







基于空间填充曲线的图像恶意软件分类混合框架
目录
4.2 虚拟机自检Virtual Machine Introspection
摘要
在本文中,我们提出了一种混合的恶意软件分类框架,旨在克服恶意软件开发人员使用反分析混淆技术(如打包和加密)来逃避检测并阻止分析过程带来的挑战。该框架结合了新的静态和动态恶意软件分析方法,其中静态恶意软件可执行性和动态进程内存转储被转换为通过空间填充曲线映射的图像,从中提取视觉特征进行分类。在来自23个家族的13599个混淆和非混淆恶意软件样本数据集上,该框架优于静态和动态独立方法,精确度、召回率和准确性得分均为97.6%, 97. 6%和97.6%(使用KNN-HOG-Z-order方法)。
关键词:恶意软件分类,空间填充曲线,图像处理,计算机视觉
一、引言
由于这些混淆方法导致恶意软件程序二进制结构的剧变,静态分析在很大程度上无法抵抗混淆。动态方法克服了静态分析的混淆限制,因为程序必须在执行之前去混淆并写入主存。然而,由于与良性程序或其他恶意软件家族的行为相似,动态分析可能会产生大量误报。混合方法将静态和动态方法的要素结合在一起,以克服这些限制。
在这篇文章中,我们提出了一种新的基于计算机视觉技术的恶意软件分类混合框架。我们的框架结合了从转化为二维图像的恶意软件样本中收集的静态和动态特征,通过空间填充曲线(SFC)遍历进行映射。我们的混合方法静态处理未混淆样本,动态处理混淆样本。采用这种混合方法使我们能够优化分析过程。本研究的主要贡献是:
- 新颖的基于图像的恶意软件分类框架,结合静态和动态分析的优势,以克服混淆程序的挑战;
- 从映射到SFC图像格式的进程内存转储中获取恶意软件行为数据的新表示;
- 研究了基于图像的恶意软件分类的几种特征描述符号和分类方法;
- 三个SFC格式的开源恶意软件图像数据集,可供进一步研究使用。
二、相关工作
2.1 二进制文件可视化
Conti 等人的工作中引入了第一项将二进制文件可视化为图像的研究,该研究提出了一种将二进制文件逆向工程为可视图像的方法,称为byteplots,以增强基于文本的十六进制编辑器的能力。
2.2 byteplot恶意软件可视化
Nataraj等人首先应用byteplot来表示恶意软件二进制文件以进行分类。他们的方法将静态恶意软件样本可视化为灰度图像,并观察到对于许多恶意软件家族,属于同一家族的图像在布局和纹理上非常相似。恶意软件特征向量是使用GIST推导出来的。
2.3 空间填充曲线恶意软件可视化
Baptista提出了一种利用Hilbert曲线和自组织增量神经网络按类型分类恶意软件的方法。实验在180个样本上进行,其中78个是良性的。该恶意软件分为四类:特洛伊木马、勒索软件、其他和未知。尽管作者报告的分类准确率为89%,但180个样本的小样本集不足以清楚表明将希尔伯特曲线应用于恶意软件分类的优点。较小的数据集往往会产生过度拟合,这意味着该模型无法很好地推广到看不见的样本。
2.4 总结
本节讨论的相关研究回顾指出了一些局限性。
- 首先,之前的工作主要集中在byteplot图像格式上,以表示恶意软件数据。这种格式本质上是恶意软件二进制的静态视图,对加密或打包等混淆技术不具有鲁棒性。
- 其次,Nataraj 等人收集的Malimg数据集是大多数研究人员选择的以图像格式表示恶意软件的测试数据集。此数据集是在2011年编译的,因此不能被视为当前恶意软件威胁状况的代表。
其他研究工作利用了Microsoft Challenge数据集。出于无菌考虑,已从此数据集中的恶意软件示例中删除文件头。此数据集中恶意软件样本的不完整性意味着无法提取完整的特征集进行分类。
本文提出的框架在以下方面克服了之前讨论的研究的局限性:
- 代表当前恶意软件变体的恶意软件数据集。
- 一种混合的特征选择和提取方法,结合静态和动态分析的优点,与之前讨论的方法相比,开销和限制更少。
- 空间填充曲线用于表示恶意软件分类。与主要的byteplot方法相比,SFC之前已经证明了更好的分类性能。
三、空间填充曲线
空间填充曲线是数学构造,也称为连续分形曲线,其极限包含整个二维单位平方。本文考虑了Hilbert, Z-order 和 Gray-code曲线。这些曲线的基本遍历路径如图1所示。

