







Flow
Flow 分为两种一种是 冷流 ,一种是热流。
冷流
冷流采用是订阅者与发布者是一一对应关系,数据只会给目标订阅者发送,不会发送给其他订阅者
只有订阅者订阅后,发布者才会生产数据
使用emit()方法来发送元素,并使用collect()方法来消费元素。
emit() 和 collect() 都是挂起函数,所以肯定需要在协成作用域下使用。
冷流的基本使用
fun main() {
//定义一个流,处理数据是Int,通过flow{}创建冷流
var flow : Flow<Int> = flow {
//流内部可以做多个耗时操作,包括 suspend 等挂起函数,然后把通过emit数据发送出去
//但是flow{}内部只能相同协成作用域,不能切换
delay(100)
emit(1)
delay(100)
emit(2)
}
runBlocking{
//当调用 flow 的 collect 方法上面的flow{}内的代码才会启动。才会生成数据和发射数据,这个机制默认是冷流的机制
// collect是个挂起函数,需要在协程作用域下才可以使用,而上面流的定义不需要在协程作用域下
flow.collect{
println(it)
}
// 而调用多次的 collect 上面的 flow{}内代码就会多次调用互不干扰
//这就是冷流的机制,相当于,调用 一次 flow.collect{}就是 一个创造 订阅者,并且再创造一个发送者, 发送者跟订阅者都是一对一,
//也就是这里创建了两个订阅者监听者 flow.collect{},以及;两个生产者,一对一 的关系 ,他们之间没有任何关系,数据不会共享
flow.collect{
println(it)
}
}
//想要取消流的 collect 就是取消掉流对应的协程
coroutineScope.cancel()
}
注意 flow.collect的协程跟 flow {}内协程不是同一个,
当调用 flow.collect ,会拿当前 collect 的协程作用域 再 开启一个协程去做 flow {}内的事情,每当调用一次就会 在再开启一个协程去做 flow {}内的事情,
而在上面这段代码中, flow.collect 与 flow {} 内,协程不是同一个,但是线程是同一个的。
flow {} 大部分都是在耗时操作,如果你希望改变 flow {}内的线程,就是调用 flowOn 去切换
flow {}内的线程。
另外flow {} 内发送的数据必须来自同一个协程内,不允许来自多个CoroutineContext,所以默认不能在flow{}中创建新协程或通过withContext()切换线程。如需切换上游的CoroutineContext,可以通过flowOn()进行切换
flow 会有很多的操作符,会做很多操作,如果你想对指定的操作做线程切换 需要在指定的操作符后面
再 调用flowOn , flowOn不会改变 调用 flowOn之后的操作或Flow的收集的线程, 它是改变Flow中调用flowOn之前的操作。
创建flow的方式
- flowOf(里面存放数据)
flowOf(1,2,3,4,5)
.onEach {
delay(100)
}
.collect{
println(it)
}
- 对一个list 对象 , asFlow() 成为一个flow对象
listOf(1, 2, 3, 4, 5).asFlow()
.onEach {
delay(100)
}.collect {
println(it)
}
- callbackFlow:将基于回调的 APi 转换为Flow数据流。
这句话的理解是这样的,我们直接看例子
// 这里是个监听listener,或者 Callback
interface MyCallback {
fun onDataReceived(data: String)
}
// 这里有个简单的类,我们把他叫做数据源
class DataProduct {
// 也就是 在这个普通的类里, 创建了一个 listener,或者 Callback
private var callback: MyCallback? = null
fun registerCallback(callback: MyCallback) {
this.callback = callback
}
fun unregisterCallback() {
this.callback = null
}
//当这个类获取到数据的时候,我们希望把这个数据传给 listener,或者 Callback
fun fetchData() {
// 假设这是一个异步操作,比如从网络获取数据
// 当数据准备好时,我们调用回调
val data = "Hello from Callback API!"
callback?.onDataReceived(data)
}
}
很多时候我们都有上的代码,也就是类会设置一个监听获取callback,当产生数据会把数据传给监听器,,或者 Callback,这个时候我们可以利用 callbackFlow{}进行封装 ,也就是当 监听器收到数据的时候,把数据转成flow
fun main() {
// 你可以理解为 callbackFlow{} 只是个模块分装,他的目的是提前把监听器设置到数据源里,然后当监听器收到数据的时候 ,
//调用 trySend 把数据转成flow中
fun callbackBasedApiToFlow(): Flow<String> = callbackFlow {
//在callbackFlow {}创建监听 MyCallback 实例对象
val callback = object : MyCallback {
override fun onDataReceived(data: String) {
// 当数据通过回调接收时,调用trySend 把数据转成flow
trySend(data)
}
}
//创建普通类
val dataProduct = DataProduct()
//注册监听器
dataProduct.registerCallback(callback) // 注册回调以开始接收数据
// 当Flow被取消时,我们需要确保取消回调的注册
awaitClose {
dataProduct.unregisterCallback()
}
}
// 然后这里开着一个协程 调用挂起函数 collect 。也就是他一直会等待着数据的发送然后接收到这个数据
//其实就是一直在等待 普通类产生数据,也就是监听器监听到数据,也是监听器一监听到数据这里就会收到
runBlocking {
// 将基于回调的API转换为Flow并收集数据
callbackBasedApiToFlow().collect { data ->
println("Received data: $data")
}
}
// 后续,如果这个普通类 获取到数据 ,就会把数据传给监听器 listener,或者 Callback,上面的协程就能收到数据了
