







通过异构图形注意网络快速检测Android恶意软件
目录
A.MSGAT: In-Sample Node Embedding
B.MSGAT++: Incremental Embedding
C. Robustness to Obfuscation 对混淆的鲁棒性
D. Model Aging and Decays 模型老化和衰老
摘要
Android每天都在遭受前所未有的恶意威胁,但现有的恶意软件检测方法往往无法应对恶意软件中不断演变的伪装。为了解决这个问题,我们提出了HAWK,这是一个用于进化Android应用程序的新恶意软件检测框架。我们将Android实体和行为关系建模为异构信息网络(HIN),利用其丰富的语义元结构来指定隐含的高阶关系。创建一个增量学习模型来处理动态显示的应用程序,无需重建整个HIN和后续嵌入模型。该模型可以快速确定新应用程序与样本应用程序之间的接近程度,并在各种语义下聚合它们的数字嵌入。我们的实验检查了七年来开发的80860多个恶意应用程序和100375个良性应用程序,结果表明HAWK实现了对基线的最高检测精度,平均只需3.5ms即可检测出样本外的应用程序,其加速训练时间比现有方法快50倍。
一、引言
图神经网络(GNN)用于建模实体之间的关系,在理论和应用领域都发展迅速。异构信息网络(HIN)作为GNN的一个特例。
- 在恶意软件检测的背景下,如果App1和App2共享权限SEND_SMS,而App2和App3共享权限READ_SMS,HIN能够捕获App1和App3之间的隐式语义关系,这是基于特征工程的方法很难实现的。
- HIN虽然前途光明,但本质上关心静态网络/图。然而,复杂的是如何有效地嵌入样本外节点(即,从已建立的HIN中嵌入传入节点)。考虑到持续的软件更新和庞大的应用程序量,不可能将所有应用程序都纳入HIN构建阶段,并且在出现新应用程序时重建整个嵌入模型效率低下。
在本文中,我们提出了一种新的Android恶意软件检测框架HAWK。
- 它借助于网络表示学习模型和HIN来探索不同应用程序之间丰富但隐藏的语义信息。
- 我们提取了七种类型的Android实体,包括应用程序、权限、权限类型、应用程序编程接口(API)、类、接口和从反编译的Android应用程序包(APK)文件中提取的.so文件,并主要通过将实体及其关系分别转换为节点和边来建立HIN。
HAWK的核心是所有应用程序实体的数字嵌入,然后可以将其输入到二进制分类器中。特别是,HAWK分别针对样本内节点和样本外节点建立了两种不同的学习模型。
- 为了嵌入样本内应用程序,我们提出了一种元结构引导图注意网络(MSGAT)机制,MSGAT将邻居嵌入到任何元结构中,并将不同元结构的嵌入结果集成到最终节点嵌入中。该设计不仅考虑了相邻节点的信息连通性,还考虑了不同实体关系的不同语义含义。
- 此外,为了有效嵌入样本外应用程序,我们在MSGAT基础上提出了一种新的增量学习模型MSGAT++,以充分利用现有节点的嵌入。
本文做出了以下贡献。
- 它检查了20多万个Android应用程序,反编译了18万多个APK,跨越了七年多的多个开放存储库。这揭示了建立HIN的丰富数据源,揭示了应用之间隐藏的高阶语义关系(第三节)。
- 通过充分利用元结构内部和跨元结构的邻居节点,提出了一种基于HIN的元结构引导注意机制,用于节点嵌入(第IV-A节)。实验表明,语义捕获能够支持良好的前向和后向兼容检测能力。
- 它提出用了一种增量聚合机制,于快速学习样本外应用程序的嵌入,而不会影响数字嵌入的质量和检测效率(第IV-B节)。
组织:
- 第二节显示了动机并概述了系统概述。
- 第三节讨论了利用HIN进行特征工程和数据重塑的过程,
- 第四节详细介绍了处理样本内和样本外恶意软件检测的核心技术。
- 第五节和第六节介绍了实验装置和结果。
- 第八节讨论了相关工作。
二、背景和概述
A.动机和问题范围
我们的工作解决了两个主要的研究挑战:归纳能力和检测速度。
检测过程通常被视为二元分类。
B.我们的HAWK方法
1)关键思想:我们方法的第一个创新之处是将信息编码为结构化HIN,其中节点描述实体及其特征。HIN是具有实体类型映射φ:V→A与关系型映射ψ:E→R的图G=(V,E,A,R), 其中V和E分别表示节点集和边集。A和R分别表示节点和边的类型集,其中| A |+| R |>2。为了支持样本外节点的连续嵌入学习,需要学习模型以增量方式充分利用现有样本内应用程序节点的嵌入结果。
2)架构概述:图1显示了HAWK的架构,包括数据建模器和恶意软件检测器组件。
