







 本文综述了Text-to-SQL任务,即自然语言到SQL查询的转换。任务旨在通过用户友好的自然语言查询数据库。早期方法基于规则和模板,现代方法转向了Seq2Seq框架,利用编码器捕获问题、表格和SQL关键词的关联,解码器生成SQL。编码端改进包括Table-aware、Anonymous Encoding、GNN和预训练模型,解码端有Pointer Network、强化学习和Abstract Syntax Network。尽管存在挑战,如SQL复杂性和上下文依赖,但不断发展的数据集和模型推动了该领域的进步。
本文综述了Text-to-SQL任务,即自然语言到SQL查询的转换。任务旨在通过用户友好的自然语言查询数据库。早期方法基于规则和模板,现代方法转向了Seq2Seq框架,利用编码器捕获问题、表格和SQL关键词的关联,解码器生成SQL。编码端改进包括Table-aware、Anonymous Encoding、GNN和预训练模型,解码端有Pointer Network、强化学习和Abstract Syntax Network。尽管存在挑战,如SQL复杂性和上下文依赖,但不断发展的数据集和模型推动了该领域的进步。
Text to SQL综述
一、背景
自然语言被公认为是许多领域的最佳交互方式。至今仍不存在一个通用模型能连接自然语言和任意领域。无论是否精通SQL查询语言,如能通过自然语言链接关系型数据库,将会简化大量现有工作。随着深度学习技术的兴起,开始涌现大量研究自然语言连接关系型数据库的工作。
本综述先介绍自然语言生成SQL查询这一任务的定义,然后整理了该任务已经公开发布的数据集。另外,针对现有一些最新方法和模型进行了归纳和描述。最后,介绍了该任务中使用的评估指标。
关键词
SQL查询生成、文本到SQL、深度学习、语义解析、NL2SQL、Table QA
SQL Query Generation, Text-to-SQL, Deep Learning, Semantic Parsing
二、任务介绍
SQL语言是当前使用的关系数据库的主要查询语言。自然语言到SQL的映射可视为语义解析问题(Andreas, Vlachos et al., 2013)。语义解析是长期存在且在自然语言处理(NLP)中被广泛研究的问题。因此,它引起了学术界和业界的广泛关注,特别是将自然语言转换为SQL查询。当今时代,从金融、电子商务到医疗领域,大量数据都存储在关系型数据库中。因此,使用自然语言查询数据库有许多应用场景。如自助式仪表盘和动态分析,可以通过自然语言来获取与业务最相关的信息。与将自然语言转成sql相关的任务还有代码生成和模式生成(code generation and schema generation)。这些任务可以总结为,将自然语言翻译成完整应用程序的一般任务。
如图-1所示(Sun, Tang et al., 2018),用户提出自然语言问题:“what 's the total number of songs originally performed by anna nalick?”,输入到Text to sql解析器中,解析器输出SQL语句“𝑆𝐸𝐿𝐸𝐶𝑇 𝐶𝑂𝑈𝑁𝑇 𝑆𝑜𝑛𝑔 𝑐h𝑜𝑖𝑐𝑒 𝑊𝐻𝐸𝑅𝐸 𝑂𝑟𝑖𝑔𝑖𝑛𝑎𝑙 𝑎𝑟𝑡𝑖𝑠𝑡 = 𝑎𝑛𝑛𝑎 𝑐h𝑟𝑖𝑠𝑡𝑖𝑛𝑒 𝑛𝑎𝑙𝑖𝑐𝑘”,执行模块再在数据库中执行sql,返回执行结果:1。
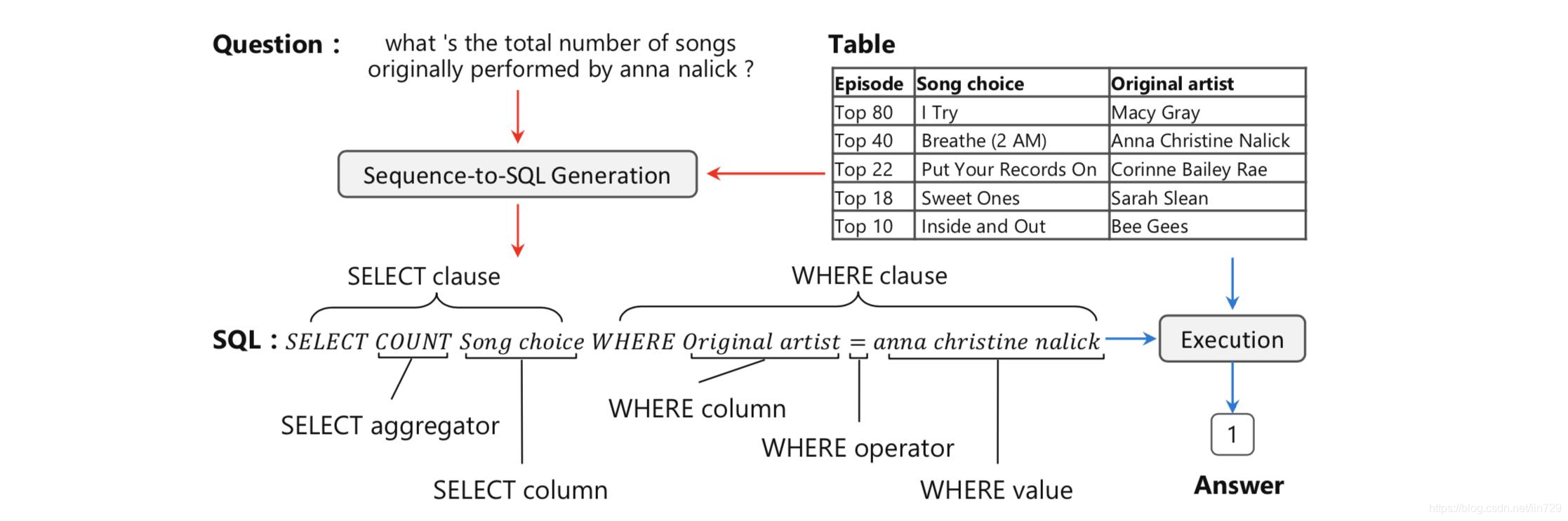
图-1.Text to SQL问题示例
三、数据集
Text to SQL的数据集由人工标注了自然语言问题和对应的SQL查询。自然语言问题是限制在数据库数据所在领域的问题,其答案来自其数据库。即该问题是描述一个SQL查询。执行SQL查询可以从其数据库中获得问题的答案。

表-1为目前主流数据集的统计数据
数据集涉及如下概念:
- 数据库:一个数据库包含多张数据表,一个数据表包含多个字段。
- 领域:数据库数据来源场景,根据涉及场景数量,可分为单领域和多领域,如餐饮数据和旅游景点为两个领域。
- 单表/多表:根据自然语言问题涉及表格数量,分为单表和多表。在多表中,SQL生成涉及到表格的选择。
- sql复杂度:根据自然语言问题对应的sql复杂度,数据集分为简单问题和复杂问题,其中问题复杂度由SQL查询语句涉及到的关键词数量、嵌套层次、子句数量等确定。
- 对话轮数:根据完整SQL生成所需对话轮数,数据集分为单轮和多轮。
- 结合对话:若SQL生成融进渐进式对话,则数据集增加“结合对话”标记。当前只有CoSQL数据集是结合对话的数据集。
