







Discriminative frequent subgraph mining with optimality guarantees
论文链接:Discriminative frequent subgraph mining with optimality guarantees
频繁子图挖掘(frequent subgraph mining)是检测子图是否在图集上反复出现。discriminative frequent subgraph可以理解为在某些类中频繁出现,但是在其他类中出现的不多。
本文提出了CORK算法,这是一个子模性质算法,可以使用贪心获取次优解,并且可以将其于gSpan结合。
1 Introduction
本文主要考虑的是frequent pattern approaches相关的问题,用频繁子图来表示一个图。并且最优化图分类的结果。
目前这类问题存在两个重点:
- 在一张大图中枚举所有存在的子结构是计算复杂的(指数级别)。
- 不频繁子图(infrequent subgraph)的区分能力(discriminative power)是很差的。
因此我们需要frequent subgraph mining。
大量的图结构会产生以下的挑战:
- 绝大部分的频繁结构仅有一些细微的区别,并且它们都会出现在一张图中。
- 仅仅是频繁结构还不具备区分能力,因此只有频繁子图结构与类挂上统计学关联的时候,它们才对分类有较大的贡献。(可以理解为在这个类中频繁出现,但是在别的类中出现的不频繁意味着它是这个类的重要频繁子图,能够代表这个类)
- 当threshold设置的过小的时候,会产生大量的频繁子图,这会是计算十分复杂并且存储不够。
本文提出了一个具有子模性质的贪心算法,通过它来提取图中重要的结构。并且将其与gSpan做结合,用于频繁子图挖掘。该算法为二分类设置,但同时可以服务多分类问题。
2 Near-optimal feature selection among frequent subgraphs
第二节开头首先是一些定义的介绍,我默认读者有一定的图论基础。
subgraph isomorphism: 两张图中有对应的节点,同时在此基础上边也对应。
threshold: 只有子图在图集中出现的次数超过定义的threshold时,才能被称为是频繁的。
2.1 Combinatorial optimization problem
频繁子图的特征提取可以被认为是组合优化问题,我们定义 D D D是特征的总集合,在预测当中, ε ⊆ D \varepsilon \sube D ε⊆D是决定图分类的特征。
我们定义 ε \varepsilon ε的相关性是 q ( ε ) q(\varepsilon) q(ε)。用于衡量它的类区分性。
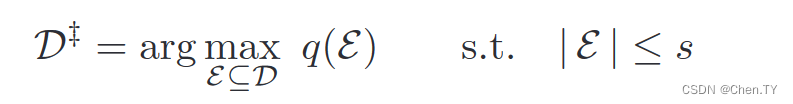
显然由于指数空间的问题,我们需要一些启发式算法并且保证near-optimal。
2.2 Feature Selection and Submodularity
本文的贪心算法就是从0慢慢的将feature集变大,用一个子模函数作为目标函数,每轮迭代增加。由于子模性质,最后我们选出的近似解跟实际最优解会有 1 − 1 e 1 - \frac{1}{e} 1−e1的差别。
2.3 gSpan
在寻找频繁子图时,我们通常需要两步,第一步是生成一些频繁子图候选集,第二步是检查候选集的出现频率。第二步涉及到子图同构,这是个NP-C问题,不过目前已经有许多方法已经可以较为高效的解决这个问题。而大部分频繁子图挖掘算法关注于如何生成一些频繁子图候选集。
gSpan使用的是一种扩展方法,它是基于DFS树的一种方法。
我们定义root为最初始访问的节点- v 0 v_0 v0, v n v_n vn是最后访问的节点,也称为right-most节点。
而从根到最右节点的这条路径被称为最右路径。
我们定义的right-most extension就是指一条新边可以是最右节点向最右路径中的一个点连线(后扩展),也可以是最右路径上的节点独自向外扩展的一条边(前扩展)。下图中 ( v 0 , v 1 , v 3 ) (v_0,v_1,v_3) (v0,v1,v3)是最右路径。
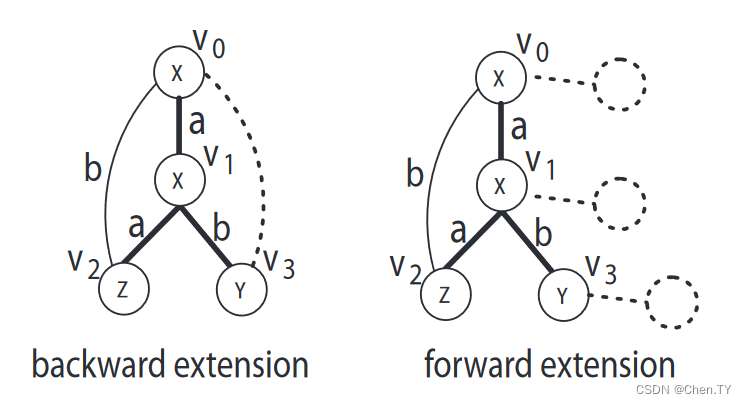
gSpan会选择建立唯一一棵DFS树,并且在这之上进行前后扩展。在此过程中,gSpan还会检测目前生成的图是否没有被处理过。