- 具体来说,数据建模器中的关系提取器首先提供了基于特征工程的Android实体提取,大量Android应用程序被编译和研究。有七种类型的节点(“App”和六种特征)和六种类型的边。
- HIN构造函数然后通过将实体和提取的关系组织到HIN的节点和边来构建HIN(第III-B节)。
- 应用程序图构造函数负责从HIN生成仅包含应用程序实体的同构关系子图。这是通过使用元结构实现的,包括元路径和元图(第III-C节)。
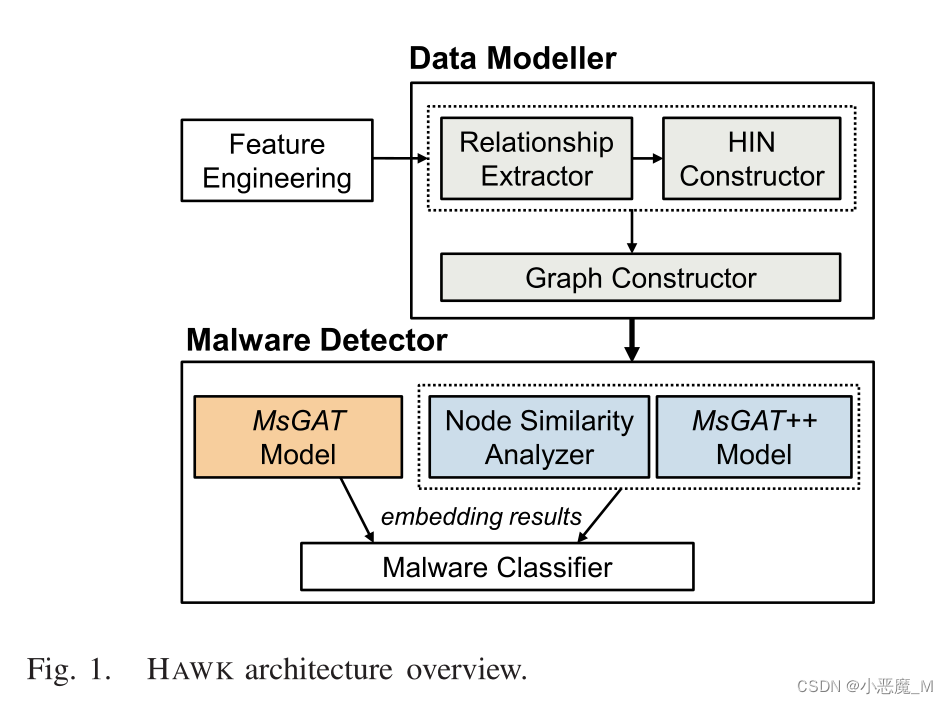
恶意软件检测器然后涉及两个不同的表示学习模型,
- 为了表示样本内的应用程序节点(MSGAT),提出的MSGAT是一种元结构支持的GAT解决方案,它首先聚合元结构内的注意聚合机制,以累积目标节点在与某个元结构相关的图中的相邻节点之间的嵌入。在第二个元结构间阶段,我们进一步融合不同元结构之间获得的嵌入,以便在最终嵌入中表达其语义(第IV-A节)。
- 为了有效地解决样本外节点嵌入问题(MSGAT++),我们通过重用和聚合样本内靠近目标节点的应用程序节点的嵌入结果,以增量方式为新节点生成嵌入。这需要模型确定现有示例内应用程序节点与目标节点之间的相似性。类似地,在进行元结构间聚合之前,首先在给定元结构下的邻居节点级别收集嵌入(第IV-B节)。
三、基于HIN的数据建模
A.特征工程
Android应用程序需要以APK格式打包并安装在Android系统上。APK文件包含代码文件、配置AndroidManifest.xml文件、签名和验证信息、lib(包含平台相关编译代码的目录)和其他资源文件。为了更好地分析Android应用程序,广泛使用反向工具(如APKTool2)来反编译APK文件,以便.dex源文件可以反编译为.smali文件。为了描述应用程序的关键特征,我们提取了以下六种类型的实体。
- 权限(P):权限决定应用程序可以执行的特定操作。例如,只有具有READ_SMS权限的应用程序才能访问用户的电子邮件信息。
- 权限类型(PT):权限类型描述给定权限的类别。表一概述了权限类型和代表性权限。
- 类(C):类是Android代码中的抽象模块,可以直接访问API和变量。HAWK在.smali代码中使用类名来表示类。
- API:它提供了Android开发环境中的可调用函数。
- 接口(I):接口是指Java中的抽象数据结构。我们从.samli文件中提取名字。
- .so文件:.so文件是Android的动态链接库,可以从反编译的lib文件夹中提取。

B.构建HIN
1)将实体关系提取到HIN中:元模式是一个元级模板,用于定义HIN中节点和边的关系和类型约束。图2(a)所示,我们找到了一个元模式,可以对Android实体之间的必要关系进行编码。基于领域知识,我们仔细研究了以下固有的语义关系。
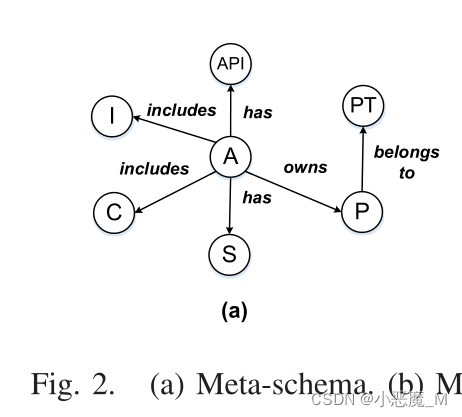
- 【R1】APP-API:表示应用程序有特定的API。使用应用程序和API之间的关系可以有效地挖掘和表示两个应用程序之间的链接。
- 【R2】APP-Permission:指定应用拥有特定权限。具有权限的应用程序,如READ_SMS、SEND_SMS和WRITE_SMS,具有很强的相关性。如果在App1和App2之间共享SEND_SMS,而在App2和App3之间共享READ_SMS,则App1和App3之间很可能存在隐式关联。
- 【R3】Permission-PermissionType:描述权限属于特定的权限类型。通常,权限可以分为不同的类型。
- 【R4】APP-Class:表示该APP在外部SDK中包含一个特定的类。恶意软件倾向于使用恶意SDK中的类生成实例。
- 【R5】APP-Interface:表示该应用包含外部SDK中的特定接口。
- 【R6】App-.so:表示该App有一个特定的.so文件。Fanetal【17】证明了在Windows系统中将动态链接库与软件相关联的有效性。
图3显示了包含两个应用程序及其语义关系的HIN。例如,App1具有API Ljava/net/URL/openConnection。App1和App2都拥有Ljava/io/PrintStream类。“权限READ_SMS属于权限类型SMS”等。
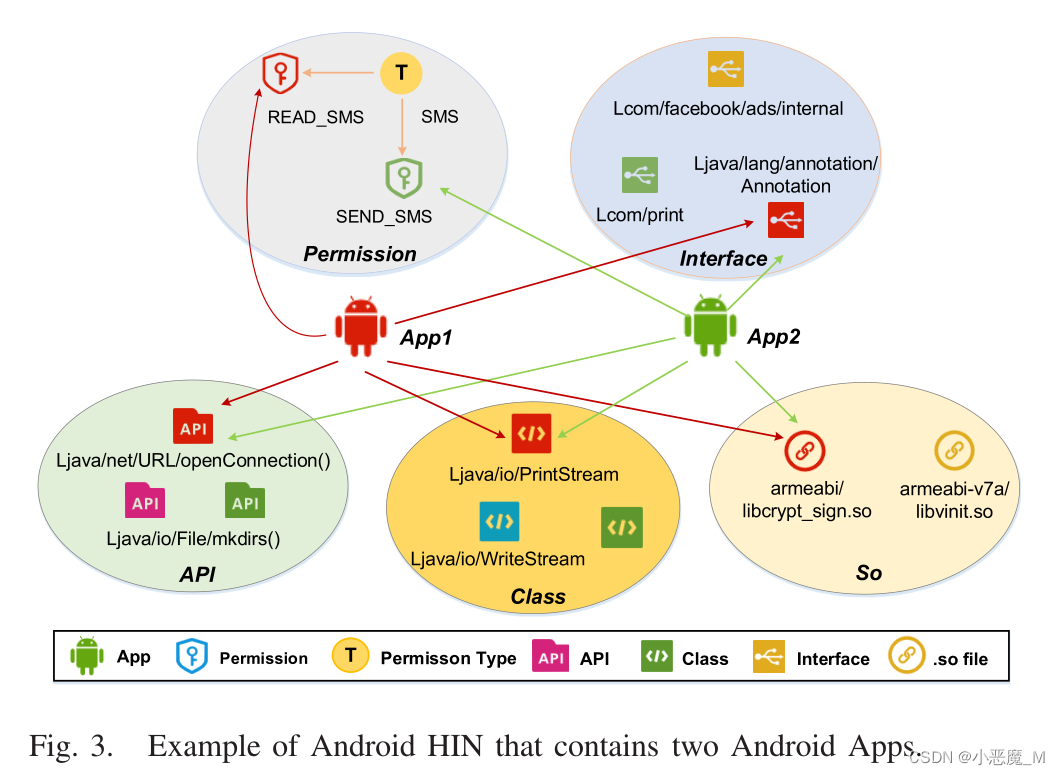
2) 存储实体关系:我们使用关系矩阵分别存储每个关系。例如,我们生成一个矩阵![]() ,其中元素
