







在无锁编程的世界里,ABA问题是一个没有办法回避的实现问题。我们有Read-Copy Update(RCU)这个法宝,帮助我们方便的实现很多的无锁算法数据结构。
本文会首先简略介绍RCU的基本概念,然后通过例子来详细阐述RCU的读写概念,最后简单介绍RCU目前的实现方案。
什么是RCU?
引用一下这篇著名的RCU科普文的开头:
Read-copy update (RCU) is a synchronization mechanism that was added to the Linux kernel in October of 2002. RCU achieves scalability improvements by allowing reads to occur concurrently with updates.
首先,RCU是一种同步机制;其次RCU实现了读写的并行;最后,2002开始被Linux kernel所使用。 RCU利用一种Publish-Subscribe的机制,在Writer端增加一定负担,使得Reader端几乎可以Zero-overhead。
RCU适合用于同步基于指针实现的数据结构(例如链表,哈希表等),同时由于他的Reader 0 overhead的特性,特别适用用读操作远远大与写操作的场景。例如在Linux内核中的routing模块(与DNS非常相关)则用到来RCU来实现高性能。
一个指针的例子
假设我们有下面这个结构定义:
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
那么在不考虑gp这个指针会被改变的情况下,我们可以这样的去进行读操作:
struct foo* p = gp;
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
一切看起来都很简单。如果我们现在有一个Writer是像下面这样去改变gp呢?
struct foo* p = kmalloc(sizeof(*p), GFP_KERNEL);
struct foo* tmp_gp = gp;
p->a = 1;
p->b = 2;
p->c = 3;
gp = p;
free(tmp_gp);
读者们知道会发生什么吗?
如果在有几个Reader在获取了旧的gp之后,被context switch,然后Writer就把这个旧的gp(这Writer端是tmp_gp)删除了。那么后面当Reader再次被调度,就会造成segfault。就也是我们在学习多线程编程里面最基本的race condition,一般来说我们就会对gp指针加上mutex或者是rwlock,这样就可以达到互斥的效果。
那么如果是RCU的话,怎么解决呢?
RCU的读写锁
RCU里面,通过一种类似于读写锁的方式来实现互斥,在Reader端,可以用rcu_read_lock/unlock来保护:
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
这里,需要保护的代码会在read_lock/unlock之间,和读写锁的读锁用法一致。
而在Writer端,我们会用一个synchronize_rcu来等待所有的使用旧的gp都结束之后再删除。
q = kmalloc(sizeof(*p), GFP_KERNEL);
q->a = 1;
q->b = 2;
q->c = 3;
rcu_xchg_pointer(&gp, q);
synchronize_rcu();
kfree(p);
因为在synchronize_rcu之后,RCU可以保证所有持有旧的gp的读锁都已经结束,所以我们可以放心的删除旧的gp。
注意上面的Writer例子里面,只允许同一时间有一个Writer的存在。如果有多个Writer的话,需要修改一下,在这出于简单的考虑,暂不考虑多Writer的情况。
这里最关键的就是synchronize_rcu这个函数了,正是它使得RCU能正确的工作。
Grace Period
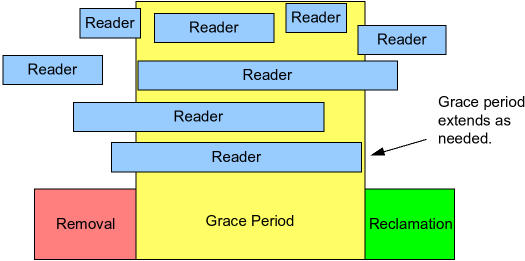
在RCU里面,有两个关键的时间区间,一个就是Reader Lock时间,一个是Grace Period。上面的图可以大概的了解一下这两者之间的关系。
Reader Lock时间顾名思义就是然后Reader在rcu_read_lock/unlock之间的时间。
而Grace Period的意思是,从Writer开始修改受保护的数据结构开始,到所有的Reader Lock都结束了至少一次的时间段。
假设我们称Grace Period开始的时间点是T:
- 如果一个Reader Lock时间横跨T,则Grace Period必然结束于这个Reader Lock结束之后。
- 如果一个Reader Lock开始于T之后,则Grace Period可能于这个Reader Lock的任意时间结束。也就是可能在Reader Lock开始之前结束,也可能在Reader Lock中间结束,也可能在Reader Lock结束之后才结束。
了解了上面这两个概念之后,我们可以通过简单的证明知道,在Grace Period之后,所有的Reader都不可能获取到在T时间之前的旧数据。所以在Grace Period之后,作为Writer是可以放心的删除旧数据的。
所以上面例子里面Writer的synchronize_rcu,实际上就是等待Grace Period的结束。
RCU的实现
