







 文章详细介绍了Linux内核中的RCU(Read-CopyUpdate)机制,包括其基本思想、功能、使用场景和核心API。RCU主要用于解决内核中的读多写少的同步问题,通过graceperiod确保数据安全。同时,文章讨论了内核抢占的概念,包括中断、抢占性调度和非抢占性调度的差异,以及它们与进程调度的关系。此外,还探讨了内核同步的必要性和非必要条件,以及不同同步技术如自旋锁和RCU的优缺点。
文章详细介绍了Linux内核中的RCU(Read-CopyUpdate)机制,包括其基本思想、功能、使用场景和核心API。RCU主要用于解决内核中的读多写少的同步问题,通过graceperiod确保数据安全。同时,文章讨论了内核抢占的概念,包括中断、抢占性调度和非抢占性调度的差异,以及它们与进程调度的关系。此外,还探讨了内核同步的必要性和非必要条件,以及不同同步技术如自旋锁和RCU的优缺点。
Why RCU
1. 中断与抢占
当一个进程被时钟中断打断后,kernel运行tick中断处理程序(一般是top half),中断处理程序运行结束后,有两种情况:
-
之前的进程获得CPU继续运行。
-
另一个进程获得了CPU开始运行,而之前的进程则被抢占(preempted)了。
所以,抢占只会发生在tick时钟中断之后,但时钟中断并不是每次都会产生进程抢占。
这里一定是时钟中断sheduler_tick()么?还是指所有的interrupt中断都可能产生抢占?
1.1 进程调度与抢占关系
进程调度是由kernel中scheduler来完成,但是也分为抢占性调度和非抢占性调度。如果内核没有开启抢占,那么OS一旦将CPU分配给某个进程开始运行后,除非该进程执行完毕或因事件主动放弃CPU,否则该进程会一直执行下去,这种情况下因该进程主动放弃CPU或执行结束而放弃CPU导致的进程调度,我理解为非抢占调度,是scheduler被动调度,然后发生进程切换。
而如果内核开启了抢占,那么当某个进程在执行时,来了更高优先级的进程或事件,则可以抢占当前正在运行的进程,scheduler_tick()时钟中断处理中scheduler会去判断,然后安排进程调度,将CPU让给更需要优先运行的任务,进而发生进程切换,这是scheduler主动调度,我理解为抢占调度。
2. 内核同步
2.1 内核抢占
2.1.1 理解内核
内核如同辛勤劳动的你,对,没错,你就是内核。你每天的工作运行至少能满足两类人的需求,老板和客户,所以你每天采取的策略是:
-
老板(中断)发起要求时,如果你(内核)手头空闲,则为老板(中断)服务。
-
如果老板(中断)发起要求时,你(内核)正在为客户(异常包括系统调用)服务,则你(内核)停止为客户(异常)服务,开始为老板(中断)服务。
-
如果老板1(中断1)发起要求时,你(内核)正在为老板2(中断2)服务,那么你(内核)停止为老板2(中断2)服务,开始为老板1(中断1)服务。
-
老板1(中断1)发起要求,你(内核)原本在为客户1(异常1)服务,然后停止,去为老板1(中断1)服务完成,服务完成后,你(内核)没有选择原来的客户1(异常1)继续服务,而是挑选了一个新的客户2(异常2)开始服务。
你的服务就对应于CPU处于内核态时所执行的代码。老板们的请求就是中断,客户们的请求就是异常(这里的异常是用户态进程系统调用和普通的异常的统称)。
2.1.2 抢占
内核分为抢占式和非抢占式,Linux kernel 2.6之后就可以配置选择抢占还是非抢占。
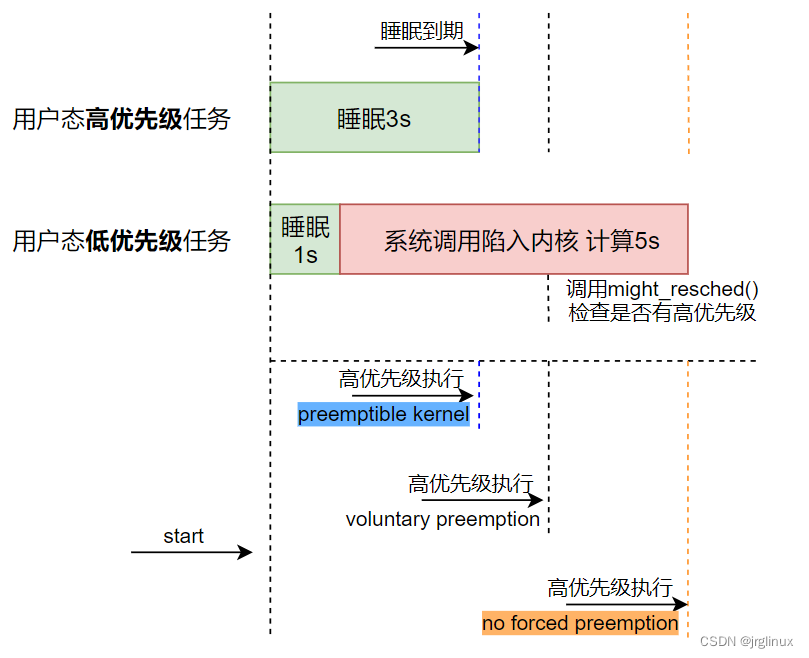
| 抢占模式 | 理解 |
|---|---|
| No Forced Preemption |
