







pytorch模型搭建
torch.nn还是torch.nn.functional?
原文
torch.nn 中大多数 layer 在 torch.nn.funtional 中都有一个与之对应的函数。二者的区别在于:
torch.nn 中实现 layer 的都是一个特殊的类, 会自动提取可学习的参数。
nn.functional 中的函数,更像是纯函数,由 def function( ) 定义,只是进行简单的数学运算而已。即 functional 中的函数是一个确定的不变的运算公式,输入数据产生输出就ok。而深度学习中会有很多权重是在不断更新的,不可能每进行一次 forward 就用新的权重重新来定义一遍函数来进行计算,所以说就会采用类的方式,以确保能在参数发生变化时仍能使用我们之前定好的运算步骤。
当所需的函数不含有需要学习的参数且在train和test阶段运行方法一致时,无论用torch.nn.X 还是torch.nn.functional.X 都可以,并且既可以现在 init中声明,也可以直接在forward中使用:(不具备可学习参数的层,将它们用函数代替,这样可以不用放在构造函数中进行初始化。)
如: torch.nn.functional.relu, torch.nn.ReLU
train和test阶段运行方法不一致时,尽量用 torch.nn,避免了手动控制的麻烦
如 batch normalization 和 dropout
有可学习参数时,使用torch.nn
如卷积层和全连接层
maxpool2d
ceil_model参数:
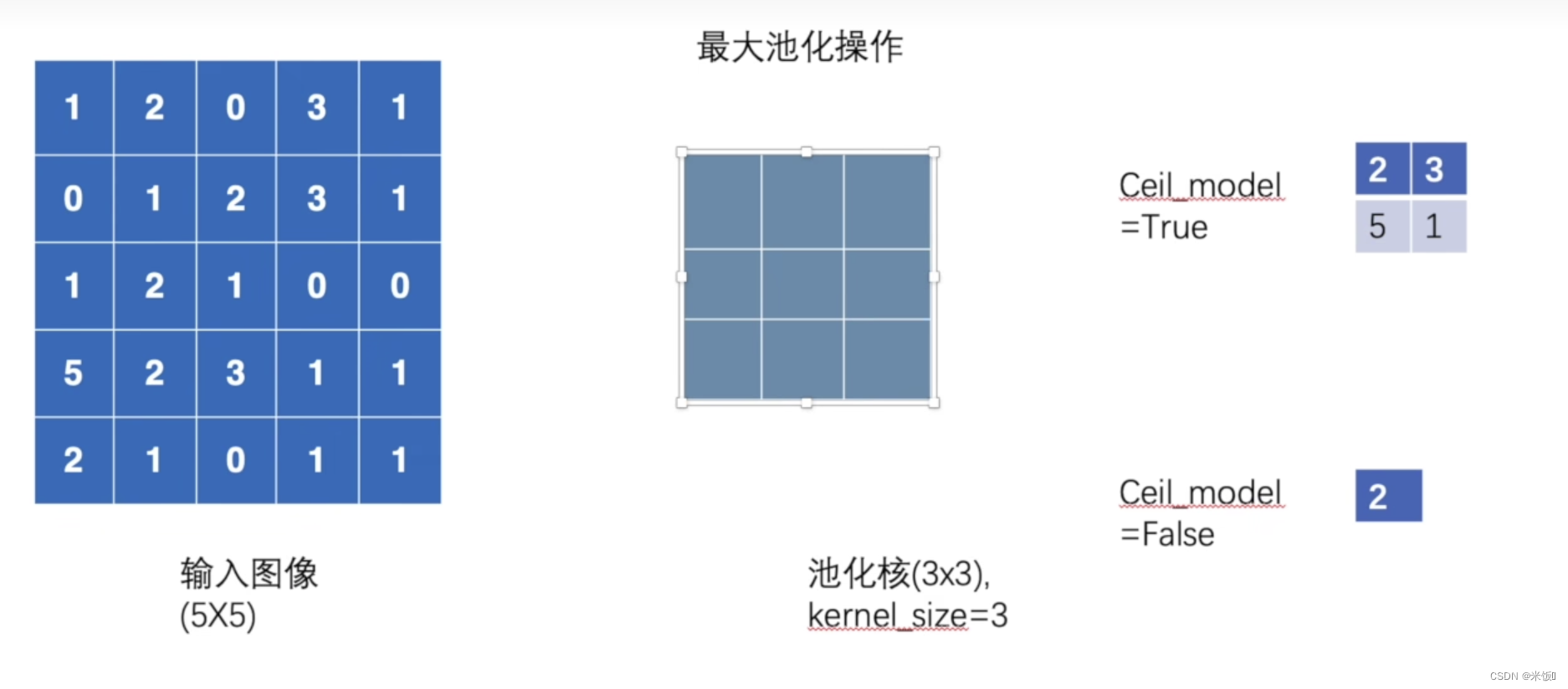
小例子:包括conv2d,maxpool, sigmoid激活
线性层linear略
以下分别对这三个组件构建了对应的类,并且将组件对图片的处理结果用tensorboard展示
具体用到什么组件的详细信息可以去官网查询:pytorch.org
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
# tensorboard --logdir=p6
class CONV(nn.Module):
def __init__(self):
super(CONV, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
class POOL(nn.Module):
def __init__(self):
super(POOL, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, x):
output = self.maxpool(x)
return output
class ACT(nn.Module):
def __init__(self):