val dataProduct = DataProduct()
dataProduct.fetchData()
}
冷流的数据发送和接收顺序
正因为 emit() 和 collect() 都是挂起函数
想要emit 是需要等 collect上一个数据做完,也就是需要等待 collect{} 内代码做完
那么emit后的代码才会继续走,也就是再继续下发下一个数据
runBlocking {
var flow = flow<Int> {
for (i in 1..5) {
println("开始发送 $i 数据 ")
emit(i)
println("发送数据 $i 后 ")
}
}
launch {
flow.collect {
//在这里消费速度每一次都延迟5s
delay(5000)
println("收到处理数据 $it")
}
}
}
日志打印如下:
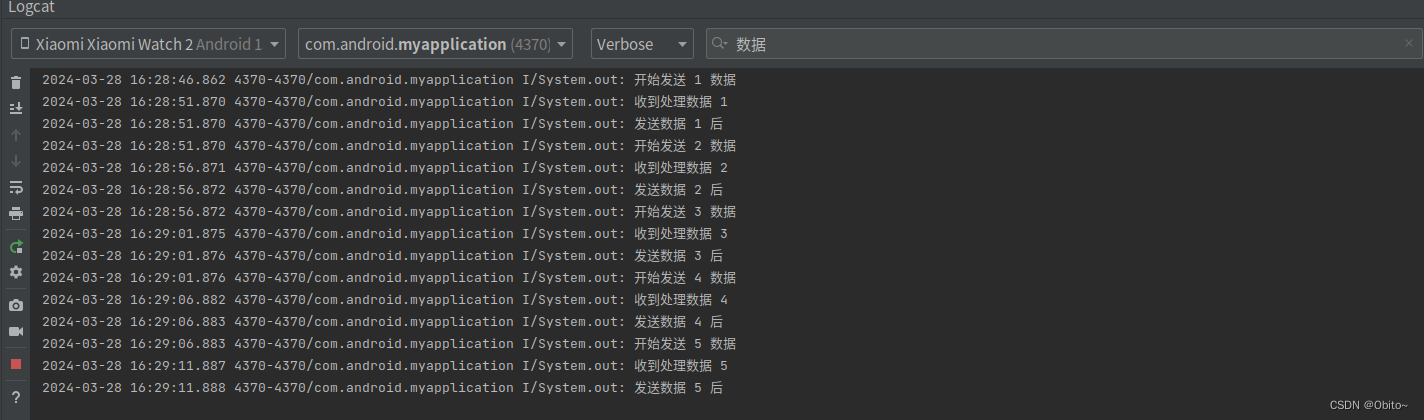
按上面的日志,开始发送1后,collect{} 先延迟了5s 才收到数据,而得等到 collect{}代码做完,
emit(i) 后的代码也就是这句 println("发送数据 1 后 ") 才开始打印,然后才开始发送下一个数据
然后再过5s, 得等到 collect{}代码做完, emit(i) 后的代码也就是这句 println("发送数据 2 后 ") 才开始打印,然后才开始发送下一个数据
也就是当调用 emit 数据后,需要等到 collect{} 的代码都做完,然后 emit 函数后面的代码才会再执行
流的链式调用与执行顺序
flow {
log("send hello")
emit("hello") //发送数据
log("send world")
emit("world") //发送数据
}.flowOn(Dispatchers.IO)
.onEmpty { log("onEmpty") }
.onStart { log("onStart") }
.onEach { log("onEach: $it") }
.onCompletion { log("onCompletion") }
.catch { exception -> exception.message?.let { log(it) } }
.collect {
//接收数据流
log("collect: $it")
}
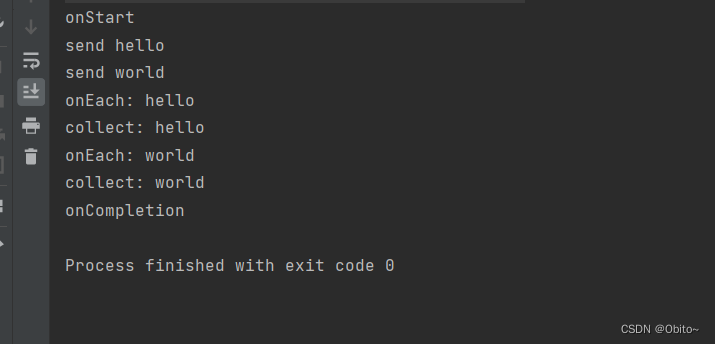
注意这里的 onCompletion 方法,就算是过程中出现了异常,onCompletion 方法也会被调用的
在上面的代码中,我们说 flowOn不会改变 调用 flowOn之后的操作或Flow的收集的线程, 它是改变Flow中调用flowOn之前的操作 。我们可以做个验证
runBlocking {
flow {
println("send hello")
emit("hello") //发送数据
println("send world")
emit("world") //发送数据
println("flow {}内的线程: ${Thread.currentThread().id}")
}
.flowOn(Dispatchers.IO)
.onEmpty {
println("onEmpty")
println("onEmpty :${Thread.currentThread().id}")
}
.onStart {
println("onStart")
println(" onStart : ${Thread.currentThread().id}")}
.onEach {
println("onEach: $it")
println(" onEach : ${Thread.currentThread().id}")}
.onCompletion {
println("onCompletion")
println(" onCompletion :${ Thread.currentThread().id}")}
.catch { exception -> exception.message?.let { println(it) } }
.collect {
//接收数据流
println("collect: $it")
println("collect :${Thread.currentThread().id}")
}
}
上面代码中 ,flowOn 比 onEmpty onEach先调用 ,所以 他们的线程都跟
flow{}不是同一个

而如果 ,flowOn 比 onEmpty onEach 后面 , onEmpty onEach 的线程就跟 flow {}是一个了
runBlocking {
flow {
println("send hello")
emit("hello") //发送数据
println("send world")
emit("world") //发送数据
println("flow {}内的线程: ${Thread.currentThread().id}")
}
.flowOn(Dispatchers.IO)
.onEmpty {
println("onEmpty")
println("onEmpty :${Thread.currentThread().id}")
}
.onStart {
println("onStart")
println(" onStart : ${Thread.currentThread().id}")}
.onEach {
println("onEach: $it")
println(" onEach : ${Thread.currentThread().id}")}
.onCompletion {
println("onCompletion")
println(" onCompletion :${ Thread.currentThread().id}")}
.catch { exception -> exception.message?.let { println(it) } }
.flowOn(Dispatchers.IO)
.collect {
//接收数据流
println("collect: $it")
println("collect :${Thread.currentThread().id}")
}
}

flowOn 方法在整个链路中是可以调用多次 ,每次调用代表flowOn 上面的属于指定的线程
private val mDispatcher = Executors.newSingleThreadExecutor().asCoroutineDispatcher()
fun main() = runBlocking {
(1..5).asFlow().onEach {
printWithThreadInfo("produce data: $it")
