







前言
使用wps合并pdf, ppt,居然还要wps超级会员, wps会员留下伤心的眼泪…
另一片相关: python下将图片合成pdf
刚好和这篇文章差不多是逆操作 python选择制定页码提取出子pdf
PyPDF2
代码修改自 https://cloud.tencent.com/developer/article/1627099
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
def GetFileName(dir_path):
file_list = [os.path.join(dirpath, filesname) \
for dirpath, dirs, files in os.walk(dir_path) \
for filesname in files]
file_list.sort()
return file_list
def MergePDF(dir_path, file_name):
output = PdfFileWriter()
outputPages = 0
file_list = GetFileName(dir_path)
print(file_list)
for pdf_file in file_list:
file_type = pdf_file.split('\\')[-1].split('.')[-1]
if file_type != 'pdf':
continue
print("文件:%s" % pdf_file.split('\\')[-1], end=' ')
# 读取PDF文件
input = PdfFileReader(open(pdf_file, "rb"))
# 获得源PDF文件中页面总数
pageCount = input.getNumPages()
outputPages += pageCount
print("页数:%d" % pageCount)
# 分别将page添加到输出output中
for iPage in range(pageCount):
output.addPage(input.getPage(iPage))
print("\n合并后的总页数:%d" % outputPages)
# 写入到目标PDF文件
print("PDF文件正在合并,请稍等......")
with open(os.path.join(dir_path, file_name), "wb") as outputfile:
output.write(outputfile)
print("PDF文件合并完成")
if __name__ == '__main__':
# 设置存放多个pdf文件的文件夹
dir_path = r'H:/大三下/大物/课件/11pdf'
# 目标文件的名字
file_name = "第十一章全集.pdf"
MergePDF(dir_path, file_name)
如果是PyPDF2 3.0.0以上的版本,请用下面这个: (修改了一些函数和包名)
import os
from PyPDF2 import PdfReader, PdfWriter
def GetFileName(dir_path):
file_list = [os.path.join(dirpath, filesname) \
for dirpath, dirs, files in os.walk(dir_path) \
for filesname in files]
file_list.sort()
return file_list
def MergePDF(dir_path, file_name):
output = PdfWriter()
outputPages = 0
file_list = GetFileName(dir_path)
print(file_list)
for pdf_file in file_list:
file_type = pdf_file.split('\\')[-1].split('.')[-1]
if file_type != 'pdf':
continue
print("文件:%s" % pdf_file.split('\\')[-1], end=' ')
# 读取PDF文件
input = PdfReader(open(pdf_file, "rb"))
# 获得源PDF文件中页面总数
pageCount = len(input.pages)
outputPages += pageCount
print("页数:%d" % pageCount)
# 分别将page添加到输出output中
for iPage in range(pageCount):
output.add_page(input.pages[iPage])
print("\n合并后的总页数:%d" % outputPages)
# 写入到目标PDF文件
print("PDF文件正在合并,请稍等......")
