






<内容摘自互联网 主要为自用学习>
概述:MapReduce是hadoop的三大核心组件之一,主要提供的是计算模型,比较典型的应用案例就词频统计
MapReduce含义
计算模型:对数据的分布式处理计算抽象为Map和Reduce两个过程,为所有的数据处理提供统一且简单的处理方式,更加非技术人员的理解
运行框架:提供了一个计算精良的并行计算软件框架,能自动完成计算任务并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行子任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算中的很多复杂细节交由系统负责处理,大大减轻了软件开发人员的
负担
MapReduce的工作流程
(详细版)
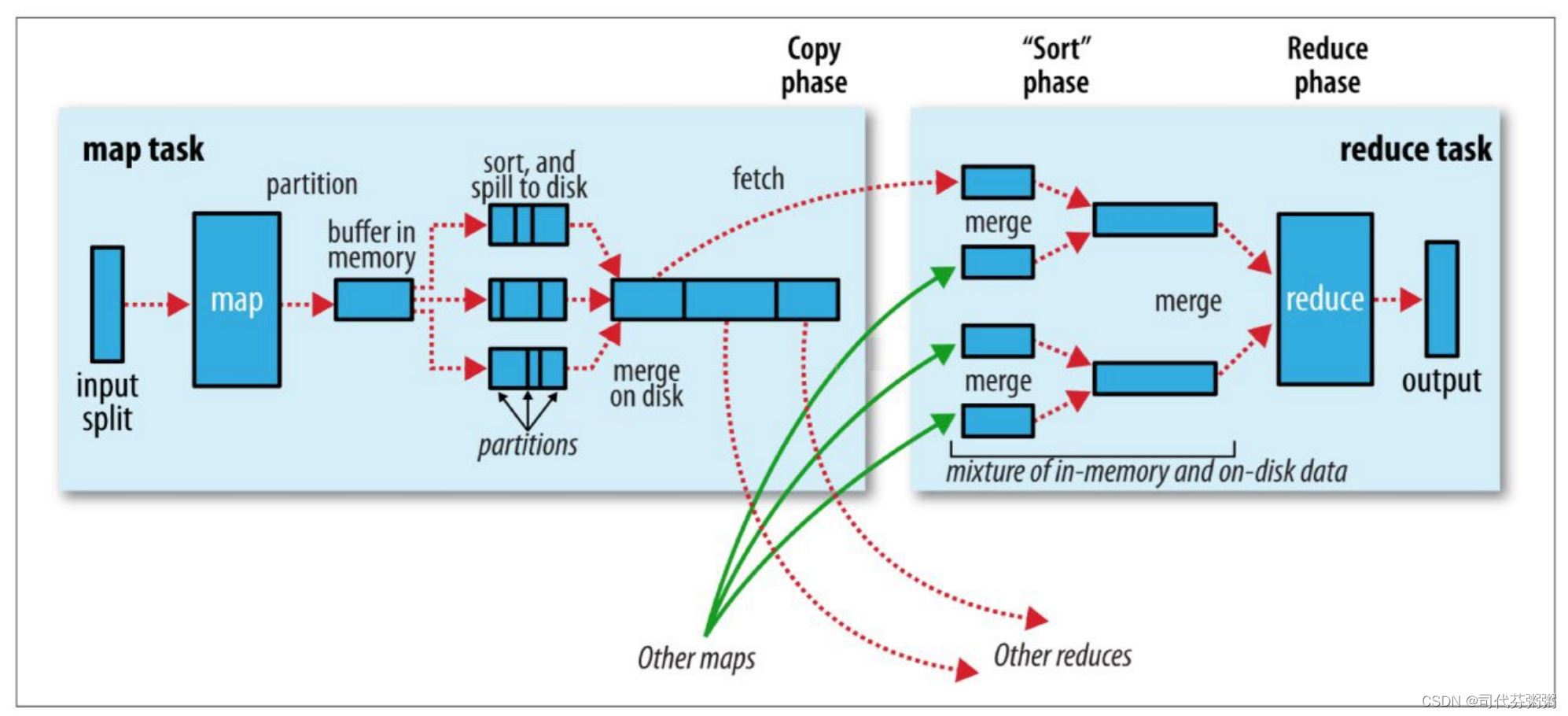
Maptask
第一阶段:把输入目录下文件按照一定的标准逐个进行
逻辑切片
,形成切片规划。
默认
Split size = Block size
(
128M
),每一个切片由一个
MapTask
处理。(
getSplits
)
第二阶段:对切片中的数据按照一定的规则读取解析返回
<key,value>
对。 默认是
按行读取数据
。
key
是每一行的起始位置偏移量,
value
是本行的文本内容。(
TextInputFormat
)
第三阶段:调用
Mapper
类中的
map
方法处理数据
。
每读取解析出来的一个
<key,value>
,调用一次
map
方法。
第四阶段:按照一定的规则对
Map
输出的键值对进行
分区
partition
。(默认不分区,因为只有一个
reducetask)
分区的数量就是reducetask
运行的数量。
第五阶段:
Map
输出数据写入
内存缓冲区
,达到比例溢出到磁盘上。
溢出
spill
的时候根据
key