上下文切换发生在系统调用返回用户空间的点,不会在内核空间主动抢占 |
| Voluntary Kernel Preemption |
与“no forced”模式类似,但内核开发者可以在进行复杂操作时时不时检查下是否可以reschedule,比如cond_resched()来检查系统是否有更高优先级的任务被唤醒 |
| Preemptible Kernel |
内核里面也可以抢占,系统会有更多的上下文切换,实时性更好,对软实时系统,该选项最佳 对服务器系统,CPU会有一定时间做上下文切换“无用功”,此时就不如no forced |
| Fully Preemptible Kernel |
硬实时系统,除了少数选定的关键部分之外,所有内核代码都是可抢占的 |
Linux内核中抢占注意点
无论是抢占模式还是非抢占模式,运行中的内核态进程都可以主动放弃CPU,比如进程需要等待资源而不得不转入睡眠状态,因为主动放弃CPU而产生的进程切换叫做计划性进程切换。而抢占模式下,内核在响应引起进程切换的异常事件(比如唤醒高优先级进程的中断处理程序)的方式上与非抢占模式下的进程切换有区别,叫做强制性进程切换。
所有的进程切换都有宏switch_to()来完成。非抢占模式下,当前正在运行的内核态进程除非它自己放弃CPU,否则不会发生进程切换(就没有所谓的时间片概念了)。
2.1.3 何时同步必需
进入临界区内,必须采取保护措施。
2.1.4 何时同步非必需
-
中断处理程序和tasklet不必编写成可重入的函数。
-
仅被软中断和tasklet访问的per cpu变量不需要同步。
-
仅被一种tasklet访问的数据结构不需要同步。
3. RCU介绍
3.1 是什么
Linux kernel document中解释:
RCU背后的基本思想可以分为removal(删除)和reclamation(回收)来理解。
removal:删除对旧数据的指针引用,同时还允许readers读访问旧数据。
reclamation:释放旧数据,必须是在没有读者还指向该旧数据之后才能释放回收。
RCU中updater可以立即实施removal操作,然后等到在removal操作期间的active readers都完成了读操作再来实施reclamation操作,等待的方法一般由两种:1. 阻塞直至所有readers完成;2. 设置callback函数来等待readers完成然后通知。这里只需要考虑removal过程中依然还是active状态的readers,因为在removal操作之后再来进行读操作的readers已经不能访问到旧数据,也就不能进行reclamation释放操作。
所以经典的RCU更新时序是:
-
删除指向数据的指针,这样后续readers就不能再指引到它。
-
等待所有之前还指引到数据的reader完成RCU的read-side操作。
-
在没有reader还指向数据后,释放到该数据。
通俗的理解:RCU机制中记录了指向共享数据的指针的所有使用者,在该数据需要改变时,先创建一个副本,在副本中修改。等待所有读者使用者结束对旧数据的读取之后,指针替换为指向新的、修改后的副本的指针,释放旧数据。 RCU机制允许读写并发。
3.1.1 RCU约束
RCU性能好,但也有一些约束:
-
对共享资源的访问主要是只读,写访问相对较少。
-
RCU保护的代码范围内,内核不能进入睡眠状态。
-
RCU保护的资源必须通过指针访问。
3.2 解决什么
是一种同步问题解决方案。
在内核代码编程中,要时刻有一个意识:任意一条执行流,都有可能在任意一条指令之后被中断,然后再执行时是不确定的时间之后。
这就会引出一个问题:被中断之后,再回到断点开始执行时,前后的依赖环境是否发生了变化?
