






持久化使用
package org.example
import org.apache.spark.sql.SparkSession
object CacheTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("spark-cache-test")
.getOrCreate()
val sc = spark.sparkContext
val l = Seq("hello spark", "hello scala")
val rdd = sc.parallelize(l)
rdd.collect()
val flatmapRdd = rdd.flatMap(_.split(" "))
def fun(x: String) = {
println("fun is call")
x -> 1
}
val mapRdd = flatmapRdd.map(fun)
println(mapRdd.toDebugString)
// mapRdd.cache()
println(mapRdd.toDebugString)
val reduceRdd = mapRdd.reduceByKey((x,y)=>x+y)
reduceRdd.collect()
println(mapRdd.toDebugString)
val groupRdd = mapRdd.groupByKey()
groupRdd.collect()
Thread.sleep(10000000)
}
}
/**
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 []
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 []
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 []
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 []
fun is call
fun is call
fun is call
fun is call
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 []
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 []
fun is call
fun is call
fun is call
fun is call
不使用持久化。map执行了8次。mapRdd没有变化
*/
package org.example
import org.apache.spark.sql.SparkSession
object CacheTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("spark-cache-test")
.getOrCreate()
val sc = spark.sparkContext
val l = Seq("hello spark", "hello scala")
val rdd = sc.parallelize(l)
rdd.collect()
val flatmapRdd = rdd.flatMap(_.split(" "))
def fun(x: String) = {
println("fun is call")
x -> 1
}
val mapRdd = flatmapRdd.map(fun)
println(mapRdd.toDebugString)
mapRdd.cache()
println(mapRdd.toDebugString)
val reduceRdd = mapRdd.reduceByKey((x,y)=>x+y)
reduceRdd.collect()
println(mapRdd.toDebugString)
val groupRdd = mapRdd.groupByKey()
groupRdd.collect()
Thread.sleep(10000000)
}
}
/**
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 []
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 []
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 [Memory Deserialized 1x Replicated]
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 [Memory Deserialized 1x Replicated]
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 [Memory Deserialized 1x Replicated]
fun is call
fun is call
fun is call
fun is call
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 [Memory Deserialized 1x Replicated]
