







(硕士期间的一个研究点,希望对大家的科研有帮助)
摘 要
移动智能终端应用于生活中的各个方面,感知终端上运行的应用在广告投放、限制区域内的应用监控等方面都具有重要意义。然而,现有技术需要系统权限来获取运行应用列表,具有很大的局限性。本文提出了基于磁场数据侧信道分析的应用识别技术,通过分析智能终端在运行应用时周围环境磁场的变化来对应用进行识别。该技术使用有限状态自动机对应用启动时磁场数据的窗口进行识别,并使用深度自编码器进行深度特征的提取。真实环境下对1000种不同应用进行识别的结果表明,该方法识别准确率最高可达0.735,而Top 5的准确率可达0.9。**
前言
根据Ericsson的统计数据[1],截至2020年第四季度,全球移动用户总数约为80亿,仅一个季度净增1900万用户。2019年第4季度至2020年第4季度,移动网络数据流量增长51%,达到60EB/月。移动智能设备发展至今,已经成为人们日常生活中必不可少的一部分。移动智能平台上丰富的应用极大方便了生活、工作以及商业活动。与此同时,智能设备的普及带来了移动应用的发展,感知用户终端上运行的应用成为一种需求:广告运营商需要感知用户的应用使用情况来对广告资源的投放进行决策;在部分限制区域(如保密单位、考场等)内,需要对用户的智能设备正运行的应用进行监控,以限制其使用部分应用(如拍照、浏览器等)。然而智能设备系统的权限管理较为严格,不允许非系统应用感知用户正在使用的应用。目前应用识别的方式从工程应用角度主要是通过获取系统的权限(安卓root权限、IOS系统越狱)、获取安卓的无障碍权限和使用ADB来连接智能设备等;在学术领域,主要侧重于研究使用侧信道信息对用户正在使用的应用进行分析,其中侧信道分析根据数据源的不同分为流量分析和基于统计数据侧信道分析。由于流量分析需要获取到用户和互联网之间的交互流量,在实际应用中具有很大的局限性。
针对上述这些问题,本文提出通过传感器数据侧信道分析来感知移动智能设备正在运行的应用的技术,并且不需要获取系统权限和设备流量。本文的主要贡献如下:
(1)本文使用基于有限状态自动机来对磁场数据进行分段,以识别应用启动时的磁场数据窗口;
(2)本文使用深度自编码器来对磁场数据进行深度特征的提取,相对于手动的特征工程,不依赖专家知识,并且提高了应用识别的效率。
相关工作
目前已有的应用识别研究已经有很多成果,按数据来源可以分为基于流量分析的应用识别技术、基于系统统计数据的应用识别技术,其中基于流量分析的应用识别不完全是侧信道分析技术。
基于流量分析的应用识别技术
由于移动应用程序与一般的HTTP通信在协议、端口号等特征上没有区别,导致无法使用简单直观的方式来对移动应用程序的流量进行识别。Xu等人[2]提出识别应用程序可以在User-Agent字段中查找应用程序名称,然而这种方法在Android平台上有严重的局限性,因为众多的Android应用厂商没有统一的字段命名标准,同时这种存在明显标识符的流量仅占移动流量总量的1%左右。Choi等人[3]提出可以利用嵌入在应用程序的辅助服务中心寻找应用标识符,例如A&A广告,但是这种识别的流量覆盖率非常低,这种广告流量只占流量的很小一部分。
随着厂商对于网络安全的愈加重视,大多数的应用使用TLS协议加密的HTTPS流量,这使得通过读取HTTP包内容来识别流量的技术失效。Alan等人[4]提出可以仅使用TCP的握手包来识别移动应用程序,通过监督式机器学习方法,最终在1595个应用程序中达到了88%的准确度,并且即使训练数据过了一周之后,再次识别应用程序的准确率也不会明显下降,但是操作系统和运营商改变会使得准确率显著下降。Choi等人[3]提出在智能设备中安装一个监控代理,这个代理可以进行移动应用程序的识别,利用在校园网中手机的数据,作者生成了基于User- Agent、HTTP主机名字段和IP子网字段的分类器。然而由于隐私问题,在用户设备上安装这样的代理是不现实的。Miskovic等人[5]提出了一个在互联网小流量样本中自动识别移动应用程序的系统AppPrint,该系统学习分散在多个通信流中的应用指纹,最终实现了高达93.7%的准确度。
基于能耗数据、系统日志等系统统计数据的应用识别技术
