







Flink API的抽象级别
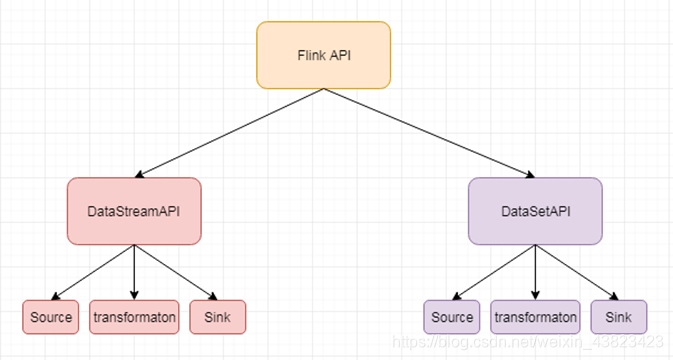
1、概述
source是程序的数据源输入,你可以通过StreamExecutionEnvironment.addSource(sourceFunction)来为你的程序添加一个source。
flink提供了大量的已经实现好的source方法,你也可以自定义source
通过实现sourceFunction接口来自定义无并行度的source,或者你也可以通过实现ParallelSourceFunction 接口 or 继承RichParallelSourceFunction 来自定义有并行度的source。
2、分类
1)基于文件
readTextFile(path)
读取文本文件,文件遵循TextInputFormat 读取规则,逐行读取并返回。
2)基于socket
socketTextStream
从socker中读取数据,元素可以通过一个分隔符切开。
3)基于集合
fromCollection(Collection)
通过java 的collection集合创建一个数据流,集合中的所有元素必须是相同类型的。
4)自定义输入
addSource 可以实现读取第三方数据源的数据
系统内置提供了一批connectors,连接器会提供对应的source支持【kafka】
内置Connectors
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache ActiveMQ (source/sink)
- Redis (sink)
下面以kafka作为source来演示:
目的:获取kafka中的输入,然后进行输出
package qyl.study.streaming
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
/**
* Created by qyl on 2019/03/23.
*/
object StreamingKafkaSourceScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换(必须要导入,否则会报错)
import org.apache.flink.api.scala._
//checkpoint配置
env.enableCheckpointing(5000);
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig.setCheckpointTimeout(60000);
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置statebackend
//env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop100:9000/flink/checkpoints",true));
val topic = "t1"
val prop = new Properties()
prop.setProperty("bootstrap.servers","hadoop110:9092")
prop.setProperty("group.id","con1")
//获取kafka的输入的数据
val myConsumer = new FlinkKafkaConsumer011[String](topic,new SimpleStringSchema(),prop)
//使用addsource,将kafka的输入转变为datastream
val text = env.addSource(myConsumer)
//将输入的数据输出
text.print()
env.execute("StreamingFromCollectionScala")
}
}依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.3</version>
</dependency>
3、Source 容错性保证
| Source | 语义保证 | 备注 |
| kafka | exactly once(仅一次) | 建议使用0.10及以上 |
| Collections | exactly once |
|
| Files | exactly once |
|
| Socktes | at most once |
|
4、自定义Source
1、两种情况:
1、实现并行度为1的自定义source
- 实现SourceFunction
- 一般不需要实现容错性保证
- 处理好cancel方法(cancel应用的时候,这个方法会被调用)
2、实现并行化的自定义source
- 实现ParallelSourceFunction
- 或者继承RichParallelSourceFunction
- 注意:继承RichParallelSourceFunction的那些SourceFunction意味着它们都是并行执行的并且可能有一些资源需要open/close
2、实现代码
需求 :
- 创建自定义并行度为1的source
- 实现从1开始产生递增数字
实现代码1:
package qyl.study.streaming.custormSource
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
/**
* Created by qyl on 2019/03/23.
*/
class MyNoParallelSourceScala extends SourceFunction[Long]{
var count = 1L
var isRunning = true
override def run(ctx: SourceContext[Long]) = {
while(isRunning){
ctx.collect(count)
count+=1
Thread.sleep(1000)
}
}
override def cancel() = {
isRunning = false
}
}实现代码2:
package qyl.study.streaming.custormSource
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
/**
*
* Created by qyl on 2019/03/23.
*/
class MyParallelSourceScala extends ParallelSourceFunction[Long]{
var count = 1L
var isRunning = true
override def run(ctx: SourceContext[Long]) = {
while(isRunning){
ctx.collect(count)
count+=1
Thread.sleep(1000)
}
}
override def cancel() = {
isRunning = false
}
}














 2175
2175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