3.1 二进制数据表示中空间填充曲线的适用性
SFC的局部保持特性意味着它们可以用于许多计算领域。在本研究的背景下,目的是以图像格式捕获恶意软件二进制文件的所有相关特征,以便提取鉴别特征用于分类。这些技术的核心是一个布局函数,该函数输入一组值,并在生成的映射图像上输出空间分区,以便区域表示不相交的不相交数据。Wattenberg定义了“完美”布局功能的概念,即空间填充可视化的布局方法,符合以下四个理想标准:
- 稳定性:输入的微小变化应产生随后的输出的微小变化;
- 分割中性:任何结构变化都不会影响图像地图上其他区域的结构;
- 顺序邻接:每个相似的项目应位于彼此相邻的位置;
- 位置:布局区域应相对紧凑。如果布局区域表示松散,例如长和窄,那么区域的可视化将不那么清晰。
Wattenberg证明SFC具有这四个基本特性,因此是以二维格式表示数据的实用解决方案。
3.2 使用空间填充曲线映射二进制文件
SFC通过图像中的每个单位正方形(即像素)跟踪一条连续曲线。为了实现文件映射,可以将恶意软件文件的二进制代码视为一条平坦的一维线,因为代码是按顺序逐字节解析的。SFC将每个点(字节)从一维空间映射到二维空间(SFC图像映射),这样,二进制文件空间中的紧密定位点在映射到SFC时也将趋向于紧密定位。
图2描绘了在一阶和二阶迭代中,一维点集到二维曲线表示(在这种情况下为Hilbert希尔伯特曲线)的映射。它显示了紧密定位的数据点(示例中的a和b)映射到SFC映射图上的类似位置。为了进行这项研究,我们使用了用Python编写的库scurve,将恶意软件二进制文件转换为SFC图像格式。

scurve库使用基于数据类型的颜色编码方案,将恶意软件二进制数据映射到生成的SFC图像。颜色方案将字节(0–255范围)分为以下类别:黑色表示0×00(0),蓝色表示ASCII文本(1–126),红色表示高值字节(127–254),白色表示0×ff(255)。
图3示出了从Chir家族生成的Z-order的SFC图像的示例。图3(d)显示了一个大的黑色区域,表示文件的大部分包含零或空填充,这有时被恶意软件开发人员用作一种简单的混淆方法。还有一个大的可打印字符区域,如图3(c)中的蓝色所示,还有一些小的高值字节部分,如图3(b)中的红色区域所示。文件的其余部分包括多种数据类型的混合,这些数据类型为结果图像提供了图3(a)所示的不同纹理区域。可以从SFC图像中生成的纹理中提取相关恶意软件常见的不同特征进行分类。

四、混合框架
本文介绍了一种新的框架,用于通过计算机视觉和机器学习将恶意软件变体分类到各自的家族类别中。该框架包括静态和动态分析组件,该框架的过程工作流如图4所示。该框架包括三个主要阶段:恶意软件转换、特征提取和分类。

4.1 数据采集和预处理
从VirusTotal学术共享存储库中编译了一个数据集,其中包含来自23个不同恶意软件家族的13599个32位可执行可移植可执行文件(PE)样本。使用scurve库,通过Hilbert, Gray-code 和 Z-order曲线遍历从样本中获得三个图像数据集。表1显示了数据集的结构,包括家族和每个类别的数量。在23个家庭类别中,有5个被认为是模糊的。

