







框架简介
WebMagic框架包含四个组件,PageProcessor、Scheduler、Downloader和Pipeline。
这四大组件对应爬虫生命周期中的处理、管理、下载和持久化等功能。
这四个组件都是Spider中的属性,爬虫框架通过Spider启动和管理。
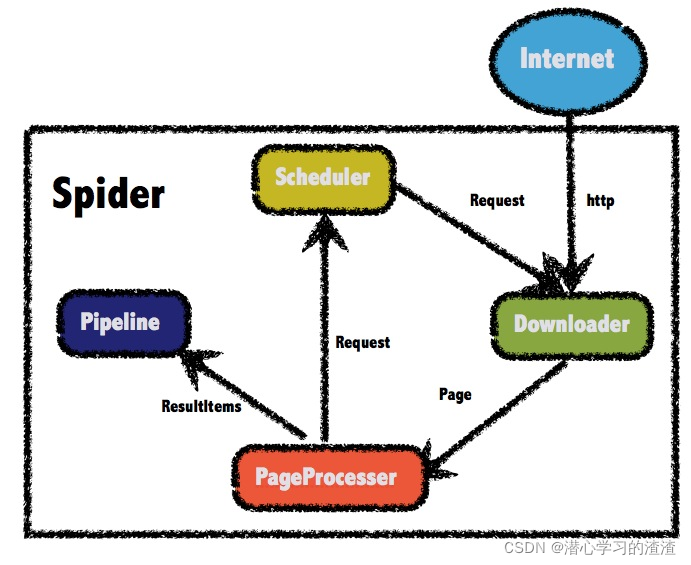
一、WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
一般无需自己实现。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
二、用于数据流转的对象
1. Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
2. Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。在第四章的例子中,我们会详细介绍它的使用。
3. ResultItems
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
三、页面元素的抽取
如何从中抽取到你想要的信息?
WebMagic里主要使用了三种抽取技术:XPath、正则表达式和CSS选择器。另外,对于JSON格式的内容,可使用JsonPath进行解析。
1、XPath
XPath本来是用于XML中获取元素的一种查询语言,但是用于Html也是比较方便的。例如:
page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()")
这段代码使用了XPath,它的意思是“查找所有class属性为’entry-title public’的h1元素,并找到他的strong子节点的a子节点,并提取a节点的文本信息”。 对应的Html是这样子的:
xpath-html
2、CSS选择器
CSS选择器是与XPath类似的语言。如果大家做过前端开发,肯定知道$(‘h1.entry-title’)这种写法的含义。客观的说,它比XPath写起来要简单一些,但是如果写复杂一点的抽取规则,就相对要麻烦一点。
3、正则表达式
正则表达式则是一种通用的文本抽取语言。
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());
这段代码就用到了正则表达式,它表示匹配所有(.all())"https://github.com/code4craft/webmagic"这样的链接。
4、JsonPath
JsonPath是于XPath很类似的一个语言,它用于从Json中快速定位一条内容。WebMagic中使用的JsonPath格式可以参考这里
四、链接的发现
一个站点的页面是很多的,一开始我们不可能全部列举出来,于是如何发现后续的链接。使用正则表达式:
