






借图 https://blog.csdn.net/qq_40640228/article/details/128265115
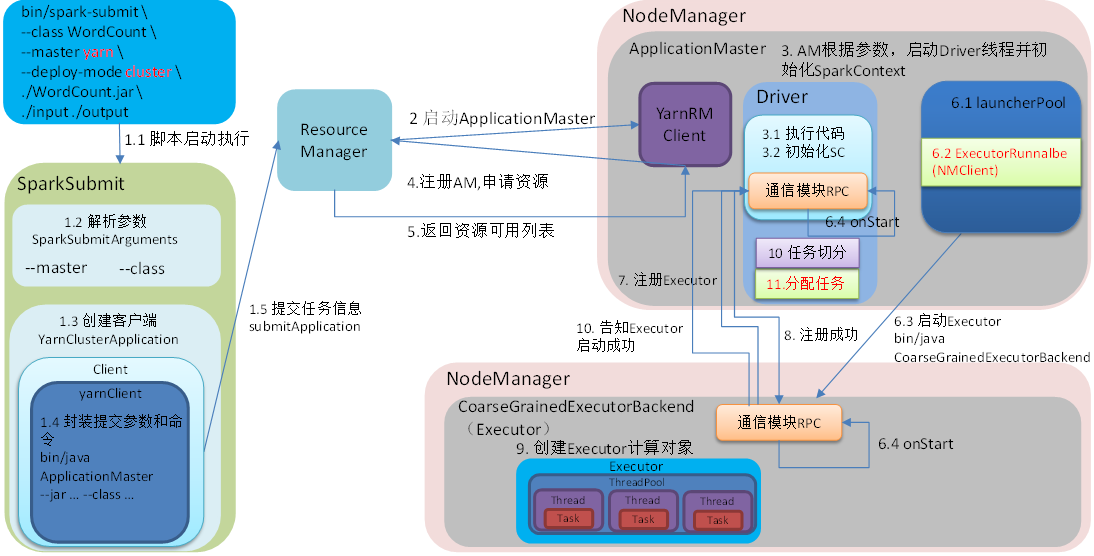
脚本启动执行
脚本入口:spark-submit.sh
spark-submit.sh中调用了spark-class.sh
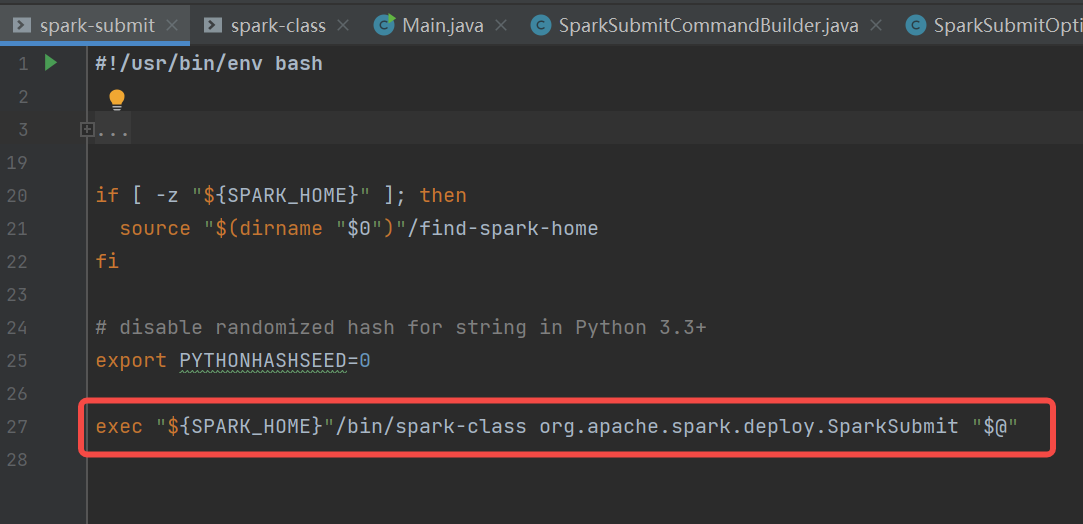
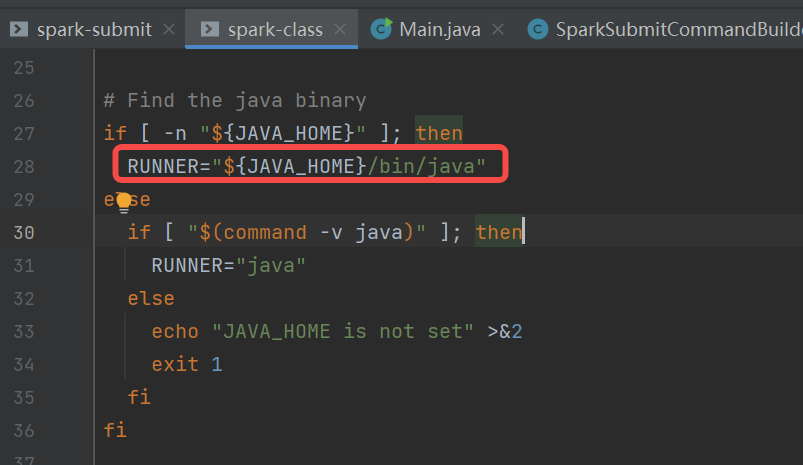
spark-class.sh中首先是找到java的目录,使用org.apache.spark.launcher.Main类生成执行命令,赋值到变量CMD中。使用exec执行CMD
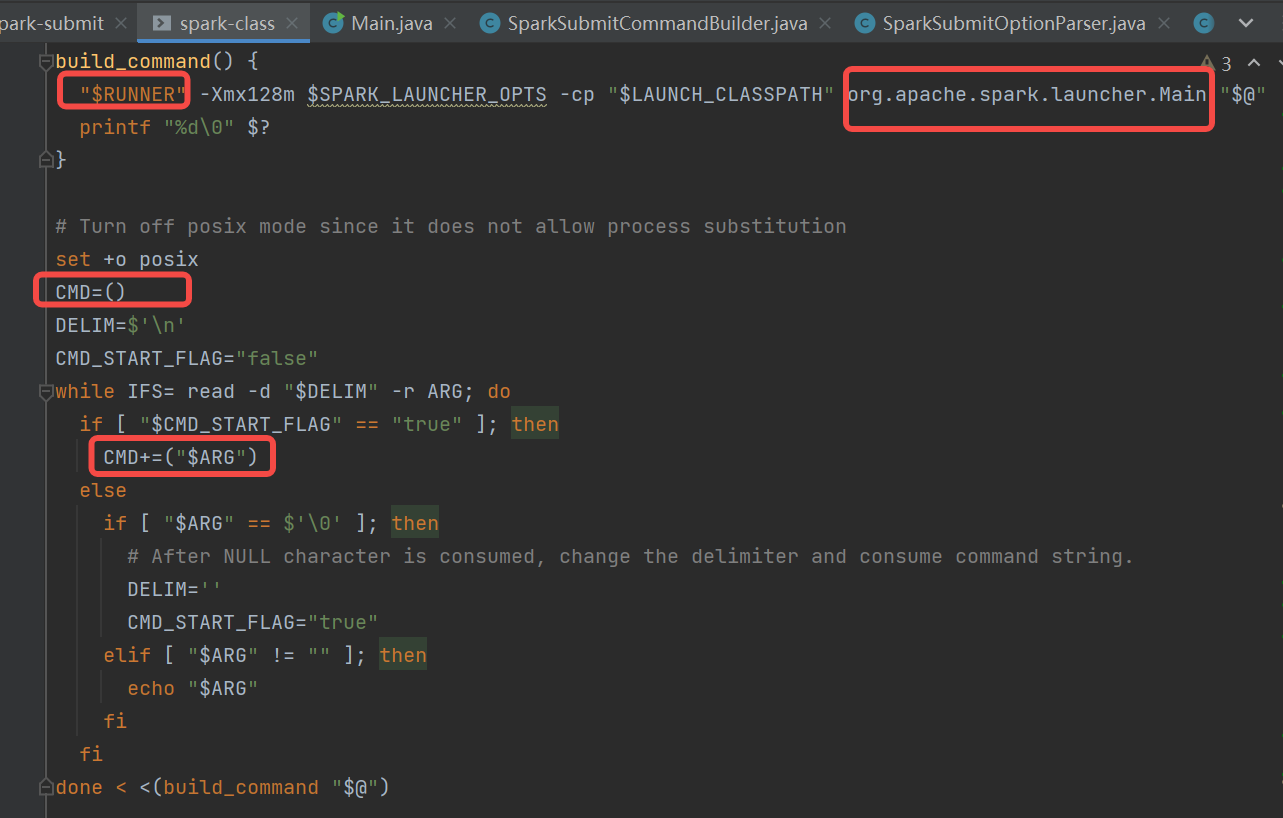
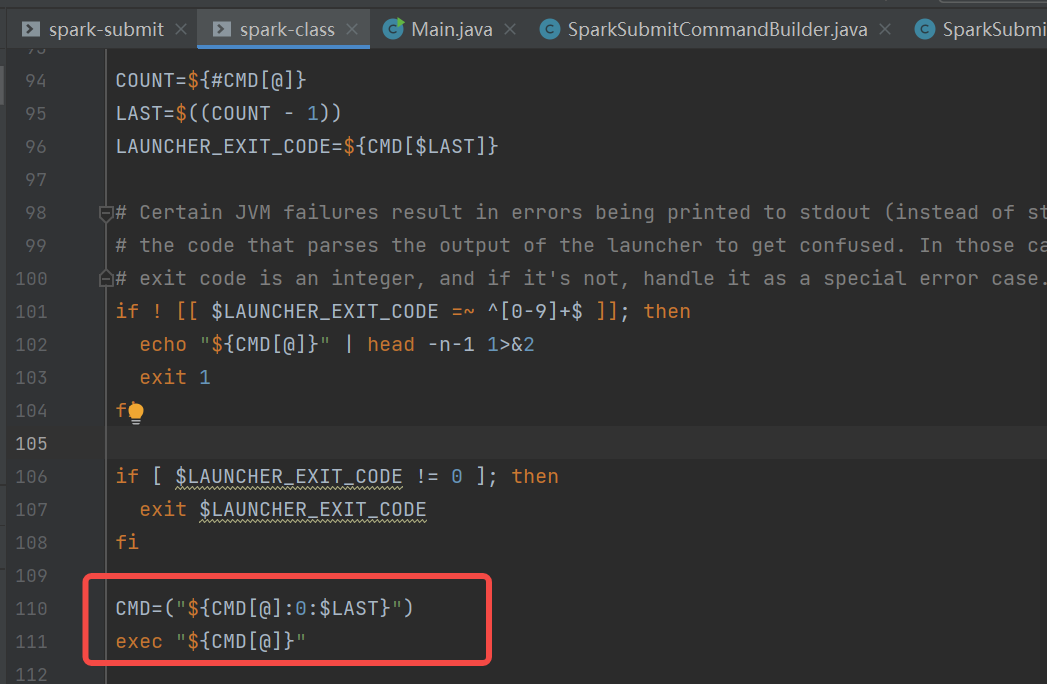
org.apache.spark.launcher.Main
调用buildCommand函数,就是调用builder.buildCommand。builder是SparkSubmitCommandBuilder。
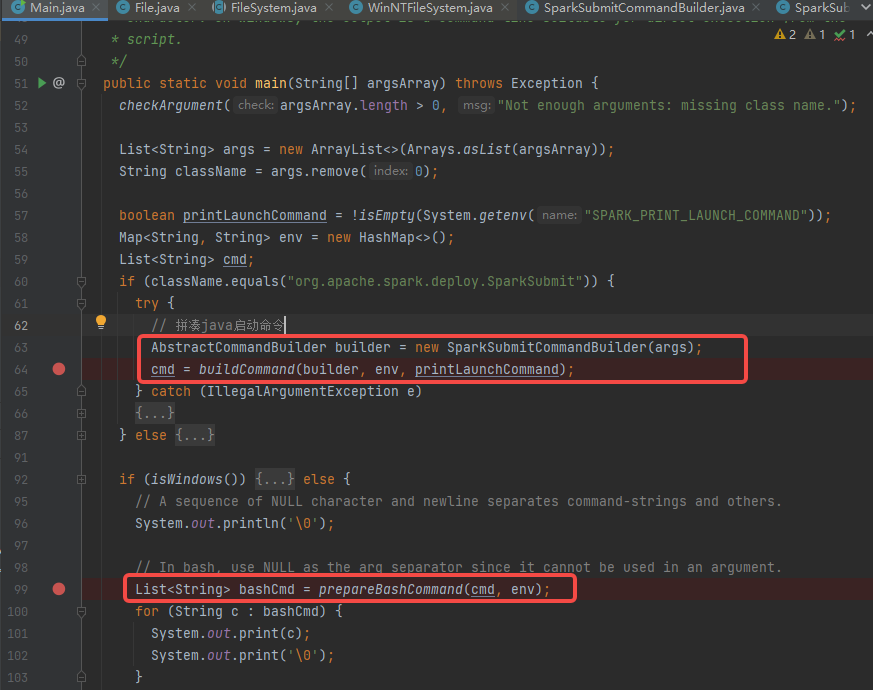
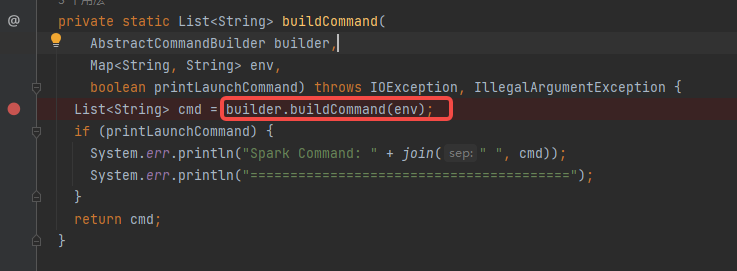
SparkSubmitCommandBuilder
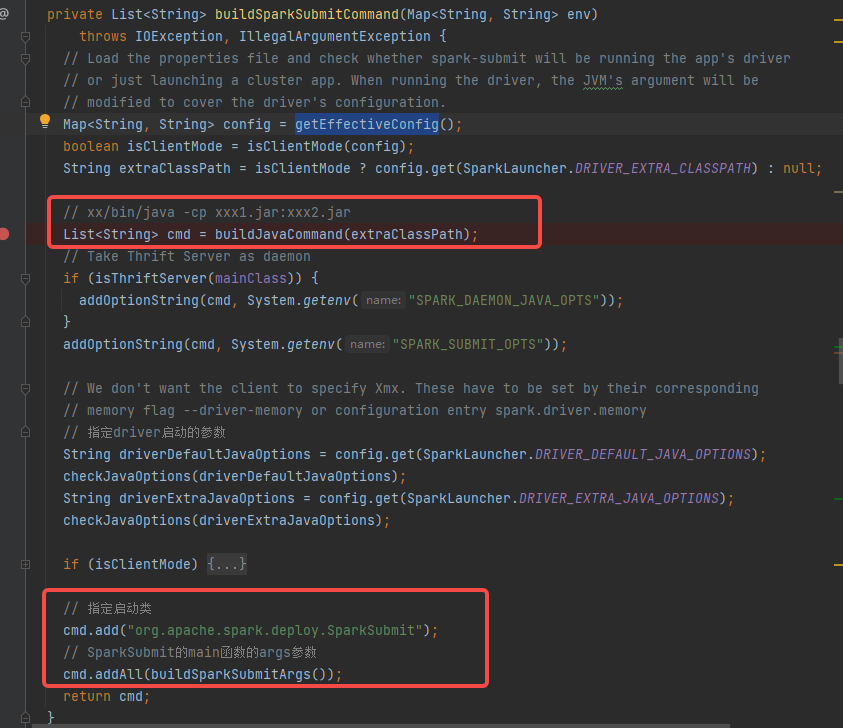
根据参数选择java命令。调用buildSparkSubmitCommand函数