| CachedPartitions: 2; MemorySize: 400.0 B; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 [Memory Deserialized 1x Replicated]
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 [Memory Deserialized 1x Replicated]
使用持久化。map执行了4次。
cache后rdd后多出[Memory Deserialized 1x Replicated],指的是持久化级别,给rdd打上了标记
rdd中多出 CachedPartitions: 2; MemorySize: 400.0 B; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B,代表优先读取cache
*/
package org.example
import org.apache.spark.sql.SparkSession
object CacheTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("spark-cache-test")
.getOrCreate()
val sc = spark.sparkContext
val l = Seq("hello spark", "hello scala")
val rdd = sc.parallelize(l)
rdd.collect()
val flatmapRdd = rdd.flatMap(_.split(" "))
def fun(x: String) = {
println("fun is call")
x -> 1
}
val mapRdd = flatmapRdd.map(fun)
println(mapRdd.toDebugString)
sc.setCheckpointDir("./checkpoint")
mapRdd.checkpoint()
println(mapRdd.toDebugString)
val reduceRdd = mapRdd.reduceByKey((x,y)=>x+y)
reduceRdd.collect()
println(mapRdd.toDebugString)
val groupRdd = mapRdd.groupByKey()
groupRdd.collect()
Thread.sleep(10000000)
}
}
/**
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 []
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 []
