







JVM
- 类加载机制
虚拟机将class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,此为类加载机制
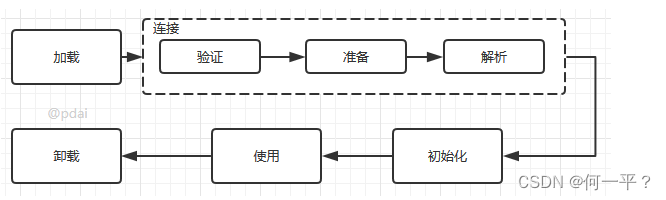
类加载过程包括:加载、验证、准备、解析和初始化五个阶段,其中验证、准备和解析3个部分统称为连接
注意:解析不一定在初始化前执行,也有可能在初始化后,为支持Java的运行时绑定
各个阶段的作用:
- 加载:查找并加载类的二进制文件
- 验证:确保被加载类的正确性
- 准备:为类的静态变量分配内存,并将其初始化为默认值
- 解析:把类中的符号引用改为直接引用
- 初始化:为类的静态变量赋予正确的初始值,JVM负责对类进行初始化,主要对类变量进行初始化
- 双亲委派机制
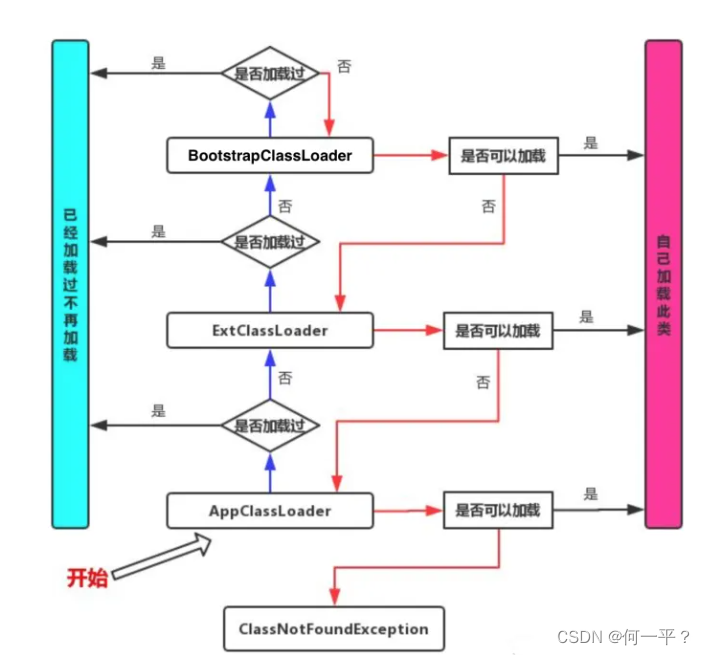
当一个class文件要被加载时,首先检查应用加载器是否加载过,如果加载过,则返回,否则则向上,找父加载器,父加载器验证是否加载过,加载过则返回,否则依次递归向上找,直到BootsrapClassLoader之前,都是再验证是否加载过,而不是直接去加载,到BootsrapClassLoader加载器,这时候考虑是否自己能加载,如果自己不能加载,则向下让子类去加载,一直到底层加载器都无法加载,则会抛出异常
- JVM内存结构
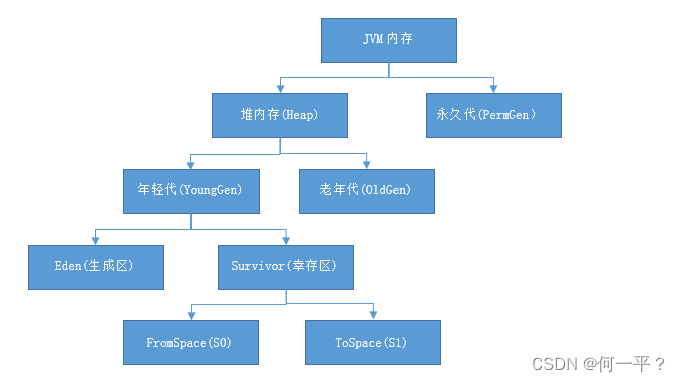
线程私有的有:程序计数器、虚拟机栈、本地方法栈
线程共享的有:堆和方法区
- 程序计数器:用于保存JVM下一条所要执行指令的地址
- Java虚拟机栈:每个线程运行需要的内存空间,每个方法执行的同时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等
- 本地方法栈:是一些带有native关键字的方法,需要Java去调用本地的C或C++方法
- Java堆:是被所有线程共享的一片区域,虚拟机启动时创建,存储对象实例,通过new关键字创建的对象都会使用堆内存
- 方法区:用于存储已被虚拟机加载的类信息、常量、静态变量和即时编译后的代码等
- 判断是否可进行垃圾回收的算法?
