










线性回归逻辑回归的详细介绍
引言:
机器学习(Machine Learning),是指赋予机器学习的能力以此让它完成直接编程无法完成的功能方法。实践:通过利用数据,训练出模型,然后使用模型预测的一种方法。
ML
>机器学习分类:
1.有监督学习(分类,回归);
2. 半监督学习(分类,回归,transductive learning 直推式学习);
3.半监督聚类(有标签数据但是标签不明确,比如:肯定不是…;可能是…);
4. 无监督学习(聚类,降维);
一、线性回归
简述
①在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合(自变量都是一次方)。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
②优点:结果易于理解,计算上不复杂,主要对连续数据预测。
③缺点:对非线性数据拟合不好。
④适用数据类型:数值型和标称型数据。
⑤算法类型:回归算法(监督学习)
⑥举例说明:房价预测
案例:
比如你是房产公司的一名职员,现在经理交给你一份任务。有一批房子需要你给出合理的预测价格,你会怎么做呢?方法就是使用回归预测,首先会有两个特征(房价和面积),想要预测出房价,要收集一些以往的数据或者调查周边类似的房子获取一组数据;然后拟合一条直线(如下图)
*房价模型由拟合模型决定,是直线拟合出直线方程,抛物线拟合出抛物线 方程,数据越多,生成模型预测效果越好。
*对新数据的预测过程叫“预测”;过程中输出的结果是“模型”;“模型”,“预测”是机器学习的两个过程。
训练产生模型,模型指导预测。
a) 数据集:(Xi,Yi) Y=>R
b) 估计值(假设函数):hθ(x)=θ0+θ1x=θ0∗1+θ1∗x1=θTX
c) 误差值:h(x)-y
d) 代价函数(cost function)【评价与预测值与实际值之间的误差】:
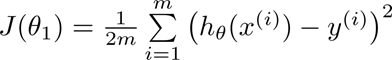
代价函数图像:
e) 梯度下降(gradient descent)【通过迭代寻找最优模型参数】:
求解最优解的方法有 最小二乘法 和 梯度下降法
首先,我们有一个代价函数,假设是J(θ0,θ1)J(θ0,θ1),我们的目标是 minθ0,θ1J(θ0,θ1)minθ0,θ1J(θ0,θ1)。
接下来的做法是:
首先是随机选择一个参数的组合(θ0,θ1)(θ0,θ1),一般是设θ0=0,θ1=0θ0=0,θ1=0;
然后是不断改变(θ0,θ1)(θ0,θ1),并计算代价函数,直到一个局部最小值。之所以是局部最小值,是因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值,选择不同的初始参数组合,可能会找到不同的局部最小值。
下面给出梯度下降算法的公式:
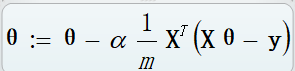
二、 多项式回归
线性回归并不适合所有数据,有时需要曲线来适应数据
二次方模型:(多项式回归)
hθ(x)=θ0+θ1x+θ2x^

梯度下降: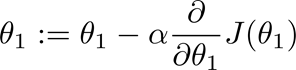
①:如果a学习率过大,梯度下降太慢会导致梯度消失,

②: 如果a太大,梯度下降可能会太快,导致梯度爆炸

通常考虑学习率:
a=0.01 , 0.03 , 0.1 , 0.3 , 1 , 3 , 10 。。。
总结:
在多维特征问题中,要保留特征相近的尺度,这些可以帮助梯度下降算法更快收敛;特征缩放思想:确保这些特征都处在一个相近的范围。
三、逻辑回归
简述:
① 线性回归(linear regression),处理是数值问题,最后预测结果是数字,如:房价。
② 逻辑回归(logistic regression),属于分类算法,预测结果为离散分类,监督学习,在统计概率过程中是回归,最后判断决定概率值是分类(二分类问题)如:邮票是否为垃圾邮件;肿瘤是否为恶性。
输出两类{0,1},0:负向类;1:正向类。
③案例:
如图,现有一批病人去医院诊治,医生会根据他们的病例,判断他们是否患为肿瘤早起还是晚期。

假设有一个二分类问题,输出为y∈{0,1}y∈{0,1},而线性回归模型产生的预测值为 z=wTx+bz=wTx+b 是实数值,我们希望有一个理想的阶跃函数来帮我们实现z值到0/10/1值的转化。
有一个单调可微的函数来供我们使用,于是便找到Sigmoid function来替代
ϕ(z)=1/1+e−z。
如图:sigmoid函数范围在[0,1]区间。
①z 小于0时,y=0
②z 等于0时,y=0.5
③z 大于0时,y=1

逻辑回归与自适应线性网络非常相似,两者的区别在于 逻辑回归 的激活函数是Sigmoid function而自适应线性网络的激活函数是y=x,

自适应网络

逻辑回归网络
1) 计算代价误差值,首先想到的是模仿线性回归,但是那样会出现一个(非凸函数)局部最小值(如图),这样不利于我们求解:
所以我们在这要使用sigmoid函数来避免局部最优值。

2) 代价函数
①逻辑回归模型:

②代价函数 cost function:
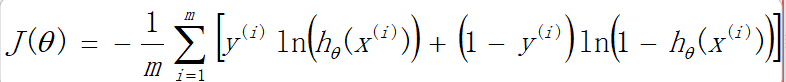
③梯度函数 gradient function:
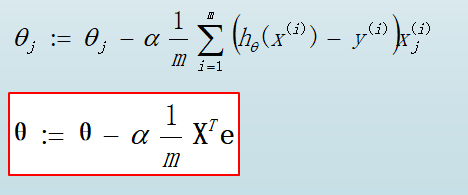
④:函数在梯度下降的时候可能会会出现过拟合或欠拟合的现象。
a) 发生过拟合原因:因为没有足够的数据集去约束过多的模型。
b) 过拟合:即高方差,低偏差。准确率很高,但是不稳定,预测结果比较发散;
c) 欠你和:即高偏差,低方差。准确率低,但是模型稳定,预测结果集中。

d) 解决方法:
减少变量数量(PCA),丢弃一些不能帮助我们正确预测的特征,手动选择需要保留特征;
保留所有特征,正则化。
e) 解决(高方差) 过拟合:
获取更多训练实例;
减少特征数量;
增加正则化成度(拉姆达)。
解决(高偏差)欠拟合:
获得更多特征;
增加多项式特征;
减少正则化(拉姆达)。
作者:程拾叁
来源:CSDN
版权声明:本文为博主原创文章,转载请附上博文链接!















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