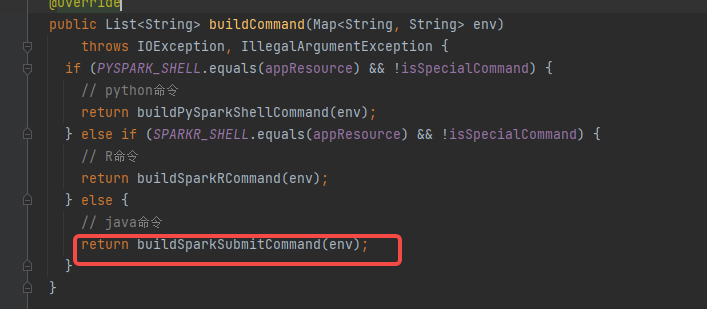
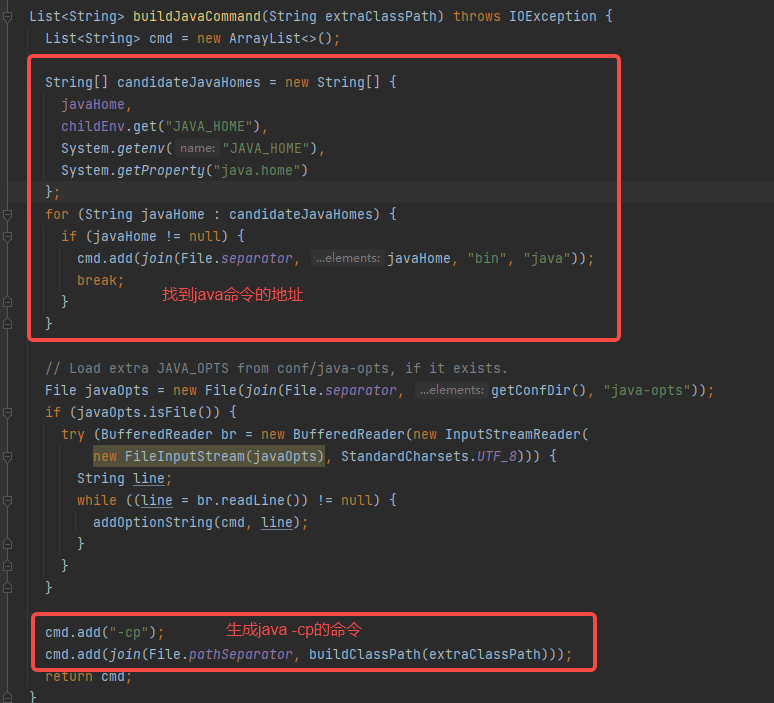
buildSparkSubmitCommand中首先调用buildJavaCommand生成xx/bin/java -cp xxx1.jar:xxx2.jar
后面加上启动类和相关参数。
最后命令:xx/bin/java -cp xxx1.jar:xxx2.jar org.apache.spark.deploy.SparkSubmit arg[0]…
SparkSubmit
可以看到是调用SparkSubmit的doSubmit方法
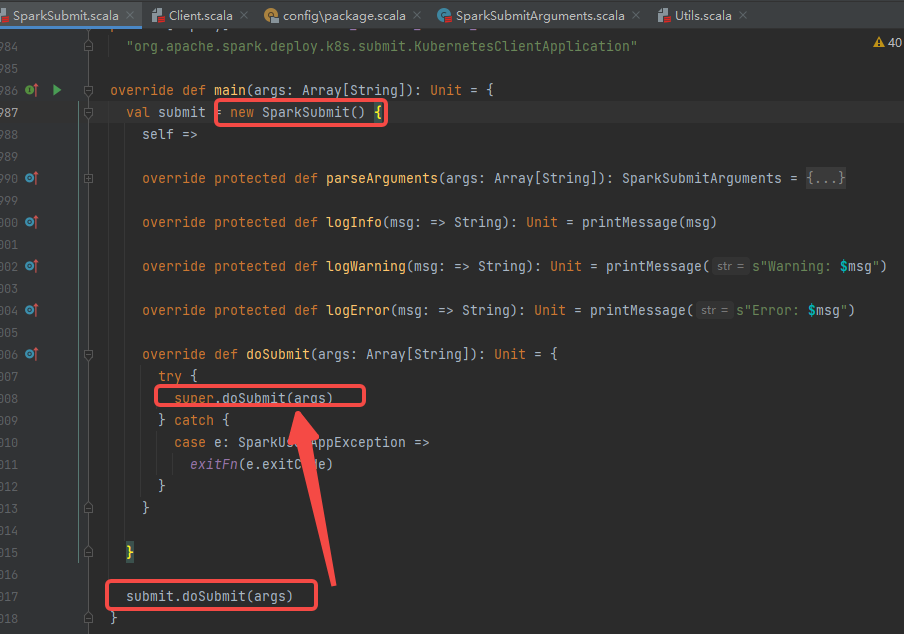
调用submit方法
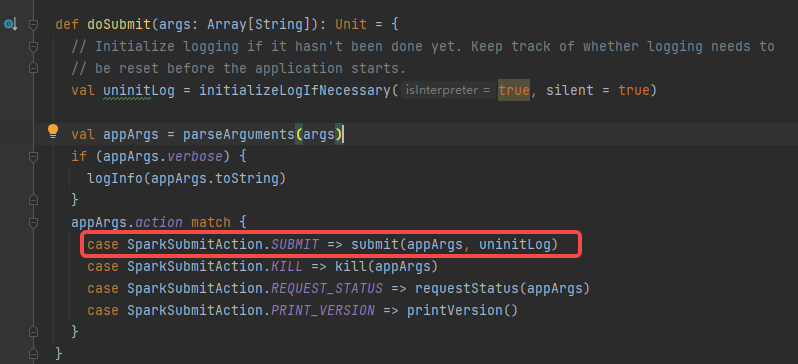
调用runMain方法
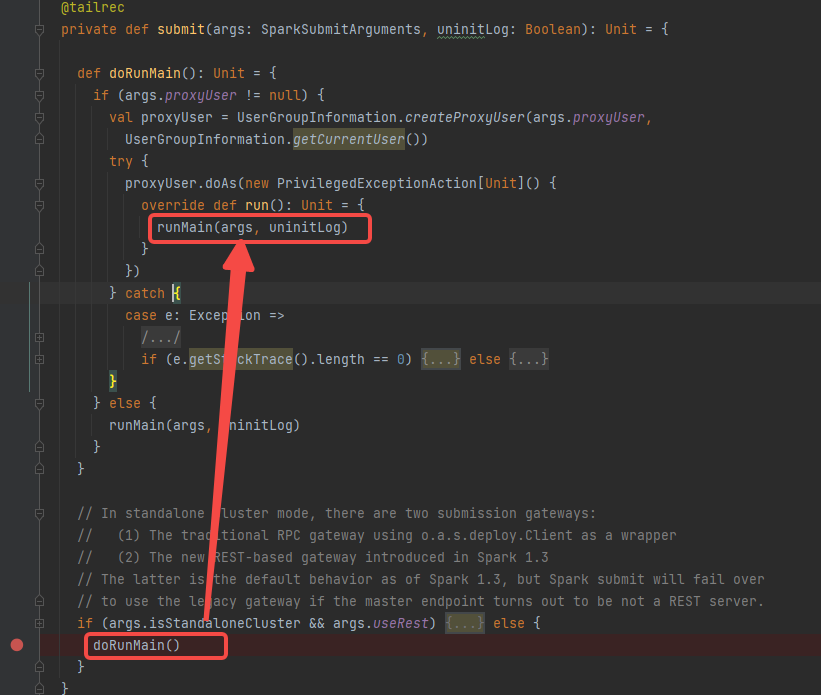
调用prepareSubmitEnvironment获取到childArgs, childClasspath, sparkConf, childMainClass。
根据childMainClass创建SparkApplication对象,因为是yarn集群模型,所以是YarnClusterApplication
调用YarnClusterApplication的start方法。
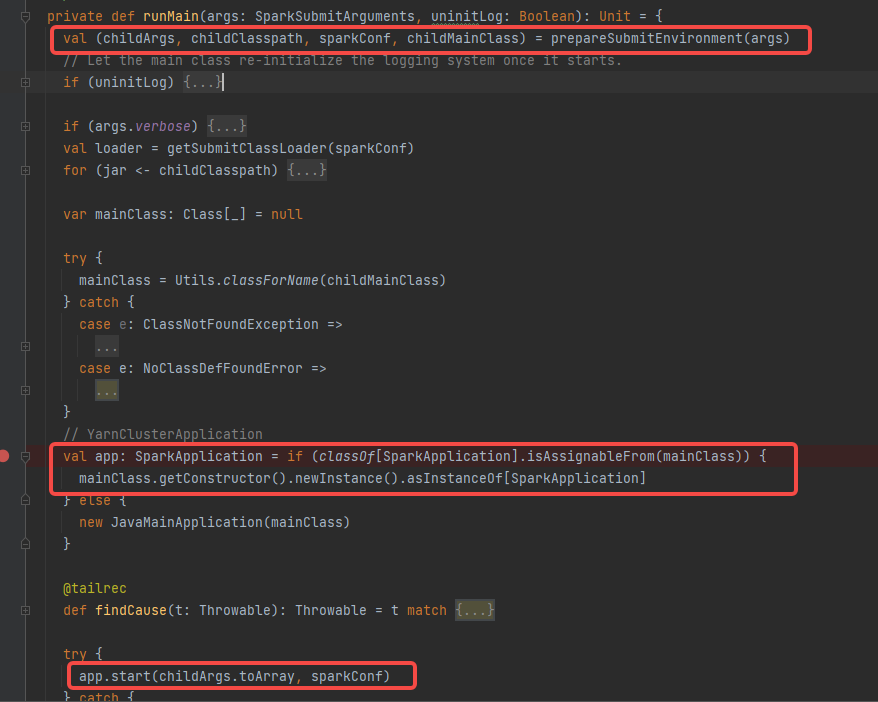
prepareSubmitEnvironment
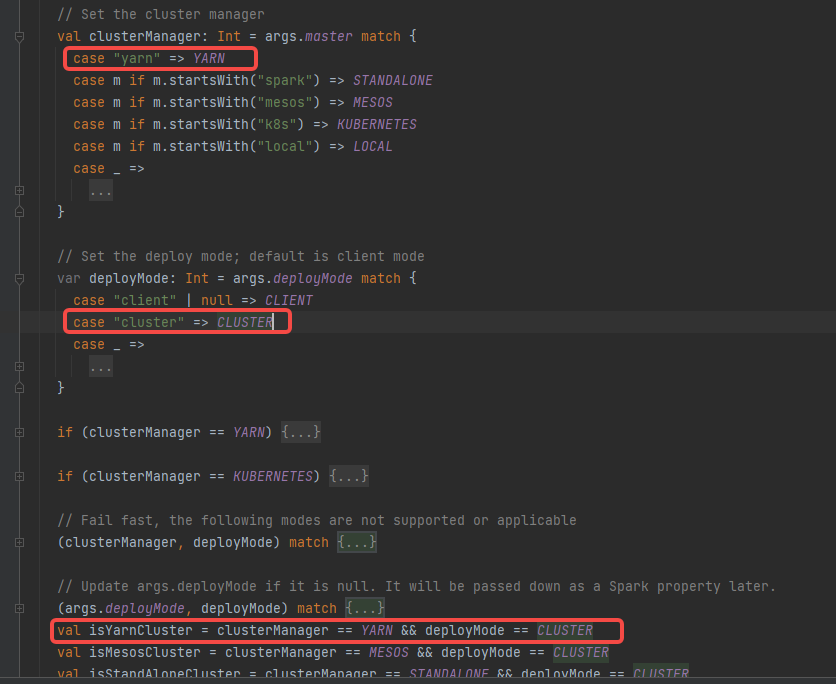