,其中元素表示Appi是否包含APIj。直观地说,矩阵的转置描述了向后关系,例如,APIj属于Appi。如表II所示,六个矩阵用于表示和存储关系【R1】–【R6】。

C.从HIN构建应用程序图
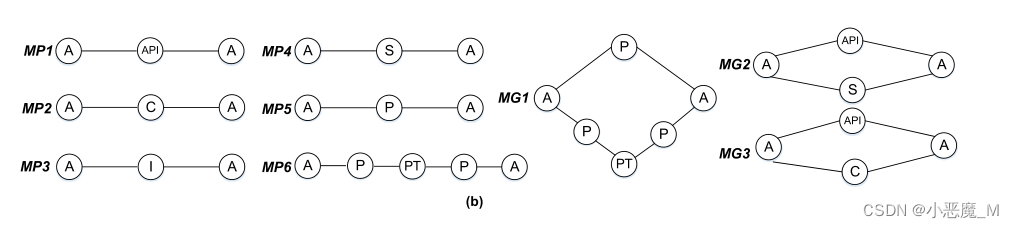
1)Meta-Structures:如图2(b)所示,我们最终给出了六条元路径和三个元图,它们可以有效地勾勒出HIN中两个Android应用程序之间的结构语义并捕获丰富的关系。例如,A-P-A描述了两个应用具有相同权限(MP5)的关系,A-P-PT-P-A表示两个应用共同拥有相同类型的权限(MP6)。MG2同时结合了A-API-A和A-S-A。因此,语义约束将更加严格,即所选节点必须满足所有预定义的约束。
2)Homogeneous App Graph for Each Meta-Structure:通过对建模的关系矩阵执行一系列矩阵操作,我们可以精确地计算图中节点的邻接度。对于给定的元路径MP,(A1,…,An),邻接矩阵可以通过以下公式计算
![]()
其中,是实体Aj和Aj+1之间的关系矩阵(表II中[R1]到[R6]的一个实例)。例如,MP1 (A-API-A)下的图的邻接矩阵为
![]()
![]() 表示Appi和Appj相互关联,即它们是基于元路径MP1的邻居。具体来说,该值表示元路径实例的计数,即节点i和j之间的路径数。同样,对于给定的元图MG,多个元路径的组合,即(MP1,…,MPm),节点邻接矩阵为
表示Appi和Appj相互关联,即它们是基于元路径MP1的邻居。具体来说,该值表示元路径实例的计数,即节点i和j之间的路径数。同样,对于给定的元图MG,多个元路径的组合,即(MP1,…,MPm),节点邻接矩阵为
![]()
其中是![]() 哈达玛积的运算(矩阵对应位置相乘) 。例如,MG2,可以通过
哈达玛积的运算(矩阵对应位置相乘) 。例如,MG2,可以通过
![]()
![]() 计算邻接矩阵。通过对每个元结构进行图建模,将原始HIN转换为多个App同构图,每个App同构图都属于邻接矩阵。给定K个元结构,我们有K个邻接矩阵的集合,即
计算邻接矩阵。通过对每个元结构进行图建模,将原始HIN转换为多个App同构图,每个App同构图都属于邻接矩阵。给定K个元结构,我们有K个邻接矩阵的集合,即
![]()
四、结点嵌入模型
A.MSGAT: In-Sample Node Embedding
我们在给定元结构(intra-ms)内的相邻节点之间采用注意机制,并协调不同元结构(inter-ms)之间的注意。图4显示了我们模型的流程图,表III概述了模型中使用的重要符号。
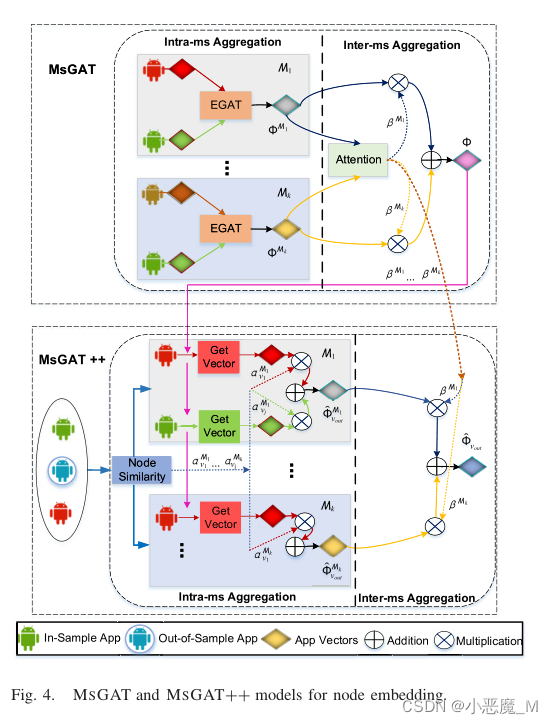
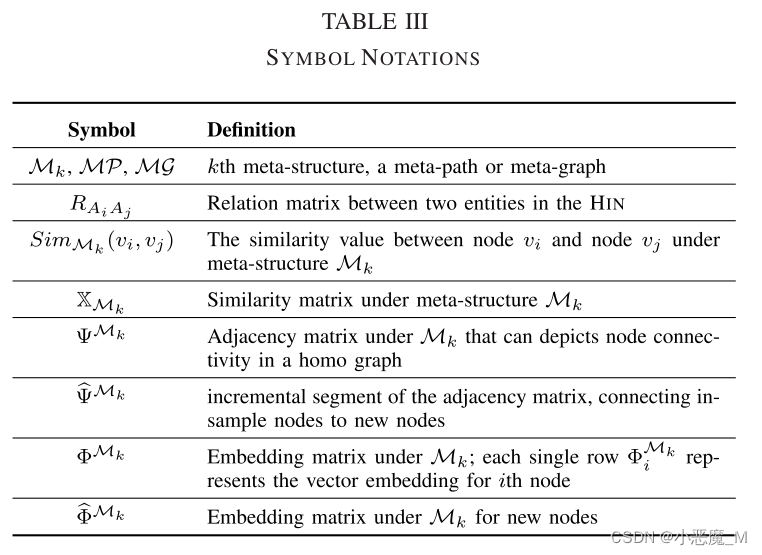
1) Intra-ms Aggregation:intra-ms聚合学习节点在元结构图中如何对其相邻节点给予不同的关注。形式上,它考虑实体的特征信息和实体之间的边缘信息,用权值聚合邻居的表示向量。
- 我们首先以one-hot的形式对每个样本App的向量进行编码,并将它们连接到矩阵H中。H的第i行Hi表示第i个App节点的嵌入向量。
- 然后,我们设计了一个边缘权重感知的GAT(EGAT)模型,将H和给定元结构Mk的邻接矩阵结合起来。为了实现EGAT模型,充分利用特征信息和边缘权重信息来聚合邻居的特征。
更具体地说,我们首先通过归一化操作构造邻接矩阵。
![]()
中低于预定义阈值τ的元素(在我们的模型中τ设置为0.1)将设置为零。此后,我们用GAT模型更新
![]()
最终,在此阶段可以获得所有样本内App节点的低维向量嵌入,其形式为具有行向量集合的矩阵。
然后,我们重复计算所有预定义元结构的向量矩阵,并获得嵌入向量的集合,即,
![]()
其中K是元结构的总和。具体而言,嵌入矩阵的形状为L×D,其中L表示HIN中样本内App的数量,D表示每个App向量的维数。因此,Appi节点的嵌入可以识别为第i行,即
。
2) Inter-ms Aggregation:由于每个元结构都提供了一个单独的语义视图,因此我们提出了一种inter-ms注意聚合来整合不同语义下的嵌入![]() ,从而提高节点嵌入的质量。具体而言,我们利用多层感知器(MLP)程序来学习融合中每个元结构Mk的权重
,从而提高节点嵌入的质量。具体而言,我们利用多层感知器(MLP)程序来学习融合中每个元结构Mk的权重。