进一步简化该问题:指令执行所依赖的环境是独享还是共享?,独享则安全,共享则可能被意外修改而引发同步问题。
那么,遇到同步问题,怎么办?
你可能直接说出来了,那就是加锁,对共享资源上锁。
3.2.1 同步问题的本质
同步问题的产生本质是共享与同时,共享顾名思义就是数据会被共同访问,不管是读还是写。同时并不是指同一个时间点,而是说A在某项工作还未做完的情况下(这可能是一段时间,因为代码执行中间可能会被中断然后切走),B也需要去参与进来访问共享资源,这就视为同时。
只要破坏共享或者同时,就可解决同步问题。
内核中的同步技术有
| 技术 | 说明 | example code |
|---|---|---|
| per CPU变量 | 在CPU之间复制数据结构 | per_cpu(name, cpu) |
| 原子操作 | 对一个计数器原子地“读-修改-写”的指令 | atomic_add(i, v) |
| 内存屏障 | 避免指令重新排序 | wmb() |
| 自旋锁 | 加锁时忙等 | spin_lock() |
| 信号量 | 加锁时阻塞等待(睡眠) | struct semaphore内核信号量对象 |
| 顺序锁 | 基于访问计数器的锁 | write_seqlock() |
| 禁止本地中断 | 禁止本地CPU上的中断处理 | local_irq_disable() |
| 禁止本地软中断 | 禁止本地CPU上的可延迟函数处理 | local_bh_disable()给本地CPU的软中断计数器加1,这样do_softirq()就不会执行软中断 |
| RCU | 通过指针而不是锁来访问共享数据 | rcu_read_lock() |
3.2.2 经典的spinlock
spinlock在无法获取锁的时候会自旋等待,其有特征:
- spinlock持锁是关闭抢占的,但不一定关闭中断,也就是说在spinlock临界区中,不会出现进程调度,但是可能出现进程环境的切换比如中断、软中断
如何深入思考spinlock的实现原理,发现一个矛盾点:spinlock的作用是对共享数据进行互斥保护,当一个访问者进入临界区后其他访问者只能等待。但是要做到当一个访问真进入临界区后其他访问者等待需要依赖线程之间的通信,这就是矛盾点:
spinlock中,等待着要知道锁已经被占用,也必须访问某个共享的资源才能获取这个信息,实现spinlock就要依赖对另一个共享资源的同步问题,谁来实现?
软件无法实现,就得靠硬件实现,对于每个不同的硬件架构至少需要实现对单字长变量的原子操作执行,比如64位平台,硬件必须支持一类或一组指令能保证对一个变量执行如++操作时是原子操作。
int main(int argc, char *argv[])
{
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
40053a: 89 7d ec mov %edi,-0x14(%rbp)
40053d: 48 89 75 e0 mov %rsi,-0x20(%rbp)
int i = 0;
400541: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
i++;
400548: 83 45 fc 01 addl $0x1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