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());
page.getHtml().links().regex("(https://github\.com/\w+/\w+)").all()用于获取所有(.all())满足"(https:/ /github.com/\w+/\w+)"这个正则表达式的链接,
page.addTargetRequests()则将这些链接加入到待抓取的队列中去。
QuickStart
目标爬取 不是天津饭的博客 的博客
网址:http://blog.sina.com.cn/s/articlelist_1487828712_0_1.html
1、添加MAVEN坐标
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
2、创建类 SinaBlogProcessor
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.JsonFilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class SinaBlogProcessor implements PageProcessor {
//列表页
public static final String URL_LIST = "http://blog\\.sina\\.com\\.cn/s/articlelist_1487828712_0_\\d+\\.html";
//文章网址
public static final String URL_POST = "http://blog\\.sina\\.com\\.cn/s/blog_\\w+\\.html";
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
// Site 对站点本身的一些配置信息进行配置
private Site site = Site
.me()
.setDomain("blog.sina.com.cn") // 设置域名
.setSleepTime(3000) //
.setUserAgent( //设置UserAgent
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public void process(Page page) {
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
// 从页面发现后续的url地址来抓取
page.addTargetRequests(page.getHtml().xpath("//div[@class=\"articleList\"]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页
} else {
// 定义如何抽取页面信息,并保存下来
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",
page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("\\((.*)\\)"));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
// Spider 是爬虫启动的入口
Spider.create(new SinaBlogProcessor()) // 创建Spider
// 添加初始URL,从http://blog.sina.com.cn/s/articlelist_1487828712_0_1.html开始爬
.addUrl("http://blog.sina.com.cn/s/articlelist_1487828712_0_1.html")
//保存结果,使用Pipeline方法,以Json的格式保存下来
.addPipeline(new JsonFilePipeline("D:\\webmagic\\"))
.run(); //启动
}
3、查看结果D:\webmagic\
(Json格式)部分爬取结果:
举例:解析页面
一、列表页
1、下一页 URL_LIST
网址:http://blog.sina.com.cn/s/articlelist_1487828712_0_1.html
可以点下一页,会发现 _1.html 中数字是可以变化的
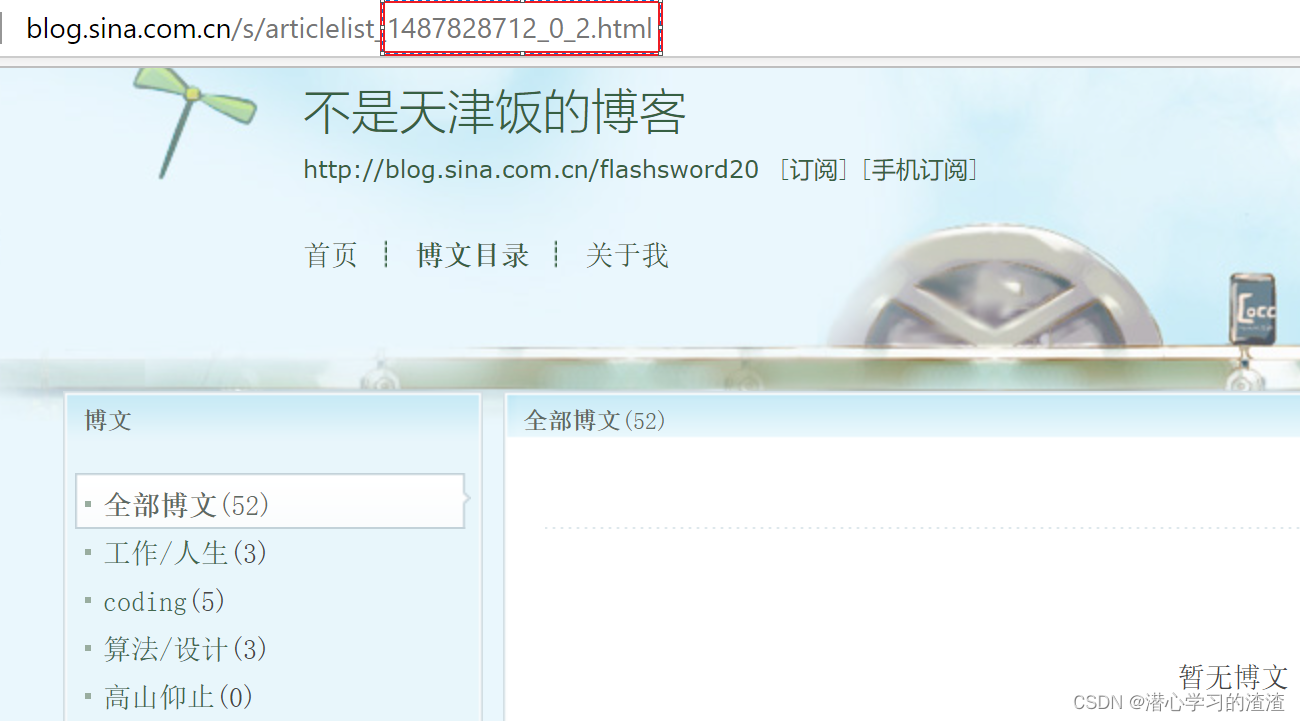
对应的正则匹配式写法
正则表达式则是一种通用的文本抽取语言。
page.addTargetRequests(page.getHtml().links().regex("http://blog\\.sina\\.com\\.cn/s/articlelist_1487828712_0_\\d+\\.html").all());
2、进入对应文章页URL_POST
其中红框是我们需要的文章页:
文章页网址如:http://blog.sina.com.cn/s/blog_58ae76e80100to5q.html
最后一段是可变的字符串,58ae76e80100to5q为文章的id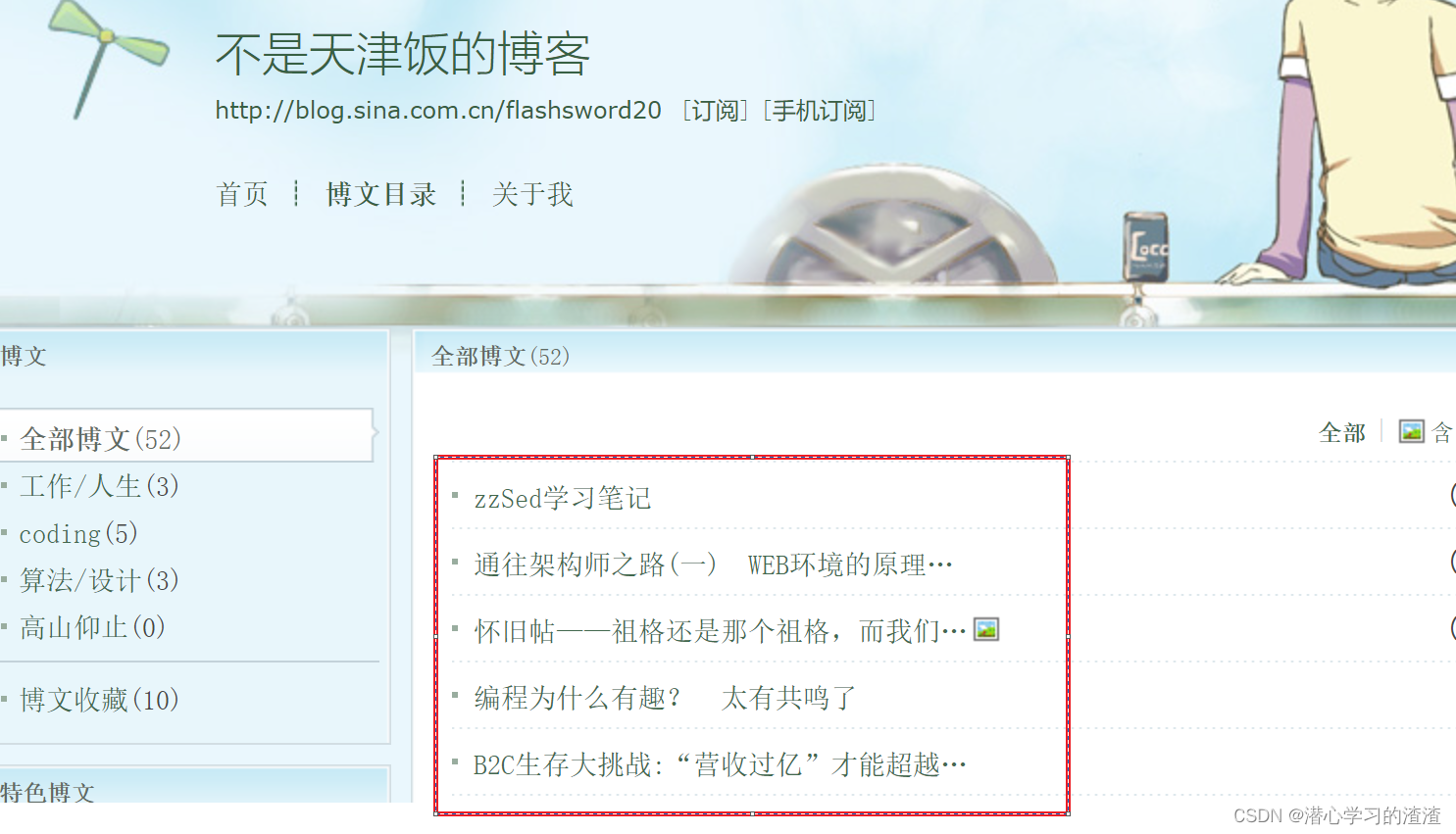
打开页面源码找到我们需要的内容
对应的源码部分 <div class=“articleList”> <div>内的内容

对应的正则匹配式写法
page.addTargetRequests(page.getHtml().xpath("//div[@class=\"articleList\"]").links().regex("http://blog\\.sina\\.com\\.cn/s/blog_\\w+\\.html").all());