![]()
其中,NN是将给定矩阵映射为数值的原生神经网络。因此,通过将加权表示矩阵相加,可以获得所有样本内App节点的最终嵌入。
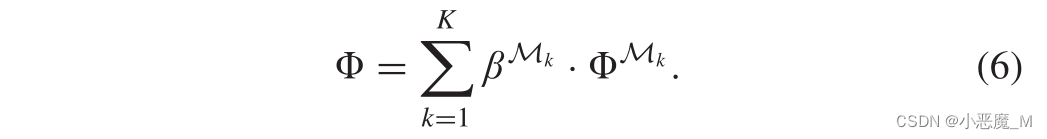
然后,我们将传递给另一个神经网络,以便通过迭代反向传播校准神经网络输出和真值标签之间的损失函数。
B.MSGAT++: Incremental Embedding
为了更好地嵌入未包含在训练过程中的未知应用程序,我们提出了一种增量学习机制MSGAT++,用于利用从MSGAT学习到的样本内嵌入来快速表示那些样本外的应用程序。为了说明这一点,我们通常使用来表示HIN中的任何样本外节点。
1) Exploring Node Similarity:准确定位HIN中新节点和现有节点之间的潜在连接。为此,必须计算和积累与现有节点之间的相似度。按照【30】中提出的类似方法,给定元路径下节点vi和节点vj之间的节点相似性定义为
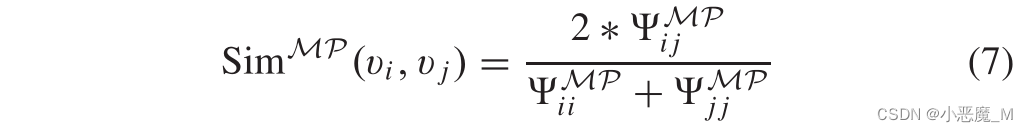
其中,表示两个连接节点之间的元结构数量,因此,更高的相似度表示这两个节点之间的关联更紧密。因此,在元图MG下,节点vi和vj之间的节点相似度为
![]()
2) Incremental Aggregation for Embedding Learning:最初的任务是捕捉增量关系并构造图信息。在给定的元结构中,我们的目标是只更新邻接矩阵,该矩阵量化样本外节点和样本内现有应用程序节点之间的连接。这应该以渐进的方式进行,以降低培训成本。
- 在实践中,我们首先重复第III-B节中提到的步骤(构建HIN),以计算表II中的所有关系矩阵,仅针对样本外的App节点。
- 其次,我们将新App节点的关系矩阵与现有App节点的关系矩阵连接起来,形成节点邻接的增量段
 —从样本应用程序节点到新节点的路径。
—从样本应用程序节点到新节点的路径。
以MP1为例;我们首先获得所有新节点的关系矩阵![]() ,然后通过
,然后通过![]() 生成矩阵。这种设计确保增量邻接矩阵
生成矩阵。这种设计确保增量邻接矩阵![]() 可以独立于已建立的邻接矩阵
可以独立于已建立的邻接矩阵运行,而它们一起作为所有节点之间连接的整体抽象。
我们建议MSGAT++在校准现有节点表示的同时,赋予新节点数字嵌入的权利。与MSGAT相似,该模型由两个步骤组成:intra-ms内聚合和inter-ms间聚合。给定一个语义元结构Mk,我们将Mk替换为(7)或(8)来计算![]() ,即新节点
,即新节点与任何示例应用程序节点vj之间的相似度。对所有样本外节点和样本内所有应用程序节点重复此操作,将形成一个相似度矩阵
![]() ,其中较大的值本质上表示两个节点之间更接近。因此,我们可以获得所有元结构的相似矩阵集合
,其中较大的值本质上表示两个节点之间更接近。因此,我们可以获得所有元结构的相似矩阵集合
![]()
可以说,为了更好地在数字向量中表示新节点,我们应该充分聚合靠近新节点的现有节点的现有嵌入结果。为此,我们基于相似度矩阵![]() 在示例应用程序节点(vn1,…,vnσ)中选择top-σ,并聚合它们的向量以嵌入新节点。
在示例应用程序节点(vn1,…,vnσ)中选择top-σ,并聚合它们的向量以嵌入新节点。
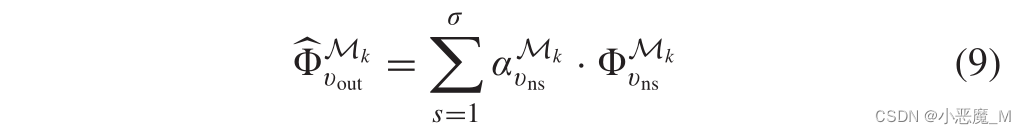
其中,表示节点vj在Mk下的权重(vj∈(vn1,…,vnσ)),
![]() 表示样本外节点的增量嵌入信息。权重可通过以下方式轻松计算:
表示样本外节点的增量嵌入信息。权重可通过以下方式轻松计算:
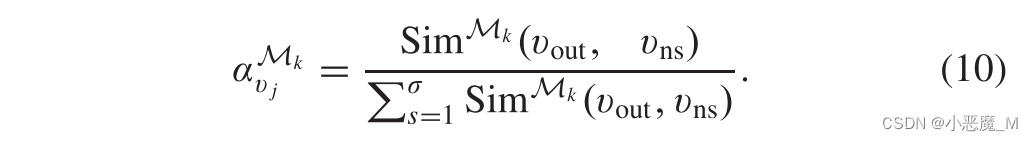
最后,我们通过在所有元结构下对K个个体表示进行inter-ms间聚合来重新校准嵌入
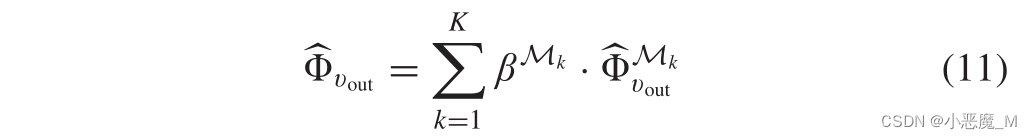
其中,可以从公式(5)中获得(事实上,为了提高我们模型的性能,我们需要微调这些权重)。算法1概述了恶意软件检测中快速增量嵌入学习的整个过程。

3) 时间复杂度:算法1演示了一种简单但有效的方法,其复杂度可以接受。总体复杂性为O(KLNlogN),其中K和L分别是元结构的数量和样本外应用的数量,N表示样本内应用的数量。
五、实验设置
A. Methodology