引用计数器和可达性分析
- 引用计数器,当对象增加引用时,计数器加一,减少引用时,计数器减一,计数器为0时,则可以被回收;缺点是:会出现循环引用的情况,两个对象互相引用,Java虚拟机不使用此方法
- 可达性分析:通过GC Roots 作为起点进行搜索,能够到达的对象都是存活的,不能到达的都是可被回收的
GC Roots 一般包含哪些?
- 虚拟机栈中引用的对象
- 本地方法栈中引用的对象
- 方法区中类静态属性或常量引用的对象
- 垃圾回收算法
- 标记清楚算法:将存活的对象进行标记,然后清理掉,未被标记的对象,缺点是:会产生大量不连续的内存碎片,导致无法给大对象分配内存
- 标记整理算法:先采用标记清楚算法确定可回收的对象,然后整理剩余对象,将可用的对象移动到一起,使内存紧凑,优点是内存利用率高,缺点是速度慢
- 复制算法:将内存分为两个等大小的区域from和to(to中为空),将GC Roots引用的对象,从FROM放入TO,再回收FROM中不被引用的对象,此时交换from和to。优点是,不会有碎片产生,缺点,只能利用一半的内存空间
- 分代收集,根据对象的存活周期,将内存划分为几块,不同块采用不同的算法
一般分为新生代(伊甸区(新产生的对象会在这里)和幸存区(经过一次Mintor GC之后会进入幸存区))和老年代,老年代是每次回收只有少量的对象需要回收(标记清楚或标记整理),而新生代每次都有大量的对象需要被回收(复制算法)
- 避免内存泄露的方法?
尽量不要使用,static成员变量,减少生命周期
及时关闭无用的资源
不用的对象,可以手动设置为null
面向对象
- 重载和重写的区别
重载是指在同一类中可以有多个方法名相同但参数类型、参数个数或参数顺序不同的方法
重写是指在子类中,可以对父类中的方法,进行重写, 重写方法必须与被重写方法拥有相同的方法名、返回值类型和参数列表,但是可以更改访问修饰符(访问修饰符范围大于等于父类)、抛出的异常类型(抛出的异常范围小于等于父类)、方法返回值(方法返回值,小于等于父类)和方法体等。
- 接口和抽象类的区别
- 所使用的关键字不同,接口定义时,所用的关键字是:interface,抽象类是abstract
- 接口中只能包含抽象方法、静态方法和default关键字修饰的默认方法,不能包含实例变量和构造函数
- 抽象类中,除了可以定义抽象方法外,还能定义非抽象方法,可以有实例变量和构造函数
- 从继承性来看,一个类,只能继承自一个抽象类,但可以实现多个接口,抽象类表现的是一种,“is a”的思想,而接口表达的是一种 “like a”
- 抽象类设计的目的是提供类的继承机制,实现代码复用;而接口是为了提供一种规约,实现类遵循特定的行为和功能
- equals 和“==”的区别
在Java中,== 是一个比较操作符,用于比较两个变量的值是否相等,而equals是Object类中定义的方法,用于比较两个对象是否相等
== ,对于基本数据类型比较的是两个变量的值是否相等,对于引用类型,比较的是两个对象,所指向的地址值是否相等
equals 用于比较两个对象的内容是否相等,在equals没有被重写的情况下,和== 的作用是一样的,比较的是对象的地址值,但可根据,实际需要,对equals 进=进行重写,以实现自定义的比较逻辑
- final 、finally 和finalize的区别
final是一个修饰符,修饰类,表示类不能被继承;修饰变量,表示变量不能被修改;修饰方法,表示方法不能被重写
finally 是一个关键字,通常和try……catch一起使用,表示,无论是否发生异常,被finally包裹的代码块,都会被执行,通常用于资源的释放,连接关闭
finalize,是object中定义的方法,被用于垃圾回收时,由垃圾回收器进行自动调用
- String、StringBuilder和StringBuffer的区别
从可变性上来看,String是不可变的(底层是final修饰的字符数组),每次针对String对象的操作,都会创建新的对象;而StringBuilder和StringBuffer都是可变对象
从线程安全的角度看,String(不可变)和StringBuffer(方法被Synchronized修饰)是线程安全的,而StringBuilder不是线程安全的,多线程环境下,需要手动进行同步控制
从性能来看,String的性能是最差的,因为其不可变性,每次操作都会创建新的对象,会导致内存消耗;StringBuffer,因其可变性,针对字符串的修改,是在原有的对象上操作,性能更好;StringBuilder和StringBuffer类似,但不保证线程安全,单线程环境下性能会更好
- Java基本数据类型?
