







文章目录
kafka的数据结构

- Producer :Producer即生产者,消息的产生者,是消息的入口。
- kafka cluster:Broker :Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
- Topic :消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
消费者和生产者都可以创建主题。 - Partition :topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
- Replication :每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message :每一条发送的消息主体。
- Consumer :消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费者组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper :kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
数据操作命令
创建主题
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic t_cdr --partitions 3 --replication-factor 2
注: partitions指定topic分区数,replication-factor指定topic每个分区的副本数
-
partitions分区数:
- partitions :分区数,控制topic将分片成多少个log。可以显示指定,如果不指定则会使用broker(server.properties)中的num.partitions配置的数量
- 虽然增加分区数可以提供kafka集群的吞吐量、但是过多的分区数或者或是单台服务器上的分区数过多,会增加不可用及延迟的风险。因为多的分区数,意味着需要打开更多的文件句柄、增加点到点的延时、增加客户端的内存消耗。
- 分区数也限制了consumer的并行度,即限制了并行consumer消息的线程数不能大于分区数
- 分区数也限制了producer发送消息是指定的分区。如创建topic时分区设置为1,producer发送消息时通过自定义的分区方法指定分区为2或以上的数都会出错的;这种情况可以通过alter –partitions 来增加分区数。
-
1.replication-factor副本
- replication factor 控制消息保存在几个broker(服务器)上,一般情况下等于broker的个数。
- 如果没有在创建时显示指定或通过API向一个不存在的topic生产消息时会使用broker(server.properties)中的default.replication.factor配置的数量
查看所有topic列表
bin/kafka-topics.sh --zookeeper localhost:2181 --list
查看指定topic信息
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic 主题名
删除主题
bin/kafka-topics.sh --delete --topic test --zookeeper localhost:2181
查看消费者组
bin/kafka-consumer-groups.sh --bootstrap-server ip:9092 --list
查看消费者组的详细信息
bin/kafka-consumer-groups.sh --bootstrap-server ip:9092 --group 消费者组名 --describe
查询到的信息为
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
order_log order_log 0 254 254 0 ClickHouse 18.16.1-7b82022e-6485-4944-87a6-96d5e665eb1a /10.177.4.38 ClickHouse 18.16.1
讲解:
- GROUP 对应的消费者组名称
- TOPIC 队列
- PARTITION 分区
- CURRENT-OFFSET 当前消费到的索引 ,如果和LOG-END-OFFSET相等则全部消费完
- LOG-END-OFFSET 队列的消息总数量
- LAG 消费积压情况
删除消费者组
bin/kafka-consumer-groups.sh --bootstrap-server ip:9092 --delete --group 消费者组名
如果删除不掉,需要把正在消费的消费者关闭再删除即可
控制台向topic生产数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
控制台消费topic的数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
--from-beginning 是从主题的初始位置开始消费,即消费主题的所有信息
查看controller
登录zookeeper客户端通过get /controller命令查看
修改指定topic的消费者组的消费索引
bin/kafka-consumer-groups.sh --bootstrap-server ip:port --group groupName --topic topicName --execute --reset-offsets --to-offset 257
ip和port都是kafka的
- group 代表你的消费者分组
- topic 代表你消费的主题
- execute 代表支持复位偏移
- reset-offsets 代表要进行偏移操作
- to-offset 代表你要偏移到哪个位置 是long类型数值,只能比前面查询出来的小
如果报错Error: Assignments can only be reset if the group 'tablename' is inactive, but the current state is Stable则需要把消费者的程序关闭
第二种方式
第二种方式offset信息保存在zookeeper当中
bin/kafka-consumer-groups.sh --zookeeper z1:2181,z2:2181,z3:2181 --group test-consumer-group --topic test --execute --reset-offsets --to-offset 10000
–zookeeper 和 --bootstrap-server 只能选一种方式
消息队列的两种模式
kafka是消费者主动轮询拉取队列信息消费,并且如果是新的消费者和消费者组,会消费到队列的所有消息,包括创建消费者之前的消息
点对点模式
一对一,消费者主动拉取数据,消息收到后消息删除, 并且消息只能被一个消费者消费
发布订阅模式
一对多,消费者消费数据后不会清除消息,生产者将消息发布到topic中,可以被所有订阅了的消费者消费,消费者可以通过两种方式获取消息,一种是主动拉取,一种topic推送消息,kafka是基于主动拉取模式的
概述
kafka是一个分布式的基于发布订阅模式的消息队列,主要应用于大数据领域。
使用消息队列的好处
解耦:允许独立的修改活扩展两边的代码,只要确保他们遵守同样的接口约束可恢复性:系统的一部分组件失效时,不会影响整个系统,即一个处理消息的服务挂掉后,加入队列中的消息仍然可以在服务恢复后处理缓冲:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的不一致- 异步通信:不需要立即处理消息,可以在需要的时候再处理
安装
kafka依赖于zookeeper,所以也必须安装zookeeper
下载地址:https://kafka.apache.org/downloads