}.flowOn(Dispatchers.IO)
.map {
printWithThreadInfo("$it to String")
"String: $it"
}.flowOn(mDispatcher)
.onCompletion {
mDispatcher.close()
}
.collect {
printWithThreadInfo("collect: $it")
}
发射数据是在 Dispatchers.IO 线程执行的, map 操作时在我们自定义的线程池中进行的,collect 操作在 Dispatchers.Main 线程进行。
flow 常用操作符
- 重试操作符 retry retryWhen
重试操作符 retry 代表如果 在生产和收集过程一旦失败,就会进行重试,参数是重试的次数,
retry ()参数是重试次数,{}内是获取到异常的信息,如果{}括号内return true 代表重试条件达成,
也会重新调用 flow{} 内,如果再失败,会再尝试,直到次数用完
runBlocking {
//下面是1到5进行分发,如果是4 就会抛出异常
(1..5).asFlow().onEach {
if (it == 4) {
throw Exception("test exception")
}
delay(100)
println("produce data: $it")
//如果异常信息是 test exception 条件满足,那么重试2次,也就是上面 的flow{}内会做两次
}.retry(2) {
it.message == "test exception"
}.catch { ex ->
println("catch exception: ${ex.message}")
}.collect {
println("collect: $it")
}
}
retryWhen 操作符跟 retry 一样的,只是{}括号内的参数会有个当前重试次数
fun main() = runBlocking {
(1..5).asFlow().onEach {
if (it == 4) {
throw Exception("test exception")
}
delay(100)
println("produce data: $it")
// attempt 就是当前重试次数,{}内返回true 就会重试
}.retryWhen { cause, attempt ->
cause.message == "test exception" && attempt < 2
}.catch { ex ->
println("catch exception: ${ex.message}")
}.collect {
println("collect: $it")
}
- 转换操作符 map
其实就是对每个分发的数据在进行一次转换
fun main() = runBlocking {
(1..5).asFlow().map { "string: $it" }
.collect {
println(it)
}
}
- 转换操作符 transform
上面的 map 他是对flow的数据一个转成另外一个,并不需要再次调用emit去再次发送
而 transform 他的意思是,对 对每次flow的数据,都会调用 transform ,然后你可以在 transform
里面做数据转换,并且需要调用 emit发送转换后的数据,不管每次 transform 都可以调用 多次emit。
runBlocking {
(1..5).asFlow().transform {
//每次数据过来都进行转换,并且还不只发送一次
emit(it * 2)
//这里还发送了 string
emit("String: $it")
}
.collect {
println(it)
}
}
输出结果:
2
String: 1
4
String: 2
6
String: 3
8
String: 4
10
String: 5
- 过滤操作符 filter 对分发的每次数据,只有filter{}内条件满足true,才会发送
fun main() = runBlocking {
(1..5).asFlow()
.filter { it % 2 == 0 }
.collect { println(it) }
}
输出结果:
2
4
- 只取指定一部分数据的操作符 take
take 操作符只取前几个 emit 发射的值,参数是前面几个的意思
fun main() = runBlocking {
//只取前面2个
(1..5).asFlow().take(2).collect {
println(it)
}
}
输出结果:
1
2
- 对多个flow对象 进行合并成一个操作符 zip
zip 是可以将2个 flow 进行合并的操作符,其实就是遍历对2个flow的数据进行合并成一个然后再分发
fun main() = runBlocking {
val flowA = (1..5).asFlow()
val flowB = flowOf("one", "two", "three","four","five", "six", "seven").onEach { delay(200) }
flowA.zip(flowB) { a, b -> "$a and $b" }
.collect {
println(it)
}
}
- 合并操作符 combine
跟 zip 不太一样,zip, 肯定是对两个flow的数据,各自遍历一个位置对应一个相同位置 然后生成一个。但是 combine 他是 flowA 发出新的 item ,会将其与 flowB 的最新的 item,这就出现了时间问题比如 flowA 发 第一个数据a , 但是 flowB 发送很慢,还没有发送第一个数据 b,这个时候 flowA 已经发送第二个数据aa 了,但是 flowB 才发送一个数据 b,那么 aa 会跟b 结合成一个新的数据出去
fun main() = runBlocking {
val flowA = (1..5).asFlow().onEach { delay(100) }
val flowB = flowOf("one", "two", "three","four","five", "six", "seven").onEach { delay(200) }
flowA.combine(flowB) { a, b -> "$a and $b" }
.collect {
println(it)
}
}
输出结果:
1 and one
2 and one
3 and one
3 and two
4 and two
5 and two
5 and three
5 and four
5 and five
5 and six
5 and seven
- 合并flow,按顺序 操作符 flattenContact
其实就是对两个flow ,合成一个,但是,先发指定的一个flow的数据,然后再发另外一个flow的数据