由于RCU最开始是从Linux kernel里面实现的,kernel里面的实现非常依赖于整个内核的运行机制(比如Scheduler,软中断等),所以要把它port出来在用户态使用的话,难度并不小。 所幸目前已经有个开源的Userspace RCU实现——liburcu,不单只实现了RCU算法,而且有几种实现方案,从侵入式的到非侵入式的。而且这个库已经在比较多的项目中用到,比如比较出名的LTTng。
liburcu提供了以下几种RCU实现:
- rcu-qsbr:性能最好的RCU实现,可以做到reader 0 zerohead,但是需要改动代码,侵入式。
- rcu-signal:性能仅次于qsbr的实现,不需要改动代码,代价是需要牺牲一个signal给urcu实现。
- rcu-generic:性能最差的rcu实现(但也比mutex强多了),不需要改动代码,可以作为初始的第一选择。
本文会详细剖析qsbr(quiescent-state-based RCU)的实现。本文的代码来自liburcu,所以代码的协议和liburcu保持一致,使用LGPL协议。
一个例子
假设我们有下面这个需求:
一个全局的gs_foo指针指向一个结构体,有几个读线程不断的读这个结构体里面的数据,求和。 这个结构体可能在某些时刻被一个写线程更新。
用liburcu的qsbr实现的话,会是下面这样的代码:
struct Foo { int a, b, c, d; };
void ReadThreadFunc() {
struct Foo* foo = NULL;
int sum = 0;
rcu_register_thread();
for (int i = 0; i < 100000000; ++i) {
for (int j = 0; j < 1000; ++j) {
rcu_read_lock();
foo = rcu_dereference(gs_foo);
if (foo) {
sum += foo->a + foo->b + foo->c + foo->d;
}
rcu_read_unlock();
}
rcu_quiescent_state();
}
rcu_unregister_thread();
}
void WriteThreadFunc() {
while (!gs_is_end) {
for (int i = 0; i < 1000; ++i) {
struct Foo* foo =
(struct Foo*) malloc(sizeof(struct Foo));
foo->a = 2; foo->b = 3;
foo->c = 4; foo->d = 5;
rcu_xchg_pointer(&gs_foo, foo);
synchronize_rcu();
if (foo) {
free(foo);
}
}
}
}
这里可以看到几个关键点:
- 对于读者
- 线程开始的时候需要调用
rcu_register_thread()进行注册,线程结束的时候需要调用rcu_unregister_thread()进行注销。 - 对于共享数据区的访问需要用
rcu_read_lock()和rcu_read_unlock()来表示临界区。 - 对于共享数据的指针,需要用
rcu_dereference()来获取。 - 线程时不时需要调用
rcu_quiescent_state()来声明线程在quiescent state。
- 线程开始的时候需要调用
- 对于写者
- 新的数据初始化需要在替换指针之前就完成。
- 指针替换需要调用
rcu_xchg_pointer()来完成。 - 替换完数据之后,需要调用
synchronize_rcu()来等待Grace Period的结束。 - 在
synchronize_rcu()结束之后,我们就可以放心的删除旧数据了。
接下来我们来看看这些函数是怎么实现的。
QSBR关键数据结构
在RCU里面,最核心的就是Grace Period了。在qsbr里面,Grace Period是用一个全局的unsigned long(64 bits)的counter——rcu_gp来表示。 每新开始一个Grace Period,就往这个counter上加一。所以这个数值我们可以称之为gp号。
而对于每个读线程,都会有一个rcu_reader结构,这个结构里面存着最近一次的gp号缓存,以及一些额外的数据。
struct rcu_gp {
unsigned long ctr;
int32_t futex;
} __attribute__((aligned(CAA_CACHE_LINE_SIZE)));
extern struct rcu_gp rcu_gp;
struct rcu_reader {
/* Data used by both reader and synchronize_rcu() */
unsigned long ctr;
struct cds_list_head node
__attribute__((aligned(CAA_CACHE_LINE_SIZE)));
int waiting;
pthread_t tid;
unsigned int registered:1;
};
extern DECLARE_URCU_TLS(struct rcu_reader, rcu_reader);
在qsbr里面,read_lock和read_unlock都不会改变本线程的gp缓存,只有在rcu_quiescent_state()调用的时候,会从全局的rcu_gp里面获取最新的gp号,更新到本线程缓存。
当写线程执行到synchronize_rcu()的时候,实际上就会先把rcu_gp加一,然后等待所有的读线程的gp缓存都等于最新的gp号,然后才返回。这也就是qsbr实现的Grace Period机制。
读线程函数
接下来我们来看看对于读线程来说,几个关键函数是怎么实现的。
线程注册、注销
