






组成部分
Text-to-SQL解析器和SQL执行器。
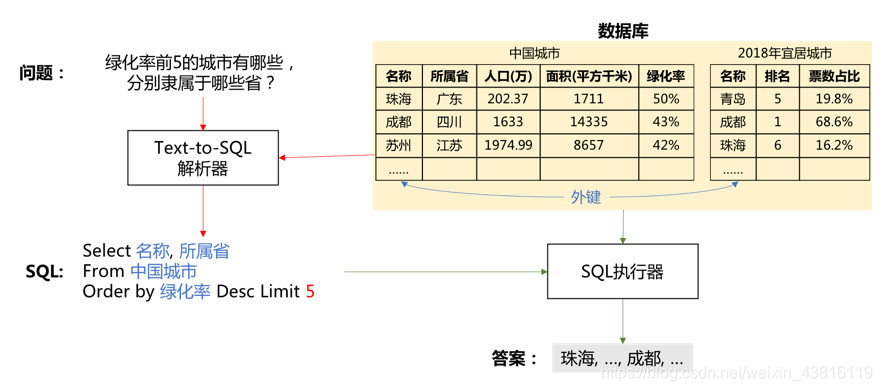
目前能做到的程度
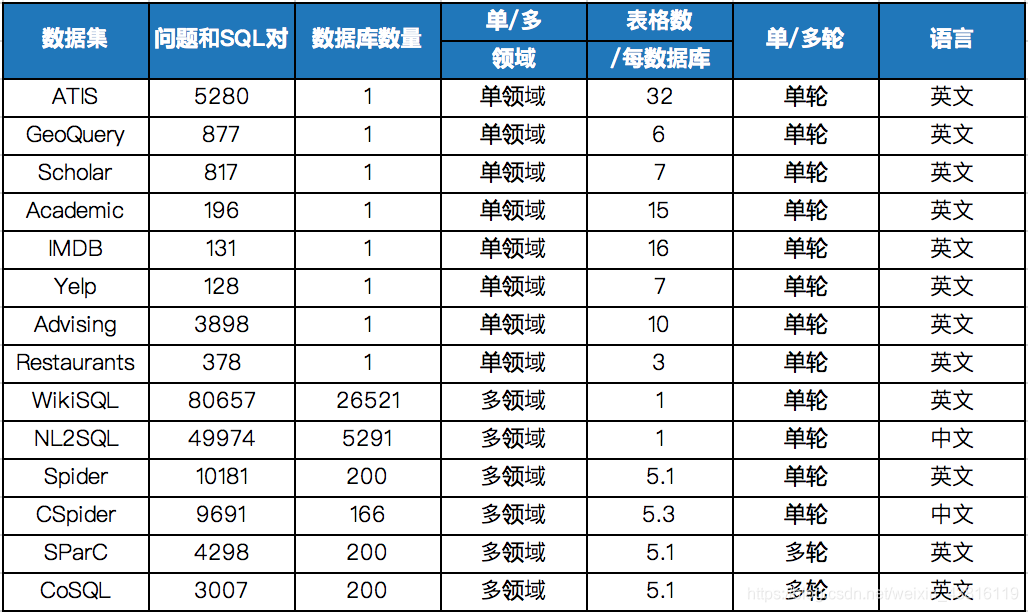
SQL查询语句是一个符合语法、有逻辑结构的序列,其构成来自三部分:数据库、问题、SQL关键词。
在当前深度学习研究背景下,Text-to-SQL任务可被看作是一个类似于神经机器翻译的序列到序列的生成任务,主要采用Seq2Seq模型框架。基线Seq2Seq模型加入注意力、拷贝等机制后,在单领域数据集上可以达到80%以上的准确率,但在多领域数据集上效果很差,准确率均低于25%。
从编码和解码两个方面进行原因分析。
在编码阶段,问题与数据库之间需要形成很好的对齐或映射关系,即问题中涉及了哪些表格中的哪些元素(包含列名和表格元素值);同时,问题与SQL语法也需要进行映射,即问题中词语触发了哪些关键词操作(如Group、Order、Select、Where等)、聚合操作(如Min、Max、Count等)等;最后,问题表达的逻辑结构需要表示并反馈到生成的SQL查询语句上,逻辑结构包括嵌套、多子句等。
在解码阶段,SQL语言是一种有逻辑结构的语言,需要保证其语法合理性和可执行性。普通的Seq2Seq框架并不具备建模这些信息的能力。
当前基于Seq2Seq框架,主要有以下几种改进。
1)基于Pointer Network的改进
首先,SQL组成来自三部分:数据库中元素(如表名、列名、表格元素值)、问题中词汇、 SQL关键字。其次,当前公开的多领域数据集为了验证模型数据库无关,在划分训练集和测试集时要求数据库无交叉,这种划分方式导致测试集数据库中很大比例的元素属于未登录词。传统的Seq2Seq模型是解决不好这类问题的。
Pointer Network很好地解决了这一问题,其输出所用到的词表是随输入而变化的。具体做法是利用注意力机制,直接从输入序列中选取单词作为输出。在Text-to-SQL任务中,将问题中词汇、SQL关键词、对应数据库的所有元素作为输入序列,利用Pointer Network从输入序列中拷贝单词作为最终生成SQL的组成元素。
由于Pointer Network可以较好的满足具体数据库无关这一要求,在多领域数据集上的模型大多使用该网络,如Seq2SQL[1]、STAMP[8]、Coarse2Fine[9] 、IRNet[16]等模型。
2)基于Sequence-to-set的改进
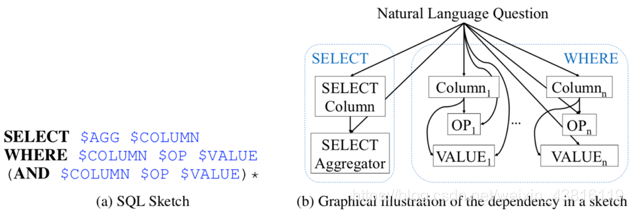
在简单问题对应的数据集合上,其SQL查询语句形式简单(仅包含Select和Where关键词),为了解决Seq2Seq模型中顺序错误带来的影响(如“条件1 And 条件2”,预测为“条件2 And 条件1”,属于顺序错误,但对应的SQL是正确的),SQLNet[10]提出了Sequence-to-set模型,基于所有的列预测其属于哪个关键词(即属于Select还是Where,在SQLNet模型中仅预测是否属于Where),针对SQL 中每一个关键词选择概率最高的前K个列。
