







布尔过滤
import numpy as np
import pandas as pd
data = pd.Series(np.random.randn(1000))
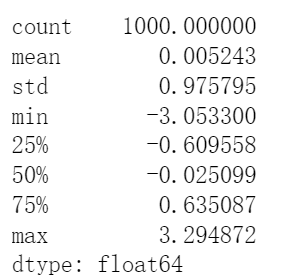
data.describe()
找出大于0的,全为NAN的删除
data[data>0].dropna(how = 'all')
data[np.abs(data) > 3].dropna(how = 'all')

为了便于分析,连续数据常常被离散化
data = pd.DataFrame(np.random.randint(1,50,(20,2)),columns = ['k1','k2'])
data.head(6)

欲了解k1数据的分布情况
bins = [0,10,20,30,40,50] #给数据分区间
cats = pd.cut(data.k1,bins) # 可以使用 right = False 控制左右括号的开闭
cats#给出数据所在区间

cats.value_counts() #计数每一个范围的元素个数,由个数从高到低排列

pd.cut(data.k1,bins, right=False)

data = np.random.randn(1000)
cats = pd.cut(data, 4)#将数据在整个数据范围内进行均分成4个部分
cats

cats.value_counts()

cats = pd.qcut(data, 4)#将数据在整个数据范围内进行个数均分,使每个区间有相同的个数的元素
cats

cats.value_counts()#注意,区间
















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









