







 ProductQuantization(PQ)是一种向量压缩技术,用于支持近似近邻搜索(ANNS)。它通过将高维向量分割并分别量化到低维子空间,然后用短编码表示,以估算向量间的欧几里得距离。PQ流程包括分割、训练和编码,其中训练阶段使用K-means聚类生成编码字典。在搜索时,通过查询编码和距离表实现快速估计。PQ显著减少了存储需求,例如,将128维向量压缩至8字节。
ProductQuantization(PQ)是一种向量压缩技术,用于支持近似近邻搜索(ANNS)。它通过将高维向量分割并分别量化到低维子空间,然后用短编码表示,以估算向量间的欧几里得距离。PQ流程包括分割、训练和编码,其中训练阶段使用K-means聚类生成编码字典。在搜索时,通过查询编码和距离表实现快速估计。PQ显著减少了存储需求,例如,将128维向量压缩至8字节。
Product Quantization for Similarity Search
Paper Link: Product Quantization for Nearest Neighbor Search
Blog Link: Product Quantization for Similarity Search
1 引言
PQ乘积量化是一种用于向量压缩的技术,其目标是将高维向量压缩为低维以支持近似近邻搜索(ANNS)。
该方法的主要思想如下:首先,将向量空间映射到低维向量子空间的笛卡尔积上,然后对每个子空间分别进行量化。其次,将一个向量表示为多个子空间量化结果的短编码组合。通过这种编码,可以估算两个向量之间的欧几里得距离(Euclidean Distance)。需要强调的是,PQ并非用于降维。
PQ方法将向量的数值转换成短编码,可以将其视为符号化的表现形式。
2 PQ流程
2.1 分割
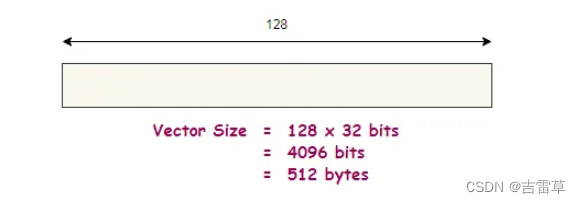
