







1、明确目标
本次目标是利用BeautifulSoup,爬取http://t.icesmall.cn/网站下一本完整小说。
Beautiful Soup 4.4.0 文档地址https://beautifulsoup.readthedocs.io/zh_CN/latest/#beautifulsoup
2、网页分析
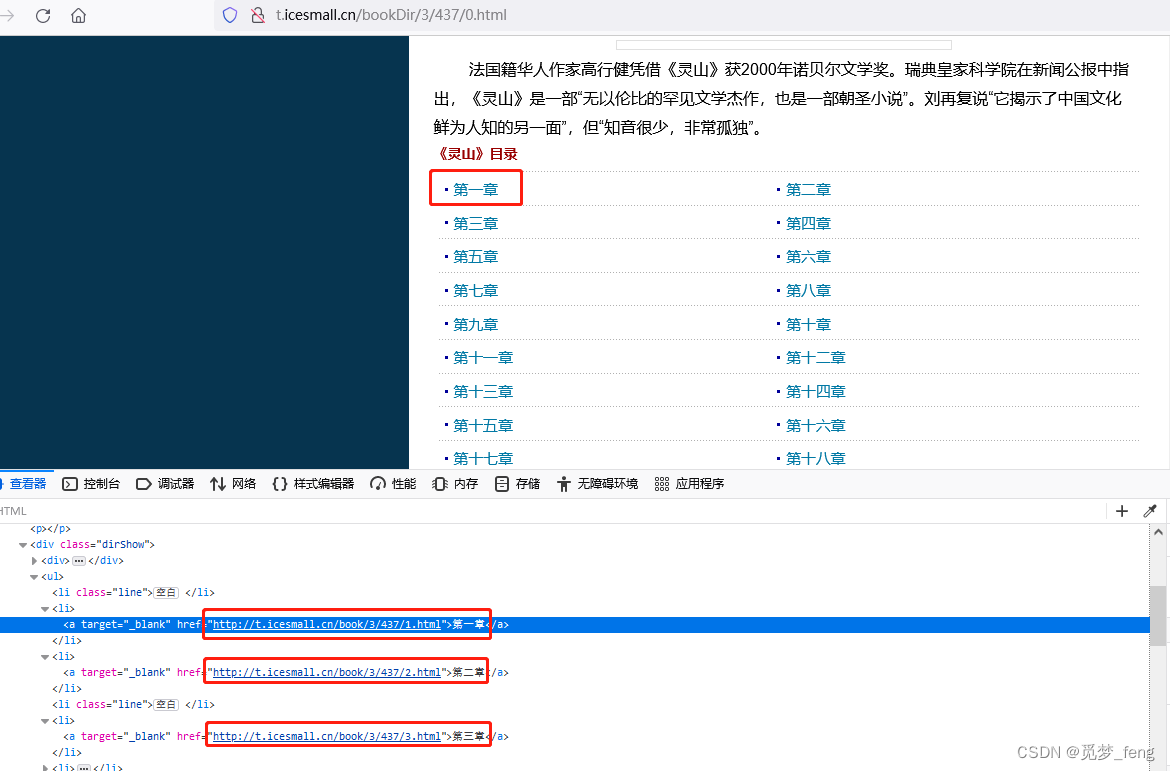
小说目录页面,有每一章节的名称及章节地址,全都在 < li > 标签中,获取所有的章节地址,一次访问一整本小说。
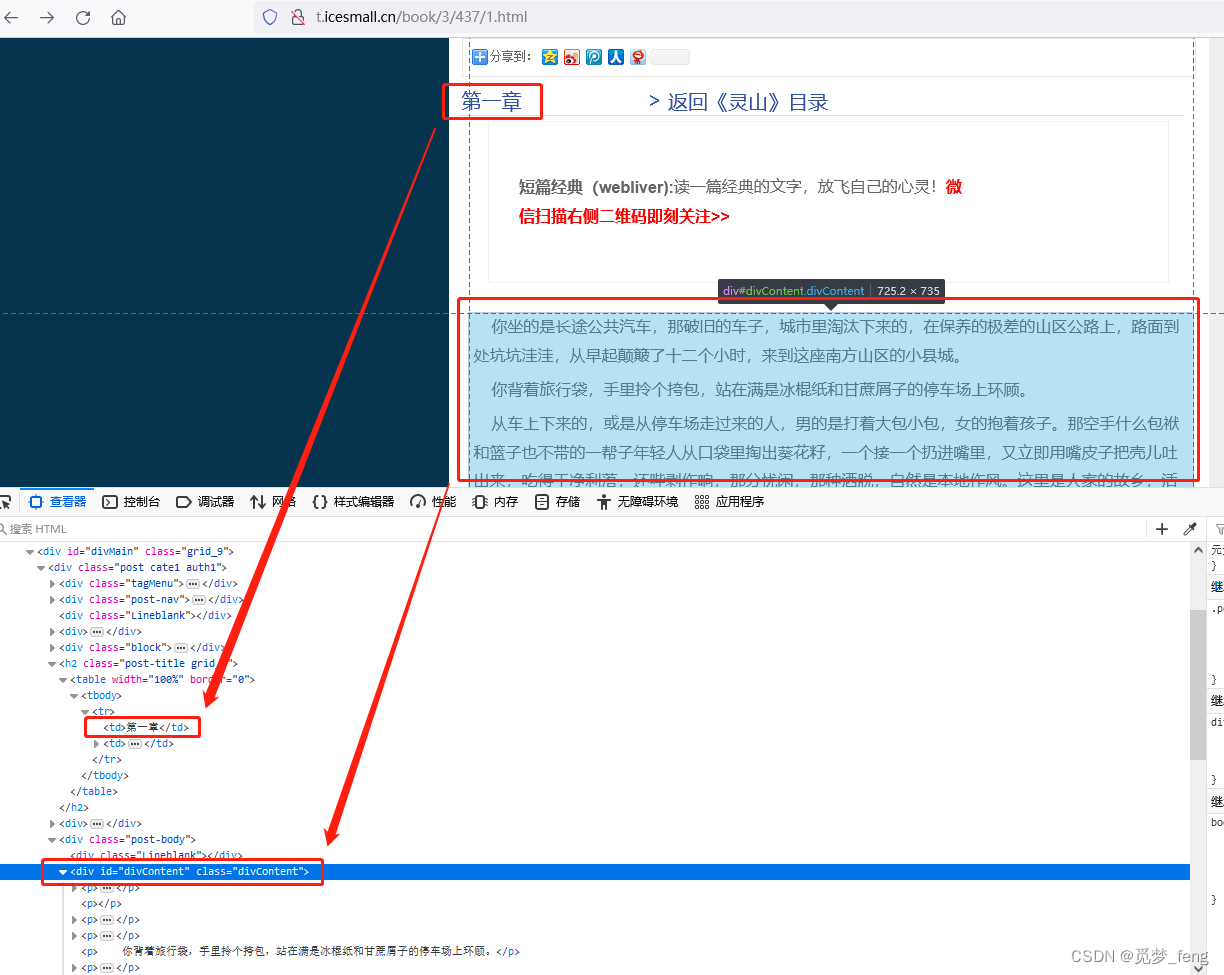
小说内容页面,章节名称位于class="post-title grid_6"下面 < td > 标签中。小说正文位于id="divContent"下面 < p > 标签中。
思路:
1、先访问小说目录,获取书名与章节地址。
2、遍历访问章节地址,得到每章名称与内容。
3、将名称与内容写入TXT。
3、代码编写
导入BeautifulSoup解析网页,requests请求网页,random生成随机数,time等待时间,re正则匹配
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
import random
import time
import re
def sleeptime():
'''随机等待'''
b = random.uniform(0.5,2) # 随机数
print(f'等待{b}秒')