根据 --master yarn --deploy-mode cluster确定是isYarnCluster
childMainClass = YARN_CLUSTER_SUBMIT_CLASS
YARN_CLUSTER_SUBMIT_CLASS=“org.apache.spark.deploy.yarn.YarnClusterApplication”
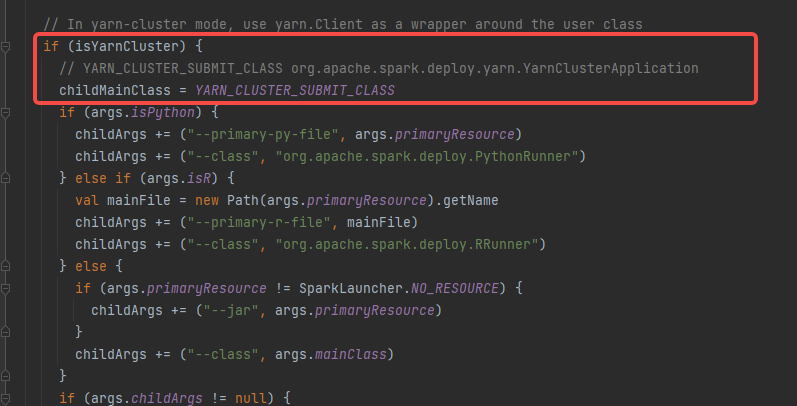
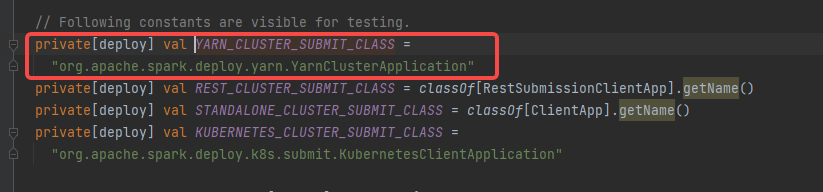
YarnClusterApplication
YarnClusterApplication在resource-managers目录下面的yarn工程的org.apache.spark.deploy.yarn包下的Client类中。
start方法就是创建Client,执行run方法,调用submitApplication方法
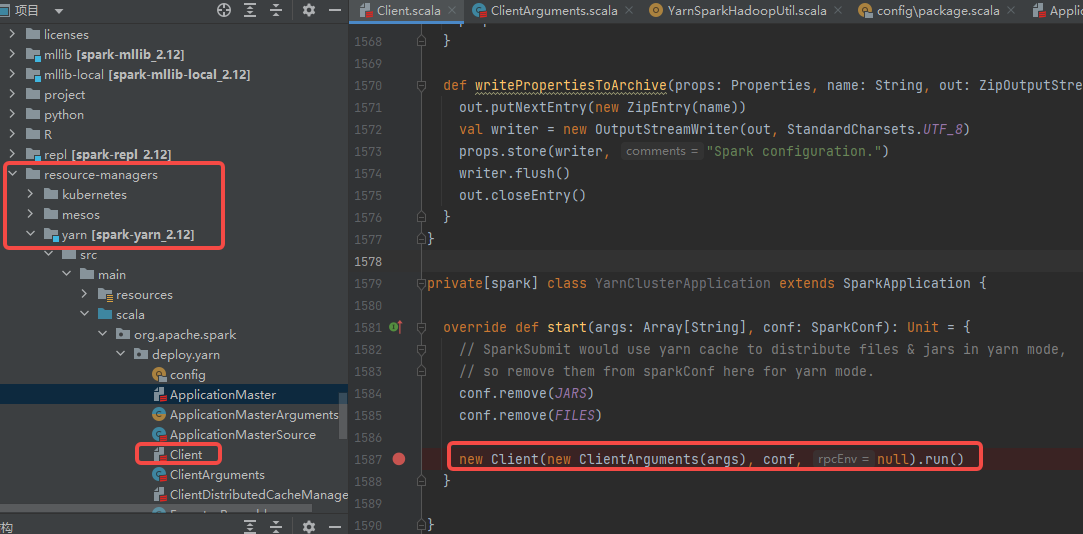
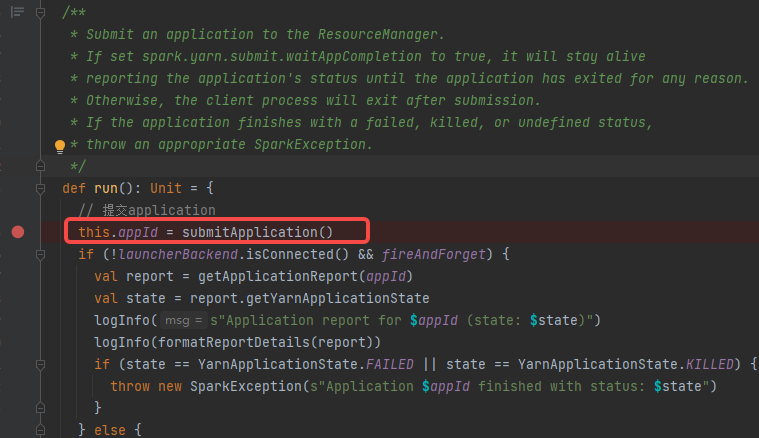
submitApplication
1.yarnClient初始化并连接
2.yarnClient向resourceManager申请创建app
3.生成app的启动命令(启动类是ApplicationMaster)
4.app状态变更为SUBMITTED
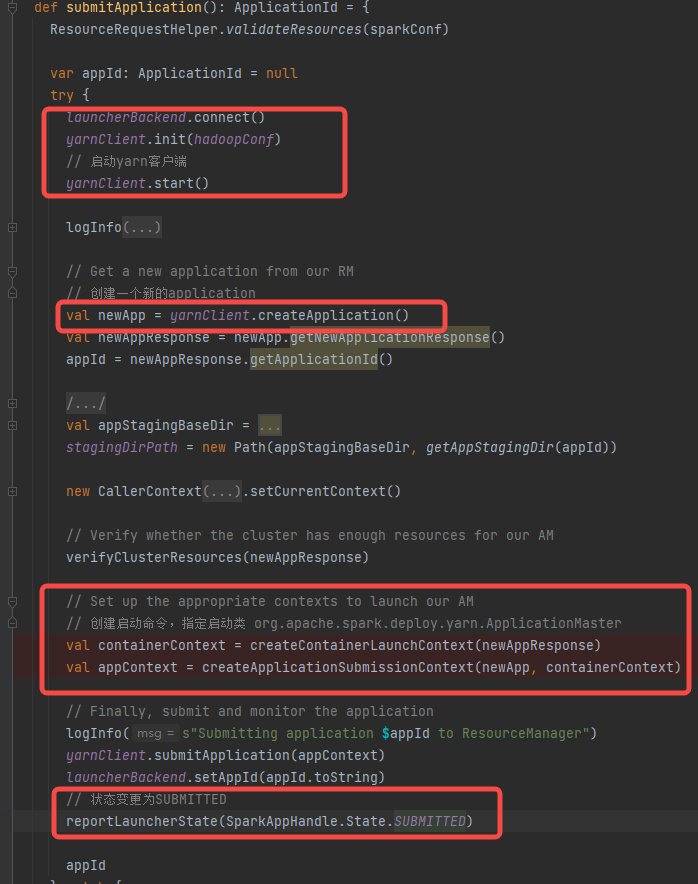
createContainerLaunchContext
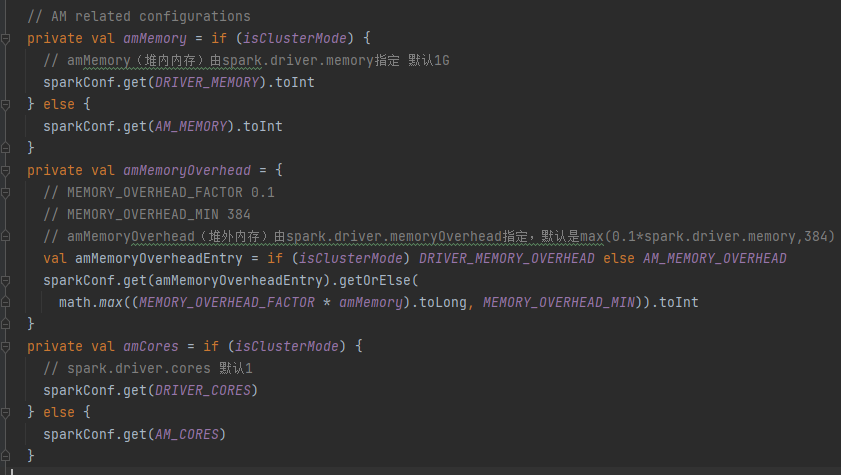