假设我们以及从数据库中获取了一堆128维的向量,因此一个向量的总大小为128*32 bits = 4096 bits (512 bytes)。
我们将向量切成多段,下面展示一种分成8段,每段由16 bits的分割方式。
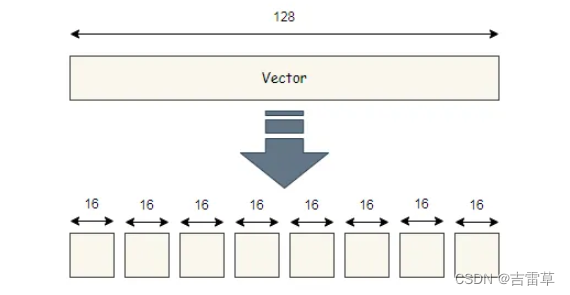
如图所示,向量被分割到8个子空间当中。
2.2 训练
我们通过在每个子空间执行K-means来训练向量。K-means会生成K个中心点(Centroid)。这些中心点和segment的长度是一样的,其实就是子空间中的一些点。
这些中心点被认为是重建值(reproduction values)。中心点的集合被叫做编码字典(codebook)。如果我们设置k=256,那么我们就会有256*8=2048 个centroids。
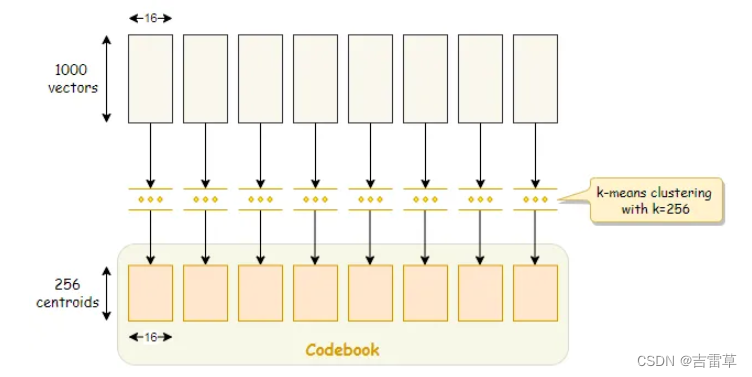
这些中心点被称为reproduction values是因为他们通过中心点的合并来近似的重建原vector。将8个子空间所属的centroid(16bits)拼接起来就是原向量的近似值。这是一种有压缩损失的方式。
2.3 编码
当训练完成后,每个向量的每个字段都可以找到在子空间离他最近的centroid。其实就是从一个子空间的256个centroids里面找到最近的一个。
找到后我们使用id来替换这个centroid的真实值(0-255)。
通过这种操作我们获取了vector的压缩向量。这就被称为PQ codes。
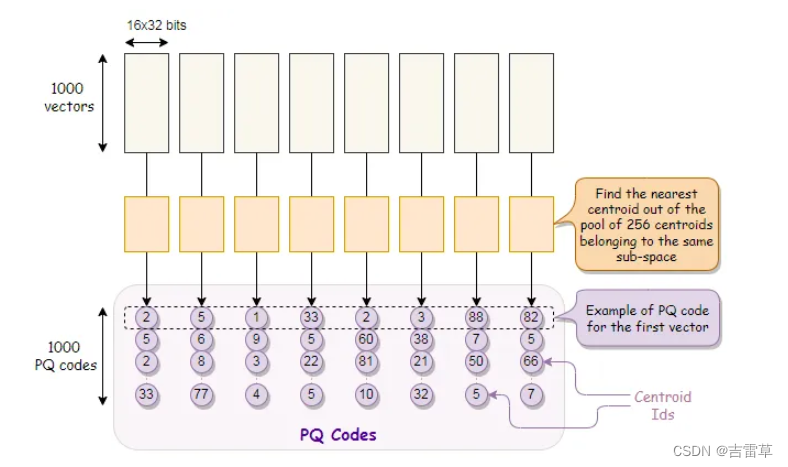
当我们选择K=256的时候,每个子段会被压缩成8 bits。
因此每个vector被压缩成8*8 bits = 8 bytes。这节省了大量的空间。
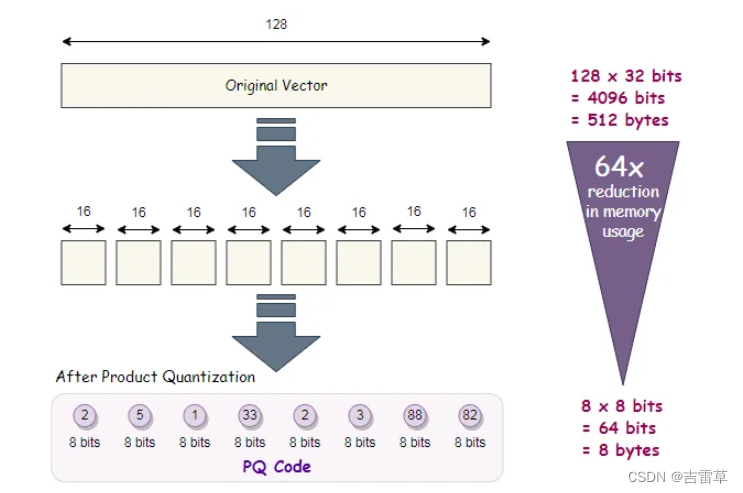
对于M个子段,一个PQ编码所需空间大小为M*(log base 2 of k)bits.