该模式适用于SQL形式简单的数据集,在WikiSQL和NL2SQL这两个数据集合上使用较多,且衍生出很多相关模型,如TypeSQL[11]、SQLova[12]、X-SQL[13]等。
3)基于TRANX(自顶向下文法生成)的改进
复杂问题对应的SQL查询语句形式也复杂,涉及到多关键词组合、嵌套、多子句等。并且,测试集合中的某些SQL查询语句形式在训练集合中没有见过,这就要求模型不仅对新数据库具有泛化能力,对新SQL查询语句形式也要有泛化能力。
针对这种情况,需要更多关注生成SQL的逻辑结构。为了保证SQL生成过程中语法合理,一些模型开始探索及使用语法树生成的方法。
TRANX[14]框架借鉴了AST[15]论文思想,根据目标语言的语法构建规约文法,基于该文法可以将生成目标表示为语法树(需要保证生成目标与语法树表示一一对应),然后实现了自顶向下的语法树生成系统,图4给出了该系统流程。
我们简单介绍一下基于该系统实现Text-to-SQL任务。
首先,根据SQL语法制定规约文法(对应图4中的ASDL Grammar),需要保证每一条SQL查询语句均可由该文法产出。
其次,设计动作集合用于转移系统(图4中的Transition System),基于该转移系统选择合理的规约文法生成语法树,该转移系统将语法树的生成转成动作序列的生成,即转成一系列文法的选择序列,文法在选择过程中保证了合理性(即孩子节点文法均在父节点允许的文法范围内);该动作序列的生成可基于Seq2Seq等框架进行。
该框架在代码生成、SQL生成等任务上都已验证过,在Text-to-SQL任务上的模型包括IRNet[16]、Global GNN[17]、RATSQL[18]等。
图4:基于TRANX的code生成
4)其他改进
在多表数据集合上,一些模型加入图网络来增强数据库的表示,如Global GNN[17]、RATSQL[18]等。在WikiSQL数据集合上,由于该数据集给出了SQL执行系统,部分模型通过加入执行指导[19]来提升SQL的可执行性和准确率。
评价方法
Text-to-SQL任务的评价方法主要包含两种:精确匹配率(Exact Match, Accqm)、执行正确率(Execution Accuracy, Accex)。
精确匹配率指,预测得到的SQL语句与标准SQL语句精确匹配成功的问题占比。为了处理由成分顺序带来的匹配错误,当前精确匹配评估将预测的SQL语句和标准SQL语句按着SQL关键词分成多个子句,每个子句中的成分表示为集合,当两个子句对应的集合相同则两个子句相同,当两个SQL所有子句相同则两个SQL精确匹配成功;

执行正确指,执行预测的SQL语句,数据库返回正确答案的问题占比。















 3453
3453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