早期数据集只包含一个领域和一个数据库,如ATIS (Dahl, Bates et al., 1994), GeoQuery(Tang, Mooney et al., 2001.), Restaurants(Tang, Mooney et al., 2000.)等。最新的数据集WikiSQL(V. Zhong, C. Xiong et al., 2017)和Spider(T. Yu, R. Zhang et al,. 2018)包含多个领域、自然语言问题规模更大,sql类型也更多样。数据集的大小对评估模型至关重要,语义解析的准确率与训练数据量之间存在Log的关系[Daya Guo, Yibo Sun et al,. 2018)。测试集中那些在训练集里未见过的复杂查询可以评估模型的泛化能力。(C Finegan-Dollak,Kummerfeld et al., 2018)中的作者指出,传统数据集高估了系统的通用性。WikiSQL虽然包含大量的自然语言问题和SQL查询,但这些SQL查询很简单,只集中在单个表上。与WikiSQL相比,Spider(T. Yu, R. Zhang et al., 2018)数据集包含的问题和SQL查询数量较少,但更复杂,其SQL查询包含了不同的SQL子句,如表联接和嵌套查询。
SParC(T. Yu, R. Zhang, M. Yasunaga et al., 2019)和CoSQL(T. Yu, R. Zhang, H. Er et al., 2019)是Spider数据集的扩展,该数据集是为上下文跨域语义分析和SQL系统多轮对话而创建的。这些新的数据集为该领域的研究带来了新挑战。DuSQL(L Wang, A Zhang et al., 2020)是百度发布的大规模多表多领域包含复杂问题的中文数据集。CHASE(Jiaqi Guo, Ziliang Si et al., 2021)整理自DuSQL和Sparc,是训练集和开发集、测试领域不重复的跨领域大规模多轮交互中文数据集,另外CHASE 额外标注了上下文依赖关系,包括 Coreference 共指、Ellipsis 省略和模式链接关系,即对于 query 中提到的表名和列名信息进行了标记。

图-2 Text to SQL数据集发展趋势,代表数据集参见表-2。
四、方法
从本任务涉及的数据来看,用户输入为自然语言问题,可利用的数据有数据库、SQL关键词,输出为SQL查询语句,本质上是一个符合语法、有逻辑结构的序列。所以,sql的构成来自三部分:
- 自然语言问题:结合数据库,一般可以直接抽取出sql中需要的表名,列名,条件表达式,条件值
- 数据库:结合自然语言问题,一般用于辅助识别sql中需要的表名,列名,条件表达式,条件值
- SQL关键词:作为sql查询语句的候选token,用于生成sql
所有工作都在完成基于上述三部分数据来生成一个可在给定数据库中执行以获取正确结果的sql。
4.1 基于模板和规则
早期研究多基于规则的方法(A.-M. Popescu et al., 2003)。因为SQL查询语句本身是一种有很强范式的编程语言,既然是语言就有一定的语法结构。根据SQL执行的复杂程度,可以将其分为简单SQL和复杂SQL。简单SQL只涉及少数的SQL关键字和组成部分,典型特征是可以拆分为“SELECT”和“WHERE”两个片段。简单SQL语句都可以抽象成如下图-3的模板:

图-3 简单SQL模板
- SELECT描述选择哪些列,并对这些列分别做什么操作,决定了最终选择的结果
- WHERE描述选择的方法或者条件,决定这些列哪些单元格能被选择出来
- AGG表示聚合函数,如求max,计数count,求min
- COLUMN表示需要查询的目标列
- WOP表示多个条件之间的关联规则“与/或”
- 三元组 [COLUMN, OP, VALUE] 构成了查询条件,分别代表条件列、条件操作符(>,=,<等)、条件值(从问题中抽取出的文本片段)
- *表示目标列和查询条件不止一个!
基于该模板,针对用户输入的问题,可以设计一些匹配问题的正则表达式来抽取SQL模板中各个片段内容。如一种简单查询的模板设计如下:
- 问题:起购金额低于1000的理财有哪些?
- 表达式:([COLUMN]+?)([低于]+?)(\d+?)的([COLUMN]+?)有哪些?
- SQL:SELECT 理财 FROM 理财产品 WHERE 起购金额 < 1000;
同理,针对其他更多的查询sql,都可以设计配套的表达式去匹配用户的问题和抽取sql相应的成分。这是基于正则表达式来识别sql类型和抽取成分。然而,正则的弊端是需要列举各种表达范式,工作量大。其次,如果表达范式写的太严,容易导致漏匹配,相反,写的太宽泛易导致误匹配。为了解决上述问题,可以使用有监督的方法来替换正则,如使用神经网络对问题进行编码,识别sql类型可以采用分类的方法;抽取sql字段值可以采用序列标注的方法。该方法类似对话系统中的意图识别和槽位填充,往往一个模型可以同时实现分类和填槽。
本方法可快速实现一套覆盖主要问题的text2sql系统,可解释性强,对定义中的sql准确率高,定义外的sql可以拒绝识别。但由于每类sql都需要先定义,导致能覆盖的sql类型较少,如select有1-n列可以组合,where条件组有1-n组可以组合,会导致sql类型数据激增,这时,该方法再覆盖就工作量巨大。为了生成的sql更灵活,样式更多,很多工作已经切换到端到端的神经网络模型。
4.2 基于Seq2Seq框架