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 []
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 []
fun is call
fun is call
fun is call
fun is call
fun is call
fun is call
fun is call
fun is call
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| ReliableCheckpointRDD[4] at collect at CacheTest.scala:32 []
使用checkpoint后,rdd没有变化。
map执行了8次,其中reduceRdd.collect()执行了4次,checkpoint执行了4次。
这说明checkpoint是重新计算的。可结合cache()/persist()使用来避免多次计算。
后面rdd血缘发生改变,替换为ReliableCheckpointRDD[4] at collect at CacheTest.scala:32 []
这说明checkpoint切断了血缘,后面计算是从checkpoint中读取数据
*/
package org.example
import org.apache.spark.sql.SparkSession
object CacheTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("spark-cache-test")
.getOrCreate()
val sc = spark.sparkContext
val l = Seq("hello spark", "hello scala")
val rdd = sc.parallelize(l)
rdd.collect()
val flatmapRdd = rdd.flatMap(_.split(" "))
def fun(x: String) = {
println("fun is call")
x -> 1
}
val mapRdd = flatmapRdd.map(fun)
println(mapRdd.toDebugString)
mapRdd.cache()
sc.setCheckpointDir("./checkpoint")
mapRdd.checkpoint()
println(mapRdd.toDebugString)
val reduceRdd = mapRdd.reduceByKey((x,y)=>x+y)
reduceRdd.collect()
println(mapRdd.toDebugString)
