






python正则表达式爬取笔趣阁小说
爬取笔趣阁小说算是爬虫中相对简单的部分了,这里采用正则表达式进行爬取下载。
开始的时候怕被封ip就先做了一个无多线程的简易版,代码如下:
import threading
import time
import requests
import re
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"X-Requested-with": "XMLHttpRequest"
}
path = 'F:\\image\\2.txt'
def download(url):
print("start")
response = requests.get(url,headers)
datas = re.findall('<a href ="(.*?)">', response.text,re.S)
for data in datas:
text = requests.get("https://www.sbiquge.com"+data,headers).text
try:
contents = re.findall(' (.*?)<br />',text,re.S)
with open(path,'a+', encoding="utf-8") as file:
for content in contents:
file.write(content)
file.write("\n")
file.close()
except Exception as e:
print(e)
download("https://www.sbiquge.com/0_466/")
中间甚至还让程序睡眠怕被检测爬虫,但这样20分钟都下载不完,效率太低。接下来就要尝试下多线程的高强度爬取看会不会被封了。
多线程的下载方案是下载在不同的文件中最后再整合在同一个文件中,解决乱序以及死锁等问题。
下面是运用线程池的加速版本,使用20个线程池,大概2分钟以内就能完成下载,效率可以接受。
import os
import requests
import re
import math
import time
import threadpool
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"X-Requested-with": "XMLHttpRequest"
}
basepath = 'F:\\image\\'
def getpage(url):
print("start")
response = requests.get(url,headers)
datas = re.findall('<a href ="(.*?)">', response.text,re.S)
return datas
def download(page,count,start):
for index in range(start, start+count):
try:
text = requests.get("https://www.sbiquge.com"+page[index],headers).text
contents = re.findall(' (.*?)<br />',text,re.S)
with open(basepath + str(start) + '.txt','a+', encoding="utf-8") as file:
for content in contents:
file.write(content)
file.close()
except Exception as e:
print(e)
def mergefile(name, count):
try:
with open(basepath + name + '.txt','a+', encoding="utf-8") as file:
for i in range(0,20):
if os.path.exists(basepath + str(i * count) + '.txt'):
text = open(basepath + str(i*count) + '.txt','r',encoding="utf-8")
file.write(text.read())
file.close()
except Exception as e:
print(e)
def removeun(count):
try:
for i in range(0,20):
if os.path.exists(basepath + str(i * count) + '.txt'):
os.remove(basepath + str(i*count) + '.txt')
except Exception as e:
print(e)
def startdownload(i):
length = math.ceil(len(pages) / 20)
download(pages,length,length*i)
pages = getpage("https://www.sbiquge.com/22_22836/")
pool = threadpool.ThreadPool(20)
reqs = threadpool.makeRequests(startdownload,range(0,20))
[pool.putRequest(req) for req in reqs]
pool.wait()
mergefile("伏天氏", math.ceil(len(pages) / 20))
removeun(math.ceil(len(pages) / 20))
接下来尝试加入站内搜索的功能。
查阅资料发现实现此功能需要用到webdriver库,于是开始基于需求的学习。
安装selenium费了我很大功夫,最后参考了https://www.cnblogs.com/xiaxiaoxu/p/8909622.html的内容成功安装。
接下来还要安装webdriver的火狐驱动器。直接放入Python文件夹下即可。
经观察笔趣阁的网站结构如下。

可以看到它的搜索功能隐藏于一个函数中放在
块里。
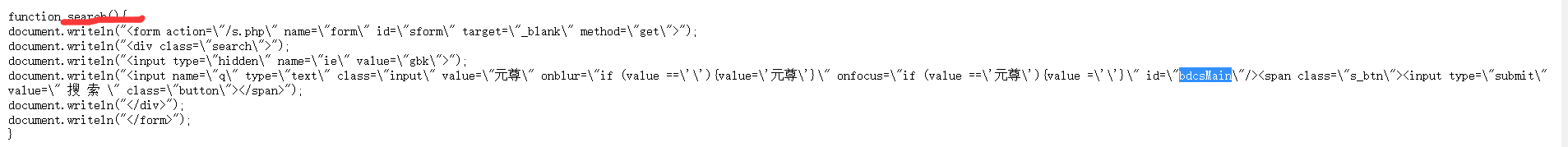
对于这方面我了解很少但经过实验发现可以直接使用selenium库的定位功能在原页面进行定位,不用跳跃到新界面。分析search()后发现通过以下两个方法完成搜索。
driver.find_element_by_name('q').send_keys("遮天")
driver.find_element_by_class_name('s_btn').click()
之后切换句柄并得到url。
handles = driver.window_handles
driver.switch_to.window(handles[1])
time.sleep(20)
简便起见只可下载第一个搜索结果。
但不知是因为服务器的问题还是其他原因跳转到下一界面十分缓慢甚至不能成功,导致程序运行效果不好。
下面附上全部源码。
import os
import requests
import re
import math
import time
from selenium import webdriver
import threadpool
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"X-Requested-with": "XMLHttpRequest"
}
basepath = 'F:\\image\\'
def geturl(name):
driver = webdriver.Firefox()
driver.get("https://www.sbiquge.com/")
driver.find_element_by_name('q').send_keys(name)
driver.find_element_by_class_name('s_btn').click()
#切换句柄
handles = driver.window_handles
driver.switch_to.window(handles[1])
time.sleep(20)
try:
response = requests.get(driver.current_url)
url = re.findall('class="bookname"><a href="(.*?)">',response.text,re.S)
print(url)
return "https://www.sbiquge.com" + url[0]
except Exception as e:
print(e)
def getpage(url):
print("start")
response = requests.get(url,headers)
datas = re.findall('<a href ="(.*?)">', response.text,re.S)
return datas
def download(page,count,start):
for index in range(start, start+count):
try:
text = requests.get("https://www.sbiquge.com"+page[index],headers).text
contents = re.findall(' (.*?)<br />',text,re.S)
with open(basepath + str(start) + '.txt','a+', encoding="utf-8") as file:
for content in contents:
file.write(content)
file.close()
except Exception as e:
print(e)
def mergefile(name, count):
try:
with open(basepath + name + '.txt','a+', encoding="utf-8") as file:
for i in range(0,20):
if os.path.exists(basepath + str(i * count) + '.txt'):
text = open(basepath + str(i*count) + '.txt','r',encoding="utf-8")
file.write(text.read())
file.close()
except Exception as e:
print(e)
def removeun(count):
try:
for i in range(0,20):
if os.path.exists(basepath + str(i * count) + '.txt'):
os.remove(basepath + str(i*count) + '.txt')
except Exception as e:
print(e)
def startdownload(i):
length = math.ceil(len(pages) / 20)
download(pages,length,length*i)
name = input("请输入小说名:")
url = geturl(name)
pages = getpage(url)
pool = threadpool.ThreadPool(20)
reqs = threadpool.makeRequests(startdownload,range(0,20))
[pool.putRequest(req) for req in reqs]
pool.wait()
mergefile(name, math.ceil(len(pages) / 20))
removeun(math.ceil(len(pages) / 20))
print("下载完毕")

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









