









之前我们有写过人脸检测,今天我们要用opencv进行人脸识别,它的作用是识别不同的人脸。今天将用三种方式实现人脸识别(准确说是用opencv的三种函数实现),无论那一种,都是先创建对应的算法模型实例,然后图片训练学习特点,最后推理预测
(一)LBPHFace人脸识别
原理我们就不讲了,直接写如何调用。
在OpenCV中,可以用函数cv2.face.LBPHFaceRecognizer_create ( ) 生成LBPH识别器实例模型,然后应用cv2.face_FaceRecognizer.train ( )函数完成训练,最后用cv2.face_FaceRecognizer.predict ( )函数完成人脸识别。
下面分别介绍上述三个函数。
1.函数cv2.face.LBPHFaceRecognizer_create( radius, neighbors,grid_ x,grid_ y, threshold)
其中全部的参数都是可选的,含义如下:
| 参数 | 解释 |
|---|---|
| radius | 半径值,默认值为1 |
| neighbors | 邻域点的个数,默认采用8邻域,根据需要可以计算更多的邻域点 |
| grid_x | 将LBP特征图像划分为一个个单元格时,每个单元格在水平方向上的像素个数。该参数值默认为8 ,即将LBP特征图像在行方向.上以8个像素为单位分组 |
| grid_y | 将LBP特征图像划分为一个个单元格时,每个单元格在垂直方向上的像素个数。该参数值默认为8 ,即将LBP特征图像在列方向.上以8个像素为单位分组 |
| threshold | 在预测时所使用的阈值。如果大于该阈值,就认为没有识别到任何目标对象(你也可以不设置) |
2.函数cv2.face_FaceRecognizer.train ( )对每个参考图像计算LBPH ,得到一个向量。每个人脸都是整个向量集中的一个点。
cv2.face_FaceRecognizer.train ( src,labels )
| 参数 | 解释 |
|---|---|
| src | 训练图像,用来学习的人脸图像 |
| labels | 标签,人脸图像所对应的标签 |
3.函数cv2.face_FaceRecognizer.predict( ) 对一个待测人脸图像进行判断,寻找与当前图像距离最近的人脸图像。与哪个人脸图像最近,就将当前待测图像标注为其对应的标签。当然,如果待测图像与所有人脸图像的距离都大于函数cv2.face.LBPHFaceRecognizer_create ( )中参数threshold所指定的距离值,则认为没有找到对应的结果,即无法识别当前人脸。该函数有连个返回值
label,confidence=cv2.face_ FaceRecognizer.predict ( src )
| 参数 | 解释 |
|---|---|
| src | 需要识别的人脸图像 |
| 返回值 | 解释 |
|---|---|
| label | 返回的识别结果标签 |
| confidence | 返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0表示完全匹配。通常情况下,认为小于50的值是可以接受的,如果该值大于85则认为差别较大 |
上代码:
import cv2
import numpy as np
import matplotlib.pyplot as plt
images=[] #创建一个容器,空数组
#以灰度图读入
images.append(cv2.imread("a1.jpg",0))
images.append(cv2.imread("a2.jpg",0))
images.append(cv2.imread("a3.jpg",0))
images.append(cv2.imread("b1.jpg",0))
images.append(cv2.imread("b2.jpg",0))
images.append(cv2.imread("b3.jpg",0))
images.append(cv2.imread("c1.jpg",0))
images.append(cv2.imread("c2.jpg",0))
images.append(cv2.imread("c3.jpg",0))
labels=[1,1,1,2,2,2,3,3,3]
#1~3(彭于晏),4~6(胡歌),7~9(我),分别标注为1,2,3.