byte、short、int、long
float、double
char
boolean
集合
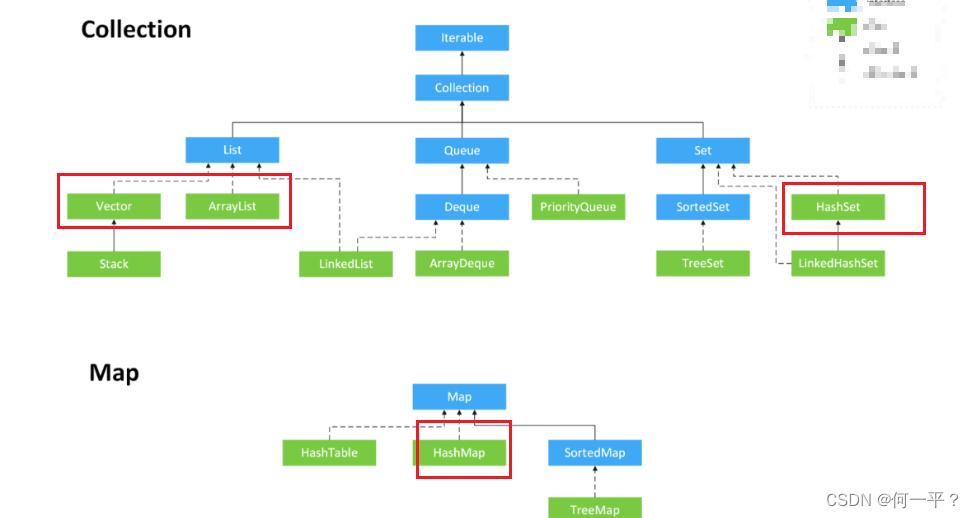
- Java中的容器有哪些?
容器包含:collection和Map两大类,collection是存储对象的集合,而Map是存储着键值对的映射表。
- ArrayList和LinkedList的区别?
数据结构不同,arrayList是基于数组实现的,linkedList基于双向链表实现
查找效率不同,因arrayList是基于数组的,对集合内元素的访问,可以直接通过下标,而linkedList,则需要通过遍历获取要查找的元素
增删效率,对于,非收尾的增加和删除,linkedList的效率要高,因为arrayList需要移动和复制数组,效率要低
- Vector 和ArrayList的区别?
两者底层都是数组
vector里面的方法(例如:add、remove)都是通过synchronized关键字修饰,所以是线程安全的,性能更低,arrayList不是线程安全的
扩容机制,vector每次扩容为原来的两倍(没有指定扩容递增值capacityIncrement的情况下),而arrayList,每次为原来的1.5倍
- ArrayList的扩容机制?
arrayList,调用add方法的时候通过ensureExplicitCapacity 方法判断是否需要扩容
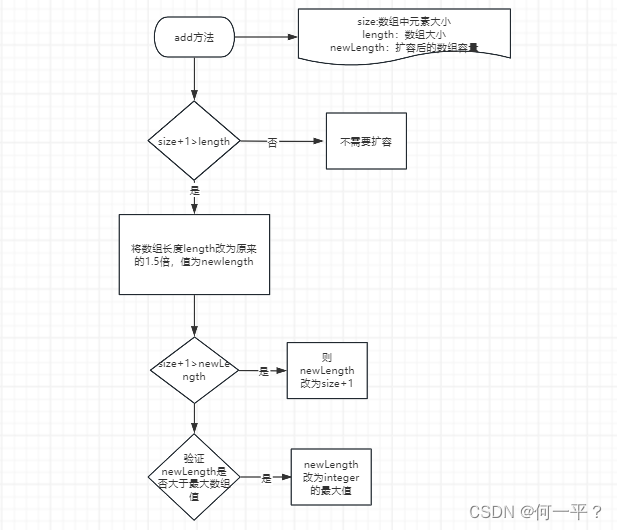
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 扩容为原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 验证后扩容后是否满足
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 不满足,则验证是否大于最大的数组值(integer最大值-8)
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
- HashMap的实现原理?
