







pom依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aliyun</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.8.1</version>
</dependency>
core-site.xml配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>oss://bucketname/</value>
</property>
<property>
<name>fs.oss.endpoint</name>
<value>oss-endpoint-address</value>
<description>Aliyun OSS endpoint to connect to.</description>
</property>
<property>
<name>fs.oss.accessKeyId</name>
<value>oss_key</value>
<description>Aliyun access key ID</description>
</property>
<property>
<name>fs.oss.accessKeySecret</name>
<value>oss-secret</value>
<description>Aliyun access key secret</description>
</property>
<property>
<name>fs.oss.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem</value>
</property>
</configuration>
HudiDemoOss.java
package com.leesf;
import org.apache.hudi.QuickstartUtils.DataGenerator;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.io.IOException;
import java.util.List;
import static org.apache.hudi.QuickstartUtils.convertToStringList;
import static org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs;
import static org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME;
import static org.apache.spark.sql.SaveMode.Overwrite;
/**
* Writing data into hudi on aliyun OSS.
*/
public class HudiOssDemo {
public static void main(String[] args) throws IOException {
SparkSession spark = SparkSession.builder().appName("Hoodie Datasource test")
.master("local[2]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.io.compression.codec", "snappy")
.config("spark.sql.hive.convertMetastoreParquet", "false")
.getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
String tableName = "hudi_trips_cow";
String basePath = "/tmp/hudi_trips_cow";
DataGenerator dataGen = new DataGenerator();
List<String> inserts = convertToStringList(dataGen.generateInserts(10));
Dataset<Row> df = spark.read().json(jsc.parallelize(inserts, 2));
df.write().format("org.apache.hudi").
options(getQuickstartWriteConfigs()).
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath);
Dataset<Row> roViewDF = spark.read().format("org.apache.hudi").load(basePath + "/*/*/*");
roViewDF.registerTempTable("hudi_ro_table");
spark.sql("select * from hudi_ro_table").show(false);
spark.stop();
}
}
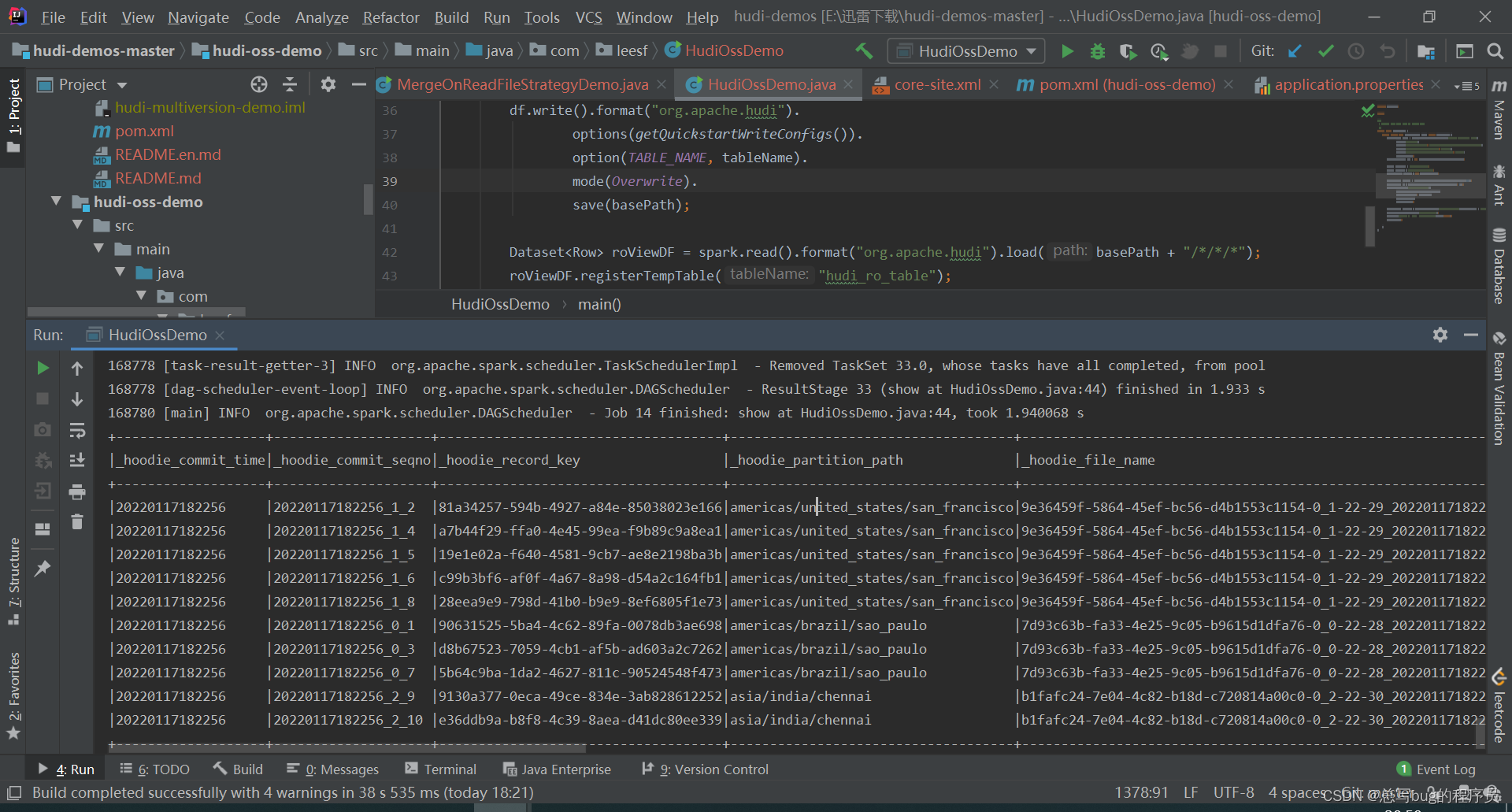
idea运行
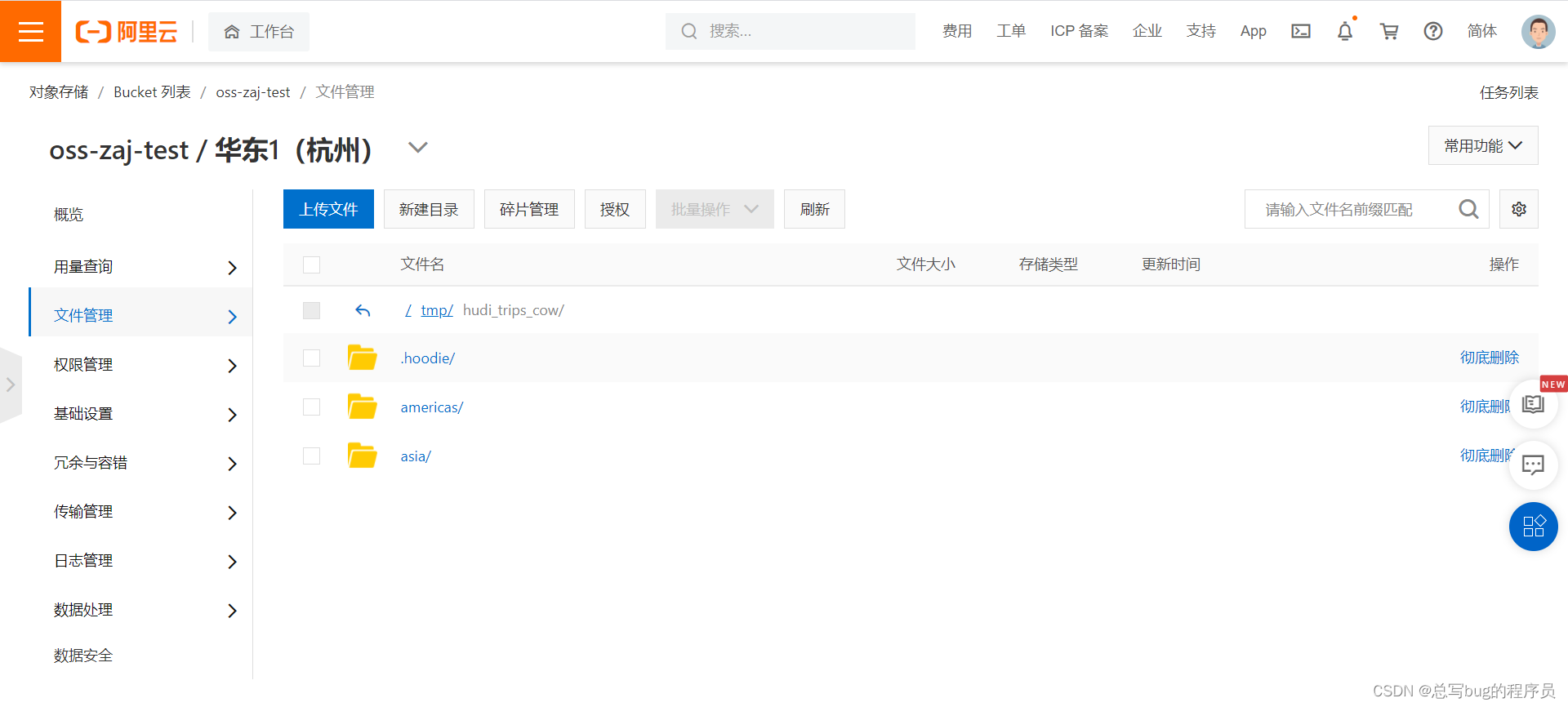
阿里云控制台














 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