启动内存spark.driver.memory指定,默认是1G

启动类是org.apache.spark.deploy.yarn.ApplicationMaster

createApplicationSubmissionContext
指定yarn的container内存和core
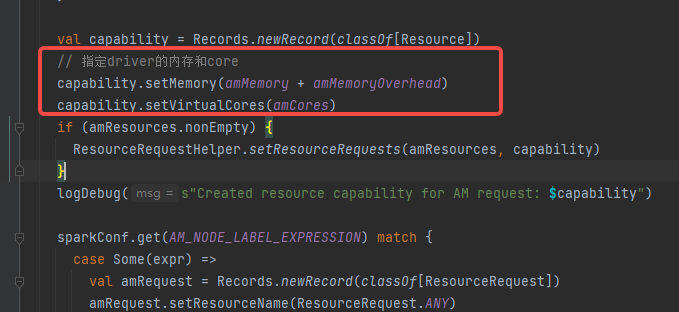
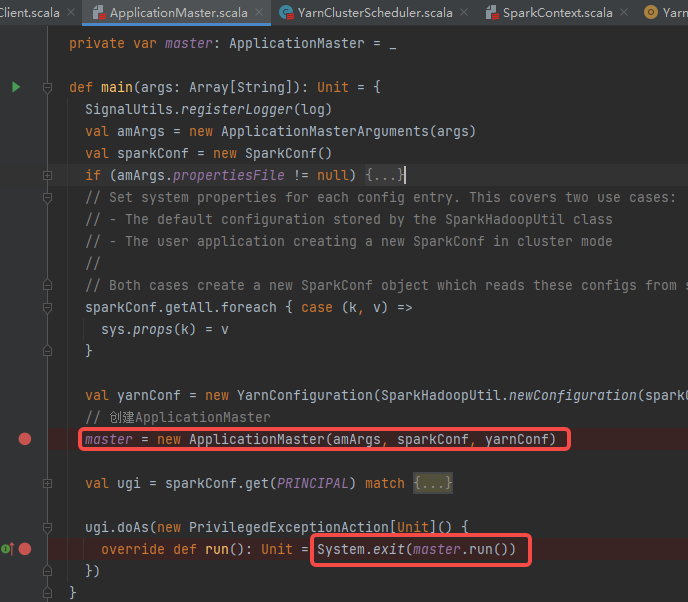
ApplicationMaster
创建ApplicationMaster对象,并执行run方法。
run中获取attemptID,并启动driver(runDriver方法)
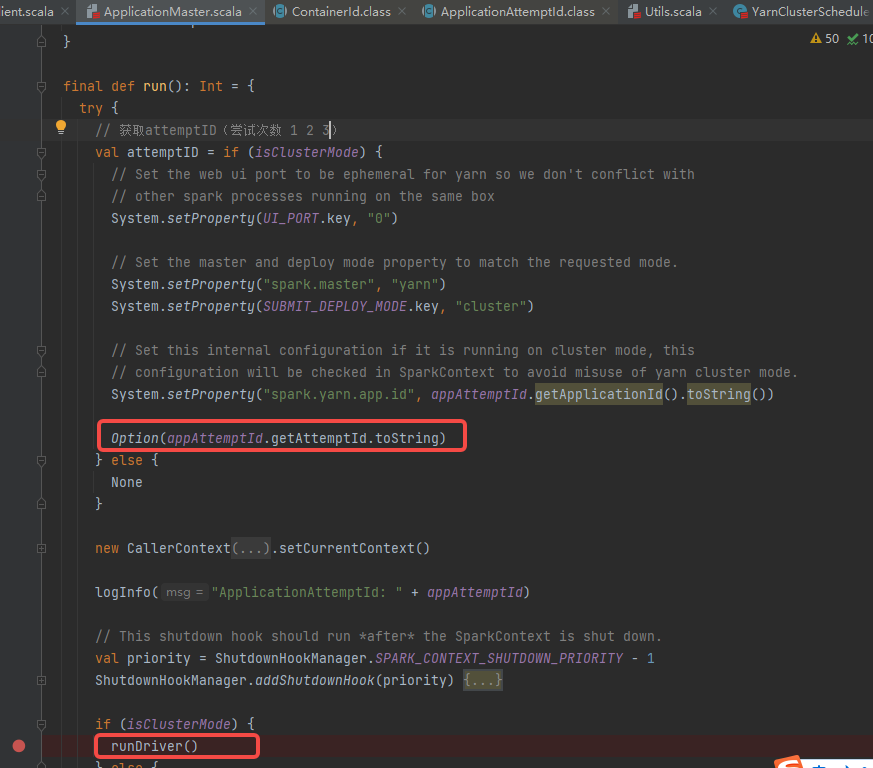
runDriver
1.调用startUserApplication执行用户类,用户类中会初始化sparkContext
2.等待sparkContext初始化完成
3.注册applicationMaster
4.申请container,用于部署executor
5.唤醒用户线程,等待用户线程执行完毕
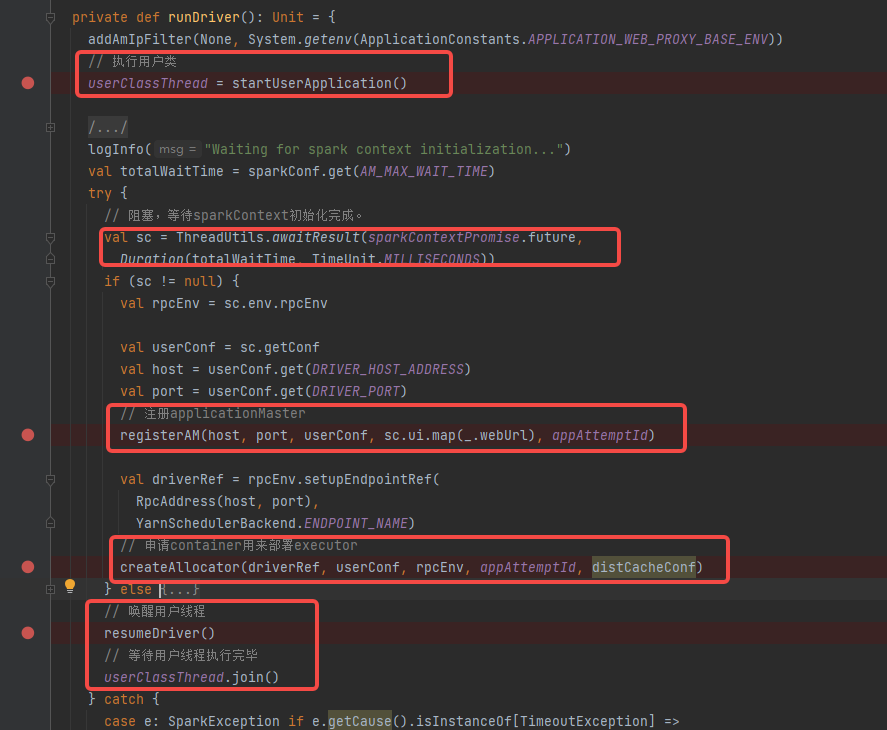
执行用户类
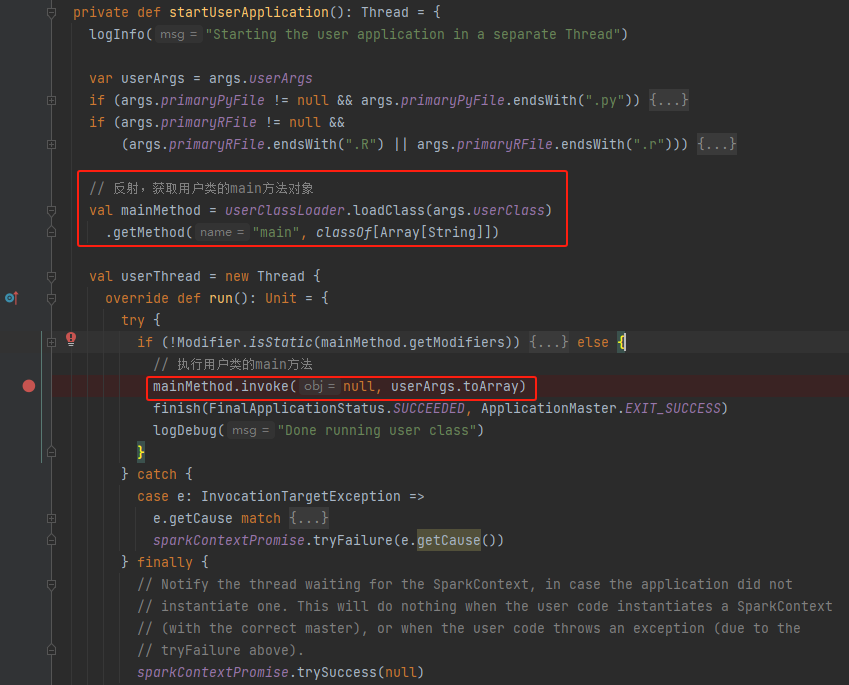
startUserApplication
通过反射获取到用户类的main方法对象,并执行。
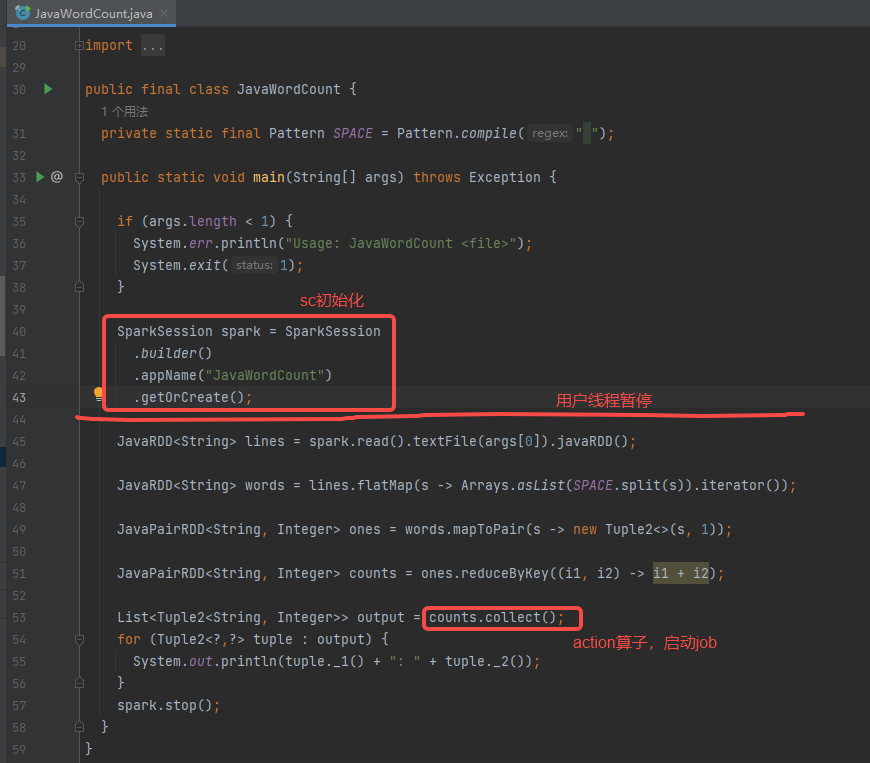
创建sparkContext
通过SparkSession创建sparkContext对象。