JDK1.7时,底层数据结构为数组+链表
JDK1.8时,底层数据结构为数组+链表/红黑树
hashMap通过,hash函数,计算得到hash值,通过(n-1)& hash(n为数组的长度),获取元素存放的位置,如果当前位置存在元素,则判断值(此处指的是key值)是否相同,相同则替换,不相同,则通过拉链法(将同一hash值的数据,以单链表的形式进行存储)解决hash冲突。
而JDK1.8 引入红黑树,主要解决,链表太长,所造成的查询性能问题
- hashMap什么时候会扩容?
put元素后,验证此时,map中元素的个数+1,是否大于数组的初始容量*负载因子(默认0.75),大于则扩容,扩容变为原来的二倍
++size(map中元素个数) > threshold(数组容量*0.75)
- hashMap中put方法的执行流程?
- 计算key的hash值
- 若数组为0,则初始化数组
- 如果通过hash计算出的key所对应的下标,里面没有元素,则直接放入
- 如果存在元素,则验证此处对应key的第一个元素key是否和待插入的key相同,相同则进行替换
- 如果存在元素,且第一个元素是树节点,则将此key放入树节点中
- 如果存在元素,且第一个元素是链表,则将其放入链表中
- 验证链表是否需要树化
- 插入元素之后验证,数组是否需要扩容
- hashMap中get方法的执行流程?
- 计算key对应的hash值
- 找到key所在位置的第一个元素
- 如果是其待查找的key,则将对应值返回
- 若是树节点,则按照树的方式查找
- 若是,链表,则按照链表的方式查找
- 没有则返回null
- hashMap什么时候树化?什么时候树化退化?
树化满足的条件:
- 链表长度超过树阈值>8
- 数组容量大于等于64
当链表长度大于阈值8之后,先尝试扩容减少链表长度,如果数组已经达到64,则会树化
树退化的两种场景:- 扩容时,如果拆分树,树元素个数小于等于6,则退化为链表
- 移除树节点时,若root、root.left、root.right,有一个为null,则退为链表
- hashMap的扩容因子为啥默认是0.75?
在空间占用和查询时间之间获取平衡
大于这个值,空间节省了,但是链表就会较长,而影响查询性能
小于这个值,冲突减少了,但是扩容频繁,空间占用多
- hashMap为什么使用红黑树?
主要为了提供查询性能,红黑树本身是一种平衡二叉树,插入数据时,会通过左旋、右旋等操作,来保持平衡,解决单链表查询深度的问题
- hashMap和hashTable的区别?
- hashtable,是线程安全的,底层方法是通过synchronized关键字修饰,hashMap是线程不安全的,hashMap性能更高,线程安全推荐使用ConcurrentHashMap
- hashMap允许key和Value为null值,hashtable不允许
- 扩容机制不同,不指定初始容量时,hashtable初始容量为11,每次扩容为原来的2n+1,hashmap默认初始容量为16,每次扩容为原来的两倍,如果指定初始容量,hashtable,则直接使用初始容量,而hashMap,则是,将初始容量定为指定容量的二倍
- 底层数据结构不同,hashmap通过链表和红黑树,来解决hash冲突,而hashtable没有
I/O
反射
异常
- finally块中的代码什么时候会被执行
finally 块的作用,就是为了保证,无论出现什么情况,finally块中的代码都会被执行,finally中的代码,会在return之前执行
多线程
- 线程和进程的区别
进程:内存中的运行程序,具有独立的内存空间,一个进程可以有多个线程(进程是资源分配的最小单元)
线程:进程中的一个控制单元,线程拥有独立的运行栈和程序计数器,线程间共享方法区和堆内存(线程是任务调度的最小单元)
- 并行和并发的区别
并发:多个任务在同一个CPU上,按照细分的时间片,交替执行
并行:单位时间内,多个CPU同时处理多个任务
- 用户线程和守护线程的区别
用户线程运行在前台,执行具体的任务,比如程序的执行入口:main线程
守护线程,主要为用户线程提供服务的,也叫:服务线程、精灵线程,一旦所有的非守护线程退出后,守护线程也会结束
JVM中垃圾回收线程,就是典型的守护线程
守护线程设置:new Thread().setDaemon(true);
- 线程的状态:
线程状态的几种说法?
