







 文章详细讨论了feature_importances_在模型评估中的作用,包括其计算原理、随机性以及受建模过程的影响。强调了在特征筛选时需注意模型泛化、运算效率和特征利用的策略,如使用交叉验证、集成学习和特征选择方法来优化模型性能。
文章详细讨论了feature_importances_在模型评估中的作用,包括其计算原理、随机性以及受建模过程的影响。强调了在特征筛选时需注意模型泛化、运算效率和特征利用的策略,如使用交叉验证、集成学习和特征选择方法来优化模型性能。
详解feature_importances_
基于模型的评估指标
当我们进行基于模型的特征筛选时,常常会利用模型训练结果产生的特征重要性指标来评估特征的贡献程度和重要性。一些常见的特征重要性指标包括线性模型中的coef_参数以及决策树及基于决策树的集成算法中的feature_importances_。这些指标能够帮助我们了解特征对模型训练的贡献程度,从而辅助进行特征筛选。
对于线性模型,例如线性回归、Lasso回归、岭回归和逻辑回归,我们可以使用coef_参数来衡量特征的重要性。其绝对值越大,表示特征对因变量的影响越大,因此特征越重要。
而对于决策树及基于决策树的集成算法,我们通常会使用feature_importances_指标来评估特征的重要性。这个指标能够衡量特征对标签取值区分度的累计结果,因此也是一种普适的评估指标。
然而,这些指标的应用并不仅仅是根据评分由高到低筛选特征这么简单。因此,有必要深入理解这些指标的计算流程,并据此探究如何应用这些指标进行特征筛选。以feature_importances_为例进行讲解,coef_指标的使用过程也是类似的。
1. feature_importances_的计算过程
这里我们首先通过一组极简的数据,先来探讨决策树feature_importances_指标的计算过程。
# 准备数据集
X = np.array([[1, 1], [2, 2], [2, 1], [1, 2], [1, 1], [1, 2], [1, 2], [2, 1]])
X = pd.DataFrame(X, columns=['x0', 'x1'])
y = np.array([0, 0, 0, 1, 0, 1, 1, 0])
X,y

clf = DecisionTreeClassifier().fit(X, y)
plt.figure(figsize=(6, 2), dpi=150)
tree.plot_tree(clf)
clf.feature_importances_#模型训练完后,我们可以查看两个特征的重要性指标

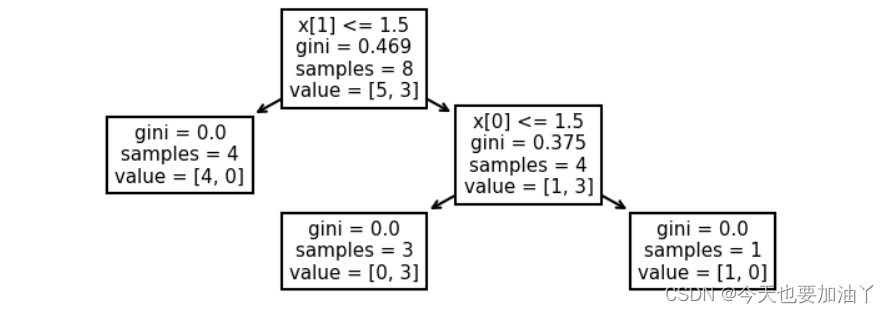
importances是一个累计结果,决策树每生长一次就会进行一次importances的计算,即计算一次本次生长中标签不纯度下降数值,并将其累计到本次生长对应的特征的重要性中。而这里的一次生长过程中不纯度下降值,并不是遵照上一小节的信息增益的计算流程,而是父节点的权重父节点的标签不纯度,减去左右两边子节点的权重子节点标签不纯度,这里父节点、子节点的权重就是各数据集样本数在总样本中的占比。例如上述x0、x1两个特征的重要性可以参照如下过程进行计算:
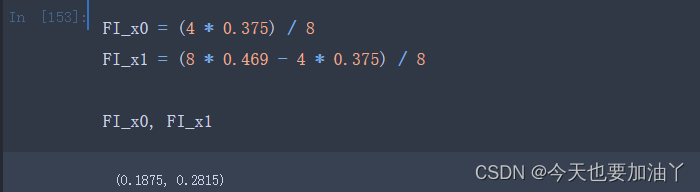
决策树最终输出的feature_importances_实际上是不同特征重要性的占比

