







 这篇博客介绍了Hadoop的基础知识,包括大数据概论、Hadoop的组成部分如HDFS、YARN和MapReduce的架构。详细阐述了Hadoop的安装配置过程,从本地模式到伪分布式再到完全分布式模式的集群搭建,包括SSH免密登录、集群时间同步等关键步骤。还提到了Hadoop源码编译的必要性和步骤。
这篇博客介绍了Hadoop的基础知识,包括大数据概论、Hadoop的组成部分如HDFS、YARN和MapReduce的架构。详细阐述了Hadoop的安装配置过程,从本地模式到伪分布式再到完全分布式模式的集群搭建,包括SSH免密登录、集群时间同步等关键步骤。还提到了Hadoop源码编译的必要性和步骤。
Hadoop基础篇
大数据概论
概念
大数据(Big Data):指的是无法在一定时间范围内用常规软件工具(JavaEE)进行捕获、管理的处理的数据集合。
需要新的处理模式更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产
常用的数据存储单位:TB、PB、EB,ZB,YB,大企业的数据量已经接近EB量级。
主要解决问题
海量数据的存储和分析计算
特点(4V)
-
Volume大量!
-
Velocity高速!
-
Variety多样!
存储各种非结构化数据:音视频、图片等
-
Value(低价值密度)
数据的价值密度和数据总量的大小成反比
应用场景
- 物流仓储:分析仓库选址
- 零售行业:分析用户消费习惯,典型:纸尿裤+啤酒
- 旅游行业
- 商品广告推荐
- 保险、金融、房地产
- 人工智能
Hadoop入门

是什么?
Apache基金会的顶级开源项目,一个分布式系统基本架构。
解决数据的存储和分析计算
通常是指的是Hadoop生态圈(HBase、Hive、Zookeeper等)
发展历程
与Lucene是同一个作者——Doug Cutting,其logo和名字源于作者儿子的一个玩具大象。
海量数据场景中Lucene和Google都遇到了相同的困难:存储困难,检索速度慢
Hadoop就是DougCutting在借助谷歌的开放技术三篇论文激发灵感改造以Lucene为核心的Nutch而来。
推荐阅读:https://www.sohu.com/a/294319573_700886
| Nutch | |
|---|---|
| GFS | HDFS(Hadoop分布式文件系统) |
| MapReduce | MapReduce |
| Big Table | HBase |

三大发行版本
- Apache:最原始基础的版本、入门学习容易上手,开源
- Cloudera:大型互联网企业中用的较多
- Hortonworks:文档完整
四大优势
- 高可靠性:hadoop底层维护多个(5个)数据副本
- 高扩展性:在集群间分配任务数据,方便扩展数以千计的节点
- 高效性:MapReduce的思想下,Hadoop是并行工作的,以加快任务处理的速度
- 高容错性:能够将自动将失败的任务重新分配
Hadoop的组成

HDFS架构概述
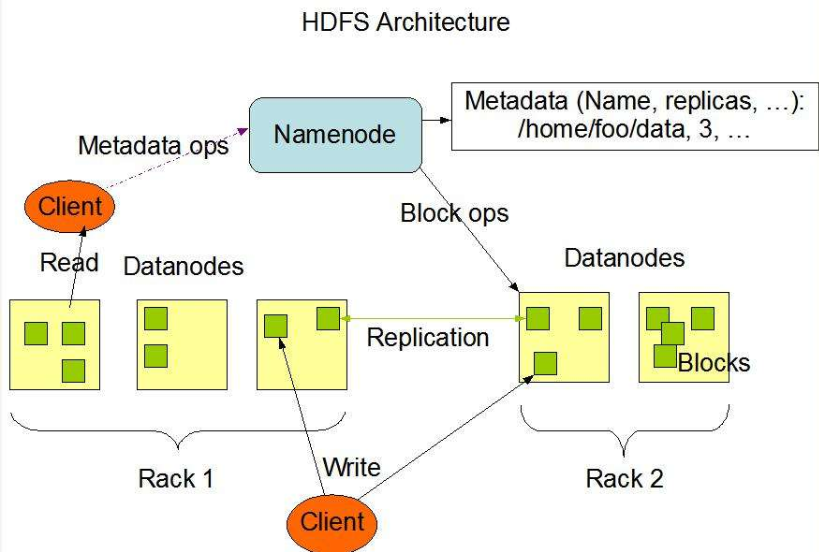
Hadoop分布式文件系统,主要负责数据存储
-
NameNode(nn)
存储文件的元数据,例如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等
-
DataNode(dn)
在本地文件系统存储文件块数据,以及块数据的校验和。
-
Secondary NameNode(2nn)
用来监控HDFS的状态的后台辅助程序,每隔一段时间获取HDFS元数据的快照。
Yarn架构
多用于资源的调度和分配

