







评估假设:Evaluating a hypothesis
Training/testing procedure for linear regression
 Training/testing procedure for logistic regression
Training/testing procedure for logistic regression

模型选择
Model selection and training/validation/test
sets
模型选择(model selection)
可以依据训练误差和测试误差来评估假设
h
θ
(
x
)
h_\theta(x)
hθ(x);
一般来说,我们将数据集划分成训练集(60%)Train set、验证集(20%)交叉验证集Cross validation set和测试集(20%)test set;
在训练集上我们学习参数 θ : minJ(θ);
计算训练误差、验证误差:
 for linear regression:
for linear regression:
J
t
r
a
i
n
(
θ
)
=
1
2
m
t
r
a
i
n
∑
i
=
1
m
t
r
a
i
n
(
h
θ
(
x
t
r
a
i
n
(
i
)
)
−
y
t
r
a
i
n
(
i
)
)
2
J_{train}(\theta)=\frac{1}{2m_{train}} \sum_{i=1}^{m_{train}}(h_\theta(x_{train}^{(i)})-y_{train}^{(i)})^2
Jtrain(θ)=2mtrain1i=1∑mtrain(hθ(xtrain(i))−ytrain(i))2
J
c
v
(
θ
)
=
1
2
m
c
v
∑
i
=
1
m
c
v
(
h
θ
(
x
c
v
(
i
)
)
−
y
c
v
(
i
)
)
2
J_{cv}(\theta)=\frac{1}{2m_{cv}} \sum_{i=1}^{m_{cv}}(h_\theta(x_{cv}^{(i)})-y_{cv}^{(i)})^2
Jcv(θ)=2mcv1i=1∑mcv(hθ(xcv(i))−ycv(i))2
for logistic regression:
J
t
r
a
i
n
(
θ
)
=
−
1
m
t
r
a
i
n
∑
i
=
1
m
t
r
a
i
n
(
y
t
r
a
i
n
(
i
)
log
(
h
θ
(
x
t
r
a
i
n
(
i
)
)
)
+
(
1
−
y
t
r
a
i
n
(
i
)
)
log
(
1
−
h
θ
(
x
t
r
a
i
n
(
i
)
)
)
)
J_{train}(\theta)=-\frac{1}{m_{train}}\sum_{i=1}^{m_{train}}(y_{train}^{(i)}\log(h_\theta(x_{train}^{(i)}))+(1-y_{train}^{(i)})\log(1-h_\theta(x_{train}^{(i)})))
Jtrain(θ)=−mtrain1i=1∑mtrain(ytrain(i)log(hθ(xtrain(i)))+(1−ytrain(i))log(1−hθ(xtrain(i))))
J
c
v
(
θ
)
=
−
1
m
c
v
∑
i
