






1. 背景
某些情况下,输入向量不止一个,并且数量是动态可变的。
案例一,输入句子。每个单词都是一个向量,如果使用one-hot编码的话,就会发现每个单词之间是没有关系的,即使是对于cat,dog这类相近的动物词汇,也是没有关系。另外一种编码方法是word embedding,它把语义相近的词汇靠在了一起。

案例二,语音。按照10ms间隔分割语音输入,可以做到输入多个向量。
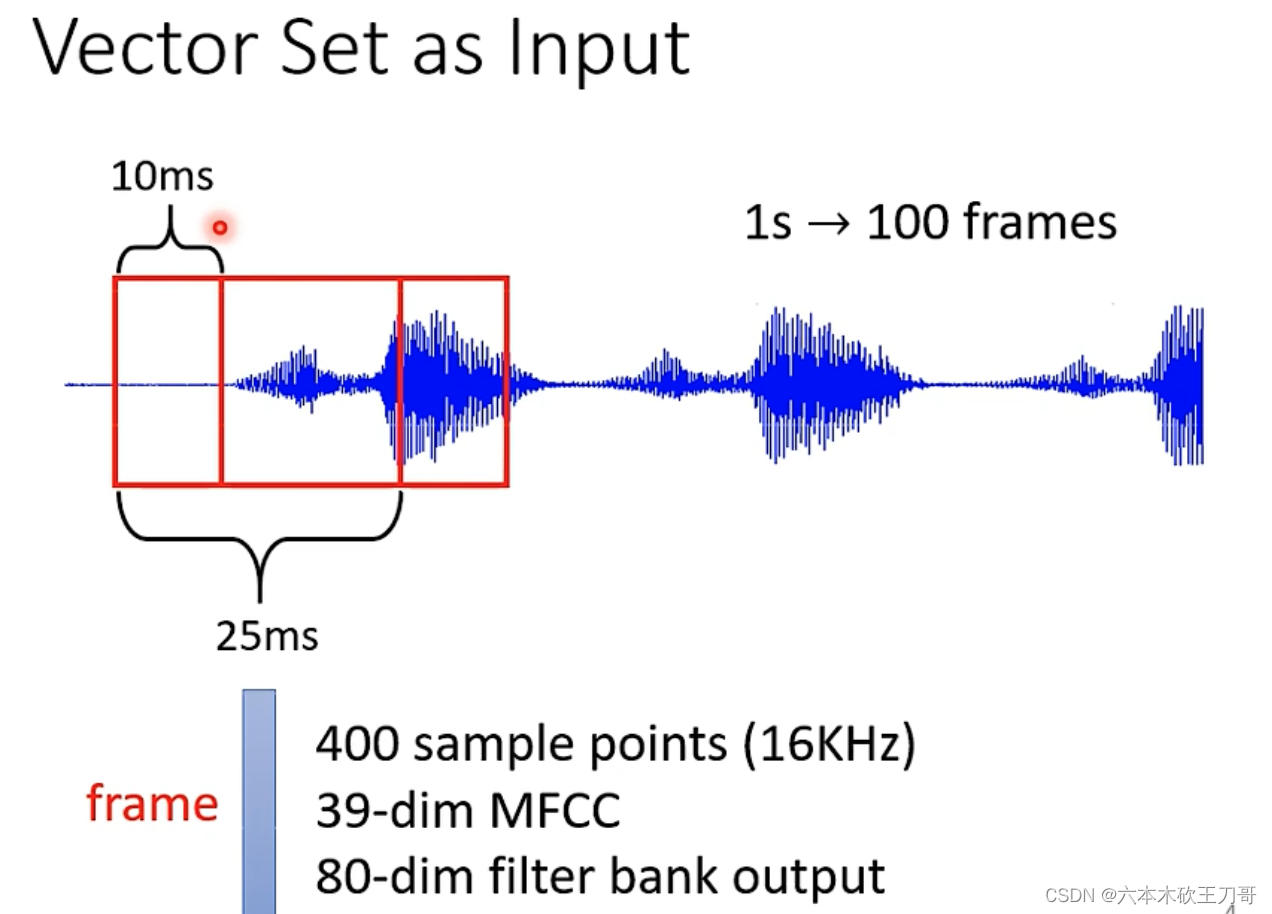
案例三,社交网络。每个人的节点可以看作一个向量。
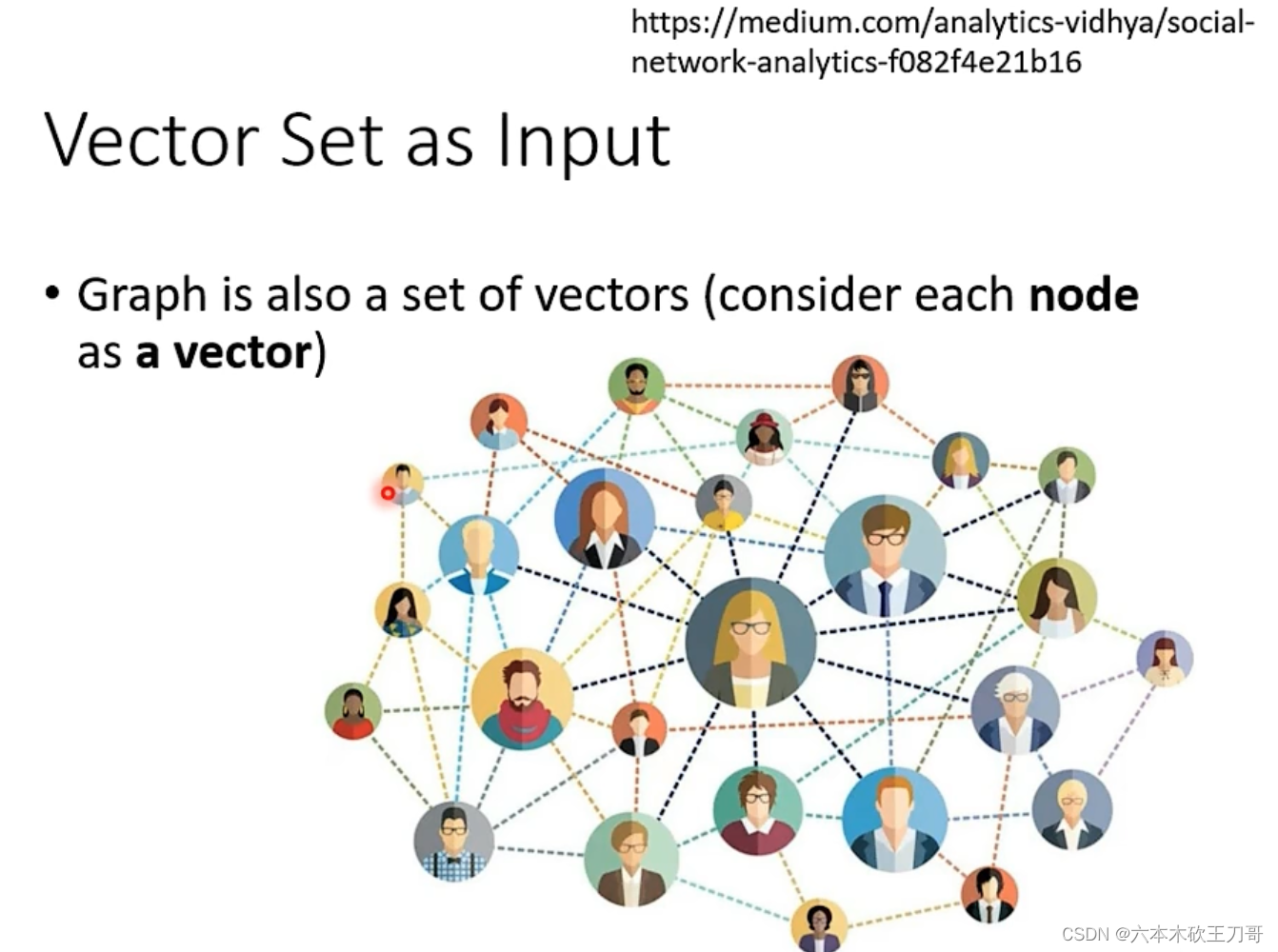
案例四,分子。每个分子可以作为一个向量。
那么得到了输入向量的集合,输出的格式有哪些类型?
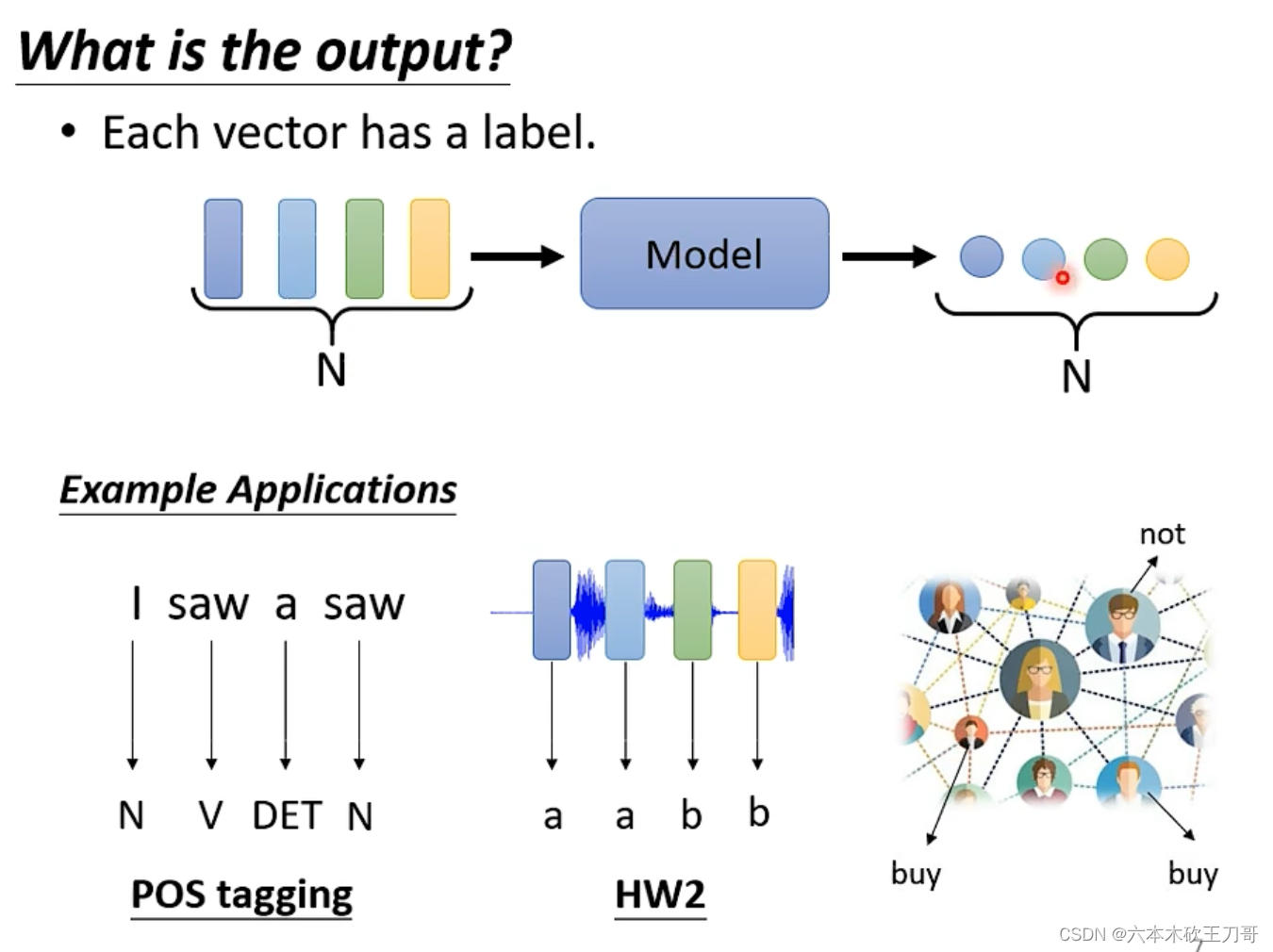
第一种:多个label输出。例如输入一堆词向量,需要输出每个单词的词性;输入语音,输出每段相关的某个特征(这里不太理解);输入社交网络,输出每个人购物的倾向。
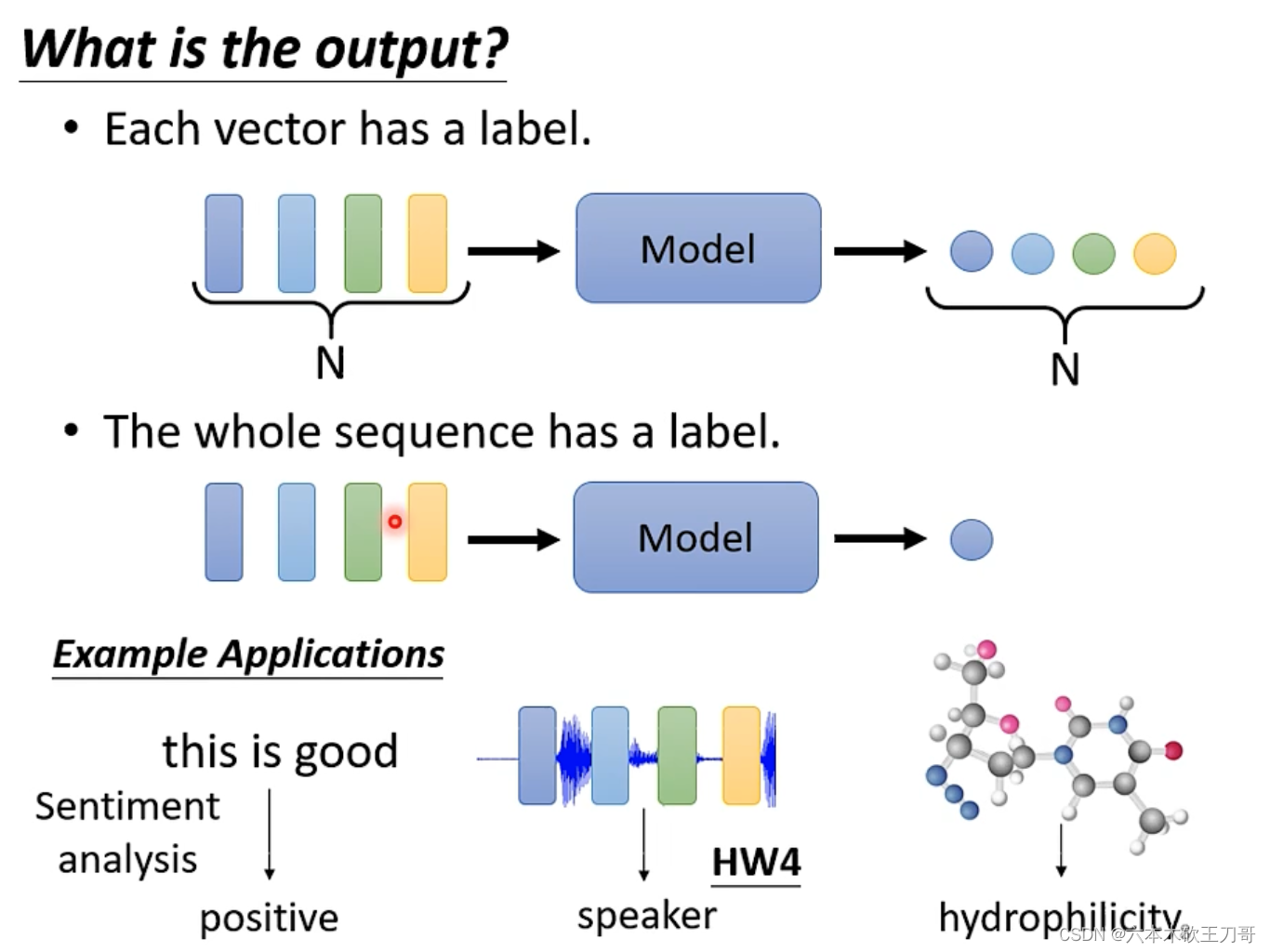
第二种:单个label输出。例如语义识别,情感分析;输入语音,输出speaker;输入分子向量,输出其是否具备亲水性等。
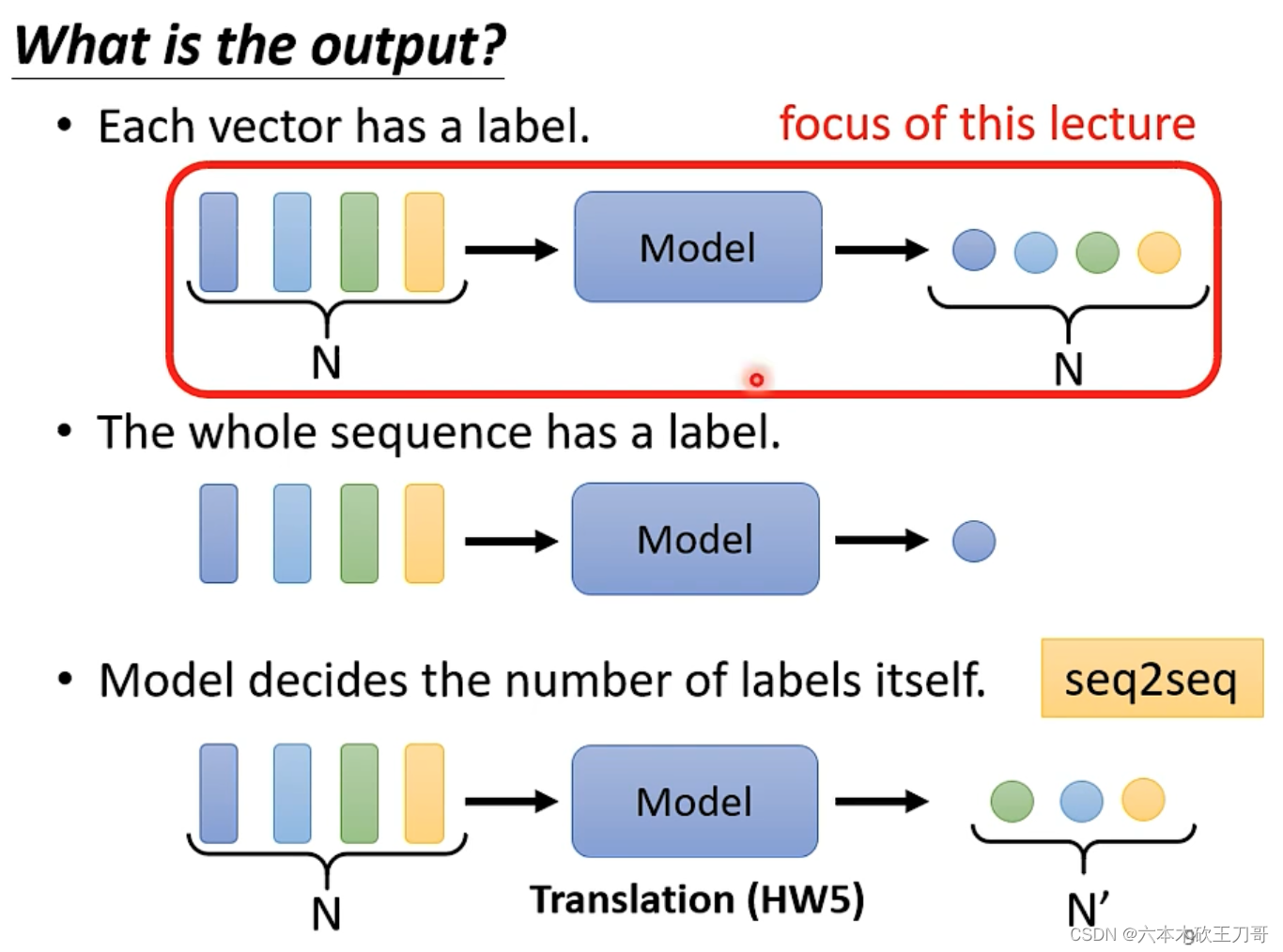
第三种:seq2seq。输入向量集,输出另一个数量不相等的向量集合。
2. 自注意力机制
现在我们重点关注第一种情况:输入向量数量和输出向量数量相等。
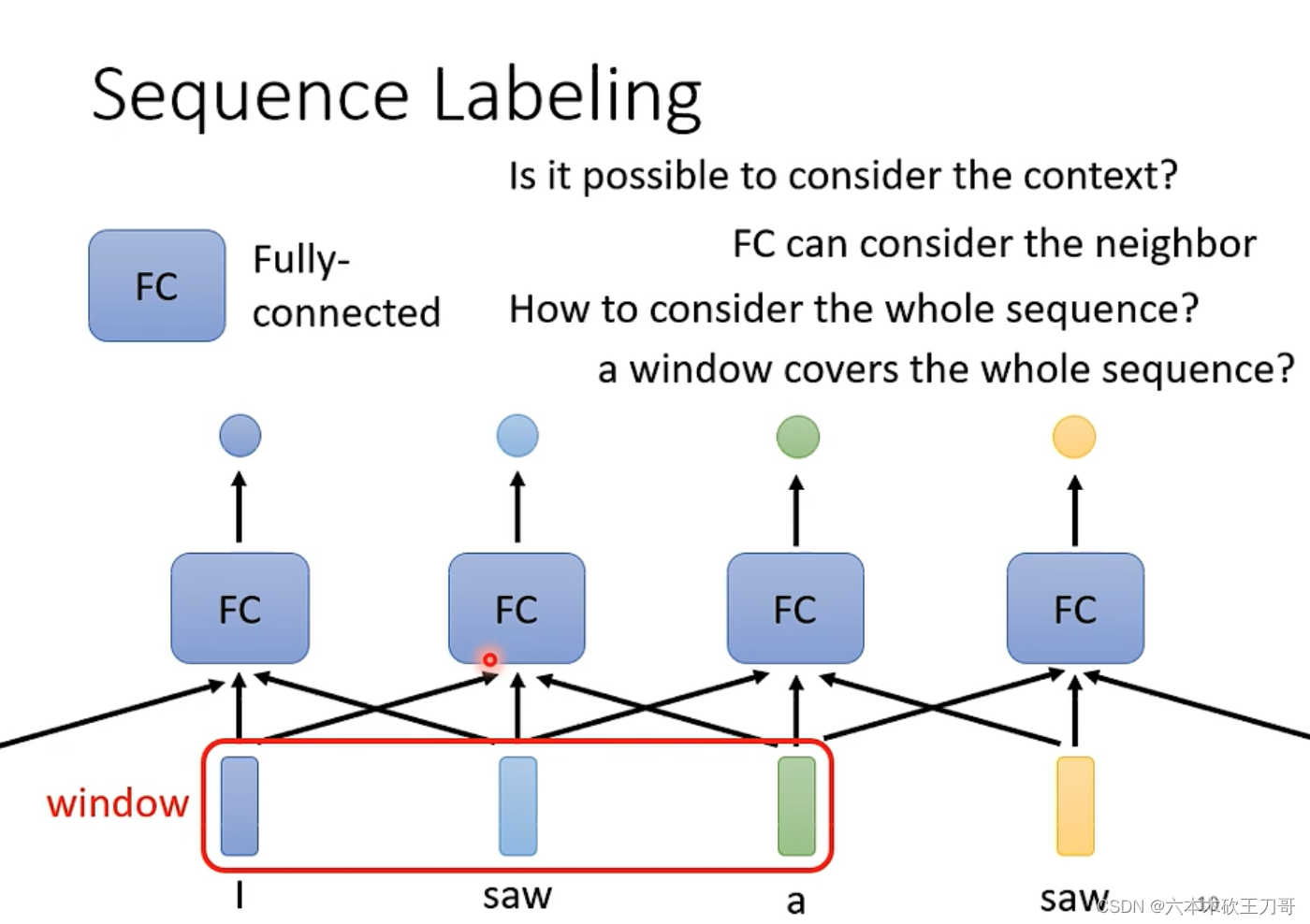
在全连接神经网络下,当输入一些词向量的时候,每个词向量之间是没有联系的,例如下面的saw动词和saw名词,没有理由输出不同的结果,但是这个两个词的词性是不同的。
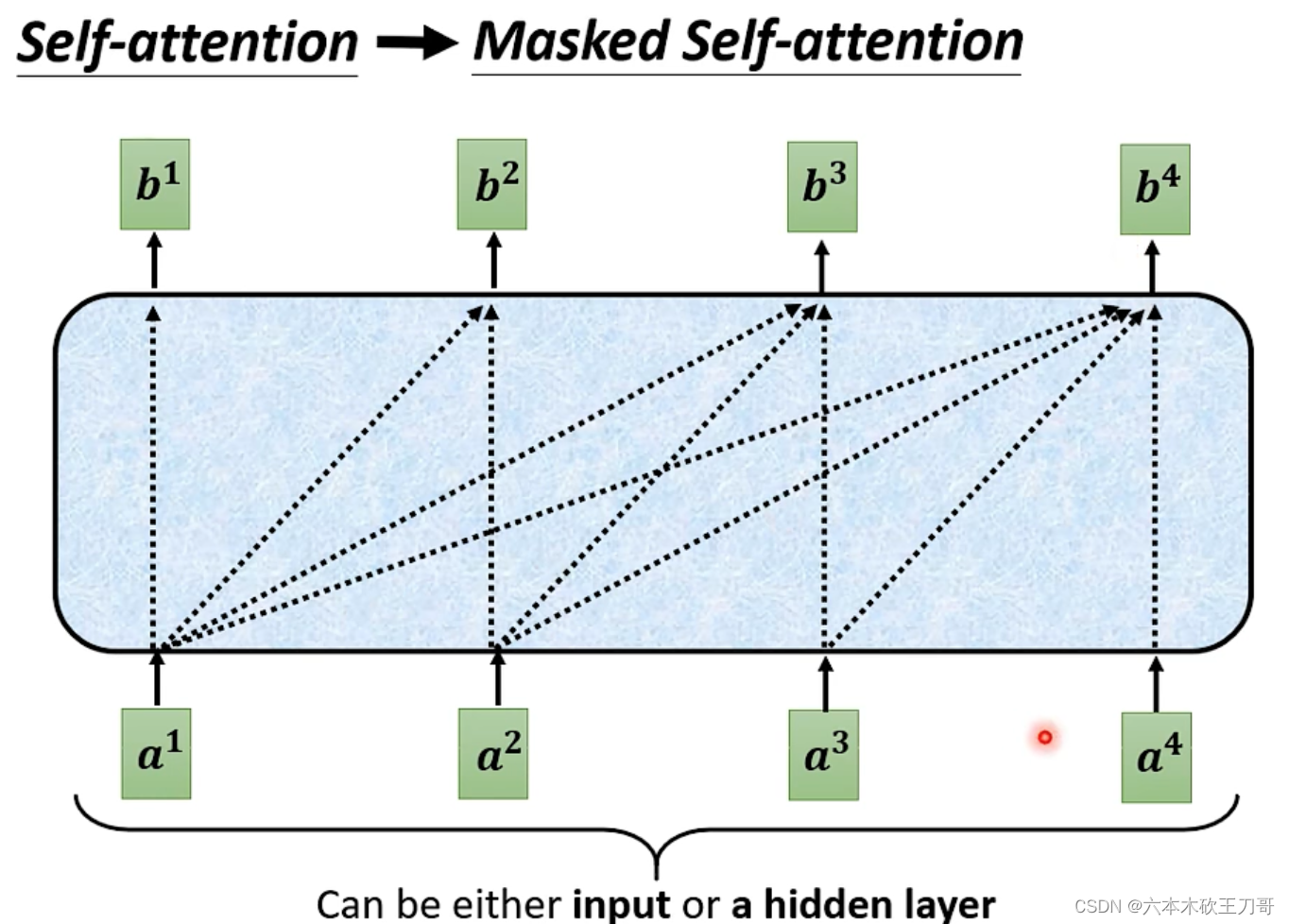
对全连接网络来说不可能做到。有没有什么办法可以让词之间有联系呢?
