







Hierarchical Navigable Small World (HNSW)算法
HNSW的主要idea是构建一个图,使得两个点之间只需要很短的几跳究竟能到达(这也是大部分graph-based算法所关注到的)
根据现实世界的六度握手原理:世界上所有的人都能够在六次联系内联系到另一个人
在介绍HNSW的工作流程前,先介绍一下跳表(skip lists)和可导航小世界(navigable small world)。
Skip lists: 这是一个概率数据结构,可在排序列表中插入和搜索元素,平均耗时为
O
(
l
o
g
n
)
O(logn)
O(logn)。跳表由多层列表组成,最底层是原始列表(所有元素),层数越高,被跳过的元素越多,连接数越少。
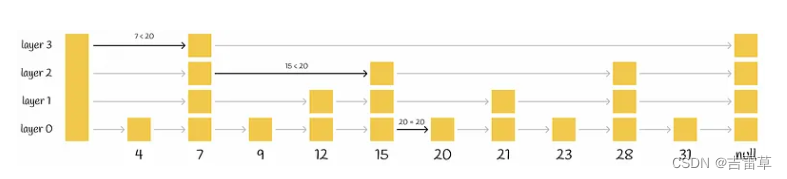
对某个值的搜索过程从最高层开始,并将下一个元素与该值进行比较。如果该值小于或等于该元素,则算法进入下一个元素。否则,搜索程序会下降到连接更多的下一层,并重复相同的过程。最后,算法下降到最底层,找到所需的节点。
Navigable Small World: 是一个搜索复杂度为多对数$ T = O(logᵏn)$的图,它使用贪婪路由。路由指的是搜索过程从低度顶点开始,到高度顶点结束。由于低度顶点的连接很少,算法可以在它们之间快速移动,有效地导航到最近的邻居可能所在的区域。然后,算法逐渐切换到高度顶点,在该区域的顶点中寻找最近的邻居。
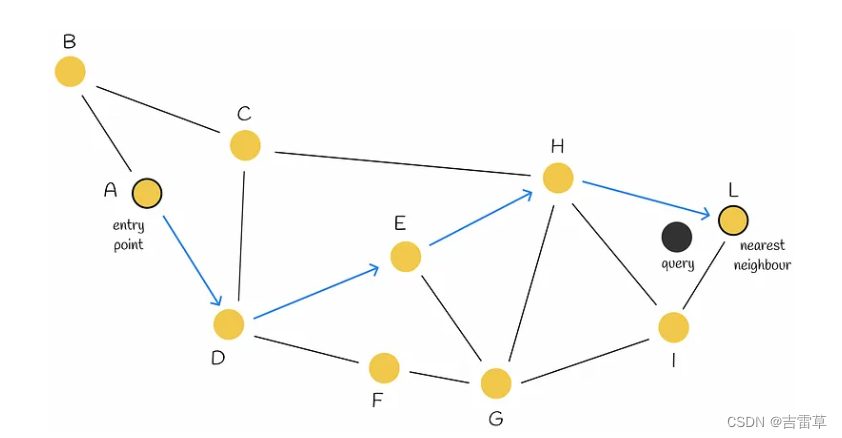
downhill寻找过程,但是遇到early stopping的问题。
NSW图构建:每个新点都向其K近邻连边,那么早连的边就会成为long range link。
1 HNSW算法
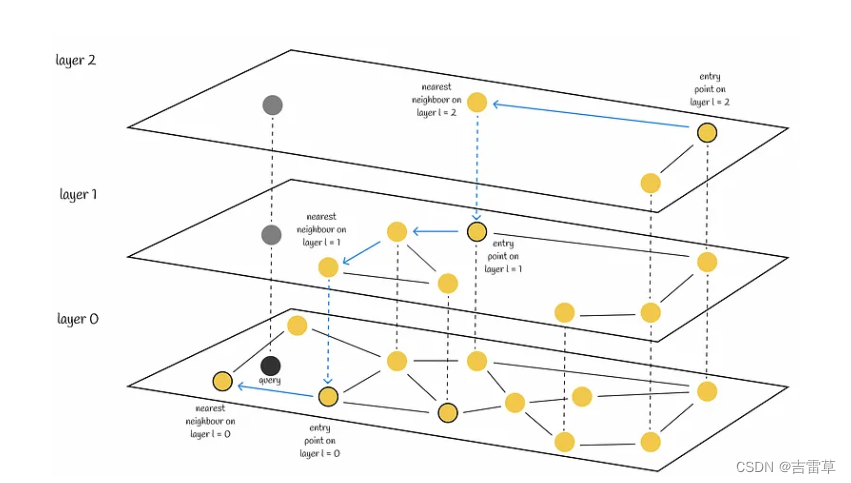