=
1
m
c
v
(
y
c
v
(
i
)
log
(
h
θ
(
x
c
v
(
i
)
)
)
+
(
1
−
y
c
v
(
i
)
)
log
(
1
−
h
θ
(
x
c
v
(
i
)
)
)
)
J_{cv}(\theta)=-\frac{1}{m_{cv}}\sum_{i=1}^{m_{cv}}(y_{cv}^{(i)}\log(h_\theta(x_{cv}^{(i)}))+(1-y_{cv}^{(i)})\log(1-h_\theta(x_{cv}^{(i)})))
Jcv(θ)=−mcv1i=1∑mcv(ycv(i)log(hθ(xcv(i)))+(1−ycv(i))log(1−hθ(xcv(i))))
选择
J
c
v
(
θ
)
J_{cv}(\theta)
Jcv(θ)最小的模型;
计算测试误差
J
t
e
s
t
(
θ
)
J_{test}(\theta)
Jtest(θ) ;

对于逻辑回归还可以计算误分类率:
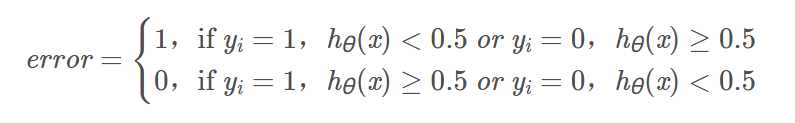
诊断方差和偏差:Diagnosing bias vs variance
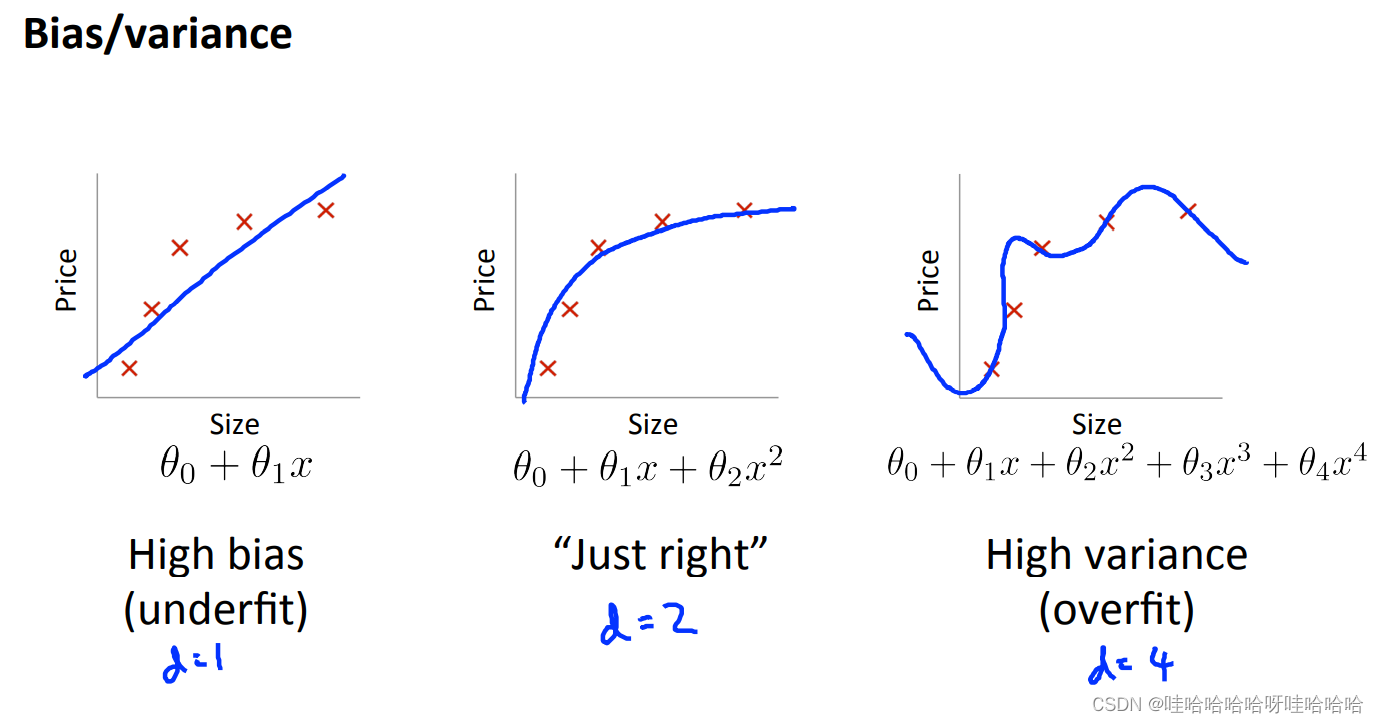 一般来说,欠拟合会产生高偏差;过拟合过产生高方差;
一般来说,欠拟合会产生高偏差;过拟合过产生高方差;
具体来说,当模型欠拟合时,训练误差和验证误差都会较大;当模型过拟合时,训练误差很小,然而验证误差很大,如下图:
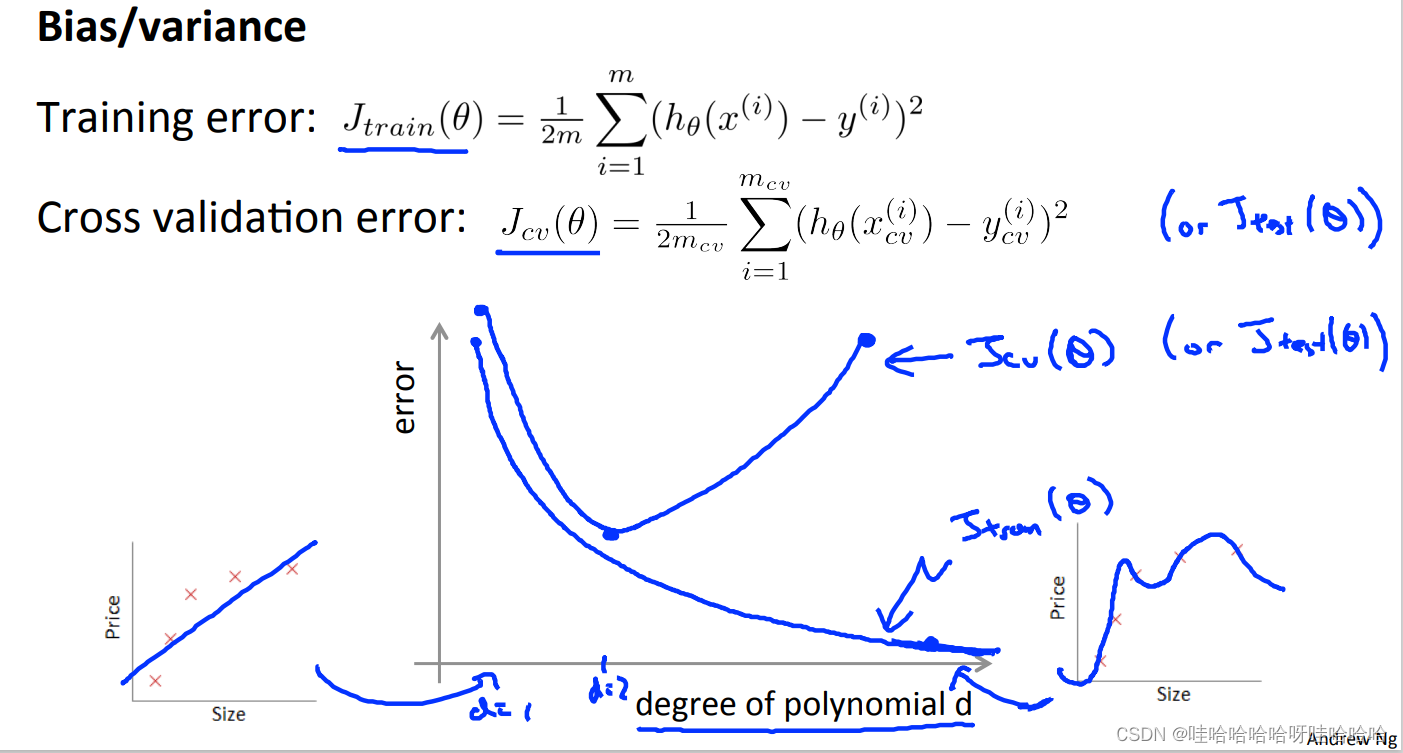

正规化和偏差方差
如何处理高方差和高偏差问题呢?