把此包解压到服务器即可
config目录下的server.properties
# broker的全局唯一标识,集群中不能重复,
broker.id=0
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://192.168.10.1:9092
# 监听ip和端口案例 listeners = PLAINTEXT://your.host.name:9092 ,ip是外网可以访问的,否则通过代码访问会访问不到
listeners=PLAINTEXT://192.168.10.1:9092
# 设置删除功能可使用,,新版本没有发现这个设置
delete.topic.enable=true
# 服务器用于从网络接收请求并向网络发送响应的线程数
num.network.threads=3
# 服务器用于处理请求的线程数,其中可能包括磁盘I/O
num.io.threads=8
# socket服务器使用的发送缓冲区
socket.send.buffer.bytes=102400
# socket服务器使用的接收缓冲区(SO_RCVBUF)
socket.receive.buffer.bytes=102400
# 套接字服务器将接受的请求的最大大小(针对OOM的保护)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 用逗号分隔的目录列表,在其中存储数据文件
log.dirs=/tmp/kafka-logs
# 每个主题的默认日志分区数。更多分区允许更大分区
num.partitions=1
# 每个数据目录用于启动时日志恢复和关闭时刷新的线程数。
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# 组元数据内部主题“__consumer_offset”和“__transaction_state”的复制因子
# 对于开发测试以外的任何情况,建议使用大于1的值,以确保可用性,例如3。
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Retention Policy #############################
# 由于过期而可以被删除的日志文件的最小过期时间
log.retention.hours=168
# 日志段文件的最大大小。当达到这个大小时,将创建一个新的日志段。
log.segment.bytes=1073741824
# 检查日志段以确定是否可以根据其删除的时间间隔
log.retention.check.interval.ms=300000
# 集群连接案例 "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# 连接zookeeper的ip地址
zookeeper.connect=localhost:2181
# 连接zookeeper超时时间
zookeeper.connection.timeout.ms=6000
# 延迟初始消费者重新平衡的时间(以毫秒为单位)
group.initial.rebalance.delay.ms=0
bin目录下的常用命令
- 启动kafka自带的zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties &,关闭:bin/zookeeper-server-stop.sh config/zookeeper.properties - kafka启动和关闭命令 : 后台启动命令
bin/kafka-server-start.sh -daemon config/server.properties,关闭命令:bin/kafka-server-stop.sh config/server.properties, 启动或者关闭前要先启动zookeeper - 生产者和消费者控制台打印信息命令
kafka-console-consumer.shkafka-console-producer.sh - 关于topic的操作,增删改查
kafka-topics.sh - 启动kafka自带的zookeeper的客户端:
bin/zookeeper-shell.sh ip:port
配置修改
log4J的日志路径修改
kafka使用的log4j,在conf目录下有log4j.properties配置文件,里面所有的文件路径都是用的配置${kafka.logs.dir} ,经百度此参数的配置在bin目录的kafka-run-class.sh配置文件中,只要我们在此文件中添加一行LOG_DIR =/log/dir即可,即可修改文件日志路径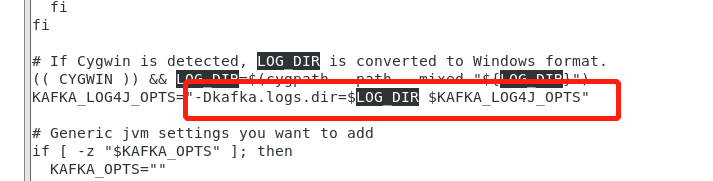
异常处理
- 如果kafka启动异常可以查看logs目录下的server.log日志
- clickhouse消费不到kafka的数据,但是通过命令从头消费是可以的,可以查看消费者组的详细信息,看消费索引消费到哪了,如果没有信息显示,可能消费者组有问题,可以删除消费者组,如果不能删除,直接把kafka的数据文件全部删除和zookeeper的配置文件中的dataDir配置路径下的全部删掉,这就相当于全新的kafka和全新的zookeeper,重启即可















 4637
4637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