HSNW基于与跳表和可导航小世界相同的原理。它的结构是一个多层图,顶层的连接较少,底层的区域较密集。
1.1 Search
搜索从最高层开始,每当在各层节点中贪心找到当前最近邻居时,就向下搜索一层。最终,在最底层找到的近邻就是查询的答案。
与 NSW 类似,HNSW 也可以通过使用多个入口点来提高搜索质量。与在每一层只寻找一个近邻不同,我们会寻找与查询向量最近的 efSearch(一个超参数)近邻,并将这些近邻中的每一个作为下一层的切入点。
1.2 Construction
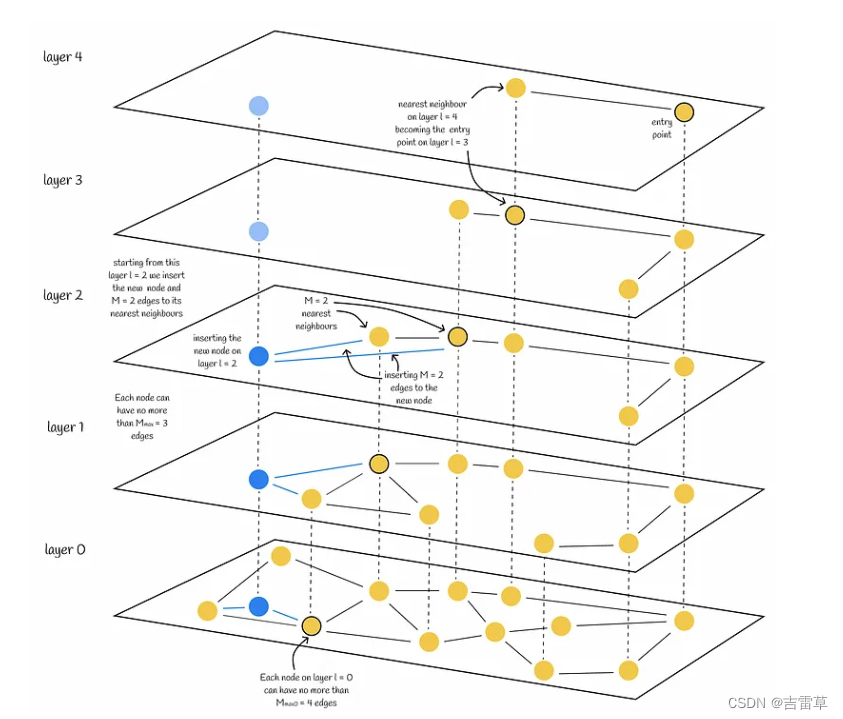
Choosing the maximum layer: HNSW 中的节点一个接一个地按顺序插入。每个节点都被随机分配一个整数 l,表示该节点在图中能出现的最大层数。例如,如果 l = 1,则只能在 0 层和 1 层找到该节点。 为每个节点随机选择 l,其概率分布呈指数衰减,并由非零乘数 M l M_l Ml归一化( M l M_l Ml = 0 会导致 HNSW 中只有一层,搜索复杂度无法优化)。通常情况下,大多数 l 值应等于 0,因此大多数节点只出现在最底层。 M l M_l Ml值越大,节点出现在较高层的概率就越大。
Insertion: 节点被赋值 层数l 后,其插入分为两个阶段:
- 1 算法从顶层开始,贪心寻找最近的节点。然后将找到的节点作为下一层的入口点,继续搜索过程。一旦到达第 l 层,插入就进入第二步。
- 2 从第 l 层开始,算法在当前层插入新节点。然后,该算法与步骤 1 相同,但不再只寻找一个最近的邻居,而是寻找efConstruction(超参数)最近的邻居。然后,从efConstruction 近邻中选出 M 个,并建立从插入节点到它们的边。之后,算法进入下一层,每个找到的 efConstruction 节点都是一个入口点。新节点及其边插入最底层 0 后,算法结束。
