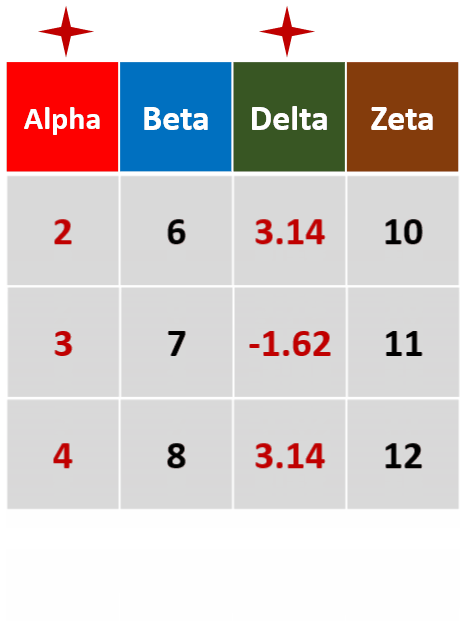
filter_all(df,all_vars(.>= 2))针对所有列,筛选所有变量都大于等于2的行
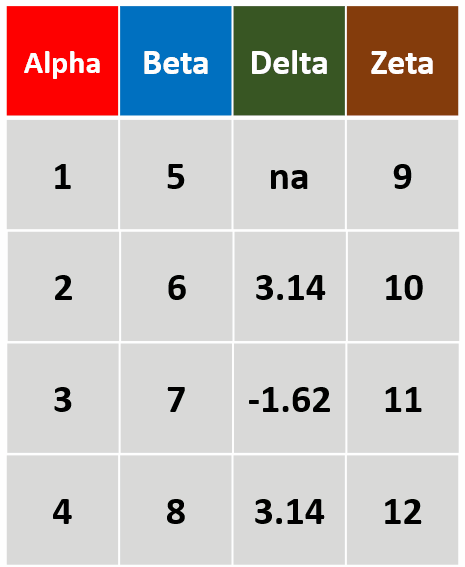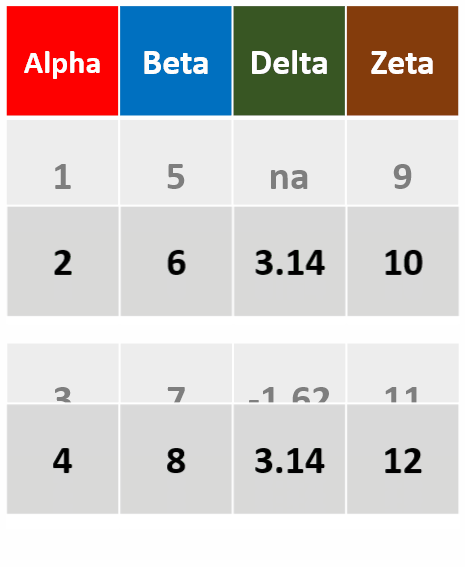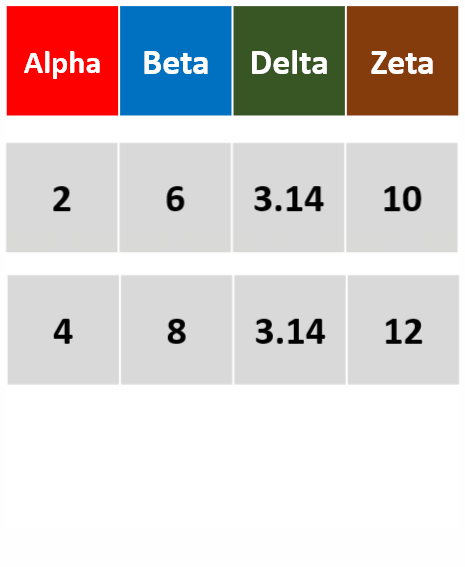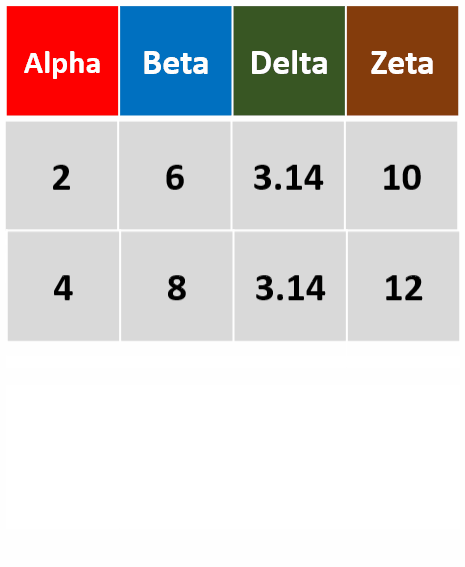
-
filter_at(df,vars(Alpha,Delta)),any_vars(.>3)针对Alpha和Delta两列,筛选存在变量大于3的行
-
还可以搭配grepl()函数,以搜索模式进行筛选
filter(df,grepl('14',Delta))对Delta变量进行含“14”的搜索筛选
5.join函数
join()系列函数用于两个数据框的合并操作,根据不同的合并规则,join函数有一系列衍生的函数,具体包括:
- 内连接
inner_join() - 外连接:
- 左连接
left_join() - 右连接
right_join() - 全连接
full_join()
- 左连接
- 筛选连接
semi_join()、anti_join()
join函数的示例动图非原创,来源:https://github.com/gadenbuie/tidy-animated-verbs#relational-data
5.1 内连接
内连接的结果是一个新的数据框,其中包含键、x值和y值。我们使用by参数告诉dplyr哪个变量是键。内连接保留键同时存在于两个表中的观测。