为了测试分类模型对看不见的恶意软件的预测能力,从原始数据集中拿出了1350个样本或大约10%的数据作为评估集。样本是使用分层随机抽样选择的,分层随机抽样给出了代表整个数据集的子集结构。删除评估集的数据后,训练数据集由12249个样本组成。
在将恶意软件二进制文件转换为SFC图像格式之前,首先计算每个样本的香农熵,以确定混淆程度(如果有)。香农熵(Shannon,1948)衡量给定数据集的随机程度,从有序或非随机数据的0到非常随机的数据的8。对于二进制文件,香农熵可以用作恶意软件混淆的指标,因为加密或打包等技术会扭曲二进制数据,因此会产生高熵分数。Lyda和Hamrock之前的工作发现压缩恶意软件二进制文件的平均熵为6.8,而加密二进制文件的平均熵为7.1,发现本机可执行文件的平均熵为5.1。在本研究中,我们将μ值作为香农熵阈值6.8,以确定样本是否混淆。
4.2 虚拟机自检Virtual Machine Introspection
如前所述,我们优化了框架,仅从被认为是混淆的样本(高于阈值μ)中提取动态或行为数据。动态分析比静态方法更具侵入性,因为样本必须在受控环境中执行,以获取其行为数据,然后将其写入物理主机。因此,以这种方式执行每个样本的时间复杂性将使其不适用于大型数据集。对于动态分析,我们实现了虚拟机自检(VMI),这是Garfinkel和Rosen-blum(2003)引入的一个过程,指的是从虚拟机监控程序级别检查或监控驻留在虚拟机内的操作系统。在这种情况下,将恶意软件传递到虚拟机,并使用Microsoft实用程序Procdump执行和提取进程内存转储。然后将转储文件写回主机上的磁盘。为了优化分析过程,从执行中的每个恶意软件中提取包含进程线程和句柄信息的小型进程转储。
4.2.1 进程转储文件分析
如前所述,我们使用小型或小型转储格式来提高处理效率。小型转储包含以下数据:
- 停止消息及其参数和其他数据
- 加载的驱动程序列表
- 已停止的处理器的处理器上下文 (PRCB)
- 已停止进程的进程信息和内核上下文(EPROCESS)
- 已停止的线程的进程信息和内核上下文(ETHREAD)
- 已停止的线程的内核模式调用堆栈
为了说明进程转储对于表示恶意软件行为特征的适用性,我们在这里重点检查从Chir家族的两个变体中提取的调用堆栈跟踪。调用堆栈由指向程序计数器当前位置的函数调用链组成,其中进程已被Procdump工具终止。直观地说,共享类似源代码的恶意软件二进制文件在目标计算机上执行时的行为相同,这会导致在相同序列中出现类似的执行跟踪。这些相似性可用作将恶意软件变体分组到其各自的家族类的特征码。显示每个程序的完整堆栈跟踪是不可行的,因此我们将比较局限于Chir样本的进程注入程序,如图5所示。

Chir恶意软件实施进程注入程序,以混淆其在操作系统上的存在。从图5可以看出,函数调用和调用序列是相同的,这表明这两个示例对于这个代码注入例程具有相同的行为特征。从正在运行的进程转储中捕获的行为数据允许我们克服混淆限制,并改善静态独立方法的分类性能。
4.3 恶意软件转换
一旦恶意软件样本得到处理,框架中的下一个阶段就是通过scurve库将未混淆的恶意软件可执行样本和混淆的样本进程转储转换为SFC格式。
图6(a−c) 说明了从Allaple恶意软件家族中提取的单个样本,通过Hilbert、gray-code和Z-order遍历将其转换为SFC图像。三幅SFC图像中的蓝色区域(ASCII可打印字符)和较小的红色区域(高值不可打印字节)明显相似。然而,由于空间填充曲线的遍历模式不同,纹理模式的位置也不同。
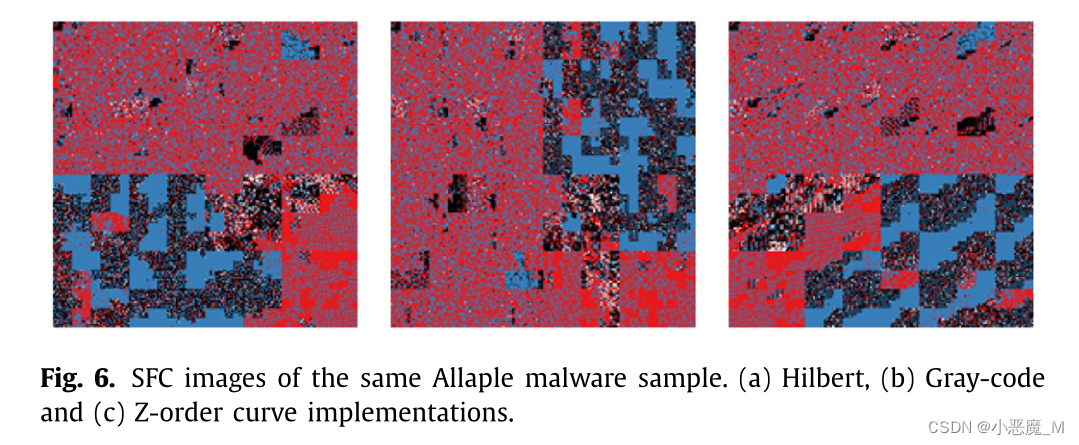
图7中示出了从处理转储文件转换的SFC图像的示例。每个图像代表Cryp-towall勒索软件家族的一个变体。从图像中可以看出,数据纹理区域非常稀疏,黑色区域很大,相当于二进制零。对内存转储的检查证实,大多数文件都由二进制零组成。

