







并查集
leetcode这个月怕是图论月,每日抑题老出并查集,之前没仔细钻研过。今天看了一下之前的官方题解和别人的模板,自己总结一下,中间有几张图用了菜鸟教程的。
-
并(Union),代表合并
-
查(Find),代表查找
-
并查集的典型应用是有关连通分量的问题
实现
最简单的版本
用数组记录每个节点的根节点,只要两个节点的根节点是一样的,那么这两个节点就是连通的,

比如现在就有两个连通分量,[0, 1, 2, 3, 4]是一组,[5, 6, 7, 8, 9]是一组。在初始化的时候需要让每个节点的根节点都是自己,代码如下:
public class UnionFind {
private int[] root;
// 集合的个数
private int count;
public UnionFind(int n) {
count = n;
root = new int[n];
for (int i = 0; i < n; ++i)
root[i] = i;
}
}
现在要查找一个节点的根节点,也就是看它是哪个集合的,只要查他的root就可以:
private int find(int x) {
return root[x];
}
如果要合并两个节点所在的集合,那么就需要遍历一次root,把这两个节点的根节点统一,时间复杂度是O(n):
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY)
return ;
for (int i = 0; i < count; ++i) {
if (root[i] == rootX)
// 这里是把根节点是rootX的都划分到rootY集合,反过来也行,都可以
root[i] = rootY;
}
// 如果本来就是一个集合的,那在上面就return了,不会-1
count--;
}
那么现在整个模板就是这样的:
public class UnionFind {
private int[] root;
// 集合的个数
private int count;
public UnionFind(int n) {
count = n;
root = new int[count];
for (int i = 0; i < n; ++i)
root[i] = i;
}
private int find(int x) {
return root[x];
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY)
return ;
for (int i = 0; i < count; ++i) {
if (root[i] == rootX)
// 这里是把根节点是rootX的都划分到rootY集合,反过来也行,都可以
root[i] = rootY;
}
}
public int getCount() {
return count;
}
public boolean isConnected(int x, int y) {
return root[x] == root[y];
}
}
改进版本
上述的合并操作每次都要遍历一次root,复杂度是O(n),显得太繁琐。现在我们不记录每个节点的根节点了,而是记录每个节点的父节点。如果两个节点是相互连通的(从一个节点可以到达另一个节点),那么他们的祖先节点是相同的。
初始化的时候,还是让每个节点的父节点都是自己。

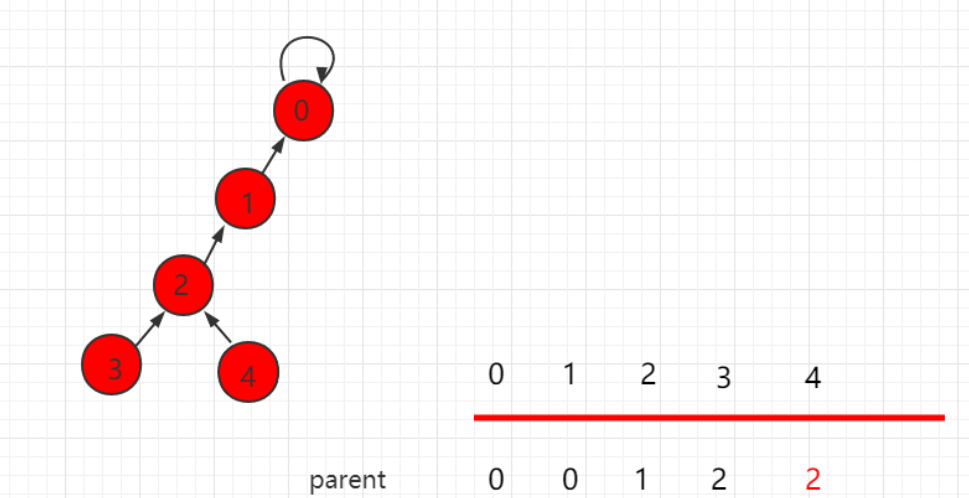
现在判断两个节点是不是同一个集合的,只要判断他们的根节点是不是相同的就可以了。怎么判断是否向上找到了根节点也比较容易,只要parent[x] == x,那么x就是根节点。
比如现在要判断4和9是否是同一个集合的,parent[4] != 4–>向上走–>parent[3] != 3–>向上走–>parent[8] == 8,所以4的祖先节点就是8。同理9的祖先节点也是8,那么他们就是一个集合的。
用代码实现也比较简单,一个while就搞定了:
private int find(int x) {
while(x != parent[x])
x = parent[x];
return x
}
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
这里find就不像上面的版本是O(1)了,而是O(h),h是树的高度,但是这样会让union的时间复杂度也得到简化。因为之前存的是根节点,所以每次合并都要检查一下所有的根节点。现在存的是父节点,只要改根节点的的父节点就行了,剩下的父节点是没有被影响的:
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rooY)
return ;
parent[rootX] = rootY;
count--;
}
这里只要让x所在集合的祖先节点rootX不再指向自己,而是指向y所在集合的祖先节点rootY,那么这两个集合就整个连通了,至于集合的节点之间到底怎么走,走多少步才能连通,并查集不关心这个。
比如刚刚的图,要让6和4连通,那么分别找到祖先节点5和8,让5指向8,就ok了,这也是上面代码做的事情。