在qsbr里面,每一个读线程都需要调用rcu_register_thread()进行注册,否则写线程并不知道该读线程的存在。而在线程结束之前也必须调用rcu_unregister_thread()进行注销,否则会造成写线程死锁。
DEFINE_URCU_TLS(struct rcu_reader, rcu_reader);
static CDS_LIST_HEAD(registry);
static pthread_mutex_t rcu_registry_lock = PTHREAD_MUTEX_INITIALIZER;
void rcu_register_thread(void) {
URCU_TLS(rcu_reader).tid = pthread_self();
assert(URCU_TLS(rcu_reader).ctr == 0);
mutex_lock(&rcu_registry_lock);
assert(!URCU_TLS(rcu_reader).registered);
URCU_TLS(rcu_reader).registered = 1;
cds_list_add(&URCU_TLS(rcu_reader).node, ®istry);
mutex_unlock(&rcu_registry_lock);
_rcu_thread_online();
}
void rcu_unregister_thread(void) {
_rcu_thread_offline();
assert(URCU_TLS(rcu_reader).registered);
URCU_TLS(rcu_reader).registered = 0;
mutex_lock(&rcu_registry_lock);
cds_list_del(&URCU_TLS(rcu_reader).node);
mutex_unlock(&rcu_registry_lock);
}
上面的代码首先定义了TLS变量rcu_reader,使得每个读线程都有一个rcu_reader。然后定义一个双向链表registry,用来保存所有读线程的rcu_reader。这会在写线程的synchronize_rcu()用到。还有一个mutex来保护这个链表。
在rcu_register_thread里面,主要就是往这个链表里面加入本线程的rcu_reader。接着调用_rcu_thread_online来缓存最新的rcu_gp。 rcu_unregister_thread则做相反的事,先清除一些标记,然后把本线程的rcu_reader从链表里面删除。
这两个函数用到了锁,但是由于这两个函数只在线程的开始和结束才会调用,所以对性能基本没有影响。
读临界区
读线程在对公共数据做操作的时候,需要调用rcu_read_lock和rcu_read_unlock来标记临界区:
inline void rcu_read_lock(void) {
urcu_assert(URCU_TLS(rcu_reader).ctr);
}
inline void rcu_read_unlock(void) {
urcu_assert(URCU_TLS(rcu_reader).ctr);
}
可以看到在这两个函数里面实际上什么都没有做,只是assert,说明在O2优化下这就是个空的函数。这也就是为什么urcu-qsbr是zero overhead的原因,因为他的读临界区完全啥事没干!
Quiescent State
而在qsbr里面对于读线程最核心的函数实际上是rcu_quiescent_state(),用来告诉写线程,该读线程已经结束了一批读临界区:
void rcu_quiescent_state(void) {
unsigned long gp_ctr;
urcu_assert(URCU_TLS(rcu_reader).registered);
if ((gp_ctr = CMM_LOAD_SHARED(rcu_gp.ctr)) == URCU_TLS(rcu_reader).ctr)
return;
_rcu_quiescent_state_update_and_wakeup(gp_ctr);
}
这个函数首先看看当前线程的gp号是否已经是最新的,如果是,直接返回;否则调用_rcu_quiescent_state_update_and_wakeup:
void _rcu_quiescent_state_update_and_wakeup(unsigned long gp_ctr) {
cmm_smp_mb();
_CMM_STORE_SHARED(URCU_TLS(rcu_reader).ctr, gp_ctr);
cmm_smp_mb(); /* write URCU_TLS(rcu_reader).ctr before read futex */
wake_up_gp(); /* similar to pthread_cond_broadcast */
cmm_smp_mb();
}
wakeup函数实际上就是把刚刚读出来的最新的gp号存到当前线程的gp缓存里,接着唤醒可能在等待的写线程。这里的三个cmm_smp_mb调用就是memory barrier,防止这个函数之前和之后的操作可能产生的乱序,以及函数中的两步操作之间可能的乱序。
可以从上面看出,核心函数的操作都不复杂,基本都是一些变量的load和store,overhead非常小。
写线程函数——synchronize_rcu
对于写线程,最核心的函数就是synchronize_rcu,等待Grace Period的结束:
void synchronize_rcu(void)
{
CDS_LIST_HEAD(qsreaders);