该领域的相关工作目前较少。Chen等人[6]通过分析 Android设备的能耗统计数据来推断应用程序使用情况。由于Android 设备上的电源配置文件不需要访问许可,因此可以通过系统电量的消耗速度来侧信道分析移动应用的使用情况。实验证明可以识别在任意特定时间使用的应用程序,准确率高达92.9%。Spreitzer等人[7]提出了一种在实践上容易实施和大规模部署的侧信道分析方法,利用Android系统的流量数据使用统计信息来推测用户使用的浏览器和浏览的网页。实验证明,在2500个被监控的页面中正确率为95%,并且即使用户使用了匿名网络来隐藏自己访问的内容,正确率也不会下降。Diao等人[8]利用记录在系统文件(/proc/interrupts)中的中断计数器日志来推断运行的应用程序,他们收集了100个应用程序的训练数据,并随机选择了10个应用程序进行攻击,这10个应用程序Android 5.1上的成功率为87%。Spreitzer等人[9]通过提取Android系统的文件系统Procfs中的日志文件中的信息,并使用机器学习的算法来推测用户使用过的应用,实验证明最终的识别正确率达到76%。
识别方法总体设计
基于磁场数据侧信道分析的应用识别技术对移动智能终端运行应用时的磁场数据进行建模和分析,以此来实现应用识别。首先利用磁场传感器来对移动智能终端周围的磁场数据进行采集,并对其进行预处理;之后,使用自编码器对预处理后的数据提取深度特征;最后,利用深度特征来对分类模型进行训练和应用识别。
本文使用磁场传感器来采集移动智能终端在运行应用时周围的磁场数据。根据相关研究[10],在运行不同应用时,由于CPU的指令顺序的不同,会产生不同模式的电流,电流会激发周围的磁场并产生不同变化模式的磁场;而相同的应用在启动的过程中,指令顺序相对固定,电流的模式基本类似,磁场的变化也基本一致。对磁场数据的变化模式进行分析并提取其中的特征之后,便可以使用机器学习的分类算法对磁场数据进行分类,进而对应用进行识别。

应用识别技术的工作流程如图1所示,主要分为两个阶段:离线训练阶段和线上识别阶段。两个阶段包含三个共同的步骤:数据获取、数据预处理以及特征提取,在离线训练阶段训练分类模型并在线上识别阶段使用训练的模型来进行应用识别。各个步骤的具体描述如下:
1)在数据获取步骤中,使用磁场传感器对移动智能终端周围的磁场进行实时监测,获取可以反映应用运行特征的磁场数据,为后续的数据处理提供有效的数据源。
2)在数据预处理步骤中,对采集到的磁场数据进行预处理,以便于进行特征提取。首先,对采集到的磁场数据滤除异常值,滤除由于传感器硬件原因采集到的异常数据;接着,使用低通滤波对磁场数据滤除高频噪声,减少磁场传感器噪声的影响。在线上识别阶段,使用有限状态自动机来对磁场数据进行监测,找到应用启动的磁场数据窗口,将其切分出来。最后,对环境磁场进行消除处理。
3)在特征提取步骤中,基于自编码器提取预处理后的磁场数据的深度特征。在离线训练阶段,提取应用运行的磁场数据的深度特征向量,并加上应用标签,形成数据集。在线上识别阶段,提取深度特征作为特征向量,作为分类模型的输入,由分类模型进行计算得出应用识别的结果。
除了上述的三个公共步骤之外,在离线训练阶段还有分类模型的训练步骤:利用特征提取步骤中的数据集来训练分类模型的模型参数,并将模型以合适的方式存储以便于在线上识别阶段进行读取;在线上识别阶段读取充分训练后的分类模型,将磁场数据提取的深度特征作为输入向量获取应用分类结果,并将分类结果存储在存储模块中。
识别模型的训练
在离线训练阶段,主要实现对磁场数据特征的提取,根据磁场数据变化模式进行建模,并训练分类模型。本节对移动智能终端应用识别的离线训练阶段进行介绍,主要包括:数据获取,数据预处理,特征提取和训练分类模型。
数据获取

在对移动智能终端设备运行应用时周围的磁场数据进行分析后,本文使用外置的磁场传感器来采集智能终端周围的磁场数据。如图2所示,将外置的磁场传感器放置在智能终端旁进行数据采集。经过大量的对比实验发现,外置的磁场传感器相较于移动智能终端内部部署的磁场传感器具有更好的采集效果,主要体现在磁场数据的噪声更小。这可能是内置的磁场传感器会被应用启动时较大的电流所影响,产生难以消除的噪声;同时外置的磁场传感器具有更高的采样率,相对于移动智能设备的传感器一般不超过100 Hz的采样率来说,外置的磁场传感器采样率一般可达200 Hz以上。对于磁场数据这种变化频率较高的数据种类而言,更高的采样率意味着可以采集到更多磁场变化的细节,可以有效提高应用识别的效果。