inner_join(x,y,by= key)

5.2 外连接
内连接保留同时存在两个表中的观测,外连接则保留至少存在于一个表中的观测。外连接有3种类型:左连接、右连接诶、全连接。
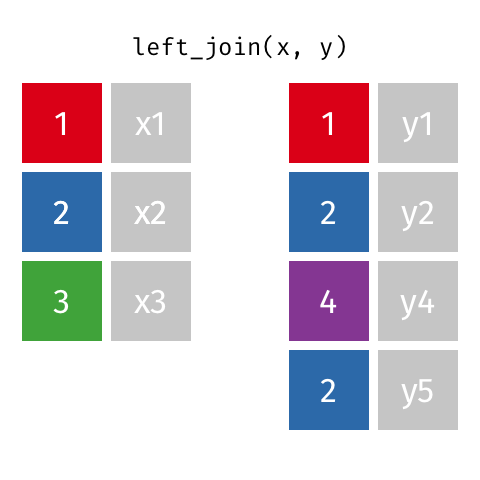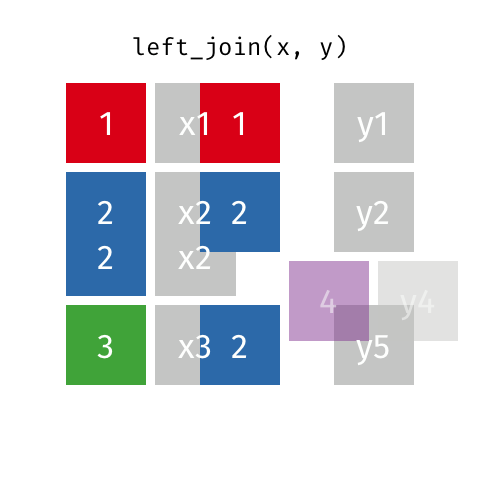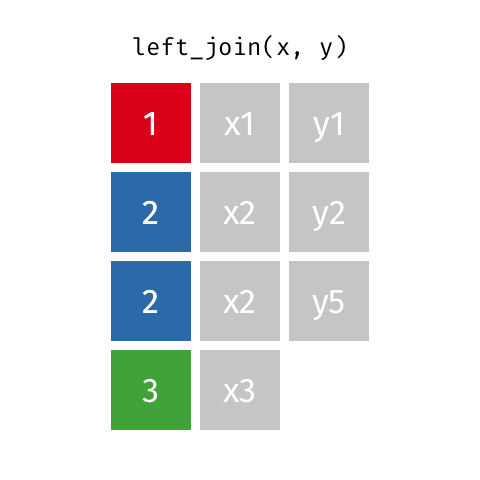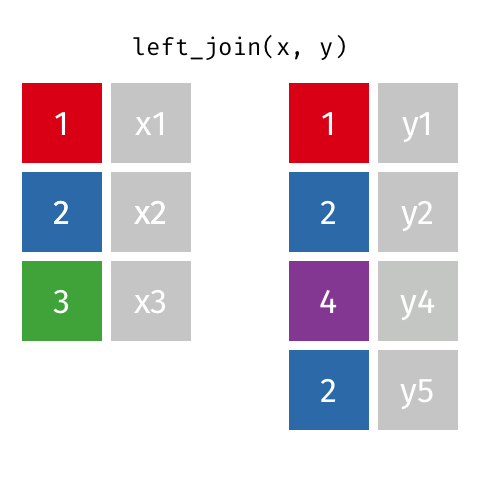
1.左连接:保留左边数据框(x)中所有观测
left_join(x,y,by= key)

如果在X中用于连接的“key”值,在Y中有多个同样的值,那么所有可能的结合都会被罗列出来
2.右连接:与左连接类似,保留右边数据框(y)中所有观测
right_join(x,y,by= key)

3.全连接:保留x和y中所有观测
full_join(x,y,by=key)

5.3 筛选连接
筛选连接匹配观测的方式与合并连接相同,但前者影响的是观测,后者影响的是变量。筛选连接有semi_join()和anti_join()2种类型。
1.semi_join():保留x中与y中的观测相匹配的所有观测
semi_join(x,y,by=key)

2.anti_join():丢弃X表中与Y表中的观测相匹配的观测
anti_join(x,y,by= key)

6.mutate、transmutate函数
mutate()和transmute()函数对已有列进行数据运算并添加为新列,类似于base::transform() 函数, 不同的是可以在同一语句中对刚增添加的列进行操作。mutate()返回的结果集会保留原有变量,transmute()只返回扩展的新变量。原数据集行名称会被过滤掉。
