







1 概述
Ray是一个开源的统一框架,用于扩展AI和机器学习这种Python Application。它为并行处理提供了计算层,最大限度地降低了运行分布式独立服务和end-to-end机器学习工作流的复杂性。基本的架构如下:
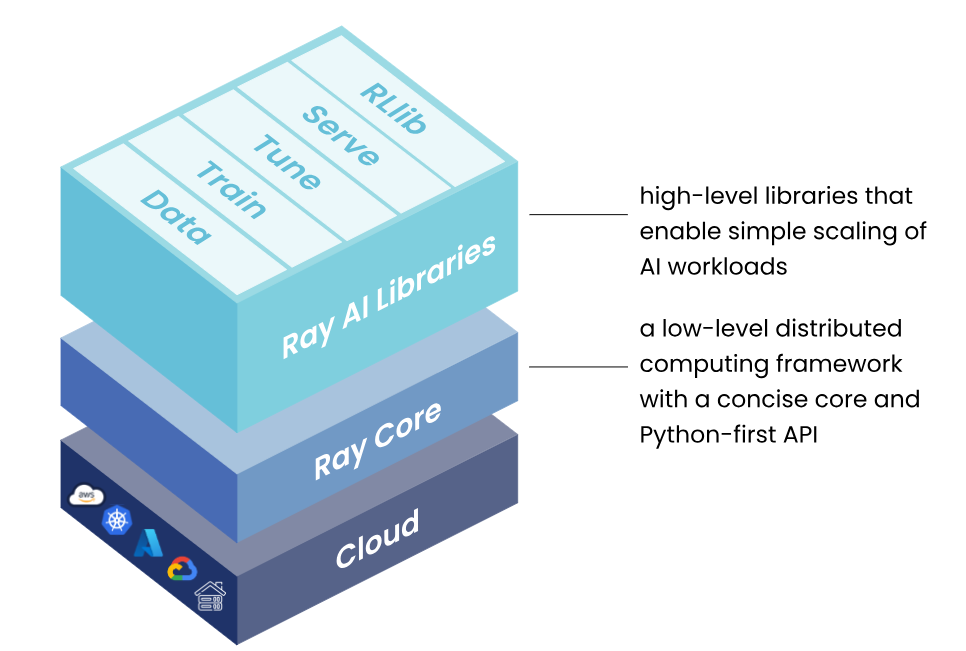
1.1 Ray AI Libraries
一组开源、Python、特定领域的库,为机器学习工程师、数据科学家和研究人员提供可扩展和统一的机器学习应用工具包。
-
Data: 可扩展的、与框架无关的数据加载和转换,涵盖训练、调优和预测。
-
Train: 分布式多节点和多核模型训练,具有容错性,与流行的训练库集成。
-
Tune: 可扩展的超参数调整,以优化模型性能。
-
Serve: 可扩展和可编程的服务,用于部署用于在线推理的模型,并可选择微批处理来提高性能。
-
RLlib: 可扩展的分布式强化学习工作负载。
对于数据科学家来说,这些库可用于扩展单个工作负载,以及end-to-end的机器学习应用程序。对于机器学习工程师来说,这些库提供了可扩展的平台抽象,可用于轻松整合和集成来自更广泛的机器学习生态系统的工具。
1.2 Ray Core
一个开源、Python、通用、分布式计算库,使机器学习工程师和Python开发人员能够扩展Python应用程序并加速机器学习工作负载。
对于自定义的Application(应用),Ray Core的库可以使Python开发人员能够轻松构建可扩展的分布式系统,这些系统可以在笔记本电脑、集群、云或Kubernetes上运行。这是构建Ray AI库和第三方集成(Ray生态系统)的基础。
1.3 Ray Clusters
一组连接到Ray Head 节点的Worker节点。Ray Cluster可以是固定大小的,也可以根据群集上运行的Application请求的资源进行集群自动缩放。
Ray可以运行在任何机器、集群、云服务商和K8S。更多的生态集成参考:The Ray Ecosystem — Ray 2.37.0
1.4 说明
此次调研的目标是结合Ray框架和应用的特点,找到RAG数据预处理服务和模型微调中数据处理服务结合Ray构建和提供服务的方式,也可以扩展到组内其他分布式服务是否可以使用Ray框架统一进行运行管理和构建。所以后面依次会介绍Ray Core中的核心概念,Ray应用概念(Ray Job、Ray Serve等),以及Ray Cluster的概念和不同部署方式的区别。
2 Ray Core
Ray Core中介绍Ray运行的基本概念,有助于理解Ray的基本原理。整体的概念如下图所示:
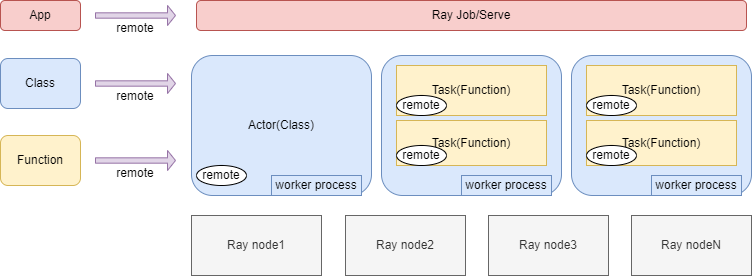
基于Ray Cluster运行的基础单元包括Actors、Tasks,以及基于Actor和Task可以封装的Application(Ray Job或者Ray Serve)。
基本说明:
1、一个Ray Cluster有多个节点(Node);
2、用户可以通过Ray的客户端或者API远程提交方法(Function)、类(Class)和应用(Application)到Ray Cluster中执行;
3、在Ray Cluster中,执行远程提交过来的Function叫Task,执行远程提交过来的Class叫Actor。Task和Actor是Ray中最基本的执行概念。远程提交的单个Application执行可以叫Ray Job,复杂的多Application执行叫Ray Serve。不过Application其实最终也是对多个Actor和Task的封装。
4、执行Task和Actor是使用的Ray Cluster上的worker process(进程),每一个Ray Worker就是一个ptyhon进程,用来执行用户远程提交的Actor和Task。但是worker process又分为两种:
-
当Ray Cluster启动的时候,每个Node上都会自动默认启动一些worker process(进程),这些worker process会用来执行用户提交的Task(有点像线程池),且worker process会被多个Task复用;
-
Actor不会使用默认的worker process,而是需要对每一个提交过来的Actor专门单独启动一个worker process给Actor使用,即Actor独占一个Worker process,只在Actor运行的时候才实例化。然后Actor中又可以执行多个Actor Tasks(调用Actor这个类的方法),这些Actor Tasks就在这个worker process上执行,而不会在别的worker process上执行。注意的一点:不像运行Tasks的worker process,这个Actor的worker process生命周期跟这个Actor是一样的,不会被其他Tasks或者Actor使用,当这个Actor被删除的时候,worker process也被删除了。
2.1 Tasks
Ray允许在Ray Node上的单独的 worker process上异步的执行任意方法(Function)。这些方法被称为Ray Remote Function,他们的异步调用被称为“Tasks”。Ray运行Task能够根据CPU、GPU和自定义资源指定其资源要求。集群调度器使用这些资源请求在集群中分配Task,以实现并行执行。具体的使用方法如下:
- 通过@ray.remote装饰器装饰方法,就会变成一个Remote方法,执行的时候直接使用.remote()方法执行即可
- 方法的参数传递:方法可以传递的参数值和对象引用,都是通过网络传递的,如果Task之间的输入值有依赖关系,会阻塞运行。
- 等待部分结果,对使用ay.get来获取task的执行结果,会导致程序被阻塞,直到任务完成执行。在启动多个任务后,如果想知道哪些任务已经完成执行,并且没有对所有任务进行阻塞。这可以通过ray.wait()来实现。
- 方法可以有多个返回,一个Ray Task可以返回多个结果对象引用,通过num_returns来设置结果返回的个数
- Task取消:可以通过ray.cancel(),传入返回的对象引用,来取消Task的执行
- 任务调度,参考ray调度实现,后面会详细说明
- 嵌套远程方法,远程方法可以调用其他远程方法,从而产生嵌套Task
- Task阻塞时支持资源释放,嵌套任务如果执行完成了,会直接释放资源,防止嵌套任务等待父任务完成而占用CPU资源的死锁情况。
- Dynamic generators,是行为类似于迭代器的函数,每次迭代产生一个值。Ray支持两种用例的远程generators:
- 从远程函数返回多个值时减少最大堆内存使用量。
- 当返回值的数量由远程函数而不是调用者动态设置时。(都是通过num_returns设置的)远程生成器可用于Actor和non-actor task。
2.2 Actors
Actor将Ray Remote从Function(Task)扩展到Class。Actor本质上是一个有状态的Worker process。当实例化新的Actor时,会创建一个新的worker process,并在该特定worker process上调度Actor的Function,可以访问和更改该worker process的状态。与Task一样,Actor支持CPU、GPU和自定义资源要求。
- 初始化Actor时可以分配资源,指定CPU/GPU的使用大小