1) Environment:Hawk在16节点GPU群集上进行评估,其中每个节点都有一个64核Intel Xeon CPU E5-2680v4@2.40 GHz,512 GB RAM和8个NVIDIA Tesla P100 GPU,Ubuntu 20.04 LTS与Linux内核v5.4.0。HAWK依赖tensorflow gpu v1.12.0和scikit learn v0.21.3。ApkTool和aapt.exe用于解析应用程序。
2) Datasets:从2013年到2019年,我们全面反编译了181235个APK(即80860个恶意应用和100375个良性应用)。在AndroZoo的帮助下,良性应用程序主要从Google Play store收集,而恶意应用程序则从VirusShare和CICAndMal获得。为了验证HAWK中拟议模型的前向和后向兼容性,我们根据2017年发布的应用程序(在七个时间跨度中)对我们的模型进行训练,然后利用它检测2013年至2019年发布的应用程序。
- 具体而言,我们提取了2017年发布的14000个良性应用和9865个恶意应用,作为样本内应用程序,构建HIN并训练检测模型。
- 为了生成样本外的样本数据,我们连续七年从VirusShare收集了七个恶意软件子集(v2013–v2019),其中每个包含大约10000个样本,还有另外两个来自CICAndMal的子集,包括2017年的242个恐吓软件/广告软件样本(c2017)和2019年的253个样本(c2019)。
- 同时,我们提取良性应用程序,以匹配上面每个子集中相同数量的良性应用程序。
3) Methodology and Metrics:实验分为三部分。
- 我们首先评估HAWK相对于传统的基于特征的ML方法和大量基线在样本内和样本外场景方面的有效性(第VI-A节)。
- 然后,我们通过比较HAWK与其他方法的训练时间消耗来证明HAWK的效率(第VI-B节)。
- 我们进一步进行了几个微基准测试,包括性能增益的烧蚀分析、元结构重要性的评估以及采样邻居数对检测精度的影响(第VI-C节)。
我们使用精度、召回率、误报率(FP)、F1和准确度来衡量有效性(见表IV),并使用时间消耗来衡量效率。执行时间包括生成嵌入向量和检测应用程序的过程,而不包括提取应用程序关系矩阵的过程。我们使用五倍交叉验证并计算平均准确度,以确保无偏和准确的评估。

B. Baselines
为了评估MSGAT在HAWK中的性能,基线包括一些著名恶意软件检测系统使用的通用模型和特定模型。
1) 通用模型:我们首先实现以下通用模型作为比较方法。
- Node2Vec:它是由DeepWalk基于齐次图网络推广而来的典型模型。
- GCN:它是一种半监督齐次图卷积网络模型,保留了图节点的特征信息和结构信息。
- RS-GCN:它表示将HIN转换为同构图的方法,将本机GCN应用于每个图,并报告不同图中的最佳性能。
- GAT:它是一种半监督齐次图模型,利用注意机制聚合图节点的邻域信息。
- RS-GAT:它表示将HIN转换为基于丰富语义元结构的同构图的方法,将本机GAT应用于每个同构图,并报告不同图中的最佳性能。
- Metapath2Vec:它是一种异构图表示学习模型,利用基于元路径的随机游走来查找邻居,并使用带负采样的跳过图来学习节点向量。
- Metagraph2Vec:它是Metapath2Vec的替代模型;元路径和元图都应用于随机游动。
- HAN:它是一种异构图表示学习模型,利用预定义的元路径和层次注意进行节点向量嵌入。
对于Node2Vec、GCN和GAT,我们将HIN中的所有节点视为同一类型,以获得齐次图。由于所有这些模型都是面向静态图的,因此我们比较了MSGAT++与任何比较模型中都可以轻松采用的三种通用策略之间的样本外检测能力。
- 邻居平均(NA):它直接平均与给定新应用程序相关的样本内邻居的向量嵌入,作为目标嵌入。
- 采样邻居平均(SNA):它根据排序后的节点相似度对固定数量的样本内邻居进行采样,并简单地将其嵌入平均为目标嵌入,从而进一步过滤邻居范围。
- 重新运行(RR):它主要将样本外应用程序与样本内应用程序合并,并重建整个HIN和恶意软件检测模型。
2) 源自专用系统的特定模型:其次,我们将HAWK中的模型与现有恶意软件检测系统使用的以下模型进行比较。
- Drebin:该框架通过从清单(manifest)和索引代码(dex code )中提取广泛的特征集来检查给定的应用程序,并在分类器中采用SVM模型。
- DroidEvolver :这是一个自我进化的检测系统,用于维护和依赖不同检测模型的模型库,这些模型由一组使用各种在线学习算法标记的应用程序初始化。值得注意的是,我们并没有直接与MamaDroid进行比较,因为已经证明它不如DroidEvolver有效。