给出两个示例介绍mutate函数:
-
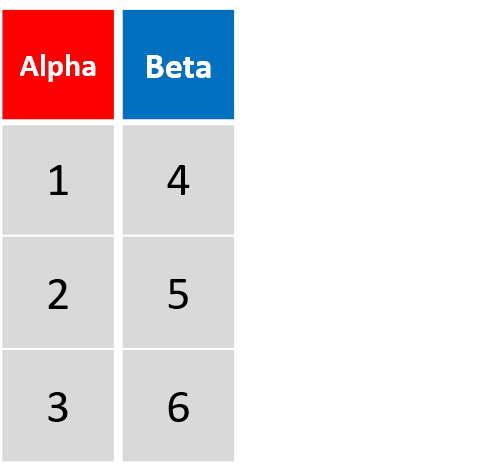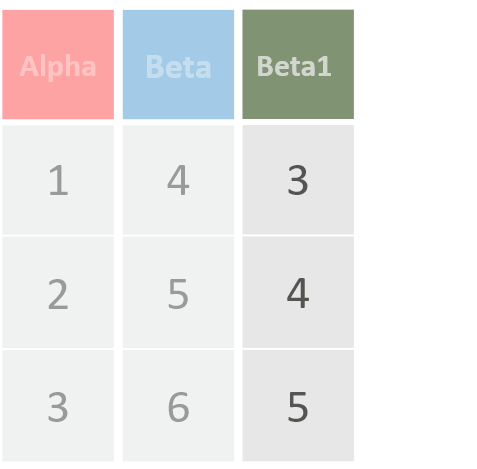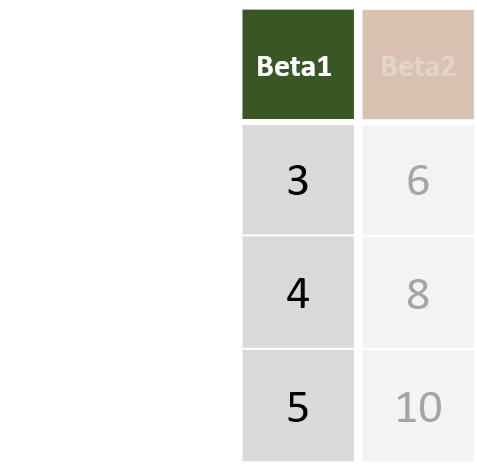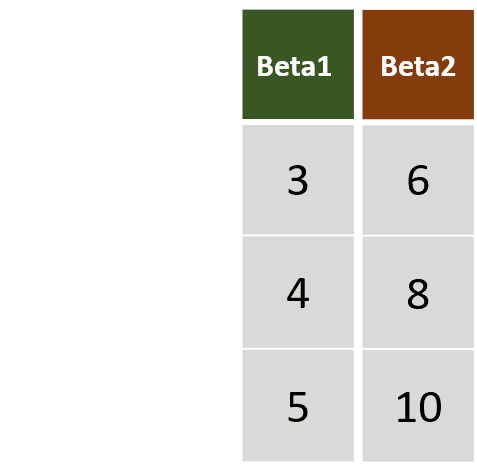
mutata(df, Beta1= Beta -1, Beta2= Beta1 *2)对Beta进行了两次运算,并将运算结果添加为新列
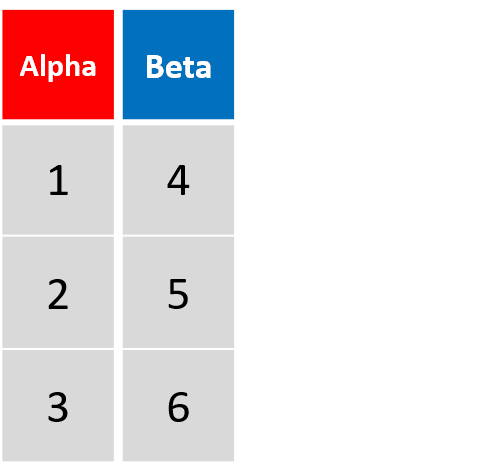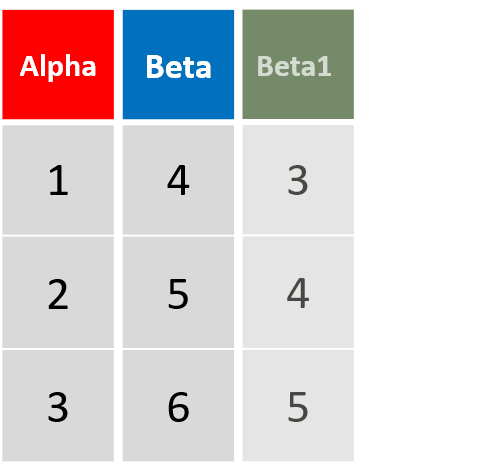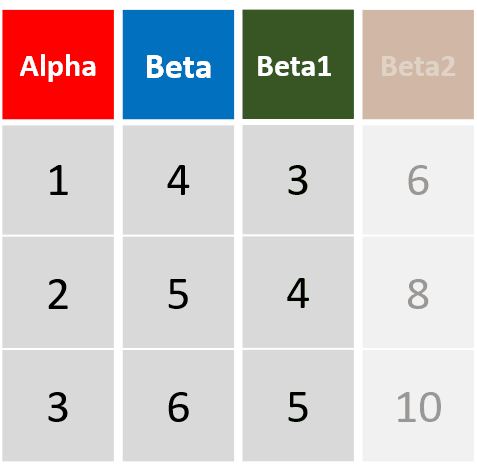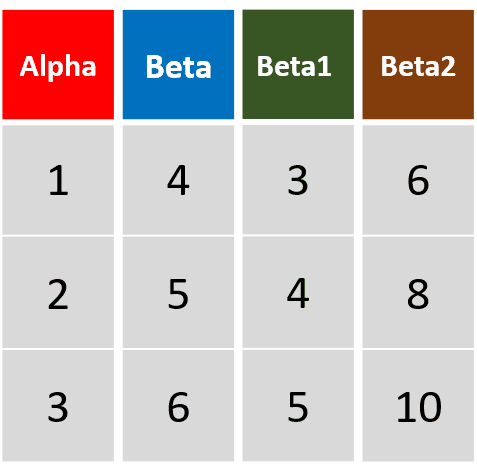
-
transmutate(df, Beta1= Beta -1, Beta2= Beta1 *2)运算过程与上一条命令完全一致,但运算后只返回扩展的新变量,返回的数据框维度与上一个不同
mutate和transmutate都有_all()、_at()、_if()三种变形,其效果在前文介绍filter函数时已作说明,不再赘述。
7.arrange函数
arrange()按给定的列名依次对行进行排序,类似于base::order()函数。默认是按照升序排序,对列名加 desc() 可实现倒序排序。排序后,原数据集行名称会被过滤掉。