- 调用Actor这个类的方法就是一个远程Task,会在当前的Actor进程执行。且调用不同Actor的方法可以并行执行,而调用同一Actor的方法则按调用顺序串行执行。同一Actor上的方法彼此共享这个进程。
- Actor Handle可以传递给其他Tasks,我们可以定义远程函数(或者Actor方法)使用Actor Handle。
- Actor的task可以被取消
- Actor的Task执行事件和记录可以通过State API获取,并展示在Ray Dashboard上
2.3 Objects(对象)
1、概念
在Ray中,Tasks和Actors的创建和计算都是基于Objects的,我称这些Objects为远程Objects,因为这些Objects可以存储在Ray Cluster的任何位置,我们使用object refs类引用他们。远程Objects都被缓存在Ray的分布式共享内存的Object Store,Ray Cluster的每一个节点都有一个Object Store。集群设置中,远程Object可以驻留在一个或者多个节点上,与Object refs的持有者无关。
一个object ref本质上指针或者唯一表示ID,用于引用远程Object,且不需要设置它的值,类似于线程的futures。Object refs可以有两种方式创建:
- 远程Function调用的返回值
- 通过ray.put()返回
注意:远程objects是不可变更的。所以他们的值一旦创建就不会被改变,这允许在多个Object Store中复制远程Object,而无需同步副本。后面会详细介绍Ray Cluster的内存管理,会提到存储Object的内存的具体定义。
2、获取:通过rag.get()从object ref中获取remote object的值。
3、传递Object参数:Ray的object ref可以在同一个Application中自由传递,这就意味这个可以通过参数传递进Tasks和Actor的方法,甚至存在其他objects中。Objects通过分布式引用计数进行跟踪,一旦删除了对Object的所有引用,它们的数据就会自动释放。
通过Ray Task有两种Object传递方式,根据对象传递的方式,Ray将决定是否在Task执行之前取消引用该对象。
- Passing an object as a top-level argument:当Object直接作为顶级参数传给任务时,Ray将取消引用该Object。这意味着Ray将获取所有顶级Object引用参数的底层数据,在Object Data完全可用之前不执行任务。
- Passing an object as a nested argument:当Object做为嵌套参数传递时,例如在Python列表中传递Object,Ray不会取消引用它。这意味着任务需要对引用调用Ray.get()来获取具体值。但是,如果任务从不调用ray.get(),那么Object值就不需要传输到任务运行的机器上。建议在可能的情况下将Object作为顶级参数传递,但嵌套参数对于将Object传递给其他任务而不需要查看数据非常有用。
4、闭包捕获Object:还可以通过闭包捕获将Object传递给任务。当有一个大型对象,并希望在多个任务或演员之间逐字共享它时,这非常方便,而不必重复将其作为参数传递。然而,请注意,定义一个闭包Object引用的Task会通过引用计数固定该对象,因此在作业完成之前,该对象不会被驱逐。
5、嵌套对象:Ray还支持嵌套对象引用。可以构建复合对象,这些对象本身包含对其他子对象的引用。
6、对象还可以序列化,详细方式参考:Serialization — Ray 2.39.0
2.4 Environment Dependencies(环境依赖)
1、概述
Ray的Application的python代码运行可能会有很多外部基础依赖。比如:
- python代码可以能import或者depend一些python的包
- python代码可能需要特殊的环境变量
- python代码可能需要导入一些外部文件
最常见的问题就是当在Ray Cluster上运行代码的时候这些依赖已经不存在于Ray的节点上,就会报错。解决这个问题有两个方法:
- 提前在Ray Cluster的每个节点上准备好所有依赖(使用镜像?)
- 运行代码的时候,使用Ray的runtime environments安装
2、核心概念
- Ray Application:一个包含Ray代码的程序,并且代码调用ray.init()方式,其实是对一组Ray Tasks或者Actors的封装
- Dependencies或者Environment,Application需要运行的Ray代码之外的任何内容,包括文件、包和环境变量。
- Files:运行Application需要的任务代码文件、数据文件或者其他文件
- Packages(包):Ray Application运行时需要的额外的包,通常可以通过pip或者conda安装
- Local machine和Cluster:提交Job的机器叫Local machine,运行Ray job的叫Ray Cluster。
- Job:一个Job是一个单独的Application,通常是来自同一代码的Ray Tasks、Objects和Actors的集合
3、实现方法
1)第一种方式是在启动Ray之前,在集群中预置好所有的依赖。
-
如果使用K8S部署,可以将所有文件和依赖项构建到容器映像中,并在集群YAML配置(Cluster YAML Configuration Options — Ray 2.37.0)中指定。
-
如果使用虚拟机部署,直接在节点中预置好依赖的所有外部依赖,再加入到集群中
2)第二种方式是使用Runtime Environments在Ray应用运行时动态安装,比如pip或者conda
2.5 Scheduling(调度)
2.5.1 调度过程
1、概述
对于每一个提交到Ray Cluster中的Task或Actor,Ray都会挑选一个node去运行。这个挑选的过程就是调度的过程。而调度的核心是根据Ray Cluster中的资源(Resources)来确定。Resources可以理解成CPU/GPU、内存等。每个Task或者Actor的执行都可以指定特定的Resources需求,所以再提交Task或者Actor时,每个Ray Cluster的Node都可能存在两个状态:
-
Feasible:Node具有运行Task或Actor所需的Resources。但是根据Node上当前Resources的可用性,有两个子状态:
-
Available:节点具有Task或Actor所需的资源,现在它们是空闲的。
-
Unavailable:节点具有Task或Actor所需的资源,但它们当前正被其他Task或Actor使用。
-
Infeasible:Node没有运行Task或者Actor所需的资源。例如,仅有CPU的Node对于GPU任务来说是Infeasible。
资源需求是硬需求,这意味着只有可行的节点才有资格运行Task或Actor。如果存在Feasible节点,Ray将根据下面讨论的其他因素,选择一个Available节点或等待一个Unavailable节点变为Available节点。如果所有节点都都是Infeasible,则在将Feasible节点添加到集群之前,无法调度Task或Actor。
2、调度策略(Scheduling Strategies)
Task和Actor都支持scheduling_strategy选项,以指定用于在Feasible节点中确定最佳Node的策略。主要的策略主要包括:
1)DEFAULT
