







1.准备语料
准备好自己的语料。保存为txt格式,每行一个句子,分好词,并以空格进行分割(" “.join(seg1))
2.代码
从GitHub下载代码斯坦福训练Glove
将corpus.txt放入GloVe的主文件下。
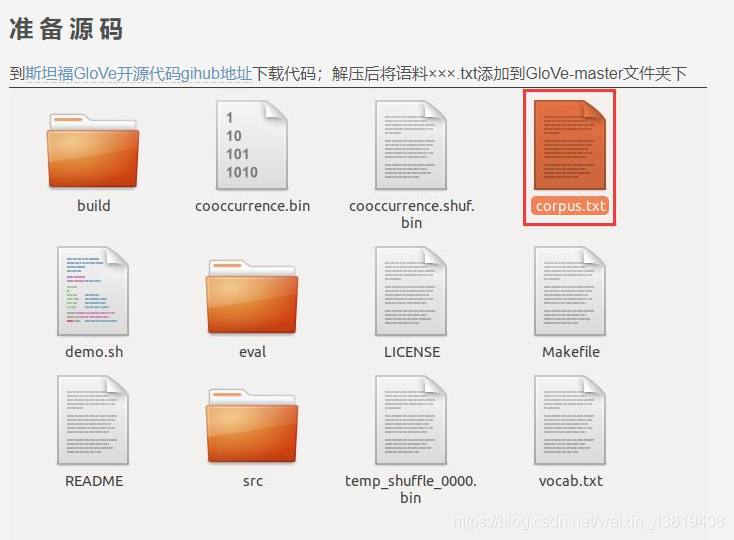
3.修改文件
(1)将上述demo.sh文件中的"make"下的内容注释掉(源码是下载text8语料文件)
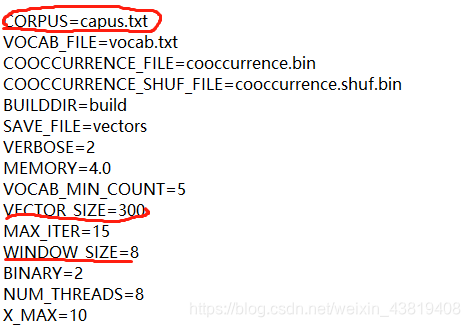
(2)修改下图中三个地方的内容(300,8)效果要好(据说)
CORPUS=text8 要生成词向量的文本 VOCAB_FILE=vocab.txt 得到的词和词频 COOCCURRENCE_FILE=cooccurrence.bin COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin BUILDDIR=build SAVE_FILE=vectors VERBOSE=2 MEMORY=4.0 内存 VOCAB_MIN_COUNT=5 最小词频数 VECTOR_SIZE=50 词向量维度 MAX_ITER=15 训练迭代次数 WINDOW_SIZE=15 上下文窗口数 BINARY=2 保存文件类型(2进制) NUM_THREADS=8 线程数 X_MAX=10
4.训练词向量
(1)进入主文件下:“make”
(2)然后”./demo.sh"
之后会生成vectors.txt和vectors.bin文件
5.将vectors.txt文件修改成Gensim可以使用的文件
在文件的额第一行加入vacob_size空格vector_size,这样才能用word2vec的load函数加载成功
我的数据:178633 50
参考文章:添加链接描述















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