自然语言中的很多任务可以分类为1->N,N->1,N->N,N->M,1、N、M为token的数量。1->N为生成任务,典型的如输入一张图片,输出为该图片的文本描述。N->1为分类任务,如输入一句话,输出为它所属类别的编号。N->N为序列标注任务,如输入一句话,输出为该句话的词性标注。N->M为翻译任务,如输入一句中文,输出该中文对应的英文。
显然Text2SQL天然符合N->M,类似翻译任务。目前主流的翻译模型都是基于Seq2Seq框架来实现,即先对输入进行编码获取语义信息,再对语义编码进行逐字递归解码,获取翻译后的句子。
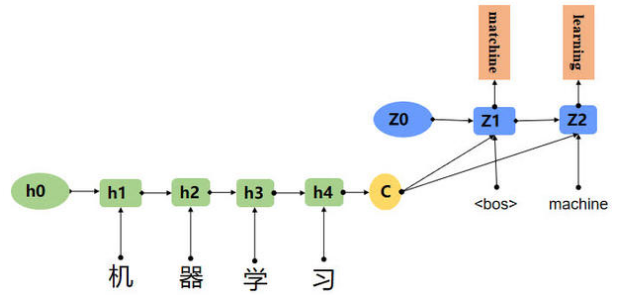
图-4 Seq2Seq框架示例
典型Seq2Seq框架不能完全解决Text2SQL中面临的各种问题,而是大量研究分别从编码端和解码端进行改进,取得了显著的效果。
4.2.1 编码方法
4.2.1.1 Table-aware
首先,在编码器上,为了充分建模问题与数据库的关系,本任务的输入一般由问题query、表名table和列名column联合,以捕捉三者隐含的链接关系。基本做法为将输入拼接为 “[CLS] query [SEP] table [SEP] column1 [SEP] column2 [SEP] … [SEP]”这样的长序列,三者在进入编码器后就会有交互,这样可以提前知道表格的信息,所以叫Table-aware。使用该编码较为普遍,典型的有Yibo Sun, Duyu Tang et al., 2018和W Hwang,Yim et al., 2019。
编码器大都采用典型的CNN,RNN,Transformer,bert来学习不同table和column对于问题query的相关性。
4.2.1.2 Anonymous Encoding
也有许多工作专门改进了这部分的结构。考虑到数据库中同一个信息,在问题中会有不同的描述,而对应的sql形式却是一样的。如:列名-年龄,问题中可能描述为“年纪大于28的老师有哪些?”,或者“岁数大于28的老师有哪些?”,但对应sql都是“select 老师 where 年龄 > 28;”。如果先对问题中涉及的表格信息进行识别,然后对识别到的token进行匿名再输入到模型中,这样可以加强模型对问题和sql本身的映射识别。
所以,论文Data-Anonymous Encoding for Text-to-SQL Generation(Z Dong,S Sun et al., 2019)先用一个序列标注模型anonymization model将用户问题x的每个token先标记为所属数据库中的成分,如COL1, . . . , COLK, CELL, UNK,COLk表示该token为表格的第几列,CELL表示该token为表格中的单元格值,UNK表示和表格没有关系。 被标记好的 x ~ \tilde{x} x~ 再次编码成向量与原始x编码向量一起当做sql解析模型的编码输入(图5)。
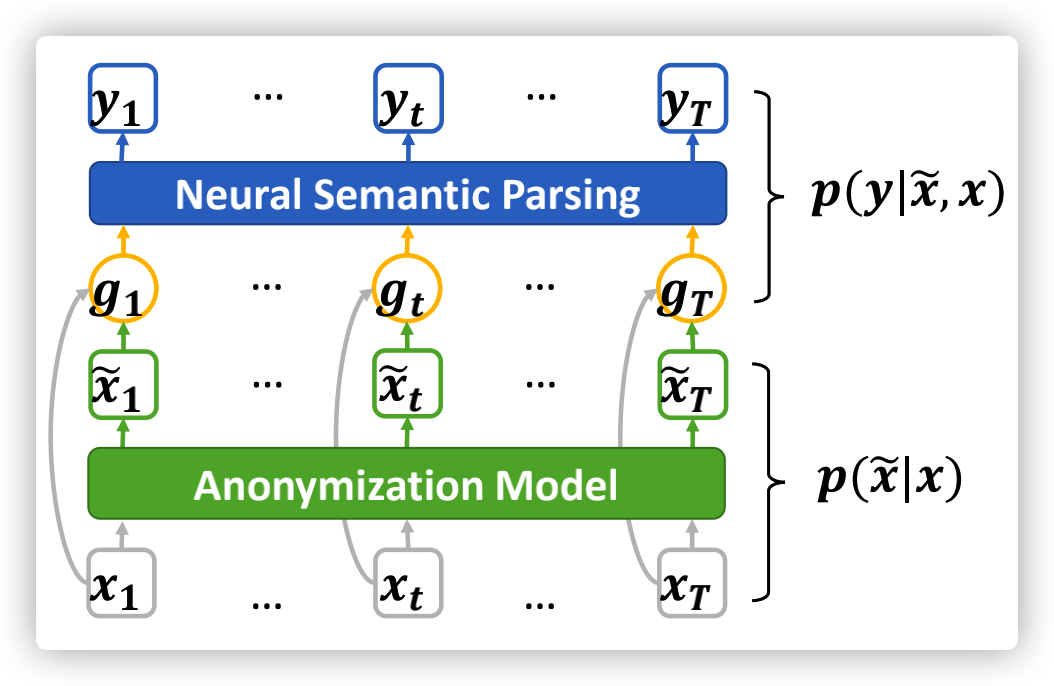
图-5 Anonymous Encoding
4.2.1.3 GNN
考虑到数据库(Database Schema)在训练以及预测时都是完全可见的,它能反映数据的结构及其数据之间的联系,比如表的列名、列之间主外键的关系等。先前的工作集中在建模问题和数据库的关系,没有对其数据库本身包含的信息进行建模,论文Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing( Bogin,M Gardner et al., 2019)介绍了一种将数据库构筑成图的形式,利用图神经网络(GNN)进行编码,以提升模型在更复杂的DB schema下的表现。
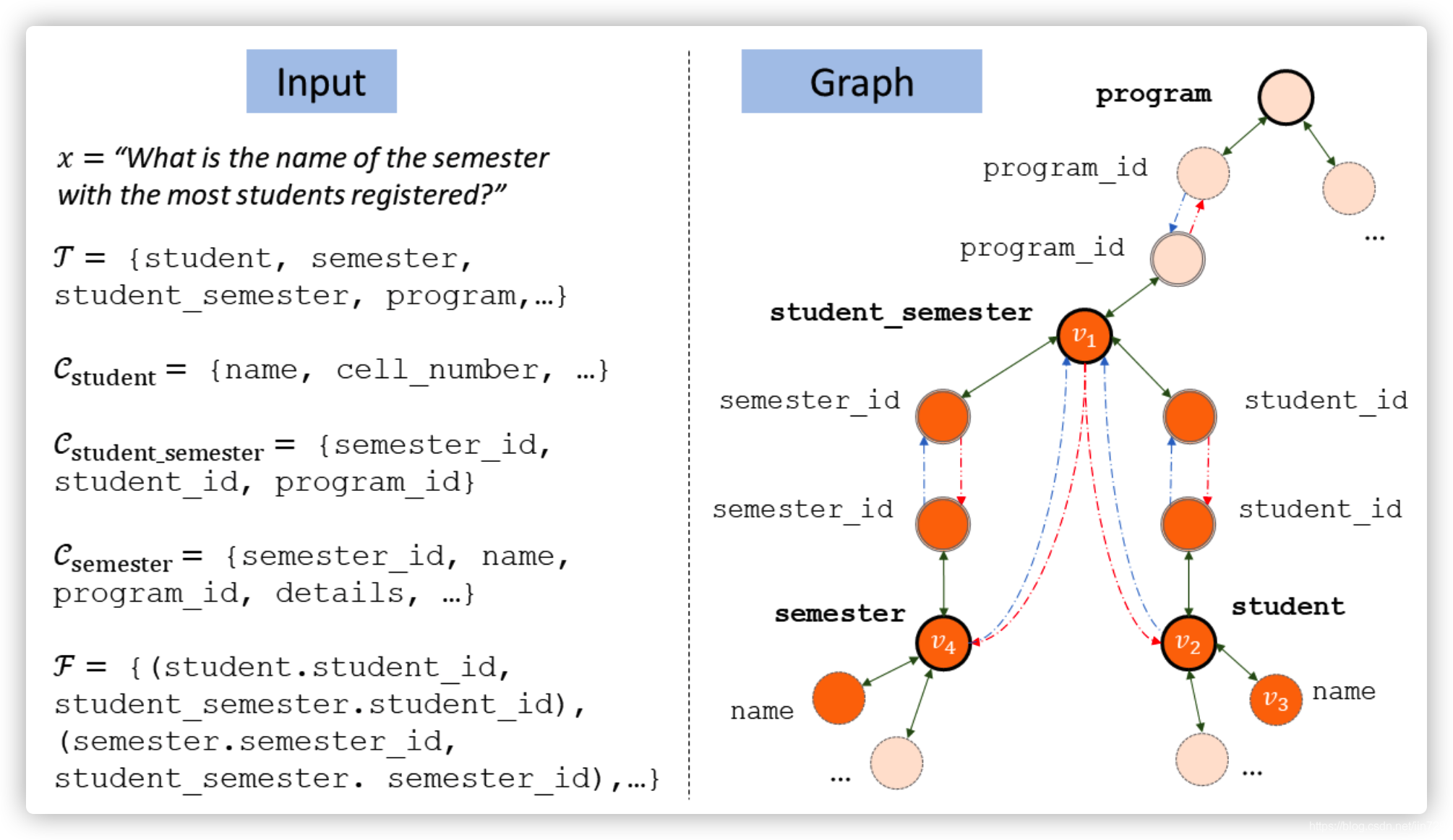
图-6 GNN编码方式
如图-6,首先将数据库转换为图,图-6左边为输入,包括问题x,表格T有student, semester, student_semester, program,每个表的列名有name,cell_number等,还有表之间的外键关系。构建右边图的过程为:将表名和列名各自作为一个节点;将每个表的节点分别与其所有的列用双向边连接起来,作为第一类边;将主外键对和相应的表连接起来,以主键为起始点的边作为第二类边,以外键作为起始点的边作为第三类边,例如student.student_id-> student_semester. student_id和student-> student_semester是第二类边,反向则是第三类边。
为了能够反映每个节点与问题的相关度,模型会学习schema每个图节点向量表示v与问题中每个词xi的相关度,最后问题中每个词xi的编码向量加上其与加权v的和,即为编码器最后输入。
在涉及多表联合查询的数据集上,加入图网络可以有效增强数据库的表示,采用该方法的模型还有如Global GNN(Ben Bogin, Matt Gardner et al., 2019)、RATSQL(Bailin Wang, Richard Shin et al., 2020)等。