fun main() = runBlocking {
val flowA = (1..5).asFlow()
val flowB = flowOf("one", "two", "three","four","five").onEach { delay(1000) }
// 两个流合成一个,不过先发 flowA的数据,再发 flowB 的
flowOf(flowA,flowB)
.flattenConcat()
.collect{ println(it) }
}
输出结果:
1
2
3
4
5
// delay 1000ms
one
// delay 1000ms
two
// delay 1000ms
three
// delay 1000ms
four
// delay 1000ms
five
- withTimeout
如何实现对异步任务设置超时操作,以避免长时间等待。可以使用withTimeout函数来实现限制时间超时操作。
fun fetchData(): Flow<Result> = flow {
try {
val data = withTimeout(5000) {
fetchDataFromNetwork()
}
emit(Result.Success(data))
} catch (e: TimeoutCancellationException) {
emit(Result.Error("Request timed out"))
} catch (e: Exception) {
emit(Result.Error("Failed to fetch data"))
}
}
在上述例子中,withTimeout(5000)表示设置超时时间为5秒,如果在规定时间内未完成异步任务,则抛出TimeoutCancellationException异常。
热流
上面说的都是冷流,得等到 flow.collect订阅数据设置监听,flow{}才会 调用产生数据发送数据,并且产生一个生产者,
多调用几次flow.collect就会多产生几个生产者,然后消费者跟生产者成为一对对消息发送接收
而热流不是这样的,生产者有数据就直接发送了,他不会管有没有设置监听者,也就是不需要等到调用flow.collect{}才可以发送数据
并且只有一个生产者, 也就是调用多次 flow.collect{} 不会多产生生产者, 发布端跟订阅者是一对多的关系,也是数据发送了, 谁有监听谁就可以接收到数据。
热流有两个一个是 SharedFlow,一个是StateFlow
SharedFlow
SharedFlow使用热流方式如下
fun main() {
runBlocking {
//创建 SharedFlow 热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 0,//接受慢的时候,已经发送未接受的数量
onBufferOverflow = BufferOverflow.SUSPEND//当发送速度大于接收的数据的背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
println("第一个监听者收集到的数据 $it")
}
}
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
println("第二个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
}
}
也就是在发送数据之前,设置了个监听,然后 后续发送数据就可以两个监听收到数据,形成一个生产者,多个监听者的情况
而如果发送完数据之后再设置监听,那么监听就不会收到
fun main() {
runBlocking {
//创建 SharedFlow 热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 0,//接受慢的时候,已经发送未接受的数量
onBufferOverflow = BufferOverflow.SUSPEND//当发送速度大于接收的数据的背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
//在这里等了1s 才设置第二个监听者,但是上面的数据已经发送了,所以第二个监听者他收到不到数据
//在加上上面的热流设置的粘性数据参数是0,所以最后就什么也不会收到
delay(1000)
launch {
sharedFlow.collect {
println("第二个监听者收集到的数据 $it")
}
}
}
}

由于上面的第二个监听者晚了1s才设置监听, 数据都发送了 而热流的参数 replay 和 extraBufferCapacity 都设置0所以肯定不会收到数据。
热流的发送和调用顺序
前面我们说冷流的调用顺序是: 当调用 emit 数据后,需要等到 collect{} 的代码都做完,然后 emit 函数后面的代码才会再执行,而热流不是这样的。
在热流 sharedFlow 的参数都设置0,并且背压都设置的默认 BufferOverflow.SUSPEND ,情况下
runBlocking {
//创建 SharedFlow 热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 0,//接受慢的时候,已经发送未接受的数量
onBufferOverflow = BufferOverflow.SUSPEND//当发送速度大于接收的数据的背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//延迟5s 在收到
delay(5000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
}
}
日志打印如下:
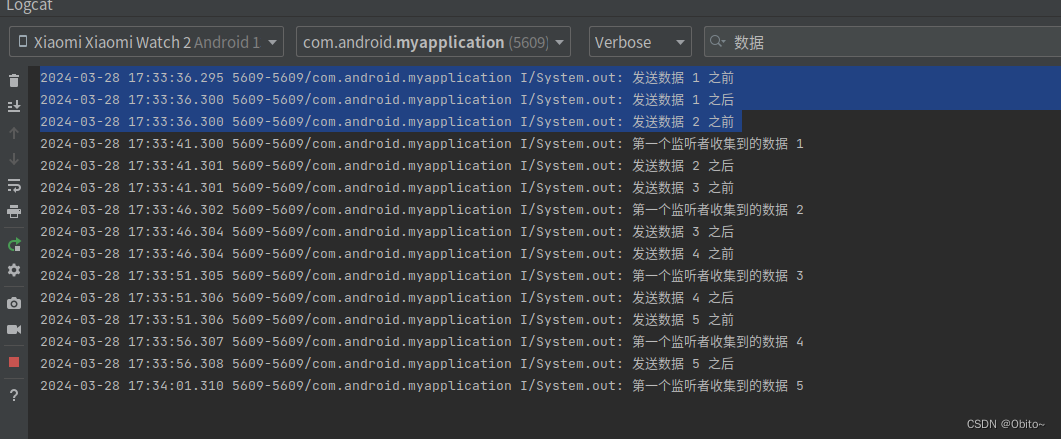
当发送者调用了emit了之后, emit 的后面代码 println("发送数据 1 之后 ") 还可以继续发,并且还在尝试继续 发送第二个数据
但是因为热流 参数设置为 BufferOverflow.SUSPEND//当发送速度大于接收的数据的背压策略,
这个策略的意思是,当消费者比生产者慢的时候,生产者要停下来,等消费者发完再继续下一个
如果没有这个参数设置,那么其实 生产者会不断的一直发送消息,根本不会理会消费者的情况,
也就是说对于热流来说,如果没有上面设置的3个参数,
那么对于生产者来说,他就是完全不管消费者,我就直接全部发送出去只顾我自己的逻辑,不管哪个消费者有没有收到,收到速度情况如何,
而对于冷流来说 当调用 emit 数据后,需要等到 collect{} 的代码都做完,然后 emit 函数后面的代码才会再执行
所以对于热流 SharedFlow 来说 3个参数很关键
现在我们分别对这3个参数进行解析.