可以使用一个window让前后几个向量一起串联起来,考虑相邻向量之间的联系,在数量比较小的时候,这个方法效果比较好,如果要考虑整个sequence才能解决的话,就需要用window把整个sequence包起来,但当向量数量较多的时候,这样全连接网络可能需要更多的参数。
引入self-attention来解决,其中所有向量输入一个自注意力模型,其中的输出向量考虑过与整个sequence的联系而输出的,并且self-attention可以被叠加很多次。
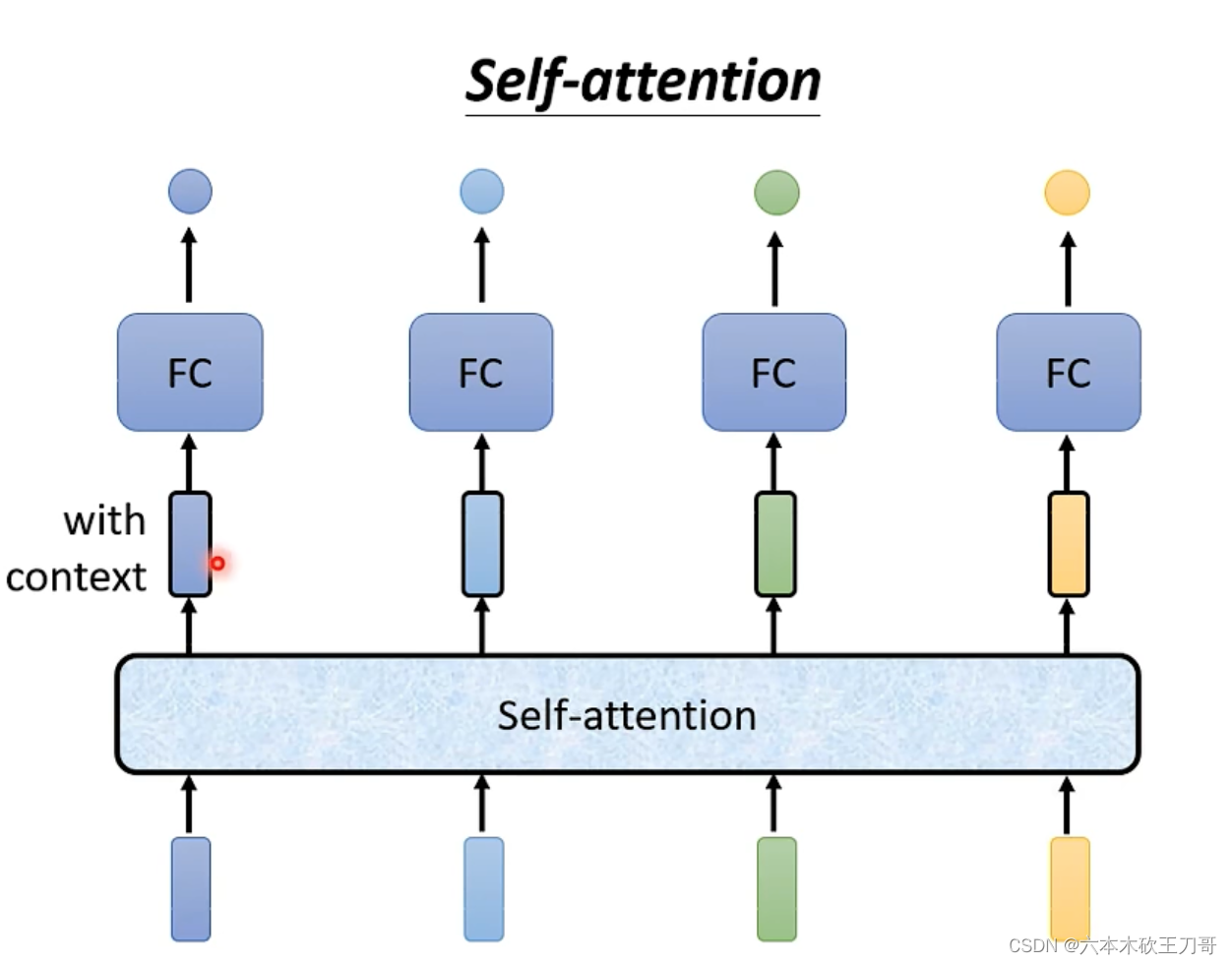
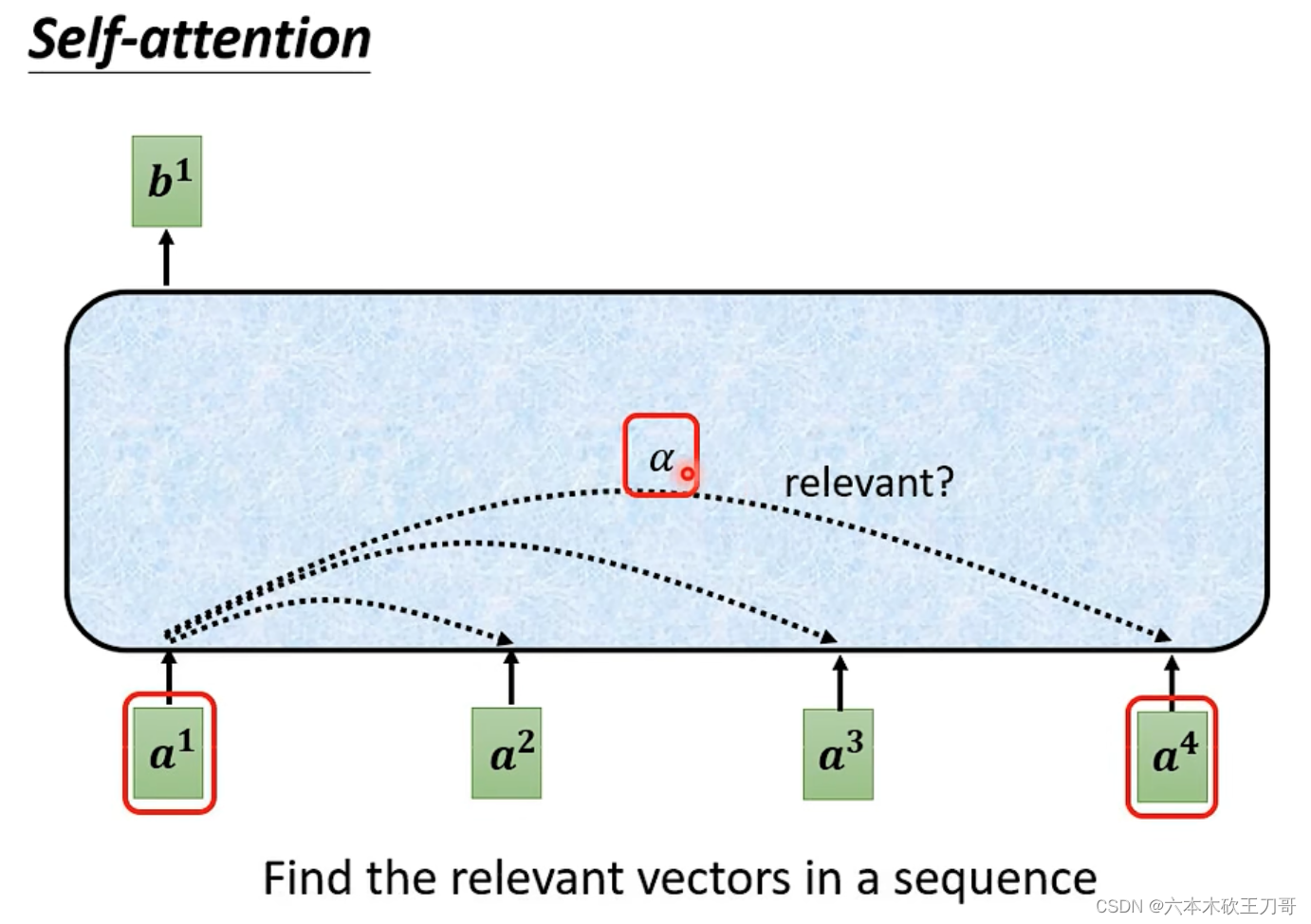
如何考虑某一个向量和别的向量之间的联系呢?可以用一个(attention分数)来表示。
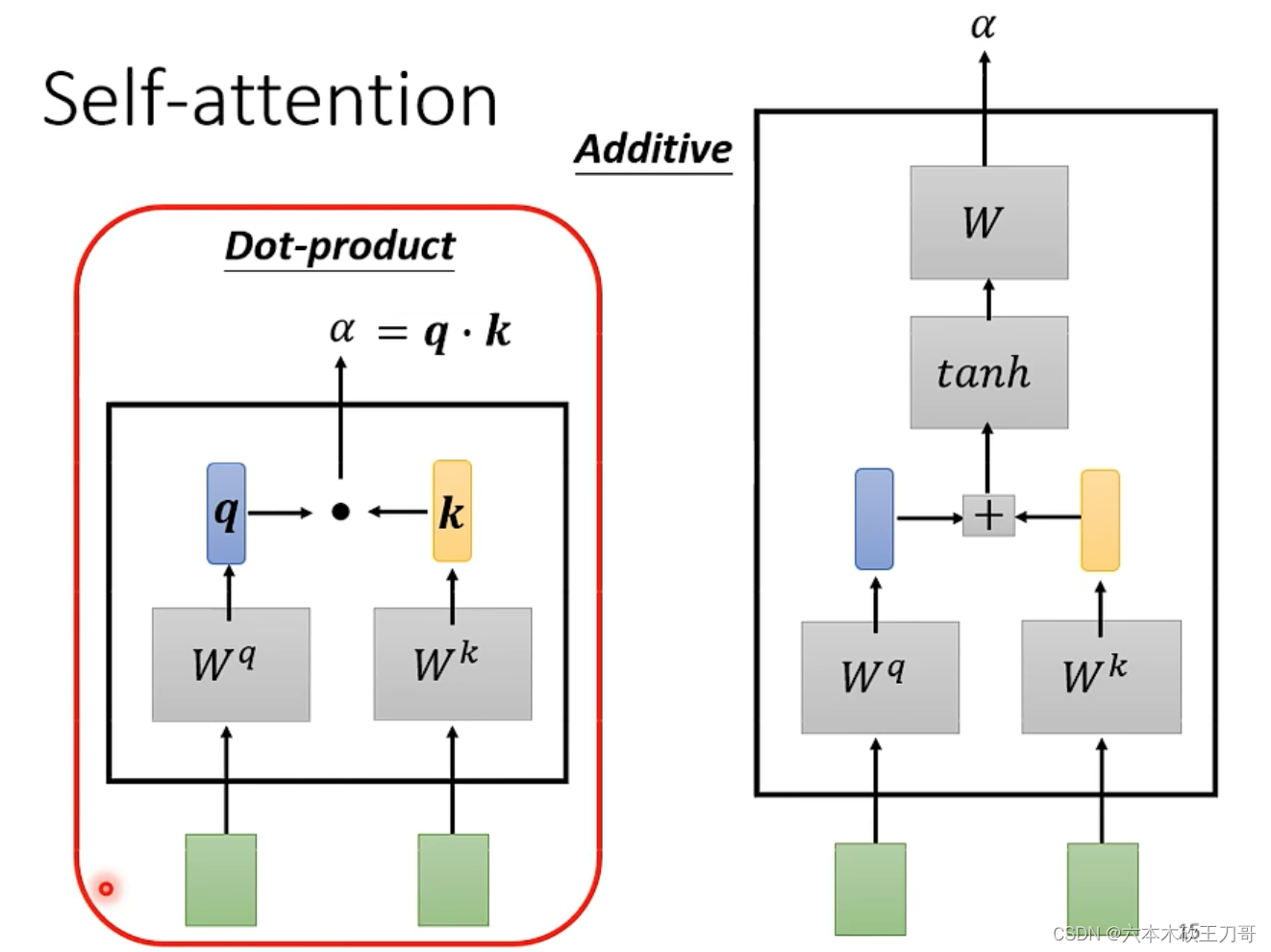
用两个向量计算一个,方法可以有如下两种。
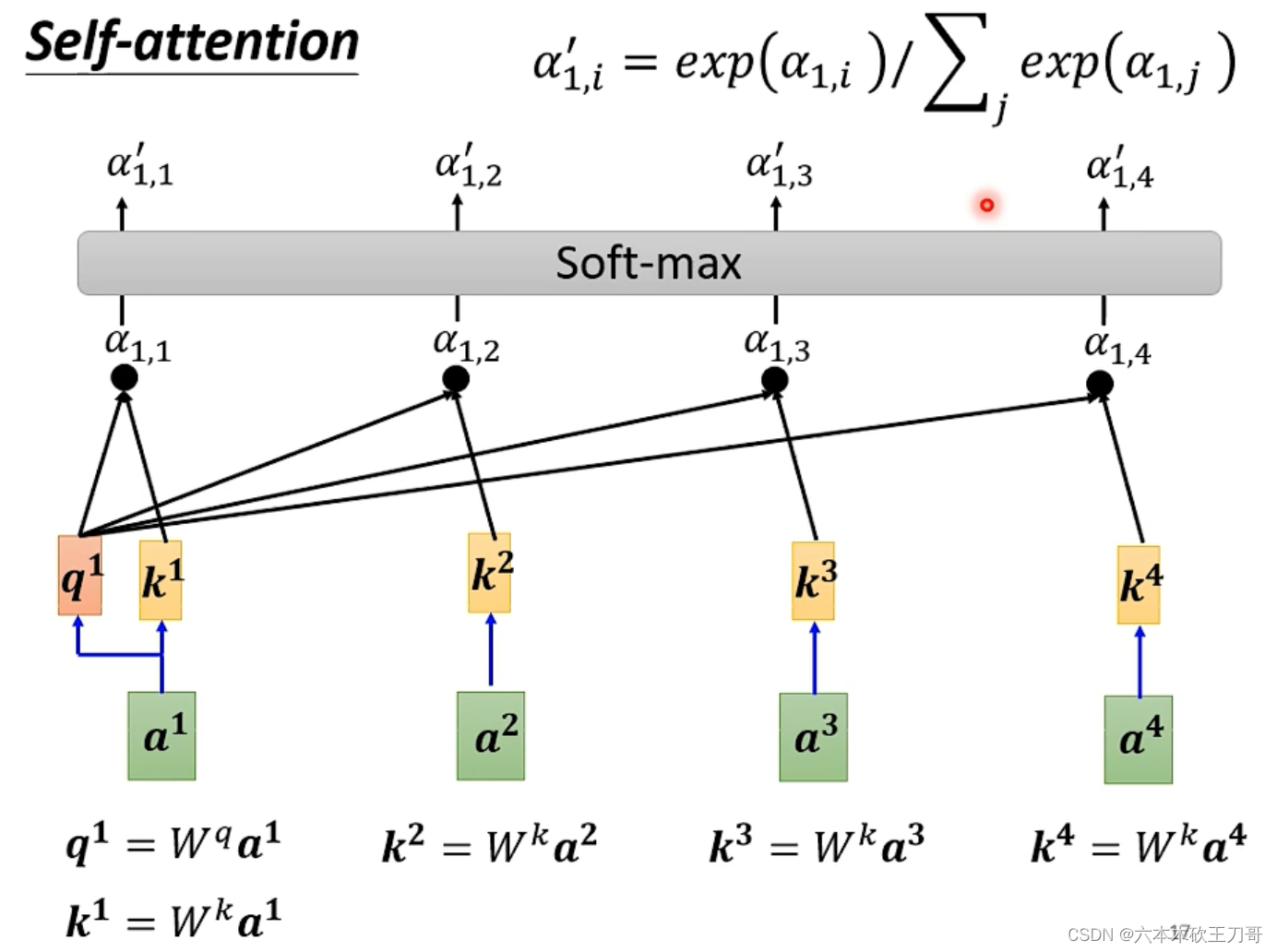
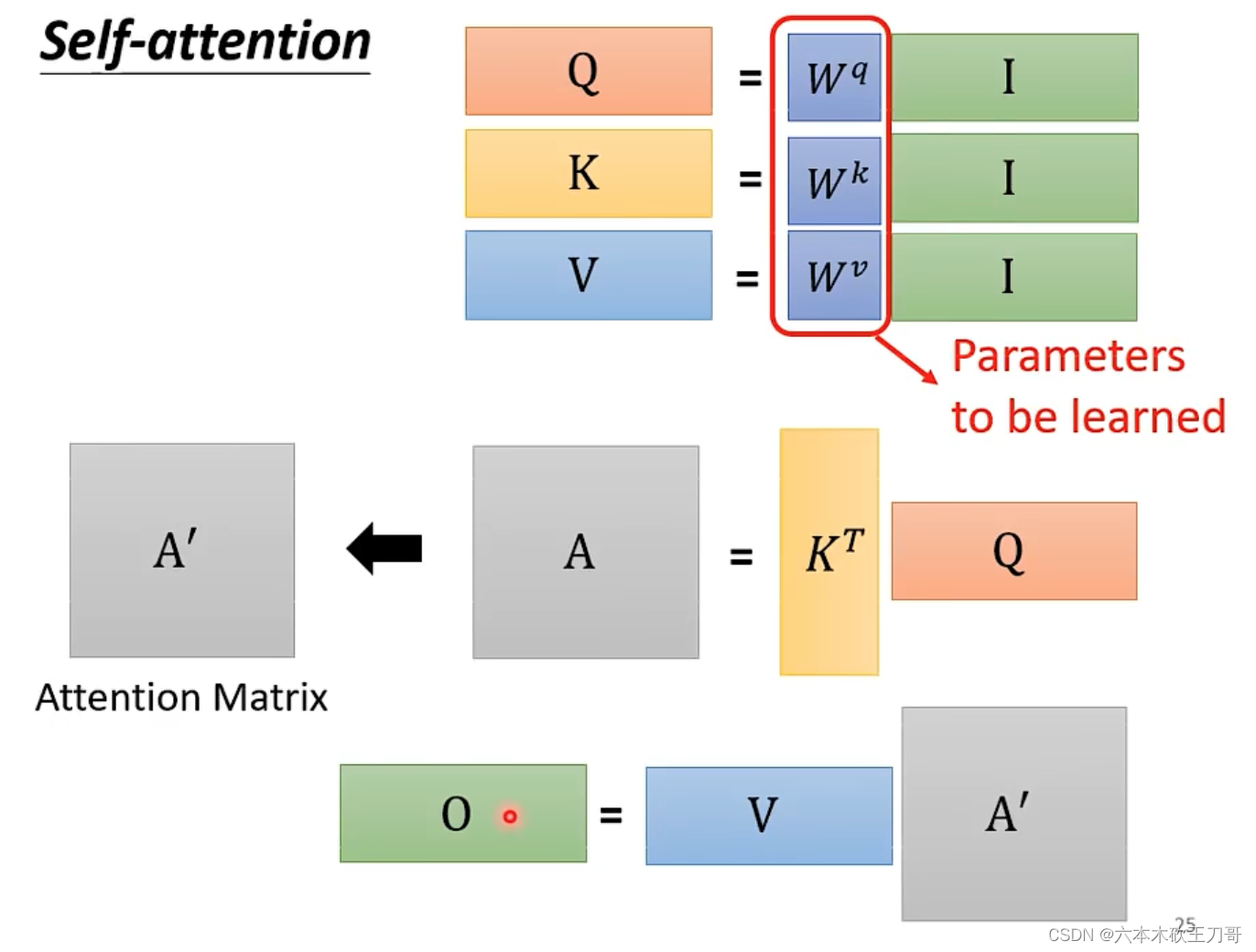
计算过程如下,假设要计算a1和别的向量之间的关系,每个输入向量和一个矩阵相乘,a1乘上矩阵得到q1,q的意思是query,代表要查询这个向量与其他向量之间的关系。其他向量得到的结果是k向量,然后通过q和k向量之间的计算,得到关联的值,再经过一层softmax得到a1和其他向量的关联程度大小。
我们已经得到向量之间的关联程度,接下来要考虑如何从其中抽取信息。我们把每个a向量乘上一个矩阵Wv,得到一个新的向量v,然后把这个向量v乘上每个关联的,再把这些向量相加得到b向量,这个b向量表示了哪个向量关联程度越大,其
越大,那么v向量乘上这个
之后,对结果b向量的贡献就越大。
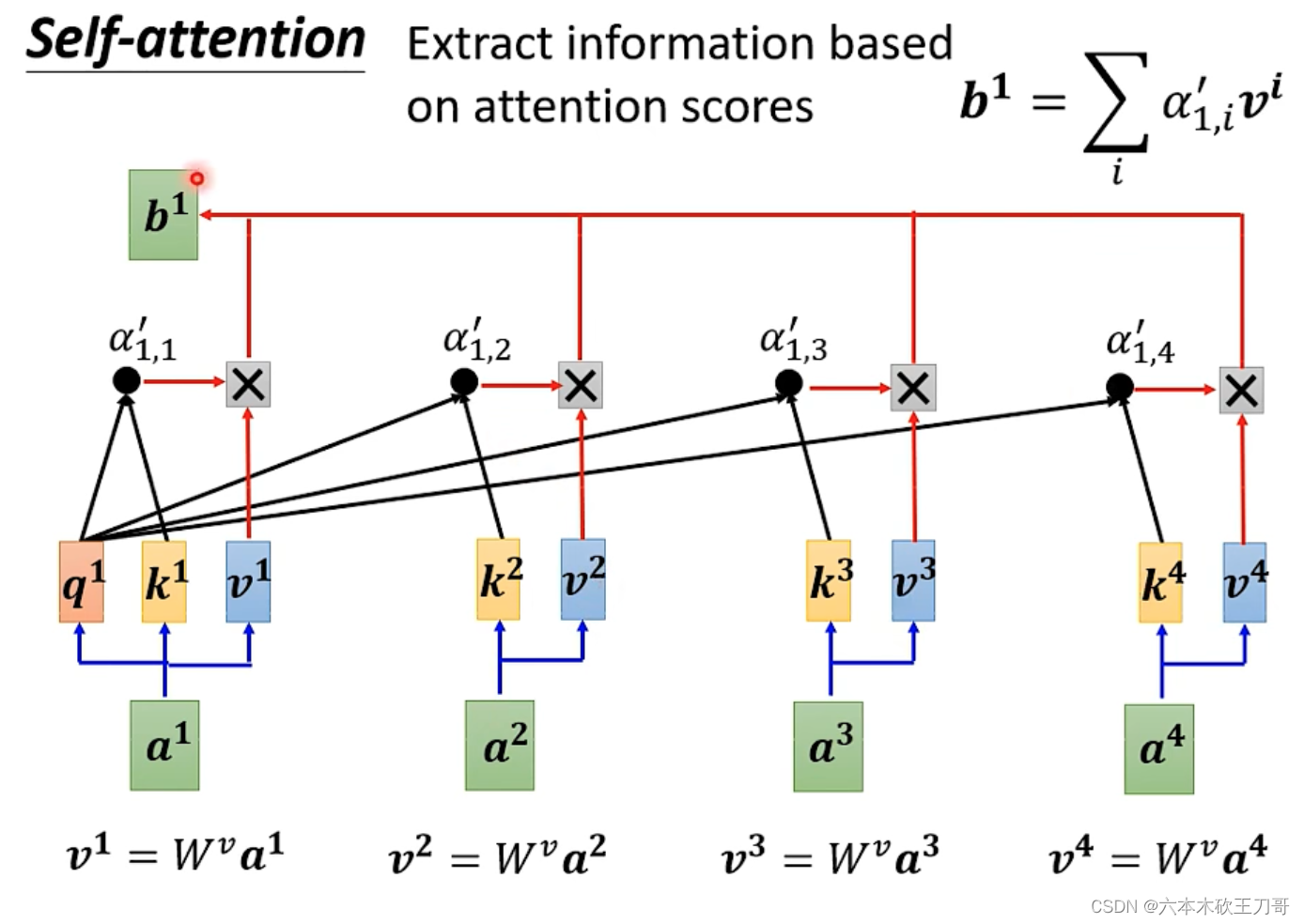
对于其他的b向量,计算过程同理。

计算q k v向量的时候,可以使用矩阵乘法来合并一系列过程。
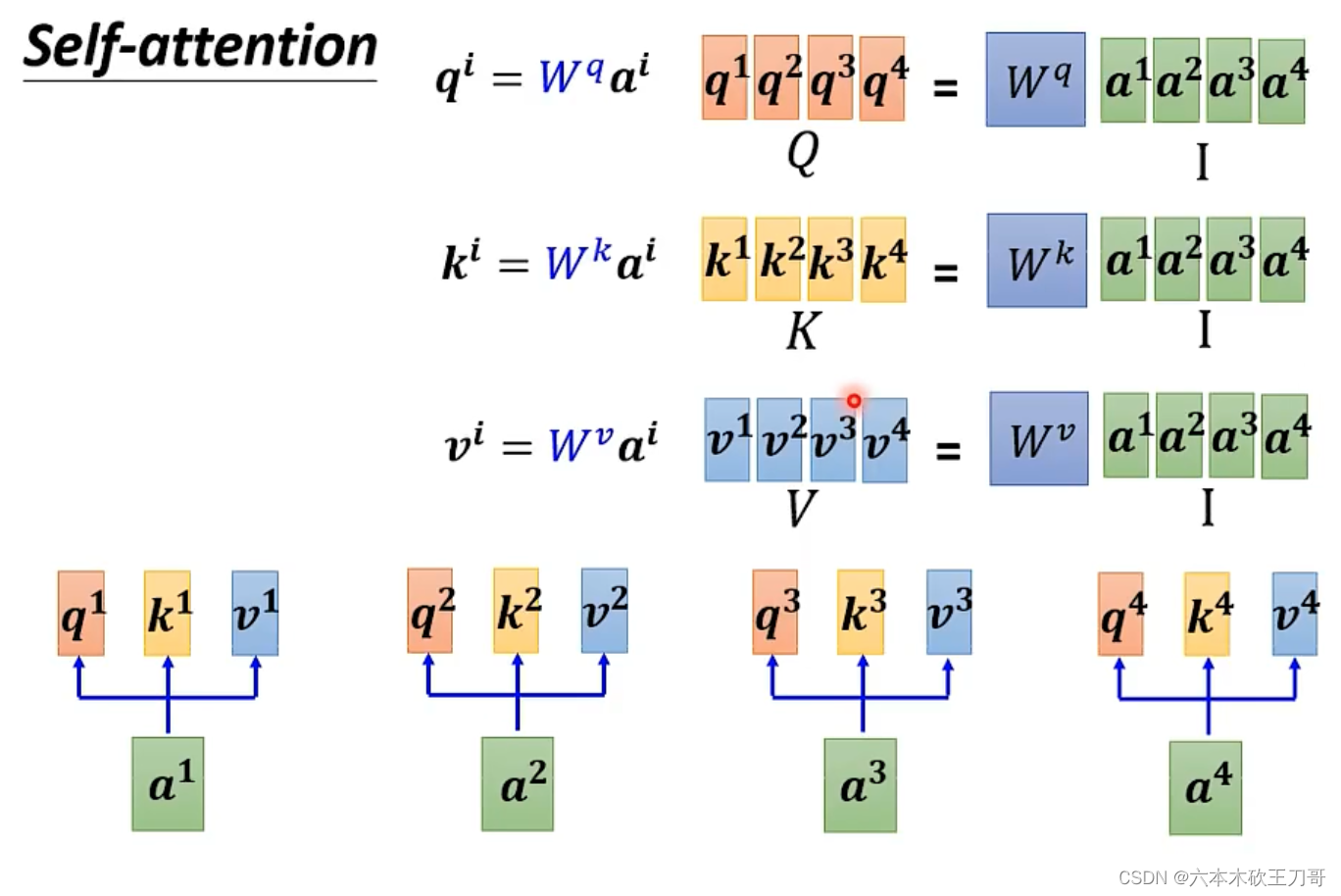
计算的过程也可以合并为矩阵向量乘法