2.feature_importances_的计算特性
2.1 feature_importances_的随机性
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import numpy as np
# 创建示例数据集
np.random.seed(0)
n_samples = 1000
age = np.random.randint(18, 65, size=n_samples)
income = np.random.randint(20000, 150000, size=n_samples)
gender = np.random.choice(['M', 'F'], size=n_samples)
education = np.random.choice(['High School', 'Bachelor', 'Master', 'PhD'], size=n_samples)
target = np.random.choice([0, 1], size=n_samples)
data = {
'Age': age,
'Income': income,
'Gender': gender,
'Education': education,
'Target': target
}
df = pd.DataFrame(data)
# 将分类变量转换为哑变量
df = pd.get_dummies(df, columns=['Gender', 'Education'])
# 定义特征和目标变量
X = df.drop('Target', axis=1)
y = df['Target']
# 训练决策树模型
tree_model = DecisionTreeClassifier()
clf = tree_model.fit(X, y)
# 获取特征重要性
feature_importance = clf.feature_importances_
# 打印特征重要性
print(feature_importance)
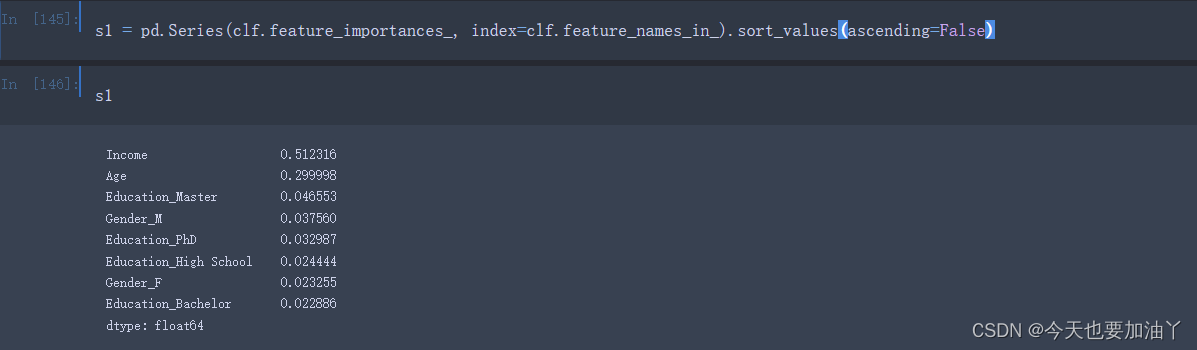
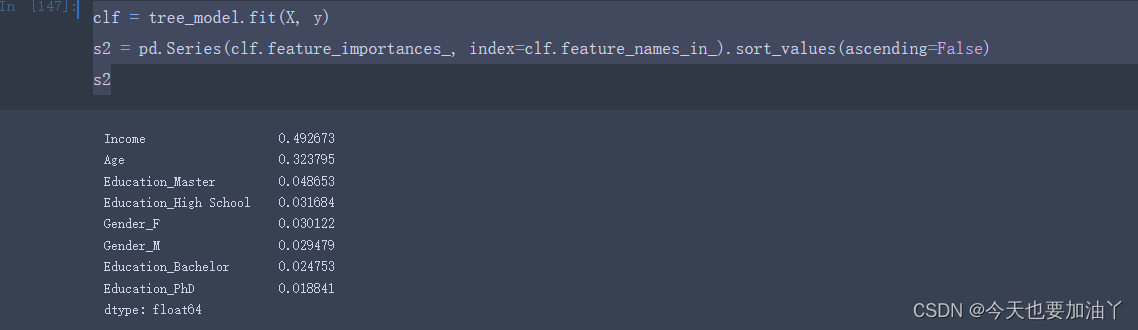
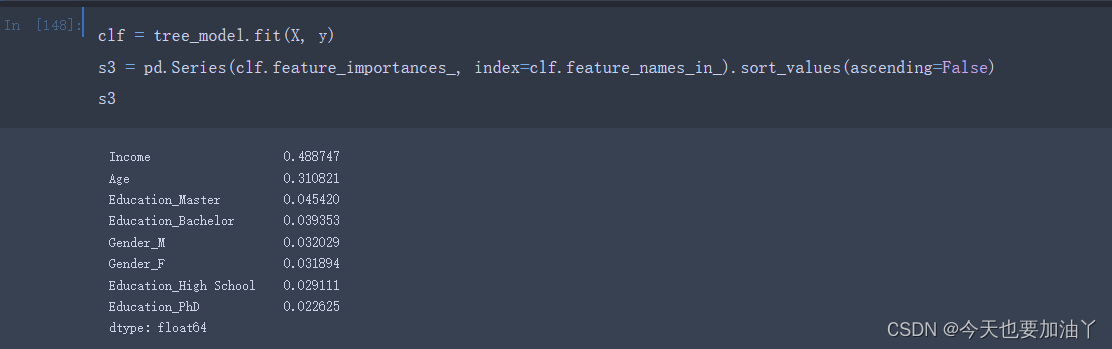
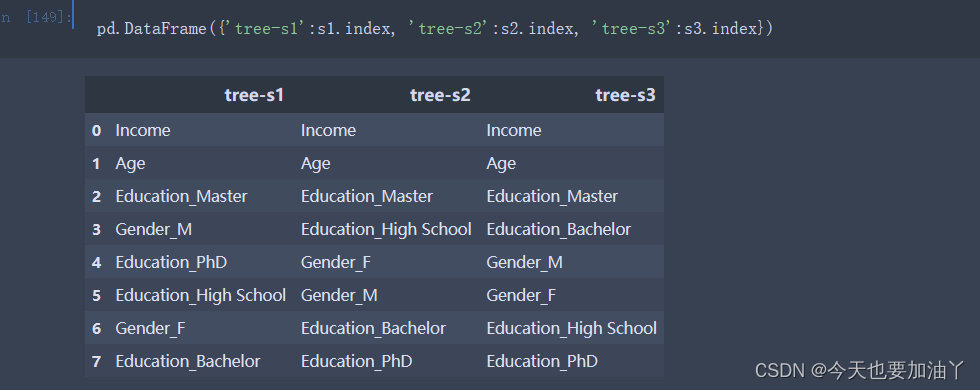
首先我们能够发现,相同参数的决策树模型,在多次训练时feature_importances_会表现出一定的随机性。
那这种随机性来源是什么呢?
根据DecisionTreeClassifier的random_state参数的解释,我们可以得知,模型中的随机性主要来自于CART树对切分点的选取。根据评估器的说明,即使在max_features=n_features(即每次训练带入全部特征)的情况下,决策树生长过程中也常常会出现具有相同效力的备选切分点(即基于基尼系数的信息增益相同)。在这种情况下,模型只能随机选择其中一个备选点进行切分,而选择哪个切分点,就会给对应的特征累积更多的重要性。因此,即使是相同的数据在多次建模时,特征的重要性也会有所不同。