- replay
上面我们说了 如果没有 上面设置的3个参数, 生产者会只顾自己发送消息,根本不会理会消费者的情况
public fun <T> MutableSharedFlow(
replay: Int = 0,
extraBufferCapacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): MutableSharedFlow<T>
replay: 事件粘滞数,不管发送有没有接收,他都会 保存着最后 发送的数据 ,
而设置的数量就是能存放多少数量。
replay的设置目的为了存放最后发送数据,好让下一个慢监听的监听者也能收到
比如说: 当设置 replay =2 的时候
当发送1 的时候, replay存储1,当发送2 的时候,存储1,2 当发送3,的时候存储,23,
当发送4,的时候,存储34,当发送5的时候,存储45
比如说上面的代码 中第二个监听他由于延迟了1s 才设置监听 ,如果把缓存 replay 改为2,那么当第二个监听者在设置监听的时候 就可以收到 最后两条数据4,5 数据,但是 1,2 ,3,依旧是收不到的
runBlocking {
//创建 SharedFlow 热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 2,//这里设置2
extraBufferCapacity = 0,//接受慢的时候,已经发送未接受的数量
onBufferOverflow = BufferOverflow.SUSPEND//当发送速度大于接收的数据的背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
delay(1000)
launch {
sharedFlow.collect {
println("第二个监听者收集到的数据 $it")
}
}
}
 最后两条数据4,5 数据,但是 1,2 ,3,依旧是收不到的
最后两条数据4,5 数据,但是 1,2 ,3,依旧是收不到的
上面的代码是 生产的速度= 消费速度 ,所以参数 onBufferOverflow = BufferOverflow.SUSPEND 没有意义
当 生产的速度> 消费速度. 参数 onBufferOverflow就会起作用了
也就是第三个参数 onBufferOverflow 就是在 生产的速度> 消费速度的时候才有意义
生产的速度> 消费速度的时候,我们管这叫做背压
注意,不管 生产的速度 消费速度 如何,如果没有 设置 onBufferOverflow 参数 ,那么 生产者默认只顾自己发,不会管消费者
onBufferOverflow 默认是 BufferOverflow.SUSPEND: 当发送速度大于接收的数据,那么会等待消费者上一个结束才会继续发送 下一个
再加上又设置了 参数 replay,
比如这样的代码:
runBlocking {
//创建热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 1,//设置1
extraBufferCapacity = 0,
onBufferOverflow = BufferOverflow.SUSPEND//背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
}

解释如下:
当发送1的时候, 由于监听者collcet 延迟了10s,所以还没收到数据 1,
而因为 onBufferOverflow 设置是 BufferOverflow.SUSPEND
所以,需要等带 消费者收到1之后才可以再允许继续发2,
但是 relay 设置了数量是1,也就是缓存池,所以在这种配合下,
会继续发送2 出去,把2 放在relay 中,然后想发送3 个时候,由于消费者还在延迟中
并且,relay 已经满了,所以发送不出去,需要等到10s 后,
监听者收到1,才可以发送3,但是这个3 并没有发送给出去,而是放在 relay 里面
真正发出去是原来relay的2,然后还想在继续4,但是因为 relay 已经满了,消费者还在收2 延迟中
所以发送不出去,以此类推。
也就是说, relay存放着最后发送的数据
怎么证明上面的观点, 或者说 你怎么知道 在每个时刻 relay就存放着你说的对应的数据,
我们说,relay就相当与粘性数据,他的作用就是,慢监听的人,在监听的时候能够收到,粘性数据。
那么我们在设置第二个监听,看看他收到的数据是不是跟我们说的上面一样
runBlocking {
//创建热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 1,//设置1
extraBufferCapacity = 0,
onBufferOverflow = BufferOverflow.SUSPEND//背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
//延迟1s的目标是为了后设置监听者,看看获取到数据是不是relay对应的
delay(1000)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
println("第二个监听者收集到的数据 $it")
}
}
}

- onBufferOverflow
上面的情况说的都是 onBufferOverflow 设置 BufferOverflow.SUSPEND 的情况
onBufferOverflow 还会有其他的参数,原本生产者就不会管监听者的情况,会一直发送,是因为参数设置了 BufferOverflow.SUSPEND才会被卡住,但是 BufferOverflow.SUSPEND 作用只是让发送者慢点发送, 接受者接收的数据一个不漏都有可以接收到
但是如果你设置了下面两个参数,生产者就会依旧不管监听者情况 依旧一直发送直到没有数据,并且接受者接收的数据会漏掉,不会全部接收
BufferOverflow.DROP_LATEST: 当缓存池数量已经满了,不会等待 消费者消费结束才可以发送下一个,可以发送,不过发送的新数据会直接丢弃,也就是消费者接受处理慢是他的事情,生产者只管发送,如果监听者慢了,在处理中耗时中,缓存池数量也满了
后续发送的新数据你直接接受不到
runBlocking {
//创建热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 1,//设置1
extraBufferCapacity = 0,
onBufferOverflow = BufferOverflow.DROP_LATEST//背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
}
日志输出如下:

当输出1的时候,消费者还在延迟,这个时候会把1放在relay里, 但是这个时候 ,消费者还在延迟
生产者不会管那么多,他只顾自己发送,当10s结束之后 数据,2,3,4,5直接发送完了,
消费者只能收到 1.也就是说当设置 BufferOverflow.DROP_LATEST 代表,如果缓存满了,
那么在消费者还没结束上一个之前, 发送的数据都会丢失
BufferOverflow.DROP_OLDEST : 当缓存池数量已经满了,不会等待 消费者消费结束才可以发送下一个,可以继续发,不过会把缓存池的数据废弃掉,新的数据替代缓存池里。Buffer 中只会存储最新的数据。不管较老的数据是否被消费,当 Buffer 已满而又有新的数据到达时,老数据都会从 Buffer 中移除,腾出空间让给新数据。
runBlocking {
//创建热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 1,//设置1
extraBufferCapacity = 0,
onBufferOverflow = BufferOverflow.DROP_OLDEST//背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
}

看上面的日志输出,发送者依旧是不会管消费者,直接只顾自己的发送逻辑