4.4 特征提取
评估了三种特征描述符算法,即局部二进制模式LBP、Gabor Filters和方向梯度直方图HOG。对于每个描述符,将为每个图像生成一个特征向量数据集,以及一个对应家族类标签的数据集。
4.4.1 LBP局部二进制模式
LBP通过将每个像素与其周围的像素邻域进行比较和阈值化,计算纹理的局部表示。我们对Ojala等人提出的原始LBP算子使用了圆形像素邻域扩展。LBP描述符中要考虑的主要参数是圆邻域的半径和圆周长上的数据点的数量。

图8(a−d) 显示了本研究中使用的LBP特征提取过程的示意图。首先将图8(a)中的SFC图像转换为图8(b)中的灰度。接下来,在图8(c)中应用LBP操作符,其返回由图8(d)中的LBP数值构造的特征的直方图。接下来,将每个直方图添加到一个数组中。在计算每个直方图时,它将连接到数组。结果是一组特征直方图,表示图像的特征向量。
4.4.2 Gabor 滤波器
Gabor滤波器是给定频率和方向的正弦信号。由于单个滤波器在空间上是局部化的,因此将具有不同方向和频率的Gabor滤波器组应用于图像,因为滤波器必须沿与目标纹理相同的方向通过才能返回准确的特征。在我们的描述符中,我们以45为间隔使用了0–180的Gabor库,以确保从不同方向捕获足够的纹理特征。本工作中考虑的主要Gabor滤波器参数为:
- k:是Gabor核的大小(以像素为单位)。为了统一起见,k的值最好是奇数,核是正方形。
- σ:是Gabor滤波器中使用的高斯函数的标准偏差。
- θ:Gabor函数平行条纹的法线方向。
- γ: 表示空间纵横比。

图9(a-c)描述了本研究中使用的Gabor滤波器过程。示例图像以Hilbert格式取自Emotet banker特洛伊木马家族。输入9(a)中的SFC图像,并在不同方向和频率9(b)中应用一系列滤波器。然后对得到的滤波器进行卷积,以生成图像9(c)的最终特征向量,该特征向量被附加到特征数组中。
4.4.3 HOG方向梯度直方图
方向梯度直方图(HOG)特征描述符统计图像局部区域中梯度方向的出现情况。图10显示了在我们的框架中使用的HOG特征提取过程。将源SFC图像划分为块,并将每个块细分为单元。计算单元中每个像素的垂直和水平梯度。然后为每个单元创建方向直方图。箱子代表不同的方向角。最终特征描述符由每个块的单元直方图串联而成,然后将其展平为特征向量。