super(ACT, self).__init__()
self.sigmoid = nn.Sigmoid()
# self.relu = nn.Relu()
def forward(self, x):
output = self.sigmoid(x)
return output
model1 = CONV()
model2 = POOL()
model3 = ACT()
writer = SummaryWriter('./p6')
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images('input', imgs, step)
output1 = model1(imgs)
# 由于add_images只能接收3通道,这里就把它展平了一下
# 与add_image区分,add_image只能接收单一图片,但add_images可以传入batch_size个图片,参数形状为[B,C,H,W]
output1 = torch.reshape(output1, (-1,3,30,30))
writer.add_images('conv', output1, step)
output2 = model2(imgs)
writer.add_images('maxpool', output2, step)
output3 = model3(imgs)
writer.add_images('sigmoid', output3, step)
step += 1
writer.close()
一个小demo
按照下面的图搭建网络,验证网络结构是否正确,并用tensorboard查看网络结构
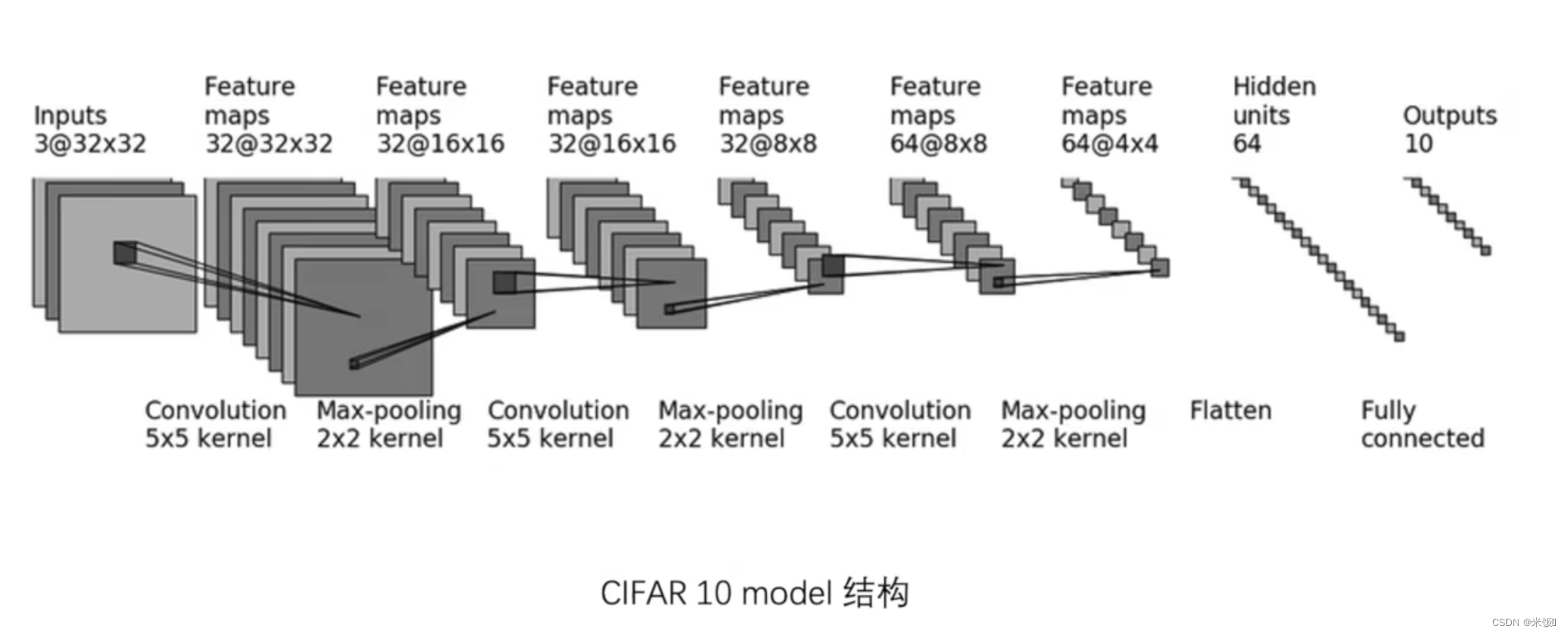
使用的库为:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
没有用sequential的情况
class cifar10(nn.Module):
def __init__(self):
super(cifar10, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
# 在不知道某层参数个数的情况下,可以将forward只写到那一层,然后看输出的shape,比如下面线性层的输入
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
# 测试时,可以生成一个batch的数据形式,传入模型调整错误
img = torch.rand((64, 3, 32, 32))
model = cifar10()
output = model(img)
print(output.shape)
# output shape:[64,10]
有sequential