一般来说,加入合适的正则化项可以有效地避免过拟合。
当正则化参数 λ \lambda λ较大时,
θ
j
≈
0
\theta_j\approx0
θj≈0 (除
θ
0
\theta_0
θ0 外),假设函数趋于直线,因而会造成高偏差的问题,导致欠拟合;
当正则化参数 λ较小时,正则化项不起作用,模型会变得过拟合。
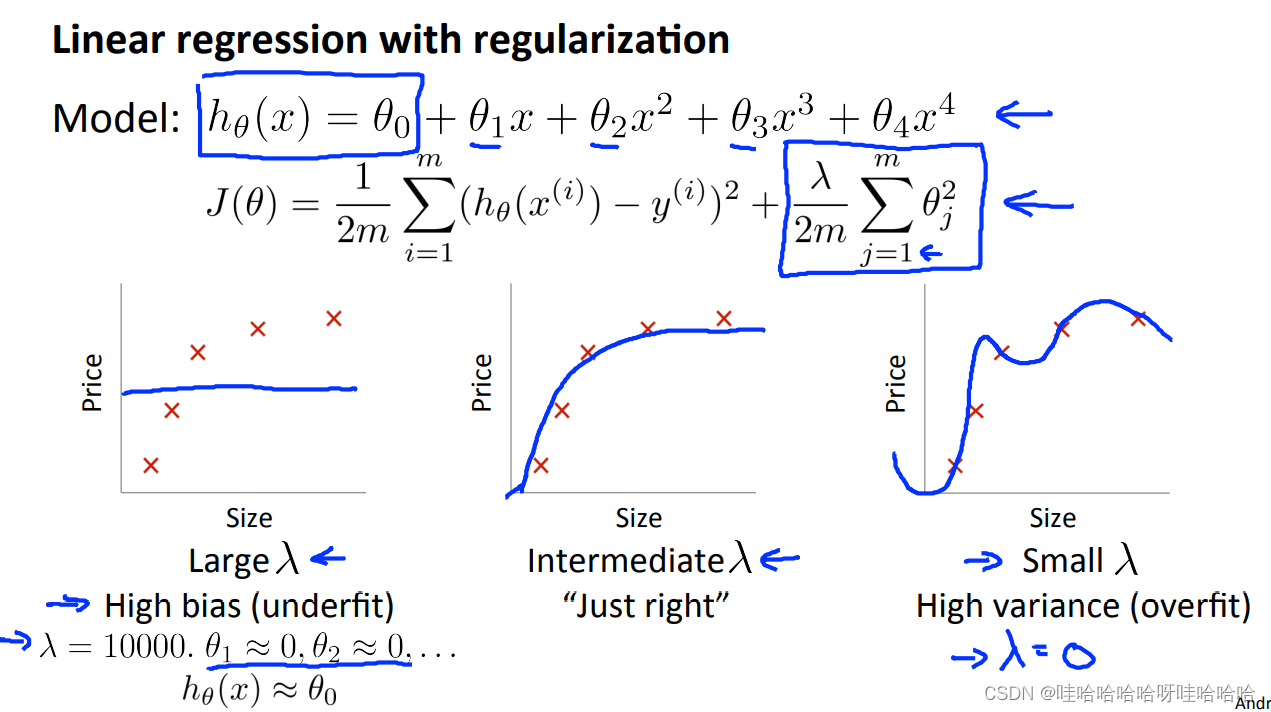
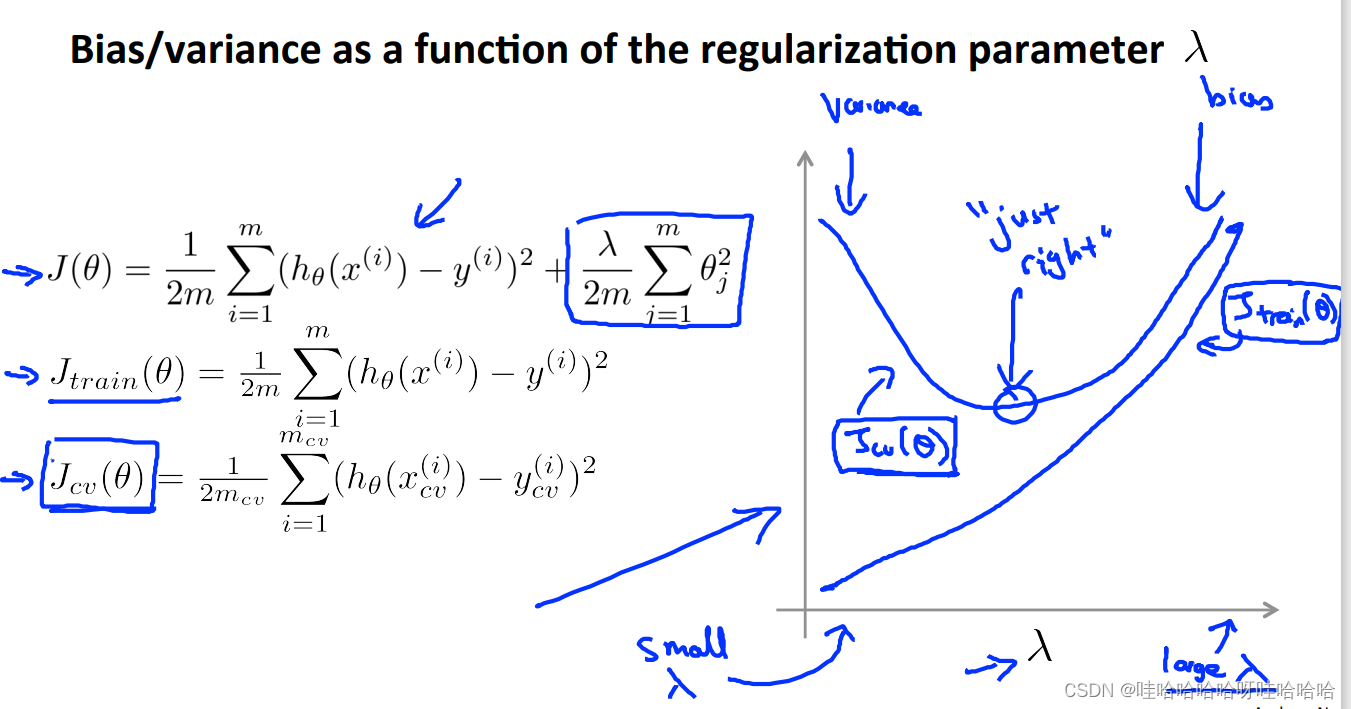 一般的,对于高偏差问题(欠拟合):