现在的整个模板就是这样的:
public class UnionFind {
private int count;
private int[] parent;
public UnionFind(int n) {
count = n;
parent = new int[n];
for (int i = 0; i < n; ++i)
parent[i] = i;
}
private int find(int x) {
while (x != parent[x])
x = parent[x];
return x;
}
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY)
return ;
parent[rootX] = rootY;
count--;
}
public int getCount() {
return count;
}
}
路径压缩
但是这里还存在一个问题,就是如果树的高度过高,那么不论find还是union的操作都会受到影响,所以需要进行路径压缩,我们在一开始就说了并查集是为了解决连通分量问题的,所以图的真实路径是怎么样的并不关心,只要保证这个集合里的点在原本的图中确实是可以相互抵达的就行。
那么到底该怎么压缩?其实思路也比较简单,因为并查集不是二叉树,所以可以有多个 子节点,也就是一个节点可以被多个节点的parent指向。那我们要做的就是尽可能的让每个节点向上指,这样树的高度就会降低。
比如我现在有一个节点x,它的父节点是parent[x],而这个时候parent[x] != x,也就是x不是根节点,那我们就希望让x再向上指一层,也就是指向parent[parent[x]],所以这个步骤用代码表示就是:
private int find(int x) {
while (x != parent[x]) {
parent[x] = parent[parent[x]];
// 接着向上走
x = parent[x]
}
return x;
}
这里可能会有点疑惑,这不就相当于跳过它的父节点了吗?相当于一次向上走两层,那会不会刚好跳过根节点了?答案是肯定不会,因为根节点parent[x] == x,那么parent[parent[x]]还是等于x,到这就停了。
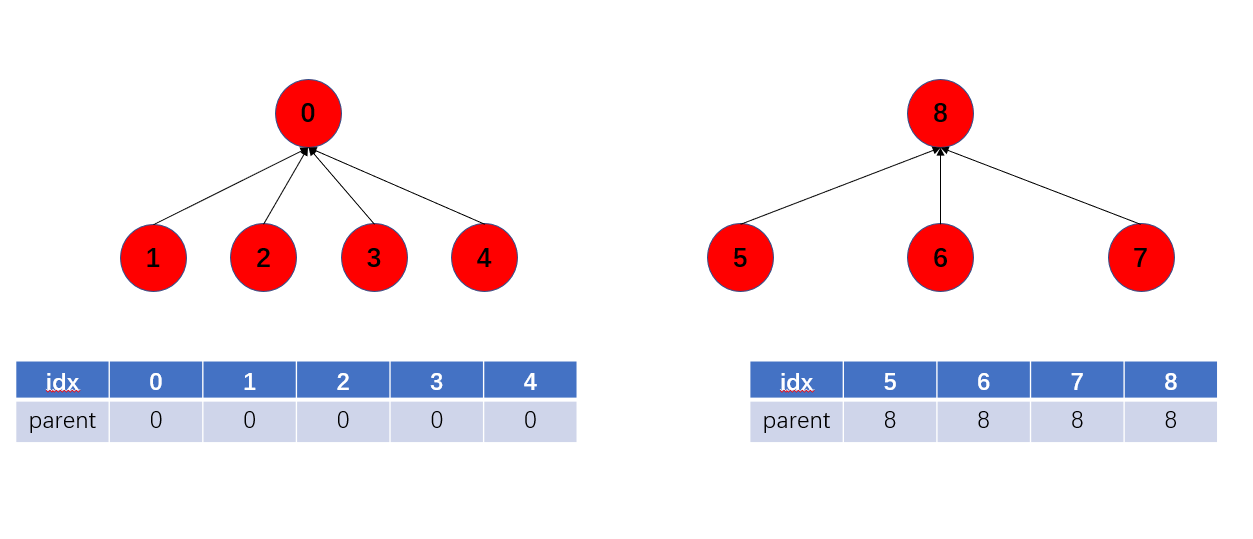
现在一个集合是这个样子的:

也就是刚刚说的树的高度过高,需要进行压缩,那么步骤就是这样的:
parent[parent[4]] == 2,然后让parent[4] = parent[parent[4]],parent[4]就更新为2了,这个时候相当于你已经更改了最原始的图结构了,因为图中是没有4–>2这条边的,之前4要到2,需要4–>3–>2。但是现在改完之后4, 3, 2他们三个之间还是连通的关系,所以并不影响。
现在代码运行到x = parent[x],也就是x = 2,再执行一次循环:

可以看到树的高度明显降低了,这样后续find和union的时候,用时就会减少。
路径再压缩
之前我们压缩路径是让parent[x] = parent[parent[x]],这样可以一次向上两层,那如果我parent[x] = root呢?直接让它指向根节点,这样树的高度自然就是最低的:
public int find(int x) {
if (x != parent[x])
// find()递归到根节点才会停,所以所有节点的parent都指向根节点
parent[x] = find(parent[x]);
return parent[x];
}
压缩之后像下面这样:

猛一看,这不又回去了?每个节点都存自己的根节点?那和最开始那个简单版本还有啥区别?
这个例子看起来确实像存了自己的根节点,但是区别在于,之前每次合并都需要手动去更新root的值,也就是遍历一次root数组。那么现在呢?
如果我要合并x=4和另一个节点y=5,我需要找到4的根节点,也就是调用find(x),得到rootX=0;找到另一个节点5的根节点,也就是调用find(y),得到rootY=8。然后让parent[rootX] = rootY,也就是现在parent[0] = 8。那么这个时候1,2,3,4的parent依然是0,不用自己手动遍历root再更新成8,这个时候树的高度是3。那什么时候1,2,3,4会进行路径压缩,指向8呢?下次调用find,,这个时候1,2,3,4调用find得到的可就不是0了,而是8,那么parent[x] = find(parent[x])就会把1,2,3,4的parent更新,也就是进行了一次路径压缩,这样树的高度就是2了。(都被调用一次高度才会变成2,否则还是3)
初始:
合并:

某次进行3和其他集合节点的合并,就会导致parent[3] = find(parent[3]) = 8:
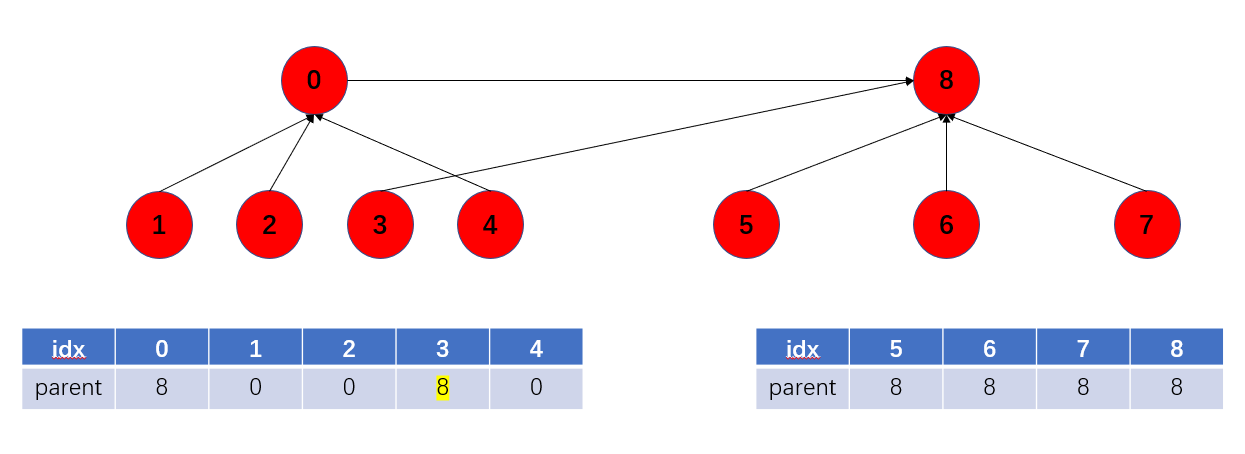
这样就不需要遍历root手动更改,也就是时间复杂度并没有退化到O(n),但是树的高度大大降低了(并不是只有两层,注意区分)。
最终模板
public class UnionFind {
private int count;
private int[] parent;
public UnionFind(int n) {
count = n;
parent = new int[n];
for (int i = 0; i < n; ++i)
parent[i] = i;
}
public int find(int x) {
if (x != parent[x])
parent[x] = find(parent[x]);
return parent[x];
}
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY)
return ;
parent[rootX] = rootY;
count--;
}
public int getCount() {
return count;
}
}
这里也可以用HashMap实现,思路一样,但是不需要确定初始容量,那么初始化的时候就不用一个个给赋初值,而是等用的时候再把这个节点当作根节点,加入HashMap就行,这个时候就要count++。
模板如下:
public class UnionFind {
private Map<Integer, Integer> parent;
private int count;
public UnionFind() {
this.parent = new HashMap<>();
this.count = 0;
}
public int getCount() {
return count;
}
public int find(int x) {
if (!parent.containsKey(x)) {
parent.put(x, x);
count++;
}
if (x != parent.get(x)) {
parent.put(x, find(parent.get(x)));
}
return parent.get(x);
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) {
return;
}
parent.put(rootX, rootY);
count--;
}
}
例题
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
如果没学并查集,可能会用dfs去做这道题,代码如下:
public class Solution {
int ret;
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
boolean[] visited = new boolean[n];
for (int i = 0; i < n; ++i) {
if (!visited[i]) {
visited[i] = true;
ret++;
dfs(isConnected, visited, i);
}
}
return ret;
}
private void dfs(int[][] adj,boolean[] visited, int v) {
int n = visited.length;
for (int j = 0; j < n; ++j) {
if (adj[v][j] == 1 && !visited[j]) {
visited[j] = true;
dfs(adj, visited, j);
}
}
}
}
但是先在学了并查集,会发现这不就是求并查集中有几个连通分量吗?所以套并查集的模板,把所有的边都union一下,getCount()就是最终答案。
public class Solution {
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
UnionFind unionFind = new UnionFind(n);
for (int i = 0; i < n; ++i)
for (int j = i + 1; j < n; ++j)
if (isConnected[i][j] == 1)
unionFind.union(i, j);
return unionFind.getCount();
}
}
n 块石头放置在二维平面中的一些整数坐标点上。每个坐标点上最多只能有一块石头。
如果一块石头的 同行或者同列 上有其他石头存在,那么就可以移除这块石头。
给你一个长度为 n 的数组 stones ,其中 stones[i] = [xi, yi] 表示第 i 块石头的位置,返回 可以移除的石子 的最大数量。1 <= stones.length <= 1000
0 <= xi, yi <= 10^4
不会有两块石头放在同一个坐标点上
同行或者同列相当于图中的“可抵达”,还是一个连通分量的问题。这里和上面有一点不同,就是节点不是一个数,而是一个坐标,坐标是会重合的,但是好在范围不大,可以给横坐标或者纵坐标加上10001。
public class Solution {
public int removeStones(int[][] stones) {
UnionFind unionFind = new UnionFind();
for (int[] stone : stones)
unionFind.union(stone[0] + 10001, stone[1]);
return stones.length - unionFind.getCount();
}
}















 2188
2188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