- HinDroid:它构建了一个异构图,其中包含应用程序和API等实体以及丰富的相互关系。它聚集来自不同语义元路径的信息,并使用多核学习来计算应用程序的表示。
- MatchGNet:它是一种基于图形的恶意软件检测模型,将每个软件视为异构图形,并学习其表示形式。它主要通过匹配未知软件和良性软件的图形表示来确定未知软件的威胁。
- Aidroid:这是第一次尝试使用异构图模型和CNN网络来处理样本外恶意软件表示。按照本文的详细描述,我们使用一跳和两跳邻居来优化其模型性能。
3)模型参数:对于Node2Vec和Metapath2Vec,我们将每个节点的行走次数、最大行走长度和窗口大小分别设置为10、100和8。对于GCN、GAT和HAN,我们设置了他们原始论文建议的参数。为了比较的公平性,每个模型将接受200次培训。这些模型提供的嵌入向量的长度设置为128。
六、实验结果
A. Detection Effectiveness
1) 针对DL模型的样本内恶意软件检测:我们选择了20%、40%、60%和80%的样本应用程序来训练LR模型,剩余的用于测试。表五显示了各模型的F1和Acc得分。
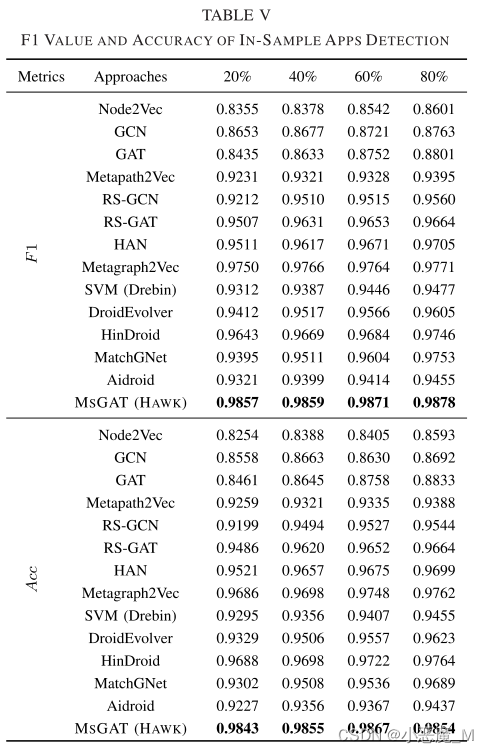
- MSGAT可以实现具有竞争力的分类精度。这是因为我们基于图的表示学习模型能够充分集成应用程序的特征信息和应用程序之间隐含的语义信息,从而提高了表达能力。
- 此外,RS-GCN和RS-GAT的精度比原生GCN和GAT提高了5%以上。这些方法将原始HIN转化为同构图,改进的方法是通过我们提出的语义元结构来保留异构网络中的语义信息。
- 值得注意的是,Metagraph2Vec和MSGAT实现了最高的精度,尤其是与仅涉及元路径的Metapath2Vec和HAN相比。显然,准确度的提高源于引入元图,这些元图为挖掘更复杂的语义关联带来了丰富的语义。
- 此外,MSGAT优于Metagraph2Vec,因为我们的模型采用了元间结构和元内结构的聚合机制,从而从更全面的角度聚合语义信息。
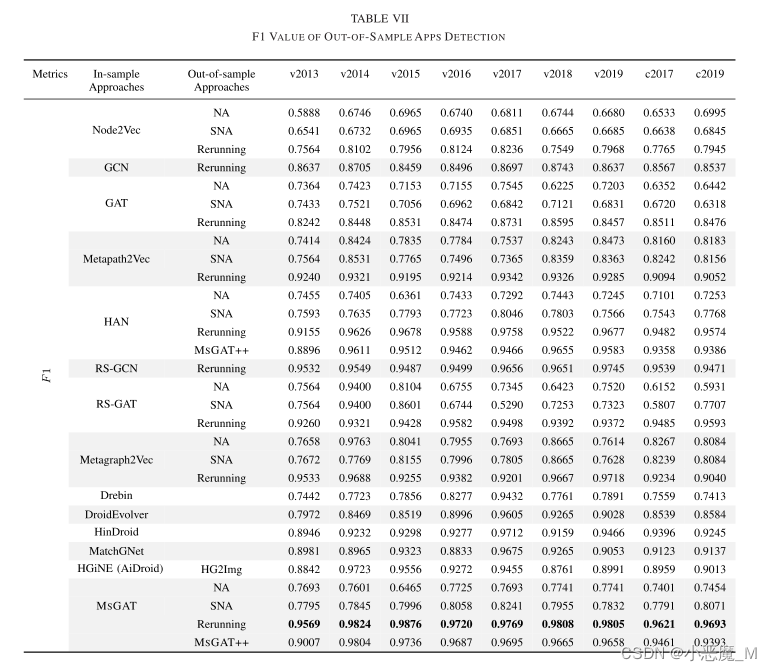
2) 针对DL模型的样本外恶意软件检测:表七和表八分别显示了当我们采用不同的样本内模型和样本外策略时的F1得分和FP率。
- 总的来说,由于语义信息的大量丢失,NA和SNA策略在所有情况下的检测精度都最低。显然,直接平均操作忽略了邻居之间的差异,从而降低了节点嵌入的精度和检测效果。
- 还可以观察到,NA和SNA在几乎所有情况下都具有非常相似的精度。这表明,与平均所有邻居节点相比,对一定数量的邻居节点进行采样能够获得近似信息。
- 直观地说,RR策略将在所有数据集上提供最佳的检测性能,因为所有新的或旧的数据都将涉及嵌入再训练。
- Metagraph2Vec、RS-GAT和RS-GCN分别优于Metapath2Vec、GAT和GCN,因为它们受益于丰富的元结构。这种性能的提高再次表明,在嵌入模型中应用丰富的语义元结构可以带来更强的泛化能力。
- MSGAT和重新运行策略在2/3数据集上实现了最佳的检测效果。然而,重新运行的开销是不可忽略的。相比之下,MSGAT++被证明是一种折衷但有竞争力的解决方案;
- MSGAT++的精度非常接近所有数据集的重新运行基线。为了证明这种泛化,我们还在HAN模型上实现了我们的MSGAT机制。增量学习方案取得了更好的改进,只是与重新运行的基线相比,差距可以忽略。
- Hindroid、MatchGNet、HG2Img和Drebin在不同的数据集上显著地提供了不稳定的结果,表明泛化能力有限。
3) 与传统基于特征的ML模型的比较:我们主要使用RF、LR、决策树(DT)、梯度提升决策树(GBDT)和AdaBoost作为比较基线。在本实验中,我们特别使用v2017作为构建HIN的训练集,同时利用具有不同发布时间或不同来源的样本外应用作为测试集。按照文献[3]中的方法,我们从权限、API、类名、接口名和.so文件中提取信息,构建63902维的特征向量,通过主成分分析(PCA)将其降到128维。
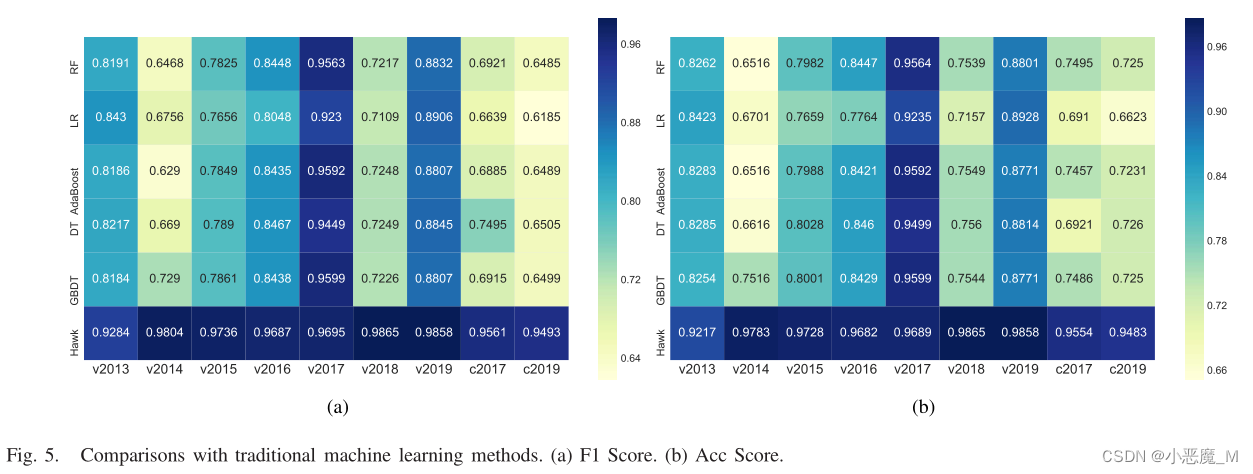
- 值得注意的是,HAWK在执行应用程序分类时,在所有情况下都稳定地优于所有传统基线。
