







引言
你这个模型, 它复现起来难吗?
我一水博客的, 能给你看复现不出来的算法?
效果展示
将梵高的代表作<星空>的风格, 迁移到视频上


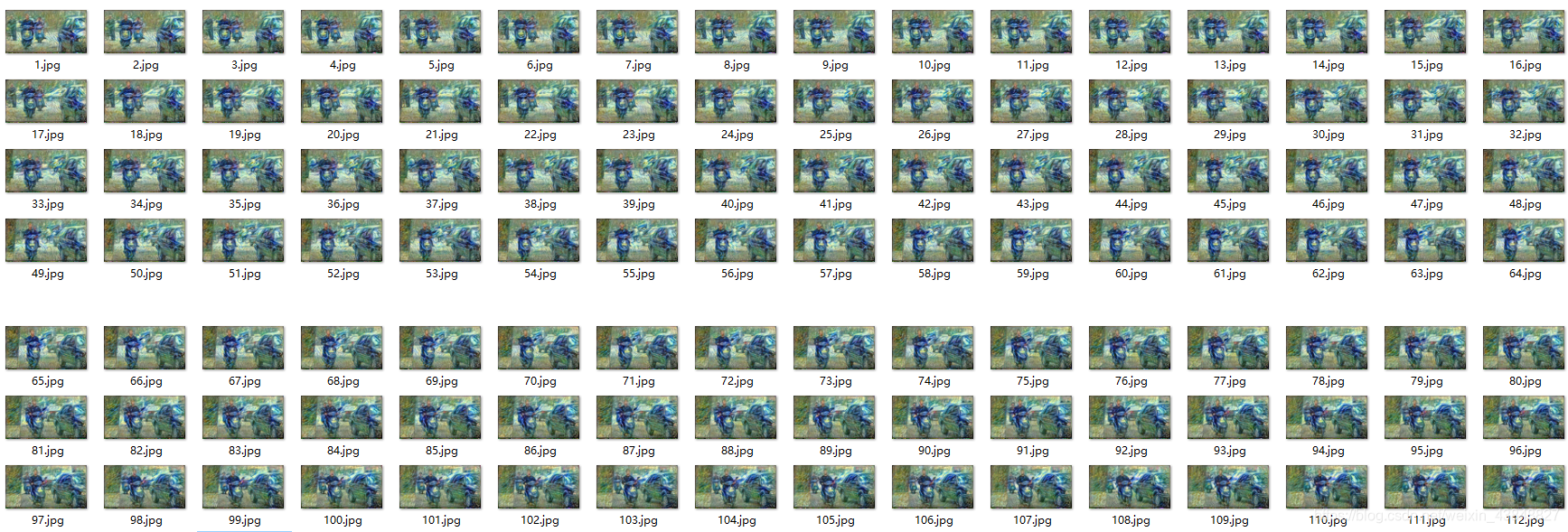
准备工作
- 华强买瓜原版视频, 不需要音频. 毕竟处理的图像不包含音频信息. 最好也不要包含字幕, 字幕会影响整体的效果. 音频和字幕可以后期用PR剪辑上去
- 风格图像, 随便挑几幅, 最好是印象派的画作, 非常具有风格
- Python3.6.7
- Tensorflow2.0.0
- OpenCV-Python3.4.2.16
具体步骤
让我们新建一个HuaQiangBuyWatermelon的项目…
业务逻辑
原来我计划的流程是这样的
原视频 = 读取视频
写入视频 = 视频写入对象
风格图像 = 读取风格图像
for each 当前帧 in 原视频
转换帧 = 转换风格(当前帧, 风格图像)
写入视频(转换帧)
end for
但是过程中OpenCV的VideoWriter出了点问题, 写不进去. 无奈只能采用以下的逻辑
for each 当前帧 in 原视频
保存(当前帧.jpg)
end for
for each 当前图像 in 所有保存的帧
转换帧 = 转换风格(当前图像, 风格图像)
保存(转换帧)
end for
最后得到了每一帧的经过风格转换的图像, 再借助PR将这些所有的转换帧剪成视频
日志
整个模型虽然简单, 但是非常耗时, 我截取的华强买瓜视频一共6900帧. 为了DEBUG方便, 日志是一个好习惯.
新建logger.py文件
为了方便DEBUG, 我会在每行日志的最前面显示输出的类型, 比如INFO, WARNING, ERROR
import time
logger = open('./log.txt', 'a+')
def log_string(out_str, dtype='INFO', to_log_file=True):
"""
保存日志
:param to_log_file:
:param dtype:
:param out_str:
"""
global logger
if not isinstance(out_str, str):
out_str = str(out_str)
if '\\r' == out_str:
print()
if to_log_file:
logger.write('\n')
logger.flush()
else:
local_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
out_str = '[{:^7s}] [{}] '.format(dtype, local_time) + out_str
if 'INFO' == dtype:
print(out_str)
elif 'WARNING' == dtype:
print("\033[0;34m{}\033[0m".format(out_str))
else:
print("\033[0;31m{}\033[0m".format(out_str))
if to_log_file:
logger.write(out_str + '\n')
logger.flush()
保存的日志大概如下:
转换风格
这里用到了神经网络, 简单来说就是通过一个深层的VGG网络去提取图像更深层的信息, 难度在于损失函数的设计, 这里不赘述, 感兴趣的读者请查阅其它文献.