titles1=['a1','a2','a3','b1','b2','b3','c1','c2','c3']#用于训练的图片
titles2=['a4','b4','c4']#用于测试的图片
detector = cv2.face.LBPHFaceRecognizer_create(threshold=65)#创建实例模型,#创建实例模型,这里设置threshold为65,你也可以不设置
detector.train(images, np.array(labels)) #开始训练
target=cv2.imread("a4.jpg",cv2.IMREAD_GRAYSCALE)#读取待识别的图片,这里是彭于晏第四张图片,lable应该为1
label,confidence= detector.predict(target)#进行识别
print("label=",label)
print("confidence=",confidence)
#显示所有的训练图片
##################################################
origin=[]
origin.append(cv2.imread("a1.jpg",1))
origin.append(cv2.imread("a2.jpg",1))
origin.append(cv2.imread("a3.jpg",1))
origin.append(cv2.imread("b1.jpg",1))
origin.append(cv2.imread("b2.jpg",1))
origin.append(cv2.imread("b3.jpg",1))
origin.append(cv2.imread("c1.jpg",1))
origin.append(cv2.imread("c2.jpg",1))
origin.append(cv2.imread("c3.jpg",1))
test=[]
test.append(cv2.imread("a4.jpg",1))
test.append(cv2.imread("b4.jpg",1))
test.append(cv2.imread("c4.jpg",1))
for i in range(9):#显示训练的图片
plt.subplot(3,3,i+1),plt.imshow(origin[i])
plt.title(titles1[i],fontsize=11)
plt.xticks([]),plt.yticks([])
plt.show()
#敲击q键退出
for i in range(3):#显示测试的图片
plt.subplot(1,3,i+1),plt.imshow(test[i])
plt.title(titles2[i],fontsize=11)
plt.xticks([]),plt.yticks([])
plt.show()
#敲击q键退出
###################################################

注意:检测的图片应该不在训练图片之内,否则检测它也么的啥意义了。小伙伴如果细心的话,也可发现,检测的a4.jpg并不在训练图片之列。而且小伙伴可以发现这里识别的并不准确,因为a4.jpg的lable应该为1,而打印的却为2
(二)EigenFace人脸识别
OpenCV通过函数cv2.face.EigenFaceRecognizer_create ( )生成特征脸识别器实例模型,然后应用cv2.face_ FaceRecognizer.train ( )函数完成训练,最后用cv2.face_FaceRecognizer.predict ( )函数完成人脸识别。
1.函数cv2.face. EigenFaceRecognizer.create ( num_components,threshold )
| 参数 | 解释 |
|---|---|
| num_components | 在PCA中要保留的分量个数。当然,该参数值通常要根据输入数据来具体确定,并没有一定之规。-般来说, 85个分量就足够了()(可以不设置) |
| threshold | 进行人脸识别时所采用的阈值(可以不设置) |
2.函数cv2.face_FaceRecognizer.train ( )对每个参考图像进行EigenFaces计算,得到一个向量。每个人脸都是整个向量集中的一个点。
cv2.face_FaceRecognizer.train ( src,labels )
| 参数 | 解释 |
|---|---|
| src | 训练图像,用来学习的人脸图像 |
| labels | 人脸图像所对应的标签 |
3.函数cv2.face_ FaceRecognizer.predict ( )在对一个待测人脸图像进行判断时,会寻找与当前图像距离最近的人脸图像。与哪个人脸图像最接近,就将待测图像识别为其对应的标签。
label,confidence=cv2.face_FaceRecognizer.predict ( src )
| 参数 | 解释 |
|---|---|
| src | 需要识别的人脸图像 |
| 返回值 | 解释 |
|---|---|
| label | 返回的识别结果标签 |
| confidence | 返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0表示完全匹配。该参数值通常在0到20000之间,只要低于5000 ,都被认为是相当可靠的识别结果。注意,这个范围与LBPH的置信度评分值的范围是不同的 |
上代码:
import cv2
import numpy as np
import matplotlib.pyplot as plt
images=[] #创建一个容器,空数组
train=[]
#以灰度图读入,并且resize为统一的大小
images.append(cv2.resize(cv2.imread("a1.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("a2.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("a3.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("b1.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("b2.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("b3.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("c1.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("c2.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("c3.jpg",0),(301,301)))
labels=[1,1,1,2,2,2,3,3,3]
#1~3(彭于晏),4~6(胡歌),7~9(我),分别标注为1,2,3.
titles1=['a1','a2','a3','b1','b2','b3','c1','c2','c3']#用于训练的图片
titles2=['a4','b4','c4']#用于测试的图片
detector = cv2.face.EigenFaceRecognizer_create()#创建实例模型,这里设置threshold为65,你也可以不设置
detector.train(images, np.array(labels)) #开始训练
target=cv2.resize(cv2.imread("b4.jpg",0),(301,301))#读取待识别的图片,这里测试的图片需要和训练的图片保持一致的大小,这里是胡歌第四张图片,lable应该为2
label,confidence= detector.predict(target)#进行识别
print("label=",label)
print("confidence=",confidence)
#显示所有的训练图片
##################################################
origin=[]
origin.append(cv2.imread("a1.jpg",1))
origin.append(cv2.imread("a2.jpg",1))
origin.append(cv2.imread("a3.jpg",1))
origin.append(cv2.imread("b1.jpg",1))
origin.append(cv2.imread("b2.jpg",1))
origin.append(cv2.imread("b3.jpg",1))
origin.append(cv2.imread("c1.jpg",1))
origin.append(cv2.imread("c2.jpg",1))
origin.append(cv2.imread("c3.jpg",1))
test=[]