4.2.1.4 Relation-Aware Self-Attention
模型需对表结构(表名、列名、列类型、主键、外键等等)进行编码,以便后续使用,这个步骤称为Schema Encoding。同时,模型必须识别用户问题与数据库中哪些表格、列名、单元格有关系,称为 Schema Linking:将用户问题中的实体与数据库中的实体对齐。
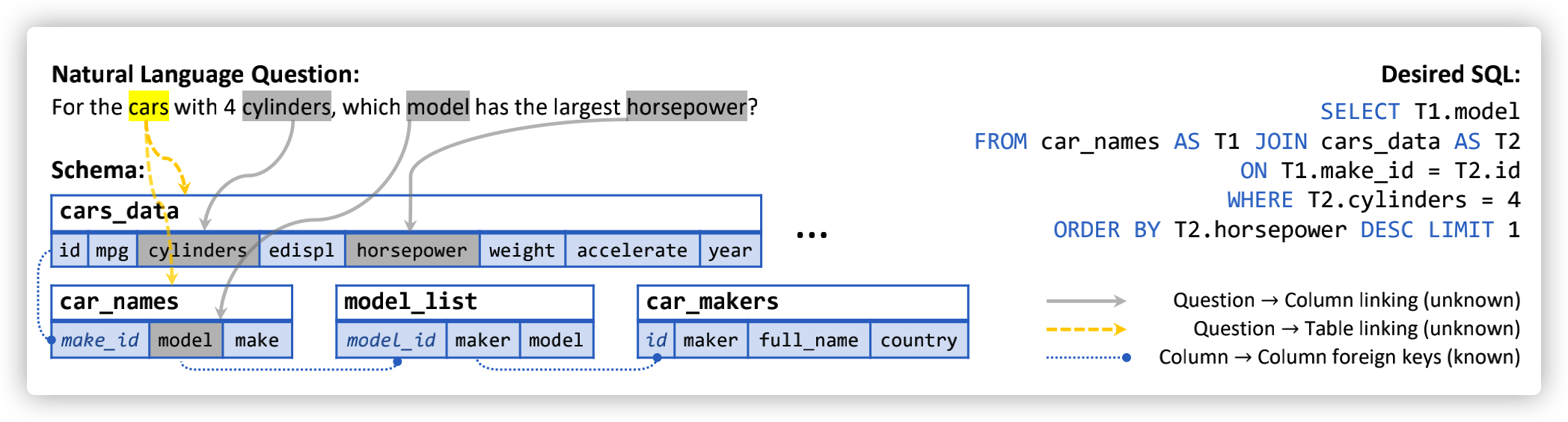
图-7 Schema Linking示例
虽然上文中提到已有文献Global GNN(Ben Bogin, Matt Gardner et al., 2019)研究了GNN的Schema Encoding,但对schema linking的研究相对较少。如上图-7中的例子:用户问题中的“model”指的是car_names.model而不是model_list.model,同样,“cars”是指cars_data表和car_names表(而不是car_makers表)。这类实体指代的歧义问题对模型是个很大的挑战。
要提升Schema Linking的准确率,必须将表结构(schema)和用户问题question中的信息同时考虑。但此前的工作(GNN encoder)在encoding时只考虑schema,未考虑到question中所包含的上下文信息。同时GNN-based的encoding方式,使得关系表示局限于预先定义的graph edges中,限制了模型的表示能力。
文章RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers(Bailin Wang, Richard Shin et al., 2020)提出使用relation-aware self-attention,将GNN各个node之间的关系
r
i
j
r_{ij}
rij 同时作为训练输入加入到transformer的attention计算中,从而把显式关系(schema)和隐式关系(question和schema之间的linking)都考虑在encoding中,完善模型的编码表示能力。
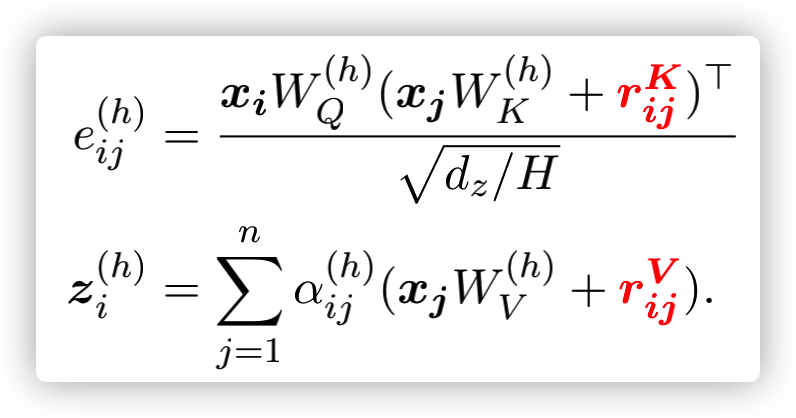
图-8 Relation-Aware self-attention公式
4.2.1.5 表格预训练
从2018年bert开始,已经出现了大量基于大规模预训练的语言模型。本任务场景下理解表格,将表格的内容和question中的实体相对应,充分利用表格里的信息尤为重要。目前的语言模型如BERT无法直接对表格encoding。另外,表格行列规模巨大,如果全部编码可能会带来内存上的负担。其次,用户问题和table会有很大的联系,还需要注意将表格和语句联系在一起。
为了解决上述问题,论文TABERT: Pretraining for Joint Understanding of Textual and Tabular Data(P Yin,G Neubig et al., 2020)提出了Tabert,使用content snapshots技术,只对最相关的行列做encoding。
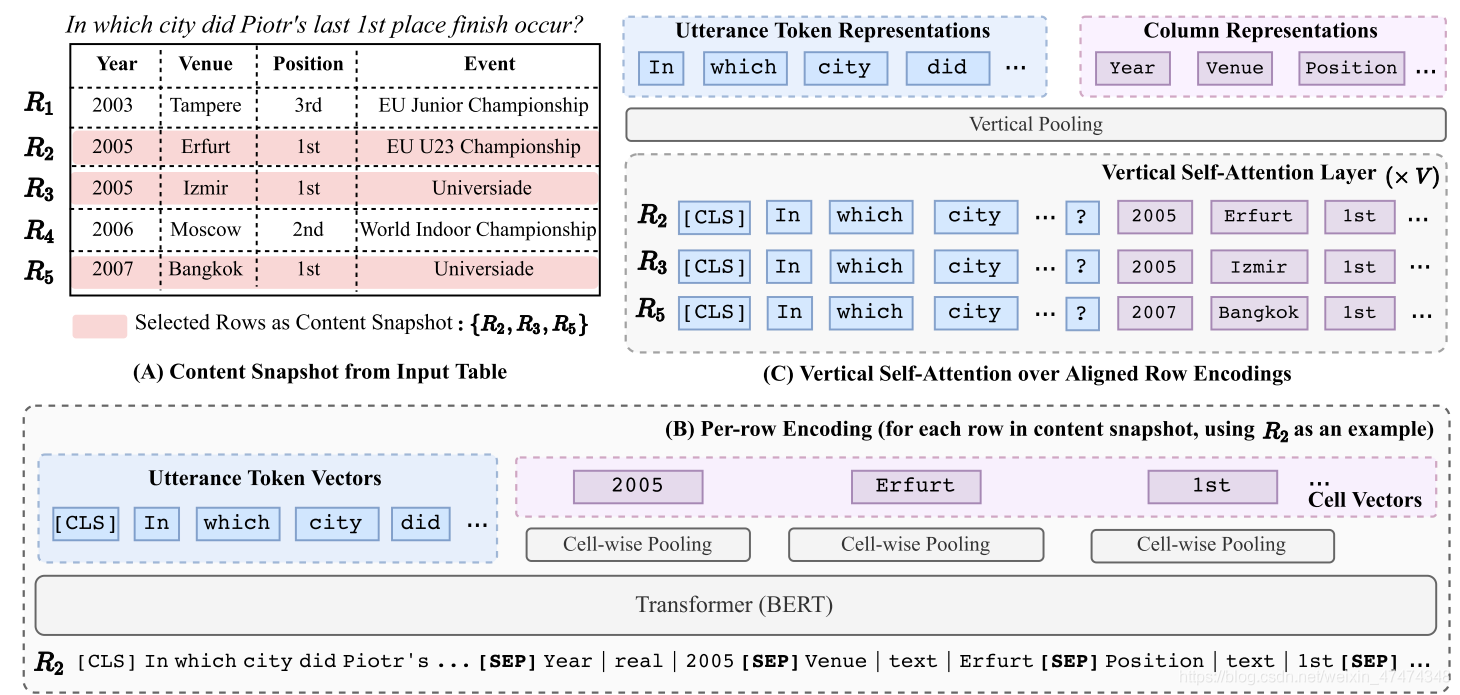
图-9 Tabert总览
如图-9,Tabert先根据用户问题utterance u和表格table T,创建content snapshot。 snapshot是选择在表格中和输入语句最相关的行,然后把所有相关的行线性化,每一行都和question拼接在一起形成新的字符串,然后输入transformer。
为了构建大规模预训练数据,作者从Wikipedia和WDC收集了大量表格和相关的语句,一共构建了包含2660w个样例(表和自然语言句子)。
TaBert使用不同的目标来学习上下文和结构化表的表示。对于自然语言上下文,使用遮蔽语言模型(MLM)目标,在句子中遮蔽15%的token。对于列的表示,TaBert设计了两个学习目标:
- 遮蔽列预测(Masked Column Prediction,MCP):目标使模型能够恢复被遮蔽的列名和数据类型。具体来说就是从输入表中随机选取20%的列,在每一行的线性化过程中遮蔽掉它们的名称和数据类型。给定一列的表示,训练模型使用多标签分类目标来预测其名称和类型。直观来说,MCP使模型能够从上下文中恢复列的信息。
- 单元值恢复(Cell Value Recovery,CVR):目标能够确保单元值信息能够在增加垂直注意力层之后得以保留。具体而言,在MCP目标中,列ci被遮蔽之后(单元值未被遮蔽),CVR通过这一列某一单元值的向量表示s<i, j>来恢复这一单元值的原始值。由于一个单元值可能包含多个token,TaBert使用了基于范围(span)的预测目标,即使用位置向量e_k和单元的表示s<i, j>作为一个两层网络的输入,来预测一个单元值的token。