是Ray使用的默认策略,Ray调度Tasks或者Actors安排在一组top k的节点上。具体来说,对节点进行排序,首先优先考虑那些已经安排了Task或Actor的节点(locality),然后优先考虑那些资源利用率低的节点(load balancing)。在Tok k组内,随机选择节点以进一步改善负载平衡,并减轻大型集群中冷启动的延迟。
具体的实现方式是,Ray根据集群中每个节点的逻辑资源利用率计算其得分。如果利用率低于阈值(由操作系统环境变量RAY_scheduler_spread_threshold控制,默认值为0.5),则得分为0。如果利用率高于等于阈值,则为资源利用率本身(得分1表示节点已完全利用)。Ray从得分最低的前k个节点中随机选择最佳节点进行调度。k的值是(集群中的节点数*RAY_scheduler_top_k_action环境变量)和RAY_schedule _top_k_absolute环境变量的最大值。默认情况下,它占节点总数的20%。
注意:如果一个Actor不需要任何资源(即num_cpus=0,没有其他资源),通过随机选择集群中的节点而不考虑资源利用率。由于节点是随机选择的,因此不需要任何资源的Actor可以有效地均匀分布在整个集群中。
2)SPREAD
该策略将尝试在Available节点之间分配Task或者Actor。
3)PlacementGroupSchedulingStrategy
将把Task或Actor安排到PlacementGroup(Placement Groups — Ray 2.37.0)所在的位置。
4)NodeAffinitySchedulingStrategy
是一种低级策略,允许将Task或Actor调度到其节点id指定的特定节点上。如果指定的节点不存在(例如,如果节点死亡)或由于节点都没有运行Task或Actor所需的资源而,即指定的节点都是Infeasible,soft flag标记可以指定是否允许Task或Actor在其他地方运行。在这些情况下,如果soft为True,则Task或Actor将被调度到其他非指定的Feasible节点上。否则,Task或Actor将因TaskUnscheduleError或ActorUnscheduleErrors而失败。只要指定的节点处于活动状态并且Feasible,Task或Actor就只会在那里运行,而不管软标志如何。这意味着,如果节点当前Unavailable,Task或Actor将等待Available。只有当其他高级调度策略(如PlacementGroup)无法给出所需的Task或Actor放置时,才应使用此策略。它有以下已知的局限性:
-
这是一种低级策略,可以防止智能调度器进行优化。
-
它不能完全利用自动缩放集群,因为在创建Task或Actor时必须知道节点ID。
-
很难做出最佳的静态放置决策,尤其是在多租户集群中:例如,应用程序不知道在同一节点上还安排了什么。
3、Locality-Aware Scheduling
默认情况下,Ray更喜欢本地具有大任务参数的可用节点,以避免通过网络传输数据。如果有多个大任务参数,则首选本地对象字节最多的节点。这优先于“DEFAULT”调度策略,这意味着Ray将尝试在本地首选节点上运行任务,而不管节点资源利用率如何。但是,如果本地首选节点不可用,Ray可能会在其他地方运行该任务。当指定其他调度策略时,它们具有更高的优先级,不再考虑数据局部性。
3 Ray Cluster
Ray可以在单机上运行,也可以将工作负载无缝切到大型集群上。当Ray在单机上运行,只需要通过pip install安装使用ray.init就可以运行Application。如果要在大型集群上运行Ray,必须要先部署一个Ray Cluster。一个Ray Cluster就是一组连接到Ray Head节点的的Worker节点。Ray Cluster可以是固定大小的,也可以根据Ray Cluster运行的Application请求的资源进行自动缩放。
目前Ray Cluster支持部署在公有云的虚拟机上(AWS和GCP,社区里也有支持阿里云、微软Azure云等)。还支持部署在K8S上,通过KubeRay这个项目。
3.1 基本架构
一个Ray Cluster包含一个Head Node和多个与之连接的Worker Nodes,架构如下图:
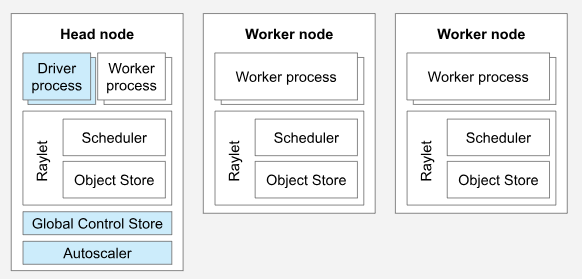
说明:
1、这是一个有两个Worker Node的集群。每一个Worker Node都会运行Raylet进程,其中的Scheduler用于分布式调度,Object Store用于内存管理。还会通过Worker process根据实际调度运行Ray的Application,比如Task或者Actor。
2、集群只有一个Head Node,Head Node本身也是一个Worker Node,会运行Worker Node的Raylet进程,也会运行Worker process。还会运行额外的集群管控进程,比如Global Control Store、Autoscaler和Driver process。
3、如果集群运行在K8S上,那么Head Node和Worker Node都会以Pod为单位进行运行,并且K8S会单独通过KubRay Operator部署Ray Autoscaler来控制集群的自动伸缩。
下面将会详细介绍集群中的各个核心概念。
3.1.1 Head Node
每一个Ray Cluster都有一个Head Node,Head Node上运行着管理集群的单进程实例,比如Autoscaler和Global Control Store(GCS),还运行着多个Driver进程,负责运行Ray Job。同时,也跟其他Worker Node一样,可以负责执行Ray Task和Actor。但是也可以通过配置,然后Head Node执行Task和Actor的CPU资源为0,Head Node就会不再执行Worker Node的任务了。
-
Driver Process:负责发起和控制Ray Job(任务)的主进程。一个典型的 Ray 应用由用户编写的 Python 脚本运行,脚本会通过 Driver Process 提交任务到 Ray 集群中。主要职责包括:
-
任务提交:Driver 负责提交 Ray 任务和 actor 到 Ray 集群。Driver 将任务发送到 Ray 的调度系统,Ray 再根据当前的集群状态将任务调度到合适的节点执行。
-
与 Ray API 交互:用户通过 Ray 的 API 提交任务或创建 actor,Ray 的 Driver Process 就会与 Ray 集群的核心服务(如 GCS、Scheduler)通信,负责解释用户的操作并将其转化为集群操作。
-
管理作业生命周期:Driver 负责管理整个任务或作业的生命周期,追踪任务的完成、失败或重试等情况。
每个运行 Ray 应用的用户程序都会对应一个 Driver Process,它是用户与 Ray 集群交互的接口。
-
Global Control Store(GCS):是 Ray 的全局控制存储,它作为系统中的一个中心化服务,负责管理和存储集群的全局元数据。在 Ray 集群的 head node 上运行。主要职责包括:
-
Actor 管理:GCS 负责管理集群中所有 actor 的元数据,例如 actor 的位置、状态、资源使用情况等。GCS 通过存储这些元数据,使得 Ray 能够追踪和调度不同节点上的 actor。
-
任务调度信息存储:GCS 也存储关于任务队列、调度策略、任务状态等信息。GCS 可以被任务调度器用来根据全局状态来做出最优的调度决策。