Choosing values for construction parameters:
- 根据模拟结果,M 的理想值介于 5 和 48 之间。M 值越小,越适合低召回率或低维数据,而 M 值越大,越适合高召回率或高维数据。
- efConstruction 的值越大,意味着搜索的深度越深,因为会探索到更多的候选方案。不过,这需要更多的计算。作者建议选择这样一个 efConstruction 值,即在训练过程中召回率接近 0.95-1。
- 此外,还有一个重要参数 M m a x M_{max} Mmax–顶点可拥有的最大边数。除此以外,还有相同的参数 M m a x 0 M_{max0} Mmax0,但用于最底层。建议选择 M m a x M_{max} Mmax接近 2 * M 的值。同时, M m a x M_{max} Mmax = M 会导致高召回率时性能不佳。
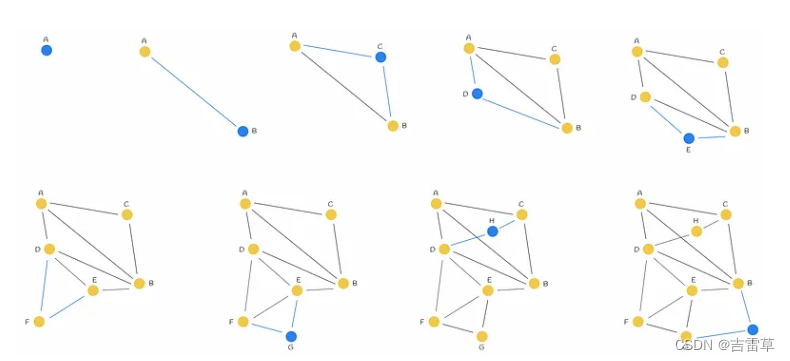
Candidate selection heuristic: 在节点插入过程中,会从 efConstruction 候选节点中选择 M 个节点来为其建立边。让我们讨论一下选择这 M 个节点的可能方法。最简单的方法是选择 M 个最接近的候选节点。然而,这并不总是最佳选择。下面是一个示例:
想象一个结构如下图所示的图形。如图所示,有三个区域,其中两个区域互不相连(位于左侧和顶部)。因此,举例来说,从 A 点到 B 点需要穿过另一个区域,路径很长。如果能以某种方式将这两个区域连接起来,导航效果会更好。
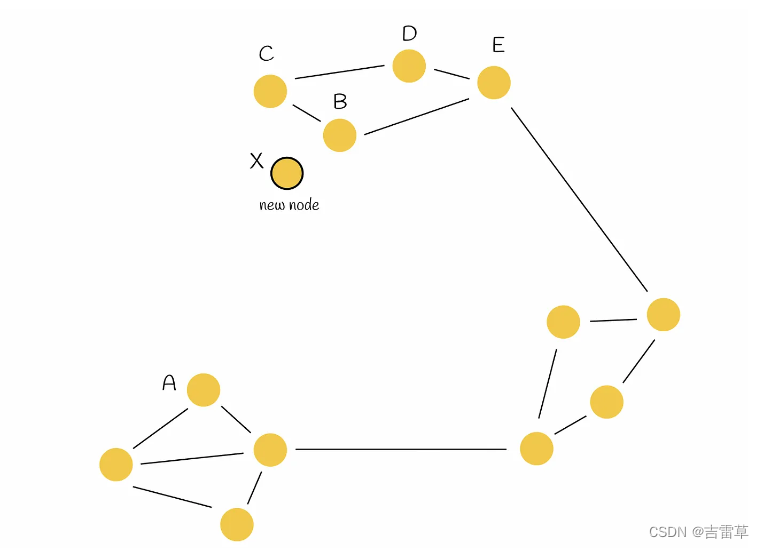
