






1. 定义数据集
import numpy as np
import pandas as pd
data = pd.DataFrame(
{'学历': ['专科', '专科', '专科', '专科', '专科', '本科', '本科', '本科', '本科', '本科', '研究生', '研究生', '研究生', '研究生', '研究生'],
'婚否': ['否', '否', '是', '是', '否', '否', '否', '是', '否', '否', '否', '否', '是', '是', '否'],
'是否有车': ['否', '否', '否', '是', '否', '否', '否', '是', '是', '是', '是', '是', '否', '否', '否'],
'收入水平': ['中', '高', '高', '中', '中', '中', '高', '高', '很高', '很高', '很高', '高', '高', '很高', '中'],
'类别': ['否', '否', '是', '是', '否', '否', '否', '是', '是', '是', '是', '是', '是', '是', '否']})
- pandas.DataFrame()
print(data)
学历 婚否 是否有车 收入水平 类别
0 专科 否 否 中 否
1 专科 否 否 高 否
2 专科 是 否 高 是
3 专科 是 是 中 是
4 专科 否 否 中 否
5 本科 否 否 中 否
6 本科 否 否 高 否
7 本科 是 是 高 是
8 本科 否 是 很高 是
9 本科 否 是 很高 是
10 研究生 否 是 很高 是
11 研究生 否 是 高 是
12 研究生 是 否 高 是
13 研究生 是 否 很高 是
14 研究生 否 否 中 否
2. 定义信息熵函数
信息熵的定义为:
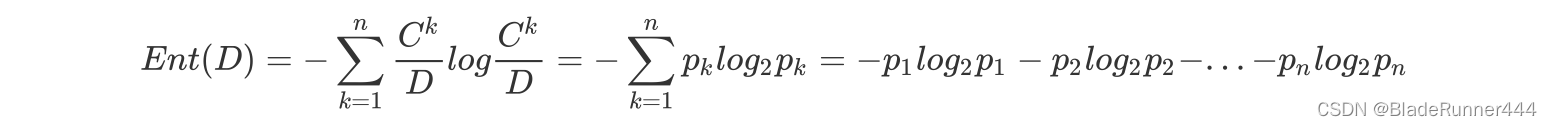
#信息熵函数
def infor(data):
a = pd.value_counts(data) / len(data)
return -sum(np.log2(a) * a)
- pandas.value_counts()
print(pd.value_counts(data["学历"]))
专科 5
本科 5
研究生 5
Name: 学历, dtype: int64
3. 定义信息增益函数
信息增益的定义为:
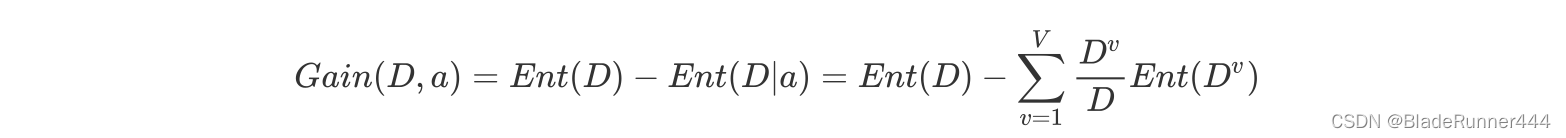
#信息增益函数
def gain(data, str1, str2):
Ent_Dv = data.groupby(str1).apply(lambda x: infor(x[str2]))
p1 = pd.value_counts(data[str1]) / len(data[str1])
Ent_D_a = sum(p1 * Ent_Dv)
Ent_D = infor(data[str2])
return Ent_D - Ent_D_a
- data.groupby()
for group in data.groupby("学历"):
print(group)
('专科', 学历 婚否 是否有车 收入水平 类别
0 专科 否 否 中 否
1 专科 否 否 高 否
2 专科 是 否 高 是
3 专科 是 是 中 是
4 专科 否 否 中 否)
('本科', 学历 婚否 是否有车 收入水平 类别
5 本科 否 否 中 否
6 本科 否 否 高 否
7 本科 是 是 高 是
8 本科 否 是 很高 是
9 本科 否 是 很高 是)
('研究生', 学历 婚否 是否有车 收入水平 类别
10 研究生 否 是 很高 是
11 研究生 否 是 高 是
12 研究生 是 否 高 是
13 研究生 是 否 很高 是
14 研究生 否 否 中 否)
- data.groupby().apply(lamda x: infor(x[str2]) )
分别对每个组进行infor(x[str2])操作
print(Ent_Dv)
学历
专科 0.970951
本科 0.970951
研究生 0.721928
dtype: float64
4. 定义信息增益率函数
信息增益率的定义为:
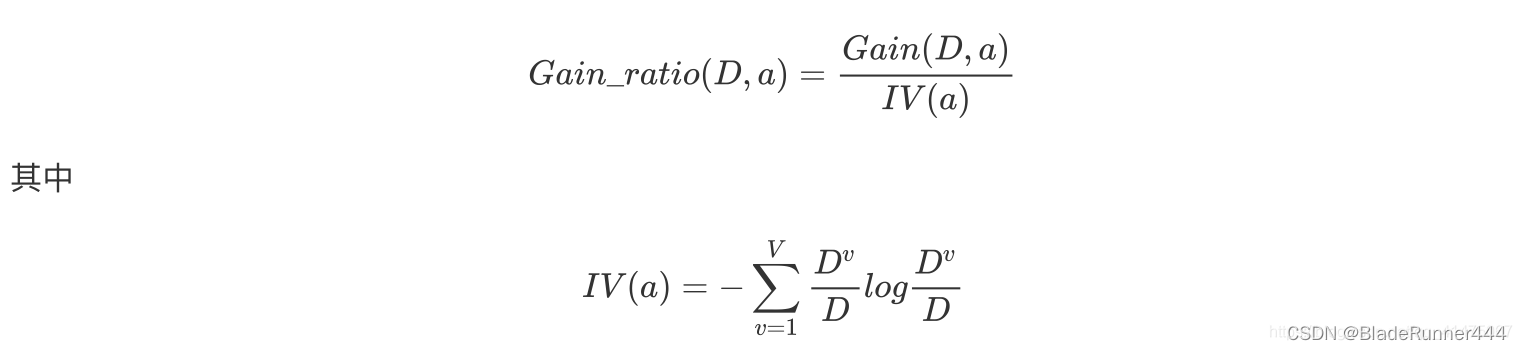
#信息增益率函数
def gainRatio(data, str1, str2):
return gain(data, str1, str2) / infor(data[str1])
print("学历信息增益率:", gainRatio(data, "学历", "类别"))
学历信息增益率: 0.05237190142858302














 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