-
arrange(df,Alpha,desc(Beta))按Alpha升序,Beta降序对df进行行排列
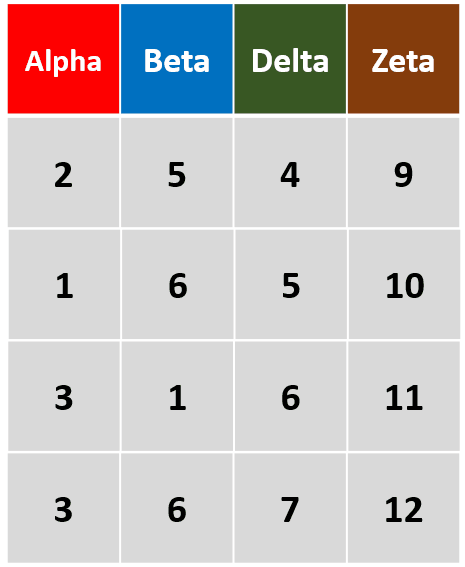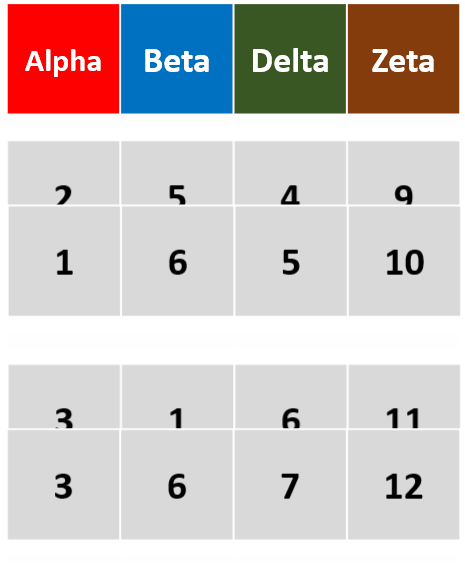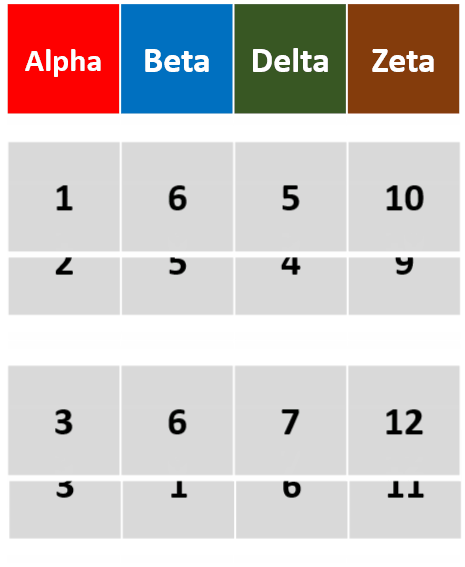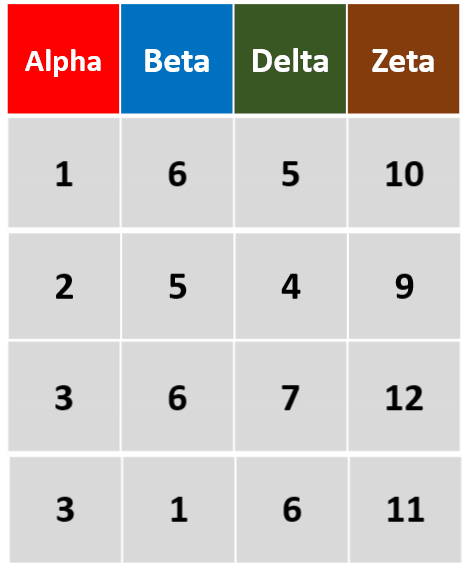
-
arrange(df,desc(Alpha),desc(Beta))按Alpha降序、Beta降序对df进行行排列
8.distinct函数
distinct()用于对输入的数据框进行去重,返回无重复的行,类似于base::unique()函数,但是处理速度更快。去重后原数据集行名称会被过滤掉。
-
distinct(df)针对整个数据集,删除完全相同的重复行
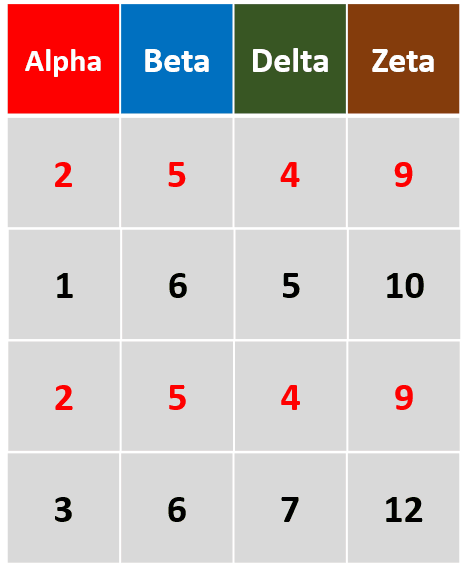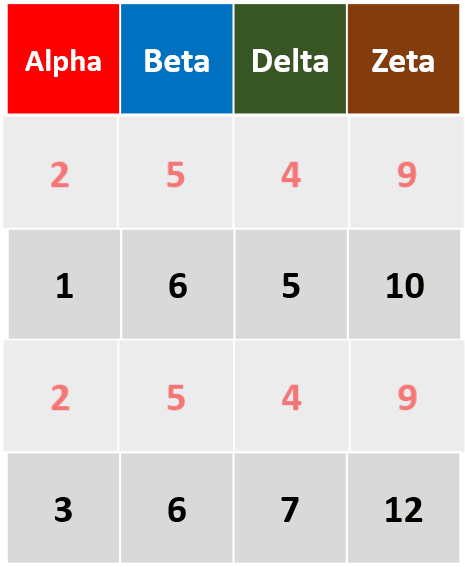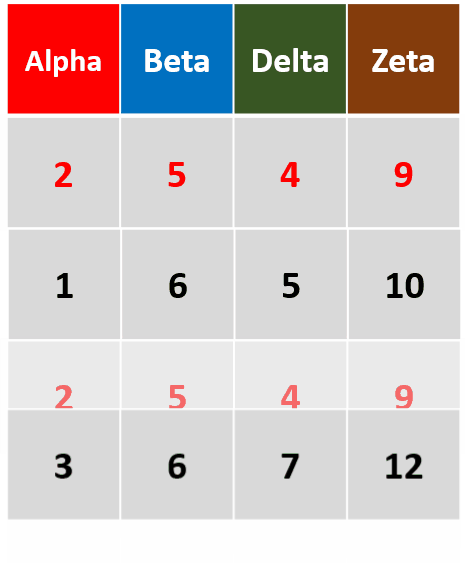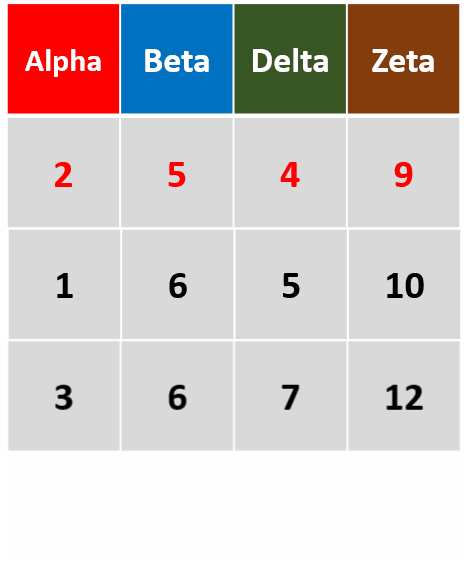
-
distinct(df,Alpha,Delta)只针对变量Alpha和变量Delta,删除重复行

distinct默认只保留选择的行,如果根据选定变量去重后,要返回所有变量值,则需将参数.keep_all设置为TRUE
distinct(df,Alpha,Beta, .keep_all =TRUE)针对Alpha和Delta删除重复行,并返回所有变量

