









本次学习基于**零基础入门数据挖掘 - 二手车交易价格预测**比赛。
本人使用的学习资料请见:https://github.com/datawhalechina/team-learning
1.数据下载
首先在官网下载数据包,下载的数据包分为两大类
- 训练集—15w条数据
- 测试集A—5w条数据

另外平台有测试集B(5w条数据)对你提交后的代码进行评估
2.数据读取
通过Pandas对于数据进行读取
#sep 分隔符参数
Train_data=pd.read_csv('G:/OutStudying/DataScience/Data/used_car_train_20200313/used_car_train_20200313.csv',sep=' ')
TestA_data=pd.read_csv('G:/OutStudying/DataScience/Data/used_car_testA_20200313/used_car_testA_20200313.csv',sep=' ')
#shape函数 返回矩阵的行数跟列数
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)
使用相应的函数查看数据的基本信息
# 1)数据简要预览
print(Train_data.head())
# 2) 数据信息查看
##通过.info()简要看到一些数据列名,以及NAN缺失信息
print(Train_data.info())
##通过.columns 查看列名
print(Train_data.columns)
# 3)数据统计信息浏览
print(Train_data.describe())
3.特征与标签构建
本次题目主要是预测二手车的交易价格,则我们可以简单的理解为
- 自变量:除价格外的其他因素
- 因变量:交易价格
因为自变量因素有太多,我们先主观的进行筛选,去除关联不大的因素(后续进行修正与改进会再补全),再将其他自变量因素写入一个矩阵,并将其数据分离开来:
#获取所有的列名 即自变量名称
numerical_cols=Train_data.select_dtypes(exclude='object').columns
print(numerical_cols)
categorical_cols=Train_data.select_dtypes(include='object').columns
print(categorical_cols)
##选择特征列
#这个是进行特定列名筛选
feature_cols=[col for col in numerical_cols if col not in ['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller'] ]
print(feature_cols)
#将不带Type字样的留下为最终要进行分析的列名即自变量
feature_cols=[col for col in feature_cols if 'Type' not in col]
print(feature_cols)
现在feature_cols中则为部分部分自变量:
v_1— v_14 : 匿名自变量
['gearbox', 'power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14']
将相关自变量的训练样本跟测试样本进行分离,将因变量训练样本进行分离:
#提前特征列,标签列构造训练样本和测试样本
X_data=Train_data[feature_cols]
X_test=TestA_data[feature_cols]
#price 是因变量(本身题目要求预测价格变化)
Y_data=Train_data['price']
4.模型训练与预测
所采用的方法主要为: 五折交叉检验
交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。
五折交叉检验:
就是将数据随机分成五部分,每一次有四个作为训练集,剩余一个作为验证集,并且互相交替。
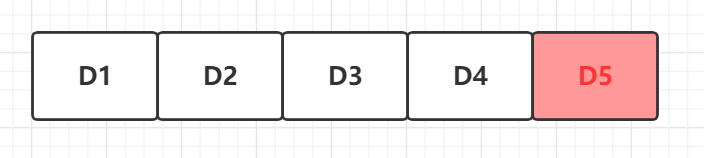
其中白色为训练集,红色为验证集 然后进行五次取平均为最终结果:

代码如下:
## xgb-Model
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'
scores_train = []
scores = []
## 5折交叉验证方式
sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
for train_ind,val_ind in sk.split(X_data,Y_data):
train_x=X_data.iloc[train_ind].values
train_y=Y_data.iloc[train_ind]
val_x=X_data.iloc[val_ind].values
val_y=Y_data.iloc[val_ind]
xgr.fit(train_x,train_y)
pred_train_xgb=xgr.predict(train_x)
pred_xgb=xgr.predict(val_x)
score_train = mean_absolute_error(train_y,pred_train_xgb)
scores_train.append(score_train)
score = mean_absolute_error(val_y,pred_xgb)
scores.append(score)
print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))
谢谢大家观看!















 1707
1707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