cmm_smp_mb();
mutex_lock(&rcu_gp_lock);
mutex_lock(&rcu_registry_lock);
if (cds_list_empty(®istry))
goto out;
CMM_STORE_SHARED(rcu_gp.ctr, rcu_gp.ctr + RCU_GP_CTR);
cmm_barrier();
cmm_smp_mb();
wait_for_readers(®istry, NULL, &qsreaders);
cds_list_splice(&qsreaders, ®istry);
out:
mutex_unlock(&rcu_registry_lock);
mutex_unlock(&rcu_gp_lock);
cmm_smp_mb();
}
函数里面的cmm_smp_mb的作用就是为了确保synchronize_rcu之前和之后的读写操作都不会乱序。 然后在函数里面分别对全局rcu_gp和registry进行了加锁,接着看看registry是否为空,如果空则表示没有读线程,可以直接返回。
如果不为空,则把rcu_gp增一。增一的作用就是表示一个新的Grace Period已经开始了。 接着调用wait_for_readers,等待Grace Period的结束。
下面我们来看看wait_for_readers的简化实现(实际实现要复杂很多,这里我们不关心具体的细节,只了解大概思路):
static void wait_for_readers(
struct cds_list_head *input_readers,
struct cds_list_head *cur_snap_readers,
struct cds_list_head *qsreaders)
{
struct rcu_reader *index, *tmp;
cds_list_for_each_entry_safe(
index, tmp, input_readers, node) {
while (index->ctr < CMM_LOAD_SHARED(rcu_gp.ctr)) {
usleep(100);
}
}
}
函数的目的就是等待所有的读线程都更新自己的gp号到最新的gp号。
在synchronize_rcu返回之后,我们可以知道没有任何一个读线程可以获取到旧的共享数据,所以我们可以删除旧数据。
以上就是一个qsbr的RCU实现最核心的代码。
性能
下面我们用一个最简单的代码例子来对urcu和mutex做一下benchmark(详细代码可以看这个repo)。
若干个读线程对一个共享数据不断的读取,而另外一个写线程也不断的更新数据。
如果用urcu来实现上面的逻辑的话,大概是下面这样:
void ReadThreadFunc()
{
struct Foo* foo = NULL;
int sum = 0;
unsigned int i;
int j;
rcu_register_thread();
for (i = 0; i < LOOP_TIMES; ++i) {
for (j = 0; j < 1000; ++j) {
rcu_read_lock();
foo = rcu_dereference(gs_foo);
if (foo) {
sum += foo->a + foo->b + foo->c + foo->d;
}
rcu_read_unlock();
}
rcu_quiescent_state();
}
rcu_unregister_thread();
pthread_mutex_lock(&gs_sum_guard);
gs_sum += sum;
pthread_mutex_unlock(&gs_sum_guard);
}
void WriteThreadFunc()
{
int i;
while (!gs_is_end) {
for (i = 0; i < 1000; ++i) {
struct Foo* foo = (struct Foo*) malloc(sizeof(struct Foo));
foo->a = 2;
foo->b = 3;
foo->c = 4;
foo->d = 5;
rcu_xchg_pointer(&gs_foo, foo);
synchronize_rcu();
if (foo) {
free(foo);
}
}
}
}
下面是在一台16核(hyper-threading 32核)机器上面的benchmark结果。横轴为读线程数,纵轴为时间(单位为秒):
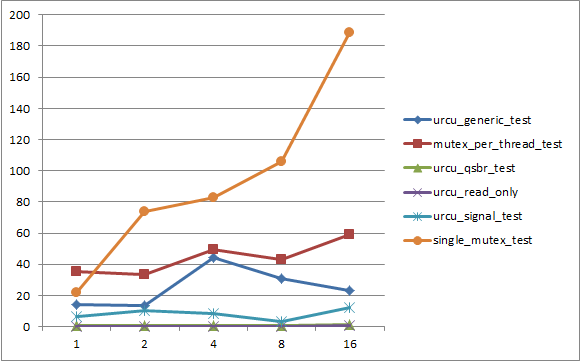
其中:
- urcu_read_only是只有读线程,没有写线程的测试。相当于无锁的版本,也是性能最好的。
- urcu_qsbr_test是用urcu-qsbr的实现
- urcu_signal_test是用urcu-signal的实现
- urcu_generic_test是用urcu-mb的实现
- single_mutex_test是用一个mutex来保护共享数据的实现,也是我们最熟悉的实现。
- mutex_per_thread_test是每一个读线程都独占一个mutex,写线程需要获取所有读线程的mutex来进入临界区。
可以看到,qsbr的性能最接近于read_only,其次是signal,都要比mutex版本好至少4倍,并且时间并不随读线程数目的增加而增加。这说明urcu随着核的增多,能够scale上去。
















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