9.bind函数
bind函数可合并多个数据框,或能转化为数据框的列表。按行合并函数bind_rows()通过列名进行匹配,不匹配的值使用NA替代。按列合并函数bind_cols()通过行号匹配,合并的数据框必须有相同的行数。
-
bind_rows(df1,df2)按行合并df1、df2两个数据框。按行合并时,可以设置参数.id='id'来添加一列,标识每一行来自哪个数据框

-
bind_cols(df1,df2, .id= 'id')按列合并两个数据框
10.add函数
add函数用于在数据框中插入行或列
-
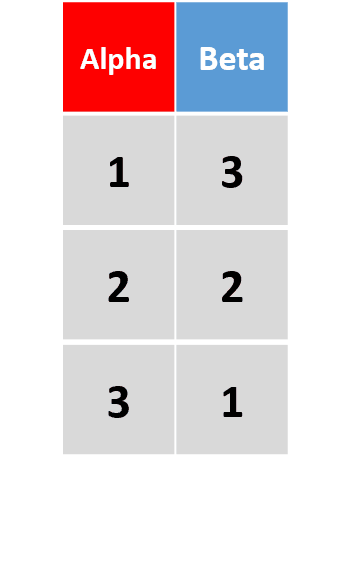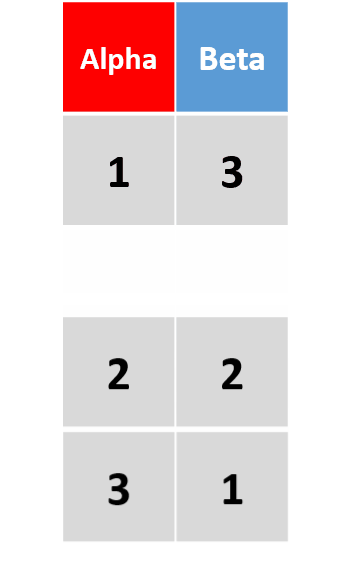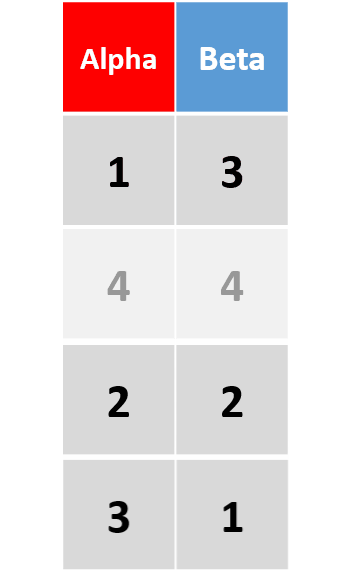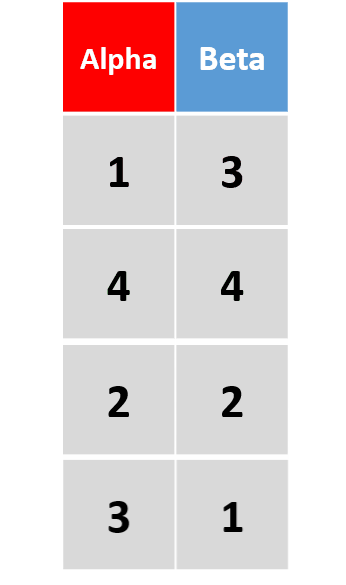
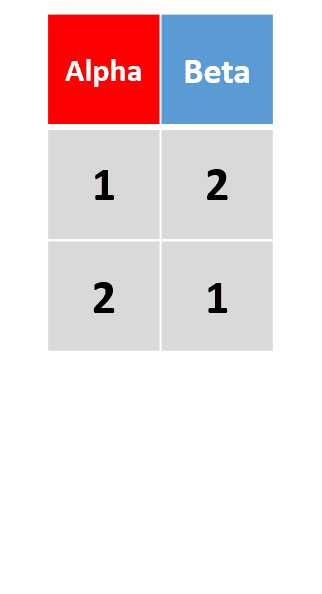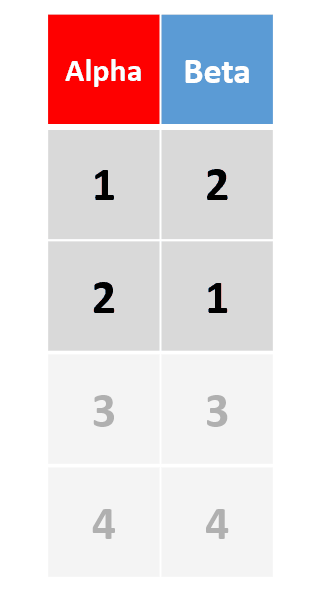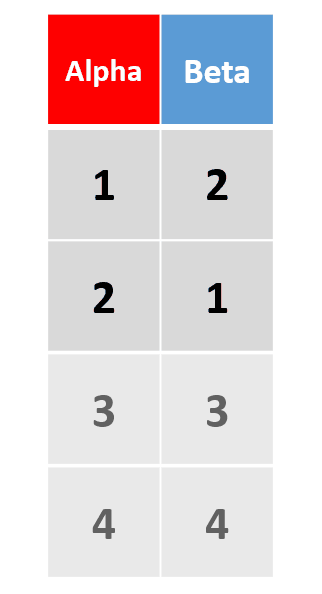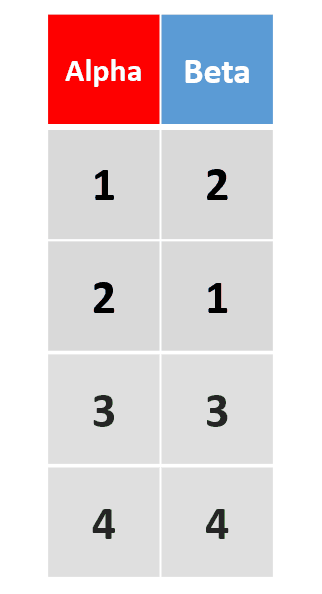
add_row(df, Alpha = 4, Beta = 4, .before = 2)在原数据框第2行前添加一行 -
将
.before替换为.after,则新行将插入与原数据框第2行之后。省略这两个参数,则默认添加在最后一行
-
add_row(df,Alpha = 3:4, Beta = 3:4)插入多行