-
资源管理:Ray 集群中的资源(CPU、GPU 等)由 GCS 管理。它通过追踪各个节点的资源使用情况,确保任务能够被合理地调度到有足够资源的节点上。
GCS 是 Ray 集群中的一个关键组件,允许不同的节点共享信息、同步状态。
3.1.2 Worker Node
Worker Node不用运行Head Node的管理集群的进程,只能用来在Task和Actor上运行用户的代码。会参与Task和Actor基于资源的分布式调度,同时也会在集群内存中存储和分发Ray Objects。
3.1.3 Ray Cluster 内存管理
系统内存:
Global Control Store(GCS):存放集群所有节点列表和集群中所有Actor的信息
Raylet:每个节点上常驻进程Raylet的使用内存
应用内存:
Ray的应用有几种不同的内存使用:
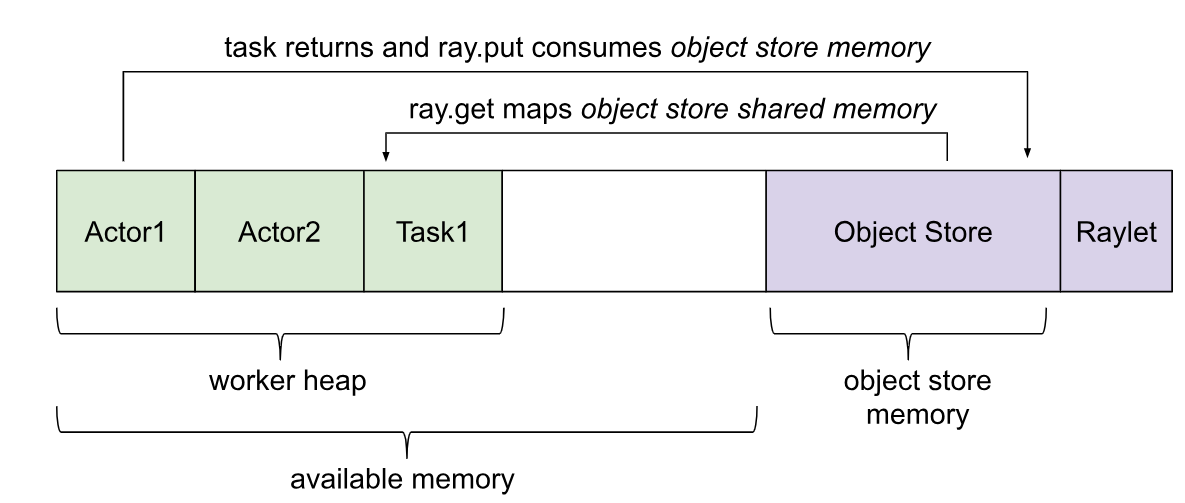
Worker Heap(Worker的堆):Ray的Application所使用的内存(例如,在 Python 代码或 TensorFlow 中)。
Object store memory(对象存储内存):当Application通过ray.put在Object store中创建Object以及从远程函数返回值时使用的内存。Object被引用计数,并在超出范围时被驱逐。Object store 服务器在每个节点上运行。默认情况下,启动实例时,Ray会保留30%的可用内存。Object store 的大小可以通过Object store memory来控制。默认情况下,内存分配给Linux的/dev/shm(共享内存)。对于MacOS,Ray使用/tmp(磁盘)。在Ray 1.3+中,如果对象存储区已满,则对象会溢出到磁盘。
Object store shared memory(对象存储共享内存):用来存储Application通过ray.get获取远程其他应用的Object。如果当前节点已经存在这个Object,就不会重复存储。这运行大对象在很多Actor和Task之间有效共享。
ObjectRef引用计数:Ray实现了分布式引用计数,以便集群中作用域内的任何ObjectRef都存储在Object store中。这包括本地python代码的引用、挂起任务的参数引用,以及在其他Object在内序中列化的ID。
注意:如果Application的Tasks和Actors消耗了大量的worker heap space,则可能会导致节点内存不足(OOM)。当这种情况发生时,操作系统将开始杀死worker或raylet进程,从而中断Application。OOM也可能使指标停滞,如果这发生在Head Node上,它可能会使仪表板或其他控制进程停滞,导致Ray Cluster无法使用。
3.1.4 Autoscaling
Ray的自动伸缩器(Autoscaler)是一个运行在Head Node的进程,当Ray的工作负载对资源的需求(CPU、Memory)超过了当前集群的容量时,自动伸缩器就会尝试增加Worker Node。如果一个集群的工作负载很小,有闲置的Worker Node,自动伸缩器也会把闲置的Worker Node从集群中移除。
注意:
1、Autoscaler只记录Ray的task和actor的资源使用情况,并且根据Task和Actor对资源的显示需求做出响应。应用级的监控指标和物理机的资源占用情况,不影响Autoscaler的工作。
2、如果请求启动Task或者Actor,发现集群资源不够,Autoscaler会将请求排队,然后扩容集群节点数,以满足Task和Actor的运行需求。
3、自动伸缩器可以通过扩容降低集群负载,也可以通过缩容提高资源利用率,但是扩容节点会增加开销,并且影响集群的稳定性,而且配置也比较复杂,所以很多情况下尽量不配置使用。
3.2 本地部署一个Ray Cluster
在本地或者私有化环境上部署一个Ray Cluster,即在本地物理服务器或者私有云中部署一个Ray Cluster。主要有两种方式:
-
通过手工安装Ray包,并在每个节点上手工启动Ray进程来手动设置Ray Cluster。
-
提前规划好所有集群节点,并打通SSH访问,就可以使用cluster-lanuncher来启动。
3.2.1 手工部署基本的流程
假设有一组机器做为集群的机器,且机器的网络可以互通。
1、在集群每台机器上都手工安装ray
# install ray pip install -U "ray[default]"2、启动Head Node
从安装了ray的集群机器中任选一台安装Head node的进程,默认端口是6379,也可以通过--port指定其他端口。
ray start --head --port=6379这个命令可以打印出Ray集群地址,该地址可以传递给其他机器上的Ray start以启动Worker Node(见下文)。如果收到ConnectionError,请检查防火墙设置和网络配置。
3、启动Worker Node
在安装了ray的剩余机器上执行如下命令,并连接Head Node:
ray start --address=<head-node-address:port>请确认将换成上一个步骤中启动Head Node的IP和端口
Ray会自动检测每个节点上可用的资源(例如CPU),但也可以通过将自定义资源传递给Ray start命令来手动覆盖此资源。例如,如果你想指定一台机器有10个CPU和1个GPU可供Ray使用,你可以用标志--num CPUs=10和--num gpus=1来实现。有关更多信息,请参阅配置(Configuring Ray — Ray 2.39.0 )页面。
4、可能出现的错误
如果启动Worker Node时报错“Unable to connect to GCS at ...”,这意味着:
-
Head Node运行异常
-
Worker Node跟Head Node上安装的Ray版本不一致
-
Head Node的地址错误
-
机器之间的网络有防火墙或者别的问题
3.2.2 使用cluster-lanuncher启动集群
假设有一组机器做为集群的机器,且机器的网络可以互通,还打通了SSH访问。
1、在一台可以访问集群机器的本地机器上安装cluster-lanuncher
cluster-lanuncher也是ray工具中的一部分,可以在一台本地机器上直接使用pip安装:
# install ray pip install -U "ray[default]"2、使用cluster-lanuncher和集群配置文件部署Ray Cluster
1)创建集群配置文件为yaml,参考样例:https://raw.githubusercontent.com/ray-project/ray/master/python/ray/autoscaler/local/example-full.yaml。配置文件中需要把所有的集群机器列表信息填入,还要指定Head Node的IP、Worker Node的IP列表,也要把访问机器的SSH信息填进去。
2)在安装了cluster-lanuncher的本地机器上执行如下命令:
# Create or update the cluster. When the command finishes, it will print out the command that can be used to SSH into the cluster head node.