解决方案:启发式选择第一个最近的邻居(本例中为 B),并将插入的节点(X)与之相连。然后,算法按照排序顺序依次选取另一个最近的邻居(C),只有当其与新节点(X)的距离大于该邻居与所有已连接顶点(B)到新节点(X)的距离时,才与其建立一条边。之后,算法会继续下一个最近的邻居,直到建立 M 条边为止。
回到示例,启发式程序如下图所示。启发式选择 B 作为 X 的最近邻居,并建立边 BX。然后,算法选择 C 作为下一个最近的邻居。但是,这次 BC < CX。这表明在图中添加边 CX 并不是最佳选择,因为已经存在边 BX,而且节点 B 和 C 相距很近。同样的类比也适用于节点 D 和 E。然后,算法检查节点 A。因此,新边 AX 和两个初始区域彼此相连。
1.3 Complexity
插入过程和搜索过程的工作原理非常相似。因此,插入单个顶点所需的时间为 O ( l o g n ) O(logn) O(logn)。HNSW 的构建需要 O ( n l o g n ) O(nlogn) O(nlogn) 的时间。
2 Combining HNSW with other methods
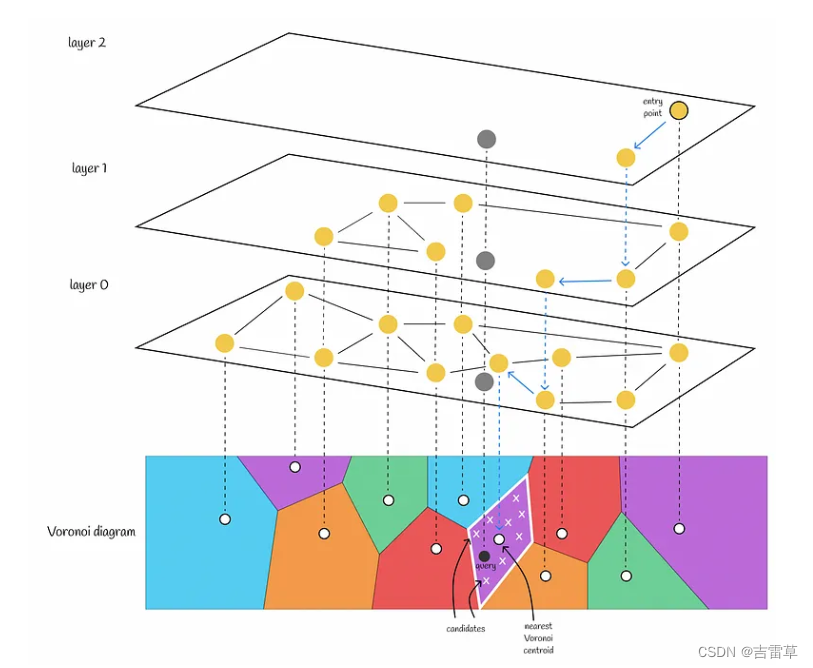
HNSW 在 IndexIVFPQ 中扮演着粗量化器的角色,这意味着它将负责寻找最近的 Voronoi 分区,从而缩小搜索范围。为此,必须在所有 Voronoi 中心点上建立 HNSW 索引。当给出一个查询时,HNSW 将用于查找最近的 Voronoi 中心点(而不是像以前那样通过比较与每个中心点的距离来进行强行搜索)。然后,在相应的 Voronoi 分区内对查询向量进行量化,并使用 PQ 代码计算距离。
前那样通过比较与每个中心点的距离来进行强行搜索)。然后,在相应的 Voronoi 分区内对查询向量进行量化,并使用 PQ 代码计算距离。


















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