本文使用python的scrapy框架从google play store各类别的热门应用排行榜中爬取了总共1000个移动应用,共分为32类。在离线训练的阶段,使用adb命令行工具来自动实现app的安装、运行以及卸载的工作,并记录下每次应用运行时对应的时间戳,若以T表示时间戳,移动应用启动的时间戳集合为 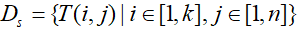 ,其中i为移动应用的种类,k为应用的总类数,n为每个应用采集的次数;与此同时,使用磁场传感器对正在运行应用的移动智能终端采集周围变化的磁场数据以及磁场数据对应的时间戳,以
,其中i为移动应用的种类,k为应用的总类数,n为每个应用采集的次数;与此同时,使用磁场传感器对正在运行应用的移动智能终端采集周围变化的磁场数据以及磁场数据对应的时间戳,以 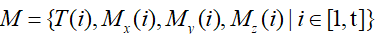 分别表示磁场传感器采集到的x轴、y轴、z轴的数据,则所采集到的磁场数据集为 ,T为时间窗口大小。
分别表示磁场传感器采集到的x轴、y轴、z轴的数据,则所采集到的磁场数据集为 ,T为时间窗口大小。
数据预处理
采集到的磁场数据需要进行预处理才能进一步提取特征。传感器的异常值会对实验结果产生影响,需要对可能产生的异常值进行处理。在采集智能终端周围磁场的数据时,地球磁场以及周围环境中存在的磁性物质的磁场会对采集到的数据产生影响,以至于会影响到后续对基于磁场变化模式进行应用识别的效果,所以需要对地磁场以及环境磁场进行消除。并且由于磁场数据存在高频噪声,为了提高识别效果,使用低通滤波对磁场数据的高频噪声进行过滤。最后,由于磁场传感器到移动智能设备之间的距离不同,会导致磁场数据变化幅度不同,为了缓解这个问题且方便自编码器的训练,将所有数据进行归一化的处理。对数据的预处理分为多个步骤:异常值处理、消除环境磁场、数据去噪和数据归一化。
异常值处理
经过观察发现,磁场数据会产生离群值的异常,通常离群值会比左右两边的磁场数据在数值上高出几百甚至上千。对相邻磁场数据之间的差值设置阈值 =500可以检测到离群值的存在,对于任意的磁场数据,若满足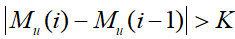 或
或 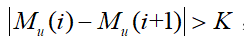
,则将此磁场数据视作离群值,其中 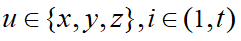 ,对于离群值使用插值法来进行平滑处理,传感器离群值的处理流程为:
,对于离群值使用插值法来进行平滑处理,传感器离群值的处理流程为:
1)遍历磁场数据集 的每一条数据。
2)基于阈值法来判断当前的磁场数据是否属于离群值,若为离群值进行下述的滤除流程,若为正常数据则继续遍历下一条数据。
3)使用插值法来对离群值进行平滑处理以滤除离群值,经过平滑后的离群值的数值为
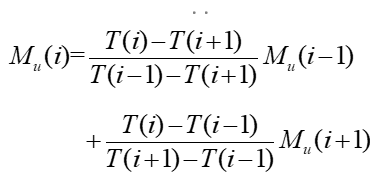
消除环境磁场
在智能终端运行应用的过程中,磁场传感器采集到的数据由环境磁场与智能终端的磁场的叠加。如果以BS作为传感器采集的数据,则有
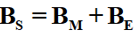
其中BM是移动智能设备运行应用对周围磁场产生的影响,BE是包括地磁场在内的周围环境的磁场的叠加。由于地磁场在一定空间范围内变化幅度不大,且一次应用启动的过程中,周围环境磁场的变化也并不大,因此,在一次应用的启动过程中,将BE作为常量。故可得
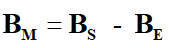
(3)数据去噪
计算得到的 中含有较多的高频噪声,可以使用低通滤波对数据中的高频噪声进行滤除。使用一阶低通滤波对磁场数据进行平滑
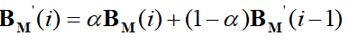