ray up example-full.yaml
# Get a remote screen on the head node.
ray attach example-full.yaml
# Try running a Ray program.Tear down the cluster.
ray down example-full.yaml3.3 KubeRay
Ray集群部署在K8S上一般来说是通过开源的KubeRay项目(ray-project/kuberay: A toolkit to run Ray applications on Kubernetes (github.com))实现,这个项目提供KubeRay Operator,通过这个Operator可以使用K8S原生方式生成Ray K8S集群。在K8S集群中,Ray的Head Node和Worker Node都以Pod的形式运行,还提供可选的Ray Autoscaler Pod,负责Ray集群的自动伸缩。同时,支持同一个Ray集群中实现异构的节点(CPU或GPU),也支持同一个K8S集群中部署多个Ray集群。整体的架构如下所示:
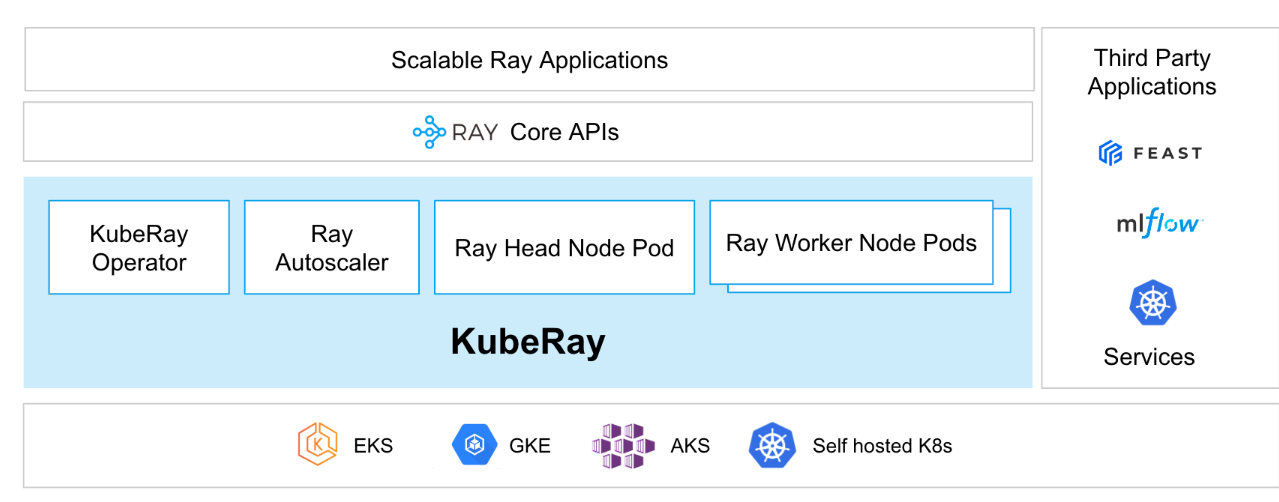
KubeRay提供三个核心的CRD(Custom Resource Definitions)帮助用户在K8S集群上管理Ray Cluster。包括RayCluster、RayJob和RayService。下文会详细的介绍三种CRD。
3.3.1 RayCluster
通过KubeRay Operator 启动的Ray集群,Head Node和Worker Node都是Pod。RayCluster运行后,可以通过部署的K8S Service提交Ray Application。具体的启动过程如下:
1、准备好K8S集群(版本大于1.23)还有Helm(版本大于3.4)
2、部署KubeRay Operator
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm repo update
# Install both CRDs and KubeRay operator v1.1.1.
helm install kuberay-operator kuberay/kuberay-operator --version 1.1.1
# Confirm that the operator is running in the namespace `default`.
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# kuberay-operator-7fbdbf8c89-pt8bk 1/1 Running 0 27s3、通过CRD方式部署RayCluster
# Deploy a sample RayCluster CR from the KubeRay Helm chart repo:
helm install raycluster kuberay/ray-cluster --version 1.1.1
# Once the RayCluster CR has been created, you can view it by running:
kubectl get rayclusters
# NAME DESIRED WORKERS AVAILABLE WORKERS CPUS MEMORY GPUS STATUS AGE
# raycluster-kuberay 1 1 2 3G 0 ready 95s
# View the pods in the RayCluster named "raycluster-kuberay"
kubectl get pods --selector=ray.io/cluster=raycluster-kuberay
# NAME READY STATUS RESTARTS AGE
# raycluster-kuberay-head-vkj4n 1/1 Running 0 XXs
# raycluster-kuberay-worker-workergroup-xvfkr 1/1 Running 0 XXs4、在RayCluster上提交Ray Application
1)直接在Head Node Pod上执行Ray Job
2)通过ray job submission sdk提交Ray Job,使用命令为:
# The following job's logs will show the Ray cluster's total resource capacity, including 2 CPUs.
ray job submit --address http://raycluster-kuberay-head-svc:8265 -- python -c python_script.py3)访问Ray Dashboard(url:http://raycluster-kuberay-head-svc:8265)查看集群的详情,以及历史执行的各种应用的记录。
3.3.2 RayJob
RayJob是KubeRay提供的可以在没有RayCluster的情况下,通过Operator提交Ray Job,就可以自动创建RayCluster运行Ray Job,并且可以配置在Ray Job运行完成后自动释放掉RayCluster。所以RayJob包含三个主要的部分:
-
RayCluster:自定义资源管理Ray Cluster所有的Head Node和Worker Node的Pod。可以运行Ray Application的Ray 集群。
-
Ray Job:一个打包的Ray Application,可以远程运行在Ray Cluster上(后面会详细介绍Ray Job的含义)
-
Submitter:是KubeRay提供的通过ray job submit提交到RayCluster上运行的Ray Job
运行一个样例的RayJob过程:
1、部署KubeRay operator
2、使用这个k8s yaml文件(kuberay/ray-operator/config/samples/ray-job.sample.yaml at master · ray-project/kuberay (github.com))启动一个Ray Job,启动命令为:
kubectl apply -f https://raw.githubusercontent.com/ray-project/kuberay/v1.1.1/ray-operator/config/samples/ray-job.sample.yaml3、检查RayCluster和RayJob的状态(RayJob会自动创建一个RayCluster,也可以配置在RayJob执行完成后自动删除)
3.3.3 RayService
RayService是KubeRay提供的可以在没有RayCluster的情况下,通过Operator提交Ray Serve Applications,就可以自动创建RayCluster,并且运行Ray Serve Applications。所以RayService主要包含两部分:
-
RayCluster:K8S上运行的Ray Cluster
-
Ray Serve Applications:用户的Applications集合(Ray Serve的概念后面会详细介绍)
能提供的功能包括:
-
K8S原生支持运行RayCluster和Ray Serve Applications,直接使用kubectl命令就可以创建Ray Cluster以及Ray Serve