-
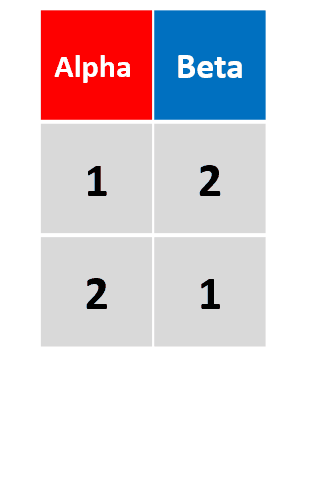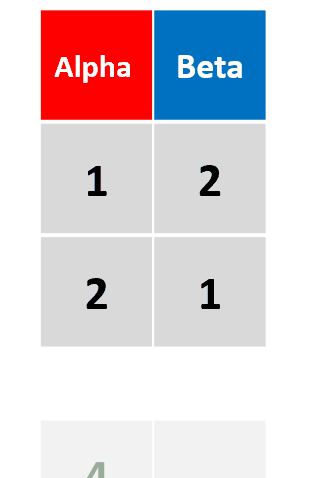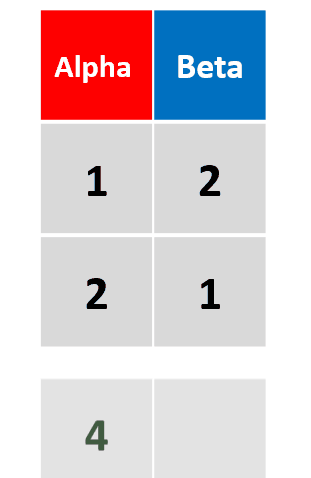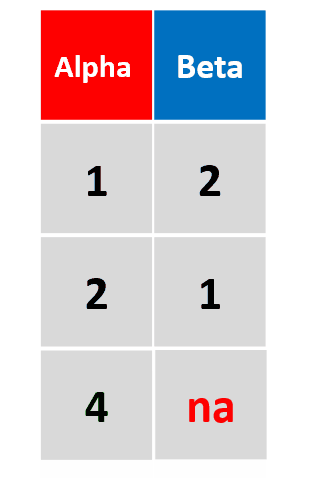
add_row(df, Alpha = 4)插入行的列数不足,以na自动补全
-
add_column()实际测试时,发现Dplyr中找不到此函数,目前暂不清楚是什么原因
11.group函数
group函数用于对数据框进行分组及后续操作,只使用group_by()并不能看出数据框的变化,只有搭配其他函数进行后续操作,才能发现其优越性。group系列函数可操作性非常强。
11.1对象分组
#### group_by与ungroup
by_cyl <- mtcars %>% group_by(cyl)
by_cyl %>% summarise(disp = mean(disp),hp = mean(hp))#分组后,分别求各组disp和hp的均值
by_cyl %>% filter(disp == max(disp)) #分组后,取disp最大值所在行
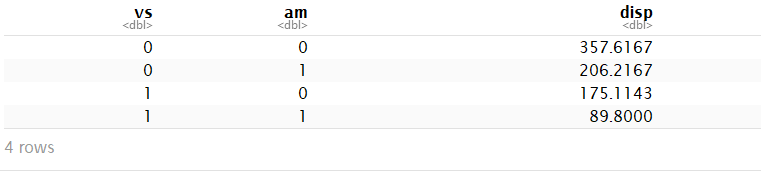
by_vs_am <- mtcars %>% group_by(vs, am) #两个分组变量,先对vs分组,再对am分组
summarise(by_vs_am, disp = mean(disp))


group_by同样可以搭配_all()、_if()、_at()进行使用,示例代码如下:
group_by_all(mtcars) #对mtcars所有变量进行分组
group_by_if(iris,is.factor) #对iris的所有因子变量分组
group_by_at(mtcars,vars(vs, am)) #对vs和am变量进行分组
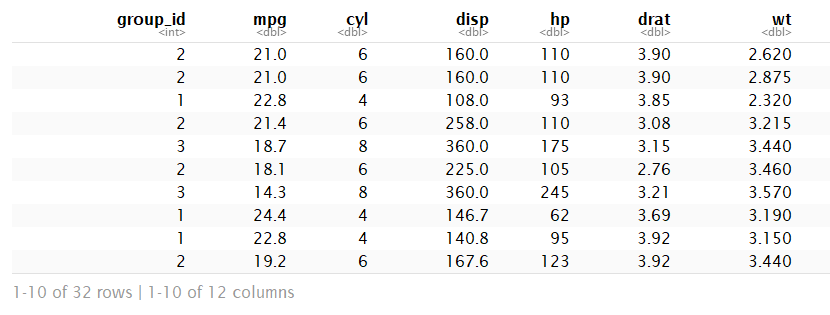
group_indices()将返回分组后各行所在组的id,搭配mutate使用 ,给数据框增加组别标识列
mutate(mtcars,group_id = group_indices(mtcars,cyl)) %>% select(group_id,everything())
11.2分组后处理
_size()和n_groups()
group_size()返回分组后各组的行数,而n_groups()则返回分组的数量
group_by(mtcars,vs,am) %>% n_groups() #返回了分组的数量4
group_by(mtcars,vs,am) %>% group_size() #返回个分组的数量12 6 7 7
####group_vars()
group_vars()返回分组的变量名
by_vs_am <- group_by(mtcars,vs,am)
by_vs_am %>% group_vars() #以向量形式返回分组变量名
by_vs_am %>% groups() #以列表形式返回分组变量名
12.summarise函数
summarise函数用于对数据框进行汇总,在介绍group函数时,已提及过使用summarise函数对分组进行求均值等操作。summarise每运行一次,都会减少一级分组,因为每次使用summarise会将一个分组汇总成一条信息