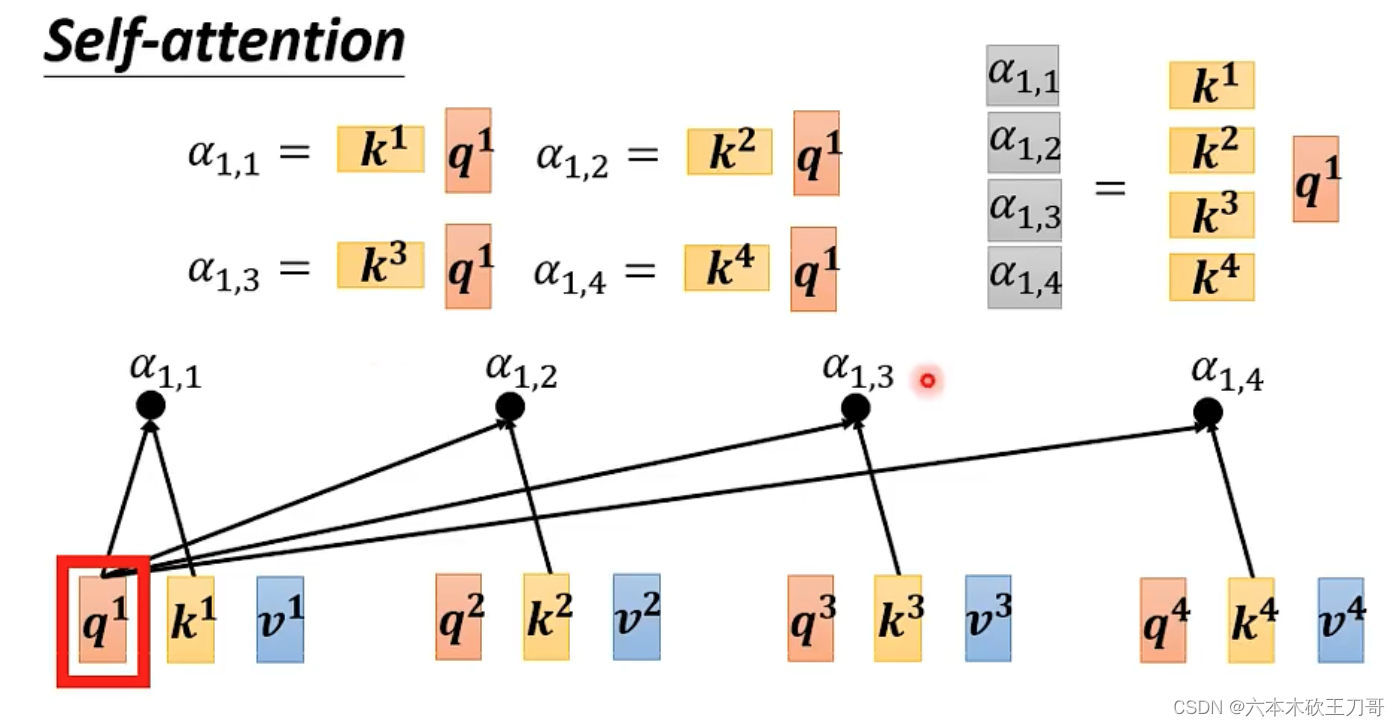
接下来,合并所有的计算过程,变成一个矩阵矩阵乘法。

接下来,计算b向量,同样可以把计算合并为一个向量矩阵乘法。
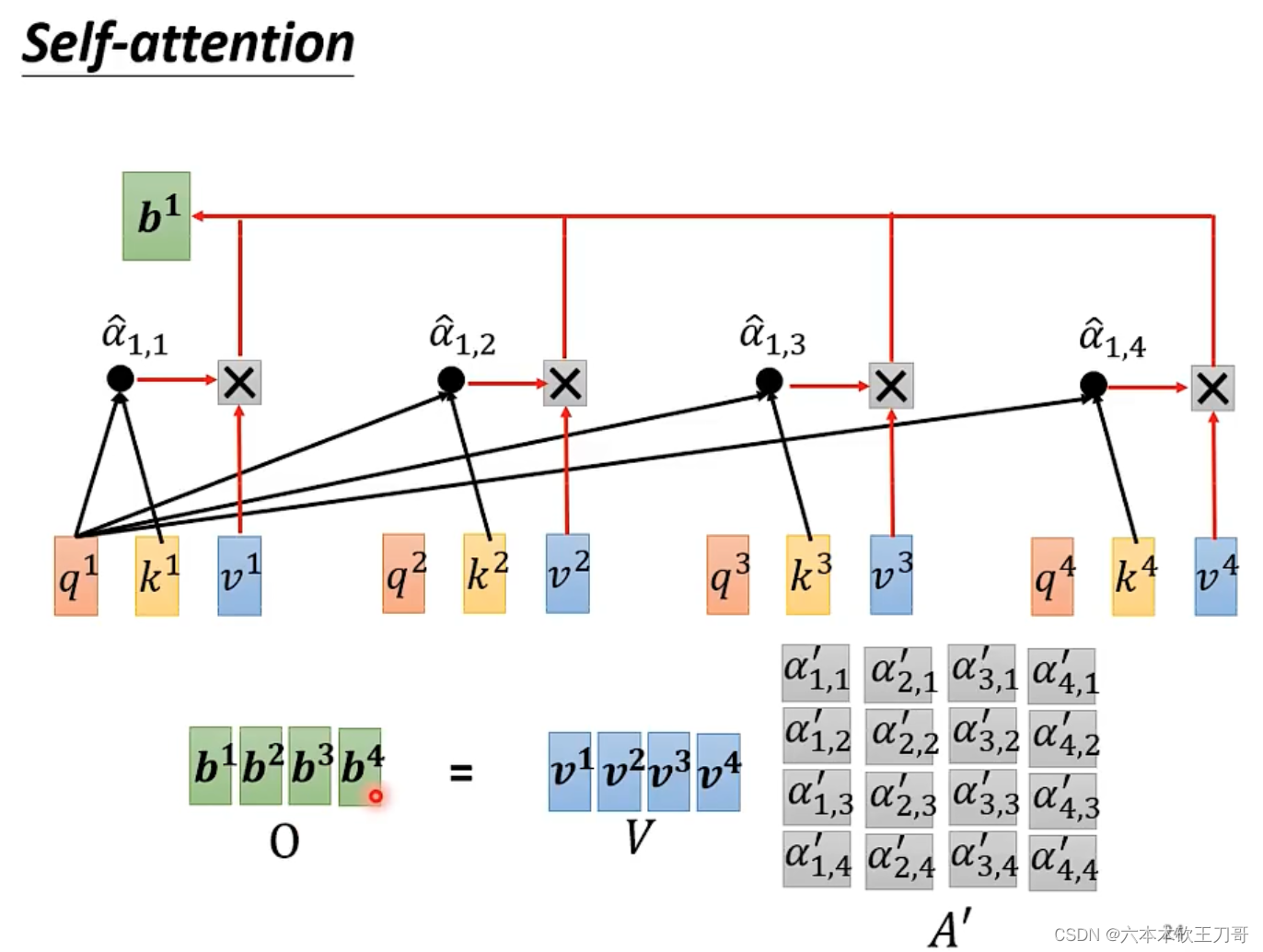
全部计算过程总结为下图,其中只有三个W矩阵是需要学习的,别的参数都已经被人为设定好。
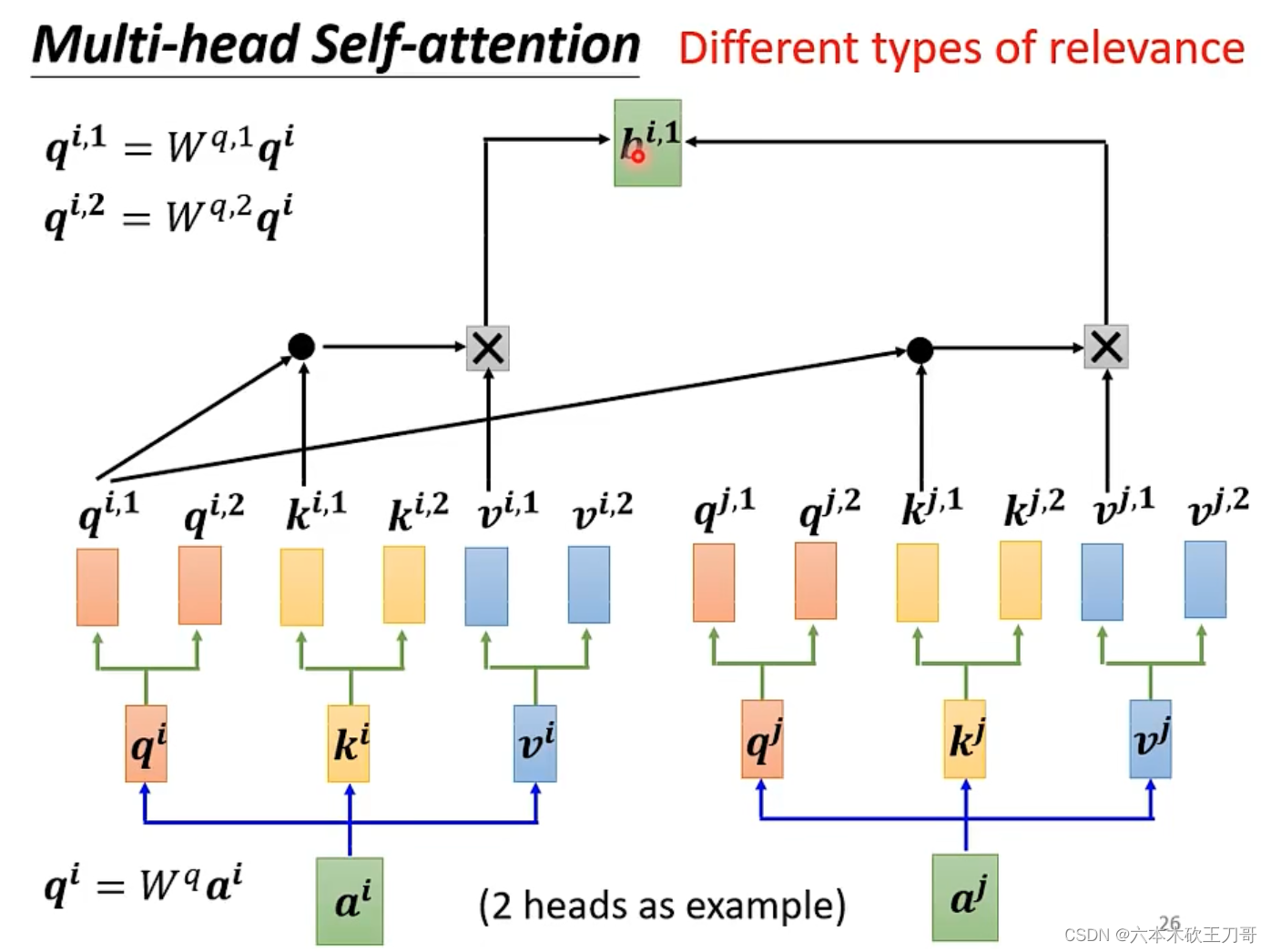
如果有多种相关性需要处理,就可以使用multi-head self-attention。例如如果有两个head,就可以用来找两种不同的相关性。
在计算的时候,初始的q k v乘上两个矩阵可以得到不同的部分。每次对于不同的相关性,值关注和它相关的向量,例如只关注
,
,
和
,下面演示了计算
的过程。
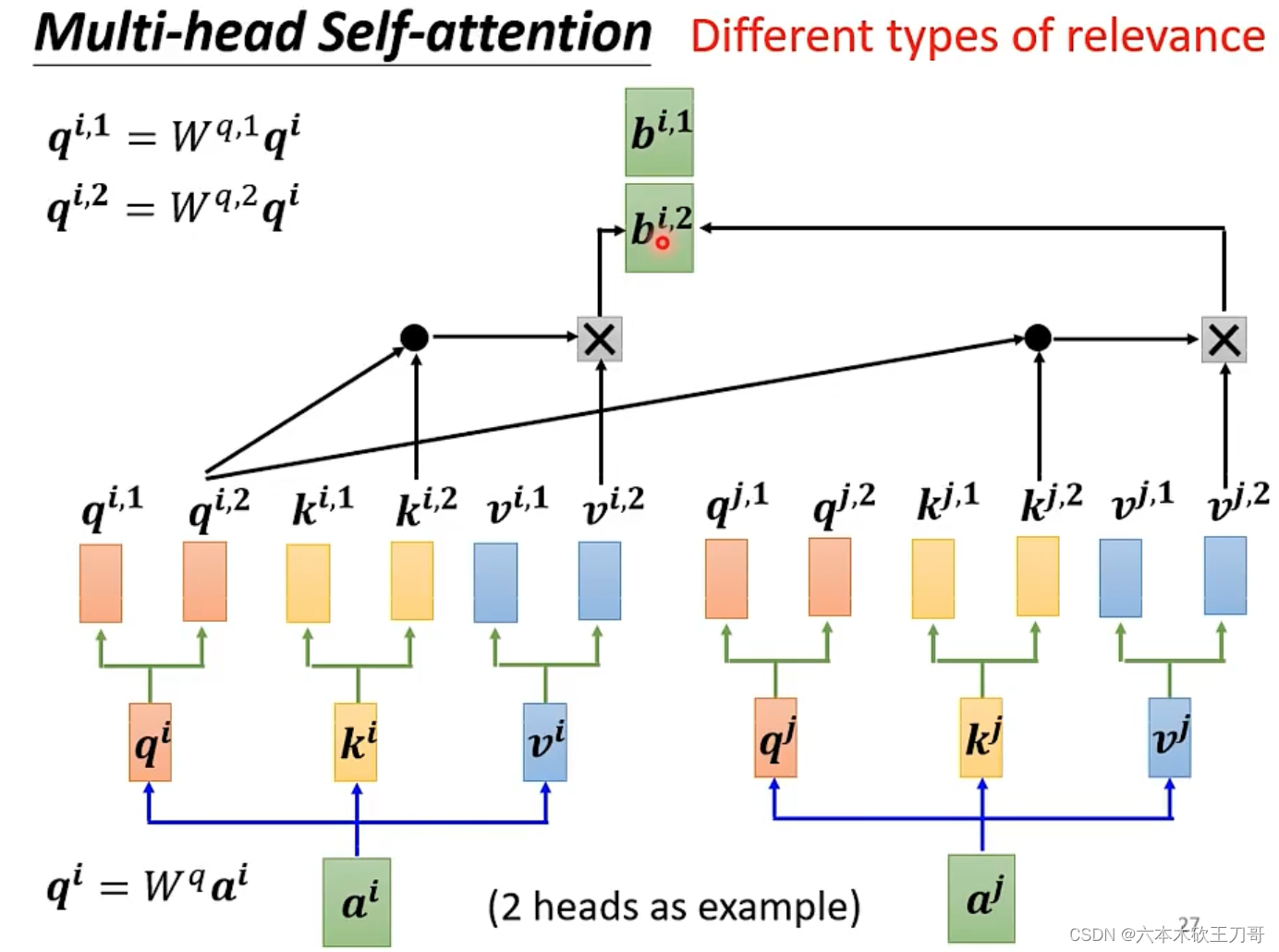
同理,计算。
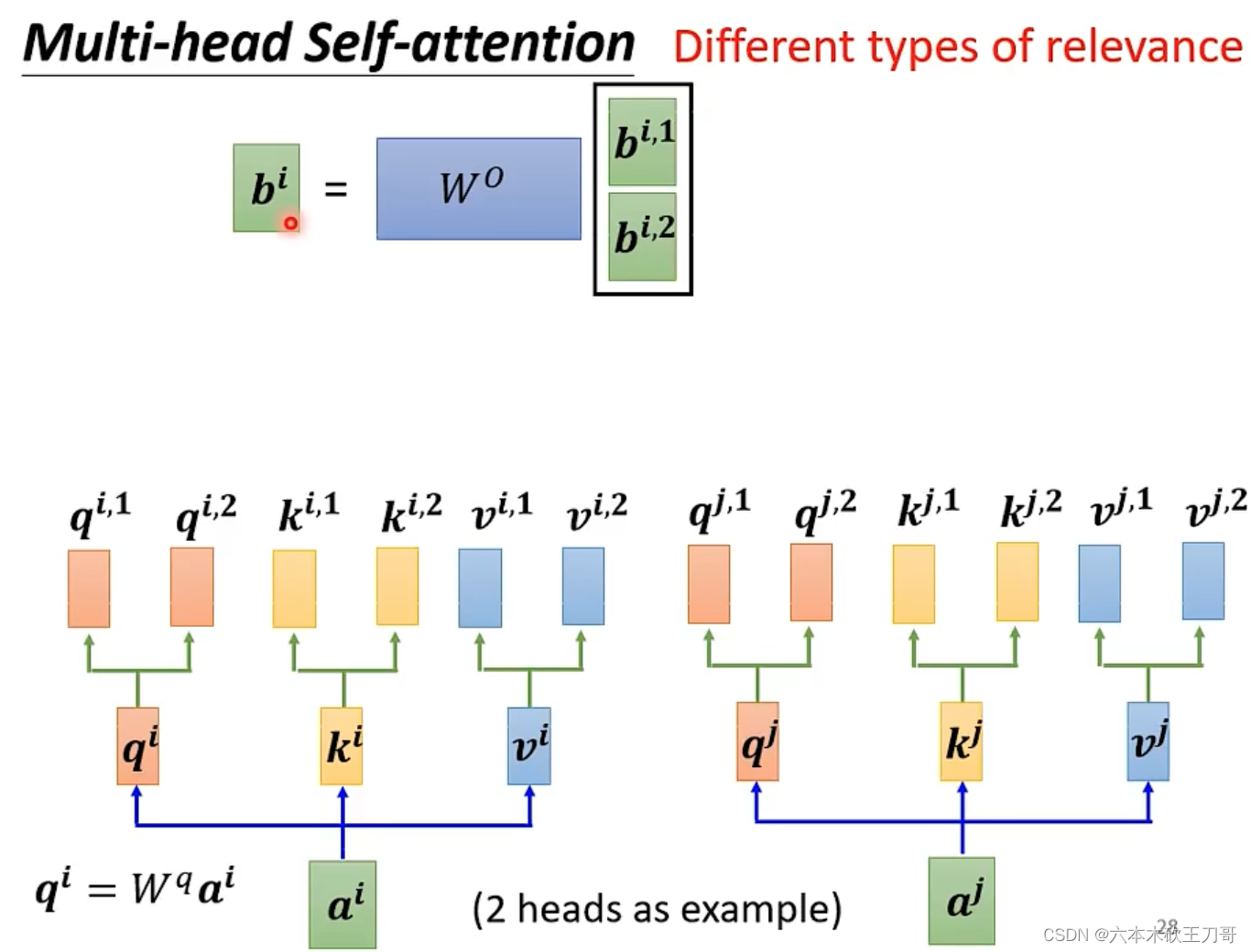
接下来,可以把和
向量连接起来再乘上矩阵得到最后的b向量。
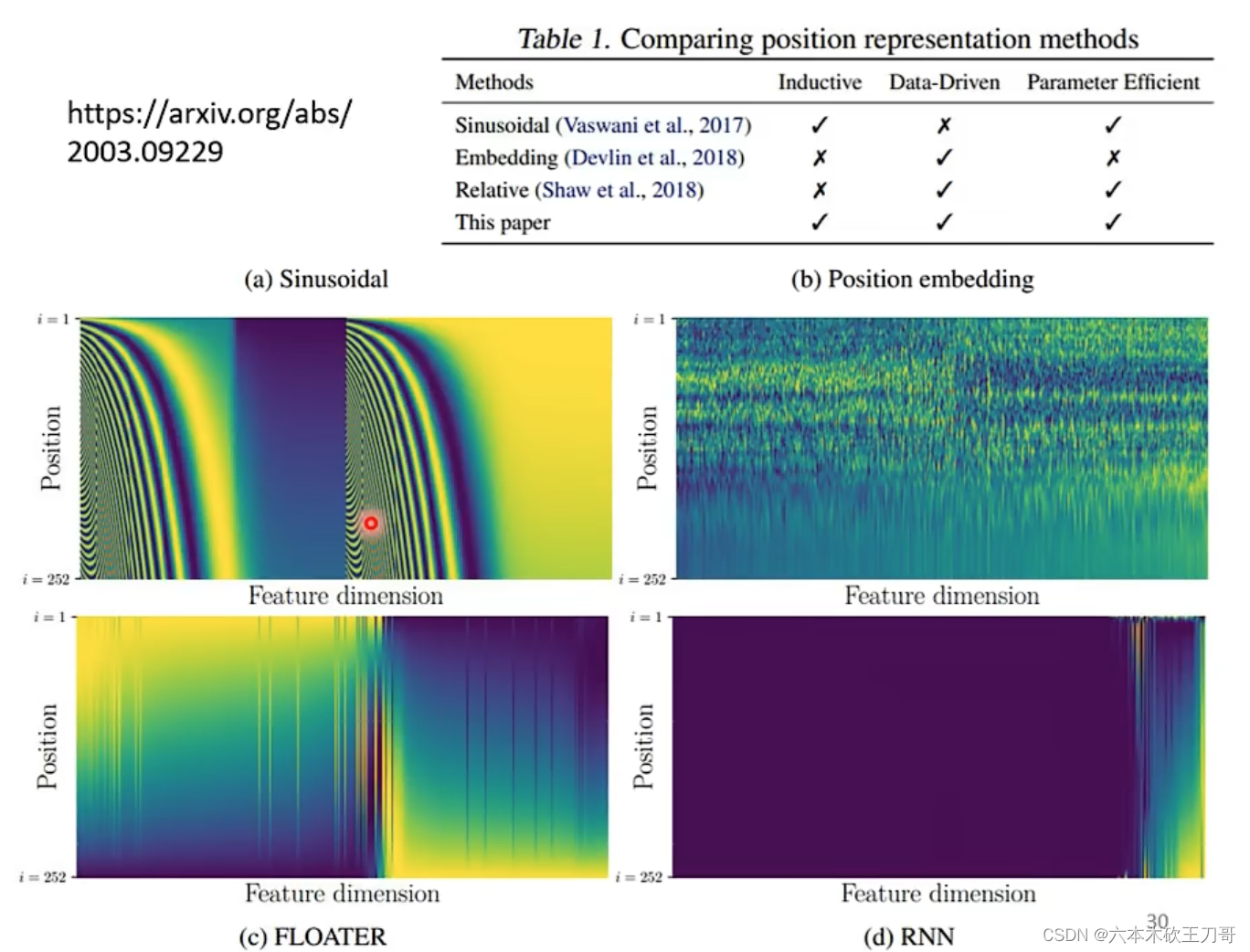
3. 位置信息
在之前的计算中,我们并没有关注每个向量的位置,虽然标上了每个向量的下标,但是在计算中,其实下标信息是不知道的,对于每个向量,相差多少距离都是未知。
位置信息是很重要的,例如在一句话中,动词出现在句首的概率较低。
生成位置信息的方式有很多种,究竟哪种最好,目前尚在研究。
4. Self-attention的应用
Self-attention不仅在Transformer上有应用,还包括BERT上也有用到。

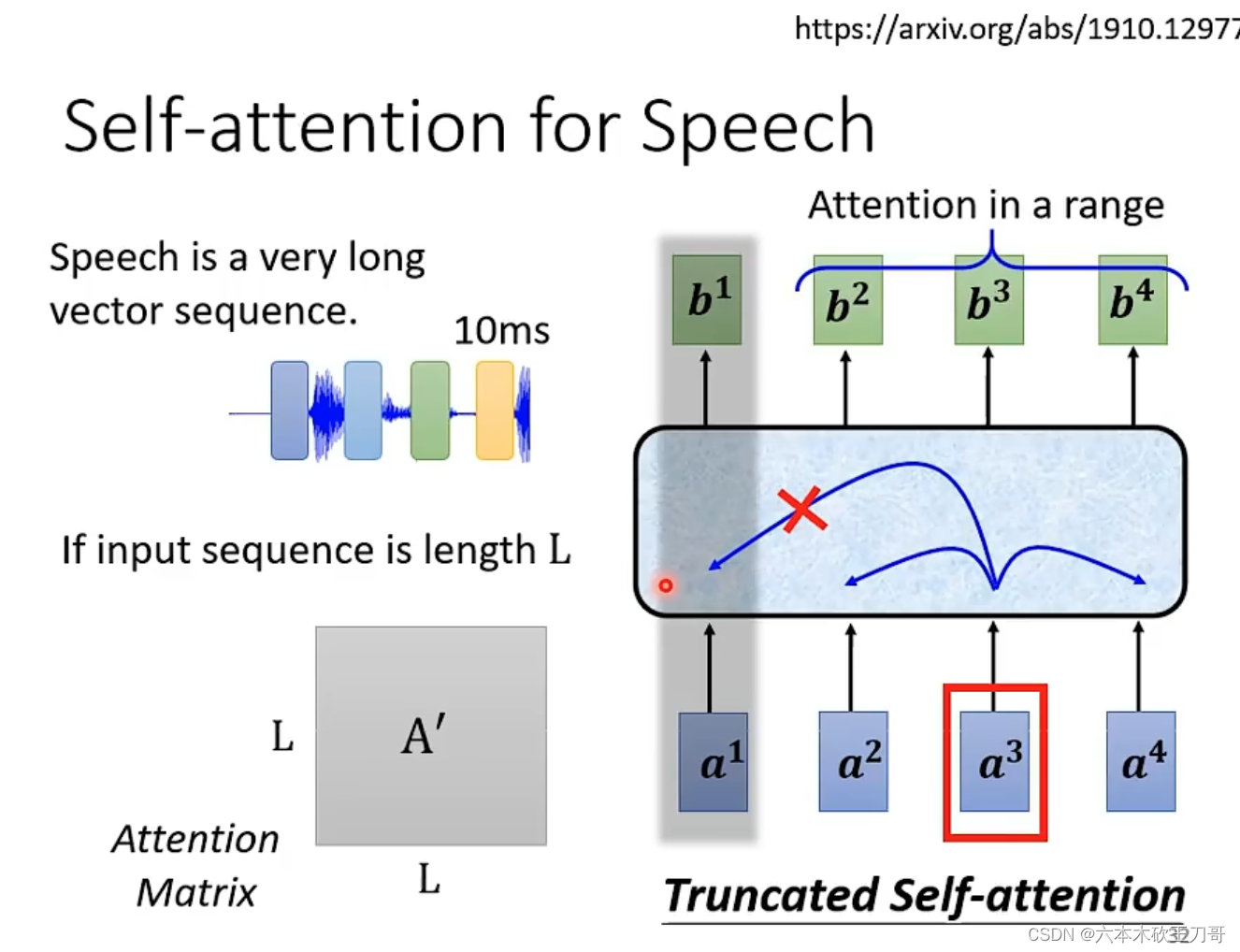
当然除了NLP领域,还有别的领域也有使用到,例如语音识别,在语音处理中,例如每10ms处理出一个向量,在语音较长的时候,会出现非常庞大的向量集合,这会导致处理的attention矩阵非常巨大,因为attention矩阵的大小取决于输入向量的数量。