TaBert模型能学习如何表达用户问题和半结构化的表格关系,已在WikiSQL和Spider上取得良好的效果。但TaBert并没有充分利用用户问题与sql的组合关系,最新发表在ICLR 2021上的GRAPPA: Grammar-Augmented Pre-Training for Table Semantic Parsing(T Yu,CS Wu et al., 2020)又加强了用户问题、表格、sql语句三者的关系预训练。
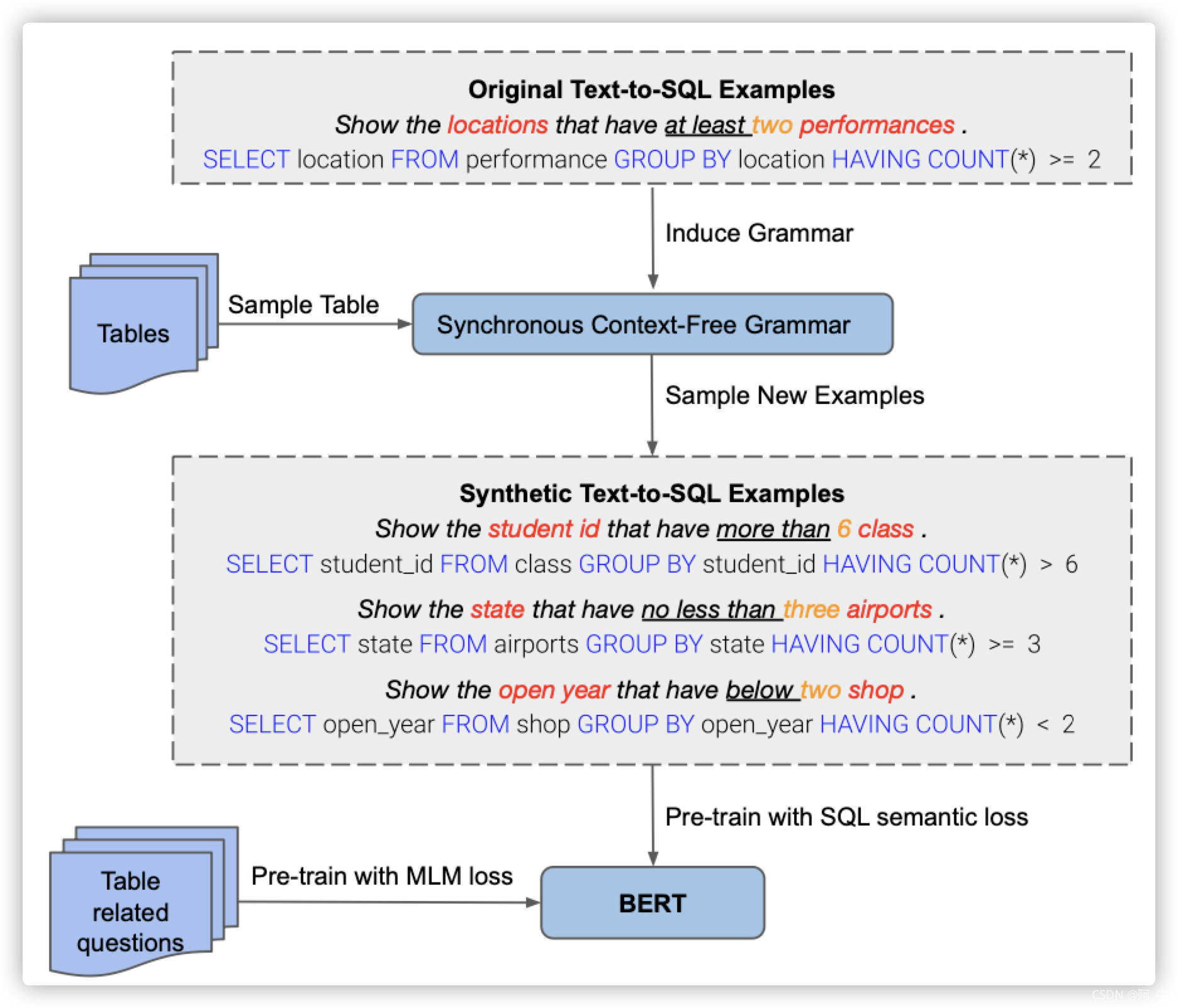
图-10 Tabert总览
GRAPPA 主要有两个部分:
- 数据合成:如上图,首先将已有的标注数据抽象成tables fields values SQL operations,创建一个question-SQL模板。然后,随机采样一些表格将其字段填入该模板,可自动合成大量的question-SQL pairs。
- 预训练:使用RoBERTaLARGE的初始化权重,再在两个目标函数上进行预训练。目标1为掩蔽语言建模(MLM),mask对象为question,mask比例为15%。目标2为SQL语义预测(SSP),给定一个question和表格列,预测每个列是否出现在question对应的SQL查询中以及触发的什么操作。将所有的SQL序列标签转换为各列的操作分类标签(operation classification label )。在本实验中,总共有254个潜在的 operation class。
GRAPPA 预训练方法可以有效利用大量的合成数据,提前充分学习自然语言问题与表格和sql之间的表示,显著提高了下游任务的性能,spider榜单中结合了该方法的RAT-SQL + GraPPa + Adv (DB content used),SmBoP + GraPPa (DB content used)都取了最近的top 1成绩。
4.2.2 解码方法
4.2.2.1 pointer network
解码端一般做法是先生成第一个token,然后基于第一个token自回归地生成第二个token,以此循环,直至生成一个停止token才终止。本任务中生成的序列为sql语句,每个token来自三方面:sql关键词,表格名,列名,用户问题片段。传统的解码方法在选择生成token时会对词汇表进行选择,选择范围很大,准确率低,同时,如遇到用户问题中包含未登陆词时,会导致sql运行错误。
考虑到sql中条件表达式的值部分往往来自用户问题中的某个片段,可以使用Pointer Network解决上述问题,使输出的token直接复制自输入序列,这样输出能随输入而变化。具体做法是利用注意力机制,直接从输入序列中选取当前注意力得分最高的单词作为输出。
由于Pointer Network可以较好的满足具体数据库无关这一要求,在多领域数据集上的模型大多使用该网络,如Seq2SQL(Victor Zhong, Caiming Xiong et al., 2017)、STAMP(Yibo Sun, Duyu Tang et al., 2018)、Coarse2Fine(Li Dong, Mirella Lapata et al., 2018)、IRNet(Jiaqi Guo, Zecheng Zhan et al., 2019)等模型。
4.2.2.2 Reinforcement Learn
如果直接用pointer network解码得到Where语句中的条件值,会存在一个问题:where语句中多个条件之间是没有顺序的,不同的顺序实质上是等价的,但训练模型是只指定一种序列。因此,Seq2SQL(P. Yin, Z. Lu et al., 2016)提出用强化学习来学习策略以生成执行正确的查询语句。
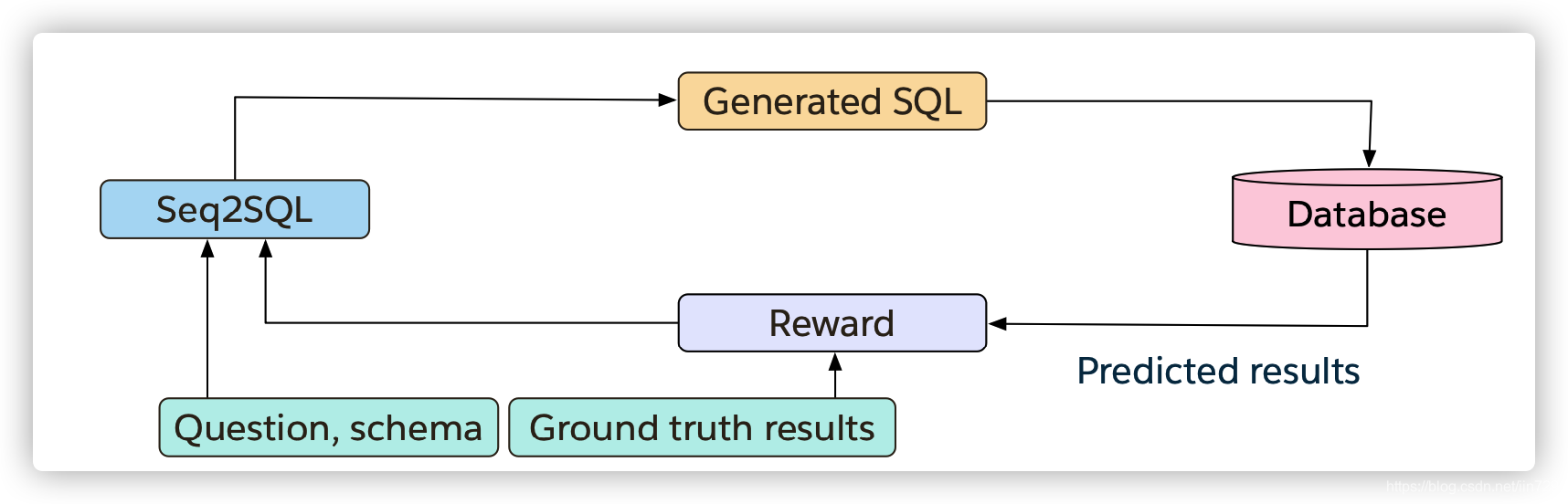
图-11 Seq2SQL模型框架
强化学习的奖励通过执行查询的结果来获得,设置如下:

图-12 Seq2SQL模型中强化学习奖励函数
4.2.2.3 Sketch and Multitask
在简单问题对应的数据集上,如WikiSQL,其SQL形式简单,可以分解为仅包含Select和Where两部分。其中where部分往往包含多个约束子句,这些子句的顺序并不影响查询结果,但从语法上看,顺序不同,对应的sql也不同,训练时产生的loss也不同,从而影响序列到序列模型的性能。为了解决该问题,SQLNet(X. Xu, C. Liu et al., 2017)提出将该类型sql用草图(sketch)来描述,基于草图再生成SQL。
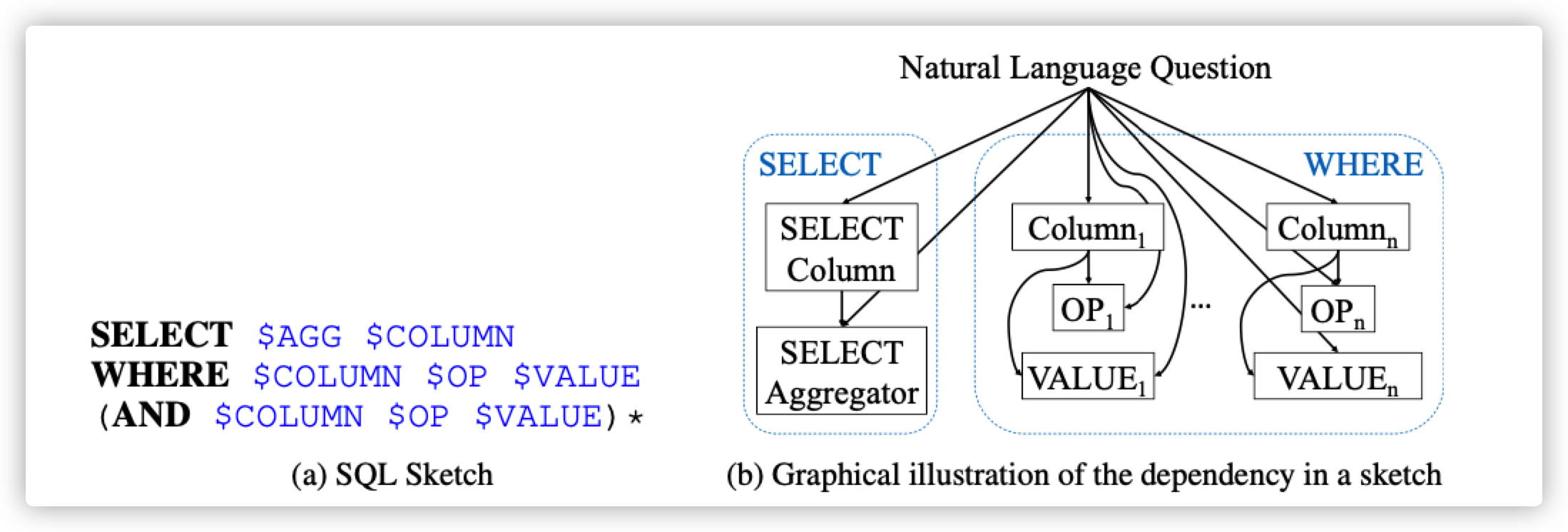
图-13 SQL语法的Sketch以及各部分依赖关系
如图-13所示,该草图可以表示所有WikiSQL数据集中的SQL。这些sql分为两种不同的标记类型:关键字(keywords,如SELECT,WHERE)和要填充的槽(slots)。槽存在于SELECT子句或WHERE子句中,即图中长方形框。槽值分为以下几类:
- COLUMN:列名,可填充在SELECT子句和WHERE的条件表达式的变量中
- AGG:对select的列进行聚合,称为聚合函数,一般有五种:sum,max,min,std,count ;