5种状态,创建、就绪、运行,阻塞、终止
6种状态,创建、就绪、阻塞、计时状态、无限等待状态、终止
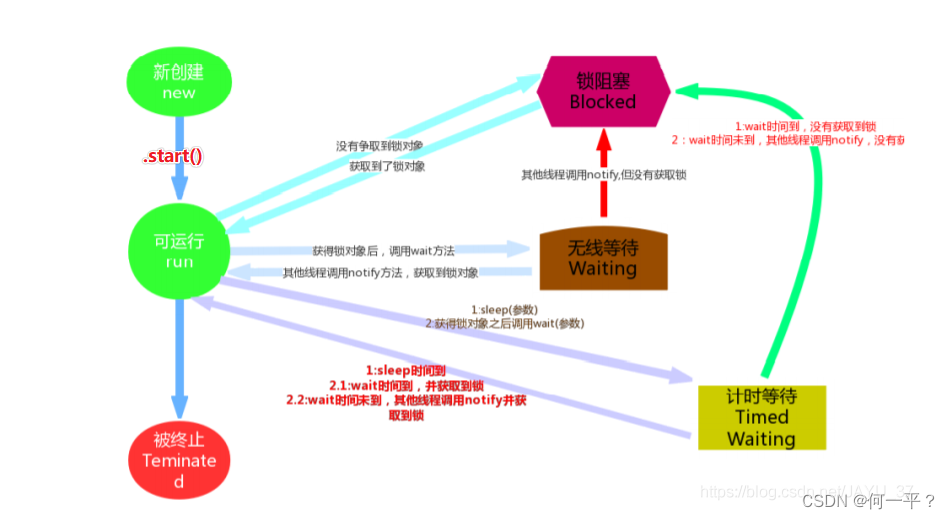
7种状态,创建、就绪、运行,阻塞、计时等待、无限等待、终止
- 创建:也叫初始态,刚被new出来
- 就绪:调用了start方法,等待cpu调度
- 运行:执行线程体
- 阻塞:wait等待的时间到了,或者其他线程调用了notify方法,但当前线程并没有获取到锁对象,就会进入阻塞,只要一获取到锁,就会进入就绪状态
- 计时等待:调用sleep或是wait方法,指定等多长时间或睡多久后,线程进入计时等待状态,睡眠时间到或等待的时间到,或调用了notify方法,进入就绪状态,还有一种是,即使时间到了,或者是调用了notify,但没有获取到锁,此时会进入阻塞状态
- 无限等待:调用了wait方法,无限等待,释放了锁
- 终止:死亡状态,正常执行完线程体或是,线程中出现异常,不可捕获导致终止
- sleep和wait方法的区别?
- 所属的类不同,sleep是thread的静态方法,wait是object的方法
- sleep不会释放锁,wait会
- wait主要用于线程间的通信,和notify和notifyAll搭配使用,sleep只是暂停执行
- wait和sleep都可以实现计时等待,但是,wait时间到了之后,需要重新获取锁,没有获取到则进入阻塞,但是sleep会立马进入就绪状态,不需要重新获取锁,若cpu不空闲,则进入阻塞
- 什么是可重入锁?
可重入性:一个线程持有锁时,当其他线程尝试获取该锁时,会被阻塞;而当前线程,尝试获取自己持有的锁时,如果可以成功,则说明,锁是可重入的,否则不是。
可重入锁,也叫递归锁,允许同一个线程在已经持有锁的情况下再次获取同一个锁,而不会被阻塞。
可重入锁,可以防止,同一线程,多次获取锁,而导致死锁的发生
- 有哪些实现了可重入锁?