4.5 SFC混合特征的分类
该框架的下一个阶段是分类阶段。在这种情况下,分类的目的是根据LBP、Gabor和HOG描述符从SFC图像中提取的纹理相似性,将恶意软件样本排序为其分类组或家族类别。然后,在第4.1节前面描述的10%验证集上测试经过训练的分类模型,以衡量它们对以前未看到的数据的泛化程度。评估了以下分类算法:随机森林(RF)、支持向量机(SVM)和K近邻(KNN)。分层k折交叉验证用于最小化过度拟合。通过实验,确定了k的最佳值为5。
4.6 参数调优
为了产生最佳的分类性能,需要一个复杂的参数调整过程,包括使用分类器对特征提取算法进行集中调整。因此,确定一组最佳参数并不是一项简单的任务;没有“通用的”的默认参数集可以优化特征描述符和分类器组合的性能。实现了一种搜索方法来确定超参数的最佳组合,即GridSearchCV,它是Python Sci-kit 学习库的一部分。使用GridSearchCV,将评估所有可能的参数值组合,并保留最佳组合。
4.7 性能指标
为了衡量框架分类模型的鲁棒性,我们使用精确度(precision)、召回率(recall)和准确性(accurancy)测试了它们的性能。
- 精确度是正确预测的正观测值与总预测正观测值的比率。在这种情况下,一个家族的正确预测样本与该家族预测总数的比率,即“对于标记为特定家族的所有恶意软件,有多少是正确的?”。
- 召回率是正确预测的积极观察结果与实际类别上所有观察结果的比率。在这种情况下,它是正确预测的恶意软件与该家族总数的比率,即“对于每个恶意软件家族,有多少应该被标记为该家族的恶意软件被正确标记?”。
- 准确度是模型正确预测的正确预测的分数。
五、实验分析与结果
本节介绍旨在调查混合框架对恶意软件分类的有效性的实验。首先提出了图像大小对分类的影响,以生成最佳数据集供进一步分析。接下来将讨论混合框架的测试,然后使用静态和动态独立方法进行对比分析。
- 在独立静态分析的情况下,所有样本在特征提取阶段之前直接转换为SFC图像格式。
- 在独立动态分析中,所有样本均通过VMI执行,其进程转储在特征提取之前转换为SFC图像格式。
5.1 图像维数在分类中的评估
本次评估的目的是研究不同大小的SFC图像对分类性能和时间复杂度的影响。表2显示了不同图像维数对分类性能的影响。从结果来看,很明显,随着图像尺寸的增大,性能会提高,但代价是处理时间变慢。

为了进一步分析,我们选择了256×256数据集。
5.2 动态运行时间对分类性能的影响
通过VMI提取的进程转储文件表示恶意软件在执行过程中的行为,即其与操作系统的交互。因此,在触发转储之前允许执行样本的时间间隔可以极大地影响返回的行为特征的数量,从而影响总体分类性能。为此,我们通过在虚拟机中以15秒到60秒的间隔执行混淆样本,确定了每个家族的最佳运行时间。
表3显示了不同转储间隔下每个系列的样本量。例如,Scar变体的原始数据集包含304个样本,在60秒的时间间隔内减少到83个。

表4显示了每个测试家庭的分类结果。为了便于比较,还显示了静态方法的结果。从表4可以明显看出,随着样本量的减少,分类性能也会下降。Chir、Cryptowall、Emotet和Scar的最佳时间间隔为15秒,而Agen在30秒的时间间隔表现最好,以粗体显示。较短的处理间隔意味着我们的方法可以很好地扩展到更大的数据集。总的来说,结果表明,与独立静态方法相比,动态方法在分类性能上有了改进。

为了进行本节中的进一步分析,Chir、Cryptowall、Emotet和Scar选择了15秒的间隔转储,Agen选择了30秒的间隔转储。
5.3 框架分类训练
使用Hilbert、gray-code和Z-order图像数据集进行了实验分析。每个分类模型都按照相同的程序进行训练:
- 计算每个可执行文件的香农熵:如果μ≥6.8、使用VMI提取过程转储
- 将每个样本/过程转储转换为SFC图像格式。
- 计算每个图像样本的特征向量和标签在特征集上训练分类器(执行k-fold交叉验证)。
- 计算平均精度、召回率和准确率。
对于Hilbert、Graycode和Z-order SFC图像数据集,使用LBP、Gabor和HOG特征描述符提取特征,然后将每个特征集传递给SVM、RF和KNN分类器。总共产生了27个分类模型,每个SFC数据集9个。
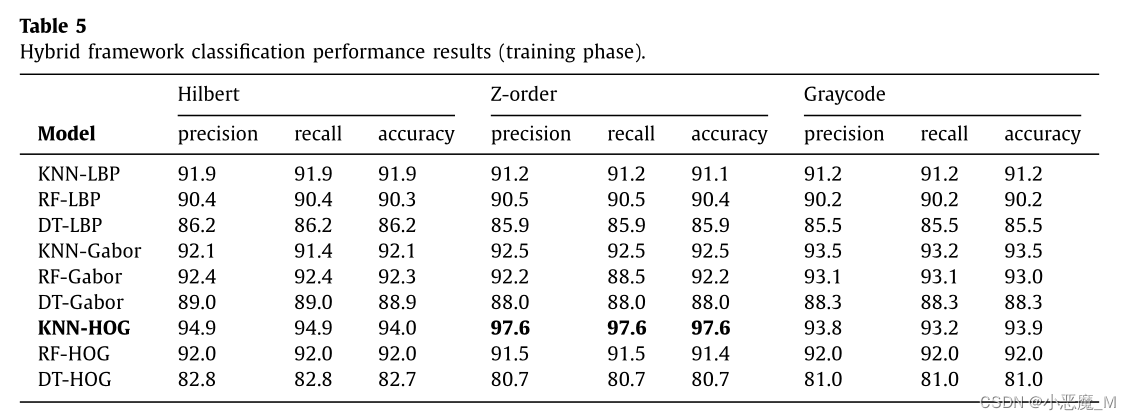
表5显示了每个模型的训练分类性能结果。KNN-HOG模型对所有三个SFC数据集都产生了最佳的训练结果,每个指标的精确度、召回率和精确度均为97.6%。KNN-HOG Z-order模型的混淆矩阵如图11所示。从混淆矩阵中可以明显看出,该模型在训练数据方面总体上取得了良好的结果,23个类中有22个类的真阳性率达到90%或以上,其中9个类的真阳性率为100%。Locky的最低真阳性率为89%。