- OP:条件表达式的比较运算符,有>,=,<等
- VALUE:条件表达式的比较值,是自然语言问题中的子字符串。
基于上述草图,sql生成可采用插槽填充的思想,通过对自然语言问句的刨析来向SQL结构中的插槽填充各种值。这样有效地避免了seq2seq中where语句的顺序问题。槽填充问题又可转化为decoder端的多任务模型,一般包括多个分类任务完成对sql关键词和列名的分类,以及输入值拷贝任务完成条件表达式中value的填充。该方法在SQL形式简单的数据集上取得了较好效果,且衍生出很多相关模型,如TypeSQL(Tao Yu, Zifan Li et al., 2018)、SQLova(Wonseok Hwang, Jinyeong Yim et al., 2019)、X-SQL(Pengcheng He, Yi Mao et al., 2019)等。
4.2.2.4 Abstract Syntax Network
semantic parsing任务是建立一个从自然语言(utterance)到机器可执行的逻辑语言(logic form)的一个映射模型,Text2sql就属于此类任务的一种。由于生成的sql需要严格符合sql语法,而传统的解码方式存在一个严重问题是生成序列中任何一个token语法有误都将导致整个sql错误。如:一开始就生成了where 这个token,那后面所有的token都是无效的,因为一开始整个输出的语法就错误了,完全无法在数据库中执行。
为了解决上述问题,需要在解码过程中强制限制decoder生成的结构,使得语法合法,能有效执行。限制方法主要分为两类,Token-based Methods和Grammar-based Methods。目前text2sql中使用较多的是第二种。Grammar-based Methods依赖语法树abstract syntax tree(AST)作为logic forms的载体。AST可以将任何具体的logic forms转化为一颗树来存储,定义这类语法树的语言称为abstract syntax description language(ADSL)。
TRANX: A Transition-based Neural Abstract Syntax Parser for Semantic Parsing and Code Generation(Pengcheng Yin, Graham Neubig et al,2018)正是基于ASTnet(Maxim Rabinovich, Mitchell Stern et al., 2017)论文思想,在decoder生成时,不再直接生成logic form里面的tokens,而是先生成一颗合法的语法树,再基于语法树生成logic forms。如下图给出的系统流程:首先,如图中ASDL Grammar,先根据SQL语法定义ASDL规范,基于该ASDL,每一条SQL查询语句均满足该文法规范,即可以由该规范产生。然后,如图中Transition System,为生成语法树设计一套动作,每个执行动作对应一个树节点(图中Abstract Syntax Tree),即将生成树任务转化成选择一系列动作的过程。由于动作选择即孩子节点文法均在父节点允许的文法范围内,所以在选择过程中保证了合理性。该动作序列的生成可采用Seq2Seq框架完成。最后,基于已生成的AST,调用已定义好的转化函数AST to MR(·),将AST中间形式转换为具有具体语义的表示,如sql语句,完成解析过程。
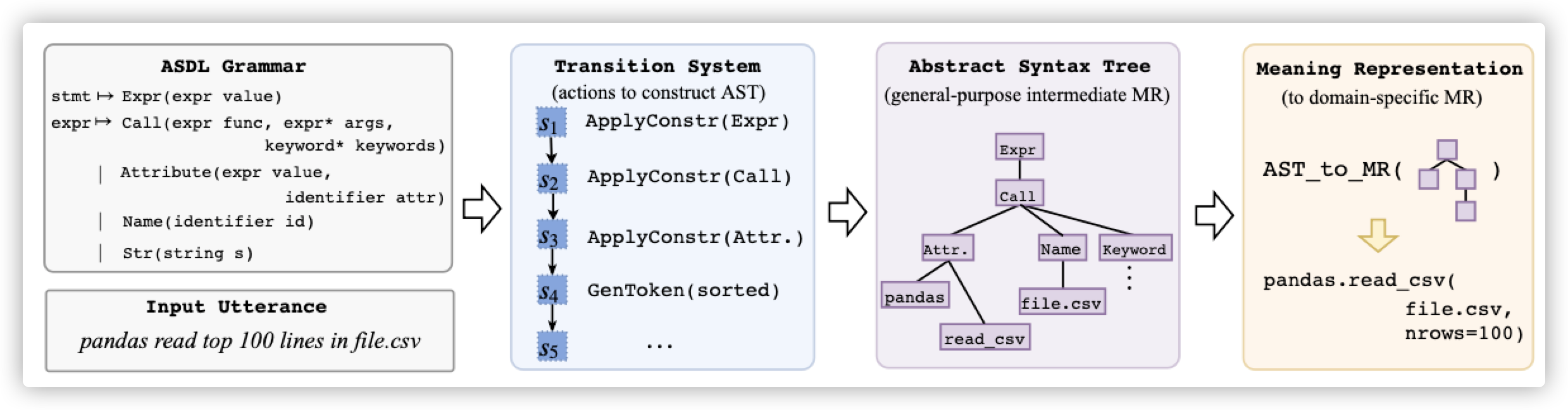
图-14 基于AST的解码器
该方法在代码生成、SQL生成等任务上都已取得了较好效果,在本任务上使用了该方法的模型有SyntaxSQLNet(T Yu,M Yasunaga et al., 2018),IRNet(Jiaqi Guo, Zecheng Zhan et al., 2019)、Global GNN(Ben Bogin, Matt Gardner et al., 2019)、RATSQL(Bailin Wang, Richard Shin et al., 2020)等。
4.2 基于Information Extraction Approach
基于Seq2Seq框架,最先进的解码方式主要采取sketch加多任务槽位填充(slot-fifilling)的方式或者基于AST进行语法树生成,这两种方法在WikiSQL和spider的benchmark上效果领先。但此类模块化系统不仅复杂,而且对于捕捉 SQL 子句之间的相互依赖关系的能力也有限。Mention Extraction and Linking for SQL Query Generation(J Ma,Z Yan et al., 2020)提出采用统一的基于BERT的抽取模型来识别query提及的槽位类型,通过用一组BIO标签标记自然语言问题中的每个 token 属于sql中的哪个成分。
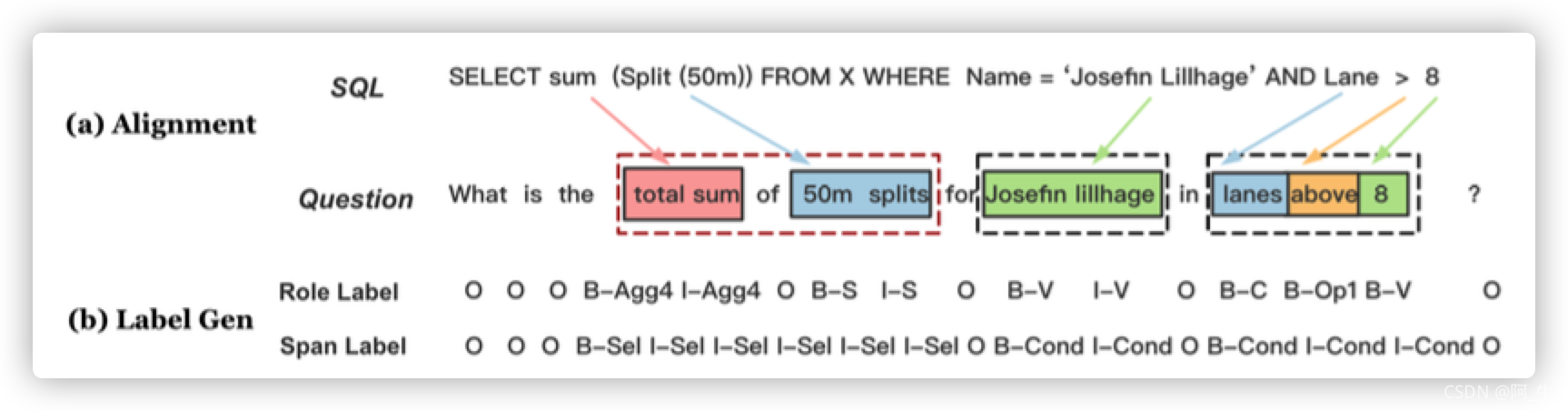
图-15 IE-SQL模型