一种解决方法是只处理一部分向量,也就是Truncated Self-attention。
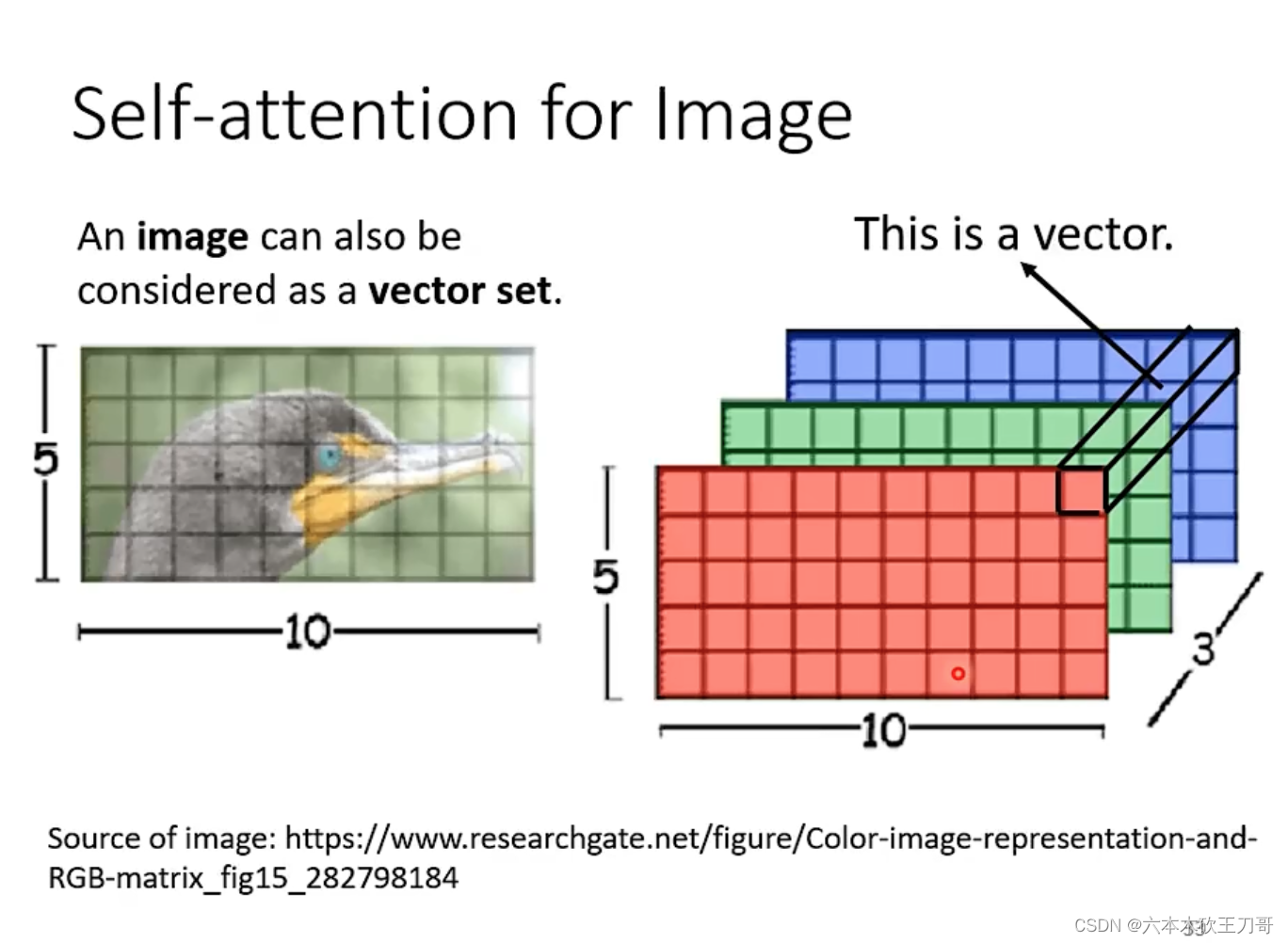
图像处理也可以使用自注意力模型,把图像按通道方向上分成多个向量。
自注意力模型在图像处理上的应用。
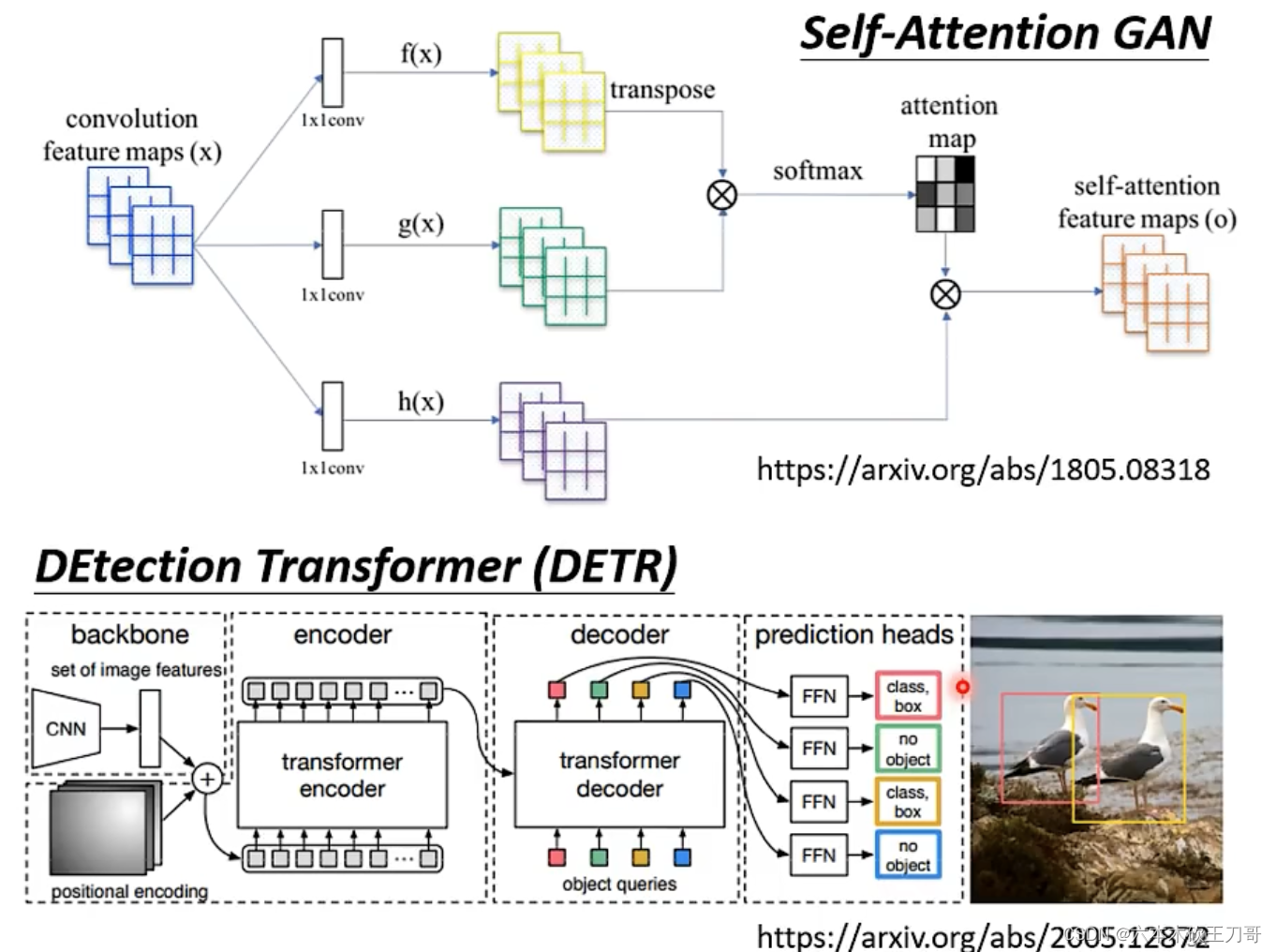
Self-attention与CNN的区别,在于CNN是通过过滤器,而Self-attention自己选出相关像素。(?)

CNN是Self-attention的一个子集,在限制某些因素的情况下,Self-attention可以做到和CNN一样。
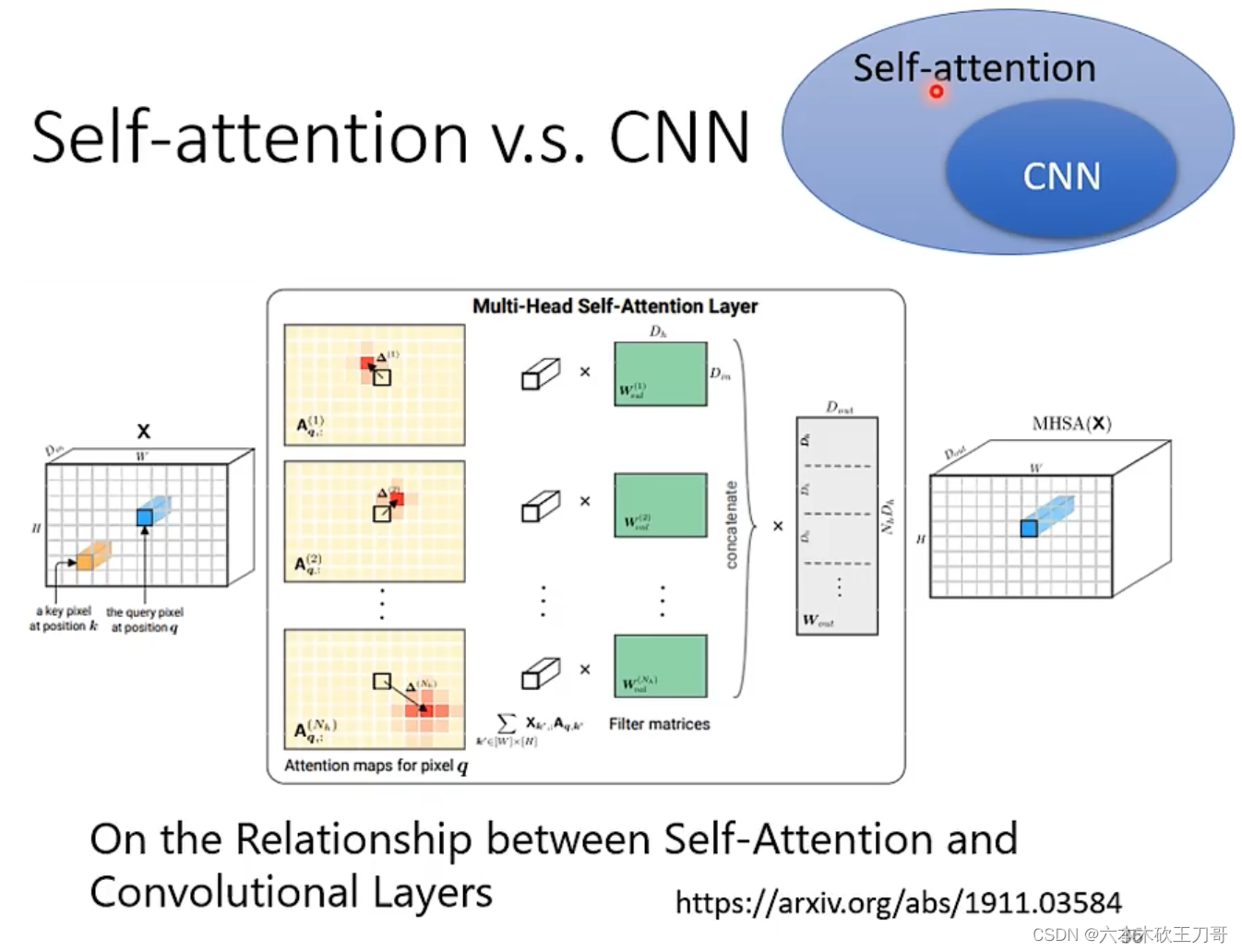
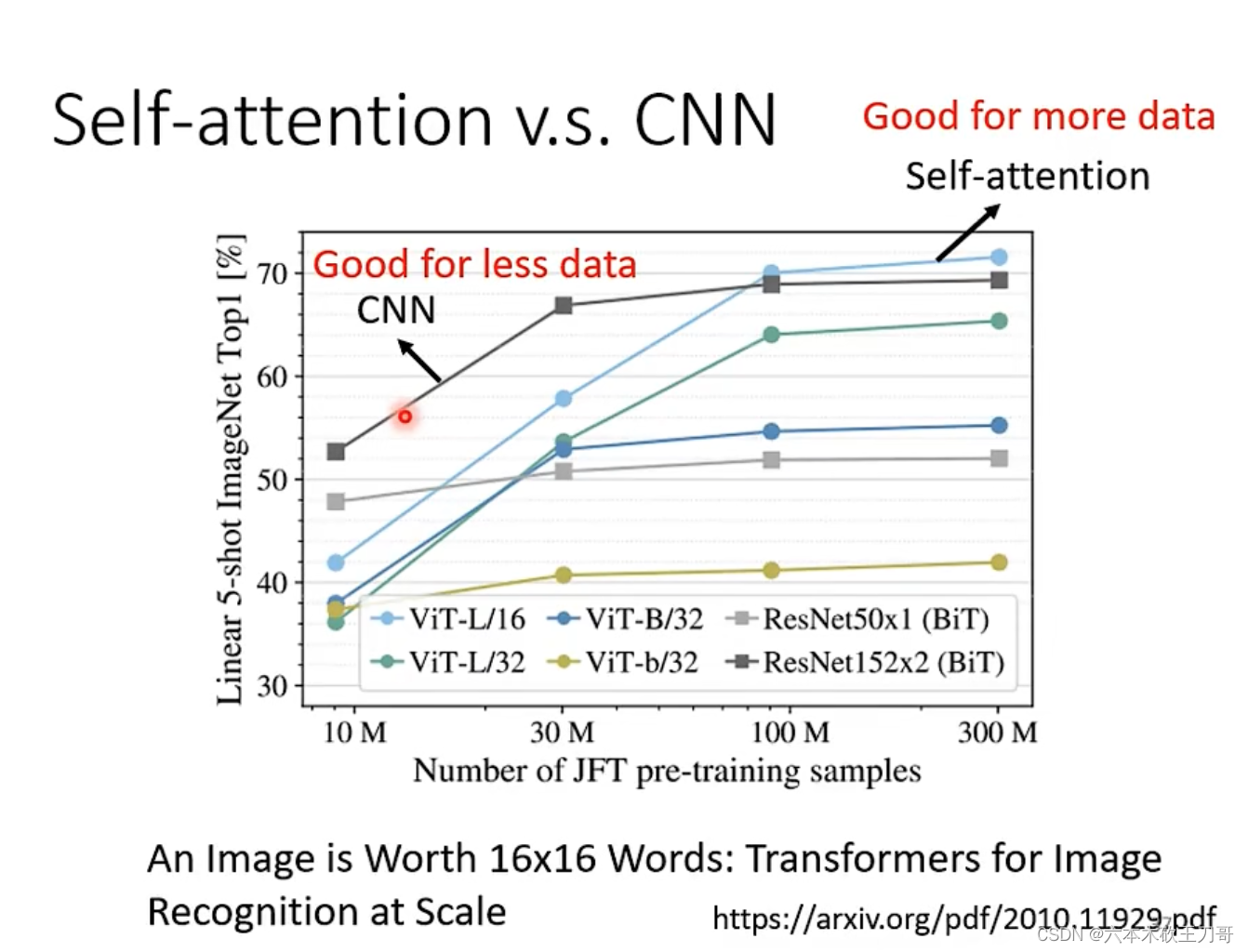
CNN适合于比较小的数据集,Self-attention适合于比较大的数据集,这是因为CNN模型比较简单,而Self-attention模型较复杂,对于小的数据集容易过拟合。
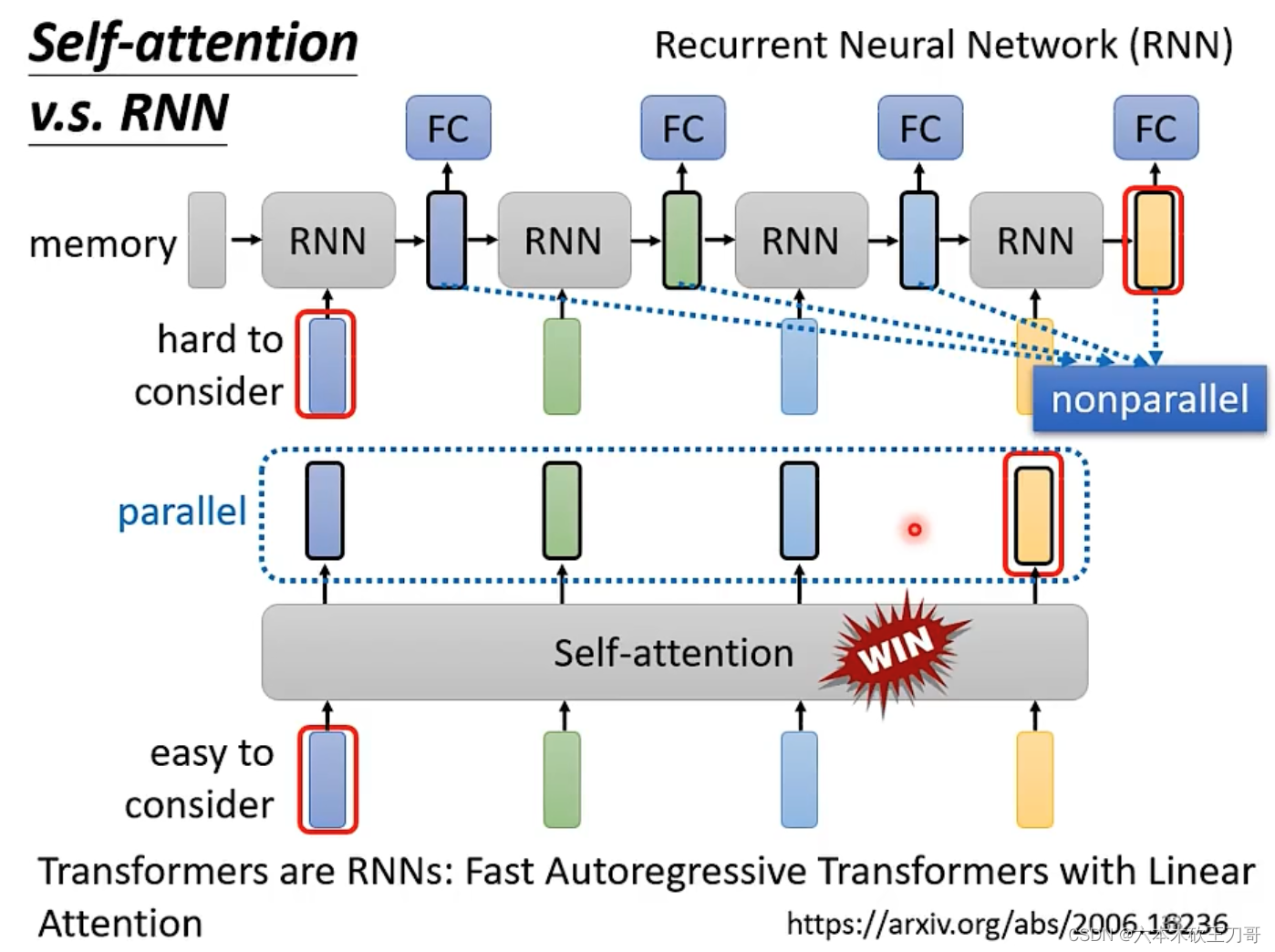
RNN和Self-attention的区别和联系。
联系在于对于双向的RNN,和Self-attention一样,其实也是考虑到了整个输入vector set。
但是区别在于,RNN中一个较远的输出如果想要获得之前的输入信息,就需要从很远的地方经过若干个时间,保存到memory中然后到达目的地,但是Self-attention不需要这样,即使逻辑距离上间隔很远,实际距离上也可以直接拿到这个vector。
第二个显著的区别在于,基于现代并行处理计算机的基础上,RNN是没有办法并行计算的,因为后一个输出依赖于前面的输入,但是Self-attention没有这种依赖关系,是可以并行计算的。
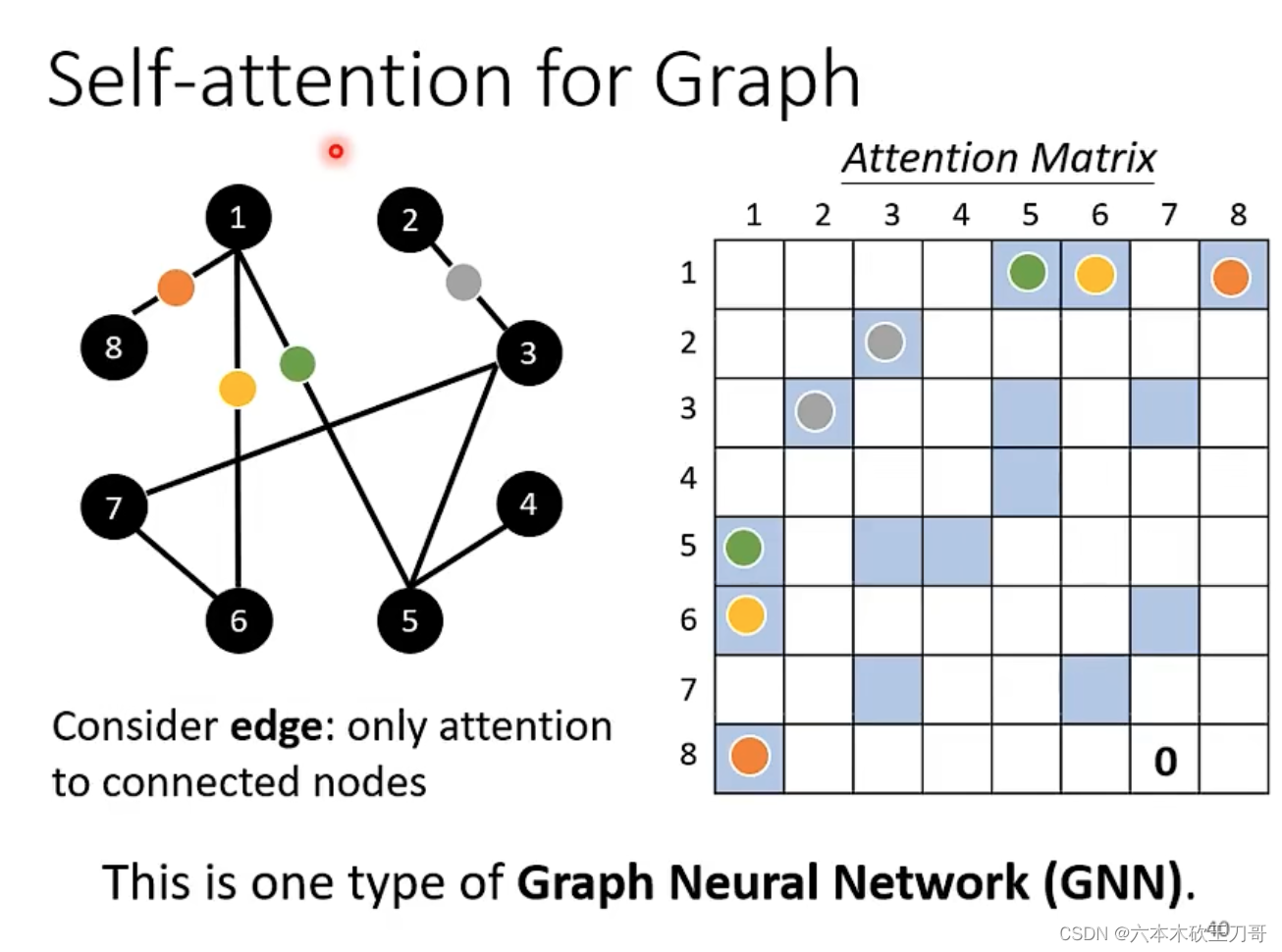
在图应用中用到Self-attention,因为图的每个节点之间是有显式的联系,所有在创建注意力矩阵的时候,可以直接在矩阵上标上有联系的点,没有联系的点之间的关系可以用0代替。