二、文章页
其中红框是我们需要的内容:
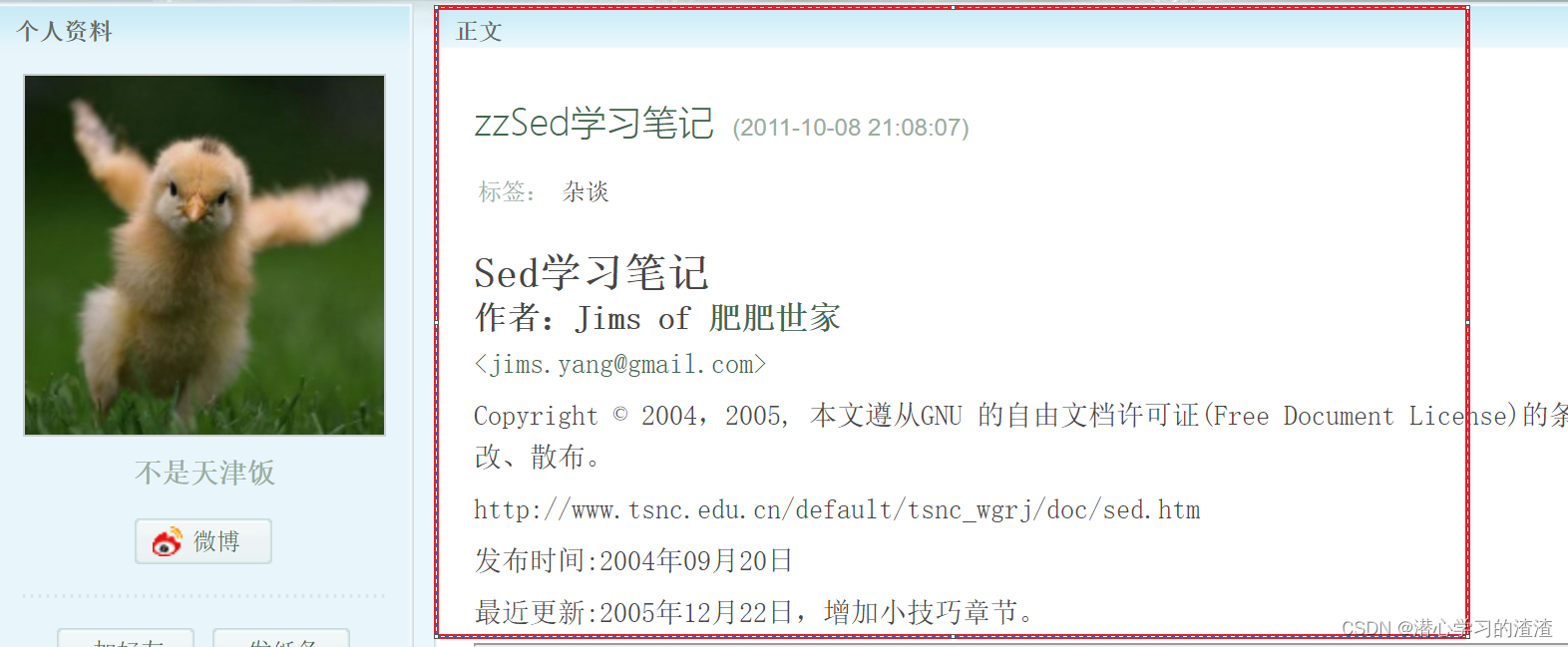
打开页面源码找到我们需要的内容
对应的源码部分:
1、 <div class=“articleTitle”><h2></h2> </div>

对应的XPath写法
XPath本来是用于XML中获取元素的一种查询语言,但是用于Html也是比较方便的
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
2、<div id=“articlebody” ><div class=“articalContent”></div></div>
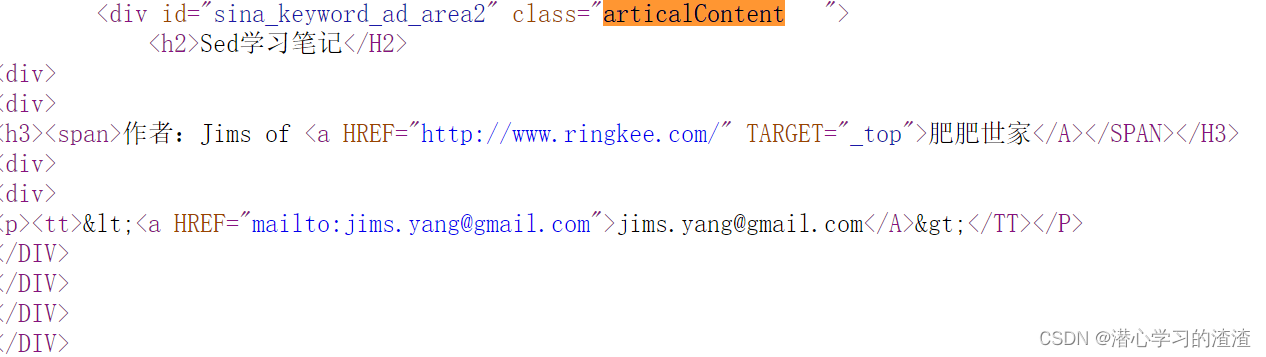
对应的XPath写法
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
3、<div id=“articlebody” ><span class=“time SG_txtc”></div></div>

对应的XPath写法
page.putField("date",page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("\\((.*)\\)"));
三、区分列表页和文章页
是否能匹配(.match())到列表页的正则表达式?
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
// 从页面发现后续的url地址来抓取
page.addTargetRequests(page.getHtml().xpath("//div[@class=\"articleList\"]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页
} else {
// 定义如何抽取页面信息,并保存下来
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",
page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("\\((.*)\\)"));
}
参考文献
- http://webmagic.io/docs/zh/posts/ch1-overview/architecture.html
- https://www.cnblogs.com/justcooooode/p/7913365.html
- https://segmentfault.com/a/1190000023531076














 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