该方法在WikiSQL数据集的测试集上sql执行准确率在达到了92.5分,曾获得WikiSQL benchmark的第一名,但此类基于序列标注(sequence labeling)的方法局限性在于对具有复杂嵌套跨度结构sql问题上表现一般。
4.3 基于MRC Approach
在WikiSQL数据集上,主流模型都采取sketch加多任务槽位填充(slot-fifilling)的方式实现sql生成。然而,一个sql中往往包含多个slot需要filling,每个filling类似于一些限制条件。之前的工作是对不同的filling都构建一个模型,然后组合到一起,这样对于多变的SQL语句来说并不稳定,而且训练过程繁琐。SQL Generation via Machine Reading Comprehension(Yan Z, Ma J et al, 2020)论文作者将该问题转化为通过多次向MRC模型提问得到回答来实现类似filling动作填充slot。

图-16 基于MRC的SQL生成模型
论文的结果并没有全方位超越目前已有的模型,不过它提出了一种全新的方法,比之前的方法更简洁更容易实施。
五、评价
本任务的效果评估,没有标准统一的唯一的度量,目前广泛使用的有两种。一种是执行准确率execution accuracy,即计算sql执行结果正确的数量在数据集中的比例(V. Zhong, C. Xiong et al., 2017)。该方法存在高估的可能,如一个完全不同的非标准的sql可能查出于与标准sql相同的结果(例如,空结果),这时也会判为正确。
另一种是逻辑形式准确率logical form accuracy(V. Zhong, C. Xiong et al., 2017),即计算模型生成的sql和标注sql的匹配程度。这种方法的缺点存在低估的可能,如一个sql执行结果是正确的,但于标注sql的字符串并非完全匹配,例如,只是select 列的顺序不同或sql查询目的完全相同的不同sql。为了解决一部分该问题,作者在[20]中介绍了一种查询匹配精度query match accuracy:将生成的sql和标注sql都以标准形式表示,再计算两者匹配精度。这种方法只解决了由于排序问题而导致的误判。另外,通过对列和表进行排序并使用标准化别名来对SQL进行规范化,也可以消除不同sql格式导致的误判问题(C Finegan-Dollak,Kummerfeld et al., 2018)。
T. Yu, R. Zhang et al., 2018中的评估指标包括sql组件和精确匹配component and exact matching。每个sql查询都分为如下组件:SELECT, WHERE, GROUP BY, ORDER BY and KEYWORDS。生成的sql和标注的sql都被划分并表示为每个组件的子集,然后将这些子集进行精确匹配。但是,对于具有相同查询逻辑的SQL,如果有另一种全新的组合语法,上述问题还是存在,需要结合执行精度进行综合评估。
目前,还没有一个指标可以独立地精确地评估不同模型差异。因此,将现有的不同指标进行结合来评估会是重要的解决方法。同时,评价指标也是这一领域未来值得研究的工作。
六、总结
将自然语言转换为SQL查询是一个语义分析问题,具有如对话系统,商业智能等实用的应用场景,引起了学术界和工业界的广泛关注。目前已经公开的文本到SQL的数据集,包括了单领域、多领域、单表、多表、简单sql、复杂sql、单轮对话、多轮对话等不同维度的数据,场景丰富,难易程度循序渐进,促进了该领域的发展。
随着数据集规模的增加,本任务也变得越来越复杂,针对这些问题,许多研究者提出了相应的改进模型,取得了显著的进步。但目前的模型,还不能很好解决复杂的sql查询,例如IRNet在Hard和ExtraHard的准确率也仅为48.1%和25.3%,目前spider榜单上最好的模型集成方案T5-3B+PICARD (DB content used)也仅达到了75.1的执行准确率。期待后面能有更加突出的工作出现。
参考文献
J. Andreas, A. Vlachos, and S. Clark, “Semantic parsing as mach. transl.,” in Proc. of the 51st Annu. Meeting of the Assoc. for Comput. Linguistics (Vol. 2: Short Papers), pp. 47–52, 2013.
Y. Sun, D. Tang, N. Duan, J. Ji, G. Cao, X. Feng, B. Qin, T. Liu, and M. Zhou, “Semantic parsing with syntax-and table-aware sql gener.,” in Proc. of the 56th Annu. Meeting of the Assoc. for Comput. Linguistics (Vol. 1: Long Papers), pp. 361–372, 2018.