- 只有当测试集与训练集(v2017)保持一致时,传统的ML方法才具有竞争力(Acc或F1分数在0.95左右),而Hawk可以不断提供精确的结果。
B. Detection Efficiency
1) 时间消耗:在本实验中,我们将增量检测设计MSGAT++的时间效率与具有可接受检测精度的比较方法进行比较(即重新运行HAN、重新运行Metagraph2Vec、Drebin、DroidEvolve和HG2Img)。为了简单起见,我们在计算总体执行时间时排除了提取时间,因为我们实验中的所有方法都共享相同的特征提取过程。事实上,每个应用程序从其原始APK文件中提取特征信息大约需要6.9秒。
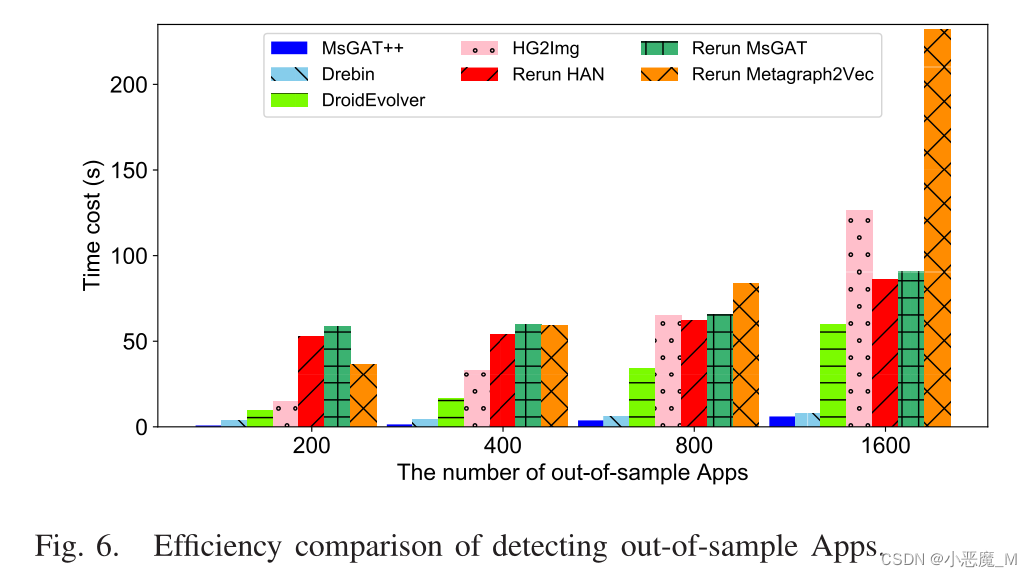
- MSGAT++的执行时间比其他方法短得多。MSGAT++平均只需3.5毫秒就可以检测出一个样本外的应用程序。HAWK的毫秒级检测说明了其在大规模实时恶意软件检测场景中的适用性。
- 特别是,与重建HIN并重新运行MSGAT的原生方法相比,MSGAT++可以将训练时间缩短50倍。加速主要来自我们的增量学习设计,它可以充分利用以前学习的信息,而无需重新运行整个模型。
- 此外,MSGAT++仅选择固定数量的邻居节点来重新校准嵌入,因此时间消耗仅随样本外数量的增加而线性增加。
2) 系统开销:总体而言,开销通常较低,主要来自加载模型数据和执行多层聚合操作。运行时内存消耗通常由模型训练中涉及的节点和特征的数量决定。
- HAWK的总内存消耗量平均约为330MB,远低于基于RR的基线的消耗量(平均20.88 GB)。这是因为所有样本内和样本外都必须完全加载到内存中并参与嵌入计算,而我们的增量设计显著降低了此类成本。
- 相应地,HAWK平均只使用3.1%的额外CPU利用率,主要用于排序 top-σ 样本。相比之下,在重新运行基线时,CPU利用率高达76%,其中必须执行CPU密集型矩阵操作。低系统成本也表明了将Hawk应用于大规模恶意软件检测的适用性。
C. Microbenchmarking 微基准
1)Ablation Analysis 烧蚀分析:为了调查每个组件的影响,我们从模型中一次删除一个组件,并研究单个组件对检测样本外应用程序有效性的影响。我们确定了两个定制的子系统:
- projtitle-I仅保留原生GAT模型,并从HAWK中删除层次化GAT结构;
- projtitle-R排除增量设计。表九报告了它们在v2017上检测单个应用程序的准确性和平均时间

- projtitle-I无需在元结构内和跨元结构进行多步骤和分层聚合,即可将平均检测时间减少到1.8ms。然而,与HAWK相比,准确率和F1得分都降低了9.9%。这一现象表明,融合不同元结构下的嵌入结果可以提高准确度。
- projtitle-R需要更长的时间来检测恶意软件应用程序,原因很简单,因为没有加载增量模型,所有内容都需要从头开始重新训练。因此,有必要采用增量MSGAT++来确保可靠和快速的恶意软件检测。
2) Importance of Meta-Structures:为了确定元结构个体对检测效果的贡献,我们在本实验中每次选择一个元结构。图7显示了不同元结构之间的度量差异。
- 更具体地说,在所有元路径中,MP1和MP4对检测精度的贡献是最高和最低的。事实上,在分析反编译代码时,我们能够提取比so文件多得多的API信息,因此关系矩阵
 比
比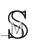 更密集,因此包含更多用于节点嵌入的连接信息。
更密集,因此包含更多用于节点嵌入的连接信息。 - 值得注意的是,与纯粹使用元路径相比,使用元图可以实现更高的检测精度,因为元路径的组合可以找到亲和力更高的邻居。

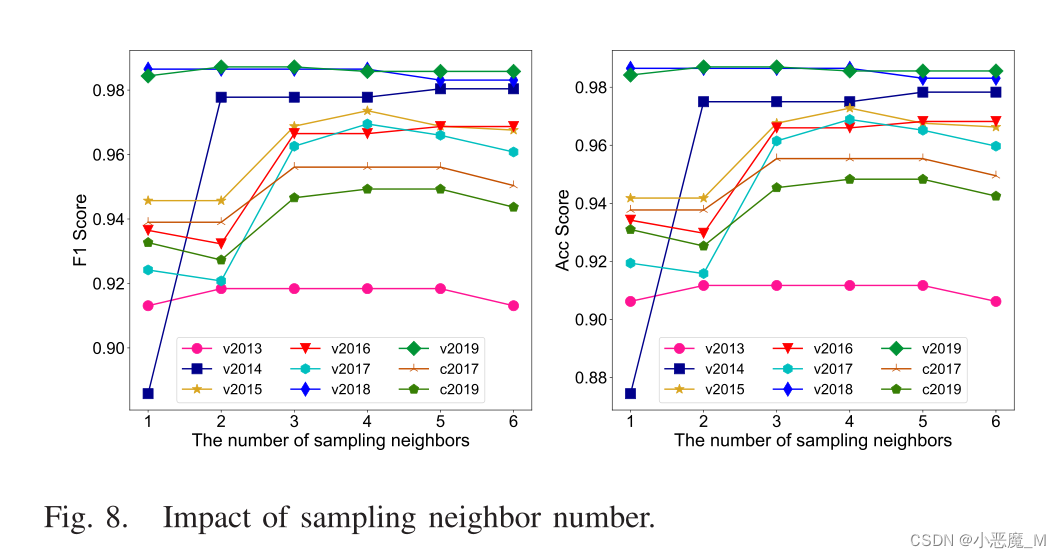
3) Impact of the Sampling Neighbor Number:
- 精度将首先在一定范围内提高,但一旦采样邻居的数量变大(在我们的实验设置中超过四个),精度将下降。
- 实际上,增加邻居可以为新节点的参考提供更多相关和信息的嵌入。然而,当邻域开始积累时,更多不相关邻域产生的噪声反过来会对嵌入聚合产生负面影响,即降低表示学习的有效性。
- 这意味着衡量适当数量的邻居对于嵌入传入应用程序并识别其类型的整体性能非常关键。我们选择3-4个邻居来产生足够好的效果。