train()接受4个参数:
- content_image 待转换的图像
- style_image 风格图像, 将这张图像的风格迁移到content_image上
- num_epochs epoch的数量, 训练的周期数
- remain 剩余的待处理的图像数量, 用来估计剩余时间ETA
该函数返回风格转换完毕的图像
新建train.py文件
def train(content_image, style_image, num_epochs, remain):
# 截取0-1的浮点数,超范围部分被截取
def clip_0_1(image_):
return tf.clip_by_value(image_, clip_value_min=0.0, clip_value_max=1.0)
# 损失函数
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
# 风格损失值,就是计算方差
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name] - style_targets[name]) ** 2)
for name in style_outputs.keys()])
# 权重值平均到每层,计算总体风格损失值
style_loss *= style_weight / num_style_layers
# 内容损失值,也是计算方差
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name] - content_targets[name]) ** 2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
# 总损失值
loss = style_loss + content_loss
return loss
# 一次训练
@tf.function()
def train_step(image_):
with tf.GradientTape() as tape:
# 抽取风格层、内容层输出
outputs = extractor(image_)
# 计算损失值
loss = style_content_loss(outputs)
# 梯度下降
grad = tape.gradient(loss, image_)
# 应用计算后的新参数,注意这个新值不是应用到网络
# 作为训练完成的vgg网络,其参数前面已经设定不可更改
# 这个参数实际将应用于原图
# 以求取,新图片经过网络后,损失值最小
opt.apply_gradients([(grad, image_)])
# 更新图片,用新图片进行下次训练迭代
image_.assign(clip_0_1(image_))
# 定义最能代表内容特征的网络层
content_layers = ['block5_conv2']
# 定义最能代表风格特征的网络层
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
# 神经网络层的数量
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
# 使用自定义模型建立一个抽取器
extractor = StyleContentModel(style_layers, content_layers)
# 设定风格特征的目标,即最终生成的图片,希望风格上尽量接近风格图片
style_targets = extractor(style_image)['style']
# 设定内容特征的目标,即最终生成的图片,希望内容上尽量接近内容图片
content_targets = extractor(content_image)['content']
# 内容图片转换为张量
image = tf.Variable(content_image)
# 优化器
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
# 预定义风格和内容在最终结果中的权重值,用于在损失函数中计算总损失值
style_weight = 1e-2
content_weight = 1e4
start = time.time()
epochs = num_epochs
steps_per_epoch = 50
step = 0
for n in range(epochs):
start2 = time.time()
for m in range(steps_per_epoch):
step += 1
train_step(image)
end2 = time.time()
log_string('time of epoch {}: {:.2f}s'.format(n+1, end2-start2))
end = time.time()
log_string("Total time: {:.2f}s, ETA: {:.2f}min".format(end - start, remain*(end - start)/60))
########################################
return image[0].numpy()
其中用到的各种函数如下
from __future__ import absolute_import, division, print_function, unicode_literals
import time
from abc import ABC
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from logger import log_string
# 设置绘图窗口参数,用于图片显示
mpl.rcParams['figure.figsize'] = (13, 10)
mpl.rcParams['axes.grid'] = False
def load_img(path_to_img):
max_dim = 512
# 读取二进制文件
img = tf.io.read_file(path_to_img)
# 做JPEG解码,这时候得到宽x高x色深矩阵,数字0-255
img = tf.image.decode_jpeg(img)
# 类型从int转换到32位浮点,数值范围0-1
img = tf.image.convert_image_dtype(img, tf.float32)
# 减掉最后色深一维,获取到的相当于图片尺寸(整数),转为浮点
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
# 获取图片长端
long = max(shape)