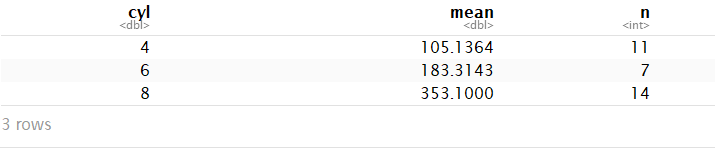
summarise(mtcars, mean = mean(disp), n = n()) #返回只有一行的tibble
mtcars %>% group_by(cyl) %>% summarise(mean = mean(disp), n = n()) #先分组,后汇总
summarise同样可与_all()、_at()、_if()搭配使用
starwars %>% summarise_at(vars(height:mass), mean, na.rm = T) #返回所选3个变量的均值
by_species <- iris %>% group_by(Species)
by_species %>% summarise_all(list(min,max)) #返回各分组所有变量的最大值和最小值

使用summarise能较方便地得到分组或未分组数据的数量信息,常见的如:最大值、最小值、均值、分位值、计数、标准差等等
13.参考资料
本文档对R语言中专注于数据预处理的Dplyr包做了一些简要介绍,演示了一些主要的函数及其功能。但要指出的是,还有相当大一部分函数操作的细节被忽略了。要彻底掌握Dplyr包的使用,必须在熟悉其函数功能框架的基础上,究其细枝末节。
主要的参考资料:Kingsley_W的CSDN博客、tibble_dplyr_tidyr_深入浅出















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