2.2 feature_importances_受建模过程影响
所有的特征评估其实都是为了找到一组能够更好的帮助模型提升结果和泛化能力的特征,而此时树模型的特征重要性计算结果,如果是在模型过拟合状态下算得得,其结果可信度并不高。因此我们希望训练一个泛化能力更强的模型。综上所述,feature_importances_是一个和树模型建模过程高度关联的指标,并且模型结果越好,该指标就越可信。
3 基于feature_importances_的特征筛选
几点需要注意:
首先是模型层面,为了提供更加可信的feature_importances_结果,模型训练一定要借助交叉验证或者超参数优化器共同执行、以训练一个泛化能力更强的模型;
其次是运算效率方面,很明显,带入模型的特征筛选过程需要耗费更大的算力,往往更加适合于小范围高精度的特征筛选;
其三,这个特征筛选过程其实已经有Embedding的影子在里面了,在训练模型的同时筛选出了一组有效特征,如果第一次训练的模型就是最优模型、并且特征子集就是最优子集,则上述过程就是一个完整的Embedding过程。
此外,上述结果还涉及一个非常重要的议题,那就是单独一颗决策树能够利用特征的最大个数问题?其实决策树的结构和决策树能够利用的特征个数是直接相关的,一颗两层的二叉决策树只有一个切分点、最多只能用到一个特征,而一个三层的二叉树则有3个切分点,最多也只能用到三个特征。尽管对于单独一棵决策树来说当前用到的特征一定就是模型训练的最优解,但对于集成学习或者模型融合过程,特征的利用程度却是影响模型效果的重要因素。
要解决单独一颗决策树能够利用特征的最大个数问题,可以考虑以下方法:
-
特征选择和降维: 使用特征选择方法(如方差选择法、相关系数法、互信息法、基于树模型的特征选择等)或降维方法(如主成分分析、线性判别分析等)来减少特征数量,从而降低单颗决策树能够利用的特征个数的限制。
-
集成学习: 使用集成学习方法,如随机森林、梯度提升树等,通过组合多颗决策树的预测结果,可以综合利用更多特征,从而提高模型的效果。
-
特征重要性评估: 对于集成学习模型,可以通过特征重要性评估方法(如基于树模型的特征重要性评估)来识别并重点利用对模型性能有重要影响的特征,从而提高特征的利用程度。
-
模型融合: 在模型融合过程中,可以结合多种模型,如线性模型、树模型、神经网络等,以综合利用不同模型对特征的利用程度,从而提高整体模型的效果。
综合利用上述方法可以解决单独一颗决策树能够利用特征的最大个数问题,从而提高模型的效果和泛化能力。

















 3869
3869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









