 数据库缓存与缓冲区管理解析
数据库缓存与缓冲区管理解析








 本文围绕数据库管理系统中的缓存和缓冲区管理展开。介绍了缓存是将数据存于内存以快速访问,缓冲区管理涉及缓存大小、替换策略等。阐述了缓存可提高系统响应速度,缓冲区管理能提升内存利用率和数据访问性能,还给出Python实现缓冲区管理器的示例。
本文围绕数据库管理系统中的缓存和缓冲区管理展开。介绍了缓存是将数据存于内存以快速访问,缓冲区管理涉及缓存大小、替换策略等。阐述了缓存可提高系统响应速度,缓冲区管理能提升内存利用率和数据访问性能,还给出Python实现缓冲区管理器的示例。
1. 缓存和缓冲区管理
缓存和缓冲区管理是数据库管理系统中的重要概念,用于提高数据库的性能和响应速度。缓存是指将数据存储在内存中,以便快速访问和检索,而不必每次都从磁盘中读取数据。缓冲区管理则是指数据库管理系统如何有效地管理缓存,包括缓存的大小、替换策略以及数据的读取和写入等操作。
2. 缓存的作用
数据库中的数据通常存储在磁盘上,而磁盘的读取速度相对较慢。为了提高数据库的性能,可以将热门数据或频繁访问的数据存储在内存中,形成一个缓存。当应用程序需要访问数据时,首先会在缓存中查找,如果找到了就直接返回,避免了频繁的磁盘访问,从而提高了系统的响应速度。
3. 缓冲区管理的重要性
缓冲区管理是数据库管理系统中的一个关键组成部分,它决定了数据库系统对缓存的使用效率。合理的缓冲区管理可以使得数据库系统更好地利用内存资源,提高数据的访问速度和性能。缓冲区管理包括以下几个方面:
3.1 缓冲区大小的确定
缓冲区大小的确定是一个重要的决策,它直接影响到数据库系统的性能。如果缓冲区过小,无法容纳足够多的数据,则会导致频繁的磁盘访问,降低系统的性能;如果缓冲区过大,会浪费内存资源。确定缓冲区大小的方法有很多种,可以通过性能测试和调优来确定一个合适的值。
3.2 缓冲区的替换策略
当缓冲区已满时,需要替换其中的数据。常见的替换策略有最近最少使用(LRU)、最少使用(LFU)和随机替换等。LRU策略是指替换最近最久未使用的数据,LFU策略是指替换使用频率最低的数据,随机替换策略是指随机选择一个数据进行替换。不同的替换策略适用于不同的场景,可以根据实际情况选择合适的策略。
3.3 数据的读取和写入
缓冲区管理还包括数据的读取和写入操作。当应用程序需要读取数据时,首先会在缓冲区中查找,如果找到了就直接返回;如果没有找到,则需要从磁盘中读取数据,并将其放入缓冲区。当应用程序需要写入数据时,首先会将数据写入缓冲区,然后由数据库管理系统决定何时将数据写入磁盘。
4. 缓冲区管理的实现
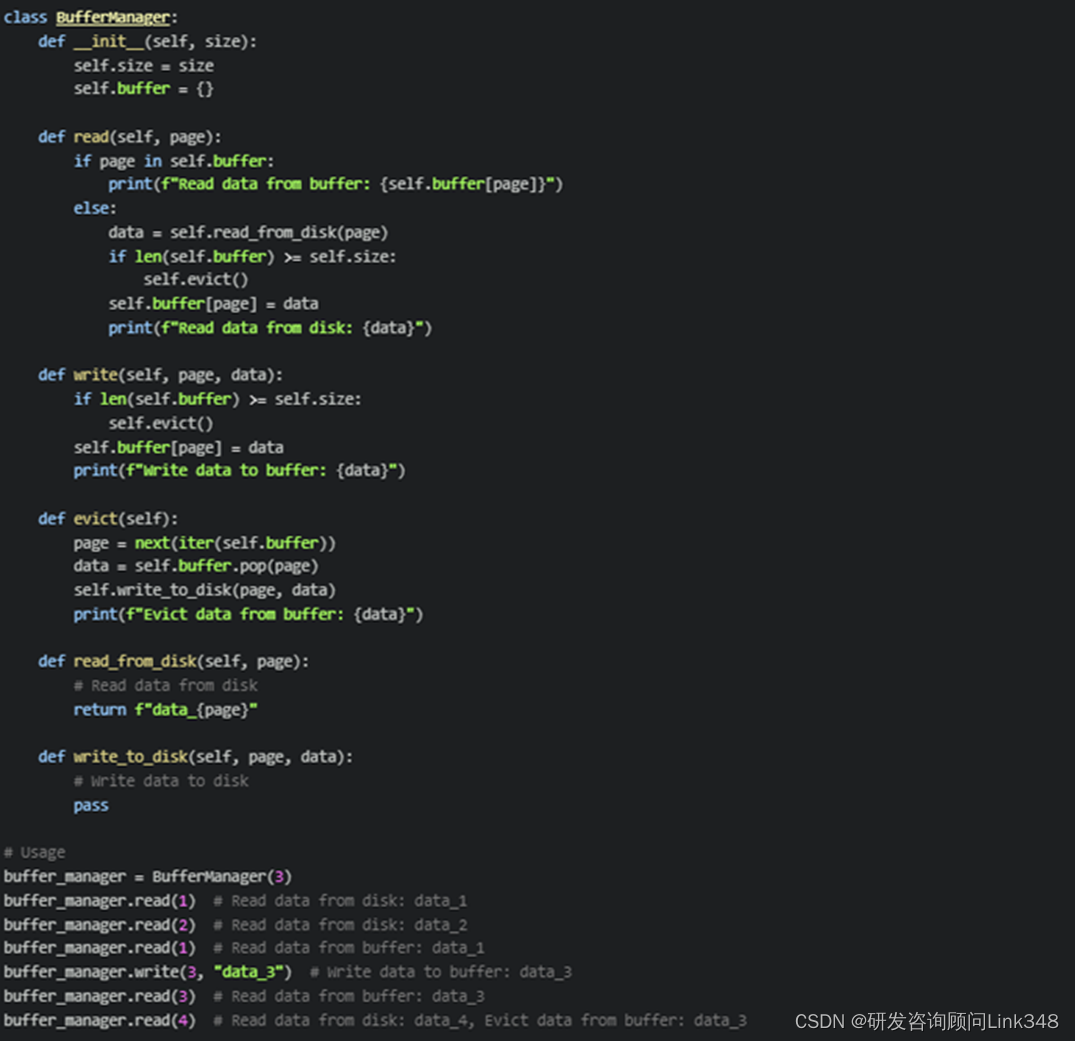
在实际的数据库管理系统中,缓冲区管理是由数据库管理系统自动完成的。下面是一个简单的示例,演示了如何使用Python实现一个简单的缓冲区管理器:
|
class BufferManager: def __init__(self, size): self.size = size self.buffer = {}