-
Ray Serve能直接就地更新
-
Ray Cluster无感升级,无需停机即可升级
-
RayService高可用部署,详情可以参考:RayService high availability — Ray 2.37.0
部署一个样例RayService过程:
1、部署KubeRay operator
2、使用样例Yaml文件(https://raw.githubusercontent.com/ray-project/kuberay/v1.1.1/ray-operator/config/samples/ray-service.sample.yaml )安装RayService,命令为:
kubectl apply -f https://raw.githubusercontent.com/ray-project/kuberay/v1.1.1/ray-operator/config/samples/ray-service.sample.yaml3、校验RayCluster和RayServe的状态
3.4 基于公有云VM部署Ray Cluster
Ray可以基于公有云VM部署Ray Cluster,现在Ray内置了对AWS和GCP虚拟机集群部署的支持,社区里也有人提供Azure、阿里云和vSphere的支持。每一个Ray Cluster包含一个Head Node,多个Worker Node,每一个Node都是一台虚拟机。同时,可选部署Autoscaler,支持集群自动伸缩。另外,也支持异构的Ray Cluster,节点中可以同时存在CPU和GPU的机器。
在公有云虚拟机上部署Ray Cluster可以参考在本地部署一个Ray Cluster的方法,同时使用云原生的能力,很多依赖可以直接使用公有云的组件或者服务。比如通过cluster-lanuncher部署,基本上跟本地部署一个Ray Cluster方法一致,知识配置文件中需要指定provider信息。还需要安装公有云虚拟机专用的Python SDK。基本的过程如下(以AWS为例):
1、安装cluster-lanuncher和公有云专用Python SDK(如AWS的boto3)
2、通过cluster-lanuncher部署Ray Cluster
3、配置AWS专有组件,比如挂载EFS存储、配置IAM角色和EC2实例初始化策略(这是为了自动扩容的时候方便自动购买机器)、配置访问S3(一些机器学习任务可以将结果或者中间结果写入)等
4、Ray的监控指标收集,可以接入AWS的CloudWatch
4 Ray Applications(应用程序)
基于Ray基本的Task和Actor,可以在Ray Cluster上构建复杂的应用程序(Ray Application),应用程序的形式目前主要有两种Ray Job和Ray Serve,下面将分别介绍。
4.1 Ray Job
Ray Job 是一个用于在 Ray 集群中运行独立应用程序的抽象,适用于需要一次性运行的计算应用程序,应用程序中包括多个Actor或者Task。Ray提供了API(包括CLI、SDK和REST API)来提交和管理这些应用程序,Ray Job这种应用程序通常用于批处理或数据处理工作。
4.1.1 使用Ray Jobs API向Ray Cluster提交Ray Job
1、基本说明
通过Ray API提交Ray Job到Ray Cluster执行有两种方式:
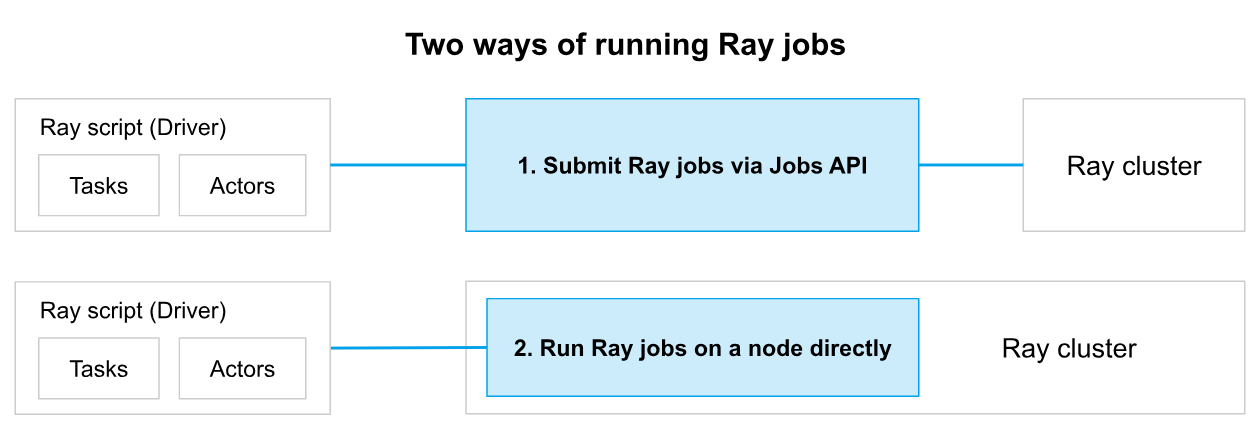
Ray Jobs API可以将本地开发的应用程序提交到远程Ray Cluster以供执行。它简化了打包、部署和管理Ray应用程序的体验。提交给Ray Jobs API的文件包括:
-
一个执行应用程序的命令,如python my_script.py,以及
-
运行时环境,指定该应用程序的文件和包依赖关系。(也可以提前在集群环境中预置好)
Ray Job可以由位于Ray集群之外的远程Client提交。提交Ray Job后,无论Submitter是否还与Ray Cluster保持连接,Ray Cluster都会将Ray Job运行到终止状态(成功或者失败)。具有不同参数的重试或不同Ray Job应由Submitter处理。Ray Job绑定到Ray集群的生存期,因此如果Ray Job运行期间,Ray 集群发生故障,那么该Ray集群上所有正在运行的Job都将终止。
要开始使用Ray Jobs API,请查看快速启动指南,该指南将引导您了解用于提交Ray Jobs和与Ray Jobs交互的CLI工具。这适用于任何可以通过HTTP与Ray Cluster通信的客户端。
2、使用方式
1)CLI方式
ray job submit,比如ray job submit --working-dir your_working_directory -- python script.py
如果要远程访问,需要访问Ray Cluster 的Dashboard 的url,默认端口是8265
2)Python SDK方式
在代码中使用JobSubmissionClient提交任务,比如
from ray.job_submission import JobSubmissionClient
# If using a remote cluster, replace 127.0.0.1 with the head node's IP address or set up port forwarding.
client = JobSubmissionClient("http://127.0.0.1:8265")
job_id = client.submit_job(
# Entrypoint shell command to execute
entrypoint="python script.py",
# Path to the local directory that contains the script.py file
runtime_env={"working_dir": "./"}
)
print(job_id)访问的地址也是Ray Cluster的url,默认端口是8265
3)使用REST API访问
import requests
import json
import time
resp = requests.post(
"http://127.0.0.1:8265/api/jobs/", # Don't forget the trailing slash!
json={
"entrypoint": "echo hello",
"runtime_env": {},
"job_id": None,
"metadata": {"job_submission_id": "123"}
}
)
rst = json.loads(resp.text)
job_id = rst["job_id"]
print(job_id)4.1.2 使用Ray Client向Ray Cluster提交Ray Job
1、Ray Client定义
Ray Client是一个API,它将Python代码连接到远程Ray Cluster上。允许用户使用远程Ray集群,就像在本地计算机上运行Ray一样。通过将ray.init()更改为ray.init(“ray://:”),可以从笔记本电脑(或任何地方)直接连接到远程集群并扩展运行的Python代码,同时保持在Python shell中交互式开发的能力。但是目前只有Ray 1.5+才支持。
Ray Client安装的方式为:
# install ray
pip install ray[client]使用方式为:
# You can run this code outside of the Ray cluster!
import ray
# Starting the Ray client. This connects to a remote Ray cluster.
ray.init("ray://<head_node_host>:10001")
# Normal Ray code follows
@ray.remote
def do_work(x):
return x ** x
do_work.remote(2)
#....2、什么时候使用Ray Client
Ray Client存在架构限制,主要用来使用Ray Jobs API对ML项目进行交互式开发时才使用。(因为这是一种同步连接方式)
Ray Client对于在本地Python shell中与Ray Cluster进行交互式开发非常有用。但是,它需要与远程集群建立稳定的连接,如果连接丢失超过30秒,它将终止工作负载。所以,一般用来测试开发,如果正式环境要提交长期运行的Ray Job,还是需要使用Ray Job API的方式。
4.2 Ray Serve
Ray Serve 是 Ray 框架中专门为构建可扩展的、低延迟的、分布式在线推理服务而设计的库。它简化了在分布式环境中部署、管理和扩展机器学习模型及其他应用的过程,同时支持多种部署模式和灵活的 API 接口。Ray Serve 允许开发者轻松构建和部署能够处理高并发流量的在线服务,包括 Web 应用、API 服务和机器学习推理服务。允许用户通过 HTTP 接口部署和管理机器学习模型。它支持模型的版本控制、流量管理和自动缩放,适合于实时推理和在线服务。
4.2.1 核心概念
Deployment
Deployment是 Ray Serve 的核心概念。一个Deployment包含业务逻辑或机器学习模型,以处理传入请求,并可以扩展到整个 Ray 集群运行。在运行时,Deployment由多个replicas组成,这些replicas是类或函数的独立副本,启动于不同的 Ray Actor(进程)中。副本的数量可以根据传入请求的负载进行增加或减少(甚至自动缩放)。也就是说Deployment是由多个actor组成的,具体的组成方式和架构,会在后面Ray Serve的架构中说明的。
要定义一个部署,可以在 Python 类(或简单用例中的函数)上使用 @serve.deployment 装饰器。然后,将可选参数绑定到构造函数中以定义一个应用程序。最后,使用 serve.run(或等效的 serve run CLI 命令)部署生成的应用程序。
Application
Application是Ray Serve Cluster中的一个升级单元。一个Application可以由一个或者多个Deployment构成,且其中的Deployment通过模型组合形成一个有向无环图。这些Deployment中会有一个叫“Ingress deployment”,负责处理所有入站流量。
DeploymentHandle (composing deployments)
Ray Serve 通过允许多个独立Deployment相互调用,实现灵活的模型组合和扩展。当绑定一个Deployment时,可以包括对其他已绑定Deployment的引用。然后,在运行时,这些参数会转换为 DeploymentHandle,可以使用 Python 原生 API 查询Deployment。
Ingress Deployment(HTTP handling)
一个Application可以包括多个Deployment,这些Deployment可以组合起来执行模型组合或复杂的业务逻辑。然而,有一个Deployment始终是在最顶层,并且启动Application的时候,这个Deployment会被传递给serve.run。这个Deployment会被叫做“Ingress Deployment”,因为它做为Application的流量入口。通常,它使用DeploymentHandle API路由到其他部署或调用这些部署,并在返回给用户之前把多个Deployment的结果合成最终结果。
Ingress Deployment定义了Application的HTTP请求逻辑,默认情况下,默认情况下,Deployment这个类的__call__方法被调用并在Starlette请求对象中传递。响应将被序列化为JSON,但其他Starlette响应对象也可以直接返回。
4.2.2 核心应用场景
1、通过应用部署多个模型组合(一个Application,多个Deployment,每个Deployment是一个模型)
解决场景:如果在同一个请求的时候,你有多个模型或者业务逻辑需要执行。并且这些模型和业务逻辑在同一个仓库中,需要同时升级,就建议使用同一个Application,把这些模型和业务逻辑都单独做为一个Deployment。
实际场景:多模型组合,支持通过 DeploymentHandle 来实现模型之间的组合。例如,一个服务可以将请求发送到多个子模型进行推理,然后将结果进行组合后返回。这适用于需要多个步骤或多个模型协同工作的复杂任务。
2、同时部署多个Application
解决场景:如果多个应用和逻辑有逻辑分组,例如一组模型需要跟另一组另一个仓库的模型交互,就建议把这两组模型放在不同的Application中。还有一种情况就是,如果模型之间不需要交互,但是你想要共同托管在同一个集群中以提高硬件使用率。因为一个Application是一个升级单元,使用多个Application可以部署多个不同的分组的独立模型或者业务逻辑,在不同的访问endpoint。还可以方便的独立删除或者升级任何一个Application。
实际场景:在一些复杂的应用场景中,往往需要同时管理和服务多个模型。例如,电商平台可能会同时部署多个推荐系统模型来为用户提供个性化推荐,Ray Serve 通过其多模型支持和动态流量路由功能可以轻松实现这一点。
3、可扩展的Web API服务
Ray Serve 不仅仅用于机器学习模型推理,还可以用来构建可扩展的 Web API 服务。开发者可以将复杂的应用逻辑封装为服务,并部署到 Ray Serve 中,享受其带来的自动扩展和容错能力。
4、在线机器学习推理
Ray Serve 最常见的应用场景是用于机器学习模型的在线推理服务。它可以处理高并发、低延迟的推理请求,支持各种机器学习和深度学习框架,如 TensorFlow、PyTorch、XGBoost 等。企业可以将其部署为实时推理 API 或微服务。
4.2.3 Ray Serve 架构
基本架构
Ray Serve中,有各个关键架构概念和组件,每个组件的作用及其工作原理,组成Serve Application的不同类型的actor。本节中会详细介绍:
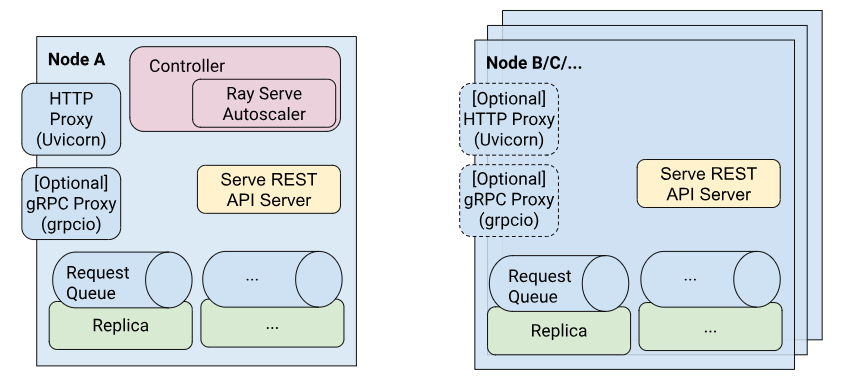
Ray Serve的Application是由如下几种actor组成的:
-