synchronized 实现可重入性
- synchronized 经过编译后,会在同步代码块前后形成两个字节码指令monitorenter和monitorexit。针对每个锁,维护一个计数器,初始值为0,标识任意线程,都可以获取锁,并执行对应逻辑,在获取锁时,会执行monitorenter指令,如果没有线程获取到锁,讲计数器加一,执行monitorexit,计数器减一,直到,计数器为0,锁被释放,其他线程才能获取锁
ReentrantLock实现可重入性- ReentrantLock,通过使用Sync内部类来管理锁,Sync又有两个实现类fairSync(公平锁)和NonFairSync(非公平锁),所以真正的获取锁,是由两个实现类控制的,ReentrantLock继承自AQS,AQS内部维护了一个计数器,来计算重入次数,避免频繁持有锁
- 当一个线程在尝试获取锁时,先判断state是否为0,若为0,标识没有线程占用,则可获取
若不为0,则判断当前持有锁的线程是不是自己,若是,则将计数器加一,标识重入,代码实现如下:
protected final boolean tryAcquire(int var1) {
Thread var2 = Thread.currentThread();
int var3 = this.getState();
if (var3 == 0) {
if (!this.hasQueuedPredecessors() && this.compareAndSetState(0, var1)) {
this.setExclusiveOwnerThread(var2);
return true;
}
//判断是否是当前线程
} else if (var2 == this.getExclusiveOwnerThread()) {
int var4 = var3 + var1;
if (var4 < 0) {
throw new Error("Maximum lock count exceeded");
}
this.setState(var4);
return true;
}
return false;
}
}
- 公平锁和非公平锁的区别
公平锁:指多个线程,按照申请的顺序,依次获取锁,线程直接进入队列中等待,按照队列的先进先出原则,最先进入队列的最先获取锁
非公平锁:多个线程加锁时,直接尝试获取锁,能抢到则直接占有锁,否则进入等待队列
公平锁和非公平锁的两点区别:
- 非公平锁,在调用lock获取锁时,会直接调用AQS进行一次抢锁,如果恰巧此时没有占用,则直接获取锁,而公平锁是,直接进入tryAcquire方法,尝试获取锁
- 非公平锁,在第一次没有抢占成功时,和公平锁一样都会进入,tryAcquire方法,尝试获取锁,非公平锁是,尝试获取锁时,如果发现state此时为0,则会再次调用AQS抢锁,而公平锁,是先判断,阻塞队列中是否有线程处于等待,有则不去抢锁
非公平锁效率较高,但非公平锁让获取锁的时间变得更加不确定,可能会导致在阻塞队列中的线程长期处于饥饿状态。
- 创建线程的方法
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口(结合FutureTask使用)
- Executors线程池创建
- 死锁
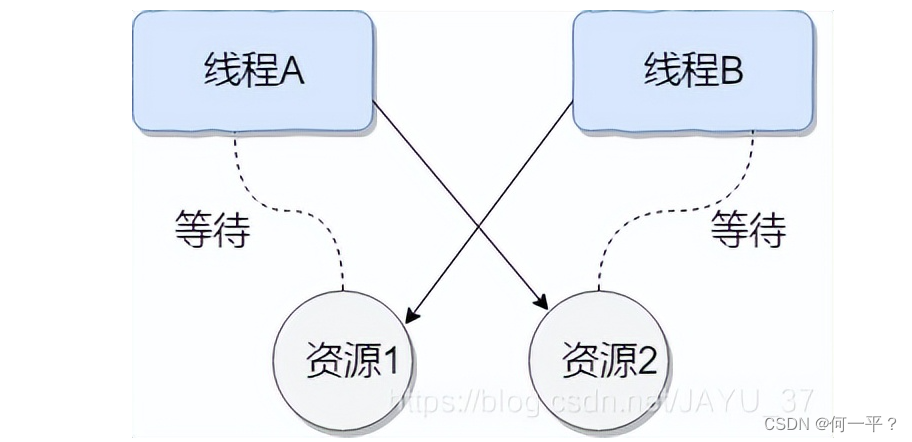
- 什么是死锁?
死锁是两个或两个以上线程,由于竞争资源或是彼此通信,所造成的一种阻塞现象,若无外力作用,都将无法推进,此时系统处于死锁
如图:资源1和资源2都只能被一个线程占有,此时线程A拥有资源2,线程B拥有资源2,线程A只有获得资源1后,才能执行完成,线程B只有拥有资源2之后才能执行完成,此时,两个线程相互等待
- 形成死锁的四个必要条件
- 互斥条件:线程对所分配的资源具有排他性,即一个资源只能被一个线程占用
- 请求与保持条件:因请求被占有的资源而发生阻塞时,对已获取的资源不释放
- 不可剥夺条件:对已获取的资源,在未使用完之前,不能被其他线程所占用
- 循环等待条件:发生死锁时,所等待的线程必定是一个环路,死循环造成永久阻塞
- 如何避免死锁?(破坏四个必要条件之一即可)
- 破坏互斥条件:多个线程共享资源,一般不可行
- 破坏请求和保持条件:一次申请所有资源
- 破坏不可剥夺条件:占有部分资源的线程尝试申请其他资源时,如果申请不到,就释放已占有的资源
- 破环循环等待:按序申请资源
- 线程池
- 什么是线程池?