# 以长端为比例缩放,让图片成为512x???
scale = max_dim / long
new_shape = tf.cast(shape * scale, tf.int32)
# 实际缩放图片
img = tf.image.resize(img, new_shape)
# 再扩展一维,成为图片数字中的一张图片(1,长,宽,色深)
img = img[tf.newaxis, :]
return img
# 定义一个工具函数,帮助建立得到特定中间层输出结果的新模型
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# 定义使用ImageNet数据训练的vgg19网络
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
# 已经经过了训练,所以锁定各项参数避免再次训练
vgg.trainable = False
# 获取所需层的输出结果
outputs = [vgg.get_layer(name).output for name in layer_names]
# 最终返回结果是一个模型,输入是图片,输出为所需的中间层输出
model = tf.keras.Model([vgg.input], outputs)
return model
# 定义函数计算风格矩阵,这实际是由抽取出来的5个网络层的输出计算得来的
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1] * input_shape[2], tf.float32)
return result / num_locations
# 自定义keras模型
class StyleContentModel(tf.keras.models.Model, ABC):
def __init__(self, style_layers_, content_layers_):
super(StyleContentModel, self).__init__()
# 自己的vgg模型,包含上面所列的风格抽取层和内容抽取层
self.vgg = vgg_layers(style_layers_ + content_layers_)
self.style_layers = style_layers_
self.content_layers = content_layers_
self.num_style_layers = len(style_layers_)
# vgg各层参数锁定不再参数训练
self.vgg.trainable = False
def call(self, input_, **kwargs):
# 输入的图片是0-1范围浮点,转换到0-255以符合vgg要求
input_ = input_ * 255.0
# 对输入图片数据做预处理
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(input_)
# 获取风格层和内容层输出
outputs = self.vgg(preprocessed_input)
# 输出实际是一个数组,拆分为风格输出和内容输出
style_outputs, content_outputs = (
outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
# 计算风格矩阵
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
# 转换为字典
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
# 转换为字典
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
# 返回内容和风格结果
return {'content': content_dict, 'style': style_dict}
读取视频并保存每一帧
新建generate.py文件
这里使用OpenCV的VideoCapture读取视频, 然后一帧一帧保存下来
这个函数只要运行一次就行了, 然后就可以注释掉了
def split_frames():
cap = cv.VideoCapture('./video/video.mp4')
cnt = 0
while True:
ret, frame = cap.read()
if not ret:
break
cnt += 1
log_string('saving frame {}'.format(cnt))
cv.imwrite('./contents/{}.jpg'.format(cnt), frame)
cap.release()
log_string('end')
log_string('\\r')
log_string('\\r')
最后, 再将保存好的这些原视频的帧, 一张一张传递给train()函数即可.
但是这里需要注意, os.listdir()返回的目录下的所有文件, 是按文件名的字典序排序的, 也就是说, 假如有1.jpg, 2.jpg, …, 20.jpg这20个图像, 它返回的结果是
1.jpg, 11.jpg, 12.jpg, 13.jpg, 14.jpg, 15.jpg, 16.jpg, 17.jpg, 18.jpg, 19.jpg,
2.jpg, 21.jpg, 22.jpg, 23.jpg, 24.jpg, 25.jpg, 26.jpg, 27.jpg, 28.jpg, 29.jpg
因此保险起见, 最好对它重新排个序(当然不排序的话, 只要按原文件名去保存转换好的图像, 也是可以的, 但是为啥推荐做排序, 假设处理某一帧的时候出错了, 那么排序后能够快速定位到这一帧的索引, 方便后续DEBUG)
files = os.listdir(content_dir)
num_frames = len(files)
files.sort(key=lambda x: int(x[:-4]))
这里需要将x.jpg中的最后4个字符.jpg去掉, 只留下一个int型的x, 然后升序排序.
def generate():
style_img = load_img('./styles/denoised_starry.jpg')
content_dir = './contents/'
files = os.listdir(content_dir)
num_frames = len(files)
files.sort(key=lambda x: int(x[:-4]))
num_epochs = 5
begin = args.begin-1
end = args.end
cnt = begin
for cur in range(begin, end):
file = files[cur]
log_string('-' * 60)
cnt += 1
save_name = './generates/{}.jpg'.format(cnt)
log_string('cnt: {}/{}, current image: {}'.format(cnt, num_frames, file))
content_img = load_img('{}/{}'.format(content_dir, file))
img_styled = train(content_img, style_img, num_epochs, num_frames - cnt) * 255
log_string('saving to {}'.format(save_name))
img_styled = cv.cvtColor(img_styled, cv.COLOR_RGB2BGR)
cv.imwrite(save_name, img_styled)
log_string('-' * 60)
log_string('\\r')
if __name__ == '__main__':
split_frames()
问题
由于整个模型需要的时间非常长, 过程中万一出现异常, 那就直接终止了, 比如你睡前开始运行…结果半小时后它碰到异常停了…那一晚上就浪费了…为了避免重新跑带来的麻烦, 需要提高点鲁棒性.
最容易发生的问题其实是OOM爆显存. 一旦发生了任何问题, 整个程序就停止了, 这时候就体现出来日志的重要性了, 查看日志可以快速地定位到模型处理到哪一帧, 然后后期再补上这一帧.
其实只需要给generate.py用try catch捕捉异常即可. 等模型跑完之后, 查看日志, 看看有多少个ERROR, 重新跑一遍这些帧即可, 不用把所有的6900帧都跑一遍.
新建main.py
import os
from logger import log_string
if __name__ == '__main__':
steps = 50 # 每次处理50帧
for begin in range(135, 6835, steps):
cmd = 'python generate.py -begin {} -end {}'.format(begin, begin+steps-1)
try:
log_string('run {}'.format(cmd))
os.system(cmd)
except:
log_string('cmd {} failed'.format(cmd), 'ERROR')
最后运行的时候只需要运行main.py即可. 由于加了try catch, 碰到异常也不会终止进程. 发生异常的时候会在日志里面记录, 最后只要等它跑完, 去日志里面定位ERROR, 然后把这些缺失的帧补上就行.















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