一般的,对于高偏差问题(欠拟合):
增加特征个数
增加多项式特征
降低 λ
对于高方差问题(过拟合):
增加训练样本
减少特征个数
增加 λ
对于神经网络来说,参数越少,越有可能欠拟合;参数越多,网络结构越复杂,越有可能过拟合,应该加入正则化项。
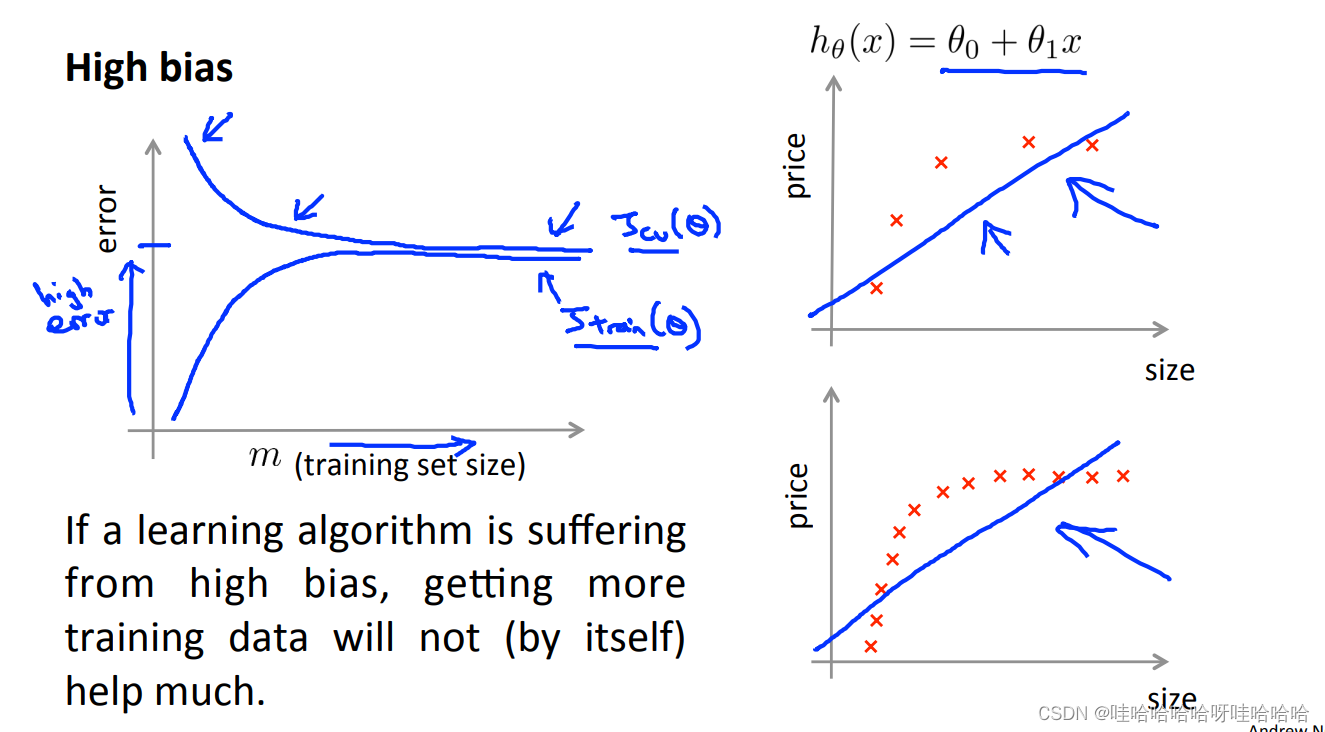
学习曲线:Learning curves
高偏差,增加训练样本,交叉验证误差不会明显下降,基本变成平的,对改善算法没有益处。
参数少,数据多,m很大的时候,训练集误差和交叉验证集误差将会非常接近。