Self-attention有很多变形,名字的后缀大部分都是以former结尾,对于不同的模型,计算的速度不一样,但是速度快不代表准确率高。
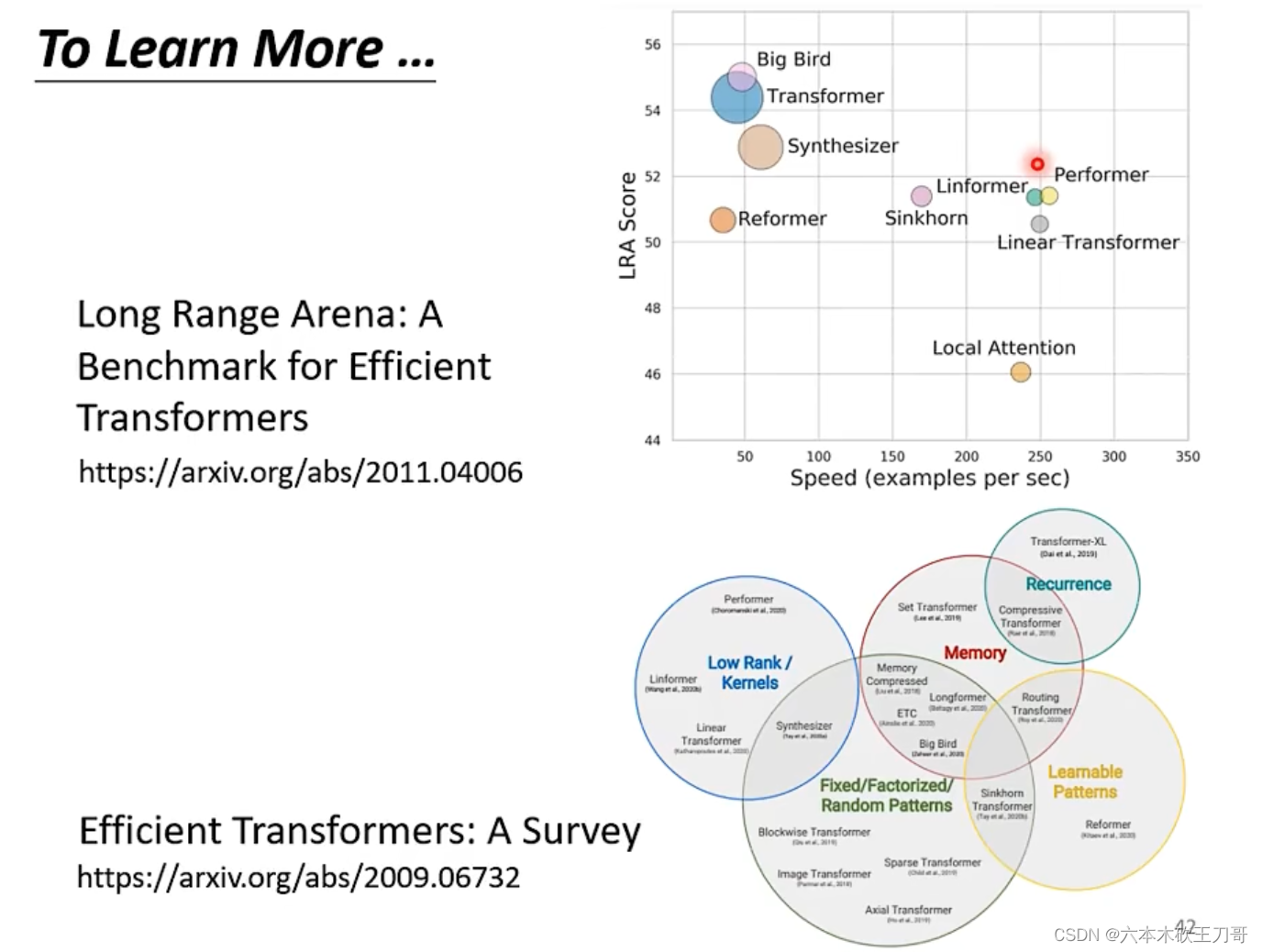
5. Transformer
5.1 seq2seq举例
对于一些实际的应用,比如语音翻译,输入一段音频输出一段翻译,为什么要做这种任务呢?为什么不直接先做一段语音识别再做一段机器翻译?这是因为世界上很多语言是没有文字的。
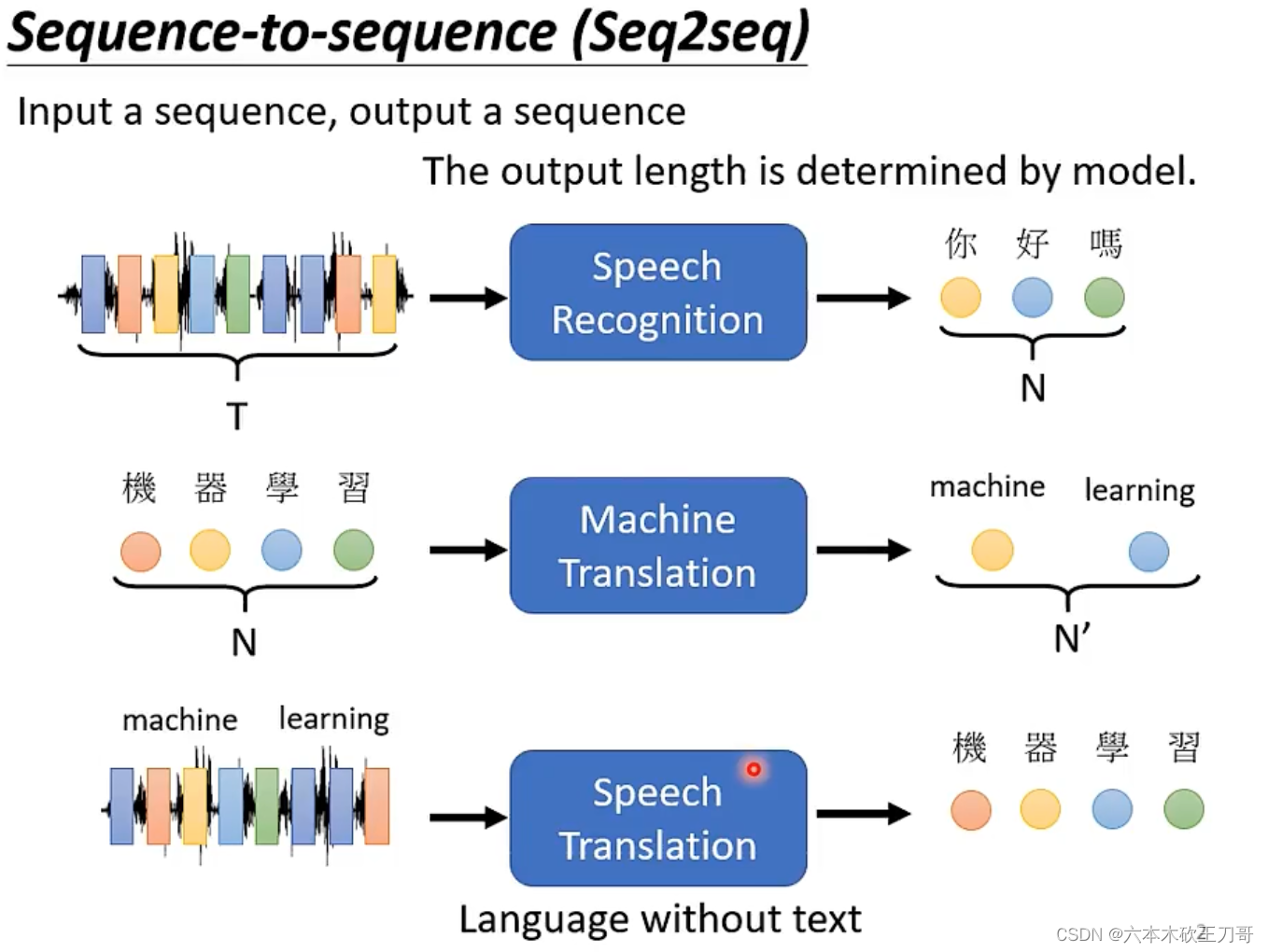
一个很好的例子是输入台语(闽南语),输出中文汉字,当然不是说台语没有文字,只是会的人不多。例如下载一些乡土剧的视频,通过闽南语语音和中文字幕,来训练模型。
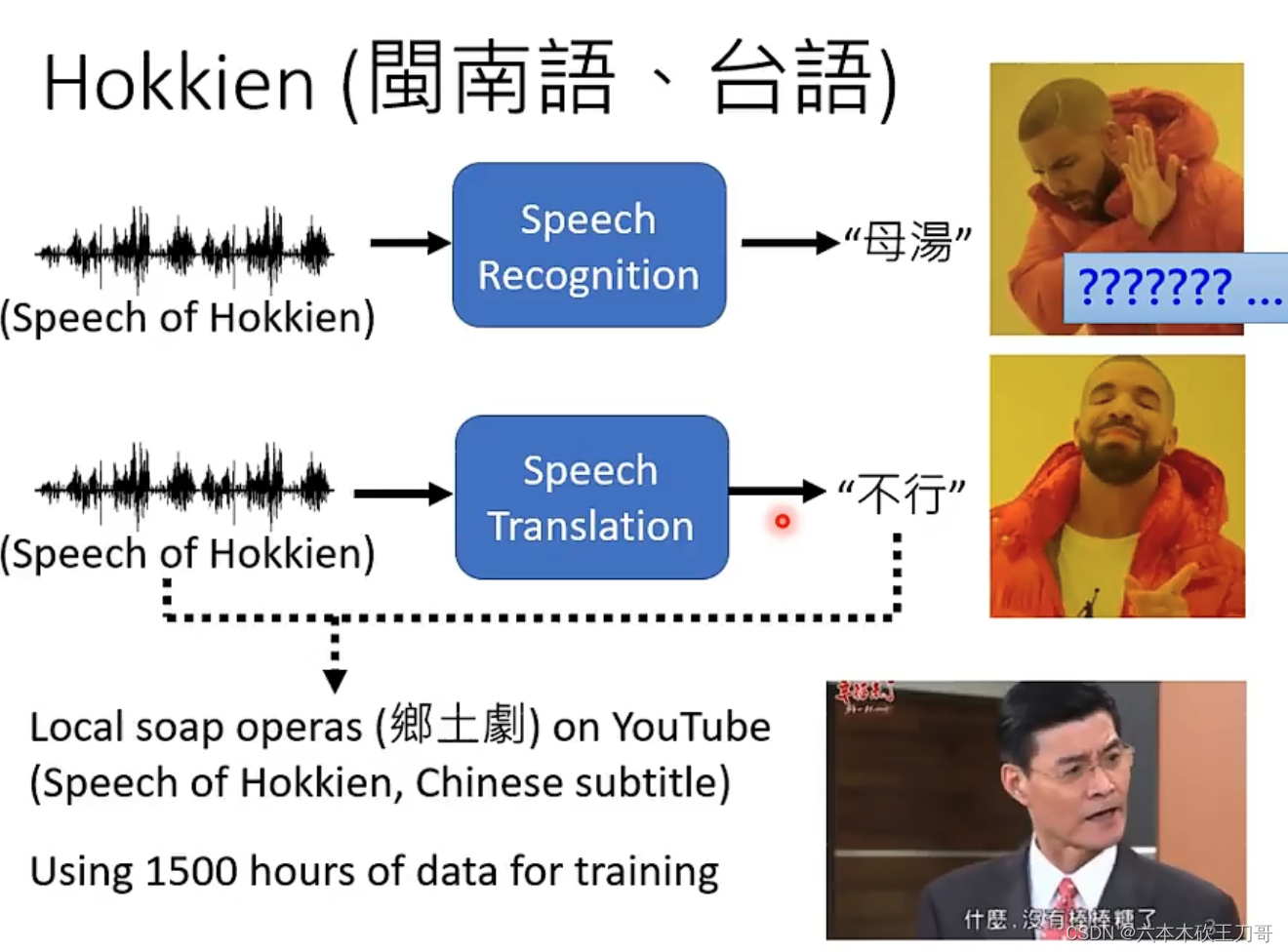
训练这样的模型听起来有很多的问题。包括背景音乐,噪音等等,其实都不需要管它,只要硬训练其实就可以。

真的有模型训练了这种转换,对于一些输入来说,机器可以很好的转换,但是也会有出错的地方,例如闽南语倒装的部分,机器就不会学习的很好。

如果反过来,输入中文文字,输出闽南语声音,就是语音合成。
聊天机器人。
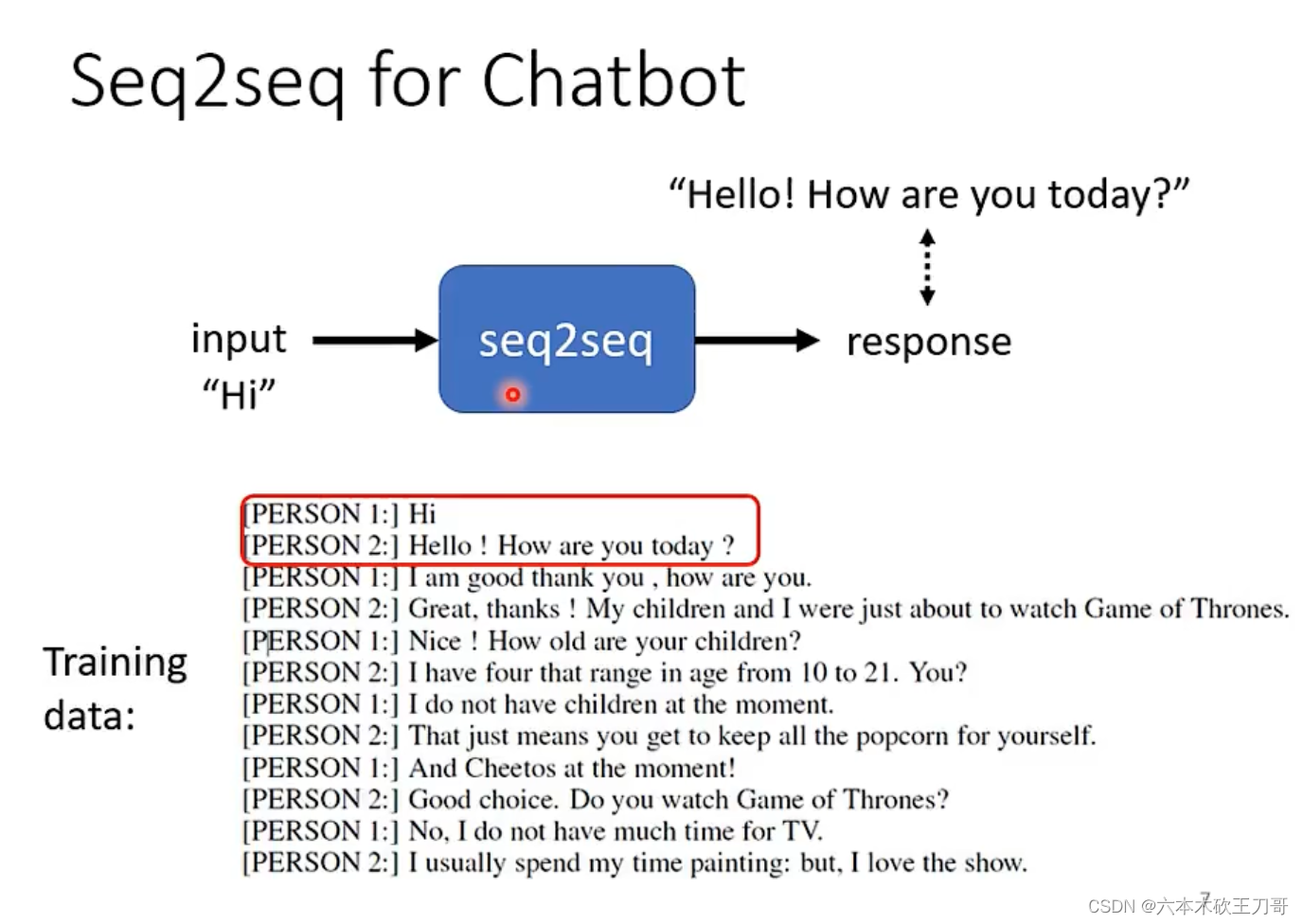
NLP中各式各样的问题都可以用QA来理解,QA可以用seq2seq来实现。
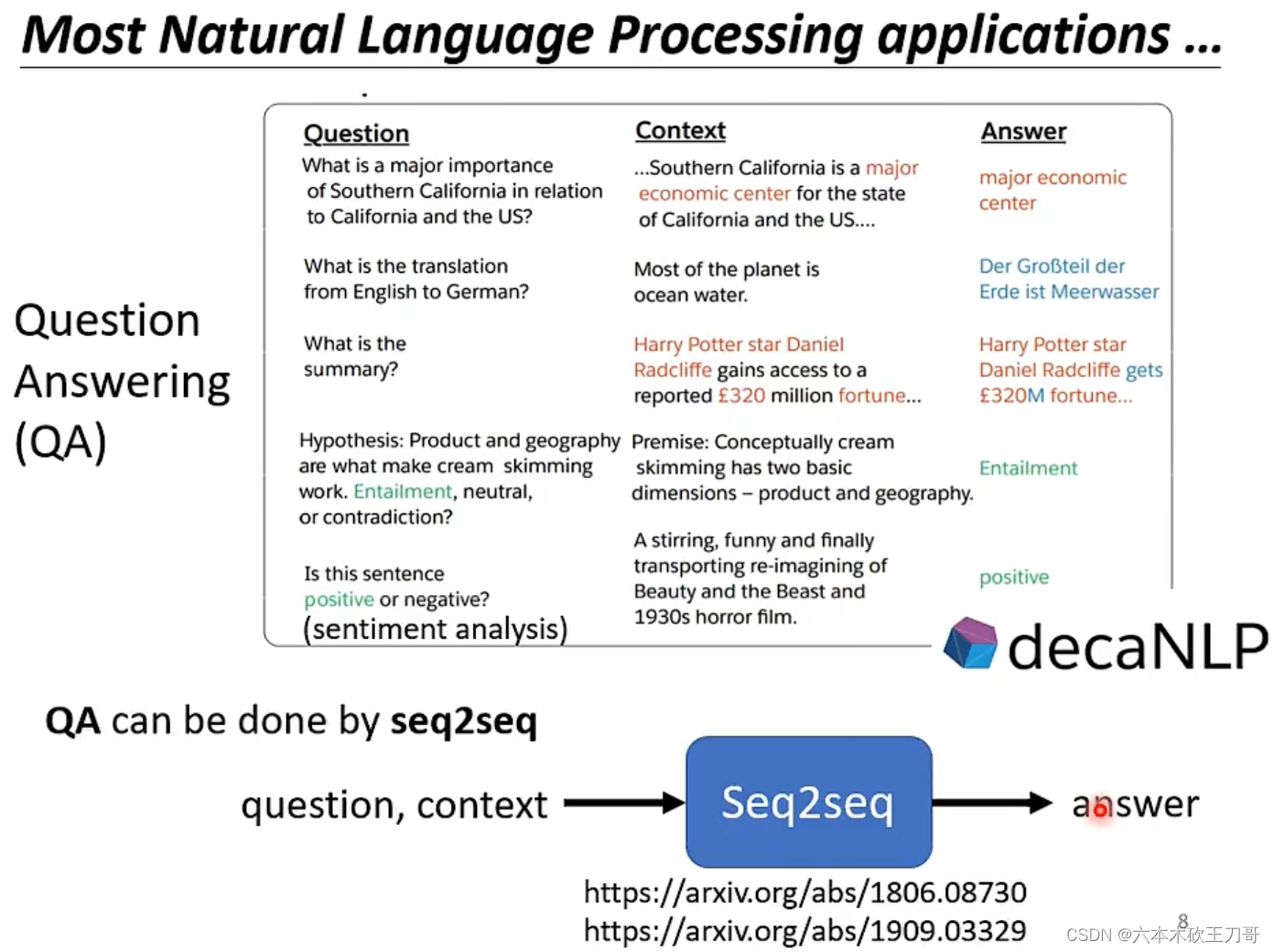
当然,对于特定的任务,用特定的模型可以输出更好的性能。
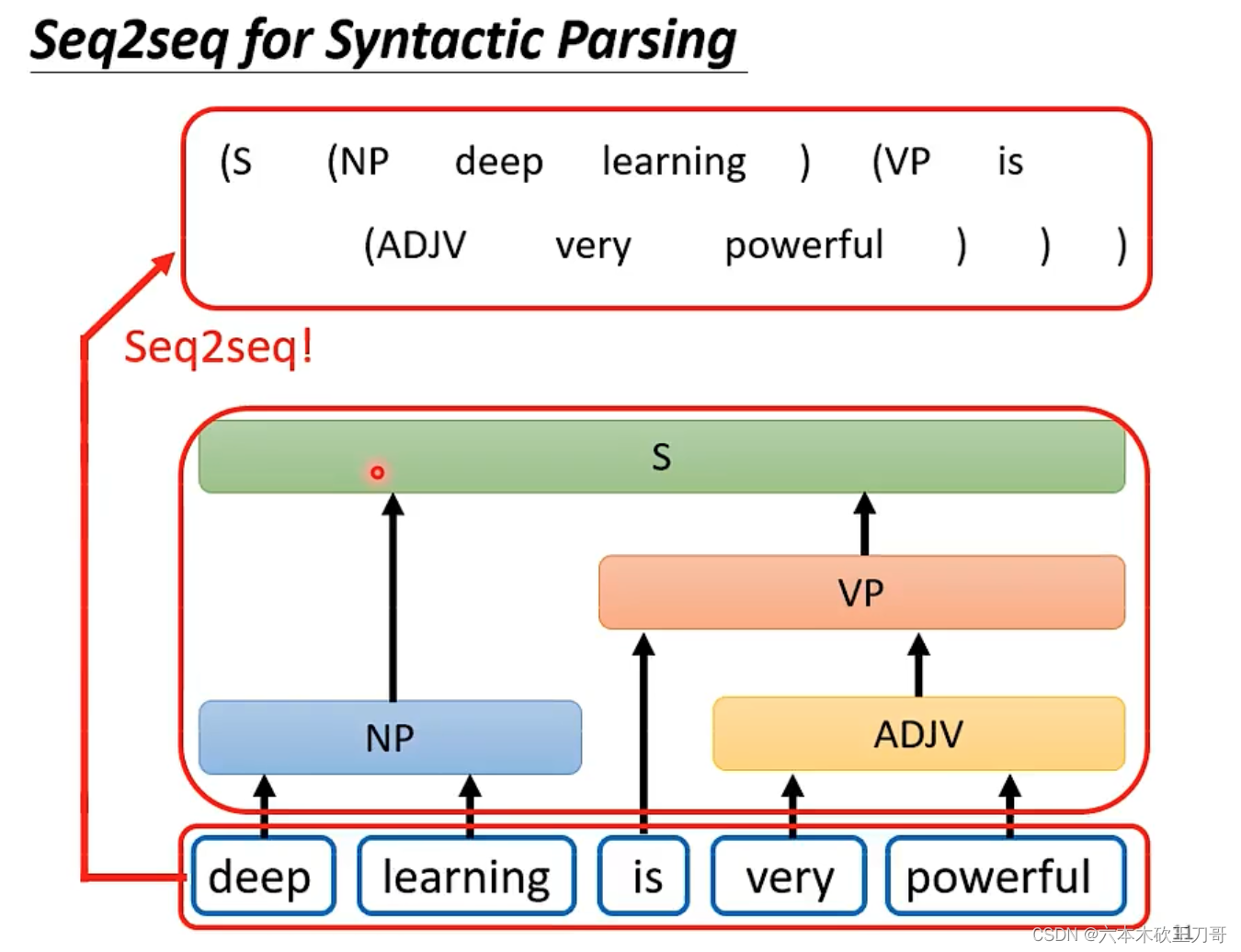
对于一些看似无法用seq2seq来解决问题,其实也是可以硬用seq来转换,例如文法解析,虽然输出是一个树状结构,但是可以把树状结构简化成一个由括号构成的向量集合。
多标签分类也可以用seq2seq来做。
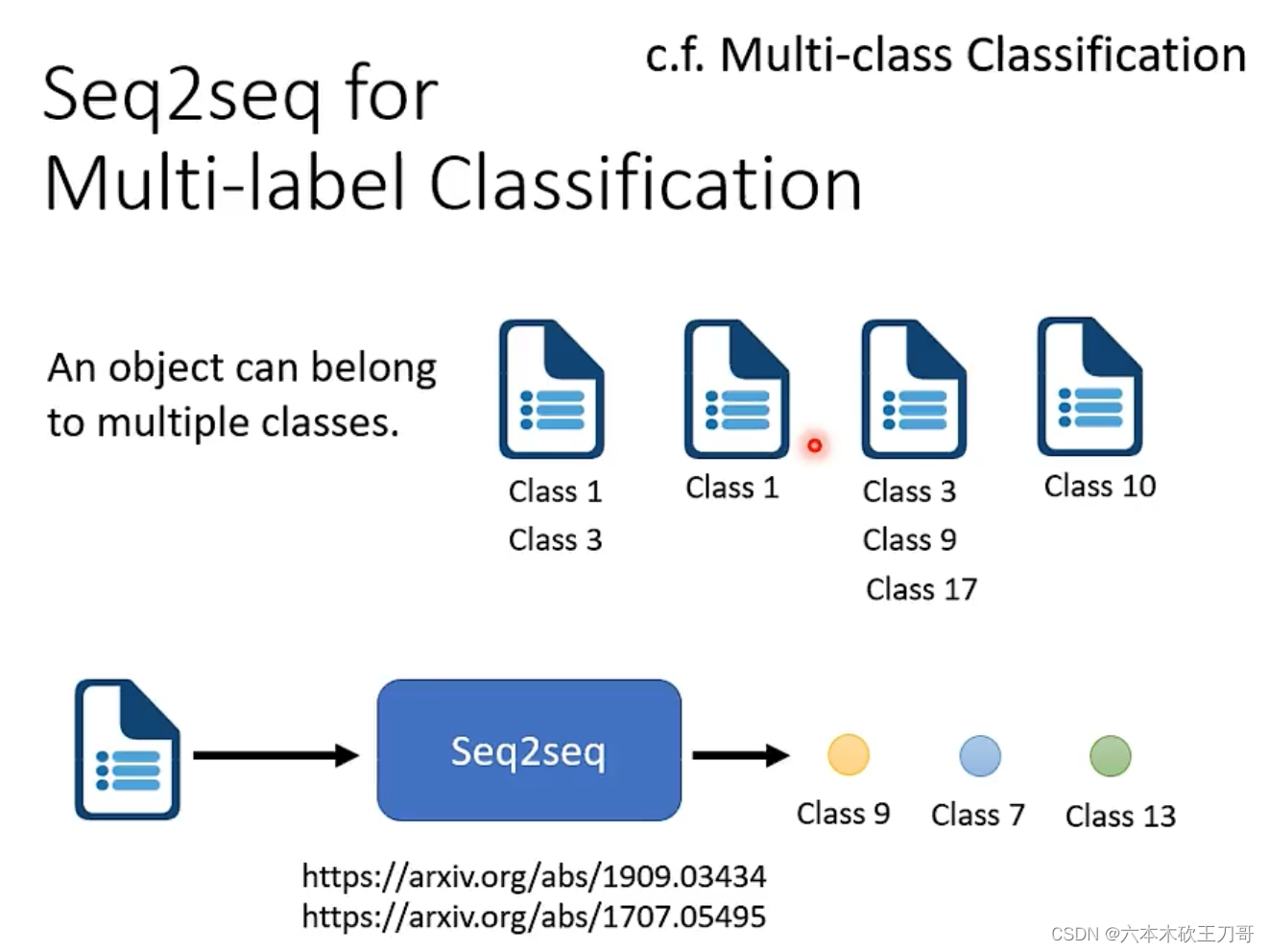
5.2 如何实现seq2seq
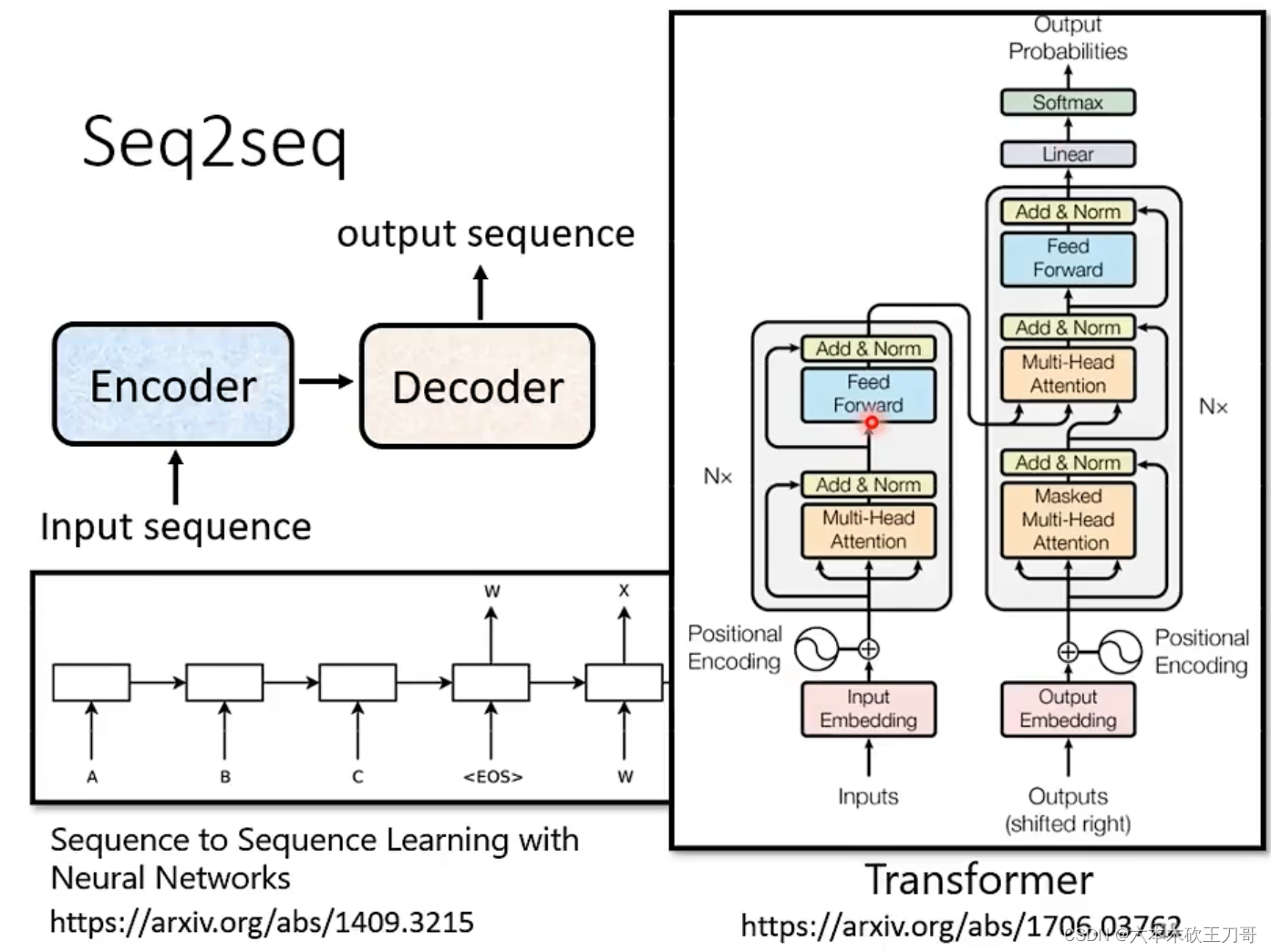
5.2.1 Encoder