val groupRdd = mapRdd.groupByKey()
groupRdd.collect()
Thread.sleep(10000000)
}
}
/**
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 []
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 []
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 []
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 [Memory Deserialized 1x Replicated]
| MapPartitionsRDD[1] at flatMap at CacheTest.scala:18 [Memory Deserialized 1x Replicated]
| ParallelCollectionRDD[0] at parallelize at CacheTest.scala:15 [Memory Deserialized 1x Replicated]
fun is call
fun is call
fun is call
fun is call
(2) MapPartitionsRDD[2] at map at CacheTest.scala:25 [Memory Deserialized 1x Replicated]
| CachedPartitions: 2; MemorySize: 400.0 B; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| ReliableCheckpointRDD[4] at collect at CacheTest.scala:33 [Memory Deserialized 1x Replicated]
先cache/persist再checkpoint,map执行了四次。checkpoint是从cache/persist中获取数据。
*/
checkpoint在本地生成了文件,因为并行度是2,所以有part-00000和part-00001两个数据文件。
作业停止后,本地文件依然存在。所以如果不需要,就手动删除。
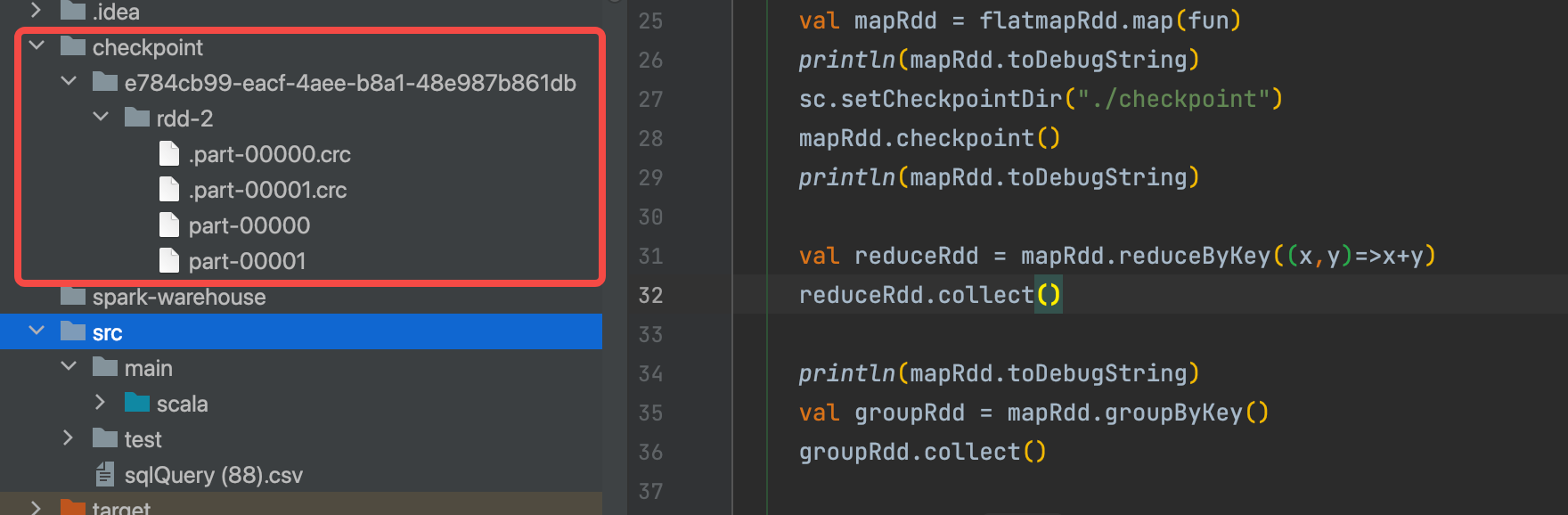
持久化对比
cache/persist/checkpoint 三个持久化算子。
cache:本质就是persist,缓存到内存中。
persist:可以选择不同的缓存策略(内存、硬盘结合),不会切断血缘,作业完成后字段删除。