3 PQ搜索
在ANNS中,我们使用asymmetric distance computation (ADC)来估计vector-to-centroid的距离。
- 我们首先将查询向量q分割为相同的子段
- 对于每个q,我们提前计算和所有中心点的欧几里得距离。
- 这些距离在distance table d中存储。下图是distance table。
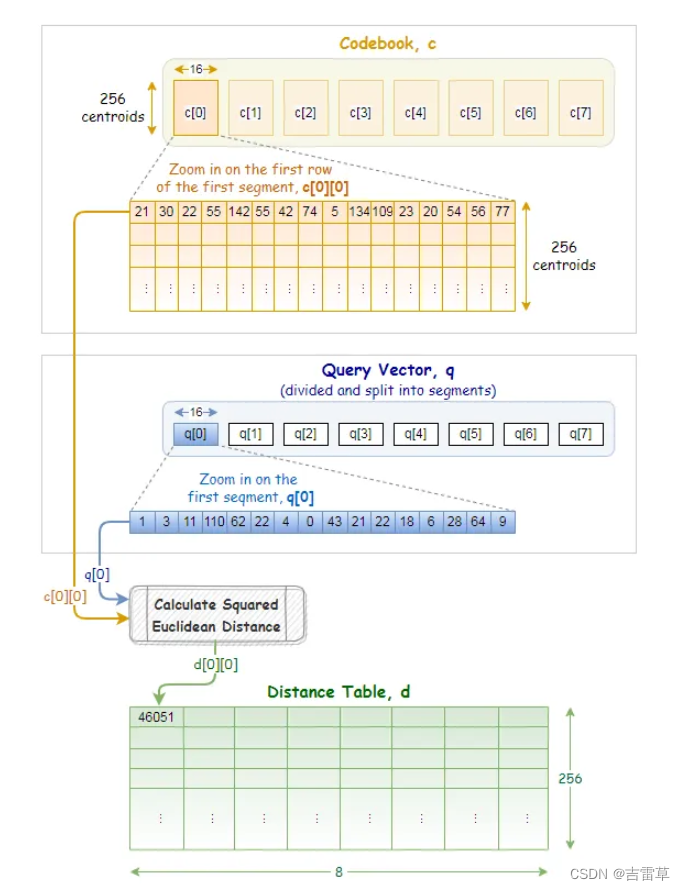
现在我们可以通过查表获得距离了。
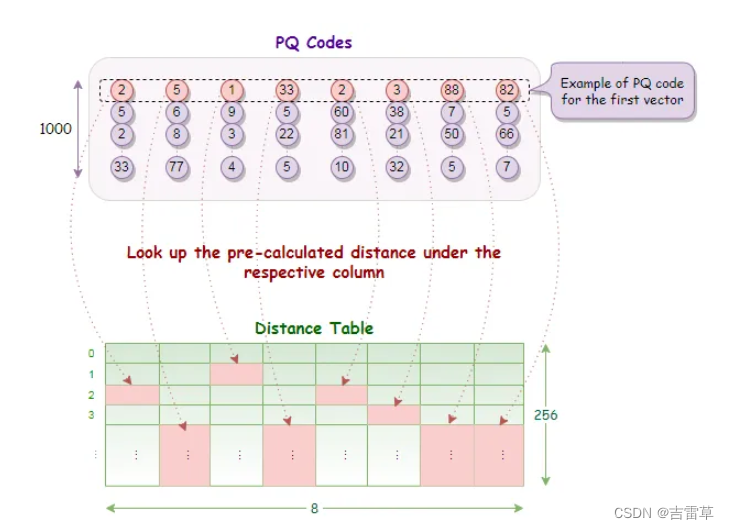
对于向量,我们通过查询它的PQ codes(也就是这个向量的当前子空间最近的centroid的ID值),通过这个ID就可以在distance table中找到对应的距离值。
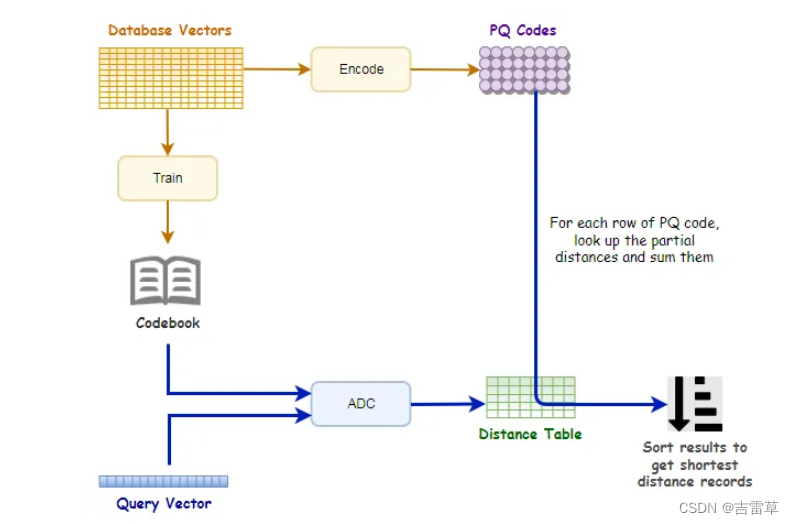
4 Python代码
import numpy as np
from scipy.cluster.vq import kmeans2, vq
from scipy.spatial.distance import cdist
def PQ_train(vectors, M, k):
s = int(vectors.shape[1] / M) # Dimension (or length) of a segment.
codebook = np.empty((M, k, s), np.float32)
for m in range(M):
sub_vectors = vectors[:, m*s:(m+1)*s] # Sub-vectors for segment m.
codebook[m], label = kmeans2(sub_vectors, k) # Run k-means clustering for each segment.
return codebook
#-----------------------------------------------------------------------------------------------
def PQ_encode(vectors, codebook):
M, k, s = codebook.shape
PQ_code = np.empty((vectors.shape[0], M), np.uint8)
for m in range(M):
sub_vectors = vectors[:, m*s:(m+1)*s] # Sub-vectors for segment m.
centroid_ids, _ = vq(sub_vectors, codebook[m]) # vq returns the nearest centroid Ids.
PQ_code[:, m] = centroid_ids # Assign centroid Ids to PQ_code.
return PQ_code
#-----------------------------------------------------------------------------------------------
def PQ_search(query_vector, codebook, PQ_code):
M, k, s = codebook.shape
#=====================================================================
# Build the distance table.
#=====================================================================