其中alpha为滤波系数,BMI为滤波前的采样值,BMI’为本次滤波后的输出值, 为上次滤波后的输出值。低通滤波将新的采样值与之前的滤波输出值进行加权平均,经过多次试验观察,alpha 取值为0.7可以较好地滤除高频噪声,并且可在一定程度上保留波形的细节。
数据归一化
最后,将进行滤波处理后的数据进行归一化处理。归一化后的数据
(4)
其中 、 分别为 三个维度上的最大值与最小值。归一化操作在不改变数据变化趋势的前提下将所有数据缩放至0-1之间,这样可以有效缓解由于传感器到移动智能设备之间的距离不同而导致的磁场变化幅度不同的问题。
特征提取
对磁场数据进行切分以及预处理之后,需要从磁场数据中提取可以有效反应应用运行特征的深度特征数据。不同于传统的特征工程需要根据数据的特点来手动提取特征,本文使用通过无监督学习的自编码器作为特征提取方式,可以从高维的时间序列数据中提取出有效的深度特征。本节对基于自编码器的磁场数据深度特征的提取进行简要介绍。

自编码器是一种能够通过无监督学习,学到输入数据高效表示的神经网络。自编码器的结构如图3所示,自编码器由一个编码器和一个解码器构成。通过编码器可以将输入的数据进行编码,其维度一般远小于输入数据,使得自编码器可用于数据的降维和深度特征的提取,同时解码器可以将编码后的数据进行解码,恢复成与原始数据几乎相差无几的数据。
自编码器是一个输入和学习目标相同的神经网络。在给定的输入空间 和特征空间 ,自编码器通过求解两者的映射 使得输入数据的重建误差达到最小,即:
其中,n为特征向量的维度,n的大小影响着后续的应用分类的性能,n过小会导致特征空间过小,在进行多类别的分类时,性能会下降;n过大又会导致分类算法的耗时增加。需要在二者之间进行平衡。
使用L2范数作为损失函数来衡量输入和输出之间的差距。在网络的训练阶段,需要预先采集一定数量的磁场数据用作自编码器的训练,经过一定轮次的训练,使得网络的损失收敛时,自编码器具备提取时间序列深度特征的能力。
在用户进行人机交互的过程中,用户的交互操作,如点击、滑动等操作也会对周围的磁场进行扰动,但是在应用启动的过程中,用户的交互行为相对较少,并且相同应用启动的时候,应用所加载的模块、智能设备的中央处理器所执行的指令也相对一致。故在传感器采样率为200 Hz的情况下,针对输入数据中的xyz三轴磁场数据,每个轴各截取前576个数据输入神经网络之中来分别提取深度特征。全连接神经网络与卷积神经网络在本质上并没有差别,理论上全连接神经网络的效果更佳,但是参数多于卷积神经网络;卷积神经网络更容易捕捉相邻数据之间的关系,但是由于降维的需要,在进行池化的过程中会损失一部分的信息。故采用全连接神经网络来对时间序列数据进行编码和解码编码器。
自编码器在训练和提取特征的过程中,将3维的时间序列数据按照维度依次输入网路中,每个维度一次,对于每条数据,总共输入三次;在提取特征时,将每个维度获取的深度特征进行拼接,以获取3维时间序列数据的深度特征。使用经过充分训练的自编码器网络的编码器部分对输入的数据 进行编码,得到低维的深度特征。
训练分类模型
根据NFL定理[11]可知,不同分类算法对于所有问题的总误差期望是相同的,但是对于特定问题而言,每个分类算法的性能都各不相同,所以无法找到一个通用的最佳算法。因此,本文使用多种经典的分类算法进行测试并对结果进行分析,以找到针对应用识别这类问题的有效的分类算法。
实验基于python中的机器学习库sklearn所提供的函数进行分析,对于不同的分类算法有多个可调参数。对于这些参数,难以在有限的时间内进行遍历,因此本文对部分参数经验性选取个别数值来进行试验。在实验中,总共测试了11种算法,如表1所示。
APP在线识别
线上识别阶段分为数据获取、数据预处理、特征提取和应用识别四个步骤。其中数据获取步骤、特征提取步骤分别与3.1和3.3一致,应用识别步骤中使用3.4中训练好的分类模型进行识别。在线上识别阶段的数据预处理步骤中,使用基于有限状态自动机的数据切割操作对获取到的磁场数据进行处理以识别应用启动的窗口。下面对应用启动窗口的识别进行详细阐述。