checkpoint:缓存到硬盘上。能切断血缘。作业完成后数据文件不会删除。
这三个算子都是transform算子,不会立即执行。等到action算子触发后,才会开始持久化。
cache算子
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
cache:本质就是persist,缓存到内存中。
persist算子
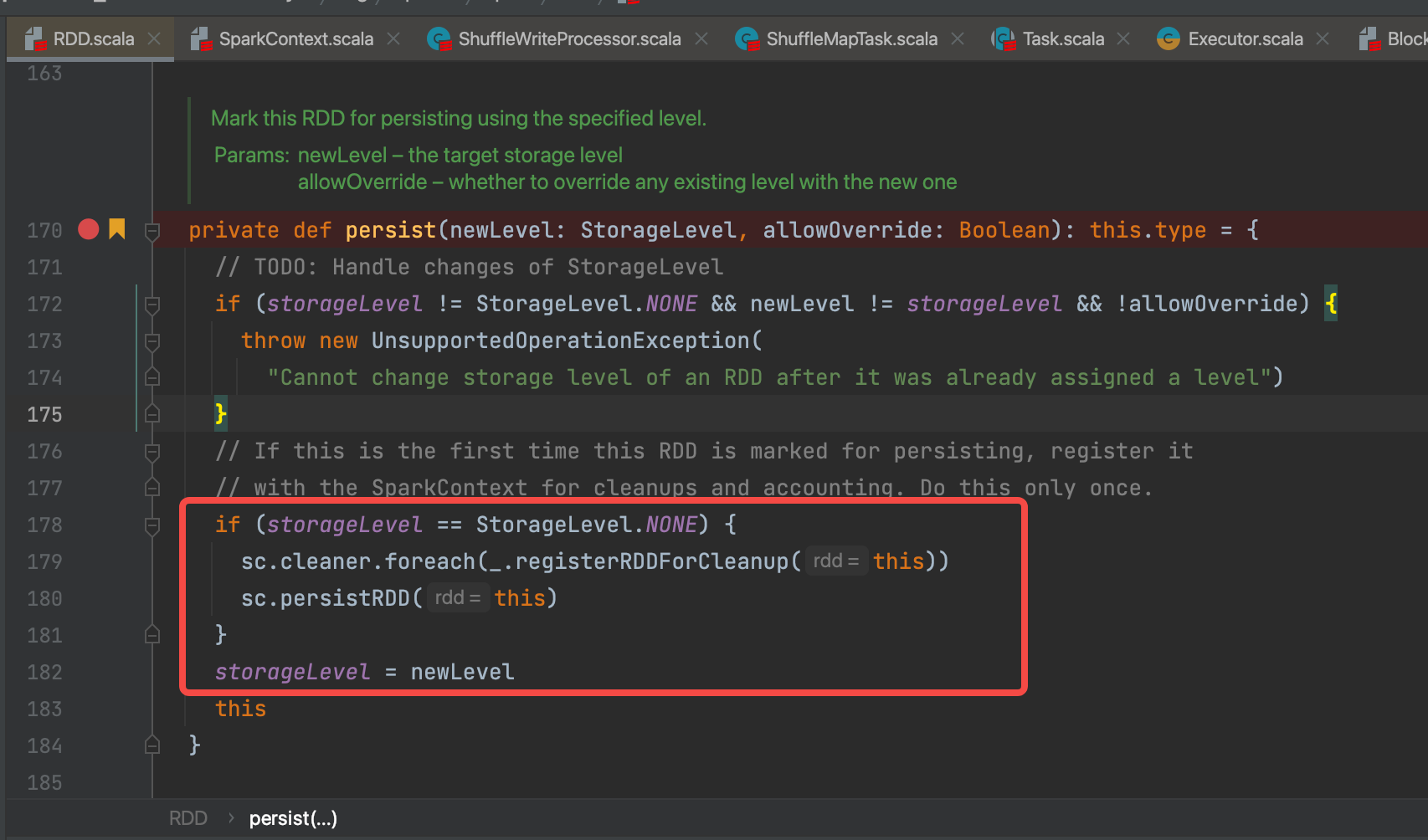
判断如果rdd自身的存储级别为None(默认值),那就说明该rdd没有进行缓存过,就调用sc.persistRDD()进行rdd缓存的注册,注册完毕更新自身的缓存级别StorageLevel。
sc.persistRDD()是将rdd添加到map里面,方便后续直接获取使用。persistentRdds在sparkContext中记录了所有持久化的rdd。
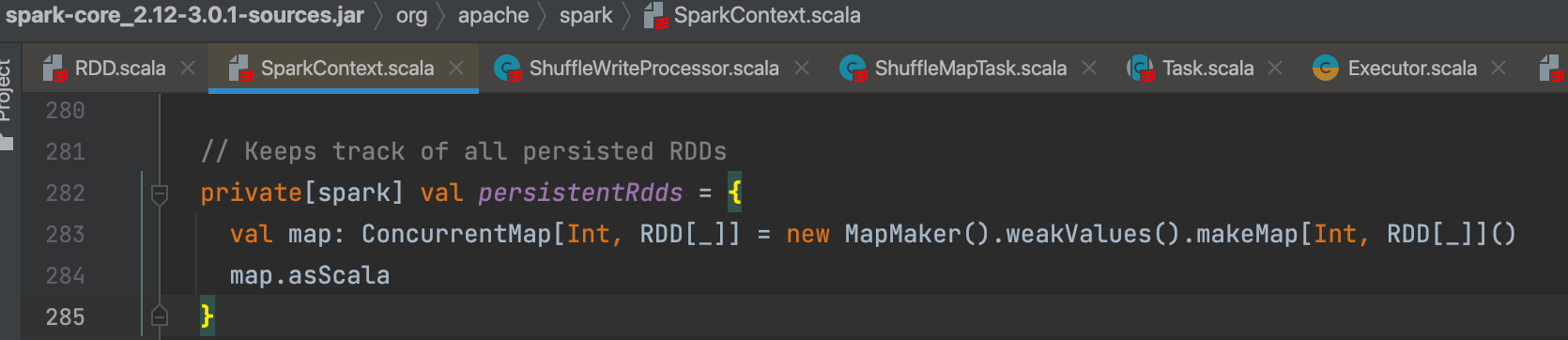
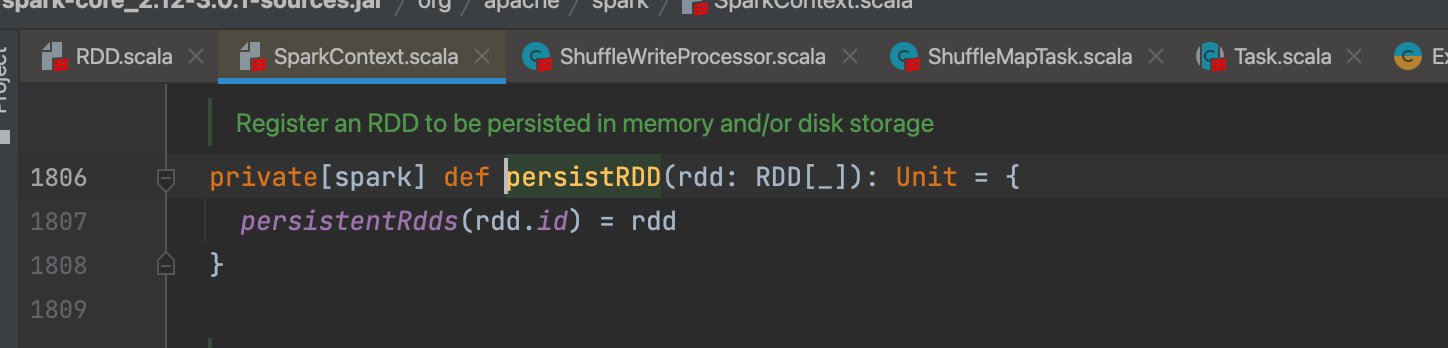
sc.persist()完成,只是给rdd打了一个缓存标记。
在action算子触发下,rdd开始便利获取数据,此时才开始正式持久化。
storageLevel已经变成对应的缓存级别,所以走getOrCompute(split, context)
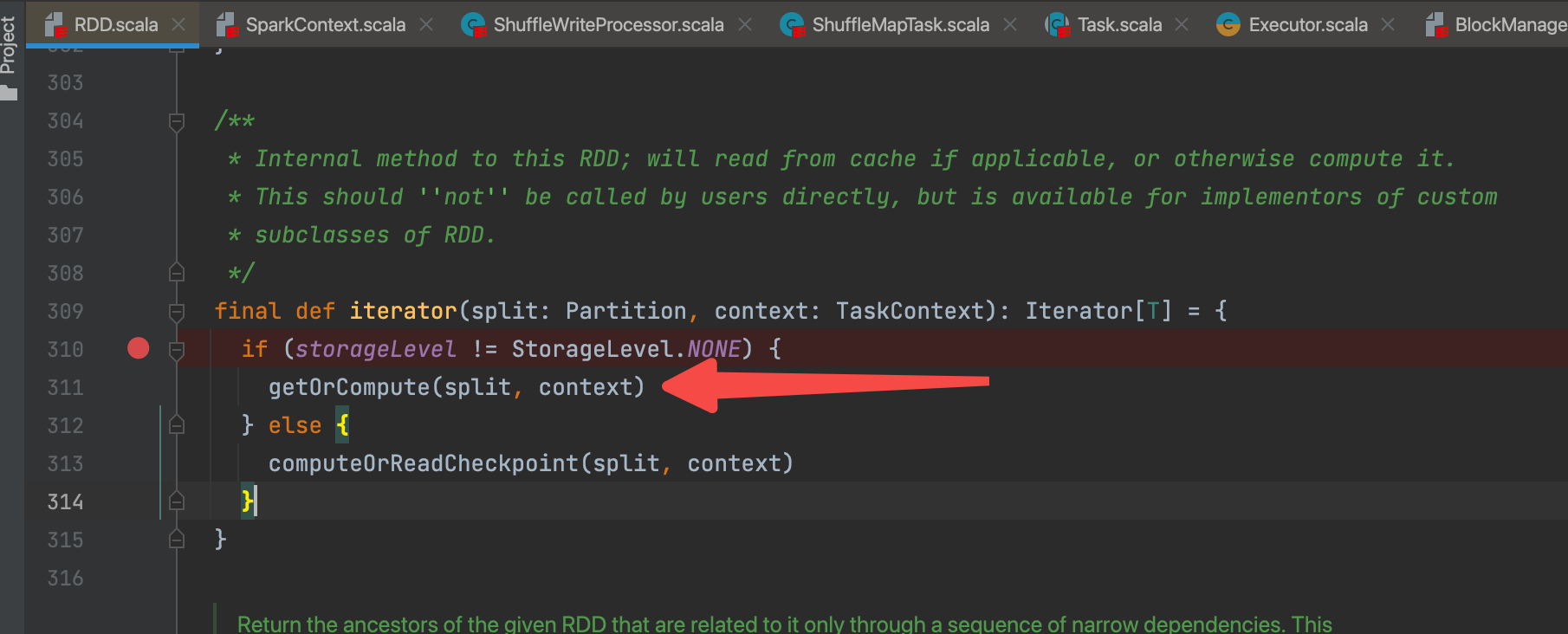
生成blockId,调用SparkEnv.get.blockManager.getOrElseUpdate方法
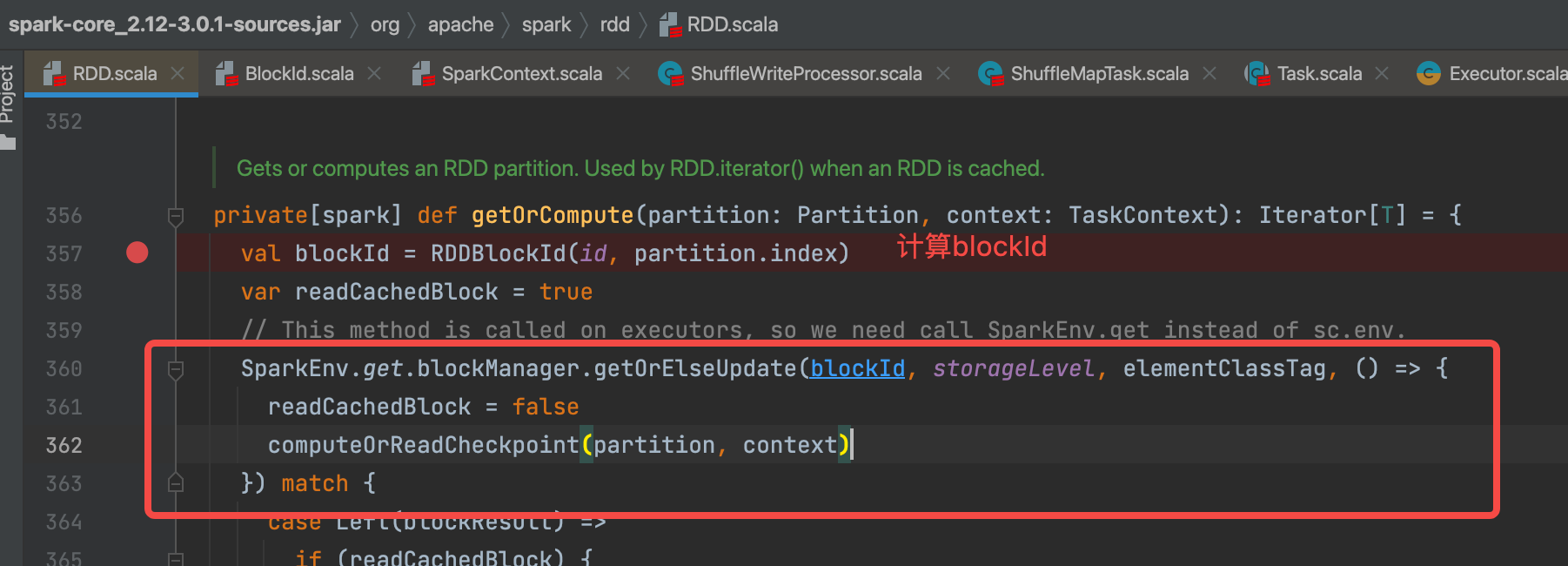
getT(classTag)是先从缓存中获取,没有的话走doPutIterator(blockId, makeIterator, level, classTag, keepReadLock = true)生成iterator。
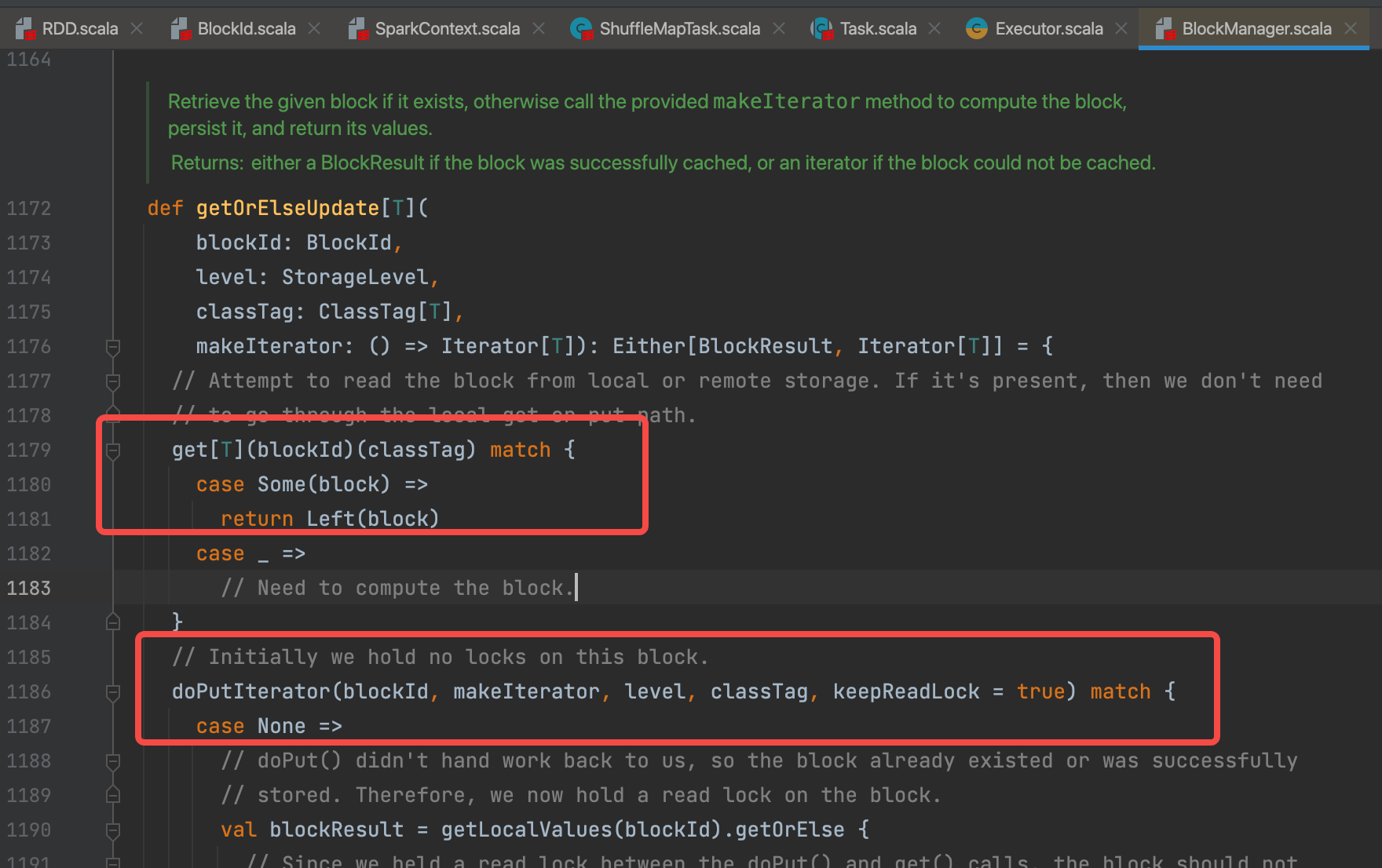
调用doPut缓存数据。{info => …}是doPut的一个参数。
val res = putBody(putBlockInfo)。putBody就是{info => …}
memoryStore.putIteratorAsValues(blockId, iterator(), classTag) 因为持久化到内存,调用memoryStore缓存数据。
返回值是var iteratorFromFailedMemoryStorePut: Option[PartiallyUnrolledIterator[T]] = None。