def read(self, page): if page in self.buffer: print(f"Read data from buffer: {self.buffer[page]}") else: data = self.read_from_disk(page) if len(self.buffer) >= self.size: self.evict() self.buffer[page] = data print(f"Read data from disk: {data}")
def write(self, page, data): if len(self.buffer) >= self.size: self.evict() self.buffer[page] = data print(f"Write data to buffer: {data}")
def evict(self): page = next(iter(self.buffer)) data = self.buffer.pop(page) self.write_to_disk(page, data) print(f"Evict data from buffer: {data}")
def read_from_disk(self, page): # Read data from disk return f"data_{page}"
def write_to_disk(self, page, data): # Write data to disk pass # Usage buffer_manager = BufferManager(3) buffer_manager.read(1) # Read data from disk: data_1 buffer_manager.read(2) # Read data from disk: data_2 buffer_manager.read(1) # Read data from buffer: data_1 buffer_manager.write(3, "data_3") # Write data to buffer: data_3 buffer_manager.read(3) # Read data from buffer: data_3 buffer_manager.read(4) # Read data from disk: data_4, Evict data from buffer: data_3 |
上述代码实现了一个简单的缓冲区管理器,其中BufferManager类包括了读取数据、写入数据和替换数据的功能。缓冲区的大小通过构造函数的参数进行设置。在读取数据时,首先会在缓冲区中查找,如果找到了就直接返回;如果没有找到,则从磁盘中读取数据,并将其放入缓冲区。在写入数据时,首先会将数据写入缓冲区,如果缓冲区已满,则需要进行替换操作。替换操作使用的是最简单的随机替换策略,即随机选择一个数据进行替换。



















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