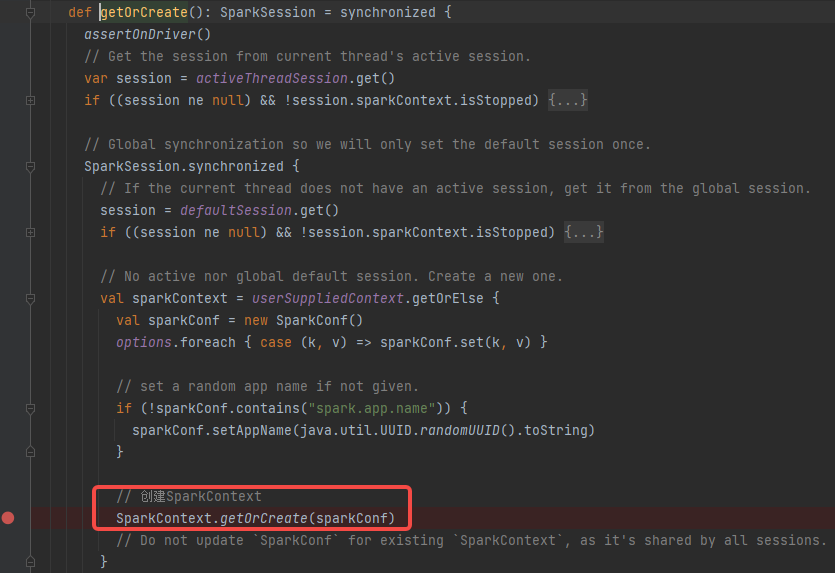
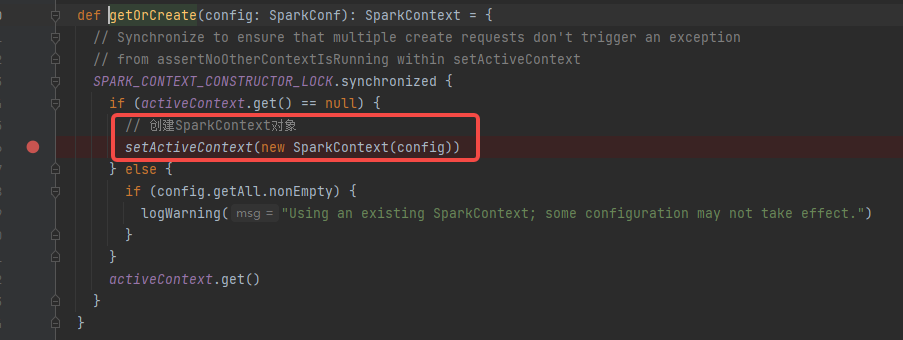
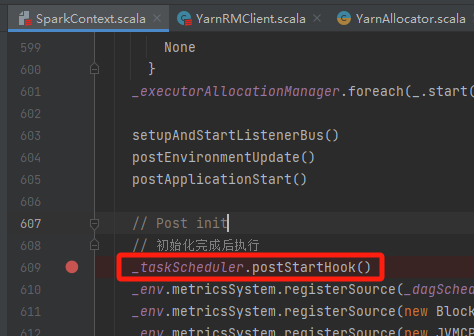
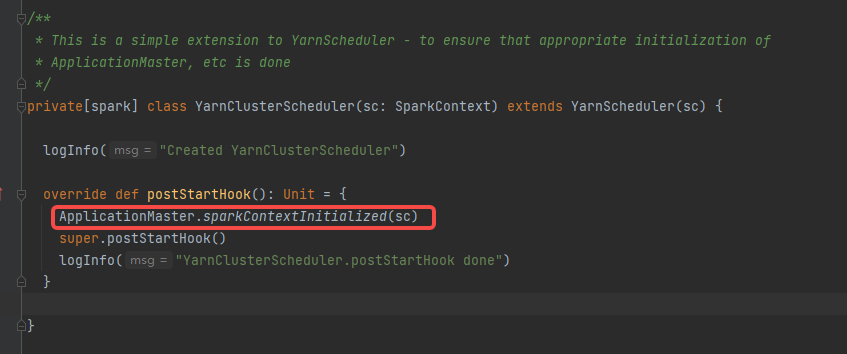
sparkContext初始化完成后,调用YarnClusterScheduler的postStartHook方法。
最终用户线程通知主线程sparkContext初始化完成,同时用户线程暂停,等待application向yarn申请到资源后再继续执行。

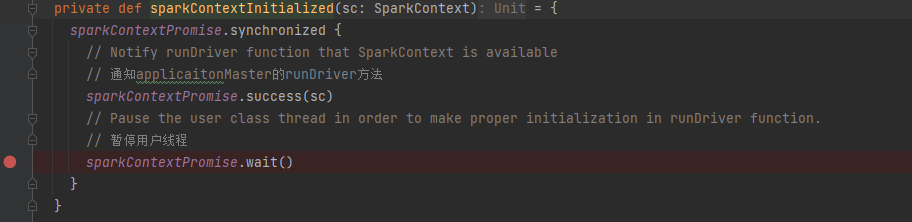
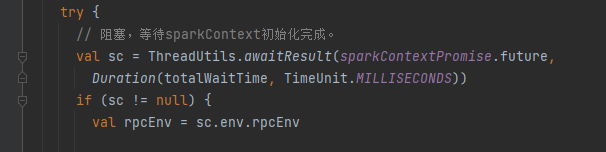
等待sc初始化
applicationMaster的host、port需要等到sparkContext初始化才有,所以在此等待。
用户类中会初始化sparkContext并通知返回sparkContext。
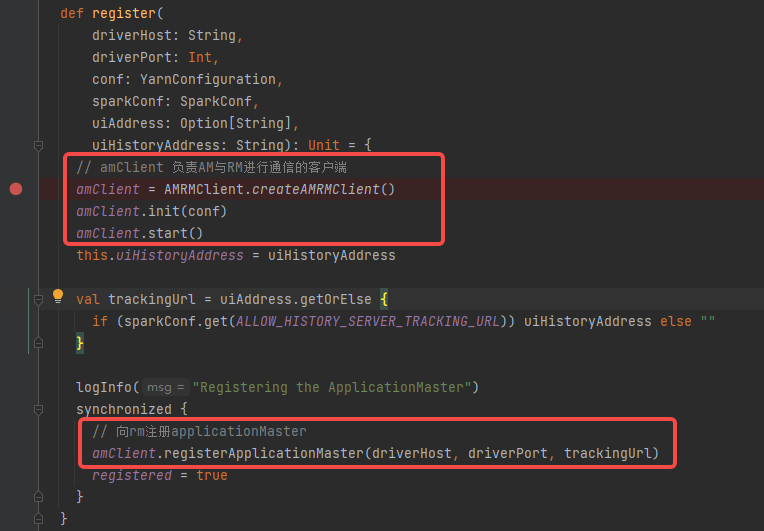
注册applicationMaster
创建并初始化amClient(负责AM与RM进行通信的客户端)
向rm注册am
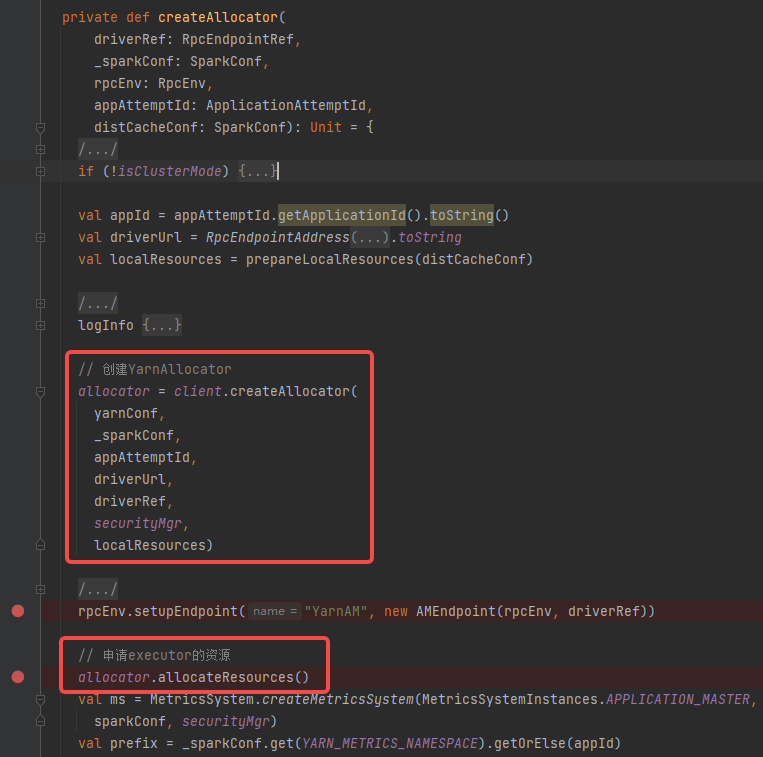
申请container
首先创建YarnAllocator(负责跟ResourceManager申请和释放container),再申请executor对应的资源并启动。