-
ResourceManager
- 处理客户端请求
- 监控NodeManager
- 启动和监控ApplicationMaster
- 资源的调度与分配
-
NodeManager
多个NodeManager隶属于一个ResourceManager,管理多个ApplicationMaster
- 管理单个节点上分配到的资源
- 处理来自ResourceManager、ApplicationMaster的命令
-
ApplicationMaster
负责每个任务(job)上进行资源请求和管理
- 负责数据切分
- 为应用程序申请资源,并分配给内部的任务
- 任务的监控和容错
-
Container
Yarn中资源的抽象,封装了某个节点上的多维度资源:内存、CPU、磁盘、网络等。
MapReduce架构

分为两个阶段:Map和Reduce
Map阶段:并行处理输入的数据
Reduce阶段:对Map阶段数据处理的结果进行汇总
来一张简单易懂的图:

大数据的技术生态体系

开发环境搭建
-
修改静态ip
-
修改主机名:
vim /etc/sysconf/network>HOSTNAME=xxx -
修改hosts文件:
vim /etc/hosts -
创建用户添加root权限:
vim /etc/sudoers->sakura ALL=(ALL) ALL -
在/opt目录下创建两个目录:/module和/software,并修改所有者和所有组。
sudo chown sakura:sakura module/ software/ -
导入java、hadoop的tar.gz的安装包
hadoop下载:https://mirror.bit.edu.cn/apache/hadoop/common/
安装jdk
-
解压到module目录下
tar -zxvf jdk-8u251-linux-x64.tar.gz -C /opt/module/ -
配置环境变量
sudo vim /etc/profile# java enviroment export JAVA_HOME=/opt/module/jdk1.8.0_251 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin重新加载配置文件
source /etc/profile -
java -version检查是否安装成功
安装Hadoop
-
解压与jdk安装一样
-
配置环境变量
# hadoop enviroment export HADOOP_HOME=/opt/module/hadoop-2.7.7 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin也需要重新加载配置文件
-
hadoop version检查是否安装成功
-
目录结构了解:

-
bin目录结构:(hadoop的组成的各部分)

-
etc/hadoop目录下存放着大量的配置文件

-
include 引用的其他文件
-
lib 本地库
-
sbin Hadoop相关的启停文件
-
share 一些说明文档和官方提供的example
官方文档:https://hadoop.apache.org/docs/r2.7.7/
-
本地模式
Hadoop官方说明中提到:Hadoop支持三种模式:
- 本地模式(Local Mode)
- 伪分布式模式(Pseudo-Distributed Mode)
- 完全分布式模式(Full-Distributed Mode)

官方给出的第一个example:Grep

-
在hadoop的根目录下创建一个input目录,拷贝 etc/hadoop/下的所有的.xml文件到input目录中

-
执行share目录中指定jar包中的example
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input/ output 'dfs[a-z.]+'注意点:
-
由于这个jar包中有多个程序,我们只需要运行grep即可
-
output一定是未创建的状态,执行位置必须在input的同级目录下,才能将output输出到同级目录
-
若output已存在会报错(file already exist)

-
-
查看输出结果:
在生成的output目录下:有两个文件

前者是生成的结果,可以查看,_SUCCESS仅作为执行状态标志。
结果文件中只有一行:
1 dfsadmin
这就是grep程序过滤出来的结果,你也可以修改正则表达式,删除output目录重新执行。
官方第二个案例`WordCount`(单词数量统计)
1. 创建一个输入文件的目录 wcinput,并创建文件wc.input,并随意写入一些单词
hadoop java
c c++
python java hadoop c
hadoop java hadoop
sakura
java
sakura
2. 启动调用wordcount程序,并指定输入和输出
```shell
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput/ wcoutput
-
查看结果:
还是两个文件:


伪分布式模式
使用分布式的配置,但是只有一台服务器
启动HDFS并运行MapReduce程序
配置集群
-
配置etc/hadoop/core-site.xml文件
一定是写在标签中的:
<!--指定HD
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









