







一.深度学习简介
***deep learning***
深度学习
- 有监督学习:利用一直类别的训练样本进行学习。
- 无监督学习:对没有概念标记(分类)的训练样本进行学习。如聚类
- 半监督学习:利用少量标注样本和大量未标注样本进行训练和分类。
常用的深度学习框架
- pytorch——Facebook
- tensorflow——Google
- caffe—— 賈揚清
- …
常用模块库
- matplotlib——2D数据绘图包
- numpy——数值计算包,存储计算大型矩阵
- pandas——数据分析包
- …
d2l常用名词
- 前馈神经网络(FNN):有向无环
- 循环神经网络(RNN):有向循环
- 卷积神经网络(CNN):特殊的FNN,非全连接、权值共享
- 对抗生成网络(GAN):生成式模型+判别式模型
- …
- 训练集:测试集=7:3
常见公式
正则化:为了防止过拟合现象,加入正则化项,常用有L1范数和L2范数。
L0范数:||x||0为x向量 各个非零元素的 个数
L1范数:||x||1为x向量 各个元素 绝对值之和
L2范数:||x||2为x向量 各个元素 平方和的开方
Lp范数:||x||p为x向量 各个元素 p次方和的1/p方
L∞范数:||x||∞为x向量 各个元素绝对值最大 那个元素的绝对值
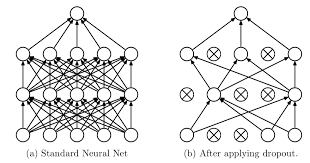
正常的正则化除了L1、L2正则化,还有常用的Dropout方法,以概率舍弃部分神经元,
梯度下降(gradient descent)
- 批量梯度下降(BGD-batch gradient descent):每一步迭代都使用训练集的所有内容,能够保证计算出的梯度为0,不需要逐渐减小学习率,但计算量巨大。
- 随机梯度下降(SGD-stochastic gradient descent):随机抽取样本 更新参数。速度快,但每次优化方向不一定全局最优,最终结果在全局最优解的附近。
Momentum
动量:前几次的梯度会参与计算。
前后梯度一致时,加速学习;不一致时,抑制震荡
补充…















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