全部缓存成功 iteratorFromFailedMemoryStorePut还是None,
没有全部缓存iteratorFromFailedMemoryStorePut就是没有缓存的数据的iterator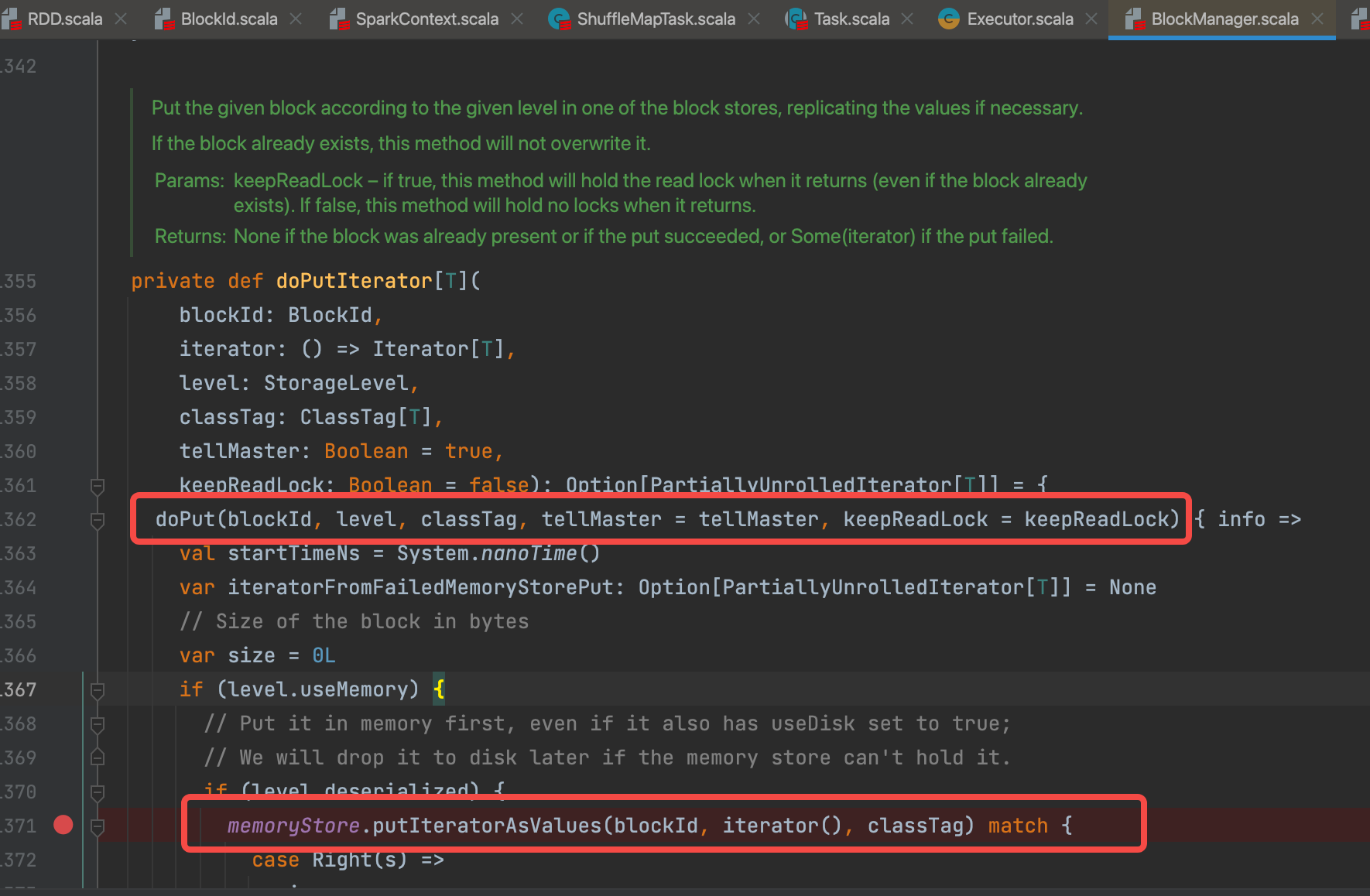
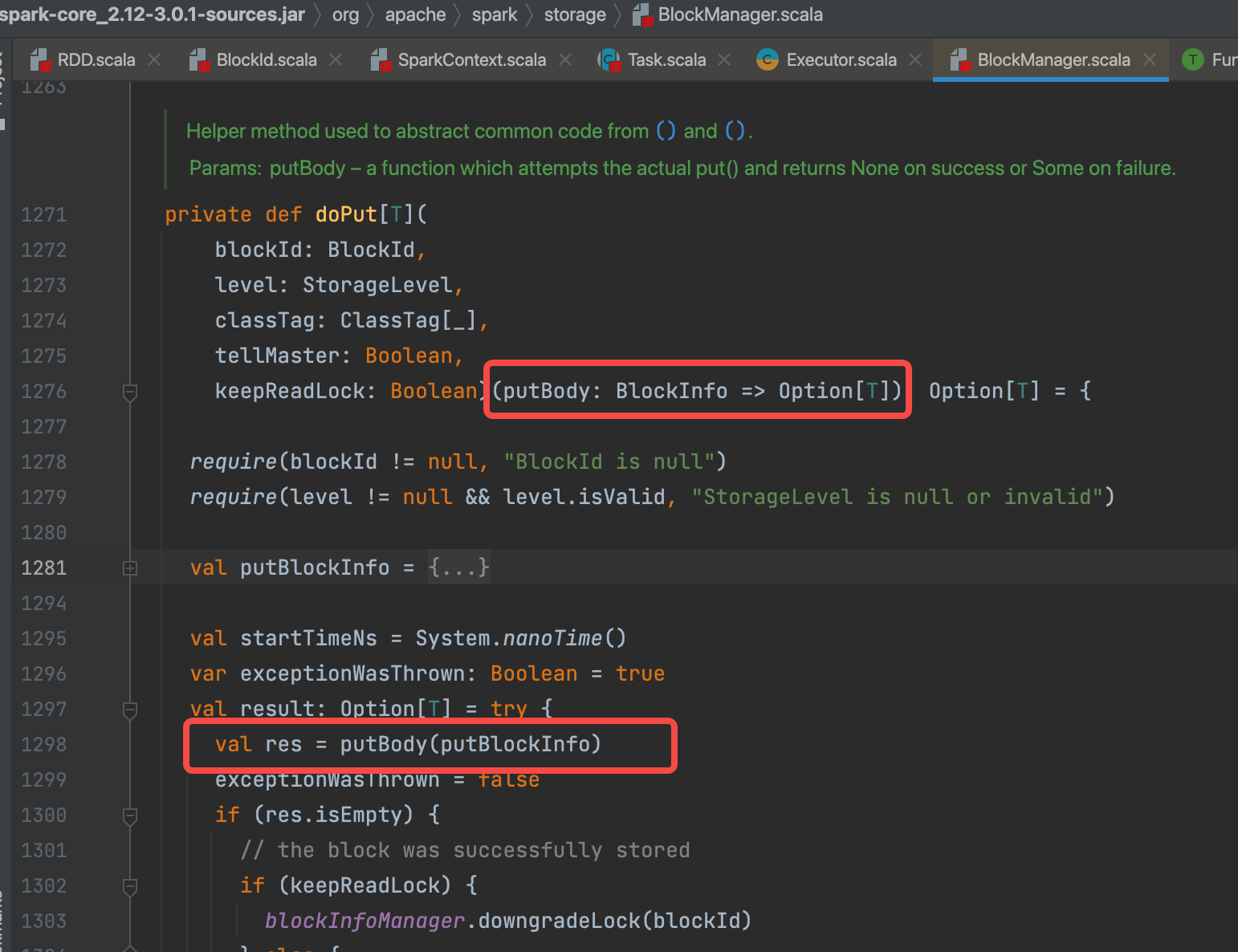
doPutIterator返回值如果是None,代表全部缓存成功,getLocalValues(blockId).getOrElse获取数据,返回Left(iter)
返回值是Some(iter),代表没有缓存成功,返回Right(iter)
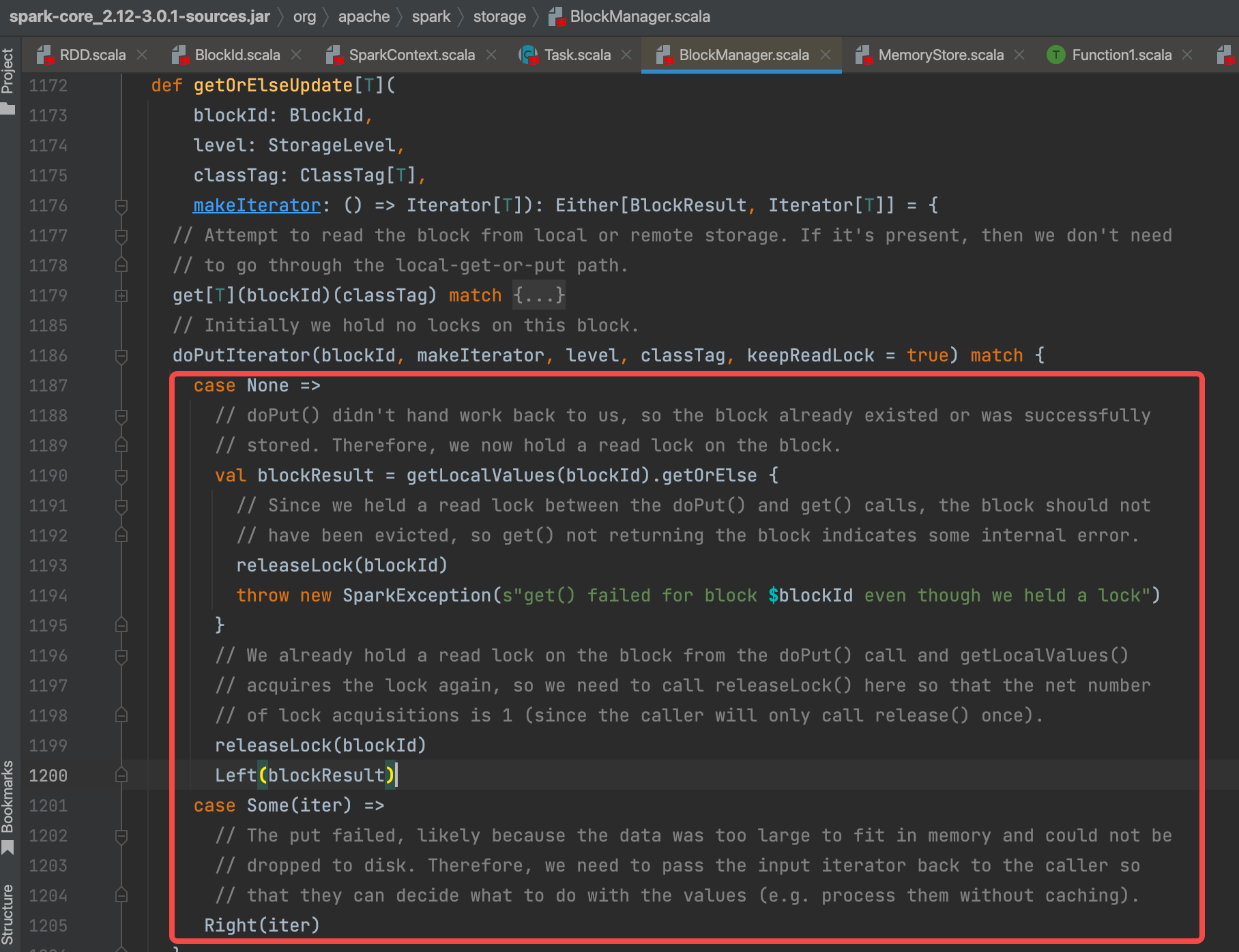
checkpoint算子
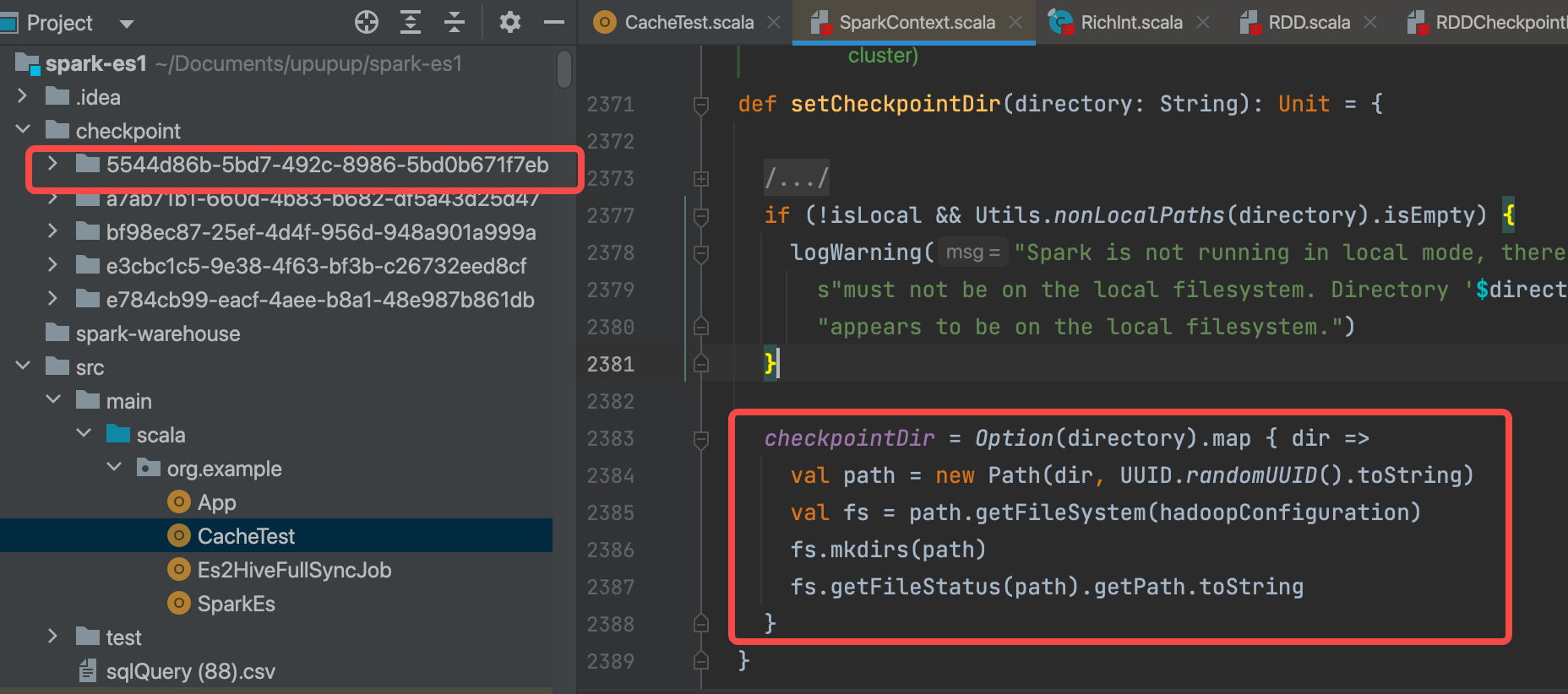
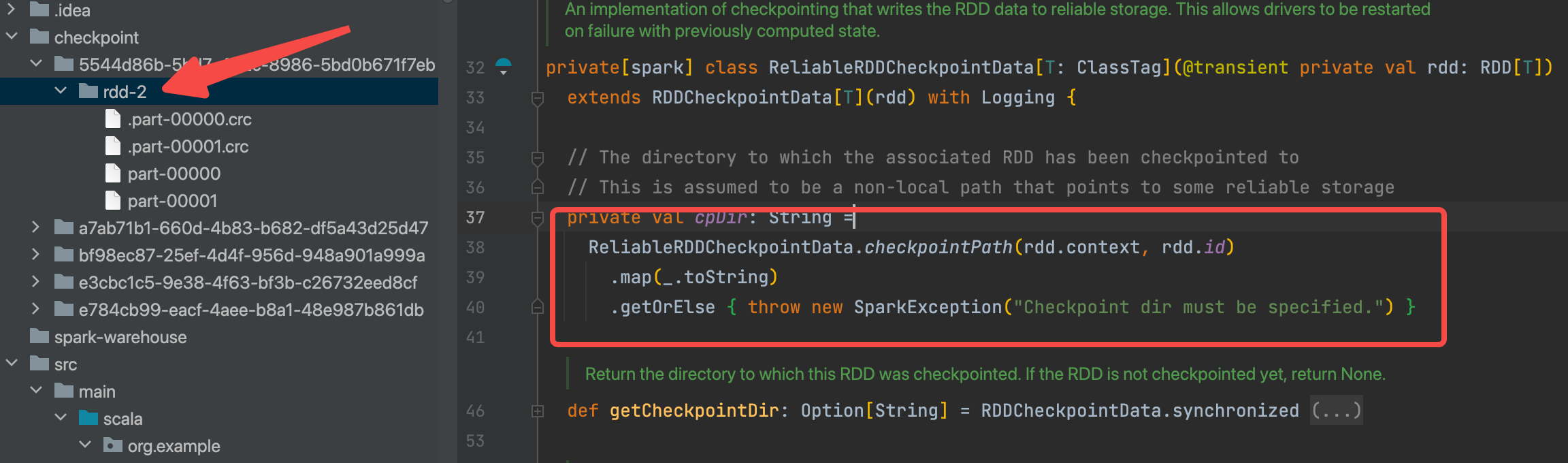
1.sc.setCheckpointDir(“./checkpoint”)
生成目录(checkpoint/5544d86b-5bd7-492c-8986-5bd0b671f7eb),并存到checkpointDir变量
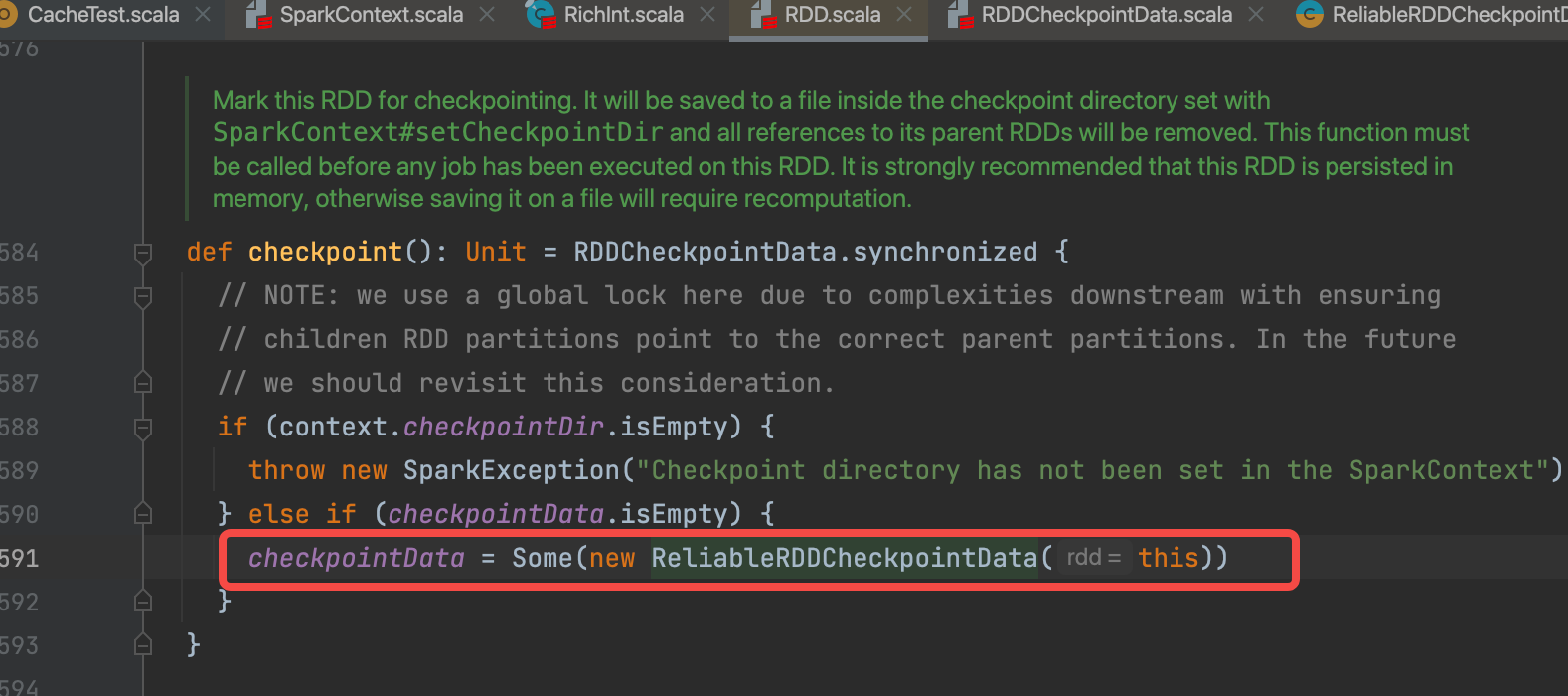
2.mapRdd.checkpoint()
生成一个ReliableRDDCheckpointData对象,赋值给当前的rdd的checkpointData变量。ReliableRDDCheckpointData中cpDir变量最重要,就是rdd-2这个目录。
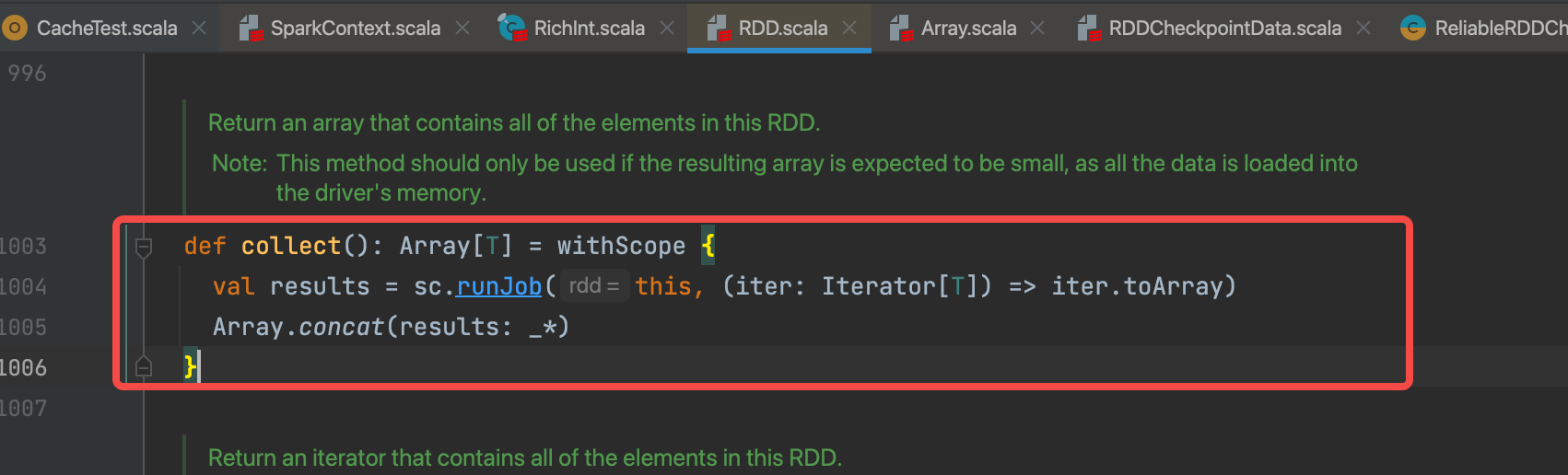
3.reduceRdd.collect()
collect算子触发checkpoint。核心是runJob()
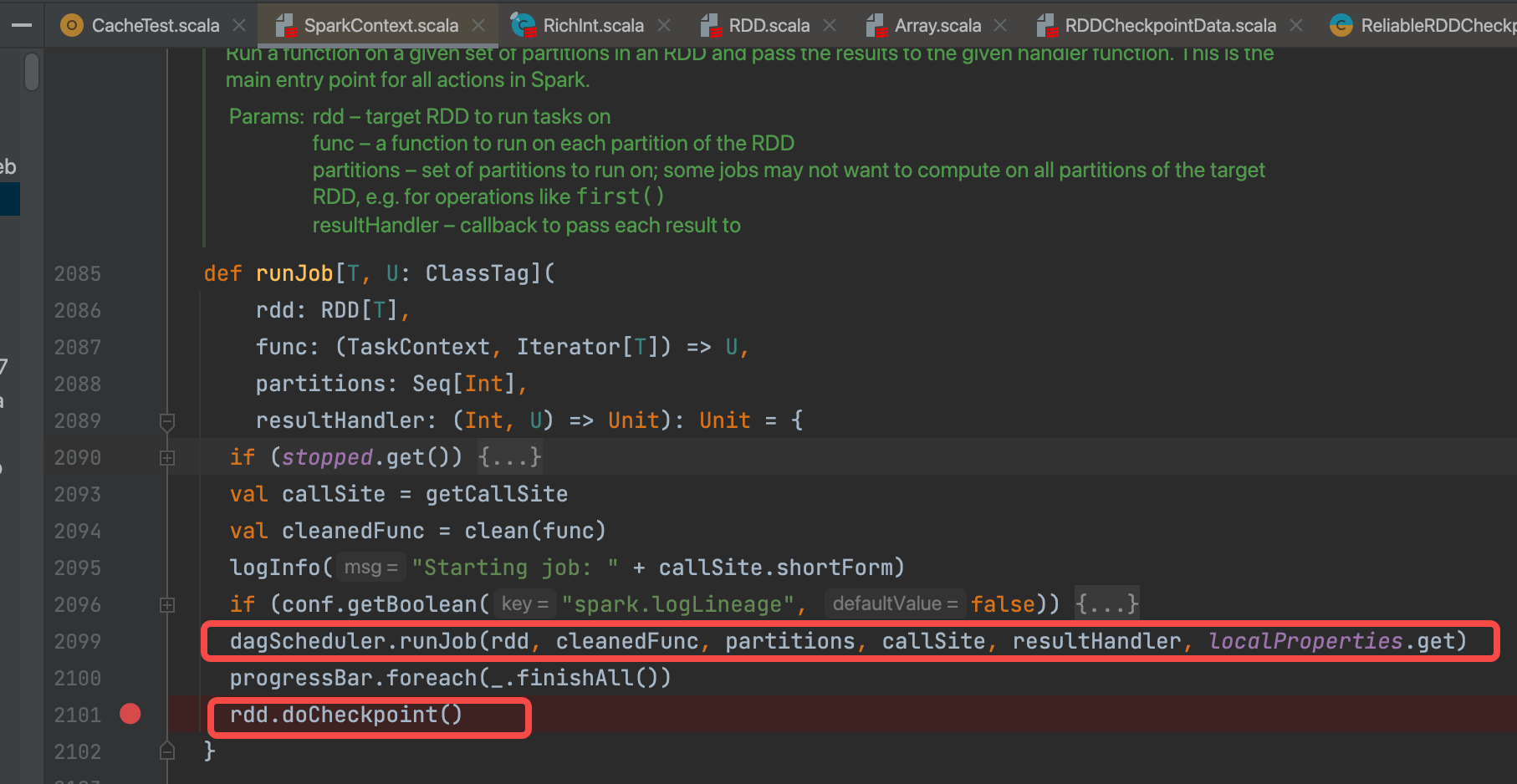
runJob中dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)表示调度执行,开始rdd的计算。
rdd.doCheckpoint()是rdd的checkpoint的部分。主要看这一部分。
从尾部开始向上遍历rdd,找到需要checkpoint的子rdd,子rdd的checkpointData变量在前面已经赋值了,对它进行checkpoint。
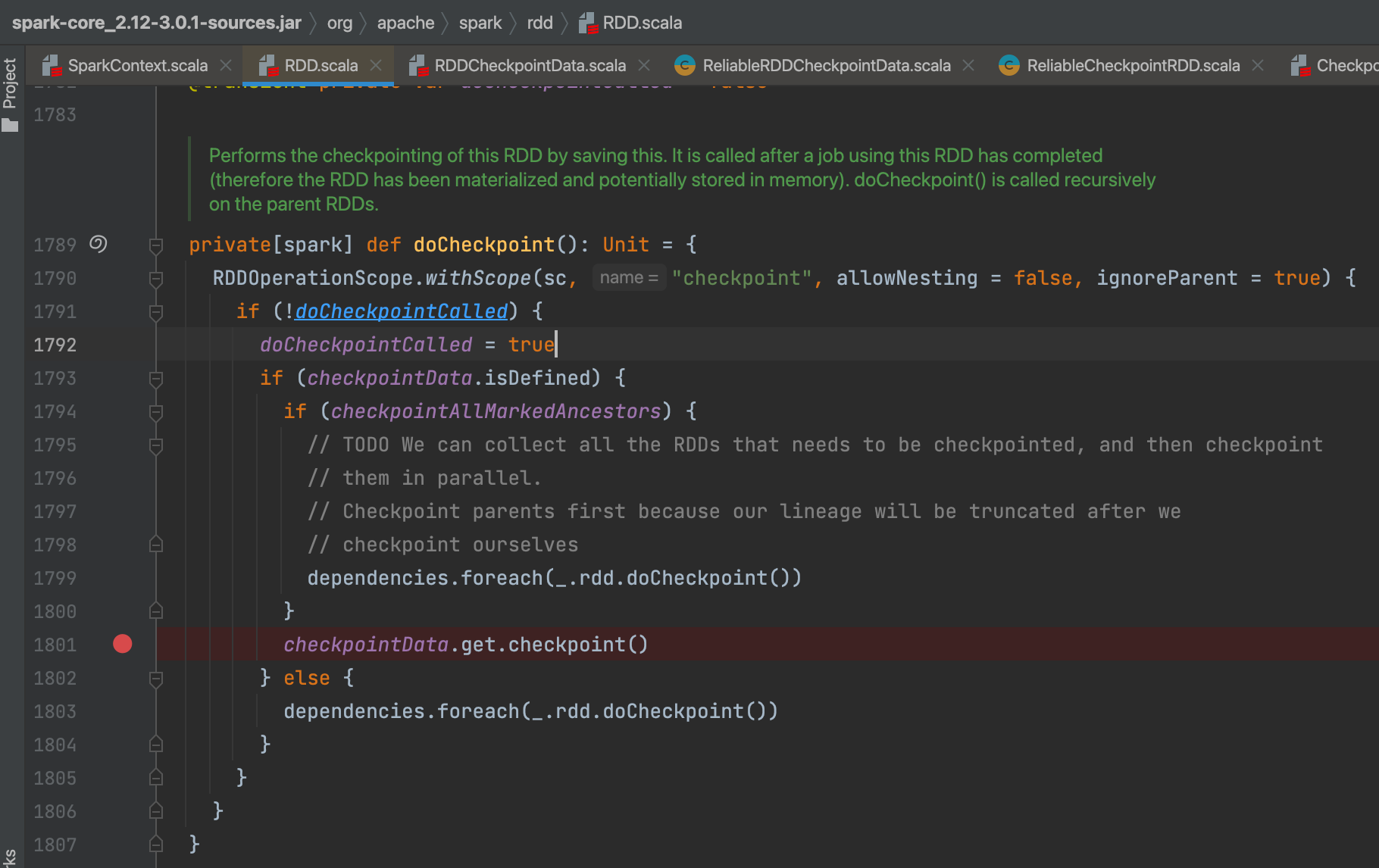
变更cpState状态为 CheckpointingInProgress,标志正在进行checkpoint。完成后,变更状态为 Checkpointed,标志checkpoint完成。用cpState变量避免同一个rdd多次checkpoint。