4) Case Study of True Negative Detection 真阴性检测案例研究: 实验还表明,真阴结果偶尔会出现。换句话说,我们的模型可能无法正确识别少数恶意应用程序。例如,v2013 中的VirusShare_ecc4c2e7和VirusShare_f21ff00cf绕过我们的检测。深入的调查确定,此类恶意应用程序的嵌入将被其良性邻居节点同化,HAWK获得的这些恶意应用的邻居更稀疏,往往是良性应用,导致分类不准确。为了解决这个问题,我们计划采用基于节点属性的标签感知邻居相似性度量,以便更好地导航邻居选择,并在将来更有效地区分恶意软件。
七、讨论
A. Interpretablity 可解释性
HAWK是一种基于HIN和GATs授权的网络表示模型的数据驱动建模和检测机制。由于HIN中元路径和元图的组合以及来自不同语义的注意力的多层聚合,丰富语义的固有性质可以显著增强模型的可解释性。
B. Scalability 可扩展性
当前基于HIN的数据建模是可扩展的,并且可以轻松地扩展到任何任意实体和关系,只要通过领域知识或实验评估证明语义有利于检测过程。此外,由于我们的设计不需要任何模型重新运行,因此在处理大型样本时,可以从本质上保证可扩展性。
C. Robustness to Obfuscation 对混淆的鲁棒性
基于多个实体(包括权限、权限类型、类和接口)的语义元结构可以克服API单独检测方法的低效性并提供了一种健壮而准确的机制,用于检测潜在的恶意软件,以应对API混淆、打包或数据集扭曲。
D. Model Aging and Decays 模型老化和衰老
概念漂移(也称为模型老化和模型衰退)通常会使经过训练的模型无法在新的测试样本上运行,这主要是由于样本的统计特性随着时间的推移而发生变化。Hawk中的MSGAT++旨在基于现有嵌入结果,假设现有应用的统计特征相对稳定,快速嵌入和检测样本外的应用。目前,将通过重新运行MSGAT来进行模型演化,这在精度和时间消耗方面是可以接受的(详见第VI-B节)。
八、相关工作
A.基于传统特征工程的恶意软件检测
基于特征工程和机器学习的恶意软件检测方法有两种:静态/动态特征分析。
- 静态特征分析方法通常包括权限、签名和API序列等特征,并直接使用RF、SVM或CNN等机器学习模型进行恶意软件检测。
- 动态特征分析依赖于运行时的行为检测。然而,将其应用于大规模恶意软件检测既耗时又不现实。
- 其他来自自然语言处理和图像识别的模型可以在恶意软件检测中自定义和重用。然而,由于应用程序不断更新,从有限的应用程序中提取明确的特征对于检测不可见的应用程序是无效的。
B、 基于图网络的恶意软件检测
- Gotcha构建了一个HIN,并利用基于元图的方法来描述PE文件的相关性,该方法捕获了windows恶意软件基于内容和关系的特征。
- HinDroid[18]主要基于基于API和应用程序之间关系的HIN,并采用多核SVM进行软件分类。
- MatchGNet[19]将HIN模型与GCN[9]相结合,以基于程序执行行为的不变图建模来学习图表示和节点相似度。
- Wanget 构建了一个异构程序行为图,特别是针对IT/OT系统,然后引入图注意机制来聚合通过GCN在不同语义路径上学习到的信息,并赋予权重。
然而,所有这些方法都受到HIN静态特性的阻碍,即它们在处理构建图之外的新兴应用程序方面的能力有限。HAWK首次尝试将基于HIN的嵌入模型和GAT连接起来,以支持增量和快速的恶意软件检测,尤其是针对样本外的应用程序。
九、结论和未来工作
- 在本文中,我们提出了HAWK,一个Android恶意软件检测框架,用于快速、渐进地学习和识别新的Android应用程序。
- Hawk首次尝试将基于HIN的嵌入模型与GAT相结合,以获得Android应用程序的数字表示,以便任何分类器都可以轻松捕获恶意应用程序。特别是,我们利用元路径和元图来最好地捕获HIN中实体之间的隐式高阶关系。
- 设计了两种学习模型MSGAT和增量MSGAT,以融合邻居嵌入任何元结构和不同元结构中的信息,并精确定位新应用程序和样本应用程序中现有应用程序之间的接近程度。通过增量表示学习模型,Hawk可以对新兴的Android应用程序动态进行恶意软件检测。
- 实验表明,hawk在准确性和时间效率方面优于所有基线。未来,我们计划通过设计轻量级和高效的图卷积模型来取代现有模块,将HAWK与智能移动设备集成。我们还计划研究更先进的机制,以支持模型在面对模型衰退时不断发展,特别是在联合学习环境中。















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