高方差,在训练误差和交叉验证误差之间有很大的差距。增加训练样本,交叉验证误差将会降低,对改进算法有好处。
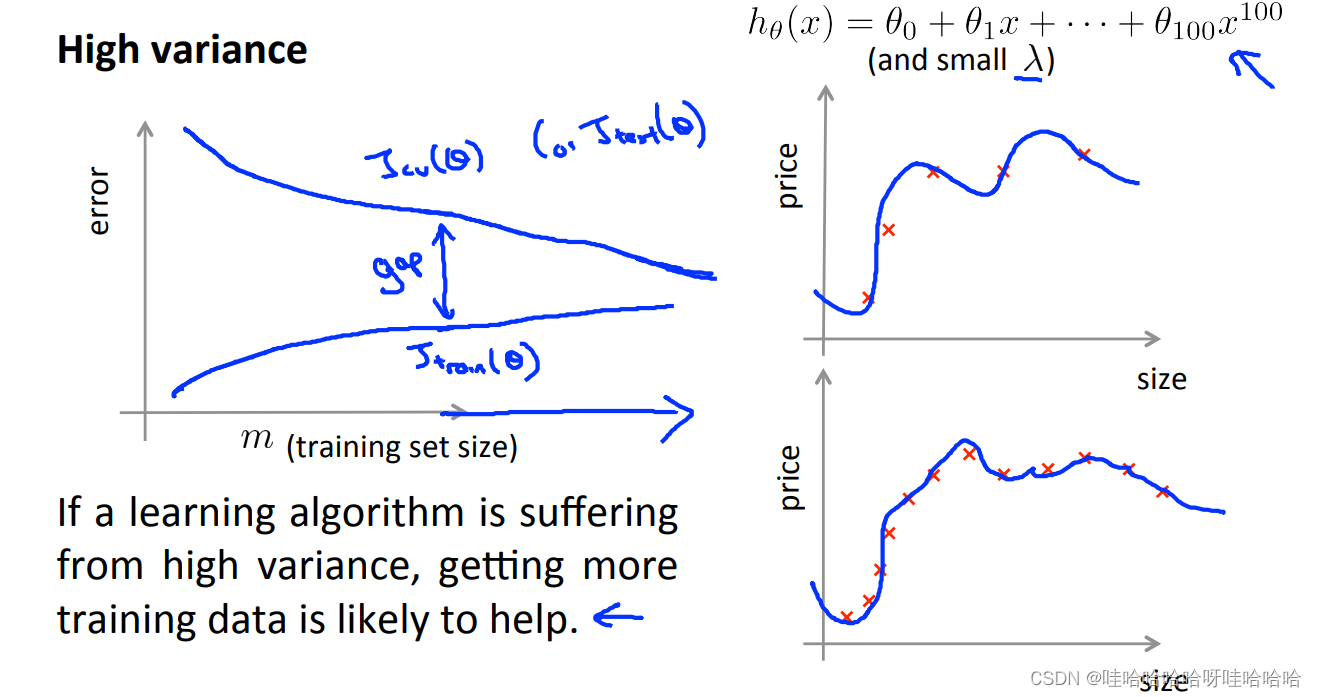
改进算法

参考链接:https://blog.csdn.net/qq_29317617/article/details/86312154














 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