第一部分是Encoder,它主要的作用是输入一排向量,输出一排向量。
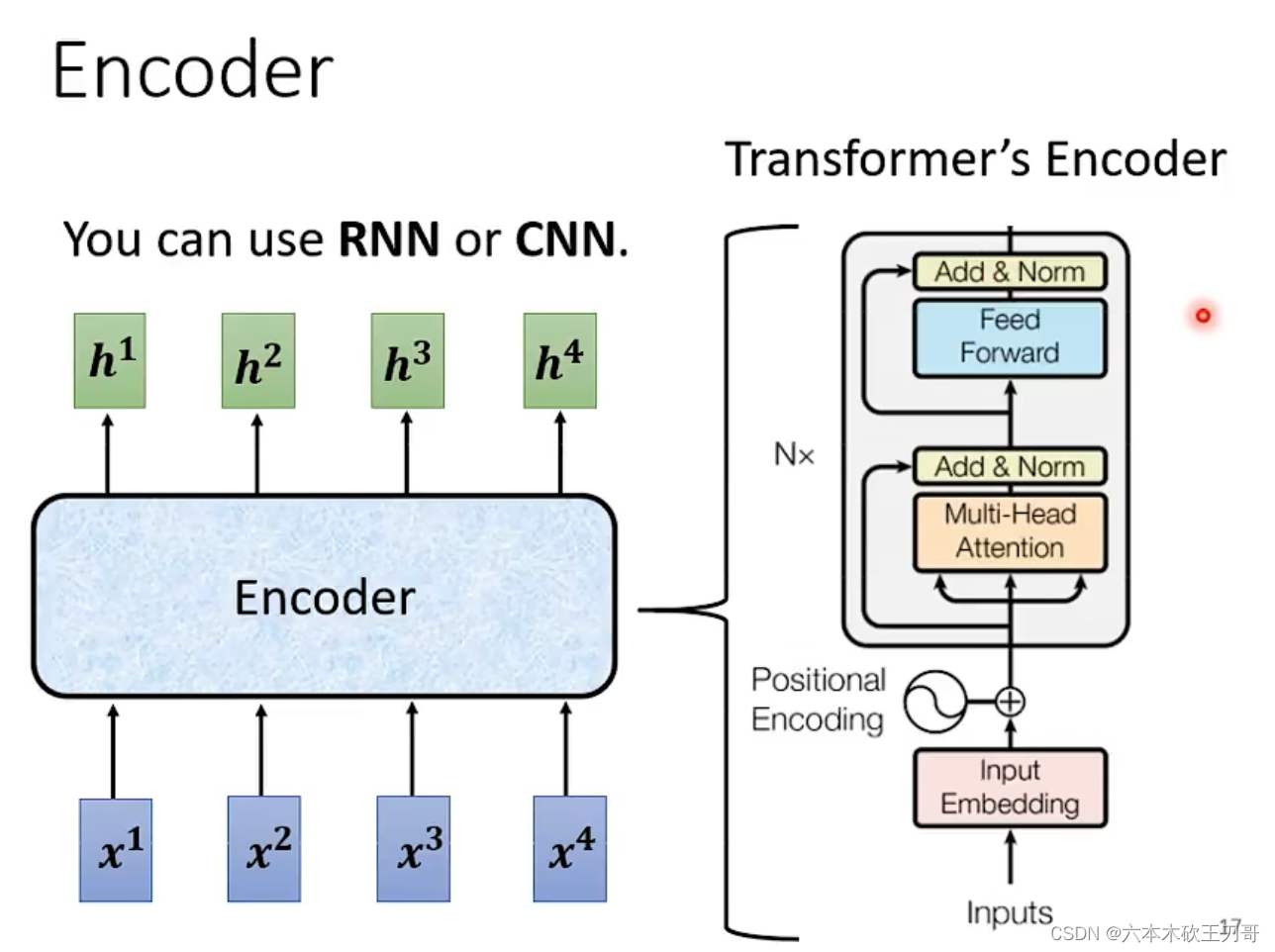
其中每个Block处理一排向量,Block在Transformer中的具体实现如右图所示。
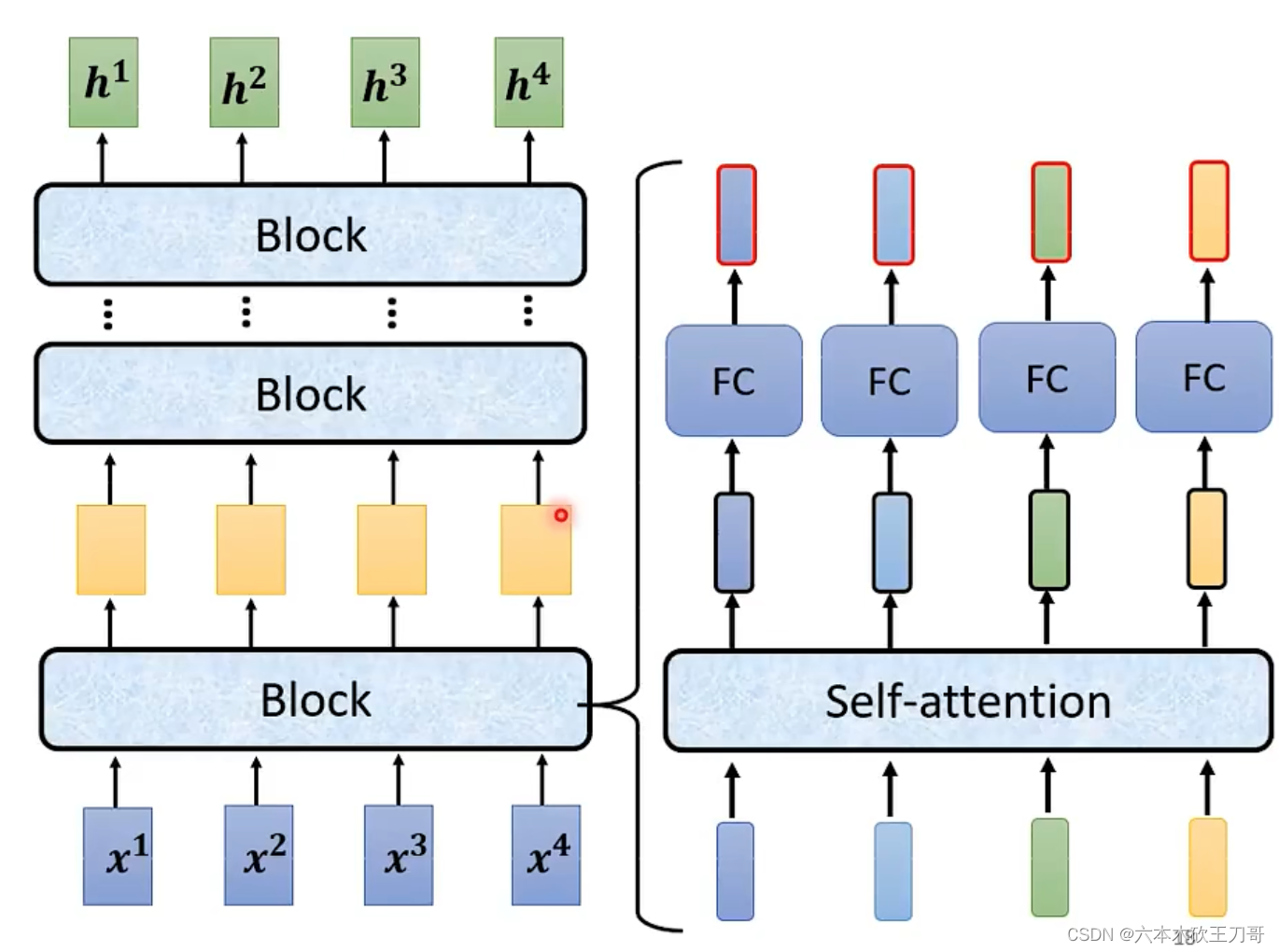
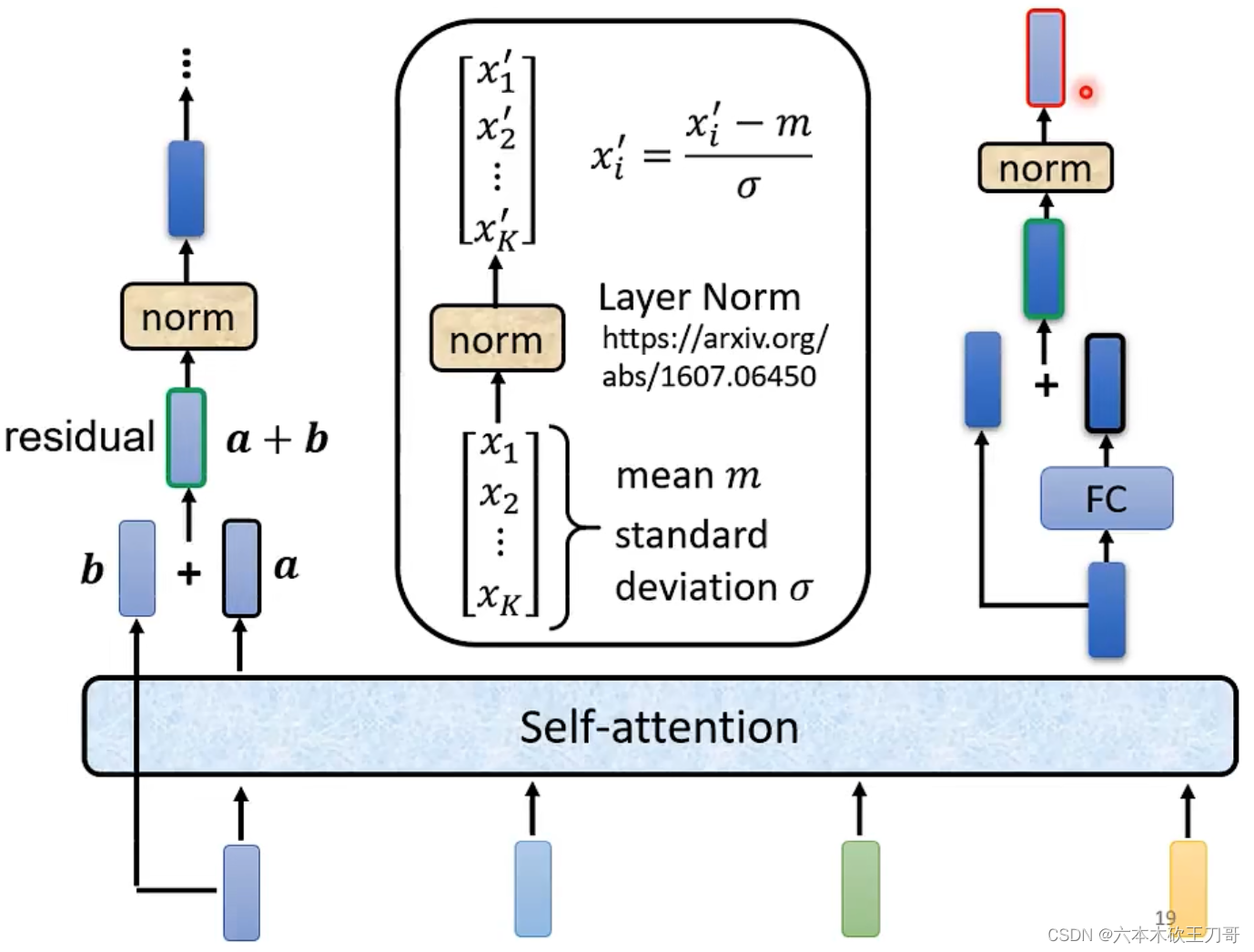
这里的实现稍有不同,每次一个向量输出一个新的向量的时候,需要加上原来的向量,这个叫做residual,然后对这个结果向量做一次norm,这个norm和别的norm不一样,叫做layer norm,需要求出方差和标准差,然后计算向量每个维度中新的值(图像计算有点bug,左边应该是
)。在做完这一次norm之后,还要穿入FC层再做一次residual和norm得到最终的结果。
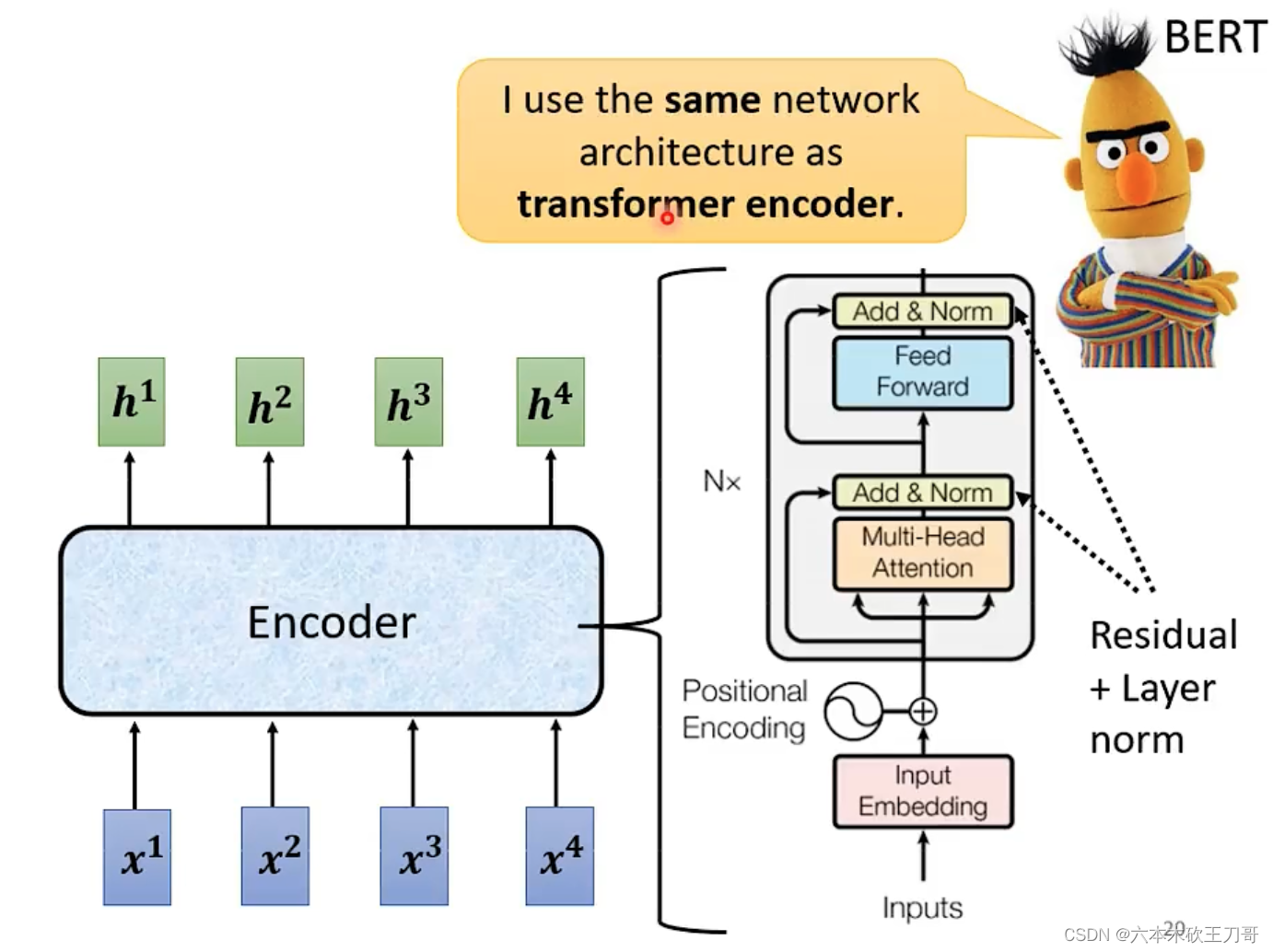
下面的encoder中,multi-head代表了self-attention,Add & Norm代表了做Residual和Layer norm,之后的Feed Forward就是一个全连接层,然后再做一次Add & Norm。这一层也是BERT中的encoder。
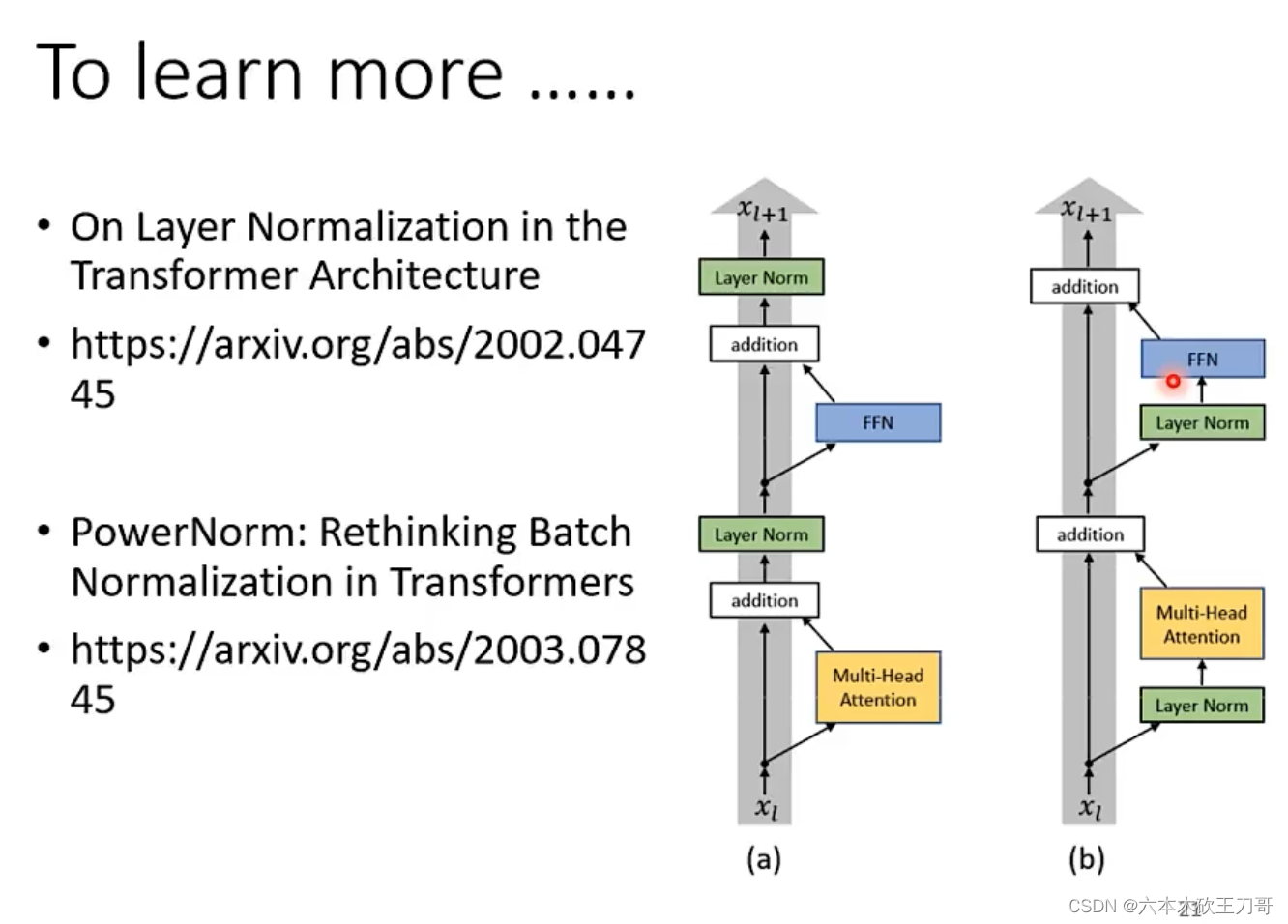
相比依然还有疑问,也就是为什么要使用这样的结构,别的结构不行吗?别的结构当然可以,原始的结构并不一定是最优的,b图是另一篇论文在提出的新结构。另外为什么要使用Layer Norm而不是Batch Norm,下面这篇论文说明了原因并且提出了PowerNorm,感兴趣可以去阅读。
5.2.2 Decoder
第二部分是Decoder,主要有两种类型,分别是Autoregressive和Non Autoregressive
首先Decoder接收Encoder输出的一排向量,然后Decoder接受一个Begin信号(可以在输入文字或语音信号里多加一个符号),吐出一个输出,例如想要输出中文,就可以通过softmax获得一个概率最高(或者分数最高)的中文然后输出。
