







西瓜书笔记:模型选择与评估(1)
1.经验误差vs 泛化误差
经验误差:在训练集上的误差–对应训练集上的误差
泛化误差:在未来样本上的误差-对应测试集数据
验证集–用来训练模型的超参数(模型本身是有参数的,但在训练的过程中有些参数是训练不到的)
2.混淆矩阵得到的评价指标
Recall、Precision、Accracy、F1、Auc(用一张图可以清楚展示他们的区别)
PS:AUC就是ROC曲线下的面积
3.偏差和方差
Bias(偏差):期望值和实际值的差值
Variance(方差)
4.整览西瓜书后,方知其精辟
※ 模型越复杂,模型拟合能力越强,偏差逐渐变小,容易过拟合。
※ 模型越复杂,可能性就会越多,方差越大。
5.其他参考资料
《统计学习方法》1.4-1.6
《百面机器学习》2
b站视频讲解
6.总结
声明:一般情况下,不是全部适用

7 测试集分割
① 3、7分,2、8分
② 测试集分割留出法:注意训练集和测试集的分布,进行多次随机划分,训练出多个模型,取平均值
③ k折交叉验证法:缺点:数据量较大时,对算力要求较高。
④ 自助法:缺点,:会引起估计偏差
8.调参与最终模型
(1)GredSearchCV
GredSearchCV网格搜索用于选取模型的最优超参数,与交叉验证相辅相成。

sklearn库中GredSearchCV各个参数的含义
使用示例:

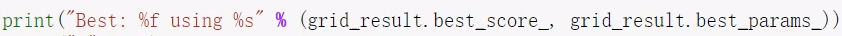
(2)贝叶斯优化(速度快)
贝叶斯优化问题有四个部分:
1.目标函数:我们想要最小化的内容,在这里,目标函数是机器学习模型使用该组超参数在验证集上的损失。
2.域空间:要搜索的超参数的取值范围
3.优化算法:构造替代函数并选择下一个超参数值进行评估的方法。
4.结果历史记录:来自目标函数评估的存储结果,包括超参数和验证集上的损失
实战参考















 8864
8864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