distance_table = np.empty((M, k), np.float32) # Shape is (M, k)
for m in range(M):
query_segment = query_vector[m*s:(m+1)*s] # Query vector for segment m.
distance_table[m] = cdist([query_segment], codebook[m], "sqeuclidean")[0]
#=====================================================================
# Look up the partial distances from the distance table.
#=====================================================================
N, M = PQ_code.shape
distance_table = distance_table.T # Transpose the distance table to shape (k, M)
distances = np.zeros((N, )).astype(np.float32)
for n in range(N): # For each PQ Code, lookup the partial distances.
for m in range(M):
distances[n] += distance_table[PQ_code[n][m]][m] # Sum the partial distances from all the segments.
return distance_table, distances
#-----------------------------------------------------------------------------------------------
# Test case
M = 8 # Number of segments
k = 256 # Number of centroids per segment
vector_dim = 128 # Dimension (length) of a vector
total_vectors = 1000000 # Number of database vectors
# Generate random vectors
np.random.seed(2022)
vectors = np.random.random((total_vectors, vector_dim)).astype(np.float32) # Database vectors
q = np.random.random((vector_dim, )).astype(np.float32) # Query vector
# Train, encode and search with Product Quantization
codebook = PQ_train(vectors, M, k)
PQ_code = PQ_encode(vectors, codebook)
distance_table, distances = PQ_search(q, codebook, PQ_code)
# All the distances are returned, you may sort them to get the shortest distance.`


















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