5.4 混合分类模型评估
为了建立稳健的分类模型,评估它们对新数据的泛化程度至关重要。如前所述,原始数据的10%用于评估目的。与训练阶段一样,KNN-HOG Z-order模型在看不见的数据上表现最好,精度、召回率和准确性得分分别为97.1%、96.6%和97.0%。
5.5 与静态和动态独立方法的比较
我们对该框架与静态和动态独立方法进行了比较分析,以证明采用混合方法的性能优势。
- 在静态方法中,所有样本都从未运行的可执行二进制文件映射到SFC图像格式。
- 对于动态方法,所有样本都在虚拟机中执行,并收集进程转储,然后将其转换为SFC格式。
在混合框架的情况下,分类模型像以前一样进行了训练。表6显示了每种方法的结果。为简洁起见,我们只展示了静态、动态和混合方法中性能最好的模型。尽管使用交叉验证的每个模型在训练阶段都表现良好,但混合模型优于静态和动态模型,在每种情况下,精确度、召回率和准确性得分均为95.1%。
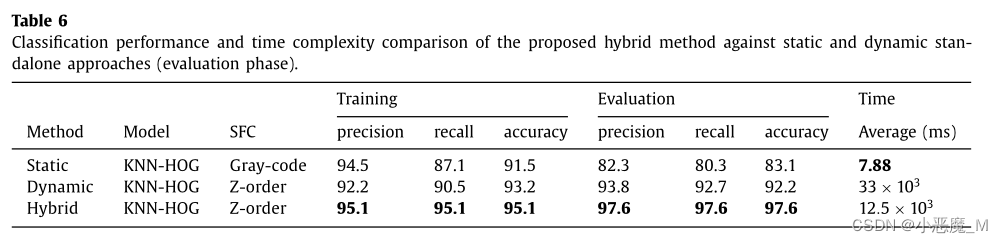
这三个模型在10%评估数据集上进行了测试。KNN-HOG模型在所有分析方法中表现最好。混合模型再次优于静态模型和动态模型,精度、召回率和准确性得分分别为97.1%、96.6%和97.0%。就时间复杂度而言,静态方法提供了最快的处理时间,平均每个样本7.88ms。静态方法的处理开销很低,因为不需要在虚拟机中执行恶意软件。正如预期的那样,动态独立方法速度最慢,每个样本平均33秒,因为每个恶意软件样本在虚拟机中执行30秒,以便在进程转储中捕获足够的行为数据。混合模型平均每个样本12.5秒。混合模型的时间复杂度受数据集中遇到的混淆或高熵样本数的影响。
5.5.1 抗混淆能力
在本节中,我们将重点介绍在评估集中对混淆家族进行静态、动态和混合分析的性能,从而证明混合方法在抗混淆方面的优越性。混淆集包括来自Agen(68)、Emotet(49)、Cryptowall(28)、Scar(30)和Chir(30)家族的205个样本。表7显示了针对混淆数据的三种方法的结果。应该指出的是,这些结果是基于整个评估集的绩效得出的。很明显,混合模型对混淆样本的恢复能力最好,在所有族中都优于静态和动态方法。