在数据采集步骤,获取到包含应用启动时的磁场数据。在离线训练阶段,可以通过adb工具记录下的时间戳来对磁场数据进行分片。在线上识别阶段,磁场传感器实时采集移动智能终端周围的磁场数据,此时需要对应用的启动数据窗口进行搜索,并找到包含有应用启动时的磁场数据窗口,本文使用有限状态自动机来对应用启动的窗口进行搜索。

如图4所示,用于搜索应用启动窗口的有限状态自动机分为四个状态:在校准状态中,执行对传感器数据的校准操作,用于减少磁场传感器长时间运行的热效应对磁场数据产成的整体偏移影响;在等待状态中,实时监控磁场数据的变化,在满足一定条件时转移到筛选状态或者重新对磁场数据进行校准;筛选状态对移动智能终端的交互操作进行滤除,避免由于瞬态事件引起的磁场扰动对启动窗口的搜索产生误判;在检测状态中,检测到应用启动,保存相应的磁场数据进行后续处理,并等待应用运行结束转移到等待状态中。下面将对有限状态自动机进行详细阐述:
1)校准状态:系统开始运行时首先进入到校准状态中,对磁场数据进行校准操作。获取环境磁场的基准值,并进行校准,周围磁场稳定时采集磁场的x轴、y轴和z轴数据 。首先采集 秒的数据,并计算磁场数据的均值和方差,根据多次实验观察, >0.5就可以得到较为准确的均值和方差。之后对于采集到的磁场数据计算
其中 对应 的均值和方差, 服从卡方分布。当 时完成磁场数据的校准,节点进入到等待状态,其中 , 为自由度为3的卡方分布的分位数,经过实验和观察,选取满足 的参数,即 ,为12.84。
2)等待状态:等待可能发生的用户交互行为和应用开启行为。当 时,节点进入到筛选状态,其中 。为了解决在长时间的数据采集过程中由于温度、震动等引起的磁场数据整体漂移的现象,在等待状态中如果 且 ,则对磁场数据重新进行校准,其中 是前者的持续时间,通过实验和观察, 可设置为2000 ms。
3)筛选状态:过滤由于用户人机的交互动作以及外界磁场干扰等产生瞬态磁场数据变动。当状态机在筛选状态时,如果 且 ,意味着应用开始运行,节点进入到检测状态中。如果满足 且 ,则重新回到等待状态中。
4)检测状态:在检测状态中,将应用启动过程中的大于 的磁场数据 记录下来,共记录 秒的数据,之后对数据进行进一步处理,以识别应用类别。当 且 ,则重新回到等待状态中。
实验验证
启动窗口识别有效性
上一章节阐述了基于有限状态自动机的应用启动窗口的识别,本节对应用窗口识别的参数进行讨论并对应用窗口识别的有效性进行验证。主要分为四个部分,分别是形成数据集、参数搜索、误差分析以及结果分析。
(1)形成数据集
为了获取线上识别阶段的基于有限状态自动机的启动窗口识别的具体参数,需要获取用户与移动智能终端进行交互时的磁场数据集 ,其中 为用户启动应用时的时间戳,n为应用启动次数。本文对用户与移动智能终端进行交互进行了模拟实验。召集2名志愿者在谷歌pixel2智能终端上进行打开应用和关闭应用两种操作,分别测试了3个应用,每个应用每个操作50次,总计打开应用300次,关闭应用300次。由于安卓系统在关闭应用时会启动系统桌面启动器应用,故关闭应用实质上也是在启动桌面启动器应用,将关闭应用的操作也作为启动应用。
(2)参数搜索
如章节4所述,基于有限状态自动机的应用启动窗口识别总共有3个参数需要确定,分别是 。使用网格搜索法对算法的参数进行遍历和搜索,由于参数值较多且都是离散的,根据经验对于各个参数的搜索范围进行限定。 的参数范围为1000至6000,每隔200取一个测试点,共25个测试参数,同时由于 ,忽略 的参数。 的参数范围为0 ms至500 ms,每隔10 ms取一个测试点,共50个测试点。
(3)误差分析
启动窗口识别的评价指标为平均绝对误差(MAE)和F1分数(f1-score),计算方法如下:
其中, 为识别到的启动窗口开始的时间戳,当启动窗口开始的时间戳和应用真实启动的时间戳的距离小于500ms即认为是正确识别到了应用的启动。TP为正确识别的应用启动窗口数,FP为错误识别和重复识别的应用启动窗口数,FN为漏识别的应用启动窗口数。
(4)结果分析
经过实验以及对实验结果进行分析后可得,当 时,启动窗口识别效果较好,此时MAE为68.6 ms,F1-score为0.902。
特征提取的有效性