time.sleep(b) # 把随机取出的整数值传到等待函数中
def gethtml(url):
'''抓取页面内容'''
header = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0' }
try:
xs = requests.get(url=url, headers=header)
except Exception as result: # Exception捕获异常
print(url + '访问出错了')
print(result)
xs.encoding='utf-8' #中文编码
blog = xs.text
soup = BeautifulSoup(blog, "html.parser") #用 html.parser 解析 html
return soup
def mulu(url):
'''根据目录页面,获取章节地址'''
urls=[] #存放章节地址
global book #声明该处使用全局变量
soup = gethtml(url)
book = re.findall(r'《(.*)》', soup.title.string) #匹配《》书名
book = book[0] + '.txt' #书名文件格式
zj = soup.find(class_="post-body").find_all('a')
for l in zj:
urls.append(l.get('href')) #获取章节地址
return urls
def xs(url,book):
'''写入小说'''
soup = gethtml(url) #访问章节
link = soup.find(class_="post-title grid_6").find("td").text #章节名
nr = soup.find('div',id="Content").stripped_strings #查找小说内容标签
with open(f'{book}', 'a', encoding='utf-8')as p1:
p1.write('\n' + link + '\n\n') # 写入章节名
for x in nr:
p1.write(' '+x+ '\n\n') #写入小说内容
print(link+'------>下载完成')
def main(mlurl):
'''主函数'''
urls = mulu(mlurl) #获取章节
for i in range(len(urls)): #遍历章节
sleeptime() #随机等待
xs(url=urls[i],book=book) #写入小说
print('-' * 40 + '\n\t\t\t\t下载完成\n' + '-' * 40)
if __name__ == '__main__':
main('http://t.icesmall.cn/bookDir/3/437/0.html') #目录页面
结果:

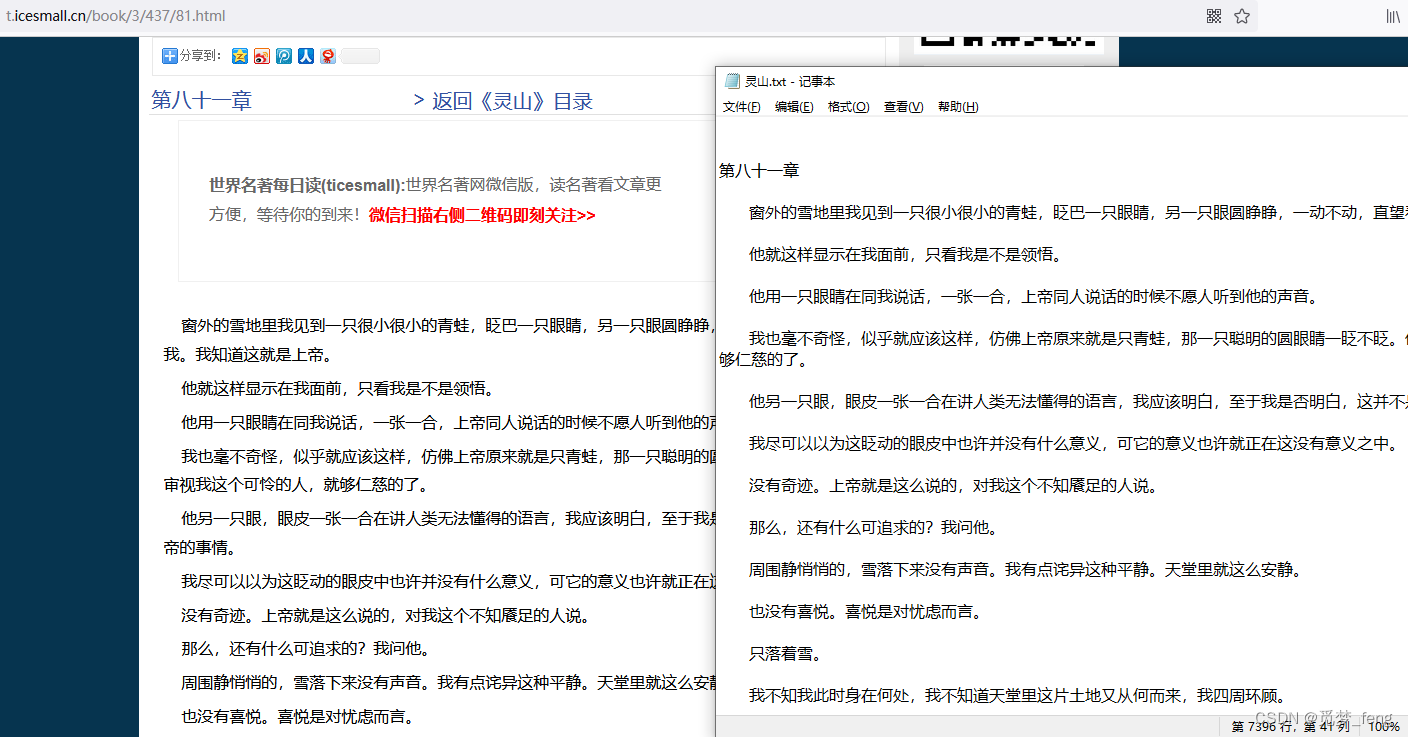
















 2370
2370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