而因为参数是 DROP_OLDEST ,当缓存池满的时候,他会把发送的数据替换到缓存池,也就是最后监听者会收到最新的值,
而那些老的数据就不会收到。
- extraBufferCapacity参数
我们前面说 replay存放着最后发送的数据,而 extraBufferCapacity 代表,先发送几个事件,不管已经订阅的消费者是否接收。
上面我们说默认情况,当 replay 设置0. extraBufferCapacity 设置0. 背压参数设置 BufferOverflow.SUSPEND
在这种默认下是发送一个然后等到接收了,才可以在继续发送一个。
当在这基础上在设置 extraBufferCapacity=2 的情况下
runBlocking {
//创建热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//设置1
extraBufferCapacity = 2,
onBufferOverflow = BufferOverflow.SUSPEND//背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
}

也就是默认情况下,他 只能发送1出去,但是你多设置了 extraBufferCapacity = 2,。那么可以再多2个数据,也就是多发送,2,3
那么在这基础上在加上 replay=1
runBlocking {
//创建热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 1,//设置1
extraBufferCapacity = 2,
onBufferOverflow = BufferOverflow.SUSPEND//背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
}

你会发现多发送了4 ,也就是说
缓存数量其实是 replay + extraBufferCapacity。
而 replay + extraBufferCapacity 的关系是
如果 当 replay 满的时候, 会把 replay 里的数据放到 extraBufferCapacity,
然后发送的新数据再放到 replay,
而当所有的都满了, 如果 第三参数是 BufferOverflow.SUSPEND 就 得等待 消费者处理完,
发送者才可以继续发送, 消费者先 处理 extraBufferCapacity 里的数据,而原来 replay 的数据就放进到 extraBufferCapacity 里,
replay就再存放刚新发送的数据。
我们再对上面的3个参数进行总结
- 对于热流来说,如果没有上面3个参数,发送会直接顾自己发送,不会管任何接收者。
- 在1的基础上,如果再加上参数 BufferOverflow.SUSPEND,那么这种情况下,会需要等待一个消费者消费完,发送者才可以再继续发送,相当于发送一个接收一个。
- 在2的基础上如果,在加上参数 extraBufferCapacity。代表,当消费者发送接收慢的时候,发送者可以不管消费者,再多发送 extraBufferCapacity个数量的数据出去,相当于把这数据放在 extraBufferCapacity 池里。
- 缓存数量其实是 replay + extraBufferCapacity,也就是在消费者接收慢的时候,发送者可以多发送 replay + extraBufferCapacity 个数量出去. replay + extraBufferCapacity 的关系是
如果 当 replay 满的时候, 会把 replay 里的数据放到 extraBufferCapacity - 不管 replay + extraBufferCapacity怎么设计,只要背压参数是
BufferOverflow.SUSPEND,那么 先监听的消费者都是可以一个不漏的接收到数据,只是发送者可以先发送放在缓冲池里而已 - replay的目的是为了保存最后发送的数据,为了后面设置监听的数据能够获取。
- 当背压参数设置 DROP_LATEST或者 DROP_OLDEST 那么发送者将恢复原来的样子,只顾自己发送,不顾消费者接收, 那么这个时候,会出现接受者接收漏的情况,不会全部数据都接收, DROP_LATEST 代表如果缓冲池满了,那么后面发送的消息直接丢弃,让接受者后面的数据收不到 DROP_OLDEST代表如果缓冲池满了,那么个更换缓冲池的时候,缓冲池的数据丢弃,让接受者前面的数据收不到
热流 StateFlow
StateFlow 是一个 replay 设置1 , extraBufferCapacity 设置0 , onBufferOverflow 设置 BufferOverflow.DROP_OLDEST的 SharedFlow ,但是他比 SharedFlow 多的功能就是,
StateFlow 对象在初始化的时候,必须设置一个值,而且他的功能跟livedata 一样
可以setValue 和getValue
因为 StateFlow 设置的 onBufferOverflow 设置 BufferOverflow.DROP_OLDEST ,所以
消费者处理数据比生产者生产数据慢的情况,消费者来不及处理数据,就会把之前生产者发送的旧数据丢弃掉
我们看个简单的使用
fun main() {
// MutableStateFlow 定义的时候需要给个初始化值
var stateFlow = MutableStateFlow(0);
// MutableStateFlow 的赋值不需要在协程中
stateFlow.value =100
stateFlow.value =200
stateFlow.value =300
//可以获取到 MutableStateFlow 的最后一个值
var a = stateFlow.value
runBlocking {
//粘性事件所以后订阅的可以收到最后一个值
stateFlow.collect {
println("stateFlow: $it")
}
// 延迟2s 再设置相同的300,跟上面一个值一样,但是 collect 不会再次收到跟上次相同的值
delay(2000)
stateFlow.value =300
}
}
StateFlow 跟 livedata 的区别
-
StateFlow 必须在构建的时候传入初始值,LiveData 不需要;
-
StateFlow 默认是防抖的,LiveData 默认不防抖;
StateFlow 默认防抖:即如果发送的值与上次相同,则生产者并不会真正发送。
也就是这次发送的值跟上次一样那么不会发送,这点要注意,而livedata是什么值都会设置进去并且监听到数据 -
对于 Android 来说 StateFlow 默认没有和生命周期绑定,;
与 LiveData 相比 ,LiveData和 Activity 的生命周期绑定,默认不可见的时候会自动解注册监听
如果想要使用 StateFlow 也有像 LiveData 的这个功能,需要再加上
repeatOnLifecycle(Lifecycle.State.STARTED){}
class MainActivity: AppCompatActivity() {
private val mainViewModel = // getViewModel()
override fun onCreate(savedInstanceState: Bundle?) {
...
// Start a coroutine in the lifecycle scope
lifecycleScope.launch {
// repeatOnLifecycle launches the block in a new coroutine every time the
// lifecycle is in the STARTED state (or above) and cancels it when it's STOPPED.
repeatOnLifecycle(Lifecycle.State.STARTED) {
// Trigger the flow and start listening for values.