5.6 与基准法的比较分析
测试我们的方法对以前基于图像的恶意软件分类方法的有效性非常重要。选择用于比较分析的方法是Nataraj 等人提出的KNN-GIST方法,如前所述2.2。该方法可以被视为一个基准,因为它是第一个将byteplot表示应用于恶意软件分类的方法。
byteplot和SFC转换过程在二进制文件的表示形式上有很大不同。
- byteplot使用字节到像素的映射,其中每个字节值(0–255)映射到等效灰度强度值(0–255)。
- SFC图像通过遍历曲线映射到图像,其中数据类型而不是字节值决定映射。如前3.2所述,scurve库使用颜色编码方案,将字节(0–255范围)分为0×00(0)的黑色、ASCII文本的蓝色(1–126)、高值字节的红色(127–254)和0×ff(255)的白色。
表8将KNN-GIST方法获得的性能指标与第5.4节中表现最好的KNN-HOG方法进行了比较。
- byteplot KNN-GIST模型在精度、召回率和准确性方面的训练成绩分别为97.6%、97.6%和97.5%,这与KNN-HOG模型的成绩几乎相同。
- 在测试阶段,我们的KNN-HOG模型表现稍好,精确性、召回率和准确度得分分别为97.1%、96.6%和97.0%,而KNN-GIST分别为96.9%、95.9%和96.4%。
- 就处理时间而言,KNN-GIST方法生成的每个样本平均为6.3ms,略快于KNN-HOG方法,该方法对256×256 SFC数据集的平均为8.1ms。

5.7 结果讨论
- 通过改变scurve库生成的图像大小,可以观察到,随着图像大小的增加,分类性能也随之增加。然而,出于可扩展性的目的(这是我们框架的一个要求),我们选择了256×256 SFC数据集,因为它提供了接近最佳的分类性能,同时比512×512样本快3.5倍。
- 通过测试进程转储时间间隔对分类性能的影响,证明了每个家族的最佳时间各不相同。进程注入和代码遗留问题证明了动态生成SFC映像有其局限性。此外,可以执行更具侵入性的进程跟踪,但这将以时间和计算复杂性为代价。
- 静态、动态和混合方法的评估结果表明,静态方法比动态或混合方法快得多,但产生的分类性能最差。动态方法的分类率通常较高,但每个样本33s的缓慢处理时间使该方法无法大规模工作。该混合方法静态处理未混淆样本,动态处理混淆样本,平均每个样本处理时间为12.5s。由于不需要承受通过VMI执行低熵样本的处理负担。对于混淆样本,混合方法解决了静态方法的局限性,将分类模型的性能提高了约15%。通过结合静态和动态方法的优点,混合框架已被证明是最佳解决方案。
六、结论和未来工作
在本文中,我们提出了一种基于计算机视觉和机器学习的新型混合恶意软件分类框架,旨在改善当前静态和动态恶意软件变体分类方法的局限性。与传统分析方法相比,该框架设计的侵入性更小,因为它不需要反向工程,也不会受到静态分析的混淆限制。该框架结合了从恶意软件二进制文件中提取的通过空间填充曲线映射的图像格式的鉴别特征分类。先前的研究表明,空间填充曲线提供了足够的特征,可用于基于图像的恶意软件分类。通过实验分析,使用最新的恶意软件样本数据集,证明混合框架优于静态和动态分析独立方法。
我们目前的研究重点是在更细粒度的级别上实现图像分割以进行分类。分割可以用来将图像分割为不同的区域,这些区域包含具有相似纹理的像素组,在这种情况下是具有相似二进制的区域。可以通过这种方式提取可执行二进制文件中的感兴趣区域,忽略不相关的数据,例如填充(二进制零区域)或混淆部分,否则熵会对分类算法产生不利影响。此外,我们还打算调查其他SFC的功效,例如应用于恶意软件领域的H曲线。最后,可以利用深度学习模型(如卷积神经网络)来提高性能。此类模型不需要特征提取,因此可以简化处理阶段。















 2386
2386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