test.append(cv2.imread("a4.jpg",1))
test.append(cv2.imread("b4.jpg",1))
test.append(cv2.imread("c4.jpg",1))
for i in range(9):#显示训练的图片
plt.subplot(3,3,i+1),plt.imshow(origin[i])
plt.title(titles1[i],fontsize=11)
plt.xticks([]),plt.yticks([])
plt.show()
#敲击q键退出
for i in range(3):#显示测试的图片
plt.subplot(1,3,i+1),plt.imshow(test[i])
plt.title(titles2[i],fontsize=11)
plt.xticks([]),plt.yticks([])
plt.show()
#敲击q键退出
###################################################
下面训练与测试的图片就不展示了,来看看打印结果
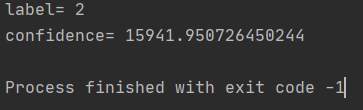
很明显,这里的置信度偏大,但还是正确识别了lable,EigenFace人脸识别的特点就是要求所有的训练的图片和待测试的图片的大小都统一。
(三)FisherFace人脸识别
在OpenCV中,通过函数cv2.face .FisherFaceRecognizer_ create ( )生成Fisherfaces识别器实例模型,然后应用cv2.face_ FaceRecognizer.train ( )函数完成训练,用cv2.face_FaceRecognizer.predict ( )函数完成人脸识别。
1.函数cv2.face.FisherFaceRecognizer_create( num_ components,threshold )
| 参数 | 解释 |
|---|---|
| num_components | 使用Fisherfaces 准则进行线性判别分析时保留的成分数量。可以采用默认值"0”, 让函数自动设置合适的成分数量 |
| threshold | 进行识别时所用的阈值。如果最近的距离比设定的阈值threshold还要大,函数会返回"-1” |
2.函数cv2.face_ FaceRecognizer.train ( ) 对每个参考图像进行Fisherfaces计算,得到一个向量。每个人脸都是整个向量集中的一个点。
cv2.face_ FaceRecognizer.train ( src,labels )
| 参数 | 解释 |
|---|---|
| src | 训练图像,即用来学习的人脸图像 |
| labels | 人脸图像所对应的标签 |
3.函数cv2.face_ FaceRecognizer.predict ( )在对一个待测人脸图像进行判断时,寻找与其距离最近的人脸图像。与哪个人脸图像最接近,就将待测图像识别为其对应的标签。
label,confidence=cv2.face_FaceRecognizer.predict ( srC )
| 参数 | 解释 |
|---|---|
| src | 需要识别的人脸图像 |
| 返回值 | 解释 |
|---|---|
| labels | 返回的识别结果的标签 |
| confidence | 置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0表示完全匹配。该值通常在0到20000之间,若低于5000 ,就认为是相当可靠的识别结果。需要注意,该评分值的范围与EigenFaces方法的评分值范围一致,与LBPH方法的评分值范围不一致 |
上代码:
import cv2
import numpy as np
import matplotlib.pyplot as plt
images=[] #创建一个容器,空数组
train=[]
#以灰度图读入,并且resize为统一的大小
images.append(cv2.resize(cv2.imread("a1.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("a2.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("a3.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("b1.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("b2.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("b3.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("c1.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("c2.jpg",0),(301,301)))
images.append(cv2.resize(cv2.imread("c3.jpg",0),(301,301)))
labels=[1,1,1,2,2,2,3,3,3]
#1~3(彭于晏),4~6(胡歌),7~9(我),分别标注为1,2,3.
titles1=['a1','a2','a3','b1','b2','b3','c1','c2','c3']#用于训练的图片
titles2=['a4','b4','c4']#用于测试的图片
detector = cv2.face.FisherFaceRecognizer_create()#创建实例模型,这里设置threshold为65,你也可以不设置
detector.train(images, np.array(labels)) #开始训练
target=cv2.resize(cv2.imread("c4.jpg",0),(301,301))#读取待识别的图片,这里测试的图片需要和训练的图片保持一致的大小,这里是胡歌第四张图片,lable应该为3
label,confidence= detector.predict(target)#进行识别
print("label=",label)
print("confidence=",confidence)
#显示所有的训练图片
##################################################
origin=[]
origin.append(cv2.imread("a1.jpg",1))
origin.append(cv2.imread("a2.jpg",1))
origin.append(cv2.imread("a3.jpg",1))
origin.append(cv2.imread("b1.jpg",1))
origin.append(cv2.imread("b2.jpg",1))
origin.append(cv2.imread("b3.jpg",1))
origin.append(cv2.imread("c1.jpg",1))
origin.append(cv2.imread("c2.jpg",1))
origin.append(cv2.imread("c3.jpg",1))
test=[]
test.append(cv2.imread("a4.jpg",1))
test.append(cv2.imread("b4.jpg",1))
test.append(cv2.imread("c4.jpg",1))
for i in range(9):#显示训练的图片
plt.subplot(3,3,i+1),plt.imshow(origin[i])
plt.title(titles1[i],fontsize=11)
plt.xticks([]),plt.yticks([])
plt.show()
#敲击q键退出
for i in range(3):#显示测试的图片
plt.subplot(1,3,i+1),plt.imshow(test[i])
plt.title(titles2[i],fontsize=11)
plt.xticks([]),plt.yticks([])
plt.show()
#敲击q键退出
###################################################

这里代码与上面的EigenFace人脸识别差别不大,还有就是这里也要求所有的测试图片与训练图片大小一致。
(四)结语
学习opencv有很多的方法,我的建议是你可以加一些群,可以充分利用B站,CSDN,和百度。
在我的博客中,我不会讲解opencv的算法实现(当然我也不太会),我只会讲解一些函数的调用,不理解就多改一些参数,多尝试尝试,慢慢你就理解来。相信你总有一天可以说opencv不过“Ctrl+C,Crtl+V”
如果有什么错误的地方,还请大家批评指正,最后,希望小伙伴们都能有所收获。















 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