// Note that this happens when lifecycle is STARTED and stops
// collecting when the lifecycle is STOPPED
mainViewModel .uiState.collect { uiState ->
}
}
}
}
}
repeatOnLifecycle(Lifecycle.State.STARTED) 的作用就是每次进入 STARTED 可见状态时都会重新观察并收集数据;而在 STOPPED 状态时就会 通过取消掉协程 以此来取消掉 StateFlow 的collect
这就相当于livedata 根据生命周期自动设置监听和取消监听的效果
SharedFlow和StateFlow的侧重点
StateFlow就是一个replaySize=1的sharedFlow,同时它必须有一个初始值,此外,每次更新数据都会和上一次数据做一次比较,只有不同时候才会更新数值,所以数据不同监听者才会收到数据的改变
StateFlow重点在状态,ui永远有状态,所以StateFlow必须有初始值,同时对ui而言,过期的状态毫无意义,所以stateFLow永远更新最新的数据(和liveData相似),所以必须有粘滞度=1的粘滞事件,让ui状态保持到最新。另外由于参数是BufferOverflow.DROP_OLDEST ,所以
消费者处理数据比生产者生产数据慢的情况,消费者来不及处理数据,就会把之前生产者发送的旧数据丢弃掉,也就是会丢弃前面的数据而只收到最后的数据
SharedFlow侧重在事件,当某个事件触发,发送到队列之中,按照挂起或者非挂起、缓存策略等将事件发送到接受方,在具体使用时,SharedFlow更适合通知ui界面的一些事件,比如toast等,也适合作为viewModel和repository之间的桥梁用作数据的传输。
冷流转热流
我们前面说冷流的数据是只给一个消费者使用,
而如果当你的冷流对象需要数据也给多个消费者使用的话,就需要把他转换成热流。
就是通过 shareIn 和 stateIn 对应的就是转成 SharedFlow和StateFlow。
冷流转成热流的创建姿势
当一个冷流通过 shareIn 和 stateIn 都会创建一个新的数据流,也就是会创建一个新的实例对象
具体说就是 shareIn 会构建一个 ReadonlySharedFlow 实例;stateIn 则会构建一个 ReadonlyStateFlow 实例
//错误示例:不要通过函数去通过 shareIn 和 stateIn 获取一个热流,因为每次调用方法都会构建新的数据流实例对象
fun getUser(): Flow<User> =
userLocalDataSource.getUser()
.shareIn(scope, SharingStarted.WhileSubscribed())
//正确示例:在属性中去获取,这样只会创建一次新的数据流实例对象
val user: Flow<User> =
userLocalDataSource.getUser().shareIn(scope, SharingStarted.WhileSubscribed())
shareIn 转成 SharedFlow
我们先看 shareIn 转成 SharedFlow使用如下:
var coroutineScope: CoroutineScope = CoroutineScope(Dispatchers.IO+ SupervisorJob())
val sharedFlow = flow {
for (i in 0..5){
emit(i)
}
}.shareIn(scope = coroutineScope, started = SharingStarted.WhileSubscribed(5000), replay = 5)
coroutineScope.launch {
sharedFlow.collect{
println("第一个监听者收到数据 $it")
sharedFlow.collect{
println("第二个监听者收到数据 $it")
}
从上面的使用看 shareIn 方法 有3个 参数
public fun <T> Flow<T>.shareIn(
scope: CoroutineScope,
started: SharingStarted,
replay: Int = 0
): SharedFlow<T>
- 第一个 scope 参数,用于设置一个 协成CoroutineScope
作用域,注意其协成生命周期的长度需要比任何消费者都要长,这样才可以保证 消费者们的收集完数据结束前,协成不会被自己取消 - 第二个参数 started 代表热流的发送启动方式,官方提供有 3 种方式,下面一个个说:
-
SharingStarted.Eagerly :这个热流不等有人设置消费监听, 他就立马发送数据出去,
并且会一直发送不会停止,数据流会缓存最近的 replay 数据 -
SharingStarted.Lazily:这个热流 需要等第一个消费者出现设置了监听才会启动发送数据,并且会一直发送不会停止,数据流会缓存最近的 replay 数据
-
SharingStarted.WhileSubscribed():这个热流 需要等第一个消费者出现设置了监听才会启动发送数据,并且当最后一个监听消费者退出它就立即停止发送数据。
这个 SharingStarted.WhileSubscribed() 他是个函数,参数是默认值,我们可以自定义传入需要的参数
public fun WhileSubscribed(
stopTimeoutMillis: Long = 0,
replayExpirationMillis: Long = Long.MAX_VALUE
): SharingStarted =
StartedWhileSubscribed(stopTimeoutMillis, replayExpirationMillis)
stopTimeoutMillis:设置最后一个消费者退出后,多长时间后再关闭数据流。默认是 0,即立即关闭。
replayExpirationMillis:设置关闭流之后等待多长时间后,再重置清空缓存区 replay 的数据。默认是 Long.MAX_VALUE,即永远保存replay的数据
在实际使用中,建议使用 SharingStarted.WhileSubscribed(5000),即在最后一个消费者停止后再保持数据流 5 秒钟的活跃状态。避免在某些特定情况下(如配置改变——最常见就是横竖屏切换、暗夜模式切换)重启上游的数据流。
- 第三个参数 replay 粘性数据,默认是0
我们上面说我们单独创建一个热流的时候,也有对应的3个参数,分别是relay , extraBufferCapacity , 背压策略 onBufferOverflow
那么当我从一个冷流通过shareIn 转成热流SharedFlow,只有 relay 参数,那剩下那两个 extraBufferCapacity , 背压策略 onBufferOverflow 是什么没有指定的默认情况是什么。
我们打印下日志就知道了