编码器对时间序列数据提取特征,编码为长度为n的特征向量。n过小会导致特征空间过小,解码器难以通过有限的信息对原始时间序列进行还原,同时后续进行应用识别时,由于特征包含的信息不足,分类的性能会下降,而n过大又会导致分类算法的耗时增加。故需要在二者之间进行平衡。本节详细阐述特征向量长度n的选取,以对特征提取的有效性进行讨论。
使用3.1中采集的1000个应用进行应用启动的实验,每个应用采集50次应用启动磁场数据,共计50000条数据作为数据集。将数据集按照7:2:1的比例根据应用的类别用分层抽样分为训练集和测试集和验证集,分别为训练集35000条数据,测试集10000条数据,验证集5000条数据。按照上述3.3中的方法对自编码器进行充分训练,具体而言,使用python中的pytorch框架进行编码,对训练集中的每条数据训练1000个轮次,同时学习率设置为0.001,使用Adam优化器对参数进行优化。选取验证集上的损失值达到最低时的网络模型作为最终的训练结果。
参数n的取值范围为 ,选取不同参数,对网络进行训练,并在测试集上进行测试,使用l2范数来对输入的数据和输出的数据的误差进行衡量,即
(8)
其中 为输入的数据, 为编码器输出的数据。
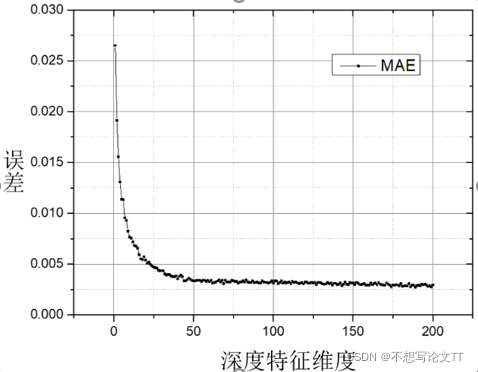
最终的测试结果如图5所示。深度特征的维度为50以上时,自编码器的重建误差基本收敛,故深度特征的维度选为50。对于输入的x、y、z三轴的磁场数据,对每个轴的数据分别提取深度特征,并将获取的深度特征拼接在一起,得到总长度为150的特征向量。
应用识别的性能验证
本文在具体的实验过程中,使用hwt-905外置磁场传感器来对移动智能终端采集磁场数据,实验用的智能设备为谷歌pixel2智能手机。在实验的过程中,按照上述3.1的采集方法来进行磁场数据集的采集工作,将数据集根据应用的种类按照4:1的比例进行分层抽样形成训练集和测试集;对磁场数据进行预处理后对磁场数据每一个维度提取长度为50的深度特征,拼接为长度为150的深度特征,最后使用3.4的分类算法对应用进行识别。
在对应用识别的性能进行评估的过程中,使用的评价指标有:准确度、召回度以及F1值以及Top 3准确度和Top 5准确度。在计算Top N准确度时,每次分类预测N个可能的应用,如果其中包含正确的应用,则认为分类正确。最终的实验结果表明:LinearDiscriminantAnalysis (LDA)和MLPClassifier在应用识别中表现较好,其中LDA的识别准确率可达0.735,F1-score为0.73,Top 5的准确率达到0.9;MLPClassifier在原理上与LDA较为类似,也取得了较为接近的效果,识别准确率达到0.722,但是由于MLPClassifier的参数量较多,且训练时间耗时更多,在应用识别的问题上,LDA算法效果显著好于其他分类算法。
总结
本文首先介绍现有的移动智能设备应用识别技术,在此基础上提出通过分析智能终端周围磁场变化来识别应用。进一步,采用自编码器对磁场数据自动提取深度特征并使用机器学习的算法进行分类,从而判断智能设备正在使用的应用或者正在切换的应用。最后在真实环境下对1000种不同应用进行识别,尝试了多种机器学习模型,实验结果证明了基于磁场传感器识别APP的可行性和有效性。
参考文献
[1] Ericsson.“Ericsson Mobility Report” [EB/OL], https://www.ericsson.com/en/mobility-report,2020
[2] Xu Q, Erman J, Gerber A, Mao Z, Pang J, et al. “Identifying diverse usage behaviors of smartphone apps”[C], in Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference, 2011, 329-344.
[3] Choi Y, Chung JY, Park B, Hong JW-K. “Automated classifier generation for application-level mobile traffic identification”[C], in 2012 IEEE Network Operations and Management Symposium, 2012, 1075-1081.