val newRDD = doCheckpoint() 这个是checkpoint的具体过程
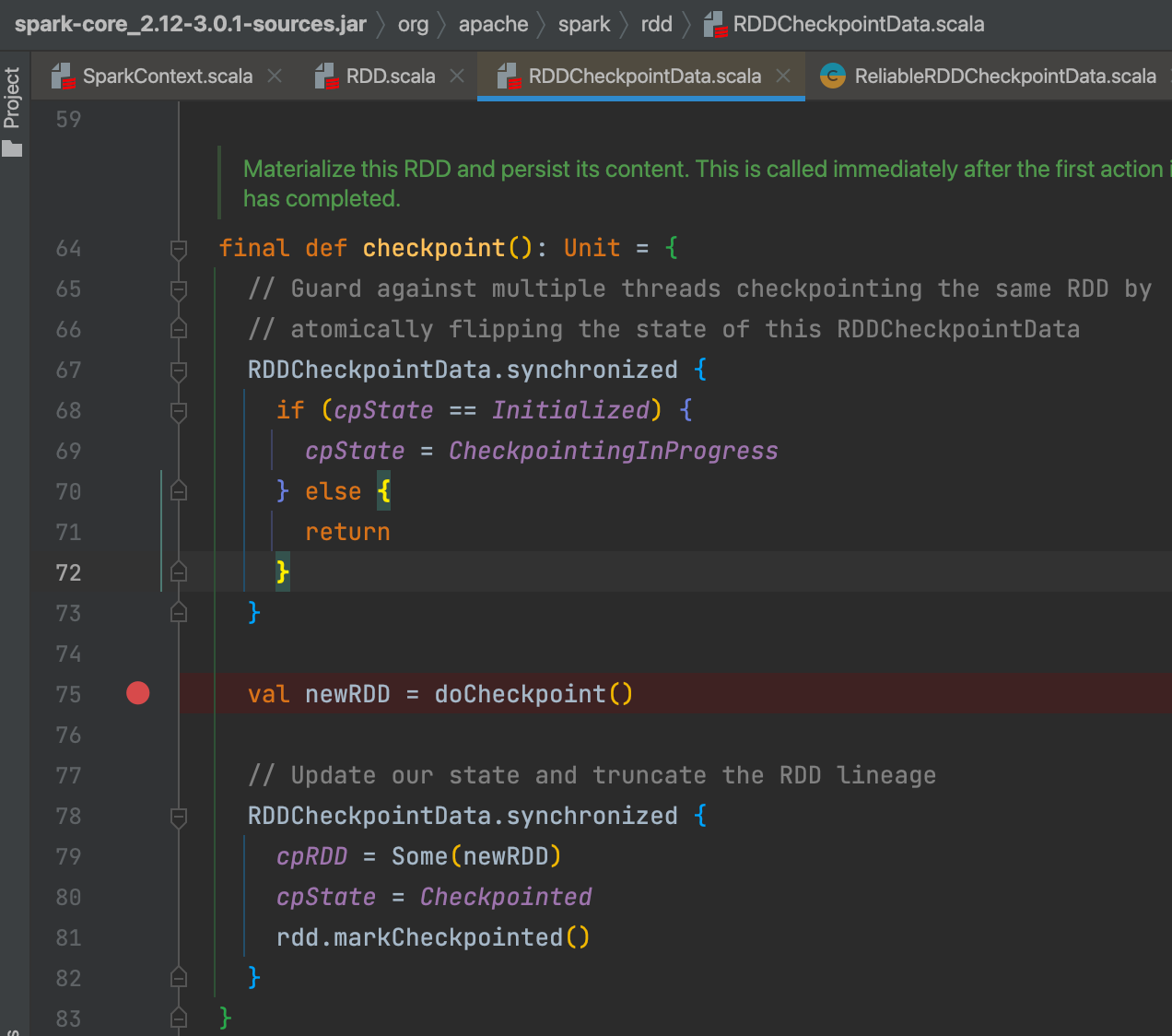
具体实现是 ReliableRDDCheckpointData。
val newRDD = ReliableCheckpointRDD.writeRDDToCheckpointDirectory(rdd, cpDir)
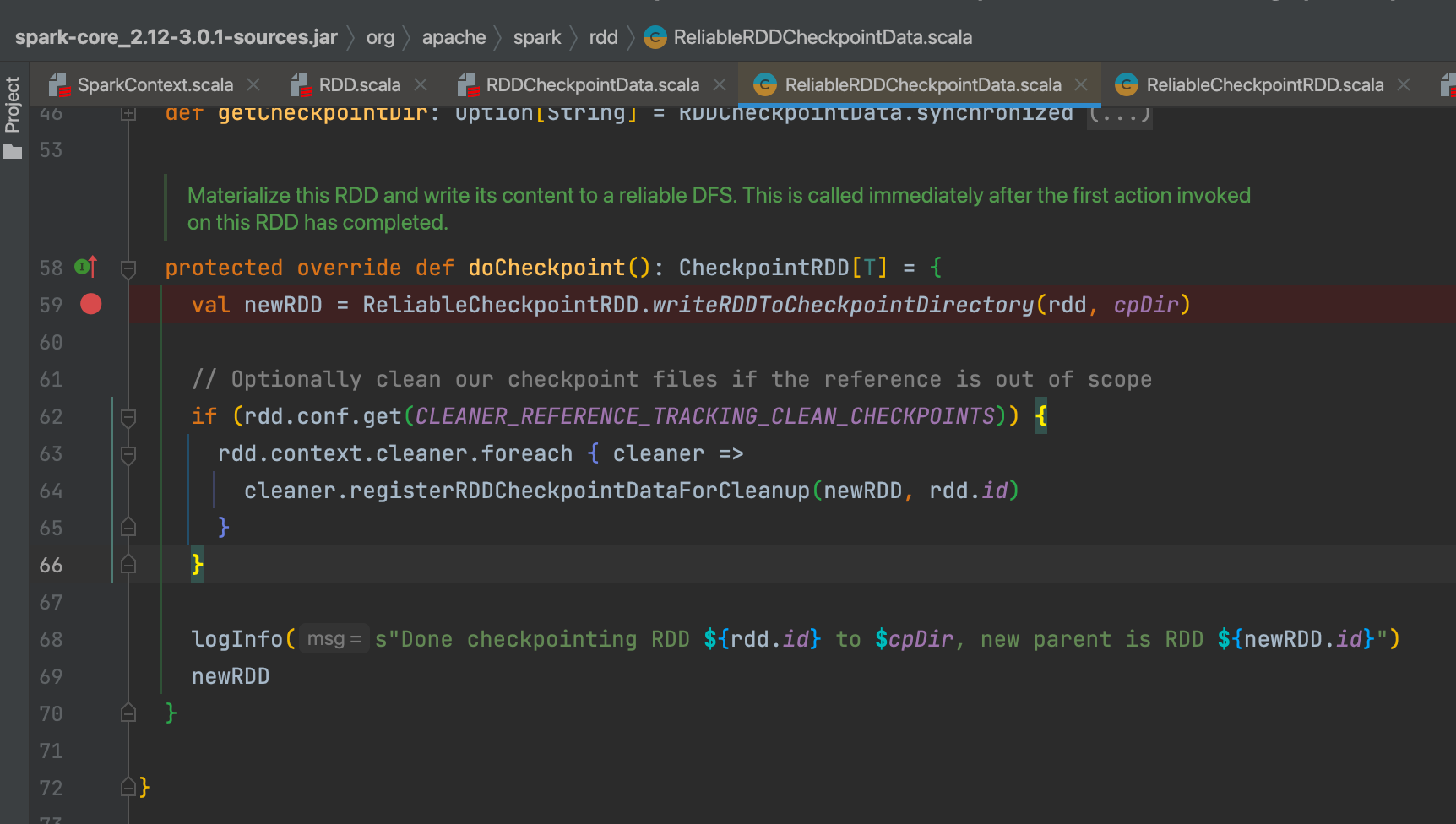
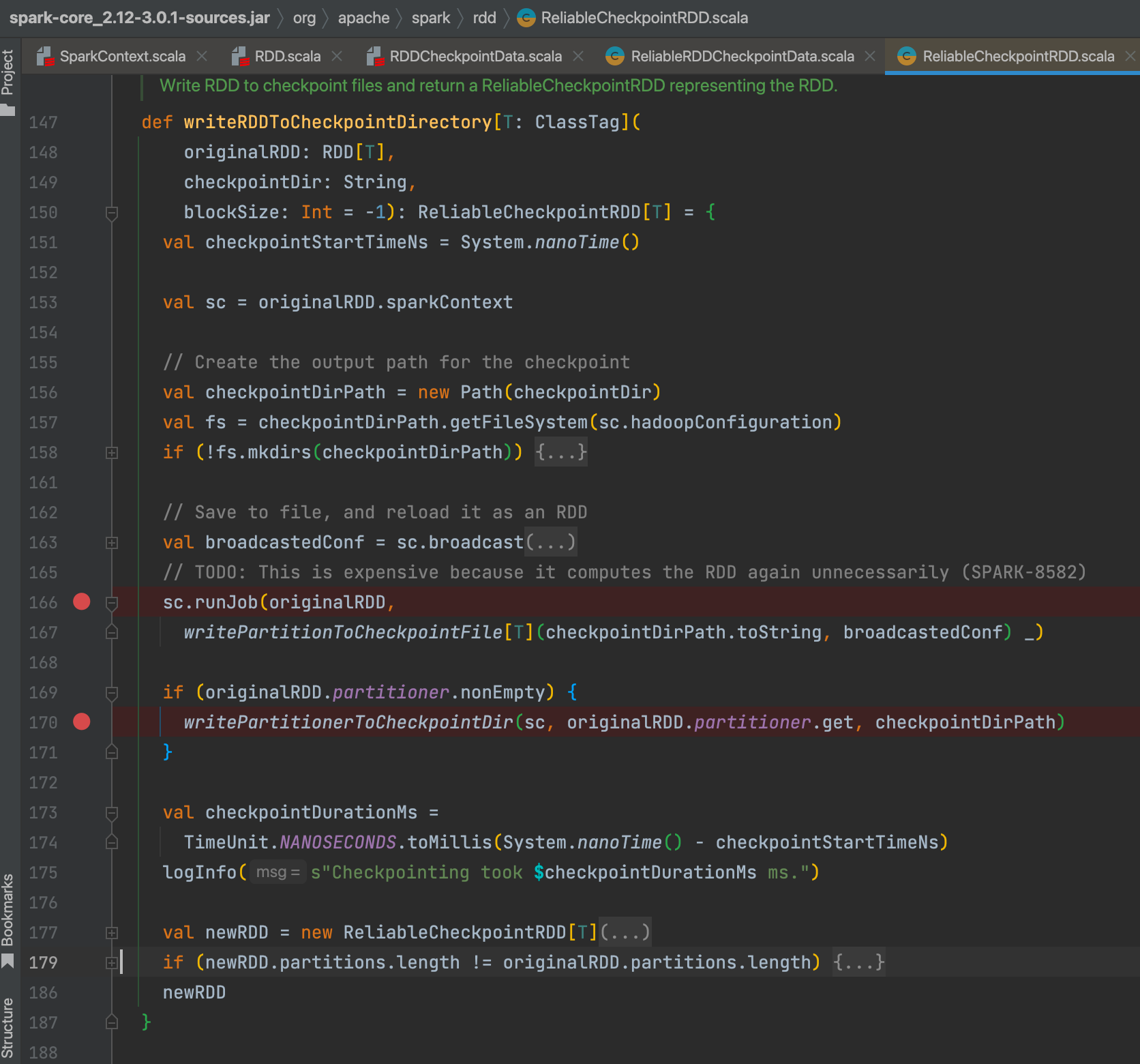
sc.runJob(originalRDD,writePartitionToCheckpointFile[T](checkpointDirPath.toString, broadcastedConf) _)
再次提交任务,表明checkpoint的时候rdd会多计算一次。
writePartitionToCheckpointFile 生产文件
writePartitionerToCheckpointDir 将文件写入对应目录
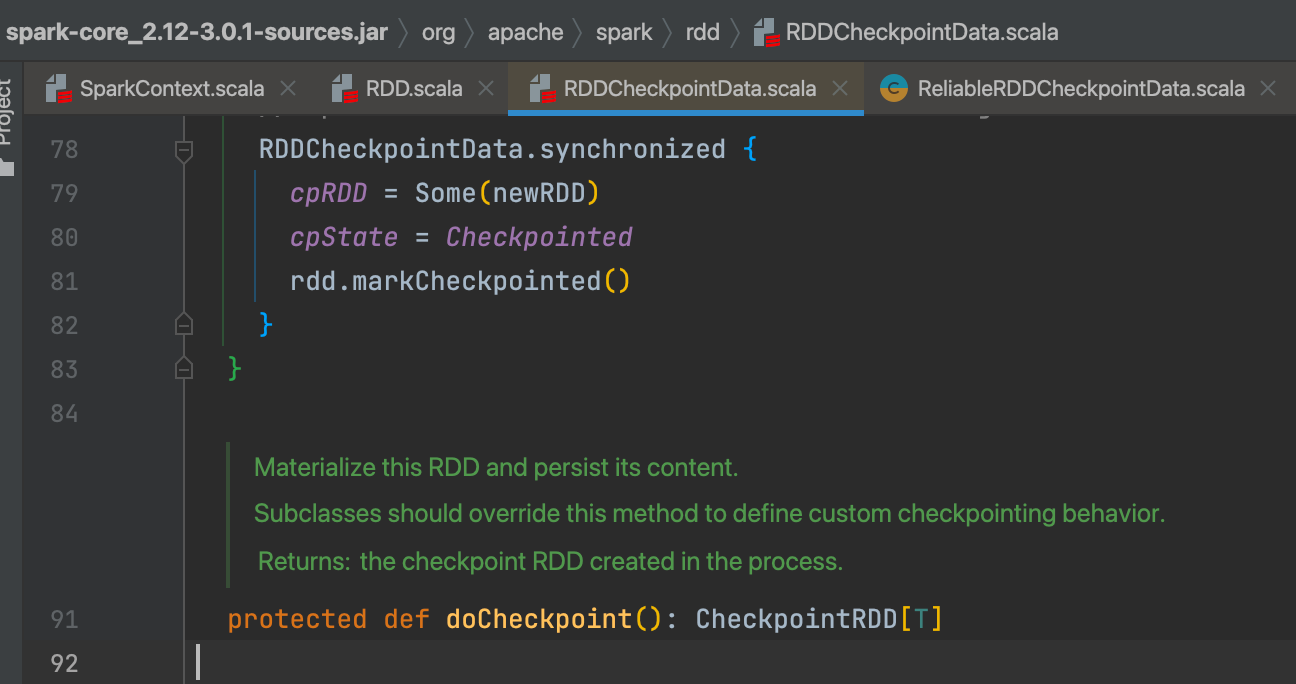
val newRDD = new ReliableCheckpointRDD[T](sc, checkpointDirPath.toString, originalRDD.partitioner)
生产新的rdd(直接从checkpoint目录读取,不需要再次计算),用来替换原来checkpoint的rdd。
将newRdd保存到 cpRDD变量,更新cpState状态完成
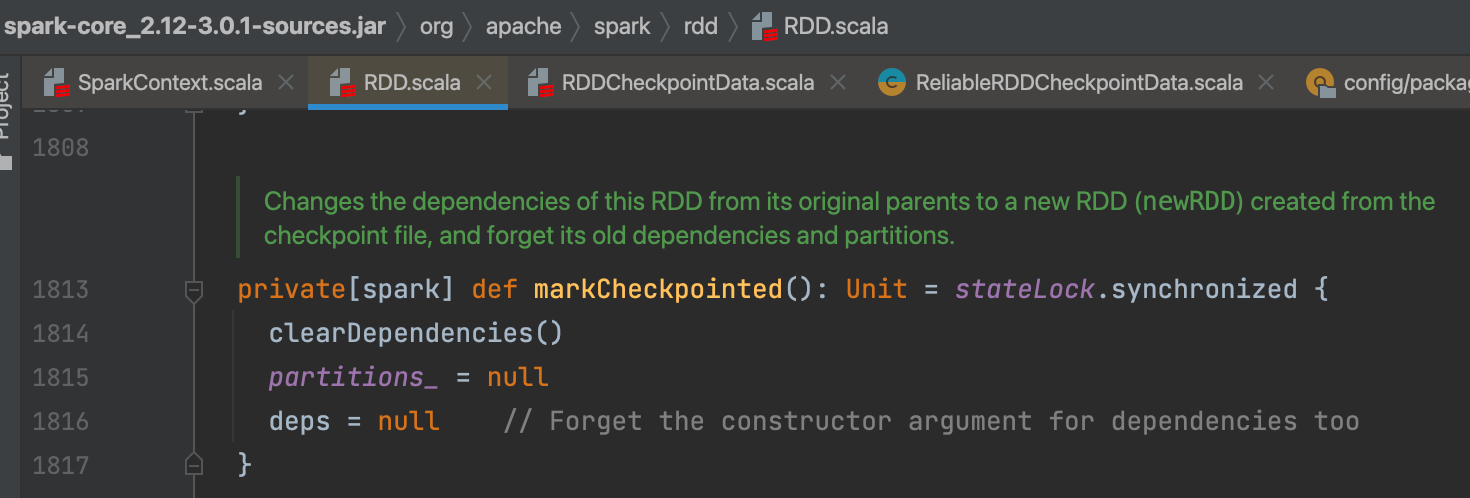
rdd.markCheckpointed() 切断血缘
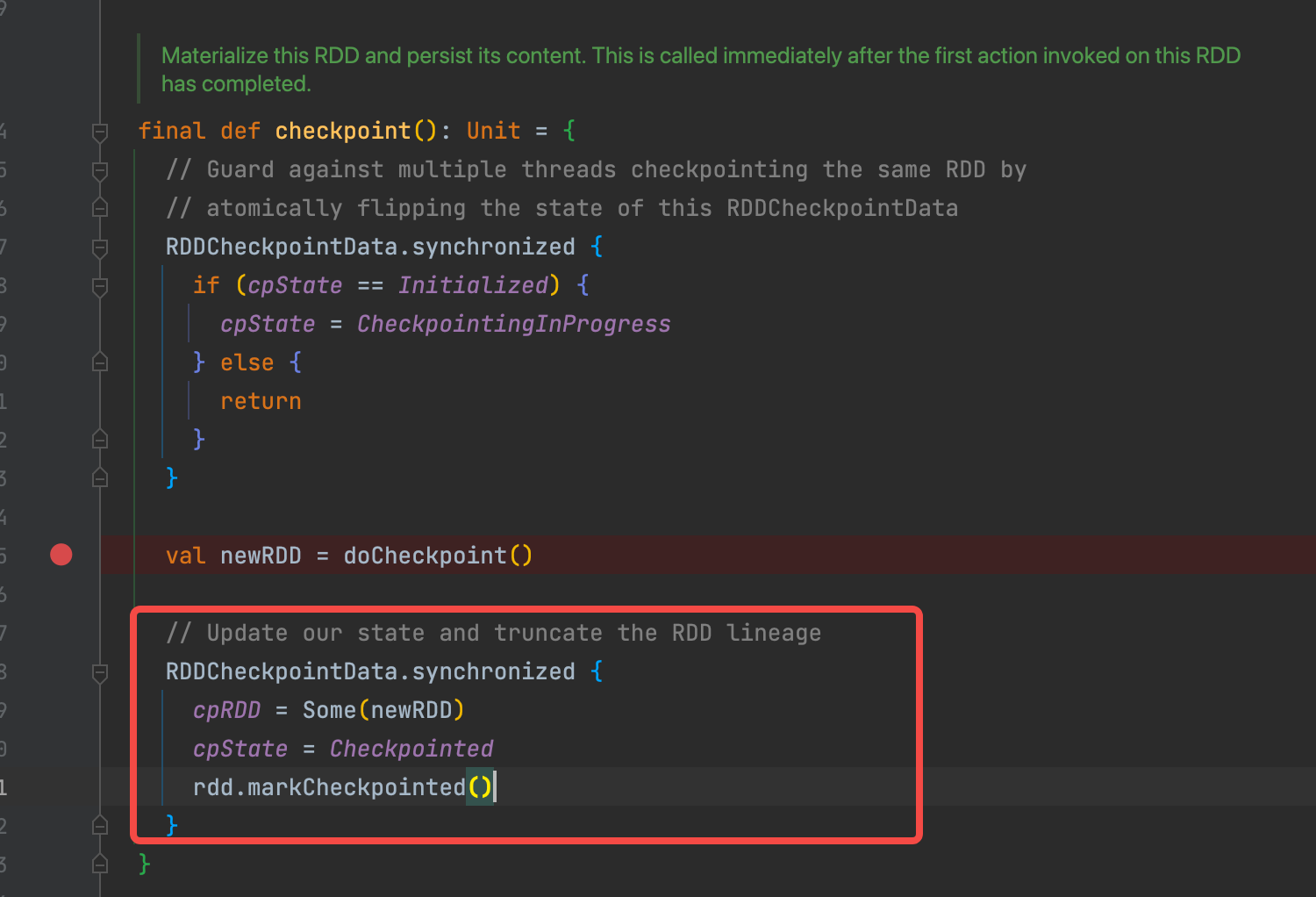
将依赖和分区都置为空,就是切断rdd的血缘
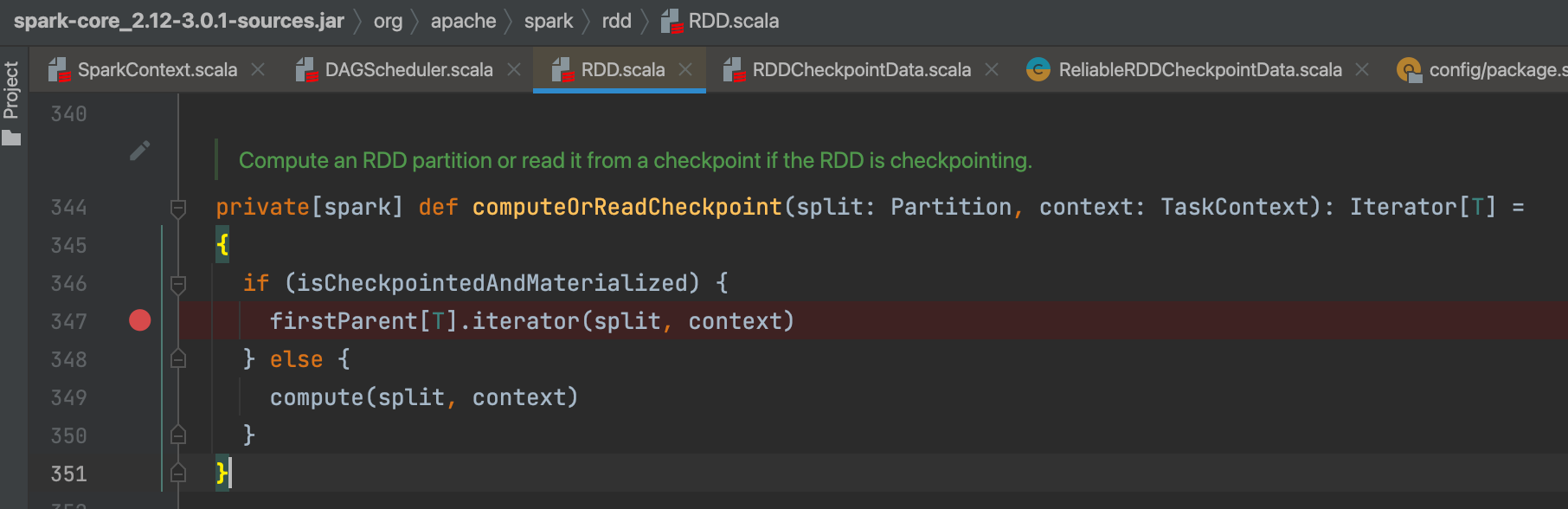
4.checkpoint复用
computeOrReadCheckpoint方法中,判断rdd是否原来checkpoint过。如果是,则使用checkpoint的rdd。
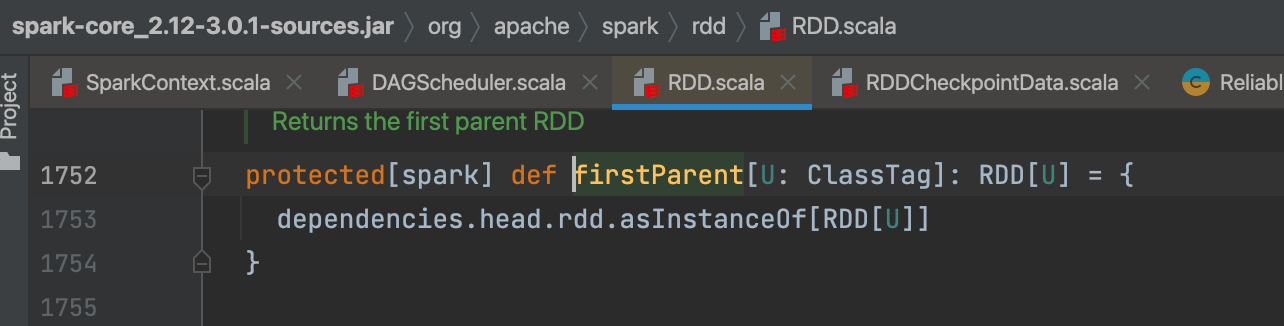
firstParent可以获取到checkpoint的rdd,因为checkpoint完成后会切断血缘,新的rdd就会在头部。

















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