with open(os.path.join(dir_path, file_name), "wb") as outputfile:
output.write(outputfile)
print("PDF文件合并完成")
if __name__ == '__main__':
# 设置存放多个pdf文件的文件夹
dir_path = r'./orgin_pdf'
# 目标文件的名字
file_name = "dip_1-12.pdf"
MergePDF(dir_path, file_name)
这里我合并的情况是这样子的,我想要把大物11章11个pdf合并起来,方便放到平板上查看。大家用的时候只需要去pip install PyPDF2, 在main函数那里传参改变一下路径就可以了。
输出结果
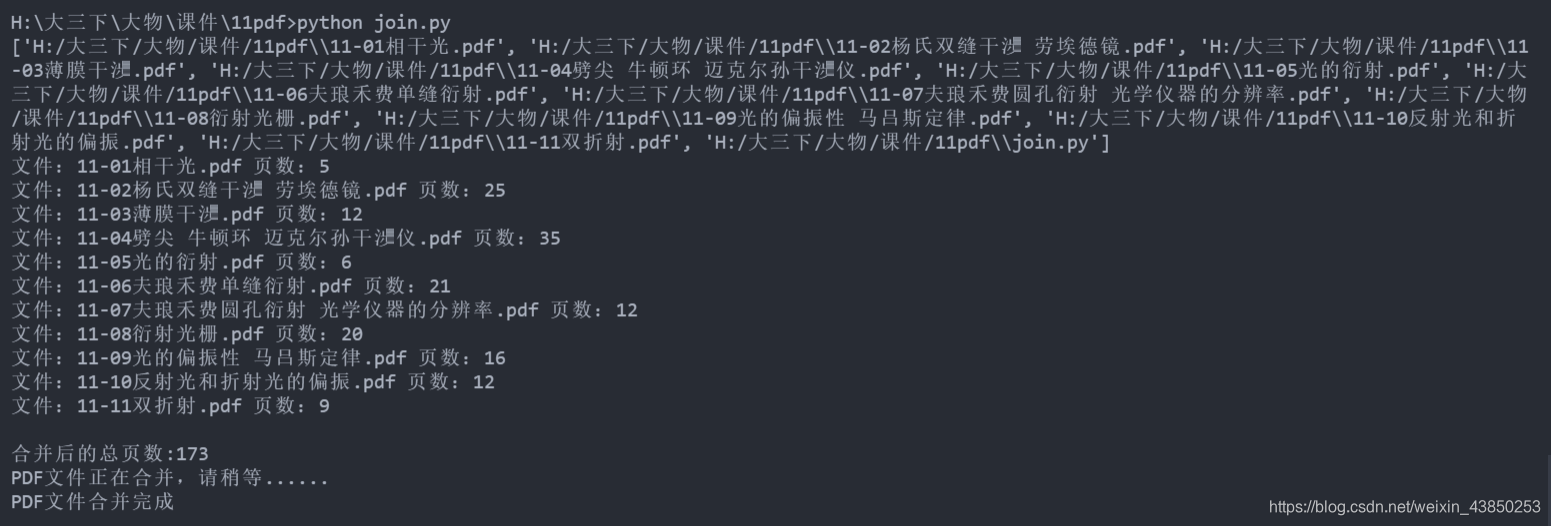
可以看到是源文件夹目录下生成了
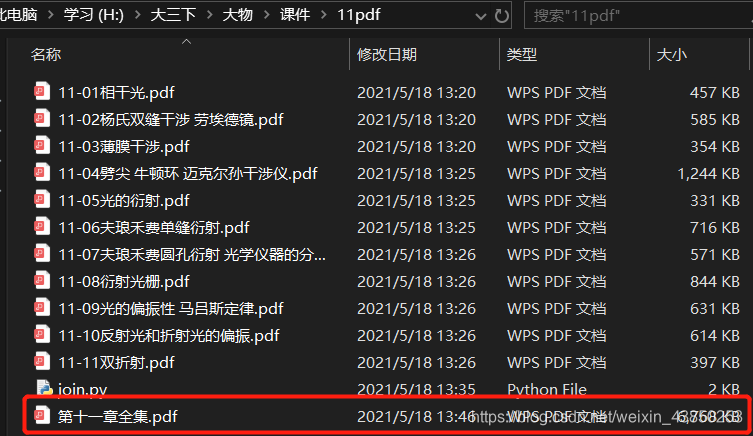
注意事项
- 大家记得重新跑的时候要删除这个pdf(合并后的)再跑哈。
或者可以这样,在write之前添加判断,若存在则删除if os.path.exists("allimages.pdf"): os.remove("allimages.pdf") with open(os.path.join(dir_path, file_name), "wb") as outputfile: output.write(outputfile)
+ 命名记得按顺序,如果是超过10注意个位数前添加0, 不然顺序可能会乱hhh.

















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