A.-M. Popescu, O. Etzioni, and H. Kautz, “Towards a theory of natural lang. interfaces to databases,” in Proc. of the 8th Int. Conf. on Intell. User Interfaces, pp. 149–157, 2003.
D. Goldwasser, R. Reichart, J. Clarke, and D. Roth, “Confidence driven unsupervised semantic parsing,” in Proc. of the 49th Annu. Meeting of the Assoc. for Comput. Linguistics: Human Lang. Technol., pp. 1486– 1495, 2011.
J. M. Zelle, Using inductive logic program. to automate the construction of natural lang. parsers. PhD thesis, 1995.
P. Liang, M. I. Jordan, and D. Klein, “Learning dependency-based compositional semantics,” in Proc. of the 49th Annu. Meeting of the Assoc. for Comput. Linguistics: Human Lang. Technol.-Vol. 1, pp. 590– 599, Assoc. for Comput. Linguistics, 2011.
P. Yin, Z. Lu, H. Li, and B. Kao, “Neural enquirer: learning to query tables in natural lang.,” in Proc. of the 25th Int. Joint Conf. on Artif. Intell., pp. 2308–2314, 2016.
D. A. Dahl, M. Bates, M. Brown, W. Fisher, K. Hunicke-Smith, D. Pallett, C. Pao, A. Rudnicky, and E. Shriberg, “Expanding the scope of the atis task: The atis-3 corpus,” in Proc. of the workshop on Human Lang. Technol., pp. 43–48, Assoc. for Comput. Linguistics, 1994.
L. R. Tang and R. J. Mooney, “Using multiple clause constructors in inductive logic program. for semantic parsing,” in Eur. Conf. on Mach. Learn., pp. 466–477, Springer, 2001.
L. R. Tang and R. J. Mooney, “Automated construction of database interfaces: Intergrating statistical and relational learning for semantic parsing,” in 2000 Joint SIGDAT Conf. on Empirical Methods in Natural Lang. Process. and Very Large Corpora, pp. 133–141, 2000.
F. Li and H. V. Jagadish, “Constructing an interactive natural lang. interface for relational databases,” Proc. of the VLDB Endowment, vol. 8, pp. 73–84, September 2014.
A. C. J. K. Srinivasan Iyer, Ioannis Konstas and L. Zettlemoyer, “Learning a neural semantic parser from user feedback,” in Proc. of the 55th Annu. Meeting of the Assoc. for Comput. Linguistics (Vol. 1: Long Papers), pp. 963–973, 2017.
I. D. Navid Yaghmazadeh, Yuepeng Wang and T. Dillig, “Sqlizer: Query synthesis from natural lang.,” in Int. Conf. on Object-Oriented Program., Syst., Languages, and Appl., ACM, pp. 63:1–63:26, October 2017.
C Finegan-Dollak,Kummerfeld, Jonathan K,L Zhang,K Ramanathan,S Sadasivam,R Zhang,D Radev, “Improving text-to-sql eval. methodology,” in Proc. of the 56th Annu. Meeting of the Assoc. for Comput. Linguistics (Vol. 1: Long Papers), pp. 351–360, July 2018.
V. Zhong, C. Xiong, and R. Socher, “Seq2sql: Generating struct. queries from natural lang. using reinforcement learning,” CoRR, vol. abs/1709.00103, 2017.
T. Yu, R. Zhang, K. Yang, M. Yasunaga, D. Wang, Z. Li, J. Ma, I. Li, Q. Yao, S. Roman, et al., “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task,” in Proc. of the 2018 Conf. on Empirical Methods in Natural Lang. Process., pp. 3911–3921, 2018.
X. Xu, C. Liu, and D. Song, “Sqlnet: Generating structured queries from natural lang. without reinforcement learning,” CoRR, vol. abs/1711.04436, 2017.
Daya Guo, Yibo Sun, Duyu Tang, Nan Duan, Jian Yin, Hong Chi, James Cao, Peng Chen and Ming Zhou. Question Generation from SQL Queries Improves Neural Semantic Parsing. 2018. EMNLP.
T. Yu, R. Zhang, M. Yasunaga, Y. C. Tan, X. V. Lin, S. Li, H. Er, I. Li, B. Pang, T. Chen, et al., “Sparc: Cross-domain semantic parsing in context,” in Proc. of the 57th Annu. Meeting of the Assoc. for Comput. Linguistics, pp. 4511–4523, 2019.
T. Yu, R. Zhang, H. Er, S. Li, E. Xue, B. Pang, X. V. Lin, Y. C. Tan, T. Shi, Z. Li, et al., “Cosql: A conversational text-to-sql challenge towards cross-domain natural language interfaces to databases,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Lang. Process. and the 9th Int. Joint Conf. on Natural Lang. Process., pp. 1962–1979, 2019.
L Wang,A Zhang,K Wu,K Sun,H Wang.,“DuSQL: A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset”,EMNLP, 2020.
Jiaqi Guo, Ziliang Si,Yu Wang, Qian Liu, Ming Fan† Jian-Guang Lou, Zijiang Yang and Ting Liu, CHASE: A Large-Scale and Pragmatic Chinese Dataset for Cross-Database Context-Dependent Text-to-SQL, ACL, 2021
W Hwang,Yim, Jinyeong,S Park,M Seo, A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization, 2019
Z Dong,S Sun,H Liu,JG Lou,D Zhang, Data-Anonymous Encoding for Text-to-SQL Generation,(EMNLP-IJCNLP) 2019
B Bogin,M Gardner,J Berant, Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing, 2019
Ben Bogin, Matt Gardner, Jonathan Berant. Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing. ACL,2019
Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, Matthew Richardson. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. ACL, 2020
P Yin,G Neubig,WT Yih,S Riedel. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. 2020
T Yu,CS Wu,XV Lin,B Wang,C Xiong. GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing. 2020
Victor Zhong, Caiming Xiong, Richard Socher. Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR. 2017
Yibo Sun, Duyu Tang, Nan Duan etc. Semantic Parsing with Syntax- and Table-Aware SQL Generation. ACL. 2018
Li Dong, Mirella Lapata. Coarse-to-Fine Decoding for Neural Semantic Parsing . ACL. 2018
Tao Yu, Zifan Li, Zilin Zhang, Rui Zhang, Dragomir Radev. TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation NAACL. 2018
Wonseok Hwang, Jinyeong Yim, SeungHyun Park, Mnjoon Seo. Achieving 90% accuracy in WikiSQL. CoRR. 2019
Pengcheng He, Yi Mao, Kaushik Chakrabarti, Weizhu Chen. X-SQL: Reinforce Context Into Schema Representation . CoRR. 2019
Pengcheng Yin, Graham Neubig. TRANX: A Transition-based Neural Abstract Syntax Parser for Semantic Parsing and Code Generation. EMNLP 2018
Maxim Rabinovich, Mitchell Stern, Dan Klein. Abstract syntax networks for code generation and semantic parsing . ACL. 2017
Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, Dongmei Zhang. Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation. ACL. 2019
Ben Bogin, Matt Gardner, Jonathan Berant. Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing. ACL2019
Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, Matthew Richardson. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers . ACL. 2020
T Yu,M Yasunaga,K Yang,R Zhang,D Wang,Z Li,D Radev. SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task. 2018
J Ma,Z Yan,S Pang,Y Zhang,J Shen. Mention Extraction and Linking for SQL Query Generation. emnlp. 2020
Yan Z, Ma J, Zhang Y, et al. SQL Generation via Machine Reading Comprehension[C]. Proceedings of the 28th International Conference on Computational Linguistics. 2020
C Finegan-Dollak,Kummerfeld, Jonathan K,L Zhang,K Ramanathan,S Sadasivam,R Zhang,D Radev, “Improving text-to-sql eval. methodology,” in Proc. of the 56th Annu. Meeting of the Assoc. for Comput. Linguistics (Vol. 1: Long Papers), pp. 351–360, July 2018.
V. Zhong, C. Xiong, and R. Socher, “Seq2sql: Generating struct. queries from natural lang. using reinforcement learning,” CoRR, vol. abs/1709.00103, 2017.
T. Yu, R. Zhang, K. Yang, M. Yasunaga, D. Wang, Z. Li, J. Ma, I. Li, Q. Yao, S. Roman, et al., “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task,” in Proc. of the 2018 Conf. on Empirical Methods in Natural Lang. Process., pp. 3911–3921, 2018.

















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