var coroutineScope: CoroutineScope = CoroutineScope(Dispatchers.IO+ SupervisorJob())
var flow = flowOf(1,2,3,4,5)
val sharedFlow = flow {
for (i in 0..5){
println("发送数据 $i 之前")
emit(i)
println("发送数据 $i 之后")
}
}
.shareIn(scope = coroutineScope, started = SharingStarted.WhileSubscribed(), 1)
coroutineScope.launch {
sharedFlow.collect {
delay(1000)
println("第一个监听者收到数据 $it")
}
}
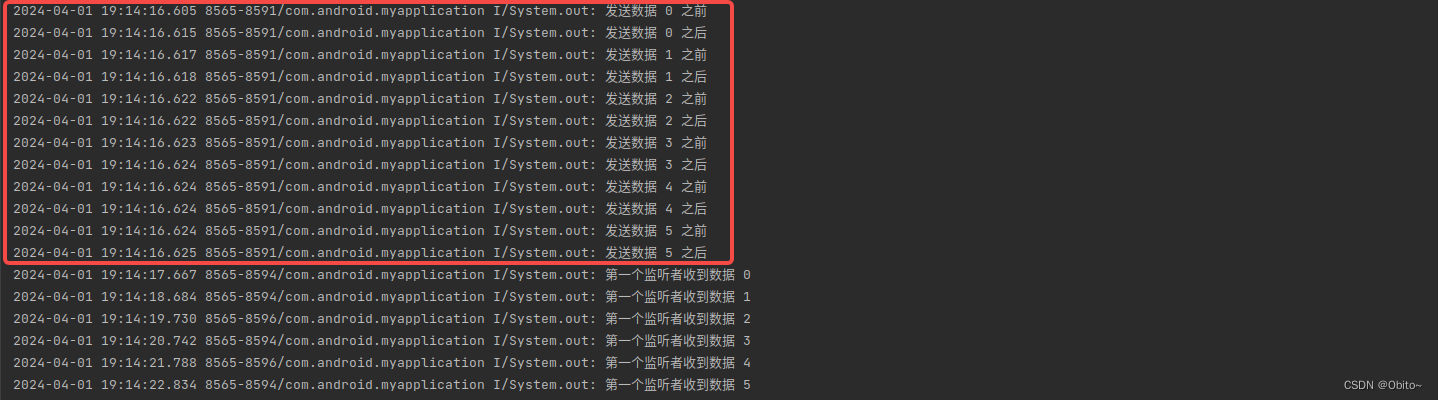
你会发现在默认情况下, 通过 shareIn 是转成的热流 SharedFlow
他就没有 extraBufferCapacity , 背压策略 onBufferOverflow 的概念,你可以理解为,就没有这两个参数的热流,也就是默认的热流就是只顾自己发送,不会管消费者的速度
而如果你想要再加上这个参数的作用,就是多添加一层操作符buffer,使用如下
var coroutineScope: CoroutineScope = CoroutineScope(Dispatchers.IO+ SupervisorJob())
var flow = flowOf(1,2,3,4,5)
val sharedFlow = flow {
for (i in 0..5){
println("发送数据 $i 之前")
emit(i)
println("发送数据 $i 之后")
}
//通过操作符设置 extraBufferCapacity , 背压策略 onBufferOverflow
}.buffer( 1, BufferOverflow.SUSPEND)
.shareIn(scope = coroutineScope, started = SharingStarted.WhileSubscribed(), 1)
coroutineScope.launch {
sharedFlow.collect {
delay(1000)
println("第一个监听者收到数据 $it")
}
}
因为这里 缓存数量设置了2 个 也就是 relay + extraBufferCapacity
那么就是可以发送3个,当发送第4个的时候,因为缓冲池满了,参数设置 BufferOverflow.SUSPEND,所以就会卡住
发送不了,得等消费者消费完才可以继续发

stateIn 转成 StateFlow
接着来看 stateIn 转成 StateFlow 使用如下
var coroutineScope: CoroutineScope = CoroutineScope(Dispatchers.IO+ SupervisorJob())
val stateFlow = flow {
for (i in 0..5){
emit(i)
}
}.stateIn(scope = coroutineScope, started = SharingStarted.WhileSubscribed(5000), initialValue = 0)
coroutineScope.launch {
stateFlow.collect{
println("第一个监听者收到数据 $it")
stateFlow.collect{
println("第二个监听者收到数据 $it")
}
}
因为 StateFlow 是 SharedFlow一个relay 设置1 的热流,所以他的参数不需要有 relay 去设置值,而是多一个 参数需要设置初始化值
public fun <T> Flow<T>.stateIn(
scope: CoroutineScope,
started: SharingStarted,
initialValue: T
): StateFlow<T> {
val config = configureSharing(1)
val state = MutableStateFlow(initialValue)
val job = scope.launchSharing(config.context, config.upstream, state, started, initialValue)
return ReadonlyStateFlow(state, job)
}
上面我们说 StateFlow 背压策略设置 BufferOverflow.DROP_OLDEST,relay 设置1
所以 通过 stateIn 转成的 StateFlow,他的背压策略默认就是BufferOverflow.DROP_OLDEST
也就是 发送者会不会自顾自己发送,而当发送的速度大于消费的数据的时候,
当缓冲池满了,旧数据会丢失,消费者只会接收新数据。

因为热流 StateFlow 设置默认参数是0 ,并且由于发送速度大于消费的数据的时候,
当缓冲池满了,旧数据会丢失,消费者只会接收新数据,也就是只会接收,一开始的默认参数0 ,还有最后的relay数据5,而剩下2,3,4 都会被丢失
额外知识
获取流的消费者的数量
使用 MutableSharedFlow 的 subscriptionCount 参数
获取流的消费者的数量
MutableSharedFlow 的 subscriptionCount 参数 并不是个Int值可以直接使用,
他其实是个 StateFlow,所以可以直接 MutableSharedFlow.subscriptionCount.value获取
runBlocking {
//创建热流对象,并设置对应的参数
val sharedFlow = MutableSharedFlow<Int>(
replay = 1,//设置1
extraBufferCapacity = 2,
onBufferOverflow = BufferOverflow.SUSPEND//背压策略
)
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第一个监听者收集到的数据 $it")
}
}
// 开启协成去设置 collect ,相当于设置监听数据
launch {
sharedFlow.collect {
//消费者延迟了10s 才接收,让生产的速度>消费
delay(10000)
println("第二个监听者收集到的数据 $it")
}
}
// 开启个协成去发送数据
launch {
//对一个数据进行遍历
(1..5).forEach {
println("发送数据 $it 之前 ")
//通过 sharedFlow.emit发送数据
sharedFlow.emit(it)
println("发送数据 $it 之后 ")
}
}
delay(1000)
println("消费者的数量 : ${ sharedFlow.subscriptionCount.value}")
}
}















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