[4] Alan HF, Kaur J. “Can Android applications be identified using only TCP/IP headers of their launch time traffic?”[C], in Proceedings of the 9th ACM conference on security & privacy in wireless and mobile networks, 2016, 61-66.WiGLE. Statistics [EB/OL], https://wigle.net/stats, 2021.
[5] Miskovic S, Lee GM, Liao Y, Baldi M. “Appprint: automatic fingerprinting of mobile applications in network traffic”[C], in International Conference on Passive and Active Network Measurement, 2015, 57-69.
[6] Chen Y, Jin X, Sun J, Zhang R, Zhang Y. “POWERFUL: Mobile app fingerprinting via power analysis”[C], in IEEE INFOCOM 2017-IEEE Conference on Computer Communications, 2017, 1-9.
[7] Spreitzer R, Griesmayr S, Korak T, Mangard S. “Exploiting data-usage statistics for website fingerprinting attacks on Android”[C], in Proceedings of the 9th ACM Conference on Security & Privacy in Wireless and Mobile Networks, 2016, 49-60.
[8] Diao W, Liu X, Li Z, Zhang K. “No pardon for the interruption: New inference attacks on android through interrupt timing analysis”[C], in 2016 IEEE Symposium on Security and Privacy (SP), 2016, 414-432.
[9] Spreitzer R, Kirchengast F, Gruss D, Mangard S. “Procharvester: Fully automated analysis of procfs side-channel leaks on android”[C], in Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 2018, 749-763.
[10] Cheng Y, Ji X, Xu W, et al. MagAttack: Guessing Application Launching and Operation via Smartphone[C]//Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security. 2019: 283-294.
[11] Wolpert D H, Macready W G. No free lunch theorems for optimization[J]. IEEE transactions on evolutionary computation, 1997, 1(1): 67-82.















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