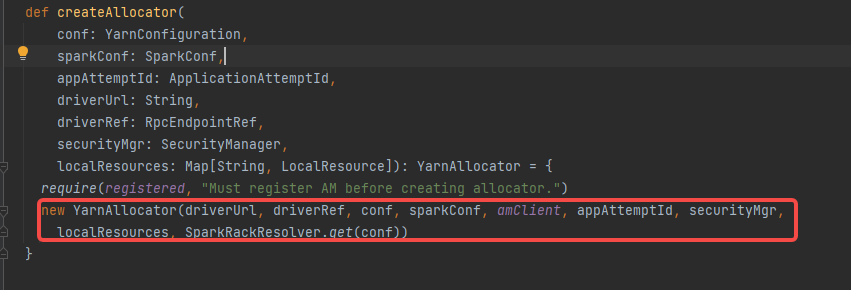
updateResourceRequests 更新一下container的request
handleAllocatedContainers 启动成功申请下来的容器
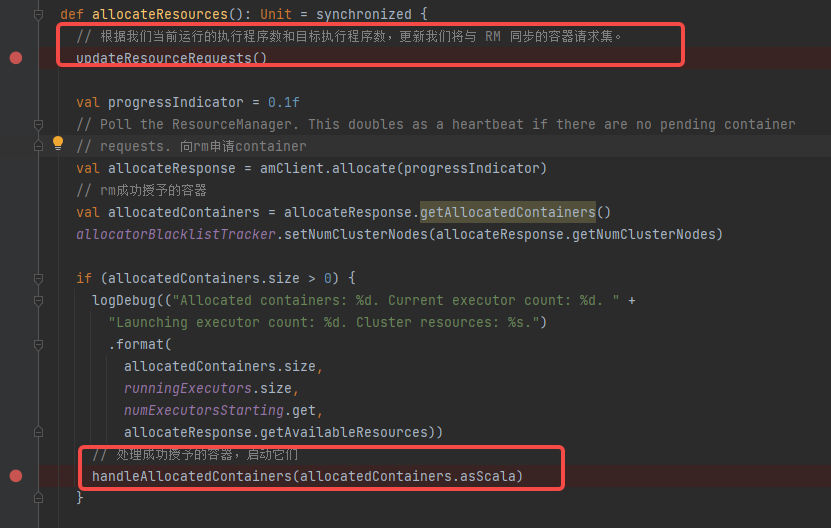
- 计算还缺少的executor数量missing
- 将处在pending状态的request分类:
- localRequests 能匹配上本地
- staleRequests 不能匹配上本地
- anyHostRequests 对运行节点没有要求
- staleRequests匹配不上的请求移除
- 根据本地优先策略尽可能分配container
- 生成新的ContainerRequest(newLocalityRequests),如果不够的话,新增不限host不限rack的请求,多的话就移除多余的LocalityRequests
- addContainerRequest将请求发送给rm,等待实际分配
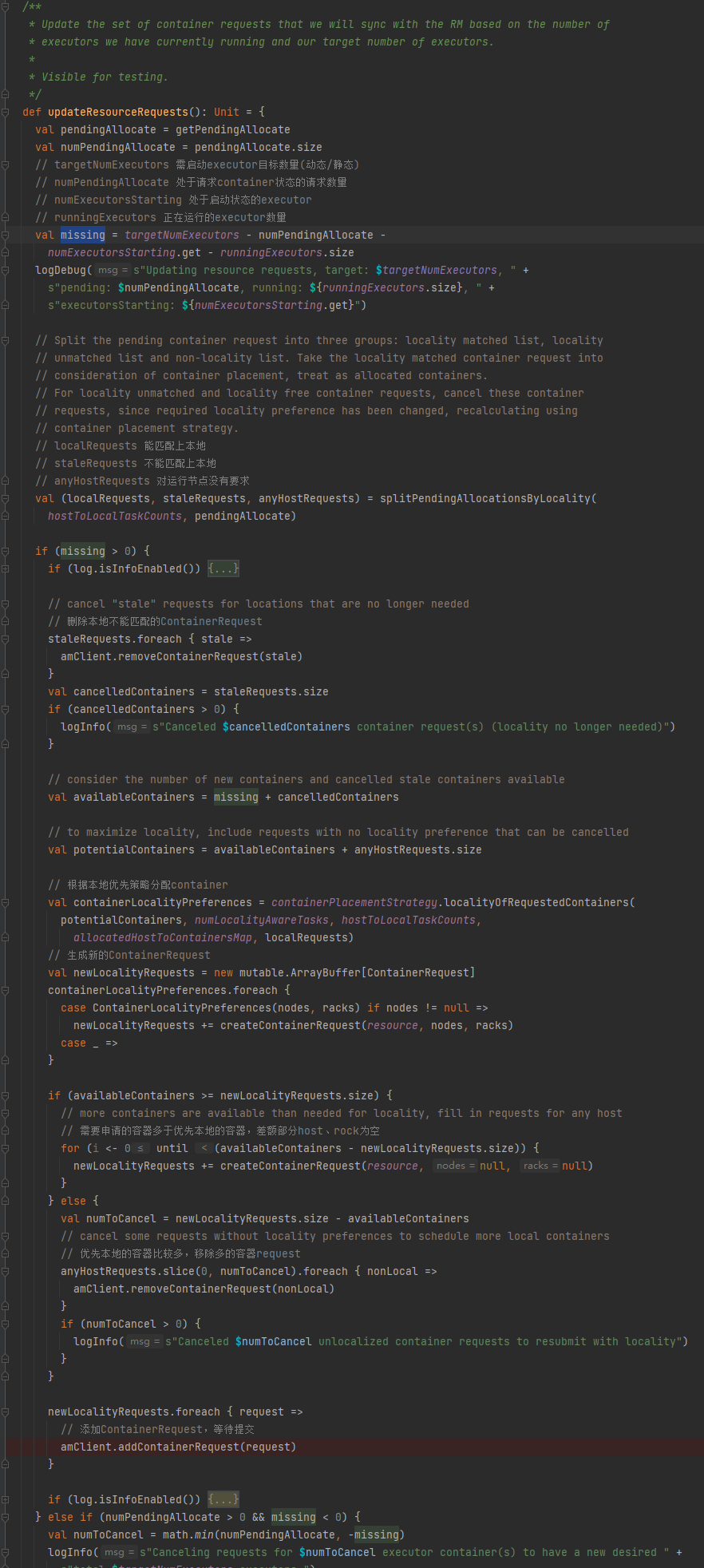
rm成功分配下来的container有可能存在不符合的情况。所以还要校验一遍,移除不符合的container。
- host匹配
- rack匹配
- 无host无rack匹配
- 移除不符合的container
- 启动container
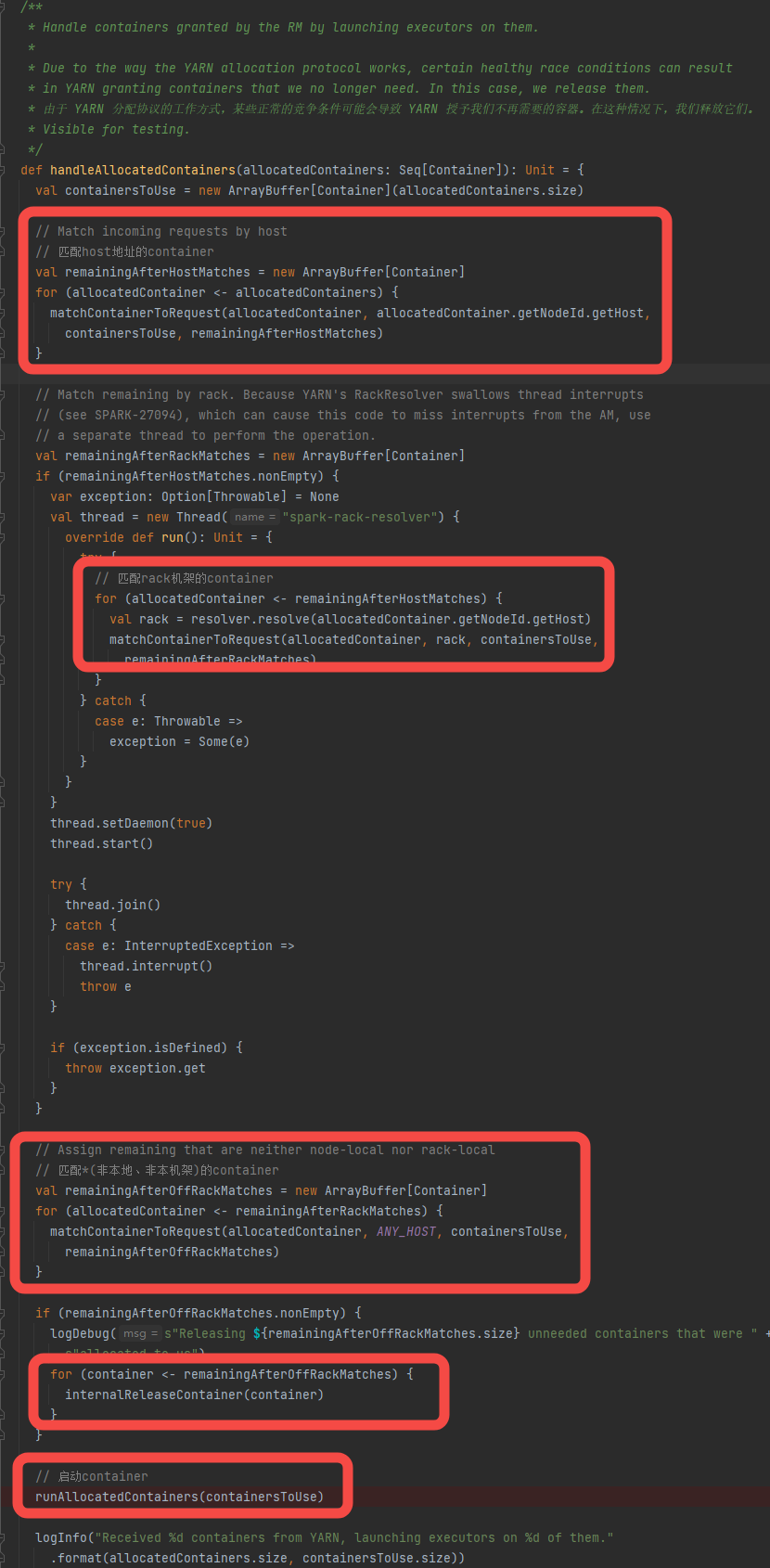
启动container
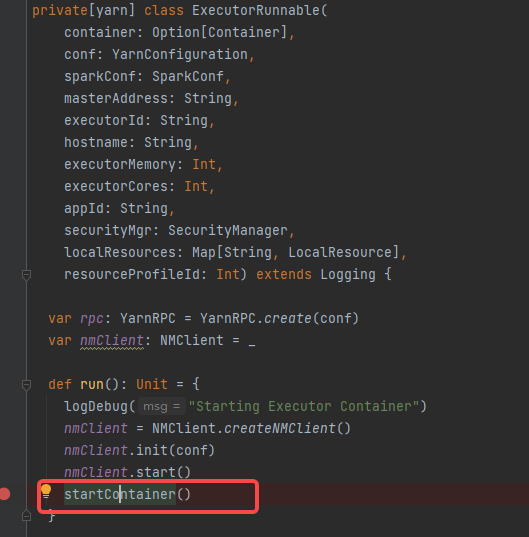