进行
排序
sort
。 默认根据key
字典序排序。
第六阶段:对所有溢出文件进行最终的
merge
合并
,成为一个文件。
Reducet阶段
第一阶段:
ReduceTask
会主动从
MapTask
复制拉取
属于需要自己处理的数据。
第二阶段:把拉取来数据,全部进行
合并
merge
,即把分散的数据合并成一个大的数据。再对合并后的数据
排序
。
第三阶段是对排序后的键值
对调用
reduce
方法
。
键相等
的键值对调用一次
reduce
方法。最后把这些输出的键值对 写入到HDFS
文件中。
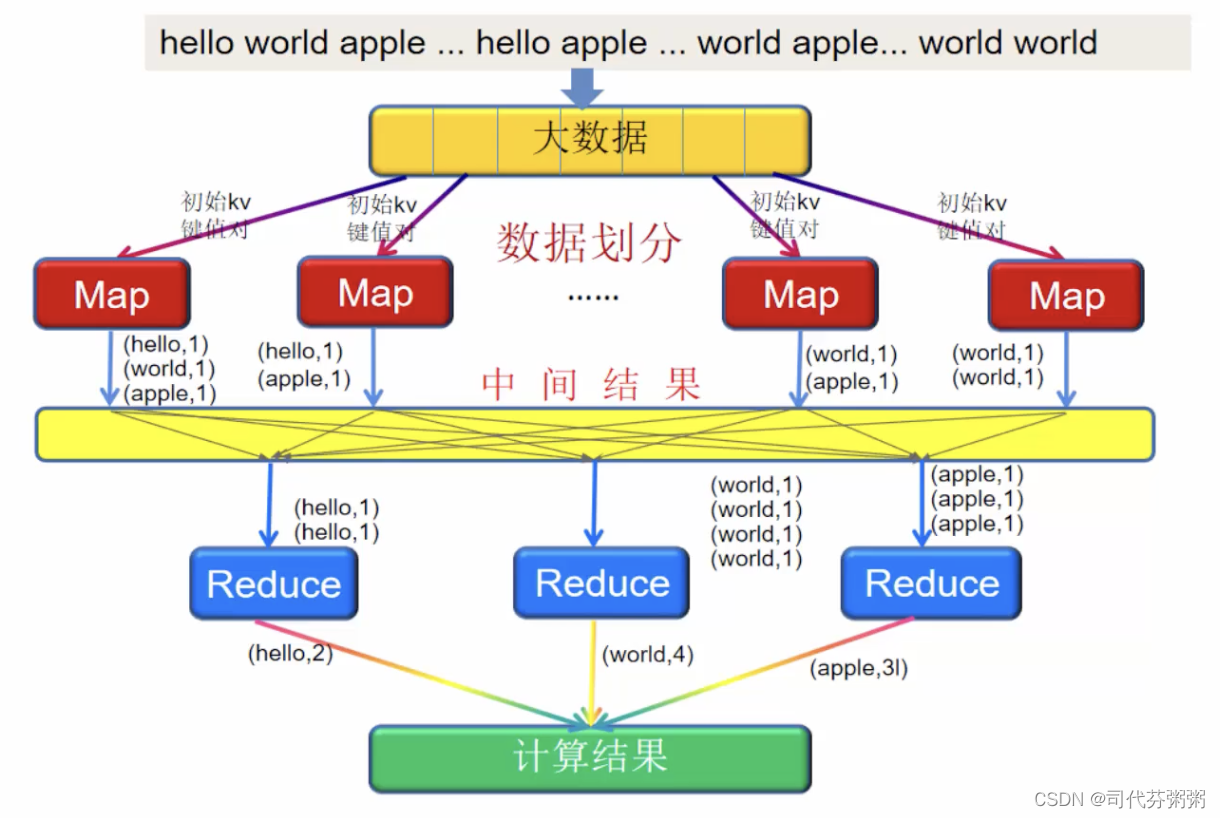
整个处理流程都不需要代码编写,直接使用即可
#1 将文件里的数据切割为一个一个的数据块,切割原则是根据系统的存储大小,默认是按128M进行切割同时考虑行
#2将切割后的数据块(split)分发到节点上,每个节点上会运行一个map对数据进行处理,因此每一个map会接受文件内的一部分数据(在map里运行一定的程序代码对数据进行处理)进行词频统计
#3所有map同时处理数据,并输出运算结果,KV键值对,(不论计算方式所有的map输出都是这种形式 )
#4map输出的结果再传输给reduce节点进行汇总,这个传输过程叫做shuffle,Shuffle是MapReduce程序的核心与精髓,Shuffle也是MapReduce被诟病最多的地方所在。MapReduce相比较于Spark、Flink计算引擎慢的原因,跟 Shuffle机制有很大的关系
#5 reduce将map输出的kv键值对按照一定规则再进行汇总,依旧处理的是部分数据,所有的reduce也是同步进行的
#6最后将reduce的结果汇总输出














 2071
2071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