总的来说就是一个从空集开始,不断在最右路径上加边并且递归的过程。
当使用gSpan后,一个自然的方法就是用01向量来表示每张图。

其实也就是把频繁子图是否出现作为01,看看每张图中出现了哪些频繁子图。
2.4 Definition of CORK

根据文章中的定义,我们所说的Correspondence就是一对 ( v i , v j ) (v^i,v^j) (vi,vj),它们的indicate向量是相互对应的特征。
我们定义q是CORK (Correspondence-based Quality Criterion)
q ( ε ) = ( − 1 ) ∗ c o r r e s p o n d e n c e 的个数 q(\varepsilon) = (-1)*correspondence的个数 q(ε)=(−1)∗correspondence的个数
q函数是子模的,这是因为添加一个特征,显然会对小数据集的q进行更多增加(correspondence减少)。
简单总结的来说,其实correspondence就是表示两张图是否含有相同的一些子图。
2.5 Computation of CORK
特征X的CORK的值可以是不同类间都包含的X的对数或者是不包含X的对数。
q
(
{
x
}
)
=
−
(
A
X
0
∗
B
X
0
+
A
X
1
∗
B
X
1
)
q(\left\{x\right\})= -(A_{X_0}*B_{X_0}+A_{X_1}*B_{X_1})
q({x})=−(AX0∗BX0+AX1∗BX1)

等价类就是指它们的indicator vector是一样的。根据等价类划分,那么上面的计算都可以进行了。
由于频繁子图挖掘的时候,threshold的设置十分重要,因此接下来将描述如何将CORK放入gSpan且只挖掘discriminative power大的子图。
2.6 Pruning gSpan’s search space via CORK
本文将推导如何计算所有子图S的超图们的CORK-value上界,这将有利于剪枝。
定理2.3:
S,T是频繁子图,且T是S的超图, A S 1 A_{S_1} AS1表示A类中包含S的图, A S 0 A_{S_0} AS0表示A类中不包含S的图。我们类似定义 B S 0 , B S 1 B_{S_0},B_{S_1} BS0,BS1。
由此我们可以得知
q
(
{
T
}
)
≤
q
(
{
S
}
)
+
max
(
A
S
1
∗
(
B
S
1
−
B
S
0
)
,
(
A
S
1
−
A
S
0
)
∗
B
S
1
,
0
)
q(\left\{T\right\}) \le q(\left\{S\right\})+\max(A_{S_1}*(B_{S_1}-B_{S0}),(A_{S_1}-A_{S_0})*B_{S_1},0)
q({T})≤q({S})+max(AS1∗(BS1−BS0),(AS1−AS0)∗BS1,0)
- A类miss+B类hit
- A类hit+B类miss
- 不变
首先提醒一下大家,我们所要求的q是衡量discriminative power的指标。那么最好的情况下,A类将全部hit,而B类将全部miss。反之亦然。
所以我们可以得出上述结论。也就是我们计算出了CORK的上界。
该不等式可以直接用于贪心算法的第一次选择,而后续的上界我们并不需要考虑全部图,而是只要分别计算等价类中的correspondence并求和累计即可。具体细节观察原文。
并且我们可以轻易的看出一个剪枝策略—当T的MAX-CORK值比最优值小,那么就可以不用剪枝T的分支,因为显然不可能更优。
2.7 CORK for multi-class problems
本部分和一下部分暂且略过。。。
观察原文。
并且我们可以轻易的看出一个剪枝策略—当T的MAX-CORK值比最优值小,那么就可以不用剪枝T的分支,因为显然不可能更优。
2.7 CORK for multi-class problems
本部分和一下部分暂且略过。。。
















 6020
6020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