可以看到启动container是创建ExecutorRunnable对象并调用run方法
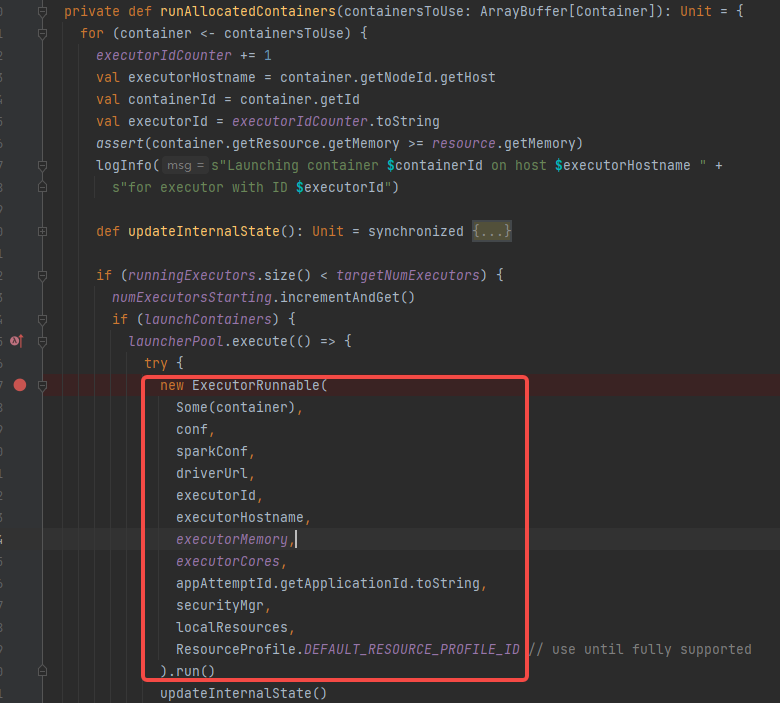
初始化NMClient,调用startContainer方法
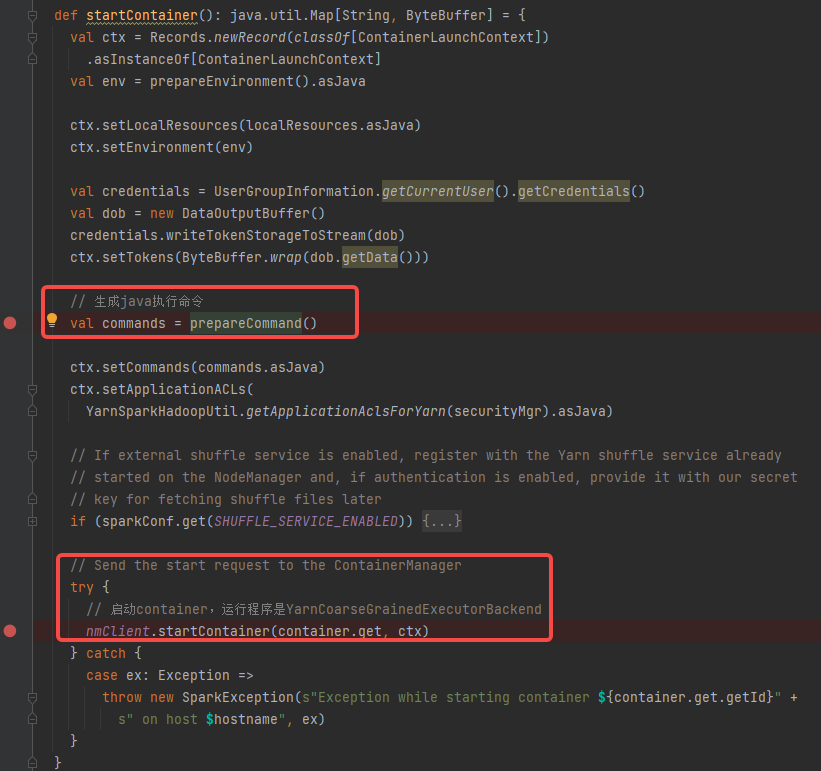
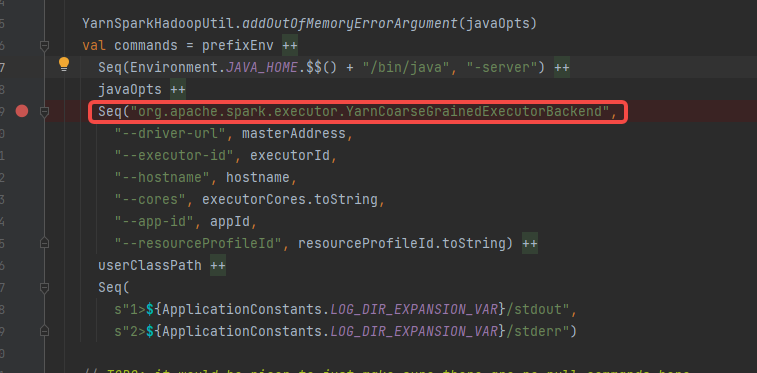
prepareCommand 拼接java启动命令,启动类是org.apache.spark.executor.YarnCoarseGrainedExecutorBackend
nmClient.startContainer(container.get, ctx)发送启动请求,在对应的节点启动,container中指定了节点
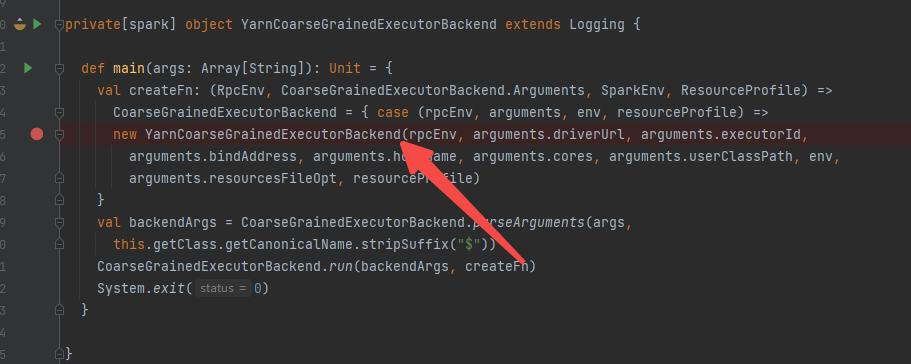
YarnCoarseGrainedExecutorBackend 在container中负责管理executor,是CoarseGrainedExecutorBackend的子类
可以看到是CoarseGrainedExecutorBackend的run方法中传入了YarnCoarseGrainedExecutorBackend创建的函数,在run中会创建YarnCoarseGrainedExecutorBackend。
CoarseGrainedExecutorBackend是一个RPC节点,创建的时候会调用onStart方法。
CoarseGrainedExecutorBackend向driver注册executor,注册成功向自身发送注册成功消息RegisteredExecutor