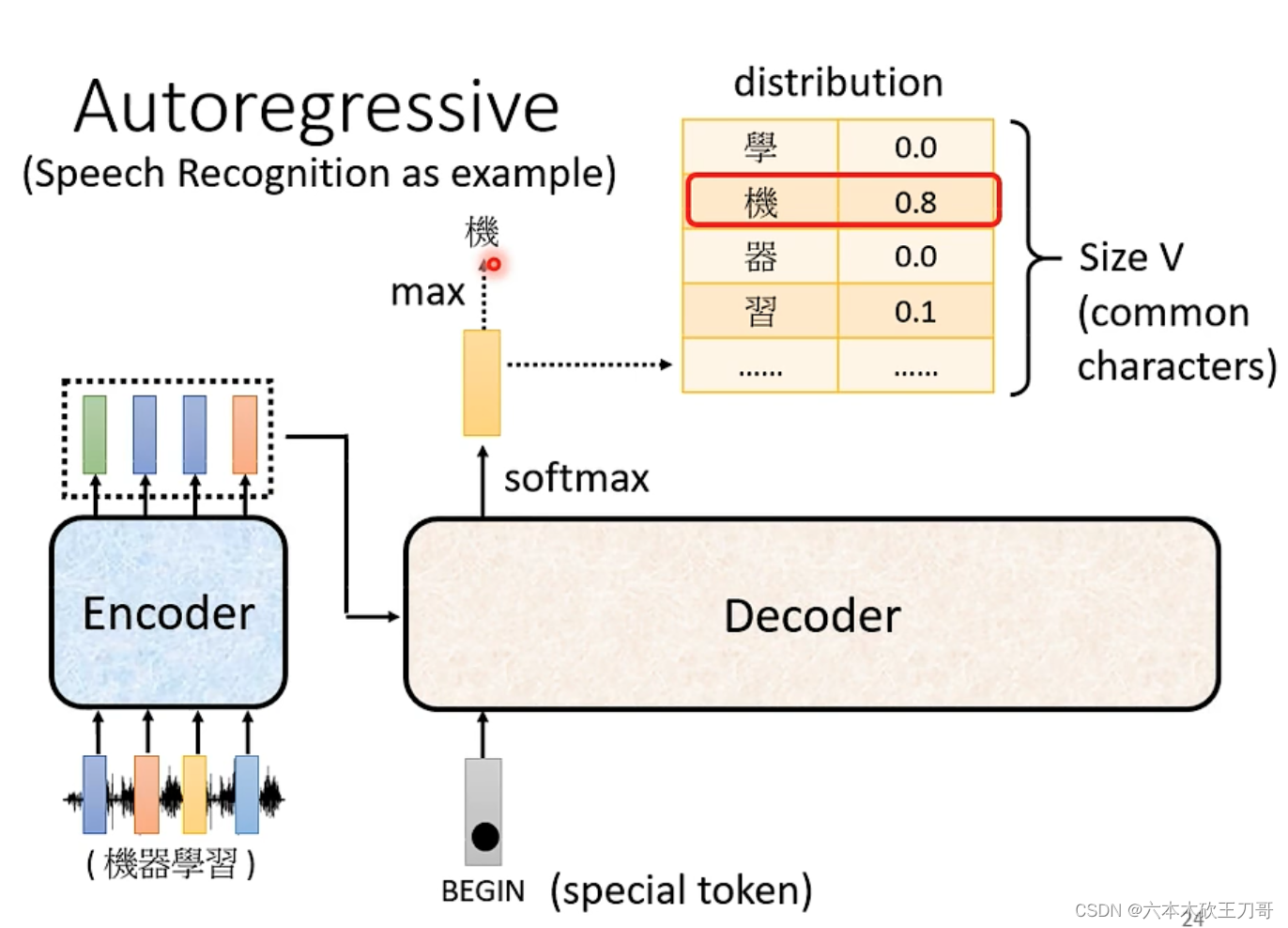
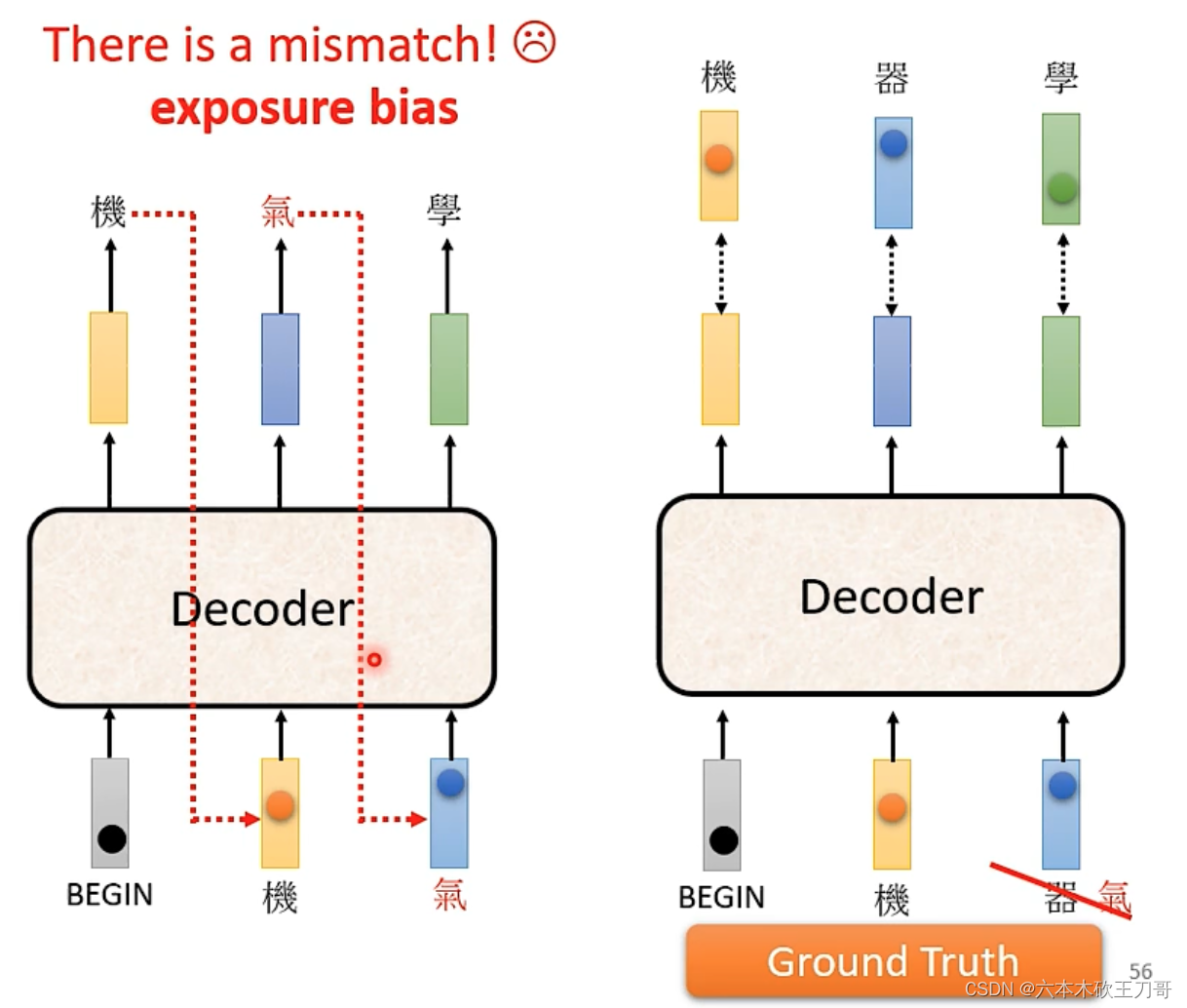
当输出下一个文字的时候,需要接收上一个输出作为输入,然后一步一步输出全部文字,但是也有可能某个位置出现错误的输出,这导致了后续可能都出错,这个问题后面有待解决。
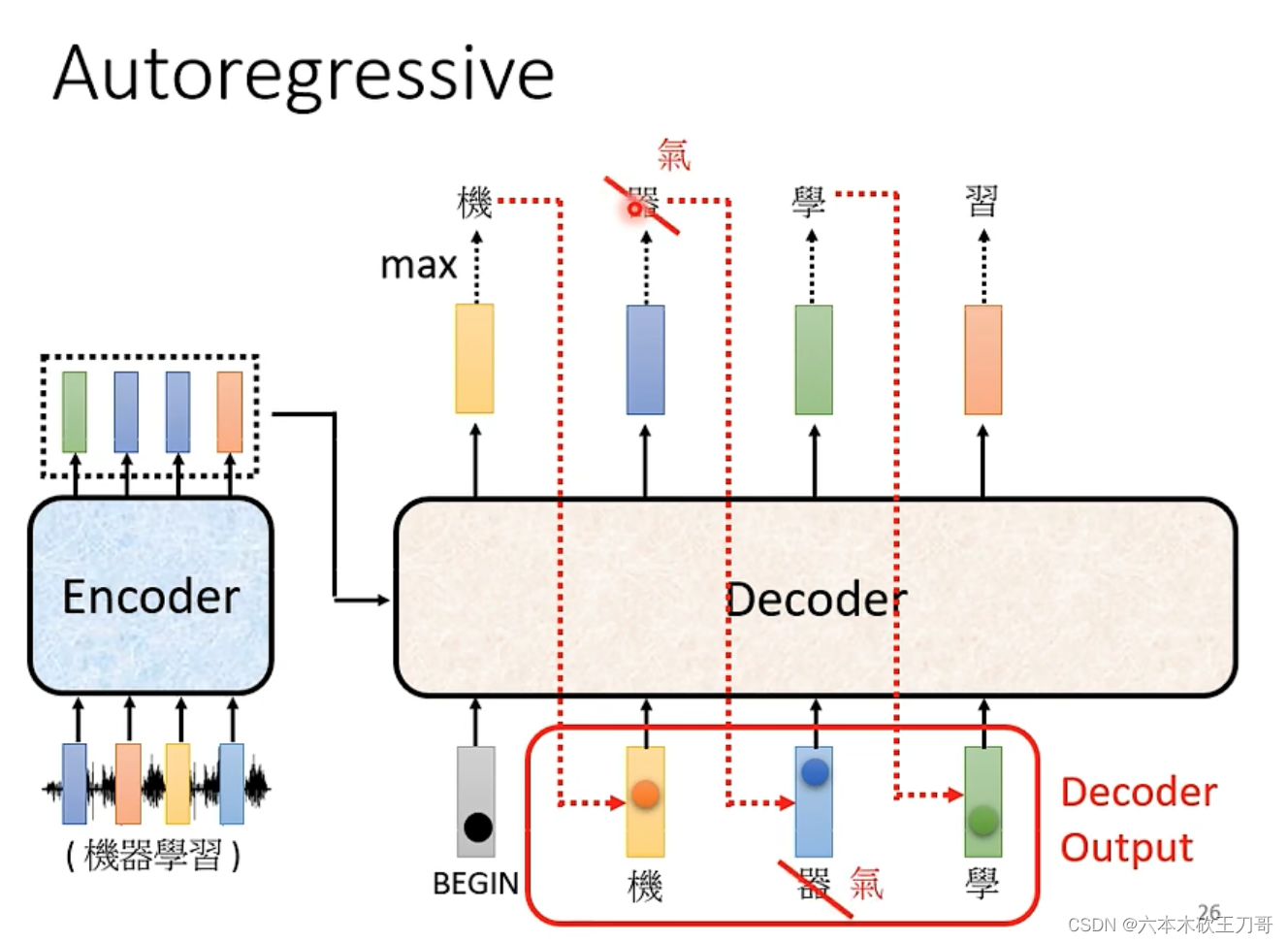
在Decoder中,Self-attention变成了Masked,这里每次输出b向量的时候只与前面的a向量有关系,例如输出b2的时候,只用到了a1和a2向量。
具体来说,例如计算b2,只用到了v1和v2向量。

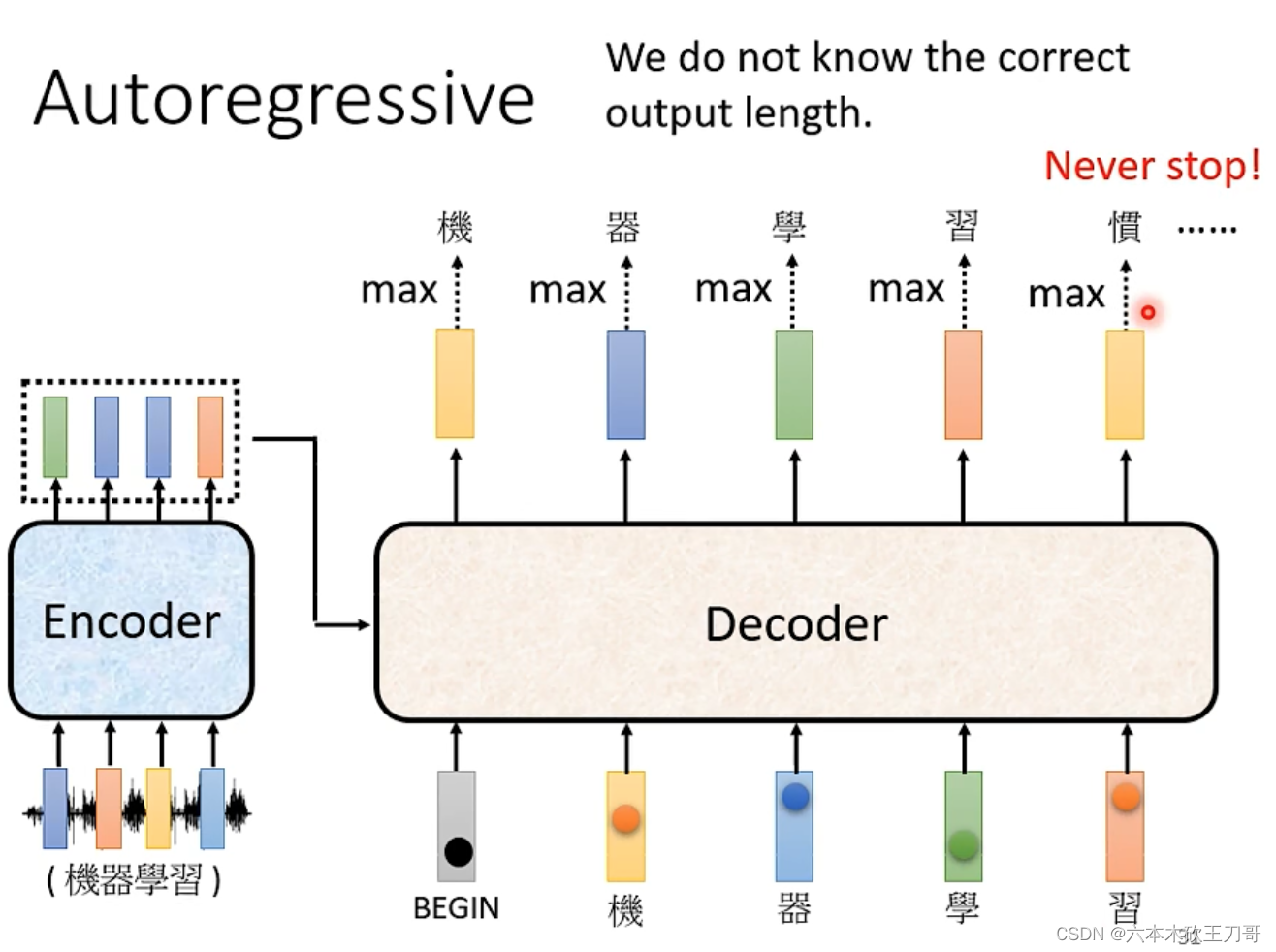
另外一个问题就是,Decoder必须自己决定输出,我们没有办法知道输出的长度,输入和输出长度关系是非常复杂的,我们希望机器能够自己学到如何输出。如果不知道输出长度的话,可能就会一直输出下去。
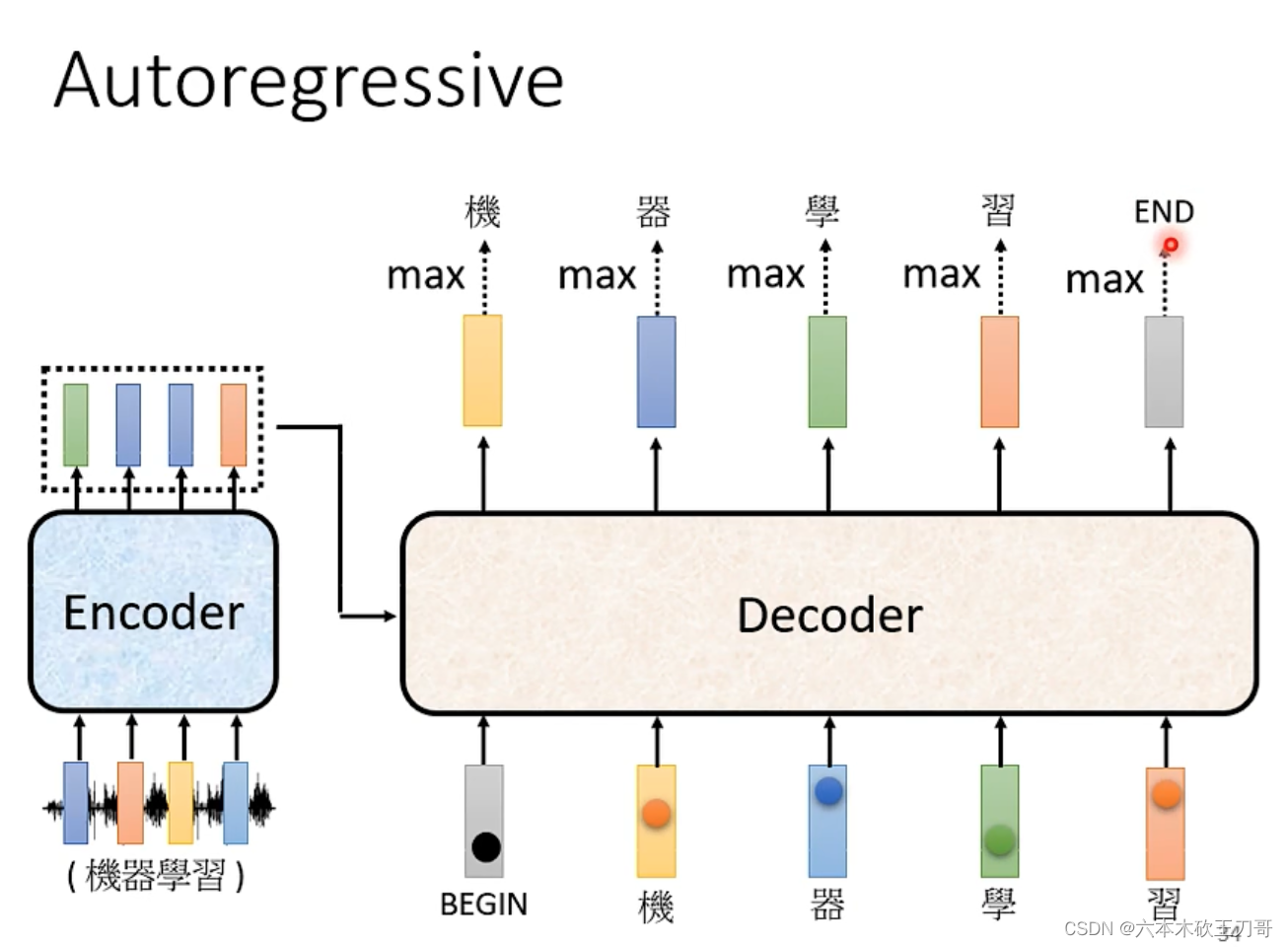
所以要让输出停下来,我们需要准备一个特殊的符号END。当输出的时候END分数或者几率达到最大的时候,那么这个输出就会停止。
另外一种是NAT,NAT控制输出的方式有控制一个输出长度的Predictor输出,根据这个值来决定输出长度,还有一张方式是直接输出一个很长的序列,根据序列中END的位置来截断输出。

接下来解释Decoder中间的部分,这里接受Encoder的输出,所以叫做Cross attention。
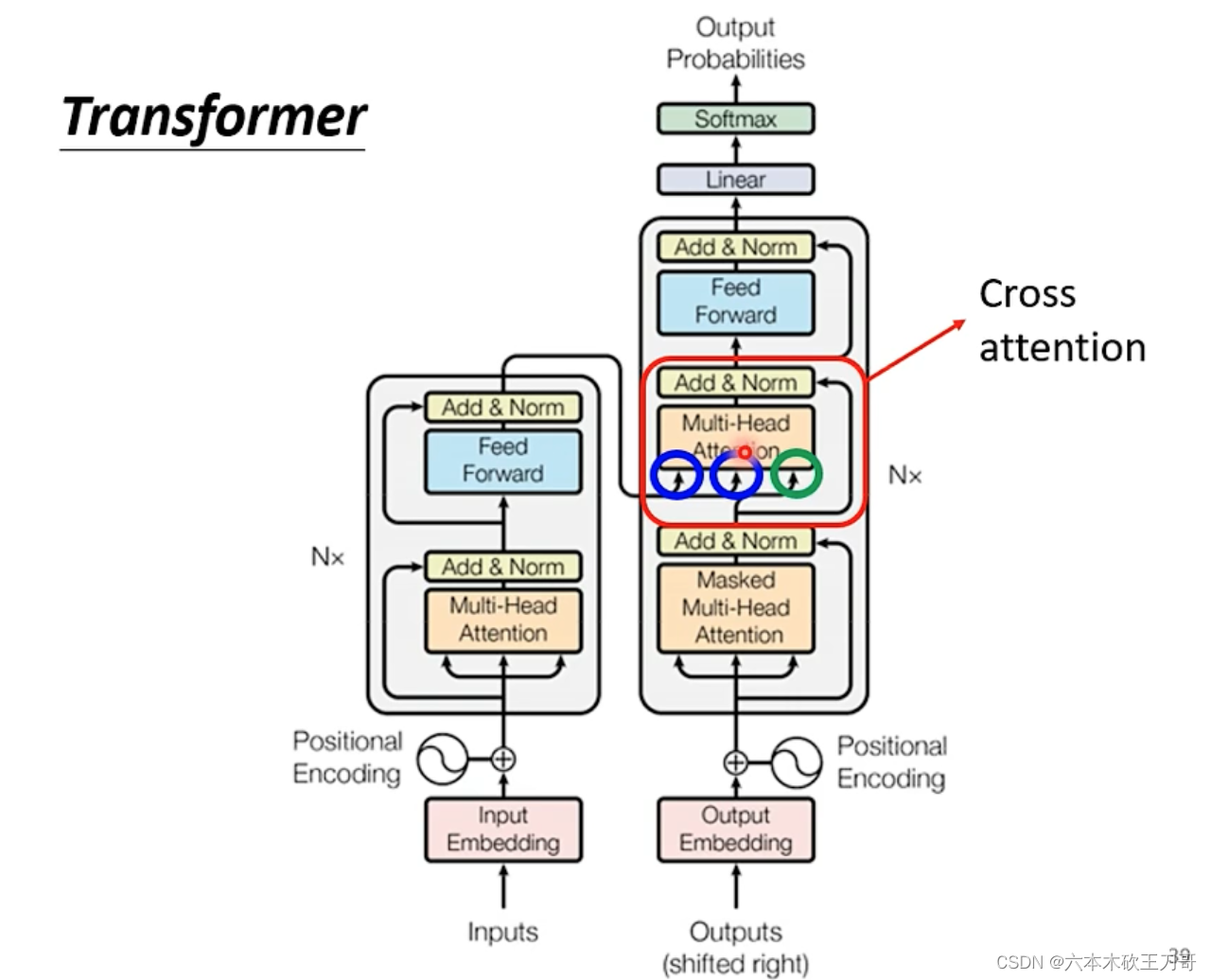
具体来说,Decoder的Masked层输出向量,然后这个向量和Encoder的k向量相乘得到,
再与v向量相乘并相加得到最终的v,这个v就可以输入到FC中,这个步骤就是k来自Decoder,q和v来自Encoder
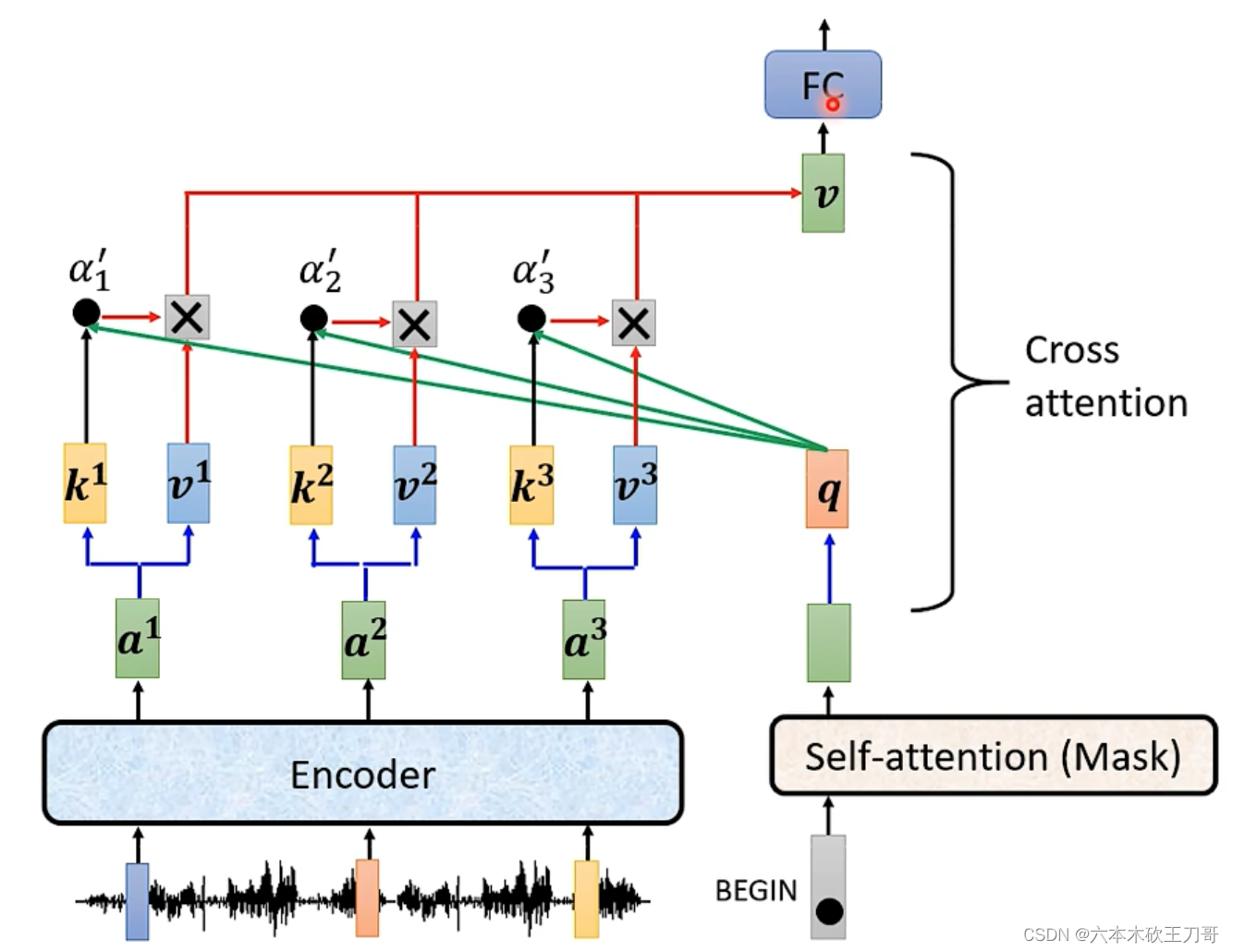
接下来,得到第一个输出之后,然后Decoder继续输出第二个值,第二个值继续和Encoder做运算,得到下一个v向量输入到FC层。