可以发现在forward中的代码会减少很多,sequential的功能可以类比transforms.Compose
这里用tensorboard的add_graph,可以实现模型结构可视化
对于参数错误:例如线性层参数计算错误,写成2048,无论用不用sequential,报错位置都不在当前文件,因此debug的时候需要逐层去看,当然用sequential并不影响,而且更简洁。
class cifar10_seq(nn.Module):
def __init__(self):
super(cifar10_seq, self).__init__()
self.seq = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
x = self.seq(x)
return x
# tensorboard --logdir=p7
writer = SummaryWriter('./p7')
model1 = cifar10_seq()
writer.add_graph(model1, img)
writer.close()
训练过程
定义损失函数,实例化模型,定义优化器(包括对什么参数优化,学习率多少,优化器的其他参数等)
每个batch先计算损失并清零梯度 -> 求梯度 -> 根据梯度更新权重
dataset = torchvision.datasets.CIFAR10('./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
# 训练阶段:
# 定义损失函数,实例化模型,定义优化器(包括对什么参数优化,学习率多少,优化器的其他参数等)
loss = nn.CrossEntropyLoss()
model2 = cifar10_seq()
optim = torch.optim.SGD(model2.parameters(), lr=0.01)
# 迭代周期
for epoch in range(3):
# 统计损失
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = model2(imgs)
result_loss = loss(outputs, targets)
# 在梯度更新之前需要清零上一轮的梯度
optim.zero_grad()
# 得到梯度
result_loss.backward()
# 根据梯度更新权重
optim.step()
# 所有batch的loss累加
running_loss += result_loss
print('epoch %d, running loss %f' % (epoch, running_loss))















 6382
6382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