Controller(控制器):每个 Serve 实例唯一的全局 actor,负责管理控制平面。Controller 负责创建、更新和销毁其他 actors。Serve 的 API 调用(如创建或获取部署)会通过远程调用与 Controller 交互。
-
HTTP Proxy(HTTP 代理):默认情况下,Head Node 上有一个 HTTP 代理 actor。这个 actor 运行一个 Uvicorn HTTP 服务器,用于接受传入的请求,转发给 replicas,并在处理完成后响应。为了实现可扩展性和高可用性,还可以通过 serve.start() 方法或配置文件中的 proxy_location 字段,在集群的每个节点上运行一个代理。
-
gRPC Proxy(gRPC 代理):如果在启动 Serve 时指定了有效的端口和 grpc_servicer_functions,那么 gRPC 代理会与 HTTP 代理一起启动。这个 actor 运行一个 grpcio 服务器。gRPC 服务器接受传入的请求,转发给 replicas,并在处理完成后响应。
-
Replicas(副本):这些 actors 实际执行响应请求的代码。例如,它们可能包含一个机器学习模型的实例。每个 replica 处理来自代理的单个请求。replica 可以使用 @serve.batch 来对请求进行批处理。
一个请求的生命周期
当 HTTP 或 gRPC 请求发送到相应的 HTTP 或 gRPC 代理时,流程如下:
-
请求被接收并解析。
-
Ray Serve 查找与 HTTP URL 路径或应用程序名称元数据相关联的正确Deployment。Serve 将请求放入队列。
-
对于Deployment队列中的每个请求,系统查找可用的replica并将请求发送给它。如果没有可用的replica(即每个replica的请求数超过了 max_ongoing_requests),请求将保留在队列中,直到有replica可用。
-
每个replica维护一个请求队列,并依次执行请求。replica可能会使用 asyncio 来并发处理请求。如果Handler(Deployment Function或Deployment类的 __call__ 方法)是用 async def 声明的,replica将不会等待Handler运行完成。否则,replica会阻塞,直到Handler返回。
-
当通过 DeploymentHandle(而不是 HTTP 或 gRPC)进行请求时(例如用于模型组合),请求会被放入 DeploymentHandle 的队列,直接跳到上述的第 3 步。
容错机制
如果在模型评估代码中发生应用错误(如异常),这些错误会被捕获并封装,返回带有追踪信息的 500 状态码,replica仍然能够继续处理后续请求。
Ray Serve 处理机器错误和故障的方式如下:
-
当replica Actors 失败时,Controller Actor 会用新的replica替换它们。
-
当Proxy Actor 失败时,Controller Actor 会重新启动它。
-
当 Controller Actor 失败时,Ray 会重新启动它。
-
使用 KubeRay 的 RayService 时,KubeRay 会恢复崩溃的节点或集群。你可以通过使用 GCS FT 功能来避免集群崩溃。
-
如果你不使用 KubeRay,当 Ray 集群失败时,Ray Serve 将无法恢复。
当承载任何 actor 的机器崩溃时,这些 actors 会自动在其他可用机器上重启。Controller 中的所有数据(如路由策略、部署配置等)都会被检查点到 head node 上的 Ray 全局控制存储(GCS)。路由器和副本中的临时数据(如网络连接和内部请求队列)将在此类故障中丢失。
Ray Serve自动伸缩
Ray serve可以根据Deployment的负载自动增加或者减少其replica的数量。
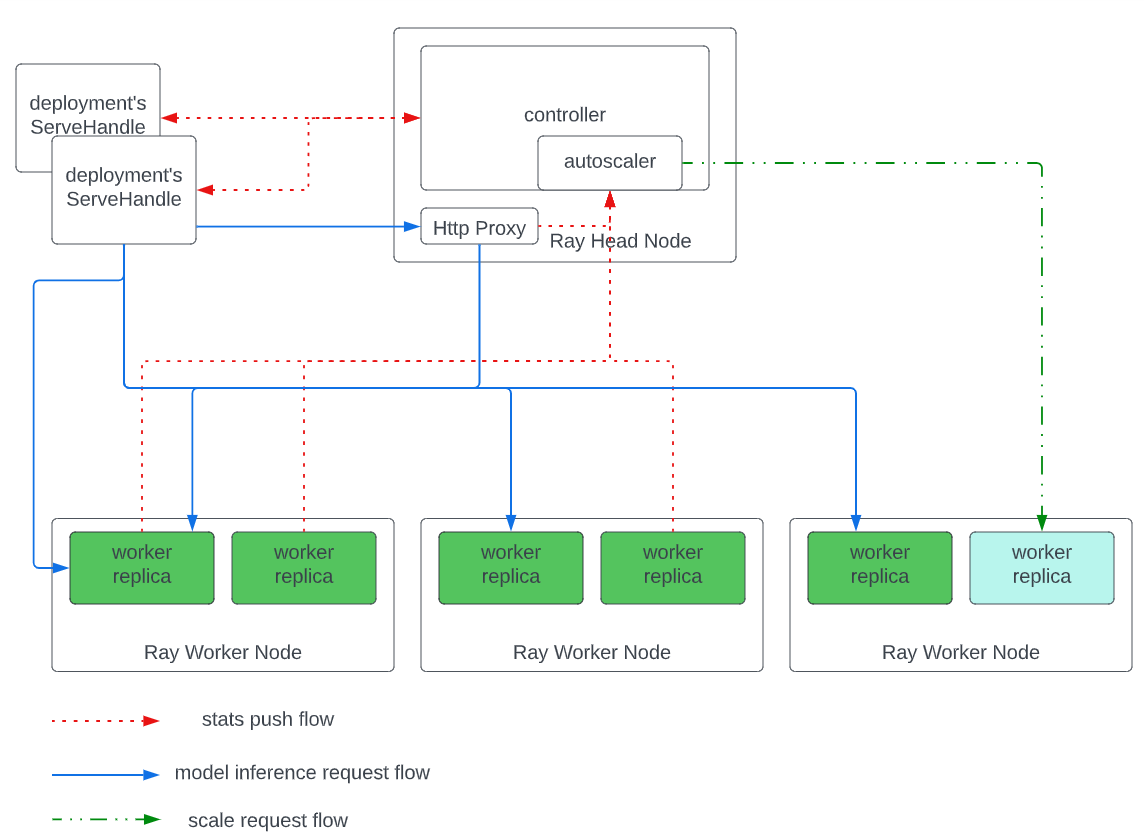
基本过程:
-
Serve 自动扩缩器运行在 Serve Controller actor 中。
-
每个 DeploymentHandle 和每个replica都会定期将其指标发送给自动扩缩器。
-
对于每个Deployment,自动扩缩器会定期检查 DeploymentHandle 队列和副本上的正在处理的请求,以决定是否需要扩展replica的数量。
-
每个 DeploymentHandle 会持续轮询 Controller 以检查是否有新的部署replica。一旦发现新的replica,它会将缓冲的或新的请求发送给这些replica,直到达到 max_ongoing_requests 的限制。请求会以轮询的方式发送给replica,但要确保每个replica同时处理的请求不会超过 max_ongoing_requests。
注意:如果Serve Controller actor进程挂掉后,对Application的HTTP、gRPC和DeploymentHandle的访问还是可以生效(因为是通过proxy actor),但是自动伸缩功能就暂时没有了。等Serve Controller actor恢复后,自动伸缩功能会再次恢复。不过之前的所有监控指标会丢失。
Ray Serve API Server
Ray Serve提供了一个用于管理Ray Serve实例的CLI,以及一个REST API。Ray集群中的每个节点都提供一个Serve REST API Server,该Server可以连接到Serve并响应Serve 的 REST请求。
确保水平可扩展性和高可用性的方法
通过在 serve.start() 或配置文件中的 proxy_location 字段配置 Serve,使其在每个节点上启动一个proxy Actor。每个proxy都会绑定到相同的端口。这样,可以通过任何服务器访问 Serve 并向模型发送请求。还可以在 Ray Serve 之上使用自定义的负载均衡器。
这种架构确保了 Serve 的水平可扩展性。可以通过添加更多节点来扩展 HTTP 和 gRPC 的入口流量,也可以通过在Deployment中增加replica数量(使用 num_replicas 选项)来扩展模型推理的能力。
DeploymentHandles怎么工作
DeploymentHandles 包装了指向同一节点上 "路由器" 的句柄,该路由器将请求路由到Deployment的replica。当一个replica通过句柄向另一个replica发送请求时,请求将经过与传入的 HTTP 或 gRPC 请求相同的数据路径。这使得相同的replica选择和批处理机制能够生效。DeploymentHandles 常用于实现模型组合。
大型请求处理方法
Serve 利用了 Ray 的共享内存对象存储和进程内存存储。小的请求对象通过网络调用直接在 Actors 之间传递。对于较大的请求对象(100 KiB 以上),它们会被写入Object Store,replica可以通过零拷贝读取来读取这些对象。

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