是将多个线程预先存储在一个“池子”(工作线程)里面,当有任务出现时,可以避免重新创建和销毁线程所带来的性能开销,只需要从池子里面,取出相应线程执行,完成对应任务即可。- 线程池一般的四个组成部分
- 线程管理器:用于创建、销毁线程池,添加新的任务
- 工作线程:线程池中的线程,可循环执行任务,没有任务时,处于等待状态
- 任务队列:用于存放没有处理的任务,一种缓存机制
- 任务接口:每个任务必须实现的接口,供工作线程,任务调度的执行,主要规定了任务的开始、结束工作,以及任务状态
- 创建线程池的方法?
- Executors.newFixedThreadPool():创建固定大小的线程池,可以控制并发的线程数,超出的线程会在队列中等待
- Executors.newCachedThreadPool:创建一个可缓存的线程池,若线程数,超出,当前当前所需处理的任务,缓存一段时间后进行回收,若线程数不够,则创建新的
- Executors.newSingleThreadExecutor:创建一个单个线程数的线程池,它可以保证先进先出的执行顺序
- Executors.newScheduledThreadPool:创建一个可以执行延迟队列的线程池
- Executors.newSingleThreadScheduledExecutor:创建一个单线程可以执行延迟任务的线程池
- Executors.newWorkStealingPool:创建一个抢占式执行的线程池,任务的执行顺序不确定**(1.8添加)**
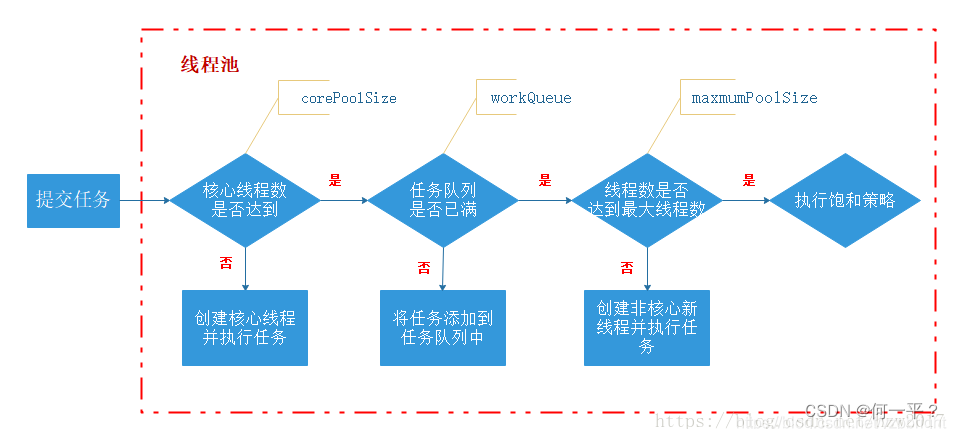
- ThreadPoolExecutor: 最原始的创建线程池的方式,有7个参数

- 创建线程池的7个参数:
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数,当阻塞队列满之后,所允许创建的最大线程数
- keepAliveTime:最大线程数可以存活的时间,当线程中没有任务执行时,最大线程允许存活的时间,最终只保留核心线程数量的线程
- unit:和参数3一起使用,最大线程数所允许存活时间的单位(天、时、分、秒、毫秒、微秒、纳秒)
- workQueue:阻塞队列,用于存储线程池中用于等待执行的任务
- threadFactory:线程工厂,主要用来创建线程
- handler:拒绝策略,线程池拒绝执行任务时,所进行的操作
- 线程池的拒绝策略
AbortPolicy:拒绝并抛出异常。
CallerRunsPolicy:使用当前调用的线程来执行此任务。
DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。
iscardPolicy:忽略并抛弃当前任务。
默认使用AbortPolicy
- 线程池执行流程:
- 线程池中的核心线程是如何被回收的?
核心线程的回收,是由allowCoreThreadTimeOut参数控制的,默认为false,若开启,则此时线程池中的线程不管是否是核心线程,只要超过keepAliaveTime,都会被回收
注意:这样会违背线程池减少线程创建开销的目的,所以默认false
- 线程调度算法和策略?
- 读写锁
- AQS
- ThreadLocal
- 锁消除和锁粗化
- 什么是自旋?

















 1794
1794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