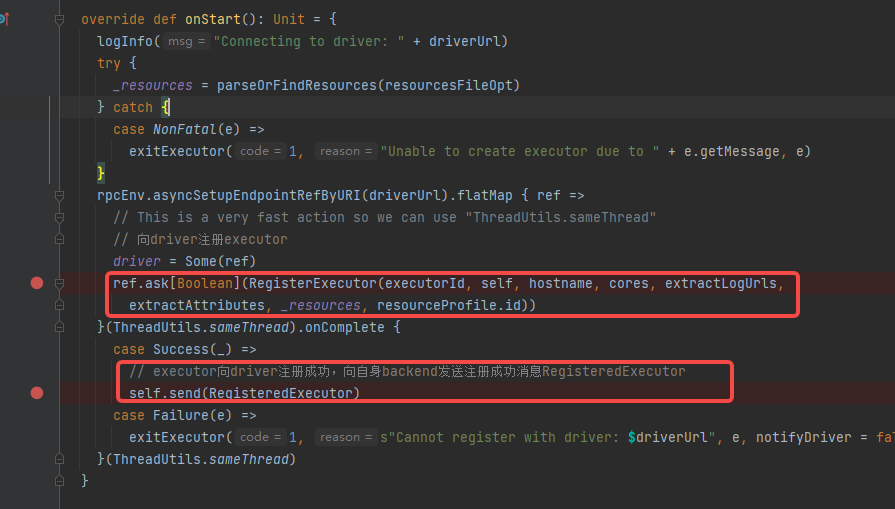
接收RegisteredExecutor消息,创建Executor,先driver发送executor加载完成消息LaunchedExecutor。Executor创建完成后,backend就会等待LaunchTask消息让executor执行task
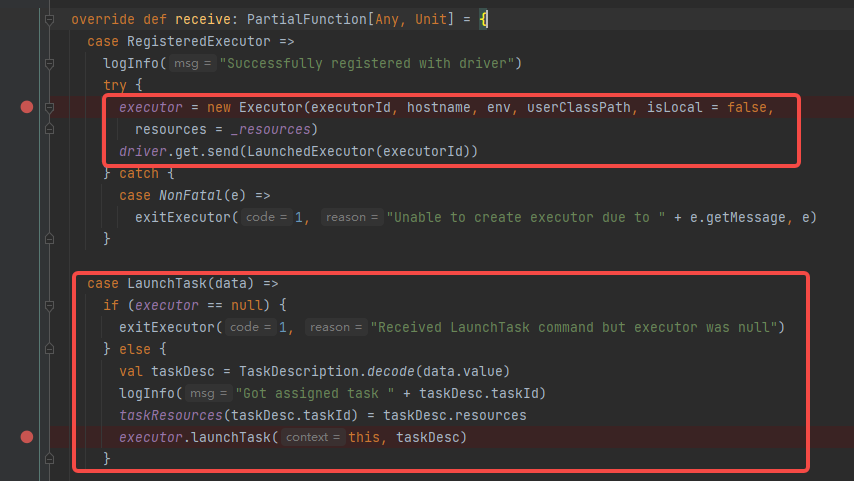
到此container已经启动,里面的executor也准备就绪,等待task任务。
唤醒用户线程
applicationMaster的runDriver方法最后,唤醒用户线程(用户代码执行完sparkContext初始化后就暂停了,可以),继续执行用户代码。
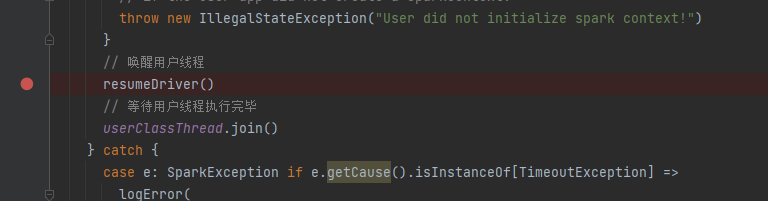
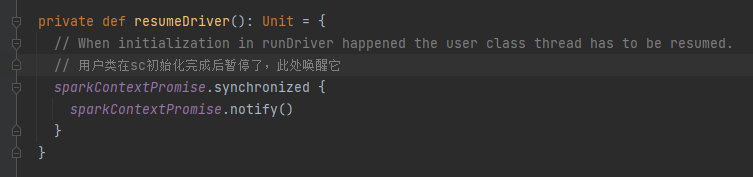
回到用户代码,rdd部分是用户的数据逻辑,最后调用action算子(此处是collect)会开始执行job。
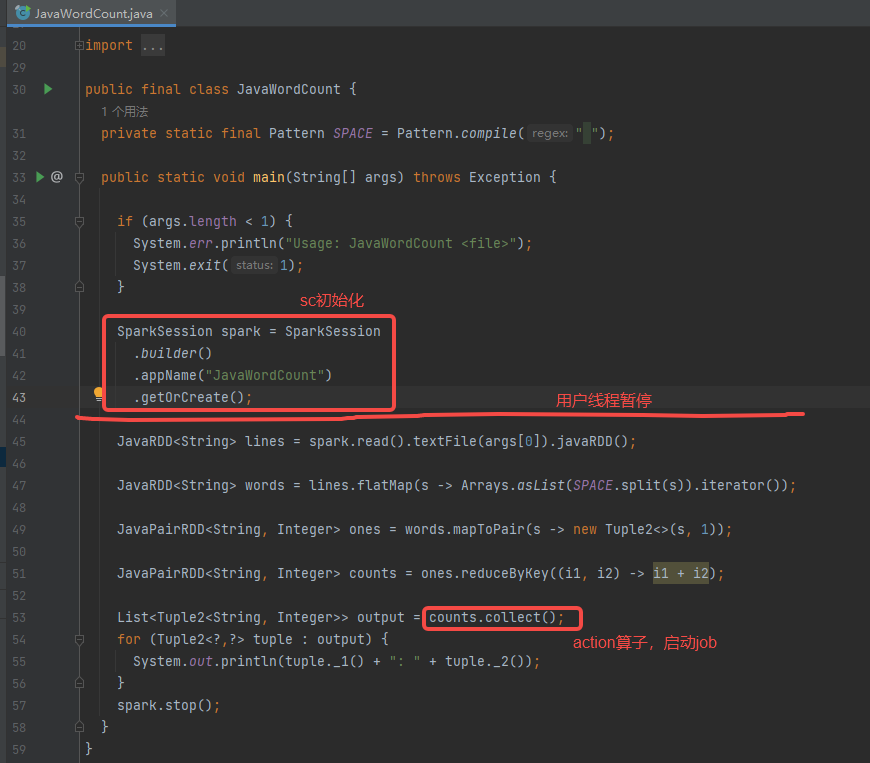
collect算子,最后调用的是sc的runJob方法。
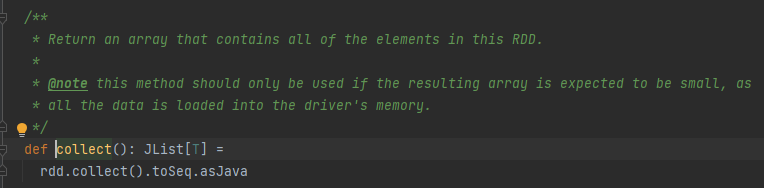
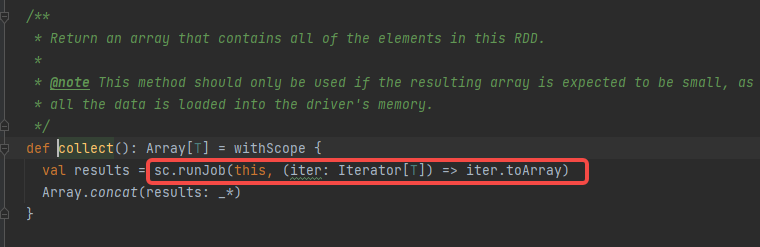
启动部分就到这里吧,再后面就是task划分和task执行















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