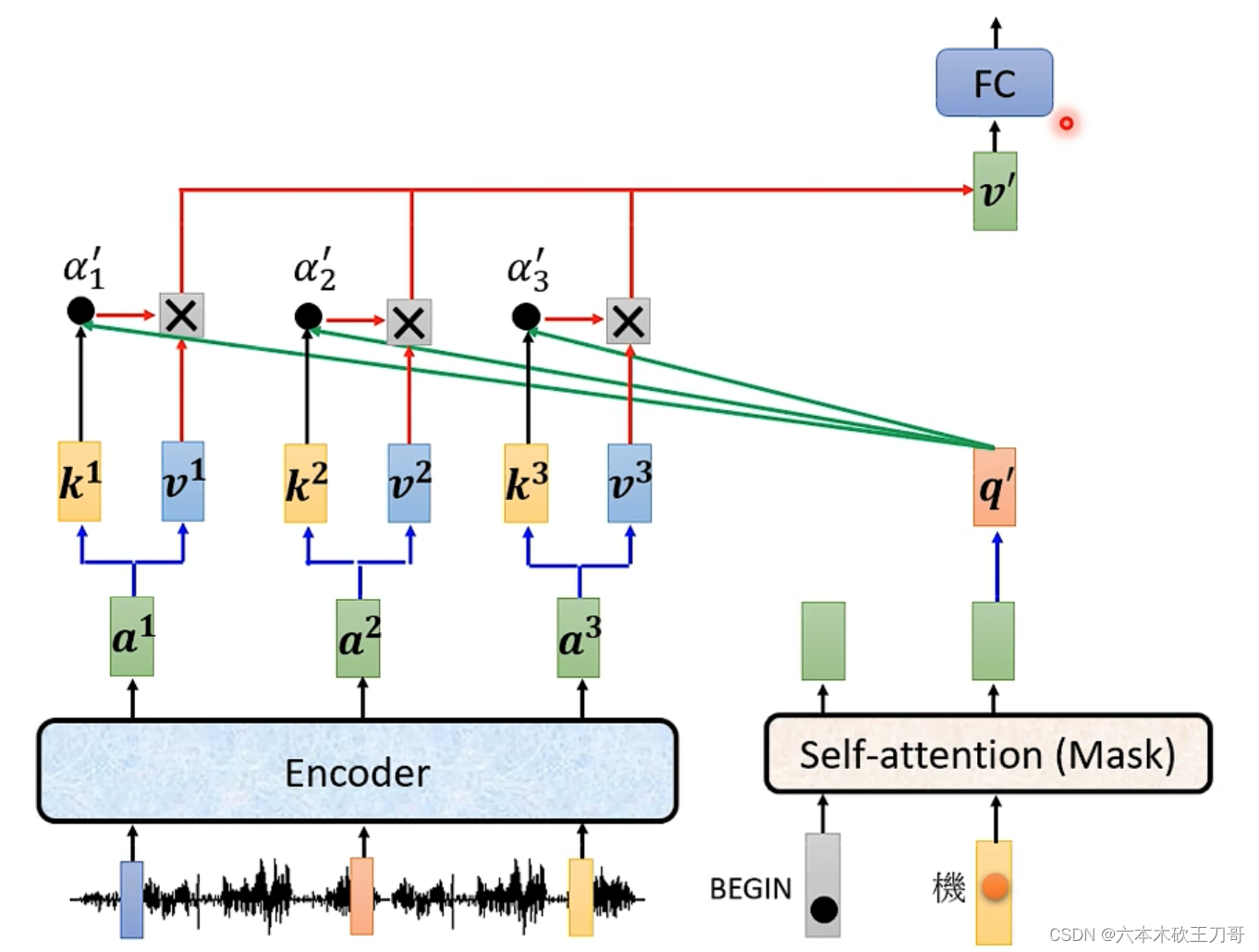
每一层有多个Decoder或者Encoder,原始文章是最后一层Encoder输出到Decoder,但是实际上并没有规定,可以尝试多种组合。
5.3 training
我们继续以语音识别为例。首先输入是一段语音信号,我们需要机器输出“机器学习”的输出,当机器开始输出的时候,得到一串不同概率分布的文字,我们希望这串概率分布中分数最大的可以与我们的标签label输出的one hot越接近越好,所以我们可以去计算Ground truth和Distribution之间的cross entropy,这个交叉熵的值越小越好,这个和分类很像,每次产生一个中文字输出的时候,实际上就是做了一次分类问题,例如如果有1000个字,那么就是1000个类别。
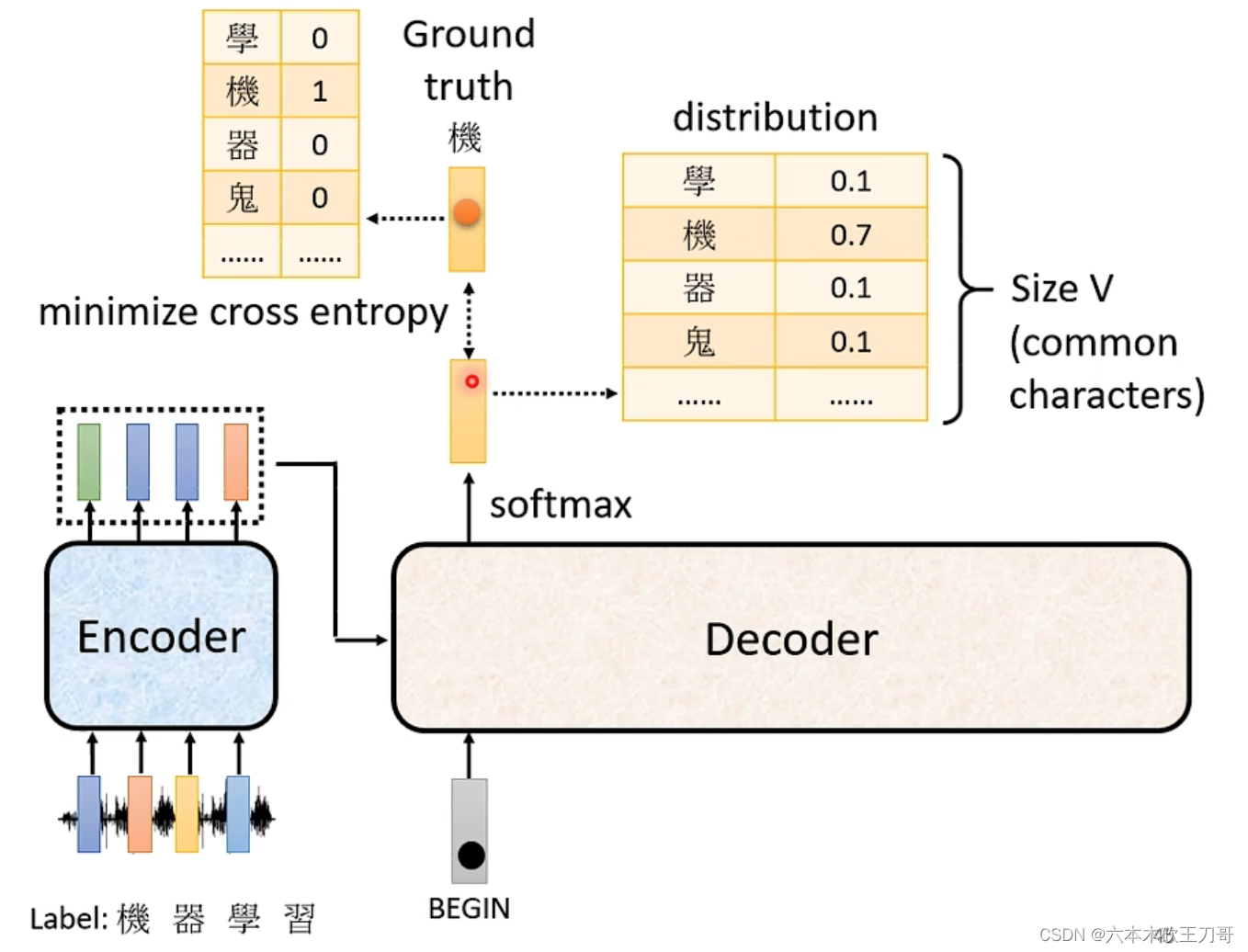
当得到全部输出,我们对每个输出都计算了交叉熵,对于这些分类问题,我们希望它们得到的总和是最小的。当输出最后一个值时,我们希望得到的输出与END之间的交叉熵值最小。已知正确输出,希望Decoder的输出与正确值越接近越好。
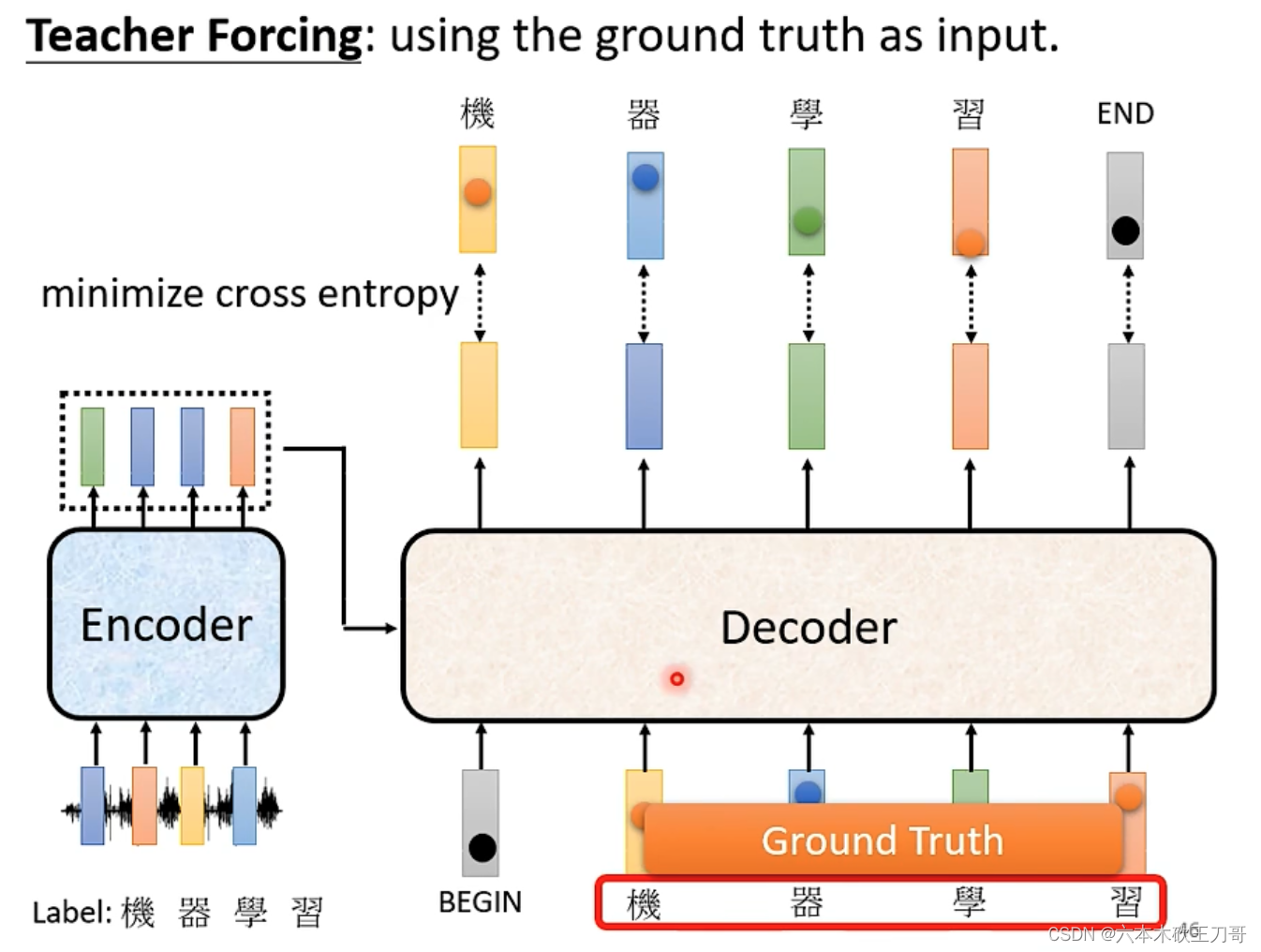
5.4 训练seq2seq的tips
之前我们希望Decoder自己产生输出,但是在很多任务中,也许不需要自己输出,而是可以从输入中复制内容,例如聊天机器人,输入一个在训练资料里没有出现的词汇,就可以直接复制出来而不是需要学习或者从头创造。

第二个例子是生成摘要,从一篇输入文章中生成对应的摘要。但是这样的训练任务需要很多的数据集。在做摘要的时候,很多内容都是从原文中复制改写过来的,复制是一个很关键的人物。这样的技术叫做Copy Mechanism。
最后,如果遇到错误的情况怎么办?可以给模型一些错误的例子,这样可以帮助模型更好的学习。















 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









